|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Henry Jerez, Giridhar Manepalli, Christophe Blanchi, and Laurence W. Lannom |
![]()
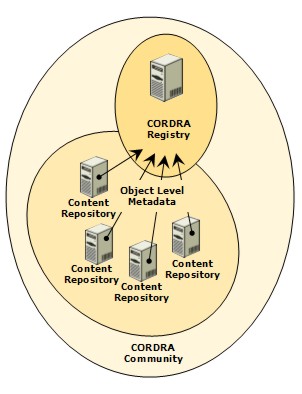
AbstractThe Advanced Distributed Learning Registry (ADL-R) is a newly operational registration system for distributed e-learning content in the U.S. military. It is the first instance of a registry-based approach to repository federation resulting from the Content Object Repository Discovery and Registration/Resolution Architecture (CORDRA) project. This article will provide a brief overview of CORDRA and detailed information on ADL-R. A subsequent article in this month's issue of D-Lib will describe FeDCOR, which uses the same approach to federate DSpace repositories. IntroductionDiscovery of and access to distributed, heterogeneous collections of information has long been a challenge across many areas of endeavor. The growth of digital information, high speed computing, and ubiquitous networks has given us the tools to tackle this problem, but a great deal of work remains to be done. This challenge has been taken up by the participants of the CORDRA project. CORDRA is a collaborative activity led by the Advanced Distributed Learning (ADL) [1] initiative of the U.S. Department of Defense, the Corporation for National Research Initiatives (CNRI) [2], and the Learning Systems Architecture Laboratory (LSAL) [3] [Note 1]. The goal of the project is to create a global infrastructure for the federation of content repositories. While the project began in the e-learning space, it immediately encountered the requirement to provide access to any type of digital collection needed in support of distributed learning, which effectively includes all types of content. Groups of repositories will form federations by registering their content in a central registry and those federations will themselves register in higher level Registries of Registries (RofRs) thus forming federations of federations, culminating in a root level Master Registry of Registries. There is no notion of control at that root level, only the start of a path to any of the registered collections in any of the federations. The individual federations will vary in the specifics of metadata standards, access policies, organizational principles, and so on, but CORDRA will define an abstract model, some working code, and a set of standards for federating the federations. ADL-R is the project and operational registry representing the first of these federations. CORDRAThe CORDRA project was announced by ADL early in 2004 at the first ADL International Plugfest in Zurich. ADL is an important player in the world of distributed learning standards, primarily through its creation and support of SCORM (Sharable Content Object Reference Model) [4], a suite of standards defining an interoperability framework for e-learning content and associated instructional systems. SCORM has been highly successful and has helped move e-learning from an era in which proprietary platforms required proprietary content formats and packaging to one in which it is possible to create content that will work across multiple systems and to create systems that can deliver content from many different sources. Having thus created an environment that enables the re-use of content, or even the real time aggregation of fine-grained distributed content, ADL faced the next logical problem – finding and accessing the distributed content. And unlike the library and publishing world, there was no established tradition of bibliographic control to at least provide a starting point for identifying and describing abstract works, manifestations, copies, and so on. ADL launched the CORDRA project to address this problem – the discovery and access of distributed learning content. LSAL, which had made significant contributions to SCORM and other aspects of distributed e-learning systems, was added as a collaborative partner. CNRI was asked to join as a third partner, based largely on our work in network architecture, especially identifier systems. The basic CORDRA approach is to create federations of repositories by registering, in a central registry, the metadata for each content object from a set of independent repositories. That set of repositories and the associated registry are then said to comprise a federation. The model assumes multiple federations and any given federation is assumed to represent a community of practice. Such a community could have its own set of metadata standards, access policies, collection policies, and so on, and the metadata registry that is the focal point for the federation should reflect those specific practices. Common practices and relatively homogeneous content allow for consistent and detailed description of content objects, which in turn allows for optimal searching and organization of the resultant metadata. That is, the best discovery and access information is naturally available across collections of metadata that are both detailed and internally consistent, and that situation is most likely to pertain in a set of relatively homogeneous content collections within a given community. In the case of ADL-R, for example, the focus is e-learning material within the military. While there will be a great deal of diversity within that collection, much of the metadata required to usefully federate a set of repositories containing that content, e.g., SCORM sequencing data or military classification, simply will not be useful or even make sense in many other environments. This initial stage of repository federation is illustrated in Figure 1.
