|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Bradley Hemminger, Ph.D. |
![]()
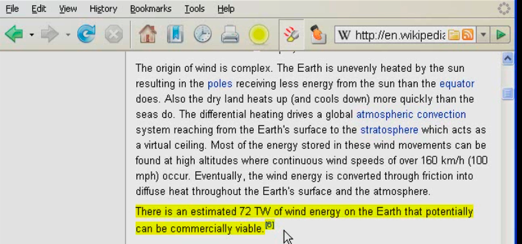
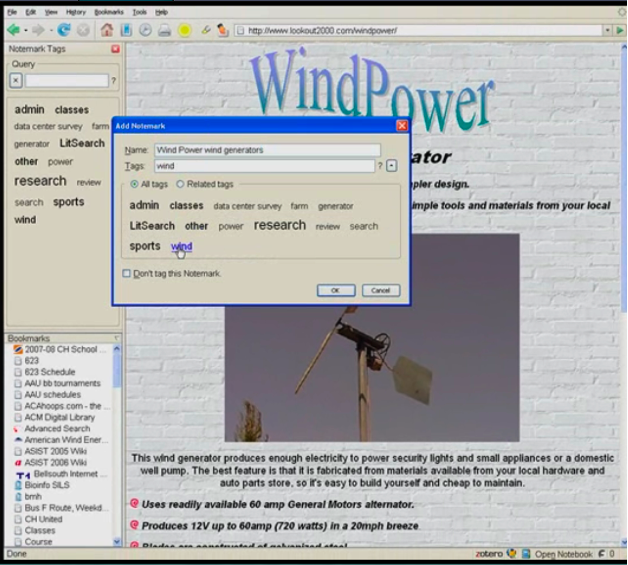
AbstractThere is a need for integrated support for annotation and sharing within the primary tool used for interacting with the World Wide Web, which today is a web browser. Based on prior work and user studies in our research lab, we1 propose design recommendations for a global shared annotation system, for the domain of scholarly research. We describe a system built using these design recommendations (NeoNote), and provide an example video demonstrating the suggested features. Finally, we discuss the major challenges that remain for implementing a global annotation system for sharing scholarly knowledge. 1. IntroductionSignificant changes are occurring to scholarly communications, in large part due to technological innovations, primarily the advent of computers and the internet. Compared to thirty years ago, scholars now use computers both to do their work and write their papers. They still publish in journals, but the articles are available and accessed primarily in digital form rather than in print form. Scholars increasingly share their work with others by putting their work on their websites or in institutional repositories, or by exchanging email. They use collaborative tools for writing papers or creating shared content on wikis. Scholars are beginning to compile large digital collections of research papers instead of print collections. They are beginning to annotate these papers electronically and to share these annotations. They save citation information digitally in citation managers and automatically incorporate this information when writing their papers. They start their searches more often with search engines than traditional library catalog resources, and they spend most of their time searching and looking for information using the web. In short, we seem to finally be approaching the Memex, the theoretical proto-hypertext computer system Vannevar Bush proposed in his 1945 Atlantic Monthly article "As We May Think". While great strides have been made towards this goal, and a proliferation of tools have been developed to help support scholars in performing this myriad of new activities, the vision has not yet been achieved because those tools are not part of an integrated whole. The existing tools are designed only for a specific task or environment, and as a result, scholars are forced to utilize many different tools to perform their scholarly work and communication. This article looks at the problem from the scholar's perspective and proposes a user interface well suited to scholarly work practices. It also proposes a paradigm for how scholarly annotations could be captured, stored, searched and re-used on both a global scale and at the level of an individual research laboratory or group. It is our hope that the paradigms proposed in this article will provoke discussions in the digital library community about shared global designs for digital library content, including annotations. While in most fields the scholarly works shared are journal articles and books, it is increasing common today to include "data" as content items that are shared. This is commonly referred to as e-science. Change is so rapid in some scientific domains that new research is primarily data driven as opposed to model and experimentally driven as it was in the past [1]. This results in an increasing need for scholars to have an integrative environment that supports iterative exploration of content from many data sources on the web. In order to integrate and tie together information content from so many places, it is critical to have a common workspace for gathering and annotating content available for scholars. As part of a user-centered design process to develop a global shared annotation solution, we examined information from several sources available to us, including a national survey of academic scientists' information seeking behavior [2], interviews with scientists and research laboratories at the University of North Carolina (UNC), and feedback from users of scholarly annotation tools. This information was analyzed to generate a list of features commonly requested by scholarly researchers. Currently, there is no system available that has been designed as a single comprehensive system that addresses all of a scholar's needs. There are, however, many individual applications that provide excellent support for one or more features needed by the scholarly researcher. This article describes the major desired features of a single comprehensive system, gives examples of current tools that support these features, and then describes the architecture of our resulting design, named NeoNote. Overall, we believe the most effective way such an interface could be delivered would be as part of a next generation interface to the web, closer to the original hypertext systems first proposed like Xanadu [3, 4, 5]. The important change would be that annotation and sharing would be integrated into the user's primary interface to the web, and as part of the everyday user experience, in the same way that browsing and searching the web is integrated in today's interface to the web (a web browser such