D-Lib Magazine
July/August 1999
Volume 5 Number 7/8
ISSN 1082-9873
Reference Linking for Journal Articles
Priscilla Caplan
University of Chicago
[email protected]William Y. Arms
Cornell University
[email protected]
Abstract
During the past year, great progress has been made in the field of reference linking, particularly in the important area of links to journal articles. This paper summarizes the current state-of-the-art, describes a general model for static linking, compares several current implementations against the model, and discusses some of the required future work. Particular emphasis is given to the minimal set of metadata needed for reference linking and to selective resolution of identifiers, methods by which a client can specify which of several copies of an item is accessed.
Introduction
Reference linking is the general term for links from one information object to another. The links may appear in a wide variety of contexts, including published citations to scientific works, references from a catalog or bibliography, and informal references transmitted by email or verbally. In recent years, extensive development has been carried out on reference linking between journal articles, and recently work has gone beyond journals. One of the first projects to examine reference linking systematically was the Open Journals Project [Hitchcock 1998].
Recently, several systems have been developed for reference links from online journal articles to other journal articles. The most complete, within its limited domain, is provided by the NASA Astrophysics Data System [ADS]. Another leading example is the National Library of Medicine's PubMed/PubRef [PubMed] system, which is used by HighWire Press and others. An excellent commercial example is ISI's Web of Science [Atkins 1999]. The International DOI Foundation (IDF) is leading another effort, using Digital Object Identifiers (DOI), a form of Uniform Resource Name [Paskin 1999].
In February 1999, the National Information Standards Organization (NISO), the Digital Library Federation (DLF), the National Federation of Abstracting and Information Services (NFAIS), and the Society for Scholarly Publishing (SSP) sponsored a one day invitational workshop to discuss issues surrounding reference linking, specifically linking from citations to electronic journal literature. The report of the February linking workshop is available at [Needleman 1999]. The participants identified three major components for constructing systems to support reference linking: identifiers for the works; a mechanism for discovering the identifier of a work from a citation; and a mechanism for taking the reader from an identifier to a particular item. A small working group was assembled to review, refine, and elaborate on the work of the first workshop. Their report [Caplan 1999a] was the basis of a follow-up workshop in June [Caplan 1999b]. This paper is an elaboration of that report. It places the results of the workshops within a broader discussion of the current state of reference linking.
The generic statement of the reference linking problem is, "Given the information in a standard citation, how does one get to the thing to which the citation refers?" The major focus of the workshops, however, was citations to journal articles. Thus, the problem statement for the meeting of the working group was, "Given the information in a citation to a journal article, how does a user get from the citation to an appropriate copy of the article?" The working group was explicitly asked to consider the situation where there are several copies of an item and the user may have a preference for which item copy is supplied. The group coined the term "selective resolution" for this situation.
The hyperlinks of the web, using URLs, often perform as surrogates for reference links. Hyperlinks can be used to represent citations, to structure information, or for a myriad of related purposes, but they suffer from several disadvantages when used as reference links. A URL identifies a single instance of a work, not the work itself. Since URLs reference a specific location, they are vulnerable to changes or poor management of the system at that location. Hence, research on reference linking is allied to the development of systems of persistent identifiers.
Throughout the study, the emphasis has been pragmatic. What is needed to get started? Are there simplifications that can be made in the short term, knowing that they will need to be addressed later? However, reference linking goes much further than citations to journal articles, and the simplifications that are being used to get started must always be considered in the long-term context. (See the discussion of dynamic linking below.)
Creations
The first stage in reference linking is to understand to what a reference refers. The framework from the IFLA report, "Functional Requirements for Bibliographic Records", provides a vocabulary for distinguishing between related aspects of an intellectual entity [IFLA 1998]. In the IFLA model, a "work" is an abstract conception of some creator. Works are realized through "expressions", which are fixed spatial/temporal representations of works, such as a performance of a play or a symphony. Expressions in turn are embodied in "manifestations", physical representations such as printed books or recorded CDs, which may or may not be mass-produced. A specific, single manifestation is an "item", also called a "copy".
The European INDECS project has done a careful analysis of these distinctions and proposes a categorization that, while somewhat different from the IFLA model, is mainly compatible with it [INDECS]. Supplementing the IFLA and INDECS terminology, the International DOI Foundation (IDF) has contributed "creation" as a useful generic term encompassing the work and all of its expressions, manifestations and items.
