|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Uwe Müller,1 Thomas Severiens,2 Robin Malitz,1 and Peter Schirmbacher1
1 Humboldt-Universität zu Berlin
2 Universität Osnabrück |
![]()
AbstractThis article describes concepts, development, and implementation of an overall Open Access infrastructure for Germany. Currently, the joint project Open Access Network is facilitating comprehensive and value-added services built on top of distributed Institutional Repositories. Using the OAI-PMH as the harvesting mechanism, Open Access (OA) Network furnishes an open and extensible architecture to form the technological base for manifold enhanced services. It not only provides a personalized end user platform but also serves as an aggregator node for passing data to other service providers (e.g., DRIVER). Moreover, OA Network provides a testbed for the development of software to implement value-added services. OA Network is funded by the German Research Foundation (DFG). 1 IntroductionCurrently, in most universities and other research institutions, Institutional Repositories (IRs) are operated as a basic part of the local information infrastructure [1]. They serve as publishing platforms designed to allow self-archiving in terms of the so-called green road to Open Access.1 As indicated by pertinent repository directories, the degree of IR coverage in Germany is particularly high.2 Widespread standards and guidelines, such as the Open Archives Initiative Protocol for Metadata Harvesting3 (OAI-PMH) and the DINI Certificate for Publishing Services in Germany [2], aim at facilitating the interoperability of these distributed document archives and at enabling comprehensive services on top of them. However, the vast majority of repositories remain virtually empty as of yet, and the content that has actually been published is barely detectable on the Internet in many cases [3]. The strong disparity that exists between the provision of local infrastructure and effective usage can be attributed to a variety of reasons [4]. For one thing, there are few incentives for researchers to deposit their materials – which have already been published formally elsewhere – additionally in institutional repositories. Doing so does not provide them with financial gains. However, depositing in IRs does increase their reputations, e.g., by enhancing their visibility – even though this is not always obvious to the authors. And while academic staff members in many cases are officially "encouraged" by their institution's management to make their scientific publications freely available following the Berlin Declaration [5], so far within Germany, neither institutional administrators nor funding organizations have issued mandates requiring the deposit of materials into IRs. In addition, for the most part, basic functionalities and value-added services built on top of Open Access repositories have not been available, commonly known, or aligned with the research communities' needs. In part, this is due to the absence of an overall Open Access infrastructure. Open Access, therefore, has not been widely accepted by researchers in their roles as both authors and readers. 2 Motivation and AimThe development of the OA Network4 is being driven by the main desiderata in the field of green Open Access publishing. The reasons that Open Access hasn't yet reached a general break-through include:
Obviously, each of these problems highly impacts the others. For example, the lack of acceptance of OA-based publishing models inhibits the achievement of a critical mass of available documents, which itself is a precondition for increasing the level of acceptance. Successful overall services (e.g., browsing, citation analyses, etc.) require a sufficient amount of available publications as well. Assuming that they are aligned with the scientific communities' needs respectively, these services in turn can contribute to increased author-side usage of IRs. In part, the lack of success with regard to green Open Access is inherent in the existing IR scenery, which is characterized by institutional specificities and disciplinary diversity. While researchers are expected to deposit their publications in IRs, they would hardly use these "pick 'n' mix shops" for their own literature search and retrievals. Because they are of fairly low value for readers, IRs tend to be unattractive to authors as well. Therefore it is obvious that enhanced visibility of publications deposited in IRs can only be achieved by the existence of joint retrieval services that can present a huge amount of data deposited in the local repositories. Consequently, the basic idea of the OA Network is to provide an overall and open infrastructure for Open Access publications built on top of distributed IRs. Thus, OA Network aims to make publishing in IRs more attractive and to help to overcome the vicious cycle of problems affecting OA publishing in Germany today. In particular, the OA Network intends to:
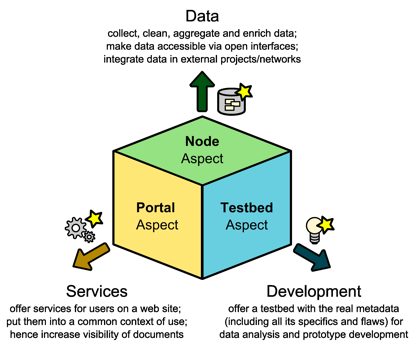
In Figure 1, the different aspects of OA Network resulting from these principal objectives are depicted. Namely, OA Network is a node delivering data to external partners; it is a portal providing services to end users; and, finally, it is a testbed allowing the development and evaluation of third party services. The particular benefit of this testbed is that algorithms and analyses can be examined and verified based on a sizeable collection of real data. Once a new service has been successfully reviewed within the testbed, it can be integrated into the OA Network portal and thereby enhance the functionality provided to end users and third party services.
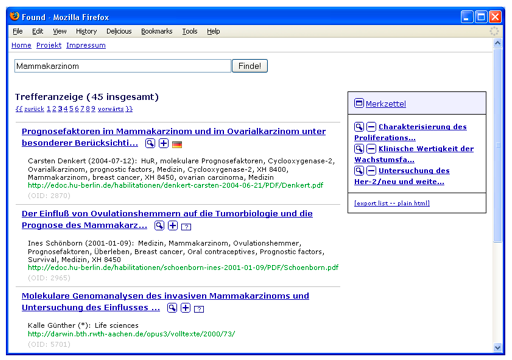
Apart from developing the technological infrastructure, the OA Network project aims at increasing the number of publications made available in Institutional Repositories. This is achieved by a variety of activities. For one thing, we directly approach researchers using the communication channels provided by professional associations and learned societies. This helps us learn about discipline-specific requirements, and it is also intended to raise awareness of OA publishing among researchers. We also strengthen the community of repository operators by supporting the technological and organizational preconditions for participation in the OA Network. OA Network development is closely coordinated with other activities, especially those accomplished by the Electronic Publishing Group of the German Initiative for Network Information (DINI). This guarantees both a sustainable service and the involvement of all relevant stakeholders regarding OA publishing, i.e., academic communities, libraries, repository operators, and funding organizations. 3 A Comprehensive OA InfrastructureThe service infrastructure established by the OA Network is based on distributed repositories – usually associated with universities and other research institutions – where scholars can deposit electronic copies of their research publications. It is also in these local archives that corresponding metadata are registered in addition to the actual digital documents – performed either by the authors themselves or by library staff. In order to collect these distributed data regularly, the OA Network – like any other overall service provider – depends on appropriate interfaces delivering data based on a defined protocol. As the de facto standard for the exposure of metadata in the repository context, the OAI-PMH serves as the natural base for the OA Network data aggregator. Since most repositories have implemented an OAI interface and nearly all up-to-date repository software solutions support this protocol, the majority of publishing servers comply with the basic prerequisite for collaborating with the OA Network. Already mandated as the least common denominator by the OAI standard, Dublin Core (DC) is used as the metadata exchange format. In addition, the OA Network assumes the application of default set definitions within the OAI interface as recommended by DINI [6]. The set framework classifies repository assets according to both DDC (Dewey Decimal Classification) subject headings and formal document types. This supplementary record information enables basic browsing functions on the part of the OA Network portal. Before being made available for other services within the OA Network, the collected data have to undergo correction and normalization procedures. Among other things, as essential preparatory work for transforming data so that it is DC qualified, during this process language and date codes are converted according to ISO standard encodings. In order to generate fulltext indices and perform other publication-based operations, the URL that leads to the actual electronic document (i.e., the fulltext link) has to be identified for each metadata record – a surprisingly complicated routine. As a basic user service built on these preprocessing operations, the OA Network provides a simple search function encompassing metadata and fulltext information of the publications of all participating repositories (see Figure 2).
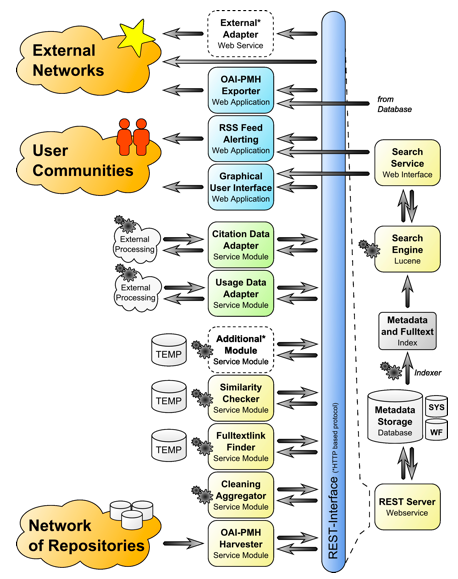
In contrast to existing federated retrieval systems for academic literature, such as Google Scholar,5 BASE,6 and OAIster,7 OA Network is characterized by highly controlled data sources, elaborate browsing features (according to subject classifications, institutions, authors, document types, etc.), a clear focus on German repositories, and – most importantly – an open architecture. The latter allows the inclusion of services developed and maintained by third parties (see Section 4 of this article). Being a dedicated harvester for repositories situated in Germany, OA Network clearly has not been designed to be a favorite access point for researchers searching for relevant literature in their respective fields. Thus, the OA Network data aggregator is not an end in itself, and the portal function is only one aspect of the developed infrastructure. Furthermore, the OA Network serves as a showcase for both the academic output within Germany and the added value facilitated by Open Access publications. In this sense OA Network is also meant to be a testbed for new service technologies, which can be provided and evaluated using the harvested and enriched data. Finally, the collected data are held ready to be delivered for external services, e.g., DRIVER or subject-related retrieval services. 4 Open Service ArchitectureTechnically, the OA Network infrastructure layer has been implemented as an open and distributed service infrastructure. Thereby, a central data storage of the collected metadata information is made available to internal and external services via documented interfaces (APIs). These interfaces are realized as REST8 web services offering a number of strictly controlled interfaces for services to interoperate with the data storage. OA Network has decided to implement the APIs in REST, since this protocol offers all requested structural elements and is more efficient than SOAP9 or .NET10 based services, for example. In addition, REST makes it possible to connect services by calling a URL with any browser as a low barrier interface. As depicted in Figure 3, the infrastructure built up within the OA Network project consists of three basic parts: a central data storage, the API layer defined by the query options of the REST interface, and a number of modules like the metadata collection service ("harvester"), and the browsing and retrieval GUI. The data storage contains resources defined as semantically coherent data objects.
While the search module enabled by the index and the search engine uses a separate interface, all the other service modules access the data storage via the uniform REST interface. This communication bus not only delivers resources to the service modules but also allows controlled writing access. This bidirectional communication approach facilitates distribution of the individual service modules, harmonizing and enriching the metadata. During this process, which is managed by a workflow component, all metadata versions are preserved. Thus, delivered resources always contain both the cleaned and original forms of the collected data. Service modules can decide how to deal with the heterogeneity of the data and determine which information should be used. Service modules requiring complex and time-consuming calculations may use local storage to process them, for example, a similarity checker needed for automatic classification processes, as described in Section 4.1. To date, a number of enhanced service modules have been implemented, including a similarity check, automatic classification according to DDC subject headings, etc. These enhanced services are programmed in PHP11 respective Perl, while the API is implemented in Java. The intention behind this inhomogeneous implementation was to demonstrate the expandability of the framework for services and functions developed by third parties. The services are distributed on computers at three universities (Berlin, Osnabrück, and Oldenburg), as the framework needs to be open for any distributed implemented services, and it also needs to offer good performance to the users. The workflow and registration of these service modules are also part of the OA Network framework, and allow developing and integrating additional and alternative services. Plans for the future include providing support and community services for developers who are building service modules. 4.1 Enhanced RetrievalAs an added value, OA Network automatically classifies the publications it harvests according to DDC subject headings before returning the publications to the repositories. For this purpose linguistic algorithms [7] have been developed and trained. During the training phase the full texts and metadata of publications that have already been classified by the local institutions' librarians are used. Since each academic domain is characterized by certain styles, vocabularies, and particular ways of writing, this prior training at least increases the probability that the automatic subject heading classification performed by OA Network will be accurate. This automatic classification is incorporated into the internal metadata description of every object in OA Network and is made publicly available via its OAI-PMH interface. Thereby, repositories can reimport the cleared and enriched metadata of their own publications. While automatic classification may work for documents of one language, it will fail for multilingual document collections. For this reason, OA Network plans to develop another module that can determine the language of both metadata and fulltext documents. Though identifiers for the language often are contained in the metadata records exposed by the Institutional Repositories, that information is of very limited value: sometimes the language information refers to the publication itself; another time it might describe the language of the metadata. For the retrieval interface that combines browsing and search functionality, the information about both the academic domain and the language of the publications is of special interest. Having determined these document properties allows the implementation of a multilingual search interface. As an example of this problem, assume a user executes a query asking for the term "field". This query would result in hits on English-language publications in the domains of agricultural research, physics, and mathematics. Automatically expanding this search term to "field OR Feld OR Körper" (given an English-German context, for instance) would not help solve this problem, as the word "Körper" (meaning "body" in the medical context) would also result in too many hits. However, knowing which subjects the documents are about respectively, the original query could be expanded to "field OR (Feld IN agriculture) OR (Feld IN physics) OR (Körper IN mathematics)".12 This would lead to a far more concise result set, eliminating hits arising from ambiguous translations. 4.2 Value-added ServicesIn addition to basic internal services implemented to clean and harmonize the collected and stored data, the OA Network also envisions the integration of manifold value-added services based on the topology and metrics of the information space. Two of these services, which provide usage statistics and citation analyses, are to be implemented within two corresponding projects, namely OA Statistics and DOARC.13 Like the OA Network, both of these projects are funded by DFG and are coordinated by DINI. The DOARC project aims at analyzing and describing the citation network of both the collected documents and other OA publications, in order to present to users additional information referring to interdocument relationships. One of the outcomes of this project will be that users will have the ability to browse documents along citation graphs. Moreover, citation and linking information will be used to enhance ranking of search results at the OA Network retrieval interface, forming a transparent analogy to the well known impact factors. Another focus of DOARC is to provide support to authors to cite works in a standardized and recognizable way. This includes the development of plug-ins for authoring software and online tools. With this activity, DOARC aims at making citations processable in an automatic way. The OA Statistics project, on the other hand, focuses on usage and linking server statistics, taken as an indicator for the actual usage of online publications. OA Statistics is developing tools and codes of practice enabling the counting of accesses to publications on a trusted, comparable, and standardized basis. Like the citation information found by DOARC, the aggregated usage statistics will serve as an additional factor in the ranking of documents contained in query result sets. 5 Consolidate Repositories and CommunityInitiated in 2007, the OA Network is only half way through the project's term. To date, the basic infrastructure – comprised of the data aggregator, data storage and harmonization, and the REST interface – has been established. To show functional efficiency, all Institutional Repositories within Germany that have been issued the DINI Certificate have been integrated into the OA Network prototype, and they are harvested on a regular basis. The developed OA Network portal provides simple retrieval functionalities, including metadata and fulltext searching, classification-based browsing, and an expanded view on single metadata records. Moreover, the principal concept of the open service architecture could be exemplarily proven with some internal services enhancing the aggregated metadata. During the second phase of the project, the consortium will focus on the following main issues:
As a matter of course, the usability of the OA Network strongly depends on the timeliness and completeness of the available publications. Hence, one of the foremost work packages within the second project phase consists of supporting local IRs in order to make them ready to participate in the OA Network. Therefore, the project aims at increasing the number of repositories holding the DINI Certificate. Also, because the acquisition of content at the local level is another important issue in terms of promoting Open Access, the project closely cooperates with the information platform open-access.net.14 To enhance the services provided by the OA Network, both the researcher and IR operator communities will be involved in the refining of the service infrastructure. These engagements are to result in a higher acceptance of the OA Network as well as acceptance of OA publishing at large. On the other hand, increasing awareness of Open Access, in general, and the essential conditions for Institutional Repositories, in particular, are crucial issues that need