|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
James E. Powell Linn Marks Collins Mark L.B. Martinez |
![]()
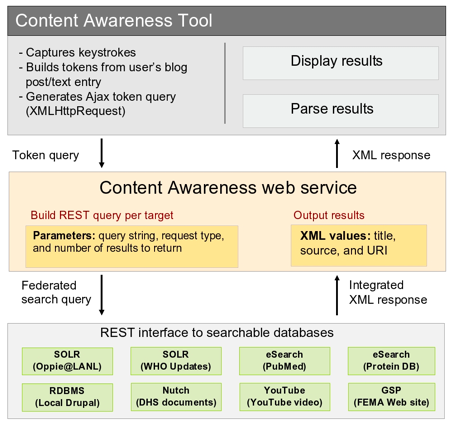
AbstractInformation awareness is distinct from explicit information seeking, such as searching. In this article we describe an information awareness tool that supports text composition by providing awareness of relevant content and references proactively and non-intrusively. As a user composes text, the tool automatically searches multiple sources, retrieves results, and displays links to the results. A working prototype of the tool has been implemented using Web 2.0 and Digital Library 2.0 technologies, and is flexible and highly configurable for both Web search engines and deep web targets. IntroductionThere are times when Google users, library patrons, and callers to 411 are all seeking the same thing: awareness of information. As commonly understood "awareness does not necessarily imply understanding, just an ability to be conscious of, feel or perceive." [1] Awareness is distinct from search in that the goal is not necessarily to plumb the depths of a particular topic, but rather to have an overall picture of what information might be available on a topic. Awareness tools aim to make users aware of potentially useful information sources in a timely manner in much the same way that a GPS unit makes a driver aware of an upcoming turn on the way to a destination. In an age of pervasive information, a capability for pervasive awareness of information is indispensable. Just as a navigation system is focused on the user's task of finding a particular destination, a content awareness tool ought to be associated with a user task that would benefit from information awareness, such as text composition, and should not require that a user explicitly shift focus to an information-seeking activity. Sometimes the urgency of an information need dictates that a computer-driven rather than user-driven approach to information seeking is preferable, as in an emergency [2]. In a situation where search is not the primary task, context becomes important. Search usually happens in a void. The search service usually does not know anything about the context of the request. But context can help in the formulation of better queries [3] and, in the case of an awareness tool, the context can even provide the terms that make up a query so that the user does not have to directly formulate one. DiscussionWe have designed an information awareness tool that is consistent with the design goals of other just-in-time information retrieval (JITIR) tools such as the Remembrance Agent [4] and the ambient search tool PIRA [5]. Unlike these other tools, The Context Awareness Tool (CAT) is a general-purpose widget suitable for integration with any web application or portal in which the user enters text, and it is capable of targeting a wide variety of search engines and databases. One component of the CAT is itself a Web service, and it is able to query other Web services on behalf of the user. It utilizes an n-tier architecture (Figure 1) to encapsulate different layers of the information discovery process. The CAT's flexibility and configurability enables it to perform proactive federated searches across multiple distributed targets [6], aggregate the results and integrate links to them on a Web page. It supports a user in composing text, whether the composition task is related to email, blogging, posting to a discussion forum, or some other Web application where writing is the primary activity.