The distinction between expression and manifestation is useful for works that are performed but usually can be ignored for works that have a single expression, like most journal articles. Journal articles represent three types of creations: the work, or creative output of the author(s); the manifestations, or instantiations of the work in print and/or electronic form; and the items, or specific copies of a manifestation. An article, for example, could have been published in a print and an electronic version. These would be separate manifestations, each of which might have multiple items (perhaps several hundred copies for the print run, and mirrored online and archival copies of the electronic version).
Citations and creations
The author of a citation sometimes refers to a work, sometimes to a specific expression or manifestation, and sometimes to an individual copy. Often a citation will refer to a specific manifestation only because the citer, working from his own copy of the article, is unaware of other manifestations that would do as well.
In some cases, however, an author will cite a particular manifestation deliberately. The British Medical Journal provides an example of a publication where manifestation is significant. Articles are published in three manifestations: print, PDF, and HTML. For some articles, the print and PDF are abridged versions of the full HTML article, which may be longer, and may contain additional figures and references. However the official citation given by the publisher refers to the print/PDF manifestations, including the pagination, which is not relevant to the HTML.
Consideration of the British Medical Journal leads to the question of under what circumstances the different versions should be considered different works, as the intellectual content varies. The distinctions between work, expression, and manifestation are a matter for judgment. The IFLA model is analytic while publishers are declarative, in essence defining different manifestations as distinct or equivalent by declaring that they consider them so. This example illustrates that the IFLA model must be seen as a general framework rather than a precise definition or specification.
In the absence of a clear indication of the author's intentions, it can usually be assumed that a citation refers to the work, as both the citer and the reader can be expected to be primarily interested in the intellectual content. (This is true even though when a citation uses a URL, the author is usually constrained to refer to the location of a specific copy.) Most current implementation projects focus on citations to works, and hence on the association of identifiers with works, while recognizing that occasionally there will be a need to distinguish different manifestations. This is the approach taken by the Astrophysics Data Center, ISI, and PubMed. One of the central aims of INDECS is to be explicit in distinguishing between the underlying work, its various expressions, and its manifestations. The IDF is a member of INDECS and is bravely attempting to be explicit about the distinctions, but has accepted that its initial services can refer generally to "articles". Currently, this cautious pragmatism seems an acceptable simplification.
A general model for reference linking of journal articles
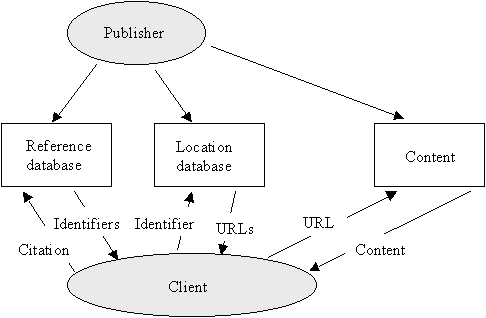
Although they differ greatly in details, most current systems fit within the framework shown in Figure 1. (A notable exception is SFX, which is mentioned briefly below.)
Figure 1. Reference linking
Each work has a unique identifier and one or more copies, each with its own URL. The provider of the information, who is usually the publisher, supplies metadata about each work. This is stored in databases as shown in the middle row of Figure 1. Clients access the databases through the interactions shown in the bottom part of the figure. The figure shows two databases: a reference database and a location database.
Reference database
For each work, the reference database contains metadata that, at a minimum, corresponds to the information in a conventional citation. A client that wishes to find the content associated with a reference sends a query to the reference database. This database returns a list of identifiers for works that match the query.
Location database
Typically each cited work will be stored at several locations. A client sends an identifier to the location database, which returns one or more URLs. The client selects the URL to retrieve the object. This is known as "resolution" of the identifier.
This process has many complications. There will be considerable variation in citations; some will be formally published as references within scholarly journal articles; some will be formulated as part of more casual communications such as course reading lists and informal bibliographies. In some cases a citation may contain the identifier of the article explicitly, in which case the reference database lookup is not needed; in other cases an identifier will have to be obtained by using the bibliographic data elements given in the citation. There may be several works in the reference database that match the query; the client must select a work either by human intervention or by algorithm. When there are several URLs to different copies of the work, the system is faced with selective resolution: the client may wish to select a specific version based on variations of content, different licensing arrangements, or network performance.