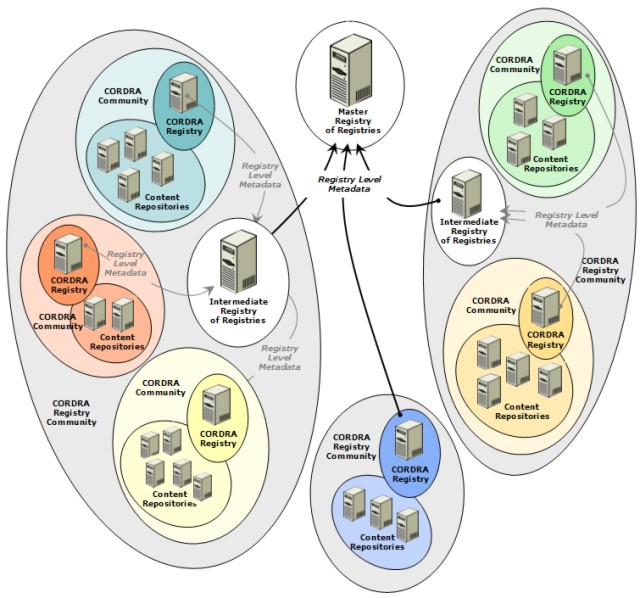
How does one then federate the federations and so provide search and retrieval services across a disparate set of collections? The CORDRA model calls for another registration process in which the first level registries, those collecting data directly from content repositories, provide data to a Registry of Registries (RofR). The initial formulation assumed a single RofR to which all federations would contribute. Subsequent analysis and initial experimentation has shown the need for intermediate level RofRs, culminating in a Master RofR, which would serve as the CORDRA root. This is the approach illustrated in Figure 2.
Many technical and organizational issues remain to be worked out and are still the subject of research and prototyping, including the details of federation level metadata. Precisely what data gets pushed or pulled up from one level of registry to the next? The answer to that question will determine the methods that could be used to provide services across federations. The goal, however, is clear. Starting from the Master Registry of Registries, an application should be able to discover and navigate to any individually identified content item anywhere within the complete set of repositories federated according to the CORDRA model. The rest of this article is devoted to ADL-R, which is the first CORDRA federation. It has been operational for several months in an advanced beta period, and has just recently become fully operational. Other CORDRA federations, based on the software developed in the ADL-R project, are currently being developed both inside and outside of the e-learning community. ADL-RADL-R is the first publicly available CORDRA registry and was developed as a partnership between ADL, CNRI and LSAL, with CNRI responsible for much of its development and implementation. The project went live in December 2005. ADL-R provides a registry of learning content for the U.S. Department of Defense. It enables the military community to register SCORM content objects and encourages their discovery and reuse by other members of the community and, in some cases, the general public. The Defense Technical Information Center (DTIC) [5] will be the future home of ADL-R and will be the DoD agency responsible for maintaining and running the registry and associated services. The project allows the various military service components and their associated contractors to submit metadata instances about content objects that they author or acquire. The submission of a metadata instance constitutes the registration of the content object being described by the metadata. Multiple metadata instances may be submitted by multiple parties for the same uniquely identified content object. These metadata instances are expressed as LOM [6] (Learning Object Metadata) encoded as XML and are submitted manually or automatically to the registry, which relates them to other metadata instances for the same content object through the identifier for that content object. ADL-R uses the Handle System [7] for identification. ADL-R accepts the registration of content objects already identified by handles, e.g., the entire DOI [8] world, in which case those handles are managed externally to the ADL-R project. It also allows, however, for the registration of content objects not currently identified by handles. In that case, the submitting organizations are assigned handle prefixes and the resultant handles are administered by the registry, thus providing a handle service to those organizations, eliminating the need for them to install and maintain handle servers, and so keeping their environments unchanged. As a CORDRA registry designed from the ground up for a particular community while respecting the general CORDRA guiding principles, ADL-R provides the necessary