| ||
D-Lib Magazine
|
|
Dale Flecker |
![]()
AbstractHarvard University has funded a 5-year project to build a first generation production infrastructure to support digital library collections. Key project activities include education and consulting on core digital library issues (metadata, technical formats, reformatting, legal issues, preservation, interfaces and access), defining an overall technical framework, and the development of a core set of systems to support digital collections (catalogs and access tools, repositories, user interfaces, access management, and naming). A significant portion of the funding has been allocated to grants to University units for contents projects, intended to inform and test the developing infrastructure. Some months ago I was seated next to Bill Arms at a function. Bill, who most readers know has spoken and written sagely about digital libraries for many years, said he had recently been wondering what a university would actually do at this point if its president or provost provided a significant amount of money for digital library development. This article provides one institution's answer to Bill's question. Harvard University has a large and unusually decentralized library system. Information technology and shared information systems have been used increasingly in the past two decades to bring coherence to library services while maintaining the independence of the University's hundred or so libraries. Two years ago a task force of faculty, librarians, and administrative deans proposed that the University administration fund a project to:
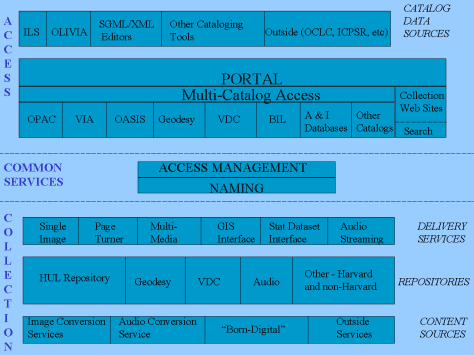
In response, the administration granted $12 million to the University Library for a 5-year project (called the Library Digital Initiative or LDI) to build Harvard's first-generation digital library infrastructure. FocusThe focus of LDI differs from that of many digital library projects in several ways: Production, not research. LDI is not a research project, but is rather intended to develop a solid production environment that will be used to support the day-to-day work of librarians and researchers. Education and ExpertiseOn one level the digital library is similar to a physical library: it involves the same issues of selection, description and intellectual access, housing, protecting, and preserving collections, and providing user assistance. However, digital objects are very different from physical objects in how these needs are satisfied. A different set of knowledge and skills is required, and because the environment is so new, these are not yet widely available. A key part of the LDI has been to build a team with understanding and expertise in various areas relevant to digital resources: Metadata (administrative, technical, and intellectual) This expertise is available to faculty and staff across the university in the form of consultation, project assistance, public presentations, and the publication of guidelines and best practice recommendations. Providing this type of consultation and education is a primary duty for several members of the LDI staff, and is not merely a sideline to be attended to as time allows. Technical InfrastructureWhile it is fashionable to say that the real issues of digital libraries are not technical, but rather intellectual and organizational, in fact there is a great deal of new technical infrastructure that is going to be required for institutions to support large-scale digital collections. Many of the early digital libraries built as research projects were conceived from the top down, and assembled as a coherent set of pieces. The real-world digital libraries that research universities will require will not be like that at all. They will be composed of a large and messy collection of systems, some of which will be internal to the institution, but many of which will be distributed across the internet and controlled by a large number of independent players. Over time the task of building an institution's digital library infrastructure will be more one of systems integration than of system building. Today, however, because many of the pieces of required infrastructure are not readily available in the marketplace or are available only as tools and not as packaged solutions, significant technical work is required to construct a working environment. The initial technical focus of the LDI is on a core set of internal systems. Appendix 1 provides an overview of the key pieces of infrastructure currently available or in implementation. The figure groups components in three primary categories:
Collections InfrastrucureRepositories. While the majority of any library's digital collection will be provided through external systems (e.g., e-journal sites, collections mounted by scholarly societies, resources at other libraries, etc.), research libraries are likely to house significant local collections themselves. Managing large numbers of digital objects over time is a nontrivial task. One of the key components of the LDI infrastructure is a generalized repository. Its purpose is to provide a robust service to store, manage, protect, and serve heterogeneous digital objects and to provide information and facilities for the preservation of those objects. The core repository is insensitive to the nature of stored objects, which are treated simply as ordered collections of bits. The repository holds two types of metadata about stored objects: a small common set of data needed to manage each object (ownership, status, access rules, interobject relationships, etc.), and varying sets of metadata specific to the particular type of object (still image, sound file, etc.). The current LDI repository is implemented as an Oracle database for metadata management and a file system on network accessible storage (NAS) hardware for the objects themselves. The use of Oracle for the metadata will support curatorial needs for the analysis of collections for preservation management and risk assessment. The core repository will be available for use beyond the library. It will be operated in part as a cost-recovered business, with charges set to recover the marginal costs of specific object storage. Expenses related to the overhead of repository operation and maintenance will be treated as a common good and not recharged to depositors. By policy, the repository is to be used for library-like objects (research resources of lasting value) that are available to the entire Harvard community. Operation of the repository explicitly includes responsibility for the preservation and migration of deposited objects: a responsibility now being defined in greater detail. Depositing adequate metadata along with an object in order to support this preservation function is a key requirement of the repository. For a variety of reasons, some locally stored collections will be housed in specialized repositories. The Harvard MIT Data Center is developing a system that will support functions sensitive to the nature of social science datasets: allowing users to access specified subsets of data and providing relatively simple exploratory analysis of a dataset to aid users in deciding whether it is relevant to their needs. Another system is being implemented under LDI to support geographic information datasets. This repository will provide facilities to allow a curator to publish selected datasets to the web, obviating the need to use specialized GIS (Geographic Information System) software to satisfy common user needs. In each of these cases, a customized repository is used, supporting functions specific to the object types involved. Delivery Services. There are of course many formats of materials in a library's digital collection, each with its own specific user interface/delivery application. Many different delivery applications will be required over time. At this point the infrastructure includes six delivery applications:
All delivery applications must enforce access rules, using the access management common facility for authentication and profile data. Content Sources. Data objects will come from many different sources. Born digital materials will be acquired from a variety of sources inside and outside the University. For materials converted from Harvard's traditional collections, services are being developed by several different units of the University. Two departments have been established to do high-quality image capture (both through scanning and digital photography): the Harvard College Library Digital Imaging Group and the University Art Museums and Fine Arts Library Imaging and Photographic Studio. In both cases the conversion services provide metadata needed by the repository for object management, and both will have facilities for efficient automated deposit of objects into the repository. In addition, the Edna Kuhn Loeb Music Library has a sophisticated facility for digital conversion of audio materials. Access InfrastructureCatalogs. One of the more striking aspects of the LDI project to date is the proliferation of catalogs providing access to the collections. Like all research institutions, Harvard has long provided access to a local OPAC (named HOLLIS) and a plethora of outside abstracting and indexing databases and catalogs. However, in addition, four other Harvard catalogs have either been implemented or are in development as part of LDI: OASIS, containing encoded archival finding aids (EADs) In addition to these, two other catalogs are being developed elsewhere in the University that will provide access to digital resources: the catalog of social science datasets provided by the Harvard MIT Data Center, and a catalog of botanical specimens being developed by the University Herbaria which will provide access to some materials from LDI projects. Multi-Catalog Access. There are many reasons these separate catalogs develop1. Separate catalogs frequently provide better service to users, as small catalogs are easier to use than large ones, and topical or format segregation can simplify finding materials for the user who knows precisely what he or she needs. However, a large number of catalogs and finding aids can obviously also be confusing and harder to use. In order to alleviate the increasing complexity of our catalog environment, an upcoming project will investigate various multi-catalog support tools. Among the approaches to be examined are a distributed search front-end (to provide parallel searching of multiple catalogs with a single command), a supercatalog with data drawn from multiple existing catalogs (perhaps based on metadata harvesting along the lines of the Open Archives Initiative), and facilities to help navigate between catalogs. Collection Web Sites. Many digital library projects involve the construction of individual web sites to provide description and navigation of specific collections. These sites have generally been hand-crafted by individual curators, raising obvious questions about long-term maintenance (curators leave, technological change suggests