Current implementations present several variations on this model. The Astrophysics Data Service derives references algorithmically, bypassing the reference database lookup. PubMed and the Web of Science combine the citation and location databases. Currently, all location databases return a single URL, though this is changing. PubMed's LinkOut experiment permits users to provide URLs in addition to those provided by publishers. The Handle System, which resolves DOIs, has an unused service that is capable of returning several URLs or other resolutions of a DOI.
Identifiers
An important question is whether effective reference linking needs identifiers other than URLs. The need for persistent identifiers has been widely advocated in a broader context than the reference linking problem. (See, for example, [Sollins 1994].) Yet, it can be argued that the deployment of general purpose Uniform Resource Names (URNs) has been slow and that wonderful systems have been built on the web using nothing more than URLs.
While it might be possible to build a reference linking model that does not presume the existence of identifiers, this seems unwise. Use of identifiers improves the reference linking model in a number of ways. Identifiers associated with works provide the primary means of clustering multiple copies of those works. The existence of the identifier allows citation lookup and resolution steps to be performed by different software systems, and facilitates distributed resolution. It provides management benefits for those running reference lookup and resolution services. Above all, the identifier gives permanence to a reference beyond the life span of any particular computer system. Given the overwhelming practical benefits of the identifier, it seems best to treat identifiers as a necessary part of the general model, while acknowledging there may be special cases in which they can be omitted.
Perhaps the most compelling argument that identifiers are needed for reference linking is that all current systems find them necessary. For ISI the identifier is a private key. The Astrophysics Data System has its own BibCode, and PubMed uses a PubMed ID. Digital Object Identifiers (DOIs) are an implementation of a Uniform Resource Name; they are public identifiers intended to be used wherever the item needs to be identified. DOIs are managed and resolved through the CNRI Handle System [Handle]. BibCodes and PubMed IDs were not explicitly intended to be Uniform Resources Names, but can be considered as such. They satisfy the commonly accepted criteria of persistence and global uniqueness, while supported by openly-accessible resolution systems.
Identifiers for reference linking must meet three functional requirements. The first two are generic; the third is specific to reference linking.
Persistence
An identifier must be persistent, or at least, have enough organizational and technical structure around it to ensure some degree of reliability. This excludes informal and unmanaged identifier systems, but does not preclude well-managed local and proprietary identification schemes (such as the PubMed ID).
Uniqueness
An identifier must be unique within its own namespace. The model assumes multiple systems of identifiers, and there is no way to guarantee an identifier will be universally unique, that is, that a particular identifier string will not resolve to different items within different resolution systems. However, identifiers must be unique within a single system of resolution. It is also reasonable to expect that uniqueness will be preserved within the larger universe if the namespace assignations are well-managed.
Multiple resolution
A system of identifiers must be capable of supporting resolution to multiple items. In the model, it is assumed that multiple copies of a creation may exist, and that it must be possible to get from an identifier to all copies or to the subset of copies most appropriate for the user. (A URL, which by definition resolves to a single location, cannot satisfy this requirement, though it is possible for a URL to point to a web page containing a list of URLs for various copies of the article. This does not, however, easily support automatic resolution to the most appropriate copy.)
DOIs, PubMed IDs, and astrophysics BibCodes all satisfy these requirements.
It has been suggested that actual identifiers are unnecessary, as citation information can be used to calculate a key to the article on the fly. However, this key must be either a URL or a string that resolves to one or more URLs. If the calculated key is a URL, it does not support the reference linking model because of the requirement to support resolution to multiple copies of an item. If the key is a string that can be resolved to one or more URLs, then that key is in fact an identifier which, if persistent and unique within its namespace, fits within this model.
Obtaining an identifier from a citation
In a recent paper, Van de Sompel and Hochstenbach [Van de Sompel 1999a] provide a categorization of the techniques used to obtain an identifier from a citation. In particular, they list the three following options.
Calculation of identifiers
In well-determined bodies of information, it may be possible to use an algorithm to calculate the identifier from the citation.
Static reference databases
Figure 1 shows the construction and use of a static reference database of references. With static linking, all reference links within a work are pre-computed, ready for clients to invoke. This is effective within a well-defined body of literature, such as scientific journals, where the publishers enter metadata about each digital object into a database on publication and use that database for establishing subsequent references.