interoperability and flexibility to fit smoothly into current organizations without the requirement of major content parsing or re-structuring. The goal of the registry is to allow community members to make their content metadata instances available and searchable. These metadata instances allow the discovery of particular content object handles that can then be resolved to provide access, where allowed, to the full registered content. The content, and the access conditions for that content, remain with the submitting organizations within whatever repository or other access methods they employ. Updates on both the metadata instances and the content objects remain a responsibility of the registrants, but the registry provides well-defined interfaces and tools for the users or automatic agents to keep this information current. Conceptual design of a flexible, robust and secure registry implementationIn the context of the CORDRA community, the registry is intended to serve as a primary node for registration and indexing of metadata related to one of three possible components of a CORDRA federation:
Each level of the federation may use the same code base to deal with registration and queries on different types of metadata. This translates into the submission, validation, and subsequent indexing of the different metadata instances being configurable rather than hard-coded. At the same time, the different CORDRA communities using an instance of the registry for their own implementation, will most likely want to implement and enforce their own authentication mechanisms, as well as their particular software packages, to store and index the contents of their submissions. This approach calls for a registry that implements a series of well-defined APIs and protocols to communicate with its particular operational components and allow their exchange or extension in the framework of such protocols. Our answer to this requirement is a configurable piece of software that is capable of implementing a series of operations and streamlining them by means of protocols and APIs that use modular software components to implement the various registry operations. These operations are:
The registry is also capable of integrating global content and uniquely identifying it across multiple repositories, registries, and even federations. Such universally unique identifiers allow delegated or strict management. Finally, the registry is intended to group itself with other registries to provide federation level cataloging services. Registry entities and modelOur architecture identifies two types of first level entities:
Each of these entities is uniquely and globally identified, and that identification constitutes essential data in the system. We also identify the following second level entities:
Handles are used to identify most of the files in the registry, including the schemas, and are used inside of XML documents by means of a handle proxy server. A third set of data, not directly exposed, is used to perform multiple registry and CORDRA-related operations. This category may evolve over time, as federation evolves, but is currently represented primarily by the Indexing Data, which includes index catalogs and supporting data created and stored inside every registry. This data is an extended subset of the first level entities and is primarily used to perform advanced query and federation operations. The registry makes only the first level entities described above accessible to the general CORDRA infrastructure and to external users. In order to maintain data independence and flexibility, the registry provides three layers of isolation for its configuration. This differentiation enables CORDRA aggregation and distributed querying, while maintaining the local independence and flexibility of each CORDRA community.
As shown in Figure 3:
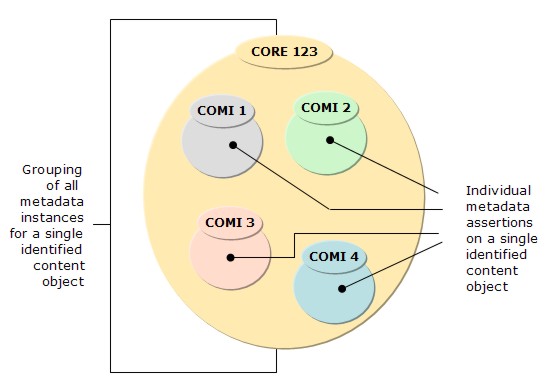
We envision the top two layers to have strict validation, while the bottom layer might accommodate more lax implementations. Based on this architecture, any submission will be subjected to a strict validation of the top two layers, an evaluation that will most likely be synchronous or pseudo synchronous, and an asynchronous validation and parsing of the bottom data layer. Content Object and Metadata InstancesInternally, the ADL-R acknowledges the existence and independence of content objects outside its control as well as the multiple metadata assertions about them. ADL-R uses an encapsulated internal digital object representation and storage in order to represent this structure and allow multiple unrelated parties to make assertions about a particular object previously registered by its owner or responsible party. In this internal representation, a globally known object identified by a handle is called a Content Object (CO) and its handle is referred to as a Content Object Identifier. The internal abstraction of this object inside the ADL-R is called CORE (Content Object Representation Entity) and is associated with a CORE identifier which is a direct calculation based on the CO's handle, in order to expedite the ID resolution. It is important to note that the CO Identifiers can be part of any handle prefix [10] while the CORE IDs are exclusively contained and administered by the Registry and fall under the specific Registry prefix. All content object abstractions and their respective metadata assertions or instances inside a particular registry share the same registry prefix. Metadata assertions, or COMIs (Content Object Metadata Instances), are stored inside COREs. Each metadata instance is exclusive to the specific registry in which an assertion has been made. The process of making a metadata assertion by submitting a metadata instance about a particular content object is called metadata submission. When the first metadata instance is submitted to a specific registry for a specific content object, a content object registration is said to have taken place. The content object registration is nothing but the creation of the internal CORE within the Registry. Figure 4 shows the internal representation of a content object and its associated metadata instances.
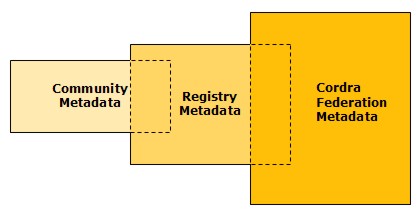
Registry Metadata Instance layersRegistry submissions consist of metadata assertions about particular content objects. These metadata instances are a combination of local community metadata and global federation or CORDRA level metadata. Local communities submitting to a particular registry will have a defined metadata format and metadata fields that they agree upon. This metadata set is meaningful for their particular uses and procedures. A smaller portion of this metadata is intended to be completely indexed by the registry in order to enable discovery of the described object, but the complete set is always stored in full. On top of this metadata, some additional metadata is needed by the registry to perform registry operations. Additionally, some information either extracted from or added to the local metadata will be required by the overall CORDRA community. Therefore, each registry submission incorporates both community metadata and registry level metadata. This is illustrated in Figure 5 below.
The registry must distinguish these metadata layers, therefore the main XML submission has two main components following two different XML schemas:
Additional characteristics of each metadata layer are captured by means of business logic modules at both the Registry/CORDRA level and the Local/Community level. ADL-R authentication and authorizationADL-R includes a basic set of authorization and authentication tools that can be replicated in other CORDRA registries and federations. Basic authentication is expressed in terms of the Handle System with users and groups identified by handles. Repositories and content objects as well as registries are identified by handles, and the relationship and rights of particular groups and the users that are part of those groups are registered in handle values that correspond to special registry types [11]. These values express different rights of groups in relation to particular registries, content objects, and repositories, and also reflect the rights of each registry over certain sets of handles for those cases in which the registry also provides handle registration and administration services for content registrants. CORDRA registries will respect the individual authentication rules and implementations of each community. Thus, the registry allows for community-specific authentication components that plug in to the authorization tools and use generic registry administration utility libraries (RAUL). In the case of ADL-R, an LDAP authentication mechanism is plugged in to the registry and allows authenticated control to both the registry and its administration tools. ADL-R functionality and componentsThe ADL-R architecture ensures modularity and scalability by dividing its operations among several interoperable modules that perform very specific tasks and present well-defined APIs, and communicate in standard fashion using XML schema enforced messages.