to be dealt with on a strategic level. Thus, a special interest group on Institutional Repositories is about to be established within the German Library Association (dbv), complementing the technological and operational aspects of Open Access publishing and network building. As described above, the OA Network has developed an infrastructure and is providing services for both end users and third party service providers. For obvious reasons, sustainability is an important issue, since the development is being conducted by a project group and external funding will eventually cease. In order to ensure the long-term availability of the services, as well as the maintenance of the base technology, the project is closely incorporated into the partners' institutions. Technically, further on the system will be hosted at Humboldt University's Computer and Media Service. Moreover, at the end of the project, an organizational model will be completed facilitating the OA Network platform to continue. Following current practice, DINI will be the coordinating frame for the activities resulting from the OA Network developments. 6 ConclusionBy developing and operating the OA Network thus far, we have shown the functional efficiency of a comprehensive Open Access infrastructure in Germany. The open service architecture, built as a distributed framework, constitutes the basis for both a national showcase that demonstrates the added value of Open Access publishing and a data provider that exposes aggregated and enriched data to other service networks. Thereby, the OA Network essentially advances the visibility of publications made available via Institutional Repositories. Clearly, the OA Network is not an end in itself. It is integrated in the international Open Access infrastructure, being first and foremost the national aggregator node for the European DRIVER (Digital Repository Infrastructure Vision for European Research) platform.15 OA Network not only recognizes its mission with regard to technical development. It also seeks to increase acceptance of OA publishing among researchers and librarians. To this end, the project group aims at strengthening the community of repository operators and at raising awareness of green Open Access among all relevant stakeholders. We are confident that an efficient and easy to use integrative Open Access platform, enhanced by beneficial value-added services, will serve as a convincing argument in this direction. 7 Notes1. "The 'green road' of Open Access (OA) self-archiving is where authors provide open access to their own published articles, by making their own eprints free for all." For more information see <http://www.eprints.org/openaccess/>. 2. E.g., OpenDOAR (Open Directory of Open Access Repositories, <http://www.opendoar.org/>), ROAR (Registry of Open Access Repositories, <http://roar.eprints.org/>), and DINI (German Initiative for Network Information, <http://www.dini.de/wiss-publizieren/repository>). 3. See <http://www.openarchives.org/>. 4. See <http://www.dini.de/projekte/oa-netzwerk/>. 5. Google Scholar, <http://scholar.google.com/>. 6. BASE, Bielefeld Academic Search Engine, <http://www.base-search.net/index.php?l=en>. 7. OAIster, <http://www.oaister.org/>. 8. REST, <http://en.wikipedia.org/wiki/Representational_State_Transfer>. 9. SOAP, <http://www.w3.org/TR/soap/>. 10. .NET, <http://www.microsoft.com/NET/>. 11. PHP, <http://www.php.net/>. 12. In reality, the domain names would be phrased as DDC subject headings, of course, transforming "... Feld IN physics ..." into "... Feld IN DDC LIKE 53% ...", etc. 13. DOARC is an acronym for "Distributed Open Access Reference Citation Services". 14. See <http://open-access.net/de_en/homepage/>. 15. European DRIVER platform <http://www.driver-repository.eu/Driver-About/About-DRIVER.html>. 8 References1. Lynch, C.A.: Institutional repositories: essential infrastructure for scholarship in the digital age. ARL Bimonthly Report 226 (2003) <doi:10.1353/pla.2003.0039>. 2. DINI Working Group "Electronic Publishing": DINI-Certificate Document and Publication Services 2007, <http://edoc.hu-berlin.de/series/dini-schriften/2006-3-en/PDF/3-en.pdf> (2006). 3. Davis, P.M., Connolly, M.J.L.: Institutional Repositories: Evaluating the Reasons for Non-use of Cornell University's Installation of DSpace. D-Lib Magazine 13 (3/4) <doi:10.1045/march2007-davis> (2007). 4. Palmer, C.C., Teffeau L.C., Newton, M.P.: Identifying Factors of Success in CIC Institutional Repository Development – Final Report. Center for Informatics Research in Science and Scholarship, University of Illinois at Urbana-Champaign (2008) <https://www.ideals.uiuc.edu/handle/2142/8981>. 5. Berlin Declaration on Open Access to Knowledge in the Sciences and Humanities, <http://www.zim.mpg.de/openaccess-berlin/berlindeclaration.html> (2003). 6. DINI Working Group OAI in Germany: Electronic Publishing in Higher Education: How to design OAI interfaces, <http://edoc.hu-berlin.de/series/dini-schriften/2-en/PDF/2-en.pdf> (2003). 7. Henzinger, M.: Finding near-duplicate web pages: a large-scale evaluation of algorithms, Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval, Seattle, Washington, pp. 284-291. (2006) <doi:10.1145/1148170.1148222>. Copyright © 2009 Uwe Müller, Thomas Severiens, Robin Malitz, and Peter Schirmbacher |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/september2009-mueller
|