Dynamic linking
In general, not all references can be or need to be precomputed. The term "dynamic linking" covers a variety of techniques for computing references only when required by a user. The approach of the Open Journal project is to compute links when a user downloads a page. The SFX system has just-in-time resolution [Van de Sompel 1999b]. When a client attempts to link to a reference, SFX attempts to resolve it. A major advantage of dynamic linking is flexibility: it allows links to materials only recently brought online and it permits forward references. Another advantage is that, unlike static linking, dynamic linking can be utilized in situations where not all of the resources in question are under the control of the linking service, a concept exploited in the SFX system. The major disadvantage is that dynamic linking is probabilistic: there is no guarantee a link will actually resolve to a valid item.
Following this analysis, for static reference linking, identifiers to journal articles may be obtained in three ways:
a citation can contain an identifier;
the bibliographic information within a citation can be used to calculate an identifier;
the bibliographic information within a citation can be used to look up the identifier in a reference database.
If an identifier is embedded in a citation, the step of querying a reference database for the identifier is obviously unnecessary. Hopefully, the practice of including an identifier explicitly with a citation will increase, but it can never be depended upon.
Calculation of identifiers
In well-determined bodies of information, it is possible to use an algorithm to calculate the identifier from the citation. As a successful example, the astrophysics BibCode can be calculated from standard bibliographic information, such as the name of the publication, volume, and pagination. It takes advantage of the standardization possible within a tight community with a small number of prominent journals. The success of the BibCode shows that, in small domains, it is possible to extract metadata fields automatically, which can be assembled into a key, with high accuracy.
The Serial Item and Contribution Identifier (SICI) standard provides a set of rules for calculating identifiers for journal articles [SICI 1996]. It combines the ISSN with data about the volume and issue, data identifying the location of the article, and a constructed title code for the article. When all basic bibliographic data are available for constructing the SICI, the identifier is consistent and highly likely to be unique. However, in the real world, citations are not always complete or fully uniform. The SICI standard allows the identifier to be constructed from the best available information, meaning that SICIs for the same article created from different citation sources could vary.
This illustrates the general flaw of calculable identifiers. So long as the data from which the identifiers are calculated can be closely controlled, calculable identifiers can work reliably. However, the more variation there is in sources of citations, the higher the likelihood this data will vary. Thus, as the number of journals, publishers, abstracting and indexing databases, and end-user citation formats increases within any system of reference linking, the reliability of calculable citations correspondingly decreases. As a result, the working group was skeptical about the possibilities of building large-scale systems of reference linking that depend on automatic computation of identifiers from citations.
In larger but well-structured domains, such as scientific journal articles, it is possible to extract metadata fields automatically, which can be assembled into a key, with good but not perfect accuracy. While the tools may not be precise enough to generate calculable identifiers, they are invaluable for preliminary analysis augmented by human editors. The philosophy behind the Scholarly Link Specification Framework (SLinkS) [Hellman 1999] and the method developed by ISI define a set of templates that correspond to the citation formats used by various publishers. A related project is the work of Lawrence and colleagues at NEC [CiteSeer]. Their ScienceIndex project (formerly known as CiteSeer) has developed a number of tools for extracting citation data automatically from documents, particularly those in PostScript. The Open Journal project has also built tools for extracting citations. All these tools are available to other researchers.
Reliable templates depend upon the consistency with which publishers format citations. ISI, which has probably the most expertise in this area, finds that templates are extremely useful, but a substantial number of citations need manual processing to extract the correct metadata. Experience with multidisciplinary collections indicates that, outside the hard sciences, the ability to match citations accurately on the first try drops substantially and additional processing is required.
Reference lookup
If the identifier is neither embedded nor calculable, lookup in a reference database is required. The reference database contains metadata linked to identifiers for works (and possibly also for manifestations of works). The database system receives a query derived from a citation and returns the identifier associated with that citation.
The act of reference lookup does not necessarily have to be implemented as a separate step, with a separate database, from the resolution of the identifier, as shown in the model. However, lookup and resolution are conceptually distinct steps, and they are likely to be implemented as separate systems. Different agencies may want to provide the different services. Also, citation lookup may require more processing power than resolution, arguing for technical separation. Further, it cannot be expected that every lookup of citation information will yield unique, unambiguous results. Lookups resulting in more than one hit may require some negotiation with the party initiating the lookup, or may return multiple identifiers, leaving it up to the user to select which to resolve. Functionally, this complexity is best dealt with by separating resolution from lookup.
Several reference lookup services are likely to exist, and it can be expected that the databases will not necessarily have unique content, so the same citation could be successfully queried in more than one reference database. For example, both PubMed and the IDF system could have information about a single journal article. Different lookup services could provide different types of identifiers (e.g., PubMed IDs, DOIs); more than one service may also provide the same type of identifier. In the simplest case, the user would choose the lookup system and enter the query through a standard interface. Possibly, there could be a registry of lookup services, which a searcher could use to find the most appropriate. If there were only a small number of lookup sites, front end software could be written to search them all simultaneously. However, for these front ends to return intelligible results to the user, it may be necessary to standardize the response formats from the various lookup sites.
Metadata for reference lookup
A key issue for the lookup service is what metadata is needed to support reference lookup. It is useful to define a minimum set of data elements sufficient to support most queries, to be implemented by all providers of lookup services. This minimum element set becomes the definition of a minimal citation guaranteed to support successful lookup, assuming an appropriate reference database is selected for the query. Several publishers were insistent that the list of elements be kept short. They do not want the reference database to become an inferior indexing service that competes with their higher quality products.
During the recent series of meetings, publishers and librarians reached considerable agreement about the necessary metadata fields for journal articles. Appendix 1 is an informal comparison of the metadata elements included in several different working systems or proposals, including PubRef, the in-house systems used by Wiley and D-Lib Magazine, and proposals drafted by NFAIS and by Norman Paskin for the IDF. (Note that this was informally compiled and is not intended to be a definitive summary of any of the included schemes.) Based on this comparison, the following recommended minimum data element set was drafted for further discussion.
1. Title: Title of the journal article.
2. Creator(s): Author(s) of the journal article. The first author at a minimum should be included; subsequent authors may be included at the discretion of the metadata provider.
3. Journal Title: Title or title equivalent of the journal in which the article is published. An unambiguous key number, such as ISSN or CODEN, could function as a title equivalent.
4. Date: Publication date of the article or the official chronology of the journal issue containing the article. Chronology is the published designation or "issue date" (e.g., May/June 1999).
5. Enumeration: The numbering designation of the journal issue containing the article. Enumeration generally includes volume and issue number, and may include other designations such as Part, Series, etc. This can be omitted only if the journal itself has no official enumeration, as is the case with a currently small number of electronic-only journals.
6. Location: Starting page number of the article, or, if there is no pagination, assigned article number.
7. Type: Type of material, in this case probably "journal article". It is assumed that the provider of the reference database will wish to provide a code for the type of entity being described, in order to distinguish between related materials. For example, in the Wiley database, "Type" can have the value "Article", "Abstract", "Issue" or "Journal", since each of these entities has its own record in the database. It is not assumed that this element will be explicitly included in citations. However, the query interface to the reference database might be able to provide this value by inference, default, or even, in some cases, asking the user. (Another useful value for this element might be "Database Record" -- e.g., to indicate that the entity found is an ISI record or a PubMed record, or a library holding record, as opposed to the actual article itself.)
This metadata set is compatible with the metadata currently collected by PubRef, and with the metadata set proposed for reference linking by Norman Paskin for the IDF. The work group attempted to relate these elements to the Dublin Core, but found difficulty in representing the relationship between a journal article and the journal in which it is published. This problem may be solved in the near future, as the Dublin Core Working Group on Bibliographic Citations is in the process of drafting guidelines for a standard way of representing citation information in both simple and qualified Dublin Core. It is hoped that these guidelines will accommodate all data elements in the recommended minimum set.
It is recognized that several of these elements must actually refer to a selected manifestation of a work. It is also recognized that the descriptions are imprecise in their specification of the data which would be supplied to populate these elements in an actual database; within each element there may be differing definitions as well as multiple definitions (e.g., "Date" may include publication date and/or issue date). But these issues can be handled successfully in a real-world implementation as long as precise element definitions are specified on the input side, while looser formulations are permitted to be successful on the query side. For example, in the case of the "Date" element, a database might be structured hierarchically such that the "Date" branch included both "Publication Date" and "Issue Date" elements. While database population would have to follow very precise rules regarding which information would be permitted in each field, on the query side the rules could afford to be much looser: e.g., if a query were "smart" enough to seek "Issue Date" specifically, it could do so, but if it only knew enough to seek a "Date," then the query processor could easily consider the values of all "Date" related fields, or else the one deemed most likely to be useful as a default answer.
Resolution of the identifier
To resolve an identifier, it is sent to a location database that returns a list of locations where copies of the creation are stored. Extra information may be associated with each location to help the client select a specific location. For efficiency, it is desirable to have multiple resolvers for each type of identifier so that the processing load can be shared and resolution could be routed to the geographically closest server. The design of the Handle System supports high-performance distributed resolution of DOIs. The other types of identifiers use database lookup with mirroring.
Since there are several types of identifier, a client must know what location databases support resolution of which types of identifiers. Under the simplest model, the identifier itself determines the resolver; a DOI is submitted to the DOI resolver, a PubMed ID is submitted to the PubMed/PubRef resolver, etc. Although not implemented, various automatic mechanisms have been proposed for registration of identifiers and for finding servers supporting resolution of the various namespaces. For the near future, the number of services is likely to be small enough that they can be listed by enumeration.
Selective resolution
While some implementation of identifier-based resolution of namespaces as described above is necessary, it is not in itself sufficient as it does not accommodate the second issue, the need for selective resolution. This requirement, which has come to be known as "the Harvard problem", was described in the report of the first workshop as follows:
In many cases there will be multiple copies of the same article available. For example, an Elsevier journal may be available in Science Direct, in Michigan's PEAK database, through OhioLink, etc. Many legitimate reasons for multiple copies exist, including performance (caching), different service models, archival needs, and competition. The system must be able to find the right copy for the user, which, in the end, may have more to do with who the user is than what the journal is.
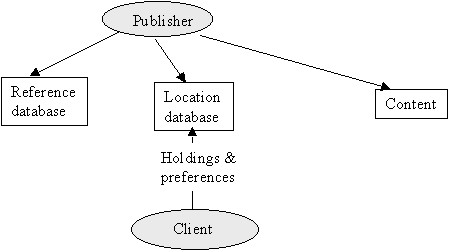
Two architectures for selective resolution have been proposed. The first is shown in Figure 2. The concept is that the location database is augmented by information supplied by the client.
Figure 2. Selective resolution: use of location database
PubRef has an experimental service of this type under development called "LinkOut". This allows institutions to store a profile in the location system that controls the selection of links returned to users of that profile. Thus a library can list its preferred source for certain groups of journals. Then, if the resolver knows the user's affiliation, it can present the user with the location of the most appropriate copy of the article.
This is a simple mechanism, but there are problems of scale because of the complexity of profiles and the need to keep them continuously updated. An academic library, for example, might change suppliers with some frequency. In one year it might receive roughly a thousand titles from one aggregator and another thousand from a second aggregator; the following year the first aggregator may be replaced with yet another service offering a slightly different set of journals. For some services, the institution may retain rights to access articles published during the course of the subscription, while for other services those rights may terminate. The period of the subscription to the aggregator service does not necessarily correspond to the publication pattern of any given journal. Meanwhile, the exact set of journal titles represented in each service is likely to have changed during the course of the subscription. Keeping such a profile comprehensive and up-to-date would be very difficult for the sponsoring institution; maintaining profiles for all sponsoring institutions would be difficult for the resolver service. Also, a service using the profile would have to base copy selection on information such as the title of the journal and the date of publication of the article -- bibliographic information that is not necessarily carried in the resolver system in this model. In sum, it is difficult to imagine large central resolver databases containing and maintaining enough information to support the selective resolution function.
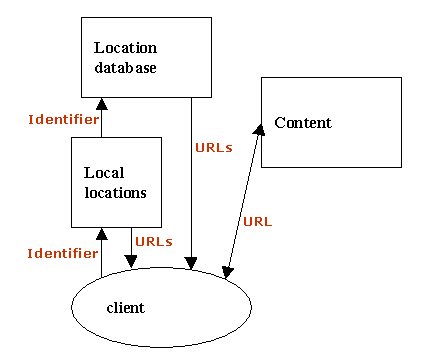
Figure 3 shows an alternative architecture for selective resolution. In this design, clients maintain their own local databases of locations in addition to the centrally maintained location database.
Figure 3. Selective resolution: use of local location database
This model posits that institutions such as universities, professional associations, and public libraries, which subscribe to information resources on behalf of specific communities, maintain local resolution services. The local resolver receives all resolution requests from a member of a particular community. It attempts to resolve the request based on its own database, which contains identifiers for all materials the local institution has made available from sources other than directly through the publisher. If the identifier is found in the local database, the pointer to the preferred source is returned to the user. If the identifier is not found locally, the resolution request would be forwarded to the global resolution service for the defined namespace.
Implementation of this model is awkward with current web browsers. It requires not only a mechanism for global resolution of identifiers as discussed above, but also a mechanism for inserting local resolvers into the resolution process. Ideally, future generations of web browsers would support user configuration of a hierarchy of identifier resolution services. At present, the only system that we know that supports local resolution (and local reference lookup) is SFX; this passes the necessary information as parameter strings in URLs and HTTP cookies. Another possibility is for a library to combine local resolution with an authentication proxy or front-end gateway.
Both Figure 2 and Figure 3 require the maintenance of a resolution profile. Potentially, the size of the profile and the rate of change in it could be very large, as it reflects each individual article available from a repository, but in practice the complexity can be reduced. Many libraries typically get their electronic journal literature from aggregator services, such as those offered by OCLC's ECO or UMI's ProQuest products. Perhaps these vendors could, as part of their service, provide profiling information for the identifiers of the articles included in the service. Larger libraries that subscribe to myriad sources would presumably have the resources to create their own profiles by merging and managing data from the various sources. Alternatively, this could be a service provided by third party suppliers.
Next steps
The details of the general model in Figure 1 and extensions for selective resolution deserve further exploration and development. They would be greatly helped by the development of browsers with the ability to support name resolution and browsers that allow users to configure a hierarchy of resolvers. Resolution requires methods to route identifiers to the default resolution server for the namespace and further specification and testing of the local resolution concept. These technical issues are not severe, however, as the existence of several practical implementations shows.
Perhaps most importantly, these models depend on metadata for the reference databases and the willingness of publishers and third party abstracting, indexing, and aggregator services to provide profiling data for their customers. For the central databases, the publishers of scientific journals are moving ahead rapidly, supplying metadata and locations to PubMed/PubRef and preparing to work with the IDF project.
Even for the narrow field of scientific journals, there are still many questions and operational issues which must be identified, addressed and documented. For example: How does a researcher find the appropriate reference database for citation lookup? What happens when a researcher resolves a citation to a copy that he/she is not entitled to view? What happens when an identifier resolves to multiple, equally appropriate copies? What interest do authors have in identifiers for their own creations, and can an author ensure that his/her paper receives a particular identifier? What if an author wants a certain identifier assigned to his/her paper, but the publisher does not support the use of that identifier? Where should transaction formats be standardized across applications -- reference lookup queries, resolution queries, query responses?
Given that there will be multiple systems for reference linking, attention should be given to the development of appropriate guidelines geared towards each of the interested parties (researchers, authors, publishers, abstracting and indexing services, vendors of repository and aggregator services, libraries). Guidelines from each vantage point would serve as a common resource, facilitate interoperability, and promote standard practices.
Finally, it is necessary to consider reference linking beyond linking to scientific journals. For less well-managed information, the model of static linking may be insufficient. For broader ranges of materials a combination of dynamic and static reference linking may be necessary.
Appendix 1: Informal comparison of data elements used or recommended for use in citation matching.
Dublin Core
Wiley
D-Lib
NFAIS
DOI proposal
Pub Ref
Title
Title (of article)
Title (of article)
Title (of article)
Creator
Author Name
Creator
First author
Agent Identifier
Author name
Additional authors
First author
Subject
Subject
Description
Publisher
Publisher
Publisher
Rights-holder
Publisher (under Agent identifier)
Other Contributor
Issue Editor
Date
Accepted Date
Received Date
Revised Date
Published Date
Date
Pub Date
Year of Pub
Pub date
Year
Type
Type (abstract, article, issue, or journal)
Type
Type (full text, abstract, bibliographic record, article sub-part)
Type (work)
DOI genre
Format
Format (MIME-type, SGML, PDF, HTML, GIF, TIFF)
Identifier
Article Identifier
SICI
DOI
Journal identifier
ISSN
Article Identifier
DOI
URL
Journal identifier
Serial name
ISSN
Article Identifier
DOI
Publication Identifier
Journal Title
ISSN
CODEN
Article identifier
PII
SICI
DOI
Journal identifier
ISSN
CODEN
Journal Identifier
Journal title
medline jta, ISO jta, CODEN, ISSN
Source
Language
Language
Language
Relation
Relation
Coverage
Rights
Copyright info
Rights
Volume Number
Volume
Volume
Journal volume #
Volume
Issue Number
Issue
Issue
Journal issue #
Issue
Page Number
Starting page number
Start page #
Page
Article number
Start page sequence #
Appendix 2: Membership of the Reference Linking Working Group
- William Arms, Chair, Cornell University (at that time CNRI)
- Dale Flecker, Harvard University
- Priscilla Caplan, University of Chicago
- David Sidman, John Wiley & Sons
- Norman Paskin, International DOI Foundation (IDF)
- Mary Grace Palumbo, Dawson Information Quest
- Helen Atkins, ISI
- Evan Owens, University of Chicago Press
- Clifford Lynch, Coalition for Networked Information
References Cited
[ADS] NASA Astrophysics Data System. < http://adswww.harvard.edu/ >
[Atkins 1999] Helen Atkins, "The Web of Science". To be published in D-Lib Magazine, September 1999.
[Caplan 1999a] Priscilla Caplan, "A model for reference linking." Report of the working group of the reference linking workshop. May 1999. < http://www.lib.uchicago.edu/Annex/pcaplan/reflink.html >
[Caplan 1999b] Priscilla Caplan, "Report of the Second Workshop on Linkage from Citations to Journal Literature." June 9, 1999. < http://www.niso.org/linkrept.html >
[CiteSeer] CiteSeer, Autonomous Citation Indexing. < http://www.neci.nj.nec.com/homepages/lawrence/citeseer.html >
[Handle] The Handle System. < http://www.handle.net/ >
[Hellman 1999] Eric S. Hellman, "Scholarly Link Specification Framework (S-Link-S)." 1999. < http://www.openly.com/SLinkS/SLinkS.html >
[Hitchcock 1998] Steve Hitchcock, Les Carr, Wendy Hall, Steve Harris, Steve Probets, David Evans, and David Brailsford "Linking electronic journals: Lessons from the Open Journal project." D-Lib Magazine, December 1998. < http://www.dlib.org/dlib/december98/12hitchcock.html >
[IFLA 1997] IFLA Study Group on the Functional Requirements for Bibliographic Records, Functional requirements for bibliographic records. Deutsche Bibliotek, Frankfurt-am-Main, 1997. < http://www.ifla.org/VII/s13/frbr/frbr.pdf >
[INDECS] Interoperability of Data in E-Commerce Systems. < http://www.indecs.org/index.htm >
[Linking 1999] Reference Linking Working Group, 1999. < http://www.niso.org/reflink.html >
[Needleman 1999] Mark Needleman. "Meeting Report of the NISO Linking Workshop." February 11, 1999, Washington D.C. < http://www.niso.org/linkrpt.html >
[Paskin 1999] Norman Paskin, "DOI: Current Status and Outlook May 1999." D-Lib Magazine, May 1999. < http://www.dlib.org/dlib/may99/05paskin.html >
[PubMed] The NLM PubMed Project. < http://www.ncbi.nlm.nih.gov/PubMed/overview.html >
[SICI 1996] National Institute of Information Standards, "SICI: Serial Item and Contribution Identifier Standard", ANSI/NISO Z39.56-1996 Version 2. < http://sunsite.berkeley.edu/SICI/ >
[Sollins 1994] Karen Sollins and Larry Masinter, "Functional Requirements for Uniform Resource Names." Request for Comments, 1737. Internet Engineering Task Force, December 1994. < http://www.ietf.org/rfc/rfc1737.txt >.
[Van de Sompel 1999a] Herbert Van de Sompel and Patrick Hochstenbach, "Reference Linking in a Hybrid Library Environment, Part 1: Frameworks for Linking." D-Lib Magazine, April 1999. < http://www.dlib.org/dlib/april99/van_de_sompel/04van_de_sompel-pt1.html >
[Van de Sompel 1999b] Herbert Van de Sompel and Patrick Hochstenbach, "Reference Linking in a Hybrid Library Environment, Part 2: SFX, a Generic Linking Solution." D-Lib Magazine, April 1999. < http://www.dlib.org/dlib/april99/van_de_sompel/04van_de_sompel-pt2.html >
Copyright © 1999 Priscilla Caplan and William Y. Arms
Top | Contents
Search | Author Index | Title Index | Monthly Issues
Previous story | Next story
Home | E-mail the EditorD-Lib Magazine Access Terms and Conditions
DOI: 10.1045/july99-caplan