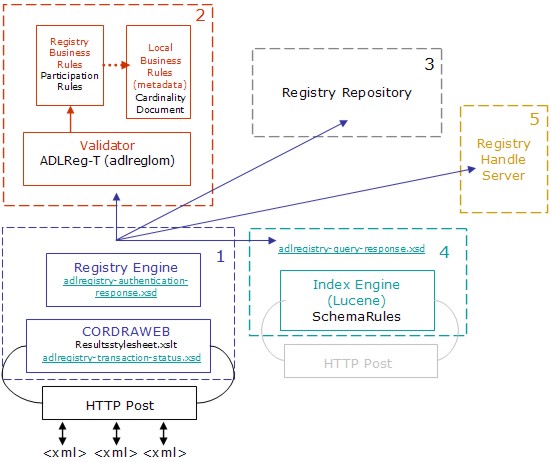
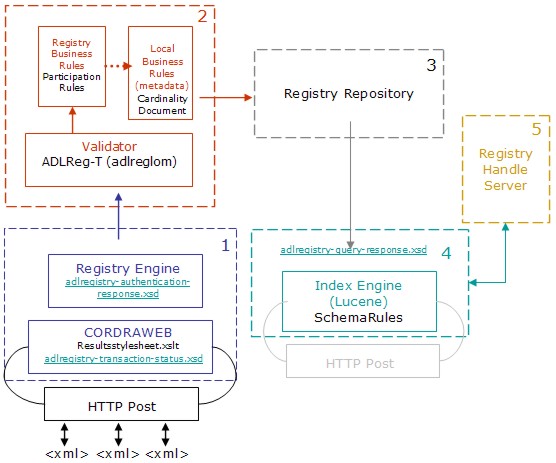
As shown in Figure 6, the ADL-R System has the following major components: 1. Main Registry ModuleThis module contains the main Registry Engine and an implementation of the web interface to the system. The web interface is provided by means of the HTTP module labeled CORDRAWEB, which deals with the reception of all the requests and the generation of HTTP-based responses. The submissions and status requests come in through an HTTP Post interface. The adlregistry-transaction-status schema is used for its responses. The Registry Engine module is responsible for implementing, enforcing and keeping track of all operations inside the registry and is, in fact, the central registry coordination module. This module is also responsible for all authentication and authorization tasks for the system. The Registry Engine main library is called RegistryLib. 2. Validator ModuleThe Validator Module relies on a series of external libraries, tools, and software packages to implement some of its basic operation validation tasks. This module takes into consideration "well-formedness" and business rule adherence for all operations. It is composed of a basic XML Validation module that enforces adherence of the transactions to the adl-reg-T schema as well as the local community XML schema, which for ADL-R is the ADL LOM metadata schema. Once the validator has determined that the transaction is well formed, the submitted data is validated against a Registry Business rules validator and a Community Business Rules validator. The Registry Business rules validator enforces registry level rules expressed in the participation rules configuration file. These business rules are intended to guarantee that the Registry is capable of performing its own operations and participate in a larger CORDRA community. The local Business Rules validator enforces the local community rules that were not expressed in the schema. These rules are purely associated with a particular community and its practices. 3. Registry RepositoryA Repository Access Protocol (RAP) [12] accessible digital object repository is responsible for providing storage and retrieval of internal content object abstractions and metadata instances. The Registry is designed to interact with a RAP-based digital object repository and implements a set of storage and management rules based on the notion that a digital object represents a content object and that each digital object container is to contain zero or more metadata instances describing its respective content object. Each digital object, and the metadata instances it contains, are uniquely identified and locatable using the same handles as those provided in the transaction request. 4. Indexer ModuleThe flexible indexing module is responsible for the contextual and full text indexing of information relevant to the particular CORDRA community and the global CORDRA infrastructure as a whole. The indexing is performed according to business rules which are specific to a community and a registry implementation. These rules are read from an object in the registry and all of this is independent of the specific implementation of the search engine, as long as it is capable of reading its key mapping from a schema rules configuration file that lists each key's XML path for extraction. The communication is implemented using HTTP, and the operations are performed following the basic operations for a Lucene search engine [13]. The Indexer module is fitted with an advanced index interface that has pre- and post- processing business rules modules that expose the indexes directly to registry of registries and advanced service interfaces. 5. Handle ServiceThe registry architecture includes a handle service responsible for the administration of internal handles as well as delegated content object handles for some of the registered content objects and their metadata instances. ADL-R expects to be able to at least resolve content object and instance metadata handles and, depending on the specifics of ownership, administer them. ADL-R is also dependent on the Handle System for identifying and locating the registries with which it is directed to interact. The handle service is crucial for the correct operation of ADL-R; it is used to configure the registry, locate and connect to the appropriate registry, and identify content objects and metadata instances, and it is also used for authenticating and authorizing users. System workflowThe registration process is illustrated in Figure 7.
