D-Lib Magazine
March 1999
Volume 5 Issue 3
ISSN 1082-9873
Collaboration as a Key to Digital Library Development
High Performance Image Management at the University of Washington
Geri Bunker
Coordinator, Digital Library Initiatives, and
Interim Associate Director of Libraries for Resources and Collection Management Services
University of Washington
[email protected]Greg Zick
Professor, Electrical Engineering and
Director, Center for Information Systems Optimization (CISO)
University of Washington
[email protected]
Abstract
As readers of D-Lib Magazine know, the world of information systems and the ways in which scholars, students, and the general population find and use information are in rapid transformation. The combination of high-speed communications, open access protocols such as are used on the Web, inexpensive but high quality scanners and other digitization devices, and pervasive support for multimedia have opened a new world of information to wide and diverse populations. These phenomena are having a significant impact on how the university communicates and teaches, how successful it is in distance education and research, and how it collaborates with other sectors such as K-12, other higher education institutions, business and industry, government, and the general public.
This dynamic information environment brings major difficulties as well as opportunities. There is widespread recognition that the current Web is cumbersome to search and use, lacks standards and mechanisms for determining quality, and places the burden of successful access on the user. The ultimate value of digital resources to the user will depend upon the quality of the content, the organization, and the data management systems. There are many challenges to optimizing the processes of acquisition, storage, retrieval and utilization of digital information. Experience has shown that successful systems cannot be developed in a vacuum, but must be researched and designed together with users and domain experts. There is great value when systems researchers and developers collaborate with professionals who bring a long-standing tradition of focusing on organization, retrieval, management and use of information, namely librarians.
The University of Washington Digital Libraries Initiative is providing the context for effective and broad collaboration among faculty, engineers, students and librarians. This initiative is a focal point for the creation, use, and investigation of electronic information services, resources, and systems -- developed from a user's perspective. This paper reports on the progress of the project and describes the synergy created when engineers, information scientists, and librarians apply a user-oriented perspective to developing, organizing, and using digital collections and resources for research and instruction.
In this paper we discuss the current challenges and our methods for addressing them. We describe three aspects of the University of Washington Digital Library Initiative: the fundamental importance of collaboration to our work, including the unique and complementary roles of the collaborating partners; collections and activities; and an image archiving software package called CONTENT.
Fundamental Importance of Collaboration
How is the explosion of networked -- increasingly visual -- resources affecting education? How do learners, from novices to scholars, conduct research across the disciplines? How can we provide access to relevant yet comprehensive multimedia resources? What does it take to build good digital repositories? What does it take to build broadly useful and enduring digital libraries? At the University of Washington, researchers, developers and librarians are coming together and changing the way we do business to learn about these and other issues in digital libraries.
We believe in practical application as a requirement for learning. We are building useful testbeds to enable a continuous system of testing, feedback, analysis and improvement. It is not enough to have interesting collections, flexible, standards-based tools for management and access. We also need current knowledge of user communities changing needs and information-seeking behaviors and access to emerging technologies. As Don Waters, Director of the Digital Library Federation, stated, " an effort must be made to understand the ways in which users interact with systems, their needs in relation to new information types, and the functionality of these types in the emerging digital environment"1.
The collaboration in the digital library initiative has included work with the University Libraries, the departments of Electrical Engineering and Technical Communications in the College of Engineering, and the School of Library and Information Science. The development of CONTENT, the high performance image archiver (which is described below) was a cooperative effort between the libraries and the Center for Information Systems Optimization -- a lab in Electrical Engineering. Usability testing by faculty in Technical Communications and Information Science has already improved the Libraries new information gateway (also described below). Continuous improvement of our systems also requires that we undertake rigorous research on the information-seeking behaviors of our largest user-group, the undergraduates. Faculty in the School of Library and Information Science are interested in partnering in digital library development and contributing to our understanding of retrieval issues. Use of cognitive sciences in understanding the learning processes of both non-specialist and expert searchers is of interest. For example, one study that uses the CONTENT system will employ a work-centered framework to observe and analyze information seeking and searching behavior of undergraduates as they attempt to integrate visual media in their own research.
There is another requirement for progress, which is less tangible still -- and the difficulty of which is impossible to predict from case to case. No one organization or type of professional, working alone, has all the needed talents and resources. An appropriate deference to, and respect for, specialization is needed -- the scholar creates new knowledge, studies and teaches assimilation of the data. The artist creates, and teaches appreciation and techniques for creation of art. The engineer creates new knowledge and uses it to build and improve the tools. Librarians, curators and other information professionals learn how users approach questions, and then organize and teach access to the data. The required synergy can only come from bringing together people with the appropriate skills and vision. Each must comprehend and embrace diverse roles in learning and the application of learning to the creation of new knowledge. Respect and confidence in each partners skills and ability to succeed help to prevent turf-battles and to combat competition.
Basic to the success of this vision is tangible support for interdisciplinary academic activities; funding for staff and equipment, release time and rewards are needed to really weave information technology into the fabric of the academy. Information technology is rapidly changing collection development in libraries, as well as teaching and research across academia. It has the capacity to revolutionize peer review, publication, and other tenure-related activities. Unfortunately, within our embattled research institutions, actual interdisciplinary support is difficult to achieve. Our outmoded organizational structures and their established cultures are badly in need of transformation to cope with the rapid progress in technology. Competition for scarce resources tends to further polarize the stakeholder issues, masking their very real need to cooperate. Fortunately, collaborative efforts are encouraged and supported at the University of Washington.
