D-Lib Magazine
November/December 2016
Volume 22, Number 11/12
Table of Contents
Intake of Digital Content: Survey Results From the Field
Jody L. DeRidder and Alissa Matheny Helms
University of Alabama Libraries
{jlderidder, amhelms}@ua.edu
DOI: 10.1045/november2016-deridder
Printer-friendly Version
Abstract
The authors developed and administered a survey to collect information on how cultural heritage institutions are currently managing the incoming flood of digital materials. The focus of the survey was the selection of tools, workflows, policies, and recommendations from identification and selection of content through processing and providing access. Results are compared with similar surveys, and a comprehensive overview of the current state of research in the field is provided, with links to helpful resources. It appears that processes, workflows, and policies are still very much in development across multiple institutions, and the development of best practices for intake and management is still in its infancy. In order to build upon the guidance collected in the survey, the authors are seeking to engage the community in developing an evolving community resource of guidelines to assist professionals in the field in facing the challenges of intake and management of incoming digital content.
1 Introduction
Digital materials pouring into special collections and archives present new and complex challenges for archivists, librarians, and records managers. As new records of our unfolding history are almost completely in digital form at this point, many cultural heritage institutions are struggling to develop and institute practical policies and procedures for the intake, selection, processing, and access of digital content. Particularly when faced with intake of multi-terabyte hard drives of mixed content, archivists may be overwhelmed with how to even begin to sort, identify, and select content from a device. Even the choice of tools can be overwhelming; for example, the Community Owned Digital Preservation Tool Registry currently lists 415 tools.1 In order to sift through the possible options more effectively before setting up local policies and procedures, we developed a survey (see Appendix I) to uncover what experienced digital archivists would recommend. The focus of the survey was on the selection of practical tools, the development of productive workflows, and recommendations.
2 Literature Review
2.1 Books
The continual change in the field virtually precludes the inclusion of detailed recommendations in published books, which instead usually focus on overviews and thematic approaches. In 2001, Lazinger provided an excellent overview of many of the issues involved in selection and preservation of electronic documents, supplemented by a then extensive compilation of existing archives and digitization centers for more information.2 While providing a useful overview of the current field of digital preservation and known standards, the recent tome by Corrado and Moulaison fails to cover practical tools and workflows for those in the field.3 Sabharwal's 2015 publication4 extends the overview to include various forms of social media, and builds on the DCC Curation LifeCycle,5 which provides a more complete overview of all aspects of digital preservation. While these books provide an excellent review of issues and sometimes recommendations for what should be done, they do not try to address how to actually perform the work. More useful from an implementation perspective is the somewhat dated 2010 manual by Ross Harvey, which recommends specific tools, websites and tutorials.6 Also in 2010, a CLIR publication provided an in-depth review of the challenges and issues in intake and management of born-digital content, with a clear focus on the digital forensics aspects and rights issues.7 For current information about tools and resources, the online Digital Preservation Coalition Handbook8 is an excellent reference, which closely aligns with the purpose of our study, as it includes some information about what other institutions are doing (as case studies, primarily conducted in Europe). Many of the resources referenced by this handbook are best maintained online, such as a crowdsourcing effort which seeks to document all existing file formats,9 and an active site for questions and answers on digital preservation.10
2.2 Articles, White Papers and Reports
Articles published in the past few years range from specific tool coverage and case studies to broad reviews of the challenges faced by librarians, archivists and records managers.
Specific tools covered in depth by articles include BitCurator,11 a custom Word plug-in for substituting fonts,12 a custom Python script for transferring digital content across NTFS systems and collecting some data,13 AutoHotkey (automation in Windows) and Selenium IDE (for metadata work in Firefox),14 and guidance for small-scale web archiving (on Macs) with SiteSucker, TimeMachine and FileMerge.15 One fascinating case study on the use of Forensic Toolkit software for capture and processing of floppy disks, Zip disks, and CDs may be very useful for archivists faced with such media.16 Another case study described a low-cost exploration into building access to old media on newer equipment, for the digital forensics and extraction of obsolete formats.17 In 2013, the IMLS-funded Digital POWRR group organized almost seventy tools into categories based on the digital curation lifecycle and documented their functionality.18 A full discussion of their findings, and recommendations based on level of financial resources, are available online in a white paper.19
Some articles focus on case studies for collecting and archiving specific types of content, such as tweets,20 digital images,21 a Web collection of fugitive literature,22 catalogues raisonnés,23 videos from DVDs,24 and institutional records.25 26 Other case studies focus in depth on particular issues, such as the risks of data migration for certain formats27, or appraisal of electronic records in national archives.28 One unusual approach to developing a framework for appraisal and selection of digital content was based on statistical sampling, risk analysis and appraisal;29 unfortunately the effectiveness of this approach is not evaluated. However, the criteria for selection are quite useful as guidelines: mission alignment, value of the resources, cost and feasibility.30
In 2015, the University of Minnesota Electronic Task Force published a public report of their initial efforts to develop capacity in the Libraries to preserve and provide access to electronic resources.31 In their effort to develop initial policies and procedures for ingest, they realized that tools often worked differently with different file types, and "each collection brings with it the possibility of a new ingest scenario".32 Because of the inconsistencies in how various tools worked, they developed step-by-step guides for over 20 tools or processes; while they did not include these in the report, they did provide an overview and general guidelines. An interesting note from a survey of the University of Minnesota library staff is that email attachments were increasingly a source of concern for collections content.33
After developing initial guidelines, roles, documentation and steps for ingest, the Minnesota task force summarized:
"A sound ingest process requires understanding the original storage media, determining the method of transfer best suited to the media and file types, having a secure storage location within the Libraries, and running multiple programs against source and destination records for quality control and to establish a preservation baseline."34
Prior to the final report, staff managed to ingest 13 accessions (over 24 GB), but the problem of determining what to keep created a bottleneck in the workflows, to be addressed in the future.35 Based on their limited experiences, they estimate an average time of 12 GB/hour for initial ingest only, with an additional seven hours per collection.36
In contrast to the University of Minnesota case study, a recent article by a lone arranger outlines her explorations in ingest of small quantities of digital content; she highlights the critical importance of appraisal, and notes that outsourcing these efforts requires funding that simply isn't available.37
Focusing on access methodology, one article offered up a method of providing web browse access to disk images, to simplify the questions of selection, management of collected content, and access, putting the burden on the user of whether to seek emulation or migration for improved usability.38 An extensive comparison of several repository systems in terms of suitability for visual research data (extendable to other data) was published in 2013.39 A more recent article combined three case studies about how to emulate and a brief discussion of the pros and cons of emulation as a service delivered over the web.40
Theoretical discussions also abound, such as Xie's analysis of the concept "reproducibility" as used in digital forensics for the purpose of digital records management.41
In 2011, Goldman urged archivists and records managers to begin to take initial steps towards appropriate management of digital content, regardless of limitations and seemingly insurmountable odds.42 In 2012 and 2013, OCLC Research provided a series of useful reports echoing Goldman's article, in an effort to assist archivists in taking the difficult first steps to effectively manage born digital content.43 In the widely acclaimed initial report, Erway provided basic principles and instructions for surveying and inventorying born-digital content, as well as basic steps for extracting digital content from readable media.44 A following report expanded on these basic steps and provided links to suggested tools, software, and resources that could provide in-depth discussions and further options.45
In 2012, the AIMS Project report stated that "the development of best practices within born-digital stewardship was not yet possible," so they sought to define good practices instead.46 Their inter-institutional framework was organized into four "Functions of Stewardship" (each with objectives, outcomes, decision points and tasks): collection development, accessioning, arrangement and description, and discovery and access.47 Critical considerations were clearly stated, such as "A determination is made as to whether the collection can be reasonably acquired, managed, and preserved within the constraints of the institution's resources."48 One of the points made in this report is perhaps key to developing best practices: each type of born digital content transfer has different implications that will likely lead to different workflows.49 The AIMS report was intentionally software-agnostic, though it included appendices with detailed case studies50 and tool reviews.51 A major outcome of this project was the draft of functional requirements for a tool to support arrangement and description of born-digital materials,52 though the resulting Hypatia project shows no signs of activity since 2013.53
Challenges faced by under-resourced institutions are eloquently described in a 2013 OCLC article.54 A recent broad overview of the current challenges of digital preservation observes that the field is developing swiftly, and that a danger to be avoided is being drawn into a preservation path that may not be critical, such as file format migration for open formats.55 Disturbingly, in the results of a survey of faculty at five Digital POWRR56 project partner institutions, 55.3% of respondents have lost irreplaceable work-related digital content, and 62.5% have obsolete digital content they likely can no longer access.57 The need for effective digital curation is pressing.
2.3 Surveys
A 2009 OCLC survey identified born-digital materials as one of the top three "most challenging issues" in managing special collections (the others were digitization and space), and stated that "management of born digital archival materials is still in its infancy."58 Yet 79% of respondents had collected born-digital materials.59 This survey covered a variety of aspects of special collections and archives content and management, but did not attempt to identify tools and workflows, target formats or useful methods and recommendations for born digital materials.
In 2012, an extensive survey of 64 of the 126 ARL libraries captured a snapshot of the tools, workflows, and policies used by special collections and archives to process, manage and provide access to born digital materials.60 This survey covered staffing, storage solutions, influences, and training as well as several of the areas covered in the survey described in this article. As the results of the current survey differed in several respects for some very similar questions, a comparison of these results will be included in the results discussion.
Also in 2012, a survey of training needs in digital preservation found that the three most needed topics were "Methods of preservation metadata extraction, creation and storage" (70.3%), "Determining what metadata to capture and store" (68%), and "Planning for provision of access over time" (65.4%).61 The current survey may provide some guidance with regard to each of these.
In 2013, the Smithsonian Institute surveyed seven of their archival units about their born digital holdings.62 They counted over 12,000 pieces of physical media, the majority of which were CDs,63 but their survey did not ask whether the holders were capable of extracting content from their media. Their holdings also may or may not be representative of those in other cultural heritage institutions.
Mayer has performed a survey annually to assess the status of born-digital preservation only in Canadian archives;64 the results of the 2013 and 2014 surveys indicate a great deal of confusion about what holdings actually existed in each repository, and a good bit of uncertainty as to how they were actually managed.65 At this writing, the 2015 results are not yet available.66
At the end of 2014 and the beginning of 2015, another survey by UNESCO67 gathered information from members of 27 organizations (seven archives, twelve libraries, two museums, and six heritage organizations) to determine world-wide trends in selection of born digital heritage collections. The results of this survey were very general and varied, indicating that determining significance of content is key to selection, and clarifying that the field was still in its infancy.68
2.4 In Context
Despite the excellent coverage of the issues and an expansive range of possible tools, none of the existing publications provide a clear and current overview of what a broad selection of cultural heritage peers are doing in the field: what works, what doesn't, and the choices they have made. When faced with almost any decision on setting policy in the field of digital librarianship, a review of what peers have implemented and an understanding of the pros and cons of their approaches can provide invaluable guidance. No one wants to repeat others' errors, and building upon existing practical experience is always ideal. While several institutions do provide some of this information either in reports, articles, or on their websites, our survey was intended as an approach that would gather information in a form which would allow us to compare responses across a targeted set of questions. Where the other surveys noted address similar issues, a comparison will be made in the results discussion.
3 Approach
We reviewed the questions used by the surveys mentioned above, and adapted some of them for our survey while adding others that would provide us with detailed clarification about format selection, tools and workflows. The 20-question survey (see Appendix I) was divided into six sections: Materials & Content, Workflows, Content Management, Preservation Metadata, Access, and Recommendations. The Workflows section, which contained primarily open ended questions, was divided by stages: Identification, Analysis, Selection, and Processing. To allow participants to review the questions prior to taking the survey, the survey was saved to PDF form and posted online, and a link to this PDF was included in the announcements.
The month-long survey was announced in mid-May (and again in early June) 2016 to four Society of American Archivist listserves: Metadata and Digital Objects Roundtable, Electronic Records Section, Research Libraries and Archives & Archivists. Other listserves included Code4Lib, Digital-curation Google group, Digital Library Federation, Diglib and the American Library Association Library Information Technology Association (LITA).
4 Results
4.1 Participants
Half of the 62 respondents were from academic libraries (31); 12.9% (8) were from archives and the same number from government organizations; 4.84% (3) from museums, 3.23% (2) from public libraries, 1.61% (1 each) from a historical library and a special library. Eight respondents (12.9%) identified their institution as "other": institutional religious archives, national library, public media organization, radio and television, museum and library, technical company, academic archives and arts & education.
Our survey allowed for free-text description of roles, but over half (58.07%) self-identified as some sort of archivist or curator (36 of 62), 43% (27) of them as having a digital role. 22.58% (14) identified as having a managerial role. Additionally, 17.74% (11) self-identified as a type of librarian, 11.29% (7) of which mentioned digital in the title, one who was also an archivist (not counted above) and one metadata librarian. One respondent did not identify a role.
4.2 Types of Media
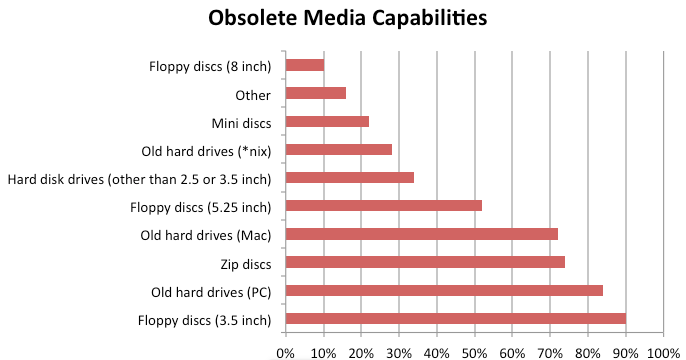
Of the 50 who responded to the question about what obsolete media they could effectively manage, 90% (45) are prepared to obtain content from 3.5 inch floppy discs, 84% (42) from PC hard drives, and 72% (37) from Mac hard drives. Over half (52%, 26) can extract content from 5.25 inch floppy disks, but only 10% (6) can work with 8-inch floppy disks. Varieties of Unix/Linux hard drives are only manageable by 28% (14) of the respondents, and hard disk drives that are not 2.5 or 3.5 inches can only be managed effectively by 34% (17) respondents. Furthermore, 74% (37) can extract from zip discs, and 22% (11) of the respondents are prepared to extract content form mini discs.
Of the other types of media that respondents can extract content from, 3 respondents mentioned media that is not yet obsolete: CDs/DVDs and thumb drives (1 mention). Of those which are becoming obsolete, 2 mention video cassettes, computer magnetic tapes/LTO, and flash media (SD cards). Two respondents also mention Jaz disks; and 1 each mention audio cassettes, reels, Syquest cartridges, DAT (Digital Audio Tape) and DDS (Digital Data Storage).
By comparison, the types of physical media (over 12,000 pieces) identified in the Smithsonian survey included:
- 33% CD
- 17% DATs
- 16% 3.5" diskette
- 14% 5.25" floppy diskette
- 12% DVD
- 7% other (excluding other data cartridges)
- 1% ZIP data cartridge69
There was no indication in the Smithsonian survey as to whether access to the media was yet supported. At the time of the survey, the expectation was that future Smithsonian acquisitions would likely include a large percentage of digital images, digital video, and computer aided design (CAD) files.70 Floppy disks, hard drives and zip disks were far more prevalent in our current survey than in the Smithsonian one.
4.3 Types of Content
Of our 62 respondents, all of them are collecting digital text documents, and 95% (59) are collecting still images; 92% (57) are collecting audio recordings and 90% (56) are collecting moving images/videos. Over half are collecting websites (55%, or 34) and databases (53%, or 33); 42% (26) are collecting email; 27% (17) are collecting Geographical Information Systems (GIS) data, and 26% (16) are collecting executable files (software). Other types of content mentioned include data sets (2 respondents), 3D models and computer-aided design, research data in all formats, books and ephemera, and other project files. In addition, academic libraries collect the most types of content: 75% (9 of 12) institutions collect 8-10 types of media.
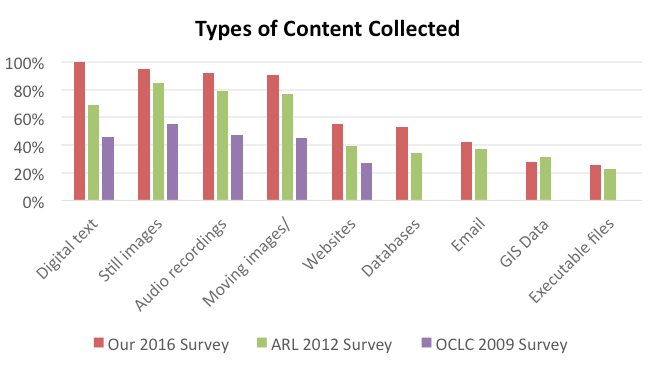
By comparison, in the 2012 ARL survey (which also had 62 respondents), all the percentages except GIS were lower, indicating a likely increase over the years; and the relative ranking among them was very similar. Only 69% (43) were collecting digital text; 85% (53) still images; 79% (49) audio, 68% (42) moving images and 77% (48) videos.71 Institutional websites were collected by 39% (24), other websites by 29% (18); databases by 34% (21), email by 37% (23); GIS by 31% (19); and executables by 23% (14).72
In the 2009 OCLC survey, the percentages were even lower:
- 55% photographs
- 47% audio
- 46% institutional archival records
- 45% video
- 44% other archives and manuscripts
- 36% publications and reports
- 27% web sites
- 15% serials
- 11% data sets73
Some of these categories differ from those gathered in our survey, but digital text has clearly increased in importance, and every corresponding category was gathered by a much larger percentage of our respondents.
We also asked what types of content respondent institutions did not collect. Email was the type least collected (48%, or 13 of 27 respondents), followed by executable files (30%, or 8). Websites and GIS data followed at 19% (5) and then databases at 15% (4). The highest numbers in this category correspond to the lowest numbers for the previous types of content collected question. Interestingly, social media content was avoided by only 1 respondent (4%), though it was not mentioned in the comments of the earlier question by any respondents as a genre commonly collected.
4.4 Target Formats
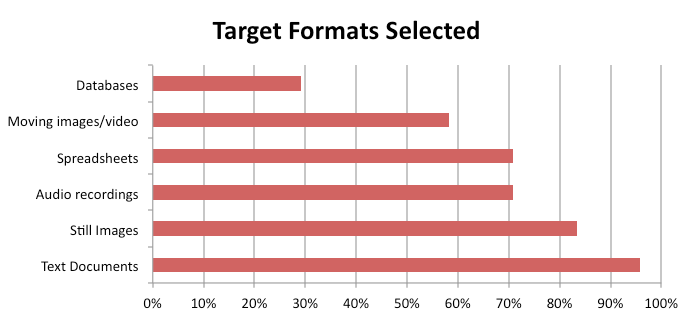
Of our total survey participants, 38.7% (24) answered the question about target file formats. Of those, 95.83% (23) provided information about text documents, 83.33% (20) about still images, 70.83% (17) about audio and spreadsheets, 58.33% (14) about video/moving images and only 29.17% (7) about databases. This may indicate that few in the field are tackling this difficult task.
Some comments clarified that certain formats were preferred, and other comments indicated that some target formats were for access only. One respondent qualified each entry by stating that their collection policies do not allow them to request specific formats, but then went on to identify which formats they strive to collect. In the "other" comments were an entry about MBOX for email and another about WordPress blog files for which appropriate formats had not yet been selected. A third "other" comment was: "We don't have target formats, we would only migrate through a rigorous format migration process inside our preservation system."
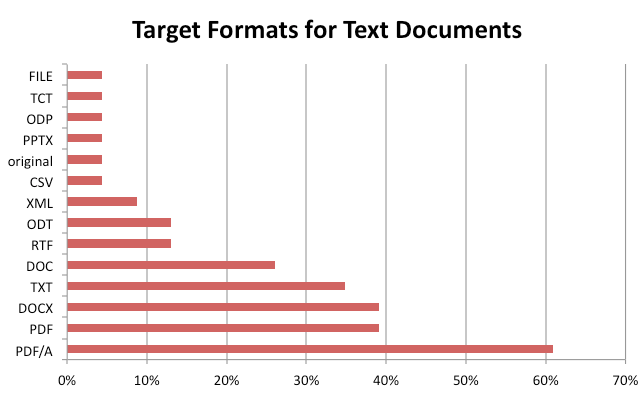
PDF/A was the clear leader for text documents, selected by 60.87% (14 of 23) as a target format. PDF and DOCX each came in at 39.13% (9), TXT at 34.78%, DOC at 26.09% (6), RTF and ODT at 13.04% (3), XML at 8.7% (2), and each of the following formats were selected by 1 respondent (4.35%): PPTX, ODP, TCT (TurboCAD drawings), FILE (openable with Microsoft Word in compatibility mode), and the original.
For still images, TIFF took the lead at 95% (19 of 20), followed by JPEG (45%, 9; 1 of these specified this is for access only); 20% (4) selected JPEG 2000; 15% (3) selected PNG; SVG and GIF were each selected by 10% (2), and JFIF, DNG and the original format were selected by 5% (1 person each).
WAV files are still the predominant archival target format for audio, selected by 70.59% (12 of 17); MP3 follows at 47.06% (8, though 2 respondents clarified these were just for access). AIFF and the original were each selected by 11.76% (2), and the following were selected by 5.88% (1): MIDI, WMA, MPEG-4 audio, FLAC, OGG, and RealAudio.
CSV is the preferred target format for spreadsheets (70.59%, 12 of 17 responses); only 29.41% (5) selected XLSX, 23.53% (4) selected TXT (1 specified ASCII); 17.65% (3) selected ODS, 11.76% (2) each selected PDF/A and the original, and XLS, TSV, and XML came in last at 5.88% each (1).
Of the 14 responders on moving images/video target file types, 57.14% (8) selected MPEG-4 encoding; 21.43% (3) selected MPEG-2 encoding and AVI and MOV containers; 14.29% (2) selected FFV1 encoding with Matroska containers (1 of these specified LPCM audio encoding); 14.29% also selected Motion JPEG 2000 (1 with MXF), MPEG encoding, and whatever form the original is in; and 7.14% (1 each) identified OGG, MFX wrapper, Digital Video file, and WMV.
Very few seem to be tackling databases. Of the 7 useful responses, 42.86% (3) selected CSV, TXT (1 ASCII), or the original format; 14.29% (1 each) selected SIARD text with DDL, ACCDB (Access Database 2007), DBF, MDB (Access Database 2003 and earlier), MS Access (unspecified years), XML, PDF/A and EBCDIC.
4.5 Content Identification
One of the first tasks when faced with incoming digital content is to examine what is there in order to build an inventory, identify duplicate files, and assess what types of material are present.
A wide range of tools were specified by 31 respondents as useful in identification of content, with Forensic Toolkit and BitCurator in the lead (29%, 9 and 26%, 8 respectively). In-house scripts and TreeSize were recommended by 16% (5); spreadsheets and DROID by 13% (4); QuickView Plus and Karen's Directory Printer by 10% (3); and 6% (2 each) recommended FITS, Data Accessioner, JHOVE, Exiftool and WinDirStat. Mentioned by 3% (1) were Total Commander, Vireo and Siegfried & Brunnhilde.
In describing workflows used for the identification of content, 24 of 34 participants (70.6%) indicated that they image disks of physical media, 2 specifying that they assess the image to determine if the entire image or only individual files are necessary for preservation. Creation of a file inventory was detailed by 35.3% (12); creation of an accession record or some other kind of reference record using metadata by 29.4% (10); extraction and transfer of files by 26.5% (9); and recognizing duplicate files by 14.7% (5). Surprisingly, few respondents described security and validation procedures in this stage of ingest: only 4 respondents mentioned write blocking media, only 2 said they generate file checksums or establish fixity, and just 1 mentioned performing a virus check of files. Of the total answers, 41.2% (14) indicated specific tools used to perform steps in the workflow — FTK (7), BitCurator (3), Data Accessioner (3), FITS (2) — and 11.8% (4) referenced in-house scripts.
In the 2013 Digital POWRR white paper, Data Accessioner was recommended for triage, to be used by institutions with no funding support.74 Three of our respondents found Data Accessioner to be useful in the identification workflows.
4.6 Content Analysis
After identification and building an inventory, some analysis of the content usually must precede selection by curators. This may include locating (and associating) all the versions of any particular file, documentation of where groups of file types are found, documenting sets of files and file structures that together comprise a single item (such as a database or software system), documenting which files are system files or known common software, documenting which files contain social security numbers, phone numbers and other potential privacy issues, how many of which file types are found, and more.
For analysis, spreadsheets and BitCurator were considered useful tools by 25% of the 24 respondents who answered this question. DROID and Forensic Toolkit were specified by 21% (5); bulk_extractor by 17% (4), and the following tools were listed as useful by 8% (2) each: IdentityFinder, Siegfried, TreeSize and Karen's Directory Printer.
Workflows for content analysis were explained by 16 participants, 7 (43.8%) of which include manual content analysis of some sort, while 2 stipulated that an archivist or specialist reviews content. Twenty-five percent (4) pinpointed personally identifiable information (PII) and used report and/or analysis functions of tools in this stage. Determining file type or format and the identification of normalization or migration targets each account for 18.8% (3) of answers. Checksum generation or fixity establishment, backup copying of files, and generating a directory tree or structure each appear in 12.5% (2) of responses. Additionally, 3 respondents stated that their workflow for content analysis is still in development.
4.7 Content Selection
Once initial analysis takes place, the difficult task of selection begins. This may include determining which of multiple versions of a file are the one(s) of interest; it may include isolating files of particular types which the donor has specified; and it may require sorting through many types of files in many directories. It's a daunting task for a large set of incoming content. Often during this stage some descriptive metadata is generated or collected to specify why particular files or directories should be retained.
When asked for the most useful tools for selection of digital content, 27% (4 of 15 respondents) used manual review. Collection policy and Forensic Toolkit (FTK) were listed by 20% each (3). Retention schedules, tools to locate personally identifiable information, and simple knowledge of collections were each specified as useful by 13% (2).
When asked whether collection policies at the host institution allow the respondent to select content to be preserved, 45.16% (28) of the 62 respondents did not answer. Of the remainder, 29.03% (18) answered "yes," 14.52% (9) selected "sometimes/under certain circumstances" and 11.29% (7) answered "no".
Details on workflows for content selection were provided by 14 respondents, and 35.7% (5) stated that selection was guided by donor agreements. Another 35.7% (5) indicated that selection is manual at their institutions (with 2 remarking that archivists perform selection), and policy and collection needs guided 21.4% (3) of respondents' selection activities. Content restrictions and excluding personally identifiable information (PII), creating a records schedule, and file transfer to external storage each account for 14.3% (2) of the answers for this workflow. It is worth noting that workflows for the middle two phases of ingest, content analysis and selection, require the most manual analysis work (both representing the greatest percentage of answers as opposed to less than 10% of answers for identification and processing), making these workflows the most subjective and least likely to be automated.
4.8 Content Extraction
When asked "do you preserve the original files (not on the original media)?" over half (51.61%, 32) of the 62 participants did not respond. Of those who did respond, 83.33% (25) said "yes;" and 16.67% (5) selected "sometimes/under certain circumstances." There were no negative responses. By comparison, in the 2012 ARL survey, only 77% (49) were ingesting records from legacy media.75 However, of our total number of survey participants, only 40% answered yes to this question, and only half of our survey respondents were from academic libraries. We contend that it is likely that academic research libraries are better equipped to ingest born digital content from a variety of legacy media.
When asked "do you migrate (or normalize) files?" again, over half (53.23%, 33) of our participants failed to respond. Of those who did answer the question, 48.28% (14) said "yes;" 41.38% (12) selected "sometimes/under certain circumstances;" and 10.34% (3) said "no." Only 2 respondents support emulation (1 in house); 36 respondents failed to answer this question, and 24 said "no." In the 2012 ARL survey, 8 of 57 respondents (14%) were actively building emulation systems, but only 1 out of 64 were providing access via emulation.76 Of our respondents, the only one who supports emulation in house qualified the response with: "Currently only in selective cases and mostly just for staff use, but we would like to expand use of emulation as an access method for end users (particularly for obsolete CAD and 3D modeling formats for which migration strategies are not particularly effective)."
4.9 Processing
The ultimate goal of processing is to make digital content accessible for both current and future users. A number of processing activities may occur to provide access points with current technology and to preserve digital content across generations of technology, including content migration, data normalization, and emulation implementation.
For processing, Archivematica was identified as useful by 23% (5) of the 22 respondents; Forensic Toolkit and Acrobat Pro followed at 18% (4). Spreadsheets, in-house software/scripts and Handbrake came in at 14% (3); Bulk Rename Utility, Microsoft Word and ffmeg at 9% (2). One respondent (5%) said Preservica is useful for processing.
Of the 16 participants who described their workflows for processing, the most (43.8%, or 7) stated that they transfer files to a repository or external storage in this phase. Normalization or migration of files takes place for 37.5% (6) respondents; creation of access copies 25% (4); and 18.8% (3) said the workflow for processing is still in development. Metadata generation or creation were specified by 31.3% (5). It is notable that this function only occurs in the first and last of our specified workflow phases: content identification and processing.
The 2013 Digital POWRR white paper recommended that institutions with some resources but no ability to add technical personnel use Preservica for processing; for institutions with technical staff who are able to take on extra work, Archivematica was recommended.77 Interestingly, only 1 of our respondents used Preservica, but 5 used Archivematica. This may indicate that the respondents to our survey had technical staff available for the additional work.
4.10 Metadata
Only 43.55% (27) of the 62 respondents answered the question about what types of technical metadata they capture. Of these, 92.59% (25) collect file date(s) and types, 88.89% (24) collect file sizes, and 85.19% (23) collect checksums. Original directory locations and file type versions were collected by 70.37% (19), creating software (and version) by 55.56% (15), associated files and structure of document by 40.74% (11), and only 29.63% (8) document the operating system type from which the files come. Endianness and appropriate technical standards based on file type (such as MIX and AES57) are only documented by 14.81% (4) of the respondents who answered this question.
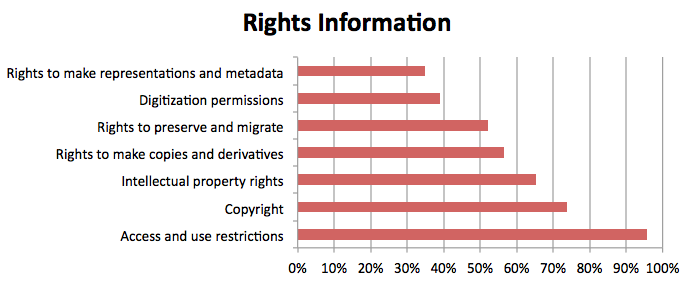
Of the 23 responders to the question about what rights information they collect, 95.65% (22) collect access and use restrictions, 73.91% (17) collect copyright information, and 65.22% (15) collect intellectual property rights information. Over half document the rights to make copies and derivatives (56.52%, 13) and to obtain the rights to preserve and migrate content (52.17%, 12); 39.13% (9) obtain digitization permissions, and 34.78% (8) collect the rights to make representations and metadata. One of the respondents qualified the above by stating that "These questions are addressed at a high level for accessions as a whole, but rarely at a more granular level." Three of the participants who did not collect any of this information added explanations:
- None [is collected] as the content belongs to the archives' mother organization
- All of our content is in the public domain (government publications)
- All our records are internal/institutional records so we own copyright
By comparison, the ARL survey did not specifically ask about what rights information is collected; instead their survey asked about whether a variety of rights-related issues was addressed by ingest policies or procedures. The most commonly addressed issue when setting policies was whether to retain or destroy personally identifiable information (PII), 71% (30 of 42 respondents); second was whether to preserve copyrighted content (48%, or 20 of 42).78
Other types of administrative metadata that our respondents collected included repository-generated information, provenance and donor information, acquisition/accession information, disposition, and notes of actions taken.
4.11 Organizing/Tracking
It is notable that 53% (10 of 19) of our respondents use spreadsheets as one of their primary tools to organize and track content; this seems to indicate that the processes are not advanced and embedded enough to have been transferred to databases or systems. Content management systems were listed by 26% (5) of the respondents, including ArchivesSpace (2), DSpace(1) and Omeka (1); 16% (3) used accession records, labels, databases or organization by collection and date to track content. Labeling tools mentioned included Forensic Toolkit and ePadd. Other tools mentioned included Bagit, Photo Mechanic, TreeSize Professional Reports, and Archivematica.
4.12 Providing Access
By far, the most common method of tracking rights information among our participants (77%, or 10 of 13 respondents) is to embed it in the metadata, whether that is the finding aid, an item-level description, or a catalog record. A single respondent tracks rights information only in a spreadsheet, and another only in an in-house database, and a third only in the deed of gift. Some respondents selected multiple tracking mechanisms, as was the case with the 2 respondents who mentioned accession records.
Of the 16 respondents who shared how they use rights information to control access, 44% (7) use manual processes, 31% (5) control access via the delivery system; 13% (2) simply do not, though 1 of them openly shares the rights metadata; 1 respondent just limits all access to in-house use, and 1 determines access based on user group (student or faculty member).
In the ARL survey, only 13% (8 of 63) provided open access of all born-digital materials; 83% (52) restricted some of the content, and 5% (3) restricted use to certain categories of users.79
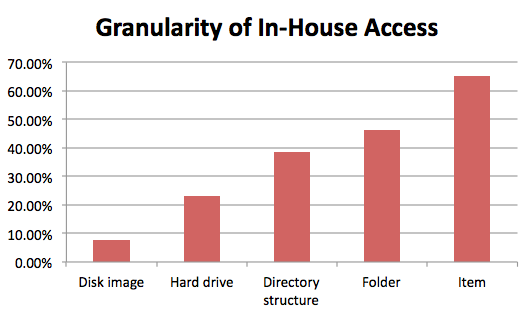
Less than half the survey participants answered the questions about the granularity with which access is provided to incoming digital content in-house (26 out of 62). Of those, 65.38% (17) provide access at the item level, 46.15% (12) at the folder level, 23.08% (6) at the hard drive level, and 7.69% (2) provide access to the disk image. One of the respondents adds that they are currently building capacity to provide access to disk images; a second respondent states they are only receiving single files from departments across campus, so they've not needed disk images. Two respondents clarify that in-house access is only available to staff, who then try to fulfill patron requests. A fifth respondent clarified that some database records are available for content search online; some can be identified and downloaded from an online catalog; and other records can be ordered on removable media. Another respondent added that for them, a folder is usually considered a "collection."
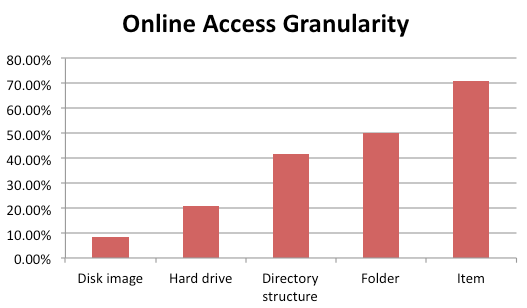
Online access to incoming digital content has very similar picture. Of the 62 respondents, only 24 answered this question. Of those, 70.83% (17) provide online access at the item level, 50% (12) at the folder level, 41.67% (10) provide the directory structure; 20.83% (5) provide online access to the hard drive, and 8.33% (2) provide online access to disk images. Six of the respondents do not provide online access to incoming digital (though 1 makes exceptions for web archives), and a seventh states that most are under copyright, and thus are not available online. Another respondent clarifies that some records are available for download, but others are only available for record-level search and retrieval. One very helpful comment was this one: "In both reading room and online, access is given based on rights determined. We have four levels: online, three concurrent users online (for published material only), reading room only, or by permission only. Items are arranged to various levels of specificity and then delivered based on those arrangement and descriptive levels."
By comparison, in the 2009 OCLC survey, 40% of the born-digital holdings are described in archival collections, 29% are cataloged, and 34% have no records80; yet 40% of respondents provide access to their born-digital content even if unprocessed.81 How that access is provided (online, in house, or by request) was not included in that survey.
In the 2012 ARL survey, 66% (42 of 64) provided online access to born-digital content via a digital repository system; 28% (18) via a third-party access & delivery system; 23% (15) via a file space; only 2% (1 respondent) provided online access via emulation.82 In-library access via a dedicated computer workstation was provided by 48% (31); 34% (22) using portable media and the user's personal computer; 2% (1) via emulation; and fully 20% (13) did not provide any access to born digital materials, either in-house or online.83
4.13 Participant Recommendations
When asked for general recommendations for other institutions that are just beginning to collect digital content, 25% (5 of 20) suggested developing policies and procedures first; 20% stated that planning, identifying target formats, selecting metadata and learning tools were critical. Documentation, connecting with professional communities, determining what works in your situation, and "just do it!" were mentioned by 15% (3); and 10% (2) focused on training & learning, making copies, using open source and starting small before attempting larger challenges.
5 Conclusions
This survey has clarified that processes, workflows, and policies are still very much in development across multiple institutions. Variations in the levels of resources and technical expertise may be accountable for much of the range exposed by this survey. The drop in respondents from the beginning of the survey (62) to the end (20) may indicate survey fatigue, but likely also reflects that many respondents may not yet have developed more than initial steps in content intake. While all 62 answered the question about what types of content they collect, only 24 answered the next question about target formats. The tools used for content identification were specified by 31 respondents; 24 answered questions about content analysis; but only 15 answered questions about selection. The number of respondents jumped to 22 for processing questions and 23 for rights information collected; however, only 13 answered how rights information is tracked, and of those, the primary method is to embed it in metadata. Only 26 of the 62 respondents spoke to granularity of in-house access, and 24 to online access. It is quite possible that over half of the survey respondents have not yet developed any policies or procedures for access to the collected digital content.
Still, some highlights are clear: the amount of digital content being collected is increasing, and the top target formats are TIFF, WAV, PDF/A, MPEG-4 and CSV or TXT. Few are able to extract content from older and more obscure media, and email and executable programs are the least collected content types. The top technical metadata collected are file dates, file type, size, and checksums. Analysis and selection are primarily manual processes, and spreadsheets are widely used to organize and track content. Forensic Toolkit and BitCurator are the lead tools for identification; and Archivematica, Forensic Toolkit and Adobe Acrobat Pro are most useful for processing.
Notably, most of the tools identified in our survey are open source. Similarly, in the 2012 ARL survey, 74% (31 of 42 respondents) use open source tools; 50% (21) stated they use commercial tools for digital processing; 43% (18) use home-grown tools, and 29% (12) use outsourced services such as Archive-It.84
Use of database calls to restrict online access based on rights and permissions is thus far a rarity. Access methods are still focused primarily on the item level, and few are engaged in emulation. It will be interesting to see how this changes as the flood of incoming digital content continues to grow, and the possibilities of emulation as an online service85 expand.
It seems clear that the development of best practices for the intake and management of digital content is still in its infancy. In the hopes that the information gathered will begin to lay the groundwork for the development of best practices and guidelines for others in the field, we are sharing the results of this survey widely, engaging practitioners in the field in multiple conference venues.86 Results from this survey have been used to seed a framework built on the AIMS87 methodology, and practitioners across archives, libraries, and special collections are invited to assist in building upon this online resource88, which was announced at the Digital Library Federation forum in November 2016. By sharing our experiences across the community, we can develop a living online resource of what works with what materials, and how best to manage the difficult challenges of the intake and curation of digital content.
References
| 1 |
Community Owned digital Preservation Tool Registry (COPTR), "Category:Tools". Last modified October 24, 2013. |
| 2 |
Susan Lazinger, Digital Preservation and Metadata: History, Theory and Practice (Englewood, CO: Libraries Unlimited, 2001). |
| 3 |
Edward M. Corrado and Heather Lea Moulaison, Digital Preservation for Libraries, Archives & Museums (Maryland: Rowman & Littlefield, 2014). |
| 4 |
Arjun Sabharwal, Digital Curation in the Digital Humanities: Preserving and promoting archival and special collections, Chandos Information Professional Series (Waltham, MA: Elsevier, 2015). |
| 5 |
Digital Curation Centre, "DCC Curation Lifecycle Model". Last modified 2016. |
| 6 |
Ross Harvey, Digital Curation: A How-To-Do-It Manual, How-To-Do-It Manuals: Number 170 (New York: Neal Schuman, 2010). |
| 7 |
Matthey G. Kirschenbaum, Richard Ovenden, Gabriella Redwine and Rachel Donahue, Digital Forensics and Born-Digital Content in Cultural Heritage Collections (Washington, DC: Council on Library and Information Resources, December 2010). |
| 8 |
Digital Preservation Coalition, "Digital Preservation Handbook" 2nd Edition. Last modified 2015. |
| 9 |
"Let's Solve the File Format Problem!". Last modified July 14, 2016. |
| 10 |
"Digital Preservation Q&A". Last modified June 23, 2016. |
| 11 |
Christopher A. Lee, Kam Woods, Matthew Kirschenbaum and Alexandra Cassanoff, "From Bitstreams to Heritage: Putting Digital Forensics into Practice in Collecting Institutions". BitCurator Project, September 30, 2013. |
| 12 |
Geoffrey Brown and Kam Woods, "Born Broken: Fonts and Information Loss in Legacy Digital Documents", The International Journal of Digital Curation,1:6 (2011). http://doi.org/10.2218/ijdc.v6i1.168 |
| 13 |
Gregory Wiedeman, "Practical Digital Forensics at Accession for Born-Digital Institutional Records", Code4Lib Journal 31 (2016-01-28). |
| 14 |
Andrew James Weidner and Daniel Gelaw Alemneh, "Workflow Tools for Digital Curation", Code4Lib Journal 20 (2013-04-17), |
| 15 |
Katharine Dunn and Nick Szydlowski, "Web Archiving for the Rest of Us: How to Collect and Manage Websites Using Free and Easy Software," Computers In Libraries 29:8 (September 2009), 12-18. |
| 16 |
Laura Wilsey, Rebecca Skirvin, Peter Chan and Glynn Edwards, "Capturing and Processing Born-Digital Files in the STOP AIDS Project Records: A Case Study", Journal of Western Archives 4:1 (2013), 1-22. |
| 17 |
John Durno and Jerry Trofimchuk, "Digital forensics on a shoestring: a case study from the University of Victoria", Code4Lib Journal 27 (2015-01-21). |
| 18 |
Digital POWRR, "Tool Grid". Last modified April 9, 2013. |
| 19 |
Jaime Schumacher, Lynne M. Thomas, and Drew VandeCreek, "From Theory to Action: 'Good Enough' Digital Preservation Solutions for Under-Resourced Cultural Heritage Institutions", August 2014. |
| 20 |
Timothy Arnold and Walker Sampson, "Preserving the Voices of Revolution: Examining the Creation and Preservation of a Subject-Centered Collection of Tweets from the Eighteen Days in Egypt", The American Archivist, 77:2 (Fall/Winter 2014), 510-533. http://doi.org/10.17723/aarc.77.2.794404552m67024n |
| 21 |
Amanda A. Hurford and Carolyn F. Runyon, "New Workflows for Born-Digital Assets", Computers in Libraries (January/February 2011), 6-40. |
| 22 |
Karen Schmidt, Wendy Allen Shelburne and David Steven Vess, "Approaches to Selection, Access, and Collection Development in the Web World: A Case Study with Fugitive Literature", Library Resources & Technical Services 52:3 (2008), 184-191. |
| 23 |
Sumitra Duncan, "Preserving born-digital catalogues raisonnés: Web archiving at the New York Art Resources Consortium (NYARC)", Art Libraries Journal, 40:2 (2015), 50-55. |
| 24 |
Laura Capell, "Building the Foundation: Creating an Electronic-Records Program at the University of Miami", Computers In Libraries (November 2015), 28-32. |
| 25 |
Joseph A. Williams and Elizabeth M. Berilla, "Minutes, Migration, and Migraines: Establishing a Digital Archives at a Small Institution", The American Archivist 78:1 (Spring/Summer2015), 84-95. http://doi.org/10.17723/0360-9081.78.1.84 |
| 26 |
Daniel Noonan and Tamar Chute, "Data Curation and the University Archives", The American Archivist 77:1 (Spring/Summer 2014), 201-240. http://doi.org/10.17723/aarc.77.1.m49r46526847g587 |
| 27 |
Chris Frisz, Geoffrey Brown and Samuel Waggoner, "Assessing Migration Risk for Scientific Data Formats", The International Journal of Digital Curation, 7:1 (2012), 27-38. http://doi.org/10.2218/ijdc.v7i1.212 |
| 28 |
Jinfang Niu, "Appraisal and Custody of Electronic Records: Findings from Four National Archives", Archival Issues 34:2 (2012). |
| 29 |
Jinfang Niu, "Appraisal and Selection for Digital Curation", International Journal of Digital Curation 9:2 (2014), 65-82. http://doi.org/10.2218/ijdc.v9i2.272 |
| 30 |
Ibid, 71-73. |
| 31 |
University of Minnesota Libraries, "Electronic Records Task Force Final Report". Last modified September 11, 2015. http://hdl.handle.net/11299/174097 |
| 32 |
Ibid, 19. |
| 33 |
Ibid, 27. |
| 34 |
Ibid, 4. |
| 35 |
Ibid, 20. |
| 36 |
Ibid, 25. |
| 37 |
Elizabeth Charlton, "Working with legacy media: A lone arranger's first steps", Practical Technology for Archives, 6 (June 2016). |
| 38 |
Sunitha Misra, Christopher A. Lee and Kam Woods, "A Web Service for File-Level Access to Disk Images", Code4Lib Journal 25 (2014-07-21). |
| 39 |
Leigh Garrett, Marie-Therese Gramstadt and Carlos Silva, "Here, KAPTUR This! Identifying and Selecting the Infrastructure Required to Support the Curation and Preservation of Visual Arts Research Data", The International Journal of Digital Curation 8:2 (2013), 68-88. http://doi.org/10.2218/ijdc.v8i2.273 |
| 40 |
Dianne Dietrich, Julia Kim, Morgan McKeehan, and Alison Rhonemus, "How to Party Like it's 1999: Emulation for Everyone", Code4Lib Journal 32 (2016-04-25). |
| 41 |
Sherry L. Xie, "Building Foundations for Digital Records Forensics: A Comparative Study of the Concept of Reproduction in Digital Records Management and Digital Forensics", The American Archivist, 74 (Fall/Winter 2011), 576-599. http://doi.org/10.17723/aarc.74.2.e088666710692t3k |
| 42 |
Ben Goldman, "Bridging the Gap: Taking Practical Steps Toward Managing Born-Digital Collections in Manuscript Repositories", RBM: A Journal of Rare Books, Manuscripts, and Cultural Heritage 12:8 (2011), 11-24. |
| 43 |
OCLC Research, "Demystifying Born Digital Reports". Last modified 2016. |
| 44 |
Ricky Erway, "You've Got to Walk Before You Can Run: First Steps for Managing Born-Digital Content Received on Physical Media", OCLC Research (2012). |
| 45 |
Julianna Barrera-Gomez and Ricky Erway, "Walk This Way: Detailed Steps for Transferring Born-Digital Content from Media You Can Read In-house", OCLC Research (2013). |
| 46 |
AIMS Work Group, "AIMS Born-Digital Collections: An Inter-Institutional Model for Stewardship", (2012). |
| 47 |
Ibid, 14. |
| 48 |
Ibid, 24. |
| 49 |
Ibid, 32. |
| 50 |
Ibid, 120-136. |
| 51 |
Ibid, 137-147. |
| 52 |
Ibid, 148-170. |
| 53 |
DuraSpace Project, "Hypatia". Last modified August 15, 2013. |
| 54 |
Amanda Kay Rinehart and Patrice-Andre Prud'homme, "Overwhelmed to action: digital preservation challenges at the under-resourced institution", OCLC Systems and Services 30:1 (2014), 28-42. http://doi.org/10.1108/OCLC-06-2013-0019 |
| 55 |
Bernadette Houghton, "Preservation Challenges in the Digital Age", D-Lib Magazine, 22:7/8 (July/August 2016). http://doi.org/10.1045/july2016-houghton |
| 56 |
Digital POWRR, "Preserving Digital Objects With Restricted Resources," last modified January 6, 2016. |
| 57 |
Jaime Schumacher and Drew VandeCreek, "Intellectual Capital at Risk: Data Management Practices and Data Loss by Faculty Members at Five American Universities", International Journal of Digital Curation, 10:2 (2015), 96-109. http://doi.org/10.2218/ijdc.v10i2.321 |
| 58 |
Jackie M. Dooley and Katherine Luce, "Taking Our Pulse: The OCLC Research Survey of Special Collections and Archives", OCLC Research. Last modified January 28, 2011. |
| 59 |
Ibid, 59. |
| 60 |
Naomi Nelson, Seth Shaw, Nancy Deromedi, Michael Shallcross, Cynthia Ghering, Lisa Schmidt, Michelle Belden, Jacki R. Esposito, Ben Goldman, and Tim Pyatt, "SPEC Kit 329: Managing Born-Digital Special Collections and Archival Materials" (Washington DC: Association of Research Libraries, 2012). |
| 61 |
Jody DeRidder, "First Aid Training for Those on the Front Lines: Digital Preservation Needs Survey Results 2012", Information Technology and Libraries (June 2013), 18-28. http://doi.org/10.6017/ital.v32i2.3123 |
| 62 |
Greg Palumbo, Smithsonian Institution Archives, "Disk Diving: A Born Digital Collections Survey at the Smithsonian", The Bigger Picture: Exploring Archives and Smithsonian History Blog, September 13, 2012. |
| 63 |
Greg Palumbo, Smithsonian Institution Archives, "The End of the Beginning: A Born Digital Survey at the Smithsonian Institution," The Bigger Picture: Exploring Archives and Smithsonian History Blog, April 30, 2013. |
| 64 |
Allana Mayer, "Survey about Born-Digital Collections in Canadian archives", Librarianship.ca Blog, November 3, 2015. |
| 65 |
Allana Mayer, "An Annual Survey Towards a Collaborative Digital Preservation Strategy for Canada" (paper presented at the 2015 Association of Canadian Archivists Annual Conference in Regina, Saskatchewan, June 11-13, 2015). |
| 66 |
Allana Mayer, email correspondence with author, July 12, 2016. |
| 67 |
United Nations Educational, Scientific and Cultural Organization (UNESCO), "Share your digital heritage strategy with the UNESCO-PERSIST project", Communication & Information Blog, January 20, 2015. |
| 68 |
Wilbert Helmus, UNESCO-PERSIST Platform to Enhance the Sustainability of the Information Society Transglobally, "Survey on selection and collecting strategies of born digital heritage — best practices and guidelines". Final version March 30, 2015. |
| 69 |
Greg Palumbo, "The End of the Beginning." |
| 70 |
Ibid. |
| 71 |
Naomi Nelson et al., "SPEC Kit 329," 29. |
| 72 |
Ibid. |
| 73 |
Dooley and Luce, "Taking Our Pulse", 59. |
