| ||
D-Lib Magazine
|
|
|
Renato Iannella |
![]()
1. IntroductionDigital Rights Management poses one of the greatest challenges for content communities in this digital age. Traditional rights management of physical materials benefited from the materials' physicality as this provided some barrier to unauthorized exploitation of content. However, today we already see serious breaches of copyright law because of the ease with which digital files can be copied and transmitted. Previously, Digital Rights Management (DRM) focused on security and encryption as a means of solving the issue of unauthorized copying, that is, lock the content and limit its distribution to only those who pay. This was the first-generation of DRM, and it represented a substantial narrowing of the real and broader capabilities of DRM. The second-generation of DRM covers the description, identification, trading, protection, monitoring and tracking of all forms of rights usages over both tangible and intangible assets including management of rights holders relationships. Additionally, it is important to note that DRM is the "digital management of rights" and not the "management of digital rights". That is, DRM manages all rights, not only the rights applicable to permissions over digital content. In designing and implementing DRM systems, there are two critical architectures to consider. The first is the Functional Architecture, which covers the high-level modules or components of the DRM system that together provide an end-to-end management of rights. The second critical architecture is the Information Architecture, which covers the modeling of the entities within a DRM system as well as their relationships. (There are many other architectural layers that also need to be considered, such as the Conceptual, Module, Execution, and Code layers [HOFMEISTER], but these architectures will not be discussed in this article.) This article discusses the Functional and Information Architecture domains and provides a summary of the current state of DRM technologies and information architectures. 2. Functional ArchitectureThe overall DRM framework suited to building digital rights-enabled systems can be modeled in three areas:
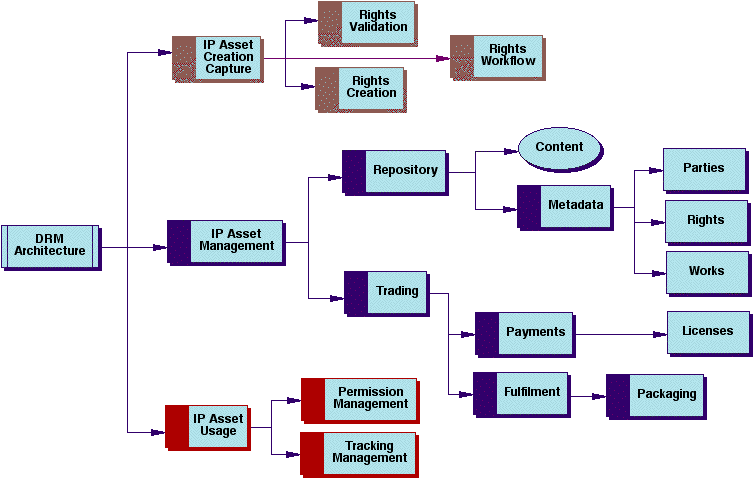
While the above models comprise the broad areas required for DRM, the models need to be complemented by the Functional Architecture that provides the framework for the modules to implement DRM functionality (see Figure 1). |
|
|
|
|
The Functional Architecture stipulates the roles and behavior of a number of cooperating and interoperating modules under the three areas of Intellectual Property (IP): Asset Creation, Management, and Usage. The IP Asset Creation and Capture module supports:
The IP Asset Management module supports:
The IP Asset Usage module supports:
Together, these three modules provide the core functionality for DRM systems. The modules have been described only at a high level, and they would also need to operate within other, existing e-business modules (such as shopping carts, consumer personalization, etc.) and Digital Asset Management modules (such as version control, updates, etc.). Additionally, the modules would support interoperability, trust, standard formats, openness and other such principles described in an article by John Erickson in D-Lib Magazine's April 2001 issue [ERICKSON]. Ideally, these modules would be engineered as components to enable systems to be built in a modular fashion. However, this implies a set of common and standard interfaces/protocols between the modules that does not yet exist. As DRM matures, the industry will move towards such standardization. For example, a DRM trading protocol is under development in the OpenEBook Forum's Rights & Rules Working Group for ebook vendors [OEBF]. The Functional Architecture is only part of the solution to the challenges of DRM. Rights Management can become complex remarkably quickly. As a result, DRM systems must support the most flexible information model possible to provide for these complex and layered relationships. The Information Architecture provides this. 3. Information ArchitectureThe Information Architecture deals with how the entities are modeled in the overall DRM framework and their relationships. The main issues that require addressing in the development of a DRM Information model include:
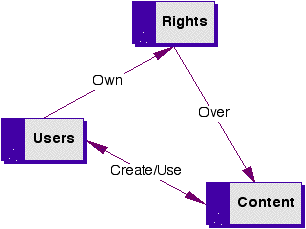
3.1 Modeling the entitiesIt is important to adopt a clear and extensible model for the DRM entities and their relationship with other entities. Existing work in this area includes the <indecs> project [INDECS]. The basic principle of the <indecs> model is to clearly separate and identify the three core entities: Users, Content, and Rights as shown in Figure 2. Users can be any type of user, from a rights holder to an end-consumer. Content is any type of content at any level of aggregation. The Rights entity is an expression of the permissions, constraints, and obligations between the Users and the Content. The primary reason for this model is that it provides the greatest flexibility when assigning rights to any combination or layering of Users and Content. The Core Entities Model also does not constrain Content from being used in new and evolving business models. |
|
|
|
|
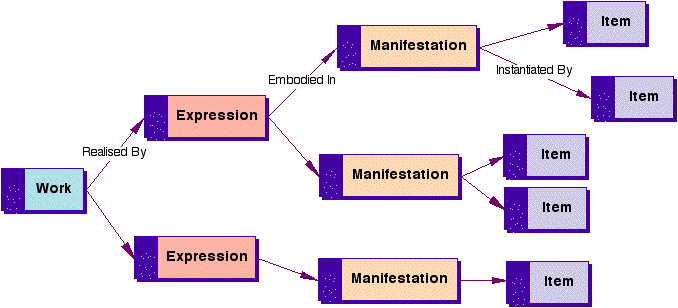
This model implies that any metadata about the three entities needs to include a mechanism to relate the entities to each other. The Content itself also needs to be modeled. Again, there has been some existing work in this area from the International Federation of Library Associations [IFLA]. The key principle in the modeling of Content is that Content contains many "layers" from various intellectual stages or evolution of its development. Such a model will enable clearer (i.e., more explicit and/or appropriate) attribution of rights information. For example, the IFLA model allows Content to be identified at the Work, Expression, Manifestation, and Item layers. At each of these layers, different rights and rights holders may need to be supported as shown in Figure 3. |
|
|
|
|
The layers of the Content defined as Work (a distinct intellectual or artistic creation) and Expression (the intellectual or artistic realization of a work) reflect scholarly or creative content. On the other hand, the other layers of Content, defined as Manifestation (the digital embodiment of an expression of a work) and Item (a single exemplar instantiation of a manifestation), reflect physical or digital form. As an example, consider "The Name of the Rose". The Work, by Umberto Eco, would be the idea of the events that took place in an isolated Benedictine monastery and include descriptions of the concepts and main ideas, features, or characters. The Expressions of the Work could then include:
The Manifestations of the "English translation" Expression could include:
The Items of the "book" Manifestations could include:
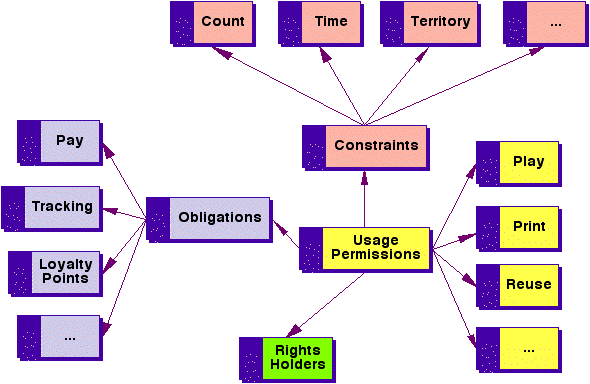
The important point in this style of content modeling is that at any of the points in the IFLA model, different rights holders can be recognized. Another aspect that may affect rights is when Content is made of many parts. Some of these parts may have different rights associated with them that need to be recognized in the aggregated content. 3.2 Identifying and describing the entitiesAll entities need to be both identified and described. Identification should be accomplished via open and standard mechanisms for each entity in the model. Both the entities and the metadata records about the entities must be identifiable. Open standards such as Uniform Resource Identifiers [URI] and Digital Object Identifiers [DOI] and the emerging ISO International Standard Textual Work Code [ISTC] are typical schemes useful for Rights identification. Content should be described using the most appropriate metadata standard for that genre (for example, the EDItEUR ONIX standard [ONIX] for books (physical and electronic) and the IMS Learning Resource Meta-data Information Model [IMS] for educational learning objects). It is also critical that such metadata standards do not themselves try to include metadata elements that attempt to address rights management information, as this will lead to confusion regarding where to describe such rights expressions. For example, the ONIX standard has elements for a number of rights holders (e.g., Authors and Publishers) and Territories for rights and single Price information. (The latter poses a problem in setting multiple prices depending on what rights are traded). In such cases, following the <indecs> model should take precedence. To describe Users, vCard [VCARD] is the most well-known metadata standard for describing people and (to some extent) organizations. An additional and important part of the Rights model is to articulate the role that the User has undertaken with respect to Content. A comprehensive list of roles can be found in the MARC Relators code list [MARC]. 3.3 Expressing rights statementsThe Rights entity allows expressions to be made about the allowable permissions, constraints, obligations, and any other rights-related information about Users and Content. Hence, the Rights entity is critical because it represents the expressiveness of the language that will be used to inform the rights metadata. Rights expressions can become complex quite quickly. Because of that, they are also modeled to understand the relationships within the rights expressions. This has been evidenced in the Open Digital Rights Language [ODRL] and a paper by Carl A. Gunter et al. [GUNTER]. As shown in Figure 4, Rights expressions should consist of:
|
|
|
|
|
For example, a Rights expression may say that a particular video can by played (i.e., a usage permission) for a maximum of 10 times (i.e., a count constraint) in any semester (i.e., a time constraint) for a $10 fee (i.e., an obligation to pay). Each time the video is played, John, Mary, and Sue (the rights holders) receive a percentage of the fee. Usually, if a right is not explicit in an expression, it means that the right has not been granted. This is a critical assumption made by Rights languages and should be made clear to all Users. For an example of a rights language, see the Open Digital Rights Language [ODRL]. ODRL lists the many potential terms for permissions, constraints, and obligations as well as the rights holder agreements. As such terms may vary across sectors, rights languages should be modeled to allow the terms to be managed via a Data Dictionary and expressed via the language. 4. Example of DRM ImplementationSecond generation DRM software is now providing some of the Architectures described in this article in deployed solutions. A typical example from the E-book sector is the OzAuthors online ebook store [OZAUTHORS]. OzAuthors is a service provided by the Australian Society of Authors in a joint venture with IPR Systems. Their goal is to provide an easy way for Society members (including Authors and Publishers) to provide their content (ebooks) to the market place at low cost and with maximum royalties to content owners. Figure 5 shows the OzAuthors' interface for the specification of Rights information. In this example, the "Usage Rights and Pricing" allows the content provider to specify Read and/or Print permissions, pricing, and security options for the ebook. Additionally, a number of pages can be specified as a free preview. The second part of the interface allows the content provider to specify all the rights holders, their roles, and their percentage of the royalty split. Each time the ebook is sold, the rights holders will automatically receive the indicated amount.
All of this information is encoded in XML using the ODRL rights language. This encoding will enable the exchange of information with other ebook vendors who support the same language semantics, and will set the stage for complete and automatic interoperability. 5. ConclusionDRM standardization is now occurring in a number of open organizations. The OpenEBook Forum [OEBF] and the MPEG group [MPEG] are leading the charge for the ebook and multimedia sectors. The Internet Engineering Task Force [IETF] has also commenced work on lower level DRM issues, and the World Wide Web Consortium [W3C] held a DRM workshop recently. Their work will be important for the entire DRM sector, and it is also important that all communities be heard during these standardization processes in industry and sector-neutral standards organizations. Digital Rights Management is emerging as a formidable new challenge, and it is essential for DRM systems to provide interoperable services. Solutions to DRM challenges will enable untold amounts of new content to be made available in safe, open, and trusted environments. Industry and users are now demanding that standards be developed to allow interoperability so as not to force content owners and managers to encode their works in proprietary formats or systems. The Architectures presented in this article are fundamental to that interoperability and openness. References[DOI] Digital Object Identifier
[EBX] Electronic Book Exchange Working Group
[ERICKSON] "Information Objects and Rights Management", John S. Erickson, D-Lib Magazine, April 2001 Volume 7 Number 4
[GUNTER] Models and Languages for Digital Rights, Carl A. Gunter, Stephen T. Weeks, and Andrew Wright. InterTrust Star Lab Technical Report STAR-TR-01-04, March, 2001
[HOFMEISTER] Applied Software Architectures. C Hofmeister, R Nord, & D Soni. Addison-Wesley, 2000. [IETF] IETF Internet DRM Working Group
[IFLA] Functional Requirements for Bibliographic Records, IFLA Study Group on the Functional Requirements for Bibliographic Records, (Approved September 1997) K . G. Saur München, 1998.
[IMS] IMS Learning Resource Meta-data Information Model (Version 1.1)
[INDECS] Interoperability of data in e-commerce systems
[ISTC] ISO International Standard Textual Work Code
[MARC] MARC Code List for Relators
[MPEG] ISO/IEC Moving Picture Experts Group
[ODRL] Open Digital Rights Language
[OEBF] OpenEBook Forum
[ONIX] EDItEUR ONIX International Standard
[OZAUTHORS] OzAuthors Online Ebook Store
[URI] Uniform Resource Identifiers (URI): Generic Syntax, IETF RFC2396
[VCARD] RFC 2426 vCard Profile
[W3C] Digital Rights Management Workshop
Copyright 2001 Renato Iannella |
| |
|
|
Top | Contents |
|
|
|
|
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/june2001-iannella
|