as Internet Explorer and Firefox). Alternatively, a smaller incremental step would be to have today's web browser incorporate such capabilities through plugins, such as are common in the Firefox web browser [6]. To test these ideas, we have taken the latter course, and we are implementing these features as an integrated set of tools through plugins to the Firefox browser. Our implementation, NeoNote, is focused on global shared annotations and is part of the more general NeoRef [7] scholarly communications project at UNC. A video demonstrating the NeoNote system that visually shows how the paradigm might work is available on YouTube [8] and at a higher resolution on the author's website [9]. At the conclusion of the article, we describe some of the current challenges facing the development of such a global scholarly annotation repository. In this article, for reasons of brevity, discussion and examples about the information (content items) that scholars identify, and want to save and re-find, focus on scholarly journal articles and annotations on them. This paradigm was chosen because it is familiar to most readers, it is currently better understood by researchers, and there are more examples of applications working with scholarly journal articles. However, it is important to remember that this discussion should apply to all types of content items, including multimedia (such as audio, pictures, video), data analysis, datasets (such as genetic sequences, observations from astronomy, weather, geography), etc. Thus, for example, users should be able to annotate a section of a home video they have placed on the web, and share it with a defined group of family and friends. Closely related to the study of shared annotations of scholarly content are the many efforts attempting to develop shared annotations of web pages. As evidenced by the lack of significant commercial success of these tools, there are significant challenges to be overcome. The first big challenge is the transient nature of web pages, which may frequently change or even disappear. As result, most systems make and keep a copy of the web page that was annotated so that the original content is preserved, along with the added annotations. The second major challenge is that of too many annotations, i.e., "who wants to see the annotations of everyone in the world?" If every website we visited could be covered with thousands or millions of annotations, with perhaps many of them being graffiti, this could ruin the experience for most users. As a result, some systems allow you to interactively select whether to see all annotations or selected ones, and most systems provide ways for you to define "groups" in which you wish to participate so that you only need to see the annotations created by participants in those groups. The latter is very similar to the "research group" or "professional society" social groups that occur in the context of scholarly paper annotations. There has been an explosion of such web annotation sites since 2007; however, few have achieved large audiences. 2. Suggestions for a Successful Global Shared Annotation System2.1 User Interface DesignSelection/Markup from Web Page. Searching and selection of content items should be done from within the single interface to the web that users utilize (currently this is a web browser). In the past, many literature database searches were performed on specific interfaces from providers like BRS, Data-Star, Dialog, and Orbit. Nowadays, most searching is done either via web-based interfaces to these same services, or via freely available web-based search engines like Google. As a result, researchers need to be able to add content items identified on a web page to their "personal digital library" with a single click. (Examples include: Zotero [10], Connotea [11], RefWorks [12]. These services scrape the marked webpage to automatically capture metadata into their applications. Because users make frequent use of these features only when information saving can be done during their web browsing experience, these search features should be an integrated part of the web browser (or whatever future application provides the user access to the web), rather than accessed through separate applications.) Support for Multiple Levels of Annotation Complexity. Annotations are created for multiple reasons. Some annotations are complex (examples, comment, tags, link), and some are very simple (save item, save item plus highlighted text). All kinds of annotations should be very easy to create, and the user should be able to specify them directly from the web browser environment. Simple Item Capture with One Click. For simple types of content item capture (e.g., saving it to a citation database, or saving highlighted text as annotation of the item), it is critical that this can be done transparently and simply within the existing interface. This implies that such interactions should be accomplished via a single click from the web browser. (Examples include: Google Notebook [13] (although first users have to select notebook), Fleck [14] (but this requires turning on Fleck for the page, then saving the bookmark), and Diigo [35] (which again is done from toolbar).) Simple Item Highlighting. A user should be able to highlight text on a content