|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
David Mimno Gregory Crane |
![]()
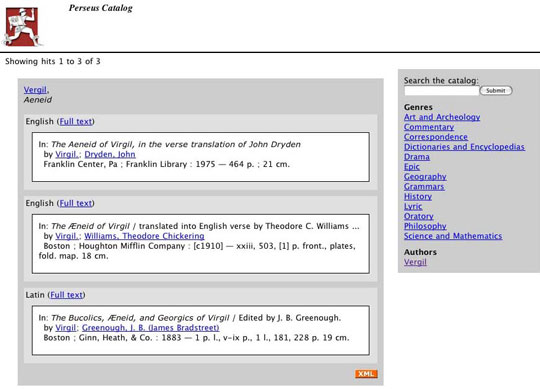
AbstractIFLA's Functional Requirements for Bibliographic Records (FRBR) lay the foundation for a new generation of cataloging systems that recognize the difference between a particular work (e.g., Moby Dick), diverse expressions of that work (e.g., translations into German, Japanese and other languages), different versions of the same basic text (e.g., the Modern Library Classics vs. Penguin editions), and particular items (a copy of Moby Dick on the shelf). Much work has gone into finding ways to infer FRBR relationships between existing catalog records and modifying catalog interfaces to display those relationships. Relatively little work, however, has gone into exploring the creation of catalog records that are inherently based on the FRBR hierarchy of works, expressions, manifestations, and items. The Perseus Digital Library has created a new catalog that implements such a system for a small collection that includes many works with multiple versions. We have used this catalog to explore some of the implications of hierarchical catalog records for searching and browsing. 1. IntroductionCurrent online library catalog interfaces present many problems for searching. One commonly cited failure is the inability to find and collocate all versions of a distinct intellectual work that exist in a collection and the inability to take into account known variations in titles and personal names (Yee 2005). The IFLA Functional Requirements for Bibliographic Records (FRBR) attempts to address some of these failings by introducing the concept of multiple interrelated bibliographic entities (IFLA 1998). In particular, relationships between abstract intellectual works and the various published instances of those works are divided into a four-level hierarchy of works (such as the Aeneid), expressions (Robert Fitzgerald's translation of the Aeneid), manifestations (a particular paperback edition of Robert Fitzgerald's translation of the Aeneid), and items (my copy of a particular paperback edition of Robert Fitzgerald's translation of the Aeneid). In this formulation, each level in the hierarchy "inherits" information from the preceding level. Much of the work on FRBRized catalogs so far has focused on organizing existing records that describe individual physical books. Relatively little work has gone into rethinking what information should be in catalog records, or how the records should relate to each other. It is clear, however, that a more "native" FRBR catalog would include separate records for works, expressions, manifestations, and items. In this way, all information about a work would be centralized in one record. Records for subsequent expressions of that work would add only the information specific to each expression: Samuel Butler's translation of the Iliad does not need to repeat the fact that the work was written by Homer. This approach has certain inherent advantages for collections with many versions of the same works: new publications can be cataloged more quickly, and records can be stored and updated more efficiently. 2. FRBR ImplementationsOne recent survey of FRBR implementations by Martha Yee has described some of the common problems users have with library catalog systems and ways that a FRBR organization can address those problems (Yee 2005). First, she finds that it is often difficult to search for author and title combinations because variant name information is isolated in authority records. Second, she finds that catalogs are often poor at displaying the full range of relevant materials that the library holds because of variations in titles. Yee then describes how both problems can be addressed by making the catalog more aware of connections between author information and work information and between different versions of the same work. A great deal of research has examined how the implementation of FRBR might affect online public access catalogs (OPAC). In recent years, OCLC has launched a number of FRBR related research projects. After conducting a number of experiments with WorldCat records, OCLC researchers concluded that the algorithmic identification of expressions is quite difficult and decided to focus their research on the identification of works instead (Hickey 2002). Other OCLC projects have included the creation of an open source FRBR Work-set algorithm that converts MARC21 bibliographic databases to a FRBR model (FRBR Work-set Algorithm 2005) and the development of the FictionFinder catalog, a FRBR prototype system for searching and browsing bibliographic records for fictional works (FictionFinder 2005). Searches in the FictionFinder system return a list