The registration process is as follows:
Once this operation has finished, the Registry Engine updates the status log and sends out an email if the batch processing has finished. Conclusion and Future WorkThe ADL-R has implemented a successful first instance of the CORDRA model that is not only flexible and scalable but modular enough to be reused in multiple new CORDRA communities and scenarios. An example of this potential is the FeDCOR project [14] that uses the same code base to form a DSpace institutional repository community. Our current focus is on the formalization of the current Registry APIs and modules to allow for even more flexible registry implementations. It is the intention of the CORDRA steering committee to release the final source code for the registry as an open source project. Extensive work is underway to build the first registry of registries instance and consolidate the first CORDRA aggregation community. This work should yield some interesting results in the near future. The authors would like to acknowledge the Advanced Distributed Learning Co-Labs who funded most of this work, as well as the collaboration of the Learning Systems Architecture Laboratory, Concurrent Technologies Corporation, Defense Technical Information Center, and all of the members of the ADL-R pilot group who helped in the design and development of the ADL-R. Note[1] The three CORDRA project principals at these organizations are Philip Dodds (ADL), Dan Rehak (LSAL), and Laurence Lannom (CNRI). These three also constitute the ad hoc Steering Committee for the project, which will likely move to a more permanent organizational format over time. References[1] Advanced Distributed Learning (ADL). <http://www.adlnet.org/>. [2] Corporation for National Research Initiatives (CNRI). <http://www.cnri.reston.va.us>. [3] Learning Systems Architecture Laboratory (LSAL). <http://www.lsal.cmu.edu/>. [4] SCORM (Sharable Content Object Reference Model). <http://www.adlnet.org/Scorm/index.cfm>. [5] Defense Technical Information Center (DTIC) <http://www.dtic.mil/>. [6] Learning Object Metadata (LOM) <http://ltsc.ieee.org/wg12/>. [7] The Handle System <http://www.handle.net/>. [8] The Digital Object Identifier System <http://www.doi.org/>. [9] Kahn, R. and R. Wilensky, "A Framework for Distributed Digital Object Services," 1995; <http://hdl.handle.net/4263537/5001>. [10] Handle System Overview, RFC 3650. <http://hdl.handle.net/4263537/4069>. [11] Handle System Namespace and Service Definition, RFC 3651, Section 3.1 Handle Value Set. <http://hdl.handle.net/4263537/4068>. [12] Sandra Payette, Christophe Blanchi, Carl Lagoze, and Edward A Overly. "Interoperability for Digital Objects and Repositories: The Cornell/ CNRI Experiments", D-Lib Magazine, May 1999. <doi:10.1045/may99-payette>. [13] Apache Lucene <http://lucene.apache.org/java/docs/>. [14] Giridhar Manepalli, Henry Jerez and Michael L. Nelson. "FeDCOR: An Institutional CORDRA Registry", D-Lib Magazine, February 2006. <doi:10.1045/february2006-manepalli>. Appendix I - GlossaryNote: the following definitions apply to the ADL-R project and are proposed, but not settled, terminology for CORDRA. ADL-R: Advanced Distributed Learning Registry. The first registry created by ADL to register SCORM-based learning modules for the U.S. Department of Defense (DoD). API: Application Program Interface. A collection of well defined libraries, programs, and routines that provide generic access to the functionality of a particular programming module. Authentication: Process of identity validation. Inside the ADL-R this is the process by which the direct relationship between a particular LDAP ID and a user identification handle is established and tested. Authorization: Process of rights assessment for a particular user associated with a respective group. In ADL-R all rights are expressed as a function of the group and its rights over a particular prefix. Typical CORDRA level rights are