| 74 |
Digital POWRR, "From Theory to Action", p.13. |
| 75 |
Naomi Nelson et al., "SPEC Kit 329", 34. |
| 76 |
Ibid, 35, 71. |
| 77 |
Schumacher et al., "From Theory to Action", 13. |
| 78 |
Naomi Nelson et al., "SPEC Kit 329", 37. |
| 79 |
Ibid, 82. |
| 80 |
Dooley and Luce, "Taking Our Pulse", 46. |
| 81 |
Dooley and Luce, "Taking Our Pulse", 39. |
| 82 |
Naomi Nelson et al., "SPEC Kit 329," 71. |
| 83 |
Ibid. |
| 84 |
Ibid, 67. |
| 85 |
bwFLA, "Legacy Environments at Your Fingertips: Emulation as a Service". Last modified date unknown. |
| 86 |
Jody DeRidder and Alissa Helms, "Practical Options for Incoming Digital Content" (paper presented at the COSA/SAA Archives * Records 2016 Conference in Atlanta, GA, August 2-7, 2016); "Practical Options for Incoming Digital Content (paper presented at the Digital Library Federation Forum in Milwaukee, WI, November 7-9, 2016); "What Works and What Doesn't? Developing Guidelines for Incoming Digital Content" (paper presented at the Digital Preservation 2016 Conference in Milwaukee, WI, November 9-10, 2016). |
| 87 |
AIMS Work Group, "AIMS Born-Digital Collections: An Inter-Institutional Model for Stewardship". |
| 88 |
Jody DeRidder and Alissa Matheny Helms, "Incoming Digital Content Management". (Open Science Framework project). Last modified November 3, 2016. |
Appendix I
Digital Content Intake Survey
Survey by Alissa Helms and Jody DeRidder, University of Alabama Libraries, Spring 2016
MATERIALS & CONTENT
- Which of the following types of digital content does organization currently collect?
- Audio recordings (including podcasts)
- Still images
- Moving images, videos
- Texts (such as unstructured office documents)
- Websites
- Email
- Databases
- Geographical Information Systems (GIS) Data
- Executable files (software)
- Other (please specify)
- What kinds of digital content do you NOT collect, and why?
- What forms of obsolete media are you prepared to obtain content from?
- Floppy discs (3.5 inch)
- Floppy discs (5.25 inch)
- Floppy discs (8 inch)
- Zip discs
- Mini discs
- Old hard drives (Mac)
- Old hard drives (Windows)
- Old hard drives (*nix)
- Hard disk drives (sizes other than 2.5 or 3.5 inch)
- Other (please specify)
WORKFLOWS
- Identification. One of the first tasks when faced with incoming digital content is to examine what is there in order to build an inventory, identify duplicate files, and assess what types of material are present. We consider this the "identification" stage.
- What tools do you find useful for this process?
- What tools have you tried that were not useful, and why?
- What is your process or workflow for this aspect of digital content intake?
- Analysis. After identification and building an inventory, some analysis of the content usually must precede selection by curators. This may include locating (and associating) all the versions of any particular file, documentation of where groups of file types are found, documenting sets of files and file structures that together comprise a single item (such as a database or software system), documenting which files are system files or known common software, documenting which files contain social security numbers, phone numbers and other potential privacy issues, how many of which file types are found, and more.
- What tools do you find useful for this process?
- What tools have you tried that were not useful, and why?
- What is your process or workflow for this aspect of digital content intake?
- Selection. Once initial analysis takes place, the difficult task of selection begins. This may include determining which of multiple versions of a file are the one(s) of interest; it may include isolating files of particular types which the donor has specified; and it may require sorting through many types of files in many directories. It's a daunting task for a large set of incoming content. Often during this stage some descriptive metadata is generated or collected to specify why particular files or directories should be retained.
- What tools do you find useful for this process?
- What tools have you tried that were not useful, and why?
- What is your process or workflow for this aspect of digital content intake?
- Processing. The ultimate goal of processing is to make digital content accessible for both current and future users. A number of processing activities may occur to provide access points with current technology and to preserve digital content across generations of technology, including content migration, data normalization, and emulation implementation.
- What tools do you find useful for this process?
- What tools have you tried that were not useful, and why?
- What is your process or workflow for this aspect of digital content intake?
CONTENT MANAGEMENT
- Do you preserve the original files (not on the original media)?
- Do you migrate (or normalize) files?
- If so, what are your target archival formats for the following types of materials:
- Text?
- Images?
- Audio?
- Moving images/video?
- Databases?
- Spreadsheets?
- Other?
- How do you track and organize content? Please share information about your workflows and any tools you have found helpful.
PRESERVATION METADATA
- What types of technical metadata do you capture?
- Checksums
- File sizes
- File date(s)
- Original location
- Associated files
- Structure of document
- File type
- File type version
- Creating software (and version)
- Operating system
- Endianness
- Appropriate standards based on file type (such as MIX, AES57, etc.)
- Other:
- What types of rights information do you collect for your incoming digital content?
- Access and use restrictions
- Digitization permissions
- Rights to make copies and derivatives
- Rights to preserve and migrate
- Rights to make representations and metadata
- Intellectual property rights
- Copyright
- Other:
- How do you track rights information? (Example: Open Digital Rights Language (ODRL), METS rights language, etc.)
- What other types of administrative metadata do you collect?
ACCESS
- How is your rights metadata used to control access? (Example: database entries queried upon clicking on item link, content organized according to access restrictions, etc.)
- At what level of granularity do you provide in-house access? (at the disk image, hard drive, directory structure, folder, or item level?)
- At what level of granularity do you provide online access? (at the disk image, hard drive, directory structure, folder, or item level?)
- Do you provide emulation of the original access method?
RECOMMENDATIONS
- What recommendations do you have for other institutions that are just beginning to collect digital content?
- Do you have other suggestions or comments about what has worked for you, and what has not? If you are willing to be contacted with follow-up questions, please provide your email address. This information is confidential and will not be published or associated with your responses in any publication or presentation.
About the Authors
Jody L. DeRidder is the Head of Metadata & Digital Services at the University of Alabama Libraries and a co-founder of the DLF Assessment Interest Group. She holds an MSIS and an MS in Computer Science from the University of Tennessee.
Alissa Matheny Helms is the Digital Access Coordinator at the University of Alabama Libraries, where she works to improve access to digitized materials from the University's Special Collections and enhance policies and procedures regarding the intake of born digital content. She received her MLIS from the University of Alabama.