works, rather than a list of individual bibliographic records. Selecting a particular work leads to a list of expressions of that work, and choosing an individual expression leads to a list of manifestations. In early 2005, OCLC announced a new project entitled CURIOSER that will seek to make open WorldCat more useful and will integrate previous OCLC FRBR research in order to support display and navigation of records in a FRBR context (CURIOSER 2005). Similarly, the Research Libraries Group has created RedLightGreen, an online catalog designed specifically for undergraduates that utilizes the FRBR model while not yet serving as a full FRBR implementation (RedLightGreen 2005). Merilee Proffitt of RLG has described this prototype as a FRBRish not FRBRized catalog that has utilized many of the intellectual concepts behind FRBR in its design. System designers found that the FRBR Group 1 entities of work, expression, manifestation and item were important during the conceptual modeling stages and have used these concepts to determine how records should cluster in their catalog (Proffitt 2004). FRBR has also been implemented in the Australian Literature Gateway (AustLit) with some modifications and extensions to the basic model. AustLit augmented the FRBR model with INDECS event modeling in their digital gateway to Australian literature. In their model, works have a creation event, expressions have a realization event, and manifestations have an embodiment event (Ayres 2003). Their modeling also introduced the concept of the Super Work. They found that there were a number of issues in converting the data to the FRBR model, of particular concern was the fact that the FRBR model has a whole monograph emphasis and most of their records were non-monograph items such as individual poems or reviews (Ayres 2004). Nonetheless, they were able to develop a number of automated processes to convert records to the FRBR format, and developed a maintenance interface to support human intervention with problematic records. The hardest challenge for catalogers was in distinguishing between new expressions and manifestations of works. In designing their user interface, they chose to use light visual clues like dot points and simple text statements such as "this work has appeared in x different versions" to guide the user. During evaluation they found that users seemed to have no difficulty in navigating the interface (Ayers 2004). Some FRBR research has involved the creation of tools for experimenting with the model, rather than full implementation of FRBR catalogs. The Library of Congress has created a FRBR display tool that takes flat files of MARC records and uses XSLT to transform this data into meaningful displays by grouping the bibliographic data into the "Work," "Expression" and "Manifestation" FRBR entities (FRBR Display Tool 2004). The tool is largely intended to display FRBR on the fly for libraries wishing to experiment with the model (Radebaugh 2004). Roberto Sturman, a librarian at the University of Trieste has also developed an experimental FRBR tool called IFPA (ISIS FRBR Prototype Application) that can be viewed on the Web (IFPA 2005). This software serves as an application for the UNESCO ISIS retrieval software and was developed to manage the data and relationships implied in the FRBR model. Sturman stresses that his tool is meant to serve as an academic experiment that will assist people interested in experimenting with the FRBR model (Sturman 2004). Several commercial vendors have also designed FRBR implementations. The Virtua catalog developed by VTLS Inc. is marketed as offering full support of the FRBR Model (Virtua 2005), while Portia has created VisualCat, an integrated cataloging system that is capable of consolidating different types of metadata within a single semantic framework based on RDF and FRBR (VisualCat 2005). 3. The Perseus Digital LibraryWe felt that the Perseus Digital Library (PDL) would be an ideal testbed for research on FRBR-based records and catalog interfaces for several reasons:
4. Building a Hierarchical CatalogThe format we chose to express our metadata was a combination of the MODS (Metadata Object Description Schema) and MADS (Metadata Authority Description Schema) standards. As was previously argued by Karen Coyle (Coyle 2004), we felt that incrementally improving the MARC record would not be a productive direction. Compared to newer XML-based formats, the infrastructural overhead of parsing, searching, and displaying MARC records was too great to make a MARC-based approach feasible. Another important feature of the MODS/MADS family is that it includes the extremely flexible <relatedItem> field, which was explicitly designed to express a wide variety of relationships between catalog entities.