COMI: Content Object Metadata Instance. Metadata instance generated for a particular content object and submitted to a CORDRA registry. This entity is stored inside the Content Object Representation Entity (CORE). Community: Short for a CORDRA Community, which may be any of: Local Metadata Community associated with a particular Registry; Registry Community associated with a particular Registry of Registries, or the CORDRA Community in general as reflected in the Master Registry of Registries. Content Object: Resource about which metadata assertions are made in the context of CORDRA; it could be an SCORM module, a technical report, a book, or any structured form of data about which a metadata assertion can be made. CORDRA: Content Object Repository Discovery Registration/Resolution Architecture: Architecture for the discovery and registration of content objects stored in multiple repositories across different local communities. CORDRA Community: The aggregated global community of CORDRA compatible registries that may integrate and share their information into a Master Registry implementation. CORDRA Federation: The successful aggregation of multiple registries and registries of registries to provide a set of discovery, registration and resolution services. CORE: Content Object Representation Entity: The internal content object abstraction and representation of a particular content object inside a CORDRA Registry. Handle: A persistent identifier composed of a prefix and suffix and that uniquely identifies a particular resource. Handle Prefix: The delegated prefix associated with a particular collection spread across one or more repositories and which is combined with a set of suffixes to uniquely identify content objects. Handle Server: An implementation of the handle software that provides basic storage, resolution and administration to a set of handles. Handle Service: The collection of handle servers that provide storage, resolution and administration services for one or more handle prefixes. Handle Suffix: The local unique identifier associated with a particular resource. HTTP Post Interface: A generic interface that receives and processes HTTP Post data sent by means of an HTML form or http connection. LOM: Learning Object Metadata. Metadata standard defined by IEEE. Messages: XML formatted documents exchanged between two particular modules inside the ADL-R. Metadata Instance: A particular metadata assertion made about a content object. Metadata Submission: XML encoded file that includes the local metadata instance information along with Registry and CORDRA level metadata. Module: Programmatic component of the ADL-R composed of multiple routines that deliver a common expected and well defined outcome. OAI-PMH: Open Archives Initiative Protocol for Metadata Harvesting. Operation: One of the following Registry operations:
Operation Request: HTTP Post that includes either the required fields to perform a query or an XML encoded operation request that includes the fields to perform the operation specified. Persistent Identifier: Identifier that remains persistent across time, including changes such as location and ownership. Prefix: Short for Handle Prefix (see above). Registry: Short for ADL-R Registry or CORDRA Registry. Repository: Content Object repository hosted at a site external to the Registry. Retrieve Metadata: Serialize a metadata instance stored inside the ADL-R. Retrieve Object: Perform a handle resolution and follow the URL value associated with it. This operation could produce the actual object or a description of how to obtain it. Schema: Short for XML Schema. Submission: An xml encoded operation request sent to the Registry. Transaction: An operation submitted to the registry, accepted for processing, and associated with a transaction identifier. URL: Universal Resource Locator. XML Schema: Guiding description of an XML document that specifies all its components and attribute characteristics and allowed values. XML Style sheet: XML document that guides an XML transformation for a particular XML document. (A spelling of one of the headings was corrected on February 20, 2006.) Copyright © 2006 Corporation for National Research Initiatives |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/february2006-jerez
|