new approaches). The LDI will be experimenting with a different approach: using XML-encoded documents and XSL style sheets to automatically generate collections sites. The hope is that by creating sites as data objects, long-term maintenance can be handled as a centralized programming task rather than as a long series of decentralized individual maintenance tasks. A key requirement of many collection web sites is the ability to search unstructured text documents (such as dirty OCR-created text to provide access to page images). A simple text search facility supporting word searching, Boolean operations, and similar commonly expected functions will be available for inclusion in collections web sites when appropriate. Portal. As the library's electronic resources grow in number and complexity, there is a need for a better means of organizing and explaining what is available. An enhanced portal system, providing a more organized and coherent view of resources has been developed to assist library users in navigating a richer but dramatically more confusing environment of electronic systems and services. Common ServicesNaming. Naming provides a robust means of identifying and finding digital materials unaffected by changes of technology or location. Unlike URLs, names do not point to the location of the named object. Instead, at the point of use a name invokes a resolution service that returns the current location of the named item. This intervening level of indirection provides two key benefits:
Eventually we hope that a true URN service will become a standard supported service of the network (as DNS is today), and the LDI naming scheme has been designed to be compatible with the proposed IETF URN scheme. In the interim, a naming service has been developed locally. It has two components:
Names are hierarchically structured to allow the distribution of naming responsibility to different organizational units in the University. The naming service is integrated with the LDI repository, and upon request deposited objects can automatically receive well-formed and registered names. The most common uses of names are to link from catalogs or web sites to digital objects and to link objects to each other. In general, object pointers resolve to a delivery service (described above), with the item identifier as a parameter. Access Management. Issues of intellectual property and the need to restrict access to objects or services permeate the digital library. Access management services are intended to provide a single mechanism to be shared by many systems. There are two key functions of the service:
Authentication and profile information are stored in cookies on a user's browser, so that the user does not need to provide repeated authentication information when navigating from resource to resource. Because of the problem posed by public kiosks, these cookies expire after a limited time. Applications that require assurance of authentication can ignore such cookies and request fresh authentication from the service. The Access Management service is designed for very high performance and availability (using redundant servers with load balancing and fail-over facilities) and is being used today by the library's portal system, a high-volume application that provides access to licensed internet resources. Content ProjectsA significant portion ($5 million) of the funding for LDI will be used to support individual projects that make digital content available through the LDI infrastructure. These projects are intended to:
In the first two years of LDI, semiannual calls for proposals were issued. Applications were received from many parts of the University (grants are not limited to libraries, although each proposal must have at least one library sponsor). To date nine projects have been funded, involving a wide range of materials: Visual materials. Projects to convert existing visual materials are the largest category of proposals. Funded projects include the conversion of nineteenth-century trade cards (from the Baker business library), images of Asian art (from the Fogg Art Museum and the Fine Arts Library), historic images of China (from the Harvard Yenching Library), and historic images of Mayan ruins (from the Peabody museum). In addition, a major project has been funded dealing with digital biomedical images, an example of born digital materials. Related ActivitiesThe Harvard University Library is a cooperating partner in a project of the Harvard MIT Data Center to build a distributed system of social science dataset archives. Funded under the NSF digital library program, the project will develop sharable, open-source software to provide a catalog, repository, and user interface for collections of datasets, and a facility to allow collections to share information about their holdings. For the past three years the Library has participated in a project with the American Political Science Association to provide on-line access to papers from the Association's Annual Meeting. Harvard and the APSA are now embarking on a planning effort (with funding from the Andrew W. Mellon Foundation) to examine the application of information technology to the communications programs of the Association. Topics to be analyzed include electronic journals (the Association publishes the premier journal in the field), e-prints, links between formal publications and supporting digital resources (e.g., the ability to link from a journal article to the dataset created by or used in the