The CAT has been implemented with the following goals in mind:
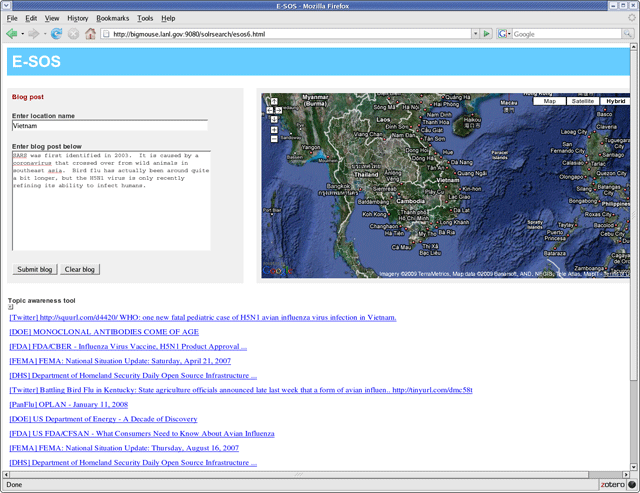
The CAT can automatically query a number of different sites, or targets, which are described in a configuration file for the tool. Targets may be (1) any service which exposes a REST-based1 query interface and returns XML results, (2) any relational database that allows JDBC2 connectivity, or (3) semantic web repositories that support SPARQL3 queries via HTTP, such as OpenRDF/Sesame [7]. For targets that support a REST-based interface, a target's query capability is described with a service URL entry that includes a partially completed REST URL and a placeholder for the value that represents the query terms. At execution time, the placeholder is replaced with an automatically generated query. Awareness tools can typically function without user intervention. The CAT uses a Javascript client, which captures user keystrokes while users compose text. Phrases or sentences, as denoted in English language text by punctuation such as commas, semicolons and periods, cause the CAT to perform an AJAX request to its server component. The server component may simply omit stop words and use the remaining terms as the basis for a query, or call an intermediate service for term extraction, such as Yahoo's Term Extraction Web Service [8] or OpenCalais [9] from Reuters, and use the response to formulate queries against the defined search targets. An example sentence follows, along with a comparison of the terms that would be used to automatically formulate a query for that sentence based on internal processing vs. the results of a call to the Yahoo service: Example sentence: "There is increasing concern among scientists studying H5N1 that co-infection with different strains of flu may provide avian flu with both a better ability to infect humans and the ability to resist existing antiviral medications." INTERNAL processing of the sentence by the CAT, which involves deleting stop words, results in the following query: "increasing" and "concern" and "scientists" and "studying" and "H5N1" and "co-infection" and "strains" and "flu" and "provide" and "ability" and "infect" and "humans" and "resist" and "existing" and "antiviral" and "medications"EXTERNAL processing of the sentence by the Yahoo Term Extraction service results in the following query, which is based on the terms returned by the Yahoo service: "antiviral" and "medications" and "avian" and "flu" and "strains" and "scientists" Since the CAT can call any REST-based term extraction service, we are also investigating other options for term extraction to support automatic query formulation, including the TRYNT Contextual Term Extraction service [10]. The CAT server component configuration file allows a default Boolean operator to be associated with each target, so multi-term queries are submitted using the appropriate default Boolean operator specified for the target. Another characteristic of JITIR tools is that they proactively present information as it becomes available. They manage user attention so that they are minimally distracting and only call attention to themselves when they retrieve information that may be of immediate interest. In supporting text composition, a JITIR tool should retrieve and display results that are relevant to the content the user is currently authoring. The CAT stores information about how to parse results from various targets in the server component's configuration file. This makes it possible to extract specific metadata about items that occur in the results returned by each target. The parsing information consists of XPath statements that specify where results set metadata (such as results titles and results item links) occur in the results document from targets. The extracted results information is then aggregated and returned to the CAT client. Finally, the client uses client-side DOM4 methods to dynamically add these results to the Web page that hosts the text composition (Figure 2). As the user types text, the CAT displays links to related information.
The server component of the CAT is implemented as a REST-based Web service, which makes it possible to integrate its federated content awareness services with other applications. While our version is integrated with a Javascript client and is a Web application, it is possible for the CAT to be integrated with any network-enabled tool, such as a word processing application or even a text messaging app on a cell phone.
Table 1: Configuration example for a search engine using the Google search appliance One of the uses we are exploring with the CAT is how to incorporate it within a collaboration space designed for technical responders to emergency situations. Our team is currently designing and developing a collaborative emergency response system using the Drupal collaboration framework, which we call E-SOS [2]. Although the CAT server is Java-based, and the client is Javascript-based, Drupal is a PHP5 application. Drupal uses Javascript internally, by leveraging the jQuery Javascript library [11], so integrating the existing CAT client simply requires re-implementing the AJAX calls using jQuery's http.request methods.
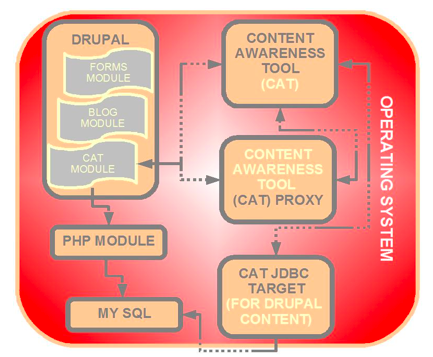
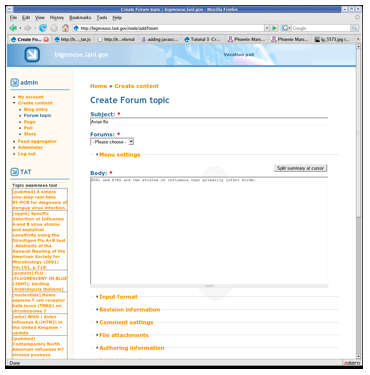
One obstacle to the integration of the CAT with E-SOS is the security-inspired limitations of AJAX. AJAX is a set of technologies that enable Web applications to asynchronously interact with server-side components in order to provide dynamic, interactive Web applications comparable to desktop applications running in an environment such as Microsoft Windows or Mac OS. Requests from AJAX-based Web applications may only target services that reside on the same host as the one that delivered the Web page, and our CAT service is hosted on a different server deployed under Tomcat6. By developing a PHP proxy which intercepts CAT client requests, reformats them into CAT server requests, and submits them to the Web service on the user's behalf it is a simple matter to add the CAT client and proxy as a Drupal module to a previously deployed instance of Drupal (Figures 3,4), and we will be able to associate it with blog and forum composition pages in the collaboration framework.
We are also developing a Drupal target for the CAT using the CAT's ability to query JDBC-compatible databases such as MySQL7, which targets the instance of Drupal in which the CAT is deployed so the service can find and display previous blog and forum posts related to the topic a user is posting about. Proactively exposing content already posted in a forum or blog will improve the user's ability to discover related content and reduce the number of similar posts in E-SOS. Drupal content is stored in a relational database such as MySQL, so developing this introspective capability requires extending the CAT server so that it can query JDBC-compliant databases. Database target entries in the CAT configuration file have partially completed SQL queries rather than REST requests: Regardless of the target type, the content returned from any target is aggregated and normalized to XML. This is handled by the server component of the CAT. At a lower level, the CAT inspects the XML response from a target. It uses XPath to inspect and retrieve information from results, such as titles and links. Many search engines offer an XML version of their results, for example, in RSS or Atom. The following two CAT configuration entries are in the form of XPath statements that retrieve title and link from, in the first case, an Atom version of a results set from Twitter Search [12] and, in the second case, an RSS version of a results set: The CAT serves several purposes in support of our ongoing work in developing information retrieval tools for emergency response situations. Because of its configurability, it is easy to add and remove targets quickly. This allows the tool to be customized rapidly with the services that are most appropriate for a particular type of emergency or particular community of users. The architecture of the CAT makes it possible to easily integrate it with existing systems, such as Drupal. Its ability to query a variety of targets including REST Web Services, relational databases, and RDF repositories makes the CAT well-suited to exploring deep web [13] content as well. And we have been able to re-use this architecture and some of the CAT client and server code to rapidly prototype several other JITIR awareness tools. ConclusionWe believe that proactive information retrieval tools can play a significant role in information seeking for users in some situations, in particular those where it is important to quickly get a sense of what information might be available about a particular topic. This may be particularly true if a user is focused on a task that benefits from information, but is not itself an information-seeking task. Additionally, the urgency of a particular task may also make it a requirement that the user be made aware of information, rather than be forced to search for it. The Content Awareness Tool is a flexible Web-based solution that can be integrated with a wide variety of Web applications where the primary task is text composition. It is capable of querying multiple targets of different types and of using external Web services to assist in automatic query formulation. It is highly configurable and can be customized to support a community of users who have a particular set of information needs that can be served by a number of existing online search engines. Our tool has the ability to provide instant access to digital library resources along with a variety of Web search engines, deep web information resources, and even live search tools such as Twitter Search, with minimal overhead. This enables near instant querying and aggregation of results from a nearly infinite combination of resources, tailored to tasks, situations, users, and communities. Notes1. REST - Representational state transfer (REST) is a software engineering architectural style for distributed hypermedia systems. <http://www.ics.uci.edu/~fielding/pubs/dissertation/rest_arch_style.htm>. 2. JDBC - The Java Database Connectivity (JDBC) API is the industry standard for database-independent connectivity between the Java programming language and a wide range of databases – SQL databases and other tabular data sources, such as spreadsheets or flat files. <http://java.sun.com/javase/technologies/database/>. 3. SPARQL - SPARQL is an RDF query language. <http://www.w3.org/TR/rdf-sparql-query/>. 4. DOM - The Document Object Model (DOM) is a platform- and language-neutral interface that will allow programs and scripts to dynamically access and update the content, structure and style of documents. <http://www.w3.org/DOM/>. 5. PHP - PHP is a widely-used general-purpose scripting language that is especially suited for Web development and can be embedded into HTML. <http://www.php.net/>. 6. Tomcat - Apache Tomcat is an implementation of the Java Servlet and JavaServer Pages technologies. <http://tomcat.apache.org/>. 7. MySQL - MySQL is a relational database management system (RDBMS). <http://www.mysql.com/>. References[1] Wikipedia. <http://en.wikipedia.org/wiki/Awareness>. [2] Collins, L.M., Powell, J.E., Jr., Dunford, C.E., Mane, K.K., and Martinez, M.L.B. 2008. Emergency Information Synthesis and Awareness Using E-SOS. Proceedings of the 5th International ISCRAM Conference, Washington, DC, USA. Available at <http://www.iscram.org/dmdocuments/ISCRAM2008/papers/ISCRAM2008_Collins_etal.pdf>. [3] Lawrence, S. 2000. Context in Web Search. IEEE Data Engineering Bulletin, 23:3, 25-32. <doi:10.1109/4236.707689>. [4] Rhodes, B. and Maes, P. 2000. Just-in-Time Information Retrieval Agents. IBM Systems Journal, 39:3-4, 685-704. <doi: 10.1147/sj.393.0685>. [5] Twidale, M.B., Gruzd, A.A., and Nichols, D.M. 2008. Writing in the library: Exploring tighter integration of digital library use with the writing process. Information Processing & Management, 44:2, 558-580. <doi:10.1016/j.ipm.2007.05.010>. [6] Powell, J. and Fox, E.A. 1998. Multilingual Federated Searching Across Heterogenous Collections. D-Lib Magazine. 4:9, Sept. 1998. <doi:10.1045/september98-powell>. [7] Open RDF/Sesame: <http://www.openrdf.org/>. [8] Yahoo Term Extraction Web Service: <http://developer.yahoo.com/search/content/V1/termExtraction.html>. [9] OpenCalais - The Calais Web Service: <http://www.opencalais.com/calaisAPI>. [10] TRYNT Contextual Term Extraction Web Service: <http://www.trynt.com/trynt-contextual-term-extraction-api/>. [11] jQuery: <http://jquery.com/>. [12] Twitter Search API: <http://apiwiki.twitter.com/Search+API+Documentation>. [13] Warnick, W.L., Lederman, A., Scott, R.L., Spence, K.J., Johnson, L.A., and Allen, V.S. Searching the Deep Web: Directed Query Engine Applications at the Department of Energy, D-Lib Magazine. 7:1. <doi:10.1045/january2001-warnick>. Copyright © 2009 James E. Powell, Linn Marks Collins, and Mark L.B. Martinez |
||||||||||||||||||||||
| |
||||||||||||||||||||||
|
Top | Contents | ||||||||||||||||||||||
| | ||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/may2009-powell
|