The starting point for our catalog was a set of MODS catalog records downloaded directly from the Library of Congress through the Voyager SRU service and manually created from OCLC WorldCat catalog data. The Perseus Digital Library has for many years maintained links between TLG identifiers for canonical works and the documents in the collection that are instances of those works (Mahoney 2000). These two databases were sufficient to generate the hierarchical catalog. Our work-level records are MADS records, extending the notion of the work as an authorized entity. The two remaining levels are implemented as MODS records. Although this distinction makes sense bibliographically, it did present difficulties in implementation, as all XPath queries against the database had to be formulated both in the MODS namespace and the MADS namespace. The last step in the process was to divide information currently in individual records into multiple hierarchical records. For single-manifestation works, this was simply a matter of passing the record through three different XSL filters. The division of metadata fields between FRBR levels is based on a proposal by Sally McCallum. (McCallum 2004). For works with more than one manifestation (largely primary texts in the Classics collection), the work-level records were generated separately from an existing bibliographic database at Perseus, independently from the LC MODS records. The distribution of MODS fields was as follows:
5. Hierarchical Records and Analytical CatalogingBringing more focus to the hierarchical relationships between intellectual works and their manifestations in our documents has also brought part-whole relationships into more prominence. Very often, manifestations of shorter works are found in our collection as part of larger volumes, for example collections of speeches by minor Attic orators or the complete works of Aeschylus. These relationships raise interesting questions. At the work level, one play by Aeschylus is clearly a distinct entity from another play, but at the manifestation level, the publication information for every translated play in the volume is the same, and therefore should be kept in a single record. Our current implementation addresses this problem by linking a single manifestation-level record for the multi-work volume to multiple expression-level works. This compromise works for our collection, but we cannot be certain that it will scale to larger collections, especially those for which analytical catalog data is not currently available. 6. Searching a Hierarchical CatalogAlthough a hierarchical catalog has many obvious advantages for searching and browsing, it presents some new challenges in implementation. With ordinary MARC records, searching a catalog has been fairly simple. A set of query terms is matched against a set of records, returning the subset of records that contain some or all of the search terms. In contrast, searches against hierarchical catalogs can become extremely complex. A single search might contain terms that occur at several different levels. For example, a search for "Butler AND Iliad" would need to match an expression-level element (translator) and a work-level element (uniform title). Even when matching records are located, they may not contain complete information: in the previous example, the system would still need to request one or more manifestation-level records. The system may also want to expand search results to include other expressions and manifestations of a matched work. Finally, de-duplication becomes an important problem. If both the work record and a manifestation record match the query (such as "Iliad" in the title and the uniform title) the system needs to know not to expand the records in both directions. None of these problems are directly addressed by current XML databases. In order to create a catalog that displayed the unique, complete results returned by arbitrary queries in hierarchical format, we would have needed to implement complex matching algorithms and slow, recursive record expansion algorithms. Initial experiments with simple queries showed noticeable performance problems. The simplest solution we have found for the problems outlined above is to keep two parallel versions of the catalog, both containing the same records. The first is simply a collection of individual records, one for each work, expression, and manifestation. The second is a set of "composite" records, one for each work, that bring together in one XML tree all of the expressions of the work and all of the manifestations of each of those expressions. The first set are the editable copies. To draw an analogy to computer programming, they are the "source code". The second set is the "compiled" version, optimized for searching. By creating composite records, we essentially reduce the problem of searching the hierarchical catalog to the earlier problem of searching a "flat" catalog: the search engine, in our case an XML database, is simply asked to return the records that match a query. The display code, an XSL stylesheet, can then choose whether or not to display unmatched elements of the composite record (e.g. versions of the Iliad not translated by Butler), and how to highlight the terms that matched the query. In our experiment, we used custom tags (<work>, <expression>, <manifestation>) as a framework for the hierarchical structure of the composite records. In order for catalogs of this nature to be accessible through federated searching systems such as SRU/W, the library community must standardize on a means for specifying relationships between blocks of XML. This could include some form of METS or RDF XML. 7. ConclusionsOur work has shown that small, theoretically well-founded changes in the structure of catalog records, combined with readily available database software can produce catalog interfaces that address previously identified problems with existing library catalog interfaces. The Need for New IdentifiersOne aspect that this work has highlighted is the need for unique identifiers at every hierarchical level. This need has been previously identified by Karen Coyle (Coyle 2004). Identifiers provide the "glue" that holds distributed records together. Currently, most standard identifiers (OCLC accession numbers, ISBNs, LCCNs) are issued at the manifestation level. Work-level identifiers exist in narrow domains, such as the TLG for works in Greek and uniform titles for works with many cataloged versions. Even these sources are problematic. Catalogers may not be aware of special-purpose schemes such as the TLG. Uniform titles, which are designed to be read by humans, are inefficient and unwieldy for computational use. As Kristin Antelman points out, "Documents do not need to be described to be referenced in a networked world; they must be identified. An inherently descriptive element, such as title, cannot meet the requirements of a network identifier." (Antelman 2004) Creating new identifiers for work- and expression-level entities is a reasonable goal within a short period of time. The technology of identifiers is already well studied. Several high quality systems for creating identifiers have been implemented. These systems are not, however, currently being applied to more abstract bibliographic entities. The creation of work-level identifiers is a question of deterimining the correct authorities for issuing the identifiers and reliable methodologies for distinguishing works, not one of actually producing the identifiers themselves. At a recent workshop at OCLC on issues related to FRBR, Ketil Albertsen (Albertsen 2005) outlined a number of the attributes of a successful identification scheme and Patrick Le Boeuf (Le Bouef 2005) described systems that could potentially fill some of the requirements. Deciding a new system of identifiers and issuing authorized numbers for works is a role that small libraries like Perseus cannot fulfill. In order for distributed hierarchical catalogs to become useful, there must be a network of widely known naming authorities, such as national libraries, that can assign unique identifiers to all cataloged intellectual works and expressions. BenefitsMoving to a hierarchical catalog would involve a substantial investment in time, money, and technology. The end result, however, is a higher quality catalog that can be more easily maintained, distributed, and searched. The hierarchical MODS/MADS catalog effectively separates FRBR levels into manageable segments. These segments in turn provide easily updatable and reusable building blocks for further cataloging and networked catalog reuse. When we add a new translation of Livy's history of Rome to our library, we only need to locate the standard identifier for the work and specify it along with a small amount of publication information. The benefits for library users are also clear. The composite records described in this article automatically organize complex works with many manifestations into a simple, understandable format. Searching for a title and author combination brings up an interface that displays all available versions, even those that would not by themselves match the query. These records can also integrate work-level authority data such as alternate titles into the searchable record. As a result, searching the catalog becomes dramatically more powerful while at the same time retaining simplicity and efficiency in implementation. Appendix: A sample of a composite record made up of distinct work, expression, and manifestation records ReferencesAlbertsen, Ketil. "What Do We Want to Identify? - FRBR and Identifier Semantics" Presentation at FRBR in 21st Century Catalogues: An Invitational Workshop. May 2-4 2005, Ohio. Available online at <http://www.oclc.org/research/events/frbr-workshop/presentations/albertsen/FRBR_identifiers.ppt>. Antelman, Kristin. "Identifying the Serial Work as a Bibliographic Entry." Library Resources & Technical Services, 48.4 (2004): 238-55. Ayres, Marie Louise, Kerry Kilner, Kent Fitch and Annette Scarvell. "Report on the Successful Austlit: Australian Literature Gateway Implementation of the FRBR and INDECS Event Models, and Implications for other FRBR Implementations." International Cataloging and Bibliographic Control, 31.1 (2003): 8-13. Ayres, Marie-Louise. "Case studies in implementing FRBR: AustLit and MusicAustralia." Paper presented at "Evolution or Revolution? The Impact of FRBR." 2 Feb. 2004, Melbourne, Australia. 2 July 2005. Coyle, Karen. "Future considerations: the functional library systems record." Library Hi Tech, 22.2 (2004): 166-174. CURIOSER. OCLC. 30 June 2005. <http://www.oclc.org/research/projects/curiouser/default.htm>. FictionFinder: A FRBR-Based Prototype for Fiction in WorldCat. OCLC. <http://www.oclc.org/research/projects/frbr/fictionfinder.htm>. FRBR Display Tool Version 2.0. 31 Mar 2004. Network Development and MARC Standards Office-Library of Congress. 7 July 2005. <http://www.loc.gov/marc/marc-functional-analysis/tool.html>. FRBR Work-Set Algorithm. OCLC. 30 June 2005. <http://www.oclc.org/research/software/frbr/default.htm>. Hickey, Thomas B, Edward T. O'Neill and Jenny Toves. "Experiments with the IFLA Functional Requirements for Bibliographic Records (FRBR)." D-Lib Magazine, 8.9 (2002). 27 July 2005. <doi:10.1045/september2002-hickey>. IFLA Study Group on the Functional Requirements for Bibliographic Records. Functional Requirements for Bibliographic Records: Final Report. UBCIM Publications-New Series. Vol. 19, Munchen: K.G.Saur, 1998. <http://www.ifla.org/VII/s13/frbr/frbr.htm> IFPA (FRBR Prototype Application) home page. 23 Nov. 2004. ed. Roberto Sturman. 11 July 2005. <http://pclib3.ts.infn.it/frbr/FRBR.htm>. Le Bouef, Patrick. "Identifying 'textual works': ISTC: controversy and potential." Presentation at FRBR in 21st Century Catalogues: An Invitational Workshop. May 2-4 2005, Dublin, Ohio. Available online at <http://www.oclc.org/research/events/frbr-workshop/presentations/leboeuf/ISTC.ppt>. Mahoney, Anne, Jeffrey A. Rydberg Cox, David A. Smith and Clifford E. Wulfman. "Generalizing the Perseus XML Document Manger." Paper presented at the workshop on Web-Based Language and Documentation and Description, 12-15 Dec. 2000, Philadelphia, USA. 23 Aug. 2005. McCallum, Sally. "An Introduction to the Metadata Object Description Schema (MODS)." Library Hi-Tech, 22.1 (2004): 82-88. Proffitt, Merrillee. "RedLightGreen: FRBR Between a Rock and a Hard Place." Presentation at ALCTS Preconference, ALA Annual Meeting, 25 June 2004, Orlando, Florida. 1 July 2005. Radebaugh, Jackie and Corey Keith. "FRBR Display Tool." Cataloging & Classification Quarterly, 39, 3-4 (2004): 271-283. RedLightGreen. Research Libraries Group. 30 June 2005. <http://www.redlightgreen.com>. Sturman, Roberto. "Implementing the FRBR Conceptual Approach in the ISIS software environment: IFPA (FRBR Prototype Application). " Cataloging & Classification Quarterly, 39.3/4 (2004): 253-70. Virtua. Visionary Technology in Library Services Inc. 12 July 2005. <http://www.vtls.com/Products/virtua.shtml>. VisualCat. Portia. 14 July 2005. <http://www.portia.dk/pubs/VisualCat/Present/VisualCatOverview20050607.pdf>. Yee, Martha M. "FRBRization: a Method for Turning Online Public Finding Lists into Online Public Catalogs." Information Technology and Libraries. 24.3 (2005): 77-95. 30 Jul. 2005. Postprint available free at <http://repositories.cdlib.org/postprints/715/>. Copyright © 2005 David Mimno, Gregory Crane, and Alison Jones |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/october2005-crane
|