research described), and the archiving of digital scholarly communications. A key task in this planning effort will be an examination of the relative roles of scholarly societies and research libraries in the evolving scholarly communications environment. Status and Future DevelopmentsThe program elements discussed above are in various stages of implementation. Consulting and education initiatives have been very active areas from the very beginning of the initiative. LDI staff have met with innumerable people from many parts of the University: the libraries, archives, museums, academic computing and course support departments, information technology departments, the Arboretum, the University Herbarium, and various academic centers and departments. Some parts of the technical infrastructure are in production release (the new portal, the visual materials and archival finding aid catalogs, naming, access management services). The initial release of the repository service is scheduled for this October. Other pieces are in development or analysis. All of the contents projects are well underway, and several (trade cards, historical photographs of China, Harvard and Radcliffe historical materials) are nearing completion. LDI resources have made it possible for Harvard to participate in a number of experimental initiatives and projects, including a trial of Ex Libris' SFX product (intended to support the localization of intersystem links), the LOCKSS experiment (an initiative of High Wire Press to prototype the large-scale replication of electronic journals), a metadata harvesting initiative (supported by the Digital Library Federation and the Open Archives initiative), and work with the International DOI Foundation and CrossRef on localizing links to electronic journals. Some of these experiments will undoubtedly lead to future components of the LDI infrastructure. The largest single investment the library is now making in digital collections is in licensing electronic journals. Yet today there exists no convincing strategy for the long-term maintenance and archiving of such journals. Harvard, in conjunction with a number of other research libraries, is in the throes of a major planning effort aimed at defining an e-journal archiving initiative. The intent is to utilize the infrastructure being developed under the LDI to support the large-scale archiving of current electronic journals. This initiative will certainly require the development of a number of new functions, including a scalable, automated ingest function, format conversion facilities, auditing tools, and perhaps an archive inventory system. As LDI enters its third year, we will be conducting a formal midproject review to evaluate current activities, identify missing pieces, and begin to plan for postproject continuation. One specific issue being discussed is the randomness of the areas covered by the content projects. Since these depend upon the initiative of individuals, it is no surprise that the inventory of projects undertaken is spotty, and that there are notable gaps (there have been for instance, no projects dealing with encoded humanities texts or with video, both areas important in many digital library projects). Future calls-for-proposals will probably encourage projects which address such gaps. It is also possible that specific projects will be commissioned to address strategic topics. Another issue to be examined is the continuation of the initiative after the initial five-year project. Given the range of departments that have been involved in the Initiative, there are likely to be challenging organizational issues about the on-going governance and funding of digital library infrastructure after grant funding ends. Perhaps the most striking feature of the LDI to date, and undoubtedly one of its major weaknesses, is that it has been predominantly focused on resources inside the University. The majority of any library's digital offerings will undoubtedly be held externally. Over time the key challenge in building institutional digital libraries will be the integration of the many heterogeneous external resources into coherent services for the population of the institution. To date, little attention (beyond the issues of portal organization and access management) has been paid to what it means to integrate internal and external resources. This may well be a major focus of a later phase of the LDI. Further information on the Library Digital Initiative and links to materials on the individual systems and projects described here can be found at: <http://hul.harvard.edu/ldi/>. NoteDifferent catalogs can support differing metadata standards (AACR II, FGDC), differing vocabularies (LCAF, ULAN, MESH, scientific rather than common names), and different formats for data exchange (MARC, DDI, EAD). Further, in many cases different catalogs provide different functionality (e.g., document ordering or map-based interface for searching), or simply reflect separate organizational responsibility (the University Library supports the HOLLIS opac, the Harvard MIT Data Center is responsible for the Virtual Data Center, and the University Herbarium is developing a botanical specimen database). Appendix: Architectural Overview
KEY: ILS: Integrated Library System, the library's core tool for managing traditional collections and for maintenance of MARC format bibliographic data. Copyright© 2000 Dale Flecker |
|
|
Top
| Contents |
|
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/november2000-flecker
|