item, and have this highlighted text automatically captured as an annotation on that content item. The user should then be able to make consecutive highlights on the content item without requiring any other interactions (for instance, re-selecting a highlight tool). This models how students highlight textbooks with a highlighter – they pick it up and then continue to highlight until they are finished. Complex Item Annotation and Capture. In some cases, users will want to capture additional information about an item. They may want to add a text note, tags, links to other items, etc. This should be supported, easily and conveniently, while not complicating the user's ability to do simple item captures or highlights. A common example is to tag an item to group it with a set of content on a particular topic. Concept of Current Folder or Notebook. This is critically important as users frequently are working on a particular topic, and they simply want all items they continue to select to all be captured and "stored" in the same "group" or "folder". The concept of the group is common and is supported as folders in most browser bookmarks, or as a "notebook" in Google Notebooks. (An example is Google Notebook [13]. Clipping an item places it in the current notebook (which is the most recently used one).) Searching and Organization. Users expressed two main preferences. First, for searching out new information and organizing it, they tended to prefer to organize materials by placing them in a folder. Second, they wished to be able to tag content items with tag words or phrases. They wanted to search by any of the tags including the folder label, by the full-text of the content item, and potentially by other metadata of the item. While we have chosen to support the hybrid system of single level folders combined with tags in NeoNote, it is an open question as to which of the three organization models (hierarchical file systems, single level folders with tags, tags only) is the most appropriate organizational and retrieval method. Interestingly, in 2009 Google seems to be heading towards concentrating its development efforts on tag-only organization with Google Bookmarks, and not further developing their hybrid model (Google Notebooks). (Examples include: Social Bookmarking Sites delicious [15], flickr [16], etc. (A good reference is the Wikipedia entry [17].)) Automatic Capture of Citation. When the user selects an item for capture, the citation information (all metadata associated with the item) should be automatically captured into the annotation and incorporated into their bibliographic database (whether this is part of web browser interface or a separate standalone package). (Examples include: Zotero [10], Connotea [11], and RefWorks [12].) Automatic Capture of the Item, Not Just the Link. While for many web pages users are content to just capture a link to the original resource, most scholars prefer to maintain their own copies of research articles. At some point in the future when content items are all easily retrieved from long term stable archives via universally unique identifiers, it may no longer be necessary to keep private copies. From our data, though, scholars currently clearly prefer to keep their own copies, just as they have made print or Xerox copies in the past. Universally Accessible Saved Content and Annotations. Most users operate from many locations and many computers. Users want to have their annotations and content items available on the web from any computer at any location. (Examples include: Google Notebook [13], Google Docs [18], Connotea [11], and social bookmarking sites [17].) Sharable Annotations and Content. Scholars want to be able to share their annotations and content items as they see fit. In some cases this means with the world, but in most cases they wish to share them with their research group, department or collaborators. (Examples include: Connotea [11] and social bookmarking sites [17].) Collaborative Sharing and Writing. Scholars wish to be able to save papers to shared digital libraries, collaboratively edit annotations, revise papers, and work on documents. The documents need to be available from any computer at any location, and should include provisions for handling multiple write accesses at the same time. (Examples include: Google Docs [18], Web based File Systems (WebDAV [19], commercial systems (SharePoint [20], etc.).) 2.2 Structure and Representation RequirementsLinks and Relationships. Through text and data mining, we increasingly have the ability to algorithmically make deductions based on collections of content items and annotations. These types of automatic deductions can be significantly improved if the information we capture in the annotations is well defined and structured. In particular, it is important to have an ontology-defined set of relationships for describing relationships between items. This implies that annotations have a structure for capturing links, as well as a vocabulary for indicating the type of relationship between links. For example, an Annotation A may be created that indicates that the evidence in Content Items B and C does not support the conclusions of content item D. (Examples include: ScholOnto [21], Nepomuk [22], and LSLink [23].) Ability to Search Content in a Prioritized Fashion. Users wish to search like they do with search engines, but in a prioritized fashion. They would like to first search materials they have saved (content items and annotations), then local files (their computer), then their work or group files (local network files), then the World Wide Web. (One example is Google Desktop [24].) Content and Annotations Available Universally at any Internet Computer. Content and annotations must be stored on the web in locations that permit simple access, and must not be locked up on local computers or local area networks. Federated Collection of Repositories for Content Items and Annotations Supported. To work effectively in a universal world, the content items, including annotations, must be stored in repositories. They must be stored in a common readable format, which supports automatic analysis. This suggests XML [25], and given the need for automatic inferencing, it points to using RDF [26] or OWL [36]. 3. Proposal for Design of a Global Shared Annotation SystemUser Interface for Creating Annotations.The ideal solution would be to have the next generation of web browsers integrate annotation into the user's interaction and experience just like browsing and searching are integrated in today's web browsers. Until that time, the best available alternative is to add a plug-in to existing web browsers that enables the user to perform annotation and sharing interactions directly from the web browser. We created NeoNote as a plug-in for the Firefox browser, which is well designed to accept plugins and has a large development community for them. To support the desired user interface, two buttons need to be added to the browser window. These buttons could be placed on the browser menu bar (as done by NeoNote, shown in Figure 1) or the bottom of the browser window pane (as done by Zotero). In NeoNote, the two buttons are a "hand grabbing paper" and a "highlighter". The grabbing hand button is modeless and is clicked to grab the contents of the current page. This is the same feature currently provided by applications like Zotero, Connotea, RefWorks, and Google Notebook. The highlighter is a moded interface, modeling the interaction of a user picking up a highlighter with the intention of highlighting portions of the paper. When clicked, it changes color and displays an "active" highlighter so the user knows it is engaged. While the highlighter is on, all highlighting of text on the page creates annotations automatically. Note that many applications bring up a menu or require clicking on a button to begin or conclude these types of interactions. This is too cumbersome, and simple captures should be available via a single click. When the annotation is created, it automatically captures the citation information and the metadata for the content item. It additionally captures the complete content item and saves it to the user's default personal digital library space (ideally a shared space).
Complex annotations require the specification of additional information to be saved with the content item. In NeoNote the same interaction is used for all annotation creation tasks. When an annotation is created, a transparent window showing the annotation information is displayed just to the side of the current pointer device location. If the user moves the cursor onto the annotation, it changes from semi-transparent to opaque, and the user can enter further information into the annotation window. If the user does not move the cursor towards the annotation window, it disappears. This interaction style is similar to how Microsoft Office 2007 tools like Word work when you select text. Information that can be added or changed includes the main tag (folder name), supplemental tags, descriptive text, links, and link relationships. Other information, including creator and date, are automatically captured. Organizing and Searching. There are several competing options for organizing materials:
NeoNote combines all three mechanisms. The user description is primarily tag-based, but the primary or main tag is in essence the "folder name". This is because users, while not needing extensive folder hierarchies, still seem to favor having "bins" or "folders" for topically organizing at the highest level. Because we strongly believe that content items should not be "placed" only into a single location, as was historically done in library systems, but instead be capable of existing (and being searched and found) in many "locations", we feel the tag and content-based storage mechanisms are more appropriate. Thus, the representation of each content item in NeoNote is such that the metadata contains the tags (keywords) and the full context of the item is directly indexed and searchable. In NeoNote, Lucene [27] is used to index and search the full text content of items. The labeling by tags and the ability to search by these tags (and folders) is referred to as "Notemarking". The mental model for NeoNote distinguishes between standard browser bookmarks, which are used for commonly referenced web resources, and notemarks, which are more temporary holders for information under investigation. Notemarks are displayed in their own separate sidebar and can be visualized different ways, including tag clouds as seen in Figure 2.
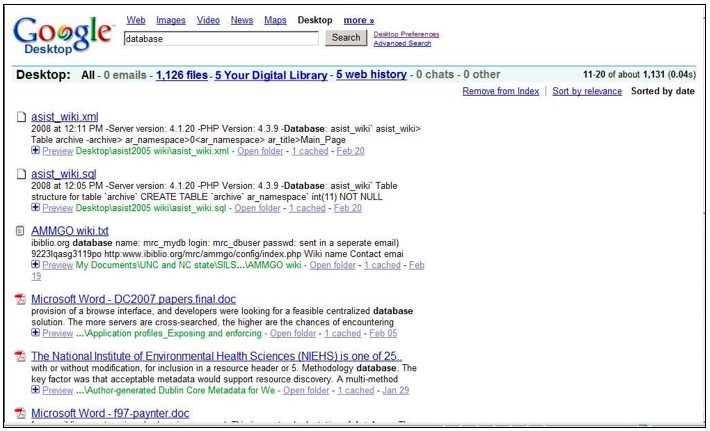
Searching Content (regular content items and annotation content items). In related work we have found that the search process can be optimized if the user has some control over the precision and recall of the result set returned [28]. As a result, our retrieval model is a weighted linear model that combines information on where the matching occurs. We know that matches on keywords are more likely to provide more relevant results than matches on words in the full text [28], so these are weighted more strongly in the search results. NeoNote supports the prioritization of search results based on which part of the annotation or content item is matched (i.e., title, URL, tags/keywords, text description/abstract, full text). It also can prioritize the results, or show them in groups based on the source location of the item (i.e., results can be displayed in groups or color coded to indicate whether the matching item was found in the user's personal content library, the user's computer, the content library of the user's group, or the world). This allows the items that the user has previously identified and annotated, or provided metadata for, to appear at the top of the user's results list. Even when the user has not provided additional information, it is still of benefit to be able to weight the results by knowing whether matches are against the metadata or annotation fields versus against the full-text fields [28].
Displaying Shared Content and Annotations. Displaying shared and collaborative annotations on content material can be difficult. In our experience, once the number of reviews exceeds about a dozen, it becomes difficult to track and stay connected to multiple individuals' comments. Personal experience from teaching several years of courses that utilized shared reviews suggests that displaying and positioning separate comment boxes for all annotations is difficult, especially with limited screen space. The most effective solution was to limit the annotations to highlighting of text (which could include associated annotation text) and inserting a symbol (again with associated annotation information). Annotations and symbols were color coded to individual authors. The best interface for viewing and editing comments was found to be simply mousing over highlights or annotation symbols to show their corresponding annotation text, and using the pointer device to click or double click on an annotation in order to bring up the complete annotation details for the purpose of editing it. (Examples include: applications like the Adobe Acrobat/Reader reviewing system [29], and social bookmarking sites that have good support for group annotations, like Diigo [35].) Representing and Storing Annotations and Content Items. A good choice for the annotation structure is the one used by the Annotea Project [30], which is a W3C Semantic Web project. It uses an RDF-based annotation schema and uses XPointer [31] for describing location down to the level of an individual symbol (character) within documents. It provides for multiple repositories of annotations, and it could be capable of supporting automatic inferencing across annotations. NeoNote utilizes this schema for annotations, and is extending it by incorporating a controlled vocabulary for indicating relationship types between content items and allowing for specification of a highlighted range of text, as opposed to a single point. The list below shows the structure of a NeoNote annotation:
Annotations and content items should be stored on web-accessible file systems, so that they can be accessed from anywhere. Currently, NeoNote utilizes URLs, but as advocated above, the long term solution should incorporate URIs or DOIs, or similar. For NeoNote, we chose to utilize the "Web-based Distributed Authoring and Versioning" (WebDAV system [19]). This allowed all materials to be stored in a single World Wide Web accessible file space that can appear as a local file to applications, as well as support file versioning and password protection. The annotation structure was designed to conveniently map into Dublin Core metadata to facilitate easy harvesting and searching of the annotation fields. One design constraint for global annotation systems that we believe to be extremely important is that annotations are treated as full fledged content items, just like any other content item. This has the advantage of facilitating uniform representation of all content types (annotations are no different) and the mechanisms for referencing them. 4. ChallengesWhile we believe this paradigm holds significant promise for revolutionizing how scholars annotate and share information, there are a number of significant challenges facing such implementations. Some of the major challenges to the adoption of such a vision are listed below. Separate Content from Presentation. In order to properly index the full content, and to refer to portions of the content, the content must be fully and openly represented. This can and is being done using the XML format. For instance, PUBMED is now utilizing XML to represent their articles. Most of the scientific literature in electronic format is, however, currently stored in PDF format. This was an opportune standard at the time because it allowed for an electronic format that could both be read on the screen and printed at high quality. It is, however, not an open standard (although PDF/A attempts to remedy this) and, more importantly, it does not properly separate content from presentation to facilitate markup at the subdocument level conveniently, or for reuse across multiple display devices. Unique Identifiers for Content. Problems with sharing and recognizing all the comments on a particular item are difficult because we cannot currently accurately identify copies or versions of the same content. Several mechanisms have been proposed to accomplish this, but for this to work there must be uniform adoption of a single mechanism (DOI, URIs, etc). Unique Identifiers for Creators. Similarly, in order to build in social constructs (reputation, authority, etc), contributors must be accurately identified as creators of content, including annotations. Local Storage versus Single Large Global Storage. Clearly "cloud computing and storage" is coming of age. Increasingly, researchers are utilizing such resources to free themselves from location-based access constraints in order to to facilitate sharing and to offload data management service. However, many researchers still want to maintain their own physical copy of materials. They have valid concerns about ownership of data in the cloud, and long term support of such data stores (most are relatively recent pilot programs, such as those available from Google, Microsoft and Amazon). Universal Store for Annotations and Content. While it may be possible to federate content from many different sources, it would be easiest if all the scholarly content was housed (at least logically) in one source location. This would allow for easy access and referencing by all users, and for annotations to be easily shared and to reference the same items. It could solve many of the problems associated with multiple copies of the same content item. As an example, multiple copies of the same item might exist in the publisher's website, on the author's homepage, in the author's institutional repository, in a professional scholarly repository, and in PUBMED. Furthermore, there may be multiple versions of the paper, especially on the author's website. If someone posts an annotation in reference to one instance of the paper at the author's institutional repository, how should this affect all of the other copies or revisions? Currently, we do not have anything close to such a unifying universal repository. As a result, content is made available through multiple access points with little to no coordination. In addition, different groups compete for authors "annotations", including publishers or repositories that may hold the paper (Nature repository [32], BioMedCentral [33]), but also third parties (Faculty of 1000 [34], Connotea [11]) who just provide annotation and review services. In the end, who will maintain these annotations? Sharing. Based on our research and surveys, it appears that there were three groups the users wish to qualify for access to their data. They wanted to grant access to one of:
Privacy of Shared Data. An expressed goal included putting up copies of all content and to be able to easily share it with students and colleagues. This can be difficult in cases where access rights among colleagues at different institutions vary with regard to copyrighted materials. Thus, problems exist in including some copyrighted materials in a "public" space. At some point in the future, maybe most materials will be available under open access licensing, but until then, some way is needed to restrict access. In NeoNote we restricted access to WebDAV folders containing all content items, including annotations, by using login and password protection. Citations Point to Specific Text, Not to Entire Documents. Historically, citations have referred to an entire document and, in some cases, to a more limiting set of page numbers within a document, because this was the smallest level that could be identified for reference. With today's electronic documents, citations should instead point precisely to the exact content being cited. This will improve understanding and access, and will allow for more transparent evaluation of citation claims. New tools like NeoNote allow the user to accomplish this with only two mouse clicks: one during the capture process to highlight the text (saving the citation to your personal digital library), and a second click when writing to select the citation to include. Markup of Documents Other than Text. For text documents we now have the technical capabilities to store and represent the content information separately from the presentation information in XML, and to markup specific pieces of documents, such as sentences, words, or diagrams. This is critical to supporting more accurate statements of citation and reference. We do not, however, have similar notational referencing mechanisms defined for many other data types that are commonly available on the web. Thus, it is important that standard representations for audio, video, graphics, images, statistical analyses, genetic sequences, etc, all similarly evolve to support referencing within their content items, and not just to the entire content item itself. The goal of this article is to prompt others to think more generally and more globally about issues surrounding access, representation, searching and sharing of content items and annotations in digital repositories. There are many examples today of implementations and visions that address pieces of the big picture. We encourage others to build and make available contributions to this global vision for sharing and communicating digital content. Note1. This article includes descriptions of results from several different research projects directed by the author in his Informatics and Visualization Laboratory (IVLab) at the School of Information and Library Science at the University of North Carolina. The author uses the plural "we" in describing the work because all of these projects are the result of team efforts within the lab. References[1] Wired Magazine: 16.07, The End of Theory: The Data Deluge Makes the Scientific Method Obsolete, Chris Anderson, June 2008. <http://www.wired.com/science/discoveries/magazine/16-07/pb_theory. [2] Hemminger BM, Lu D, Vaughan KTL, Adam SJ, "Information seeking behavior of academic scientists", JASIST, 58:14, pp2205-2225, 2007. <doi:10.1002/asi.20686>. [3] Xanadu Project Webpages, available at <http://www.xanadu.net/>. [4] Xanadu Wikipedia Page, available at <http://en.wikipedia.org/wiki/Project_Xanadu>. [5] Ted Nelson history page, available at <http://www.livinginternet>.com/w/wi_nelson.htm>. [6] Firefox Web Browser, available at <http://www.mozilla.com/firefox/>. [7] Neoref Project, available at <http://neoref.ils.unc.edu/>. [8] NeoNote YouTube Video, available at <http://www.youtube.com/watch?v=PUn09--HRaw>. [9] NeoNote high resolution video in WMV format, available at <http://ils.unc.edu/bmh/pubs/NeoNote-For-YouTube.wmv>. [10] Zotero Project, available at <http://www.zotero.org/>. [11] Connotea Project, available at <http://www.connotea.org/>. [12] Refworks Application, available at <http://www.refworks.com/>. [13] Google Notebook, available at <http://www.google.com/notebook>. [14] Fleck, available at <http://fleck.com/>. [15] delicious, available at <http://delicious.com/>. [16] flickr, available at <http://www.flickr.com/>. [17] Wikipedia entry on social bookmarking, available at <http://en.wikipedia.org/wiki/Social_bookmarking>. [18] Google Docs, available at <http://docs.google.com/>. [19] WEBDAV, available at <http://www.webdav.org/>. [20] Microsoft Sharepoint Server, available at <http://www.microsoft.com/Sharepoint/default.mspx>. [21] Shum SB, Motta E, Domingue J, ScholOnto: An Ontology-Based Digital Library Server for Research Documents and Discourse, International. Journal on Digital Libraries, 3 (3) (August/Sept., 2000), Springer-Verlag. <http://projects.kmi.open.ac.uk/scholonto/docs/ScholOnto-IJoDL-2000.pdf>. [22] Nepomuk Annotation Ontology Specification, available at <http://www.semanticdesktop.org/ontologies/nao/>. [23] Lee WJ, Raschid L, Srinivasan P, Shah N, Rubin D, Noy N, " Using Annotations from Controlled Vocabularies to Find Meaningful Associations", In: Cohen-Boulakia, S., Tannen, V. (eds.) DILS 2007. LNCS (LNBI), vol. 4544, pp. 264Ð279. Springer, Heidelberg (2007). <http://www.springerlink.com/content/rh717280508546r0/>. [24] Google Desktop, available at <http://desktop.google.com/>. [25] XML, Wikipedia entry, available at <http://en.wikipedia.org/wiki/XML>. [26] RDF W3C specification, available at <http://www.w3.org/RDF/>. [27] Apache Lucene documentation, available at <http://lucene.apache.org/java/docs/>. [28] Hemminger BM, Saelim B, Sullivan PF, Vision TJ, "Comparison of full-text searching to metadata searching for genes in two biomedical literature cohorts", JASIST, 58:14:2341-2352, 2007. <http://dx.doi.org/10.1002/asi.20708>. [29] Adobe Acrobat Review, <http://www.adobe.com/>. [30] Annotea Project, available at <http://www.w3.org/2001/Annotea/>. [31] XPointer W3C specification, available at <http://www.w3.org/TR/xptr/>. [32] Nature Journal Repository, available at <http://network.nature.com/tags/repository>. [33] BioMedCentral, available at <http://www.biomedcentral.com/>. [34] Faculty of 1000, available at <http://www.facultyof1000.com/>. [35] Diigo, available at <http://www.diigo.com/>. [36] OWL, available at <http://www.w3.org/TR/owl-features/>. Copyright © 2009 Bradley Hemminger |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/may2009-hemminger
|