Unique and Complementary Roles
The Libraries role -- information fluency for the life-long learner and widespread access to resources
The commitment to information fluency across many different constituencies means that academic librarians at the university acknowledge the art and science of collaboration, and its pivotal role in the transformation needed in higher education. When the librarian serves as liaison among different communities of interest, there is no skill more important than communication.
At the University of Washington, the best known Libraries collaboration to date has been the UWired Program, a joint program of the Libraries, Computing & Communication, the Office of Undergraduate Education and, more recently, Educational Outreach. UWired builds student and faculty skills with technology, and serves as a model program for focusing resources in a collaborative setting to support individual and interdisciplinary technology needs. We are enthusiastic about UWireds development of CATALYST2, an advanced suite of standards-based applications that are configurable to disciplinary needs.
Faculty and teaching assistants make much use of the UWired Center for Teaching and Learning Technology. Among the other top-notch platforms for instructional technology found at the center, users can now find a CONTENT workstation as part of the Libraries' partnership with the Center for Information Systems Optimization (CISO). Here users can learn to digitize and manage their visual resource collections as well as integrate them into their research and curriculum.
To provide broad and useful access to electronic resources, whether commercially acquired or locally developed, the University Libraries is migrating all electronic resources to the Web in the form of the University of Washington Information Gateway. The Libraries have built an SQL-based digital registry to which metadata is mapped from the Innovative Interfaces library catalog. As mentioned above, usability testing provided by the College of Engineering Technical Communication program was instrumental in the early design. The Gateway is available at < http://www.lib.washington.edu/ >.
In common with other universities, the Libraries provide Web access to commercial "electronica", abstracting/indexing databases, catalogs and websites. To extend this, the Libraries have begun to digitize the unique holdings and primary sources held by the Libraries and by various university departments. There is a wealth of material in both library and faculty collections, and access to visual images and multimedia is increasingly crucial to comprehensive research in all domains. We are displaying and managing these collections with the image archive package known as CONTENT, which is described below.
CISOs role -- continuously improve the multimedia tools for specialized and interdisciplinary use
The Center for Information Systems Optimization (CISO) is focused on the application of multimedia technology to disciplines that are visually based. Interest in multimedia spans almost all subject domains, and such material is now prevalent across the board. Early experience includes some aspects of medicine, art and architecture, science and engineering. The interest is to serve both instruction and research: building digital teaching and research collections and testbeds by enhancing multimedia software systems for archiving, retrieval and display.
The initial collaboration with the Libraries began when Greg Zick, in search of a testbed collection for an early version of CONTENT, suggested partnering to provide digital access to 26,000 images from a theatrical photograph collection. This led to a continued process of building collections as testbeds for CONTENT and providing electronic access to otherwise hidden treasures in University Libraries Special Collections. Feedback from users and librarians enables CISO to respond to the needs of faculty, researchers, and students as well as to the librarians who are trying to provide useful organizational strategies to them.
Collections and Activities
CISO and the University Libraries are involved in many digitization projects. A tour of the University Libraries Digital Initiatives web site at < http://content.lib.washington.edu/ > will show what is in production at the University of Washington today.
Collections of the Pacific Northwest
One of the main objectives of the digitization efforts is to expand access to a broad category of high-quality resources related to the Pacific Northwest, for the public and K-12 communities as well as to the campus. We hope this extension of services to new sectors of the citizenry will result in increased use of unique and significant materials. The University takes seriously its obligation to support life-long learning; we hope that by providing the tools, we help to enrich appreciation of our regions history, scientific and artistic contributions as well as our diverse cultural heritage. Materials in the collections include maps, guides, photos, diaries, manuscripts, moving images, oral histories, and instructional slides.
Two early offerings serve as the beginning of an archive with a "digital Northwest" emphasis. They are the Asahel Curtis Photographic Collection and the William Meed Photographic Collection, which are housed in the University Libraries Special Collections, University Archives and Manuscripts Division.
A third offering is the Jacob Lawrence Digital Collection, which is a prototype of the digital archive we are in the process of building with the not-for-profit Jacob Lawrence Catalogue Raisonée Project. Lawrence is an internationally acclaimed artist whose paintings document the African American "migration north" and the period known as the Harlem Renaissance. When the project is complete, it will allow access to approximately 1200 digital reproductions.
This project exemplifies the many connections among various communities, and it shows the potential of digital libraries for cross-domain study and cross-sector services. A decision was made to publish the digital prototype when the Henry Art Gallery on the University of Washington's Seattle campus hosted a large exhibition of Lawrences work during the summer of 1998. A kiosk version of CONTENT was developed for the exhibition hall, allowing search and retrieval of images and information about Lawrences works and Web pages describing the exhibit, the project,3 and the partners. University of Washington faculty in the 1998 "Bridge" program (an orientation for entering athletic and Educational Opportunity Program students) led their classes on a tour of the exhibition, and then used the CONTENT digital prototype to retrieve images and analyze sociological themes in the works.
Happily, further connections indicate we will soon be working across even more sectors. An educational resource component for delivery to K-12 instructors is currently under construction. Videotaped interviews with the artist can also be digitized and managed by CONTENT. The University of Washington Press has contracted to publish the two volume critical monograph and catalogue raisonée.
In development is the "American Indians of the Pacific Northwest" virtual collection, being created in collaboration with Seattles Museum of History and Industry, and the Eastern Washington State Historical Society. The University Libraries received Library of Congress/Ameritech funding to digitize 2,500 images and 6,000 pages of text on the history and culture of the native peoples of the Pacific Northwