|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Theo van Veen Georg Petz Christian Sadilek Michel Koppelaar |
![]()
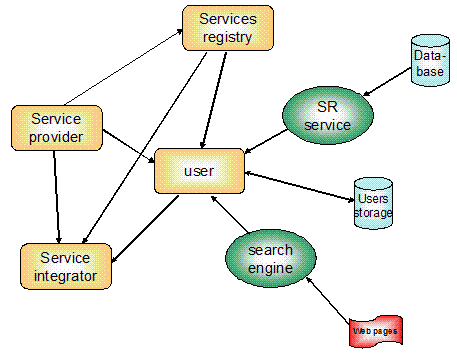
AbstractThere is existing functionality on the web that users may want to have integrated in portals like the European Library portal [TEL]. This requires the user to notify the portal on how that functionality or services are to be used. For this purpose we have developed a data model for describing functionality on the web. These service descriptions can be exchanged between users and service integrators like the European Library. In this article, we discuss these service descriptions and demonstrate them by means of a demonstrator portal. IntroductionA great deal of wonderful functionality is available on the web, but it's often hidden in websites. When users become aware of such functionality, they might want to have it applied to their own data or to data obtained from other web sites. Examples of such functionality are online translation of search results, annotation services, feature extraction, query expansion based on external thesauri, and much more. It would be a pity if that functionality were only applicable to data located on the same system as the website where the functionality is located. How can we make that functionality available to the user when he or she is using, for example, the European Library (TEL) portal? How can the user tell a data provider or service integrator what should be done with data retrieved in a previous request? The solution we aim for is that users can exchange descriptions of services that provide the functionality they want to integrate with web portals. The term "service description" as it is being used here might not correspond to a common interpretation of the term, because these descriptions do not describe the complete service but mainly the behavior of that service and how the user wants it to be used. A single service can therefore be described in different ways. The impact increases if the data model for these descriptions is supported not only by the European Library portal, but by other web portals as well. In this article we propose a data model for this purpose. We described the basic idea for this concept in an earlier article that appeared in Ariadne 47 [Ariadne], and we further developed the idea in the TELplus [TELPLUS] project. This work has resulted in a schema for service descriptions and an improved test and demonstrator portal that allows for testing and refining the service descriptions. In addition, a simple web application has been added to analyze simple web pages for automatically creating a service description for the functionality embedded in that web page. The long-term vision is that we might "follow" users in their actions – with their permission of course – recording the functionality used so that it can be re-offered automatically to users in future interactions, depending on a number of conditions. In this way the portal (or user agents invoked by the portal) can find their way in the landscape of data and services anticipating potential user actions and providing feedback on the results obtained in the background only when relevant. It is even conceivable that this type of functionality could be offered in the future by browsers rather then by portals (like the integration of search engines). The need to describe services in a standard way remains however. Many services can be integrated in a portal simply by hard coding their APIs in the portal. This, of course, will often be the best solution for optimal integration. However, in this article we concentrate especially on situations in which a service was not already integrated in that way but the user wants it to be. To reach the ultimate goal of having functionality integrated whenever and wherever it is needed is a long process; in the meantime we are building step by step upon what is available now rather than trying to reach that goal all at once. The integration of web services in the TEL portal differs from the idea of Web 2.0 Mashups. Although both approaches focus on the integration of web services, a Mashup combines content from various sources into a new integrated web service hybrid, whereas integration of web services in the TEL portal allows one to use content in conjunction with other external services. These external services exist independently of the TEL portal and are not bound to the TEL content. For creating a Mashup a variety of sophisticated tools are available such as Google Mashup Editor, Yahoo Pipes, Mozilla Ubiquity, Microsoft Popfly and others [Mashup]. These tools enable users to integrate services without needing software development skills, which is similar to the approach described in this article. What is a service and how is it used?In the context of the philosophy described in this article, functionality is offered via a service, and a service is, for the time being, considered to be anything that is available via HTTP. This may be HTTP GET or HTTP POST, with or without a higher-level protocol on top of it. The output may be any of a number of things, such as HTML, an image, XML, JSON, etc. In this context web services do not require using Simple Object Access Protocol (SOAP) [SOAP]. For example, the plain HTML Google search is considered to be a service as well. When something is not available via HTTP, the web-user considers it to be non-existent. Many people directly associate web services with SOAP. SOAP has a higher barrier to use than REpresentational State Transfer (REST) web services, and SOAP sometimes adds complexity without adding functionality. Commercial companies might benefit from this complexity in terms of the work it provides them, but at the same time these companies suffer from serious interoperability issues related to SOAP's complexity and the different implementations of message formats. In the context of what we propose in this article, the use of SOAP is certainly not a requirement. Services can be used in different ways. The simplest way is just to link to the service with the appropriate parameters and display the result. Another type of usage is to read the output of the service and extract the relevant data, and then to do something with the extracted data. In this way data can be integrated in the web application that invoked the services, e.g., replacing a piece of text by the output of the service. When the service provides HTML, the output can be understood by the user without the need to describe the output in the service description. However, when the output is XML, the portal has to have a notion of the output fields of the service to be able to deal with the fields correctly. But even when the portal does not know the schema, in some cases the user might choose to have the XML output presented in a user-friendly way. Because most services are not in compliance with a specific protocol (other than at the HTTP level), not only must the behavior of such services and how to invoke them be described by means of a service description, but the portal also has to have a notion of the meaning of certain data types to deal with them correctly. Taking the world as it isIt would be nice if everything followed a standard protocol. Although there are many standard protocols for different purposes (e.g., SRU [SRU], OAI [OAI], etc.), there is also a lot of functionality available on the web that is not compliant with a specific standard. In the proposed approach described in this article, the world is taken as it is and not as we want it to be. This might result in algorithms that are not very appealing from the perspective of a system designer but that can be very useful for users. Our approach, however, may evolve into a new way of creating and sharing web applications, resulting in new standards and new business models. Thus we start by dealing with the current situation as it is while also anticipating new paradigms that may possibly arise in the future. An important aspect of our approach is to lower the barrier to use or give access to existing web functionality, and to make it easy for non-skilled users as well as programmers to find, create, use, change, exchange and modify service descriptions. It should also be easy to add additional fields in the service description that are not part of the standard data model, in order to implement unforeseen functionality later on. Applications should ignore additional fields in the service description that are not part of the currently proposed model. Applications using the descriptions can validate them against an XML schema and reject them because of unknown fields or just ignore them. Technically this is realized by means of extensibility elements similar to those in a WSDL document. The schema for the service descriptions is meant only for publication purposes. Also, it should not require any software other than a web browser to retrieve or edit service descriptions. When we added new functionality to the demonstration portal during the development of the data model, we realized that it is not realistic to create a data model that covers every possible situation. The data model as it is now is certainly not the ultimate model that will last for years. However, it may be the start of a process in which services are created in such a way that the described behavior or usage will follow a few simple rules. For example, the data model provides a field that describes how to obtain the number of hits of a search before offering a link to the service. For a non-protocol based service, that description will currently correspond to "screen scraping" the number of hits. In this situation web pages might be used in a way that the service providers did not intend. But by describing it, we hope service providers will start providing the number of hits in a standard way via a simple HTTP request that returns only the number of hits. In general, by describing how to deal with a service, we more or less define aspects that could lead to some standardization, while leaving service providers enough freedom to offer rich functionality not ruled by a standard. The big players on the web, like Google, Amazon, Flickr, etc., are increasingly providing their services via well-described APIs and in both XML and JSON formats. Even though this makes it easy for developers to integrate these services in web applications, the services have to be hard-coded, because they do not follow a standard protocol and require a priori knowledge about the semantics to be used. Using a standard description model also helps to create standard protocols: when the service description specifies the name of a parameter with a specific meaning, this might stimulate standardization of the name of such parameter in future web applications.The service description modelThe service description provides data to allow users to search for, find and select a service, and to allow applications (like portals) to select and invoke a service and use the output in an appropriate way. The service description model is not intended to describe the service as it is but to have a single extendible model for describing a service from different points of view: the point of view of the service provider, the service integrator, the user and perhaps others as well. As a result there may be different service descriptions for the same service, but they follow the same model and can be exchanged between different parties. An example: a service provider publishes a service description, and the user may modify this description and provide his description to a service integrator. The service integrator (e.g., the provider of a portal) reads this service description and offers this service to the user in the way the user has specified. The service integrator does not have to implement all aspects of the service description. There are various existing models for service descriptions, such as WSDL 2.0 [WSDL], WADL [WADL], the IESR [IESR] model and many more [DL]. There are also services registries like the UDDI [UDDI] services registry and the IESR registry. These models, however, do not contain the elements that are needed for our purpose. WSDL 2.0 and WADL describe more or less syntactically how to invoke a service, but not when a service should be invoked and what to do with the output. In our case the syntax for accessing the service is not very relevant, because most parameters may be fixed. The IESR model might come pretty close to satisfying our needs, but it separates the actual service from the data behind the service, while in our case we describe "what is behind a URL". Rather than extending one of these models, we found it more convenient to simply introduce a new model suited specifically for our purpose. This avoids confusion and dependencies. However, the TELplus service descriptions may contain links to other service descriptions, e.g., a WSDL file. This allows advanced portals to provide more functionality based on some additional description. In some cases, services may provide their own description, like the "explain response" in SRU. Or a portal might use the explain response in addition to the TELplus service description. We also did not want to be restricted by existing services registries: In our view, one should be able to find and obtain a service description via existing search engines (like Google) or any search and retrieve protocol (like SRU), whether or not they are contained in an "official" registry, a database, or in a simple web page or on an arbitrary server. Figure 1 illustrates possible flows for service descriptions. The endpoint is always the service integrator or portal provider that actually links the user to a service.
Service descriptions as proposed here should be completely self-contained without the need to expand fields with data from other sources. Our model uses Dublin Core [DCMI] as a starting point. It is anticipated that there will be more and more applications capable of retrieving records with different underlying data models but having the Dublin Core elements in common. These applications will at least be able to present the DC fields to the user while ignoring the non-DC fields. This enables integrated searching in heterogeneous data and allows more intelligent applications to provide functionality for the extra fields without knowing the underlying schema. This fulfills the need for being able to exchange data in a structured format without presentation but with the flexibility of HTML. The philosophy is that we will be able to search with any search engine irrespective of the type of object or metadata schema, but with the DC elements in common to present to the user. The DC fields that we use for service descriptions are dc:title (of course), dc:format (mime-type of the output), dc:type (in this case 'service'), dc:language (language of the user-interface, if any), dc:description (of course) and dc:identifier. The latter will be the URL used for invoking the service. There is no intention to use a persistent identifier for the service: as soon as a service is moved or parameters have changed, it is considered a different service. Fixed parameters may, but do not have to, be part of the dc:identifier field. Below a simplified service description of Google images is shown to explain the basics. The field trigger indicates that the service has to be invoked for the metadata field "creator". The field "inputParameter" specifies that "q" is the URL-parameter that will get the value of "creator" and this will be appended to the field "identifier".
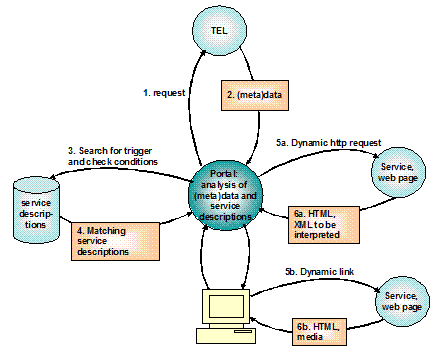
When the input parameter is not a "name=value" parameter, its position in the URL needs to be marked, and this marker will be considered to be the name of that input parameter. For example, in the URL http://myhost/xyz/@par1@ the input parameter is marked by "@par1@". Using the field identifier in this way might look "ugly" but is very effective, and we didn't find practical reasons not to do it this way. Search, select, invoke and useThe elements that will be discussed have to do with searching for services, selecting services either by a user or by a portal, invoking a service and, finally, using the service in the way it was intended or in the way the user wants it to be used. The process is shown in Figure 2.
The user conducts a search in a portal, and for the returned data fields the service descriptions are inspected to find services matching certain criteria. These criteria are in the service descriptions. For matching services, a request is generated. The output of the service will be analyzed and might result in a new request. The fields used in the service description are shown and explained in Table 1. Some important fields will be discussed here:
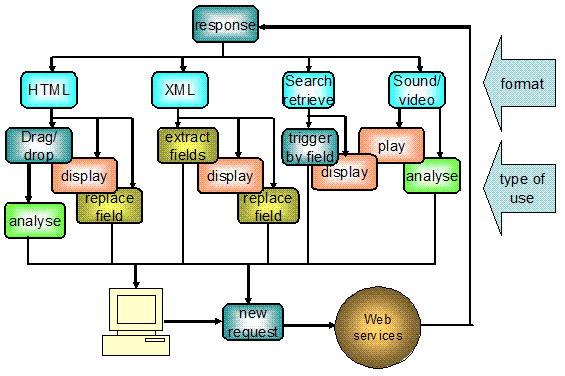
To actually use the service, the portal needs to know the type of output (like image, HTML, XML, etc) as specified in dc:format. Additional fields are needed, for example, for specifying whether the service is invoked automatically or to be started by the user (default), which part of the output is relevant (fieldSpec) and how this output is used, for example, replacing the original metadata field that was used as input or alerting the user that some data are present. In case the service is invoked as a link to a web page, the portal doesn't have control anymore. In that case, the user needs to be able to drag and drop specific contents of the web page into an input box of the portal, so that the portal software can analyze this input and possibly use it as input for the next service in the chain. Table 1 provides an overview of all generic fields that are not bound to a specific service type. There are two namespace prefixes: "dc" stands for the Dublin Core Namespace, and "sd" stands for the Service Description Namespace. The second column "O" shows the type of obligation with: M: Mandatory Repeatable elements are marked with "*". These elements will have a root tag. For some mandatory fields, a portal might use a default if such a field is absent. Special values to be interpreted by the portal start with "_"
The above table is not complete. There may be extra input parameters that are to be filled in by the portal and for which the portal has to know their meaning. For example, for a translation service the portal has to know which parameter is being used for the direction of the translation and which languages are supported so that it can fill in the language of the source and the preferred language of the user. These fields are not part of the data model but will be dealt with separately. As new service types are implemented, new type-specific fields might need to be added. The TELplus XML schema for service descriptions is at <http://dev.theeuropeanlibrary.org/tpportal/model>. Type of useThe user invokes a service for some reason, but the portal does not have any notion of the intention of the user. In some cases the portal may be very agnostic about a service specified by the user. The simplest type of use is just linking to a service, leaving the presentation to the provider. This is also the default type of use. In the case of XML or JSON, the portal can provide a table view of the contents without knowing the schema of the received data. A more specific type of use is one in which the output of a service is used to replace the original field. Another type of use is that a field is input for a service and the output is used to replace the original field, for example when a field is to be translated. Yet another type of usage is one where a specific part of the output should be displayed in such a way that it can be used to generate a new search. A very convenient type of use is that a service is invoked automatically in the background and only alerts the user if, for example, the service has a positive result like the number of hits being larger than 0. For example, when an external annotation service is used, the user does not want to check each record to see if there are annotations. One might specify a service that is invoked automatically in the background to check if there are annotations and to notify the user only when there is an annotation. The possible usage of data from a service also depends to some extent on the actual content type of the output of a service. When the portal expects an image but the image seems to be embedded in an HTML file, the portal needs to respond in an appropriate way, which might be different from what is specified in the service description. In the case of XML output, the portal can be preconfigured for specific schemas to deal with the output (e.g., MARCXML or mpeg21 DIDL). In other cases the portal needs a specification of the data fields to use and needs to know what to do with those data (for example, the name of an XML-element or JSON variable to be used). The default type of use, if it is not specified or not recognized, depends on the portal implementation. Currently, the following types of use are recognized:
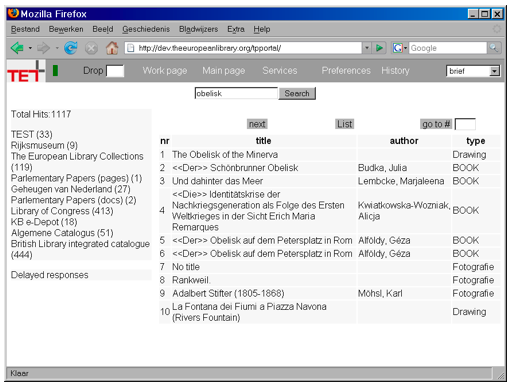
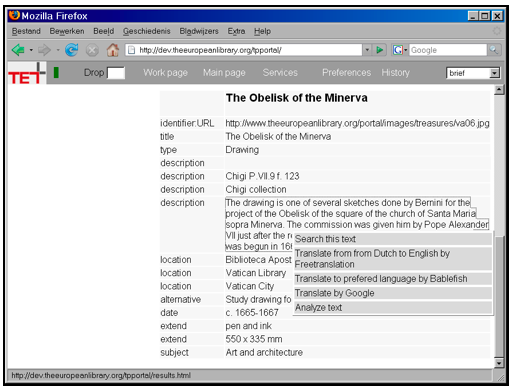
Because it is not possible to anticipate all very specific types of usage, it is expected that in the future more types of use will come up. In this respect the model needs to be extendable, and the portal should offer the most appropriate response depending on the type of data. Creation of service descriptionsIt is not expected that non-skilled users will create their own service descriptions. These users will depend on what is available. On the other hand, there are some websites that are simple enough to allow one to create their service description automatically. For a web page with a simple input form, one has to derive the relevant input field (all other parameters may be fixed), the action URL and the method (POST or GET). The user has to specify the trigger, and for the simplest cases, that's all that is needed. To help users create their own service descriptions, a webpage has been added to our demonstration portal that analyzes a web page entered by the user and creates a simple service description for the simple cases. For most web sites, however, automatic creation of a service description is not that easy. Some service providers make this analysis deliberately difficult for commercial reasons to protect the use of their service. In other cases, providers don't mind, but the web sites are just not designed that way. To facilitate the creation of service descriptions, it would be convenient if websites contained a service description as microformat, acting as a sort of "explain" as in SRU. It would be even more convenient if we could search in Google specifically for web pages containing such a microformat. A future vision is giving the user the option of being followed in his search for information. In that case, it might be possible to detect whether there is a relation between fields that "trigger" the user to invoke a service and the parameter that takes the data as input. In that case, a service description might be created semi-automatically. Extrapolation of this idea is that user agents can find their way on the web by more than just linking. However, to reach this "I have a dream" stage, we should start with the "yes, we can" stage by allowing the user to enter a link to a web page that results in a service description based on an input form. Demonstration portalWe have created a demonstration portal that is available at <http://dev.theeuropeanlibrary.org/tpportal>. Screenshots from the portal are shown in Figure 4. The screenshot at the top of Figure 4 shows the result after a search for "obelisk". The targets that give results are shown on the left side of the screenshot. Clicking on one of them will result in the title list on the right of that screenshot. In the bottom screenshot in Figure 4 a full record is shown. Clicking on the metadata field "description" shows the services that are present in the list of service descriptions and that have "description" as trigger. Clicking on one of these items will invoke the service. Because screenshots are not very effective at illustrating the process, we have provided flash demonstrations at <http://dev.theeuropeanlibrary.org/tpportal/demos>.
Trust and legal issuesThe approach described here might be very promising, but there are some major issues. First, offering a portal that takes the output of external websites to integrate the results in their own website might cause legal problems. The way we will try to solve this is by facilitating service providers to indicate how they want their service to be used (for example, by specifying a logo). The mechanism for this is still to be worked out. Another issue is that one has to be sure that the services – and therefore also the service descriptions – come from trusted parties, because using services from non-trusted parties can cause a lot of damage. Service integrators like TEL are supposed to offer a list of service descriptions of trusted parties with an indication for which ones it is permissible to use the service in this way. When users want more control, they might use their own service descriptions. However, TEL cannot be held responsible for services that users put in their own service description file. At the same time, TEL should also not prevent it, because a user might have a license agreement about which TEL is not aware. New paradigm, new business modelsThe philosophy described in this article requires a change of the business model for service providers. The main issues for service providers are that in some cases branding might disappear and that their servers will get more load. It is, however, a trend that is difficult to stop, and it is difficult for servers to detect whether a service was invoked manually by a user or automatically with input generated by a portal. Service providers might try to prevent the use of their data without the service provider's context. The lack of branding can be compensated for if the service integrator shows the logo of the service provider at an appropriate point in the presentation when a service is used. The use of their services in this user-friendly way may then work as an advertisement for the service provider. The functionality that is used by the portal without branding doesn't have to be fully integrated in the portal. On the contrary: when the service is accessed in the background to get the number of hits, for example, the user may be linked to the web page of the provider only when there are hits. The service provider can offer much more functionality in its own user interface than is needed initially in the portal. This means that the service provider can provide simple services to be integrated in the portal, and the portal will link to the full service web page only when relevant. Another example: a translation service automatically returns the first 150 translated words to be displayed by the portal. If the user wants more words to be translated, a dynamic link to the translation service's web page can be offered. In addition, a subscription model could be made available in which more functionality is offered for a fee. And also in that case, providing some basic functionality in machine-readable format at no cost may attract users to pay a fee in order to receive full functionality. It is expected that services that are easy to use in combination with other services might become much more popular than services for which this is not the case. When those services are offered in such a way that they provide a user presentation in combination with machine interpretable data, it could be beneficial for all parties. The extra load can be a problem for service providers, since their services are being used more or less automatically. In those cases, the data or service provider may offer a very simple service without complicated layout for this specific purpose. In the case of the example to request the number of hits for a request automatically, the provider only needs to return a number, which eliminates the necessity of building a complete web page. In this way both the provider and user will benefit. Although commercial service providers might hesitate to adopt our approach, it is nonetheless very attractive for institutions that work together and do not want to maintain all the applications that can be accessed as a service. Being able to use a service when needed from an institution with particular expertise might provide better results than every institution copying all services to their own machines and then having personnel maintain those services in addition to maintaining their other applications. ConclusionOur development of the data model for service descriptions went hand in hand with the development of a portal to demonstrate the functionality. It turned out that the number of websites that have functionality that can be used in the way being proposed here is limited, and the diversity of services requires an extensive data model. We expect, however, that there will be a trend towards services with a simple API that easily fits in our model. We also found that, despite the complexity of services, the idea of how to use these services began to converge to a less complex concept. There is no need to fully integrate the services with the portal. Being able to get some basic data before deciding to link to the service can work well in most cases. Future work will need to focus on analyzing unstructured data from websites (for example, by means of named entity extraction), to be used as a trigger for other services. Although the potential functionality that can be offered in this way may give rise to the fear of "functionality overload", we expect that most of the services can remain hidden to users until background processes decide that a service has something to offer that is potentially relevant. Though there is yet a long way to go, step by step the user may start using a large part of the web as virtually one big computer with the web browser rather than the portal doing the work of integrating services. References[Ariadne] Theo van Veen, Serving services in Web 2.0, Ariadne 47, April 2005: <http://www.ariadne.ac.uk/issue47/vanveen/>. [TEL] Homepage of the European Library: <http://www.theeuropeanlibrary.org/>. [TELplus] TELplus project webpage: <http://www.theeuropeanlibrary.org/telplus>. [UDDI] UDDI, <http://www.uddi.org/>. [SOAP] Simple Object Access Protocol: 1.2: <http://www.w3.org/TR/soap/>. [WSDL] Web Services Description Language: 2.0: <http://www.w3.org/2002/ws/desc/>. [WADL] Web application Description Language: <http://research.sun.com/techrep/2006/abstract-153.html>. [IESR] JISC Information Environment Service Registry: <http://iesr.ac.uk/>. [OAI] Open Archives Initiative-Protocol for Metadata Harvesting: <http://www.openarchives.org>. [SRU] SRU: Search and Retrieval via URL's: <http://www.loc.gov/standards/sru/>. [Mashup] Mashup (web application hybrid): <http://en.wikipedia.org/wiki/Business_Mashup>. [DCMI] Dublin Core Metadata Initiative: <http://dublincore.org/>. [MPEG21 DIDL] MPEG-21 Overview v.5: <http://www.chiariglione.org/mpeg/standards/mpeg-21/mpeg-21.htm>. [DL] Automatic Multi Language Program Library Generation for REST APIs, Thomas Steiner, 2007: <http://docs.google.com/View?docid=dgdcn6h3_38fz2vn5>. Copyright © 2009 Theo van Veen, Georg Petz, Christian Sadilek, and Michel Koppelaar |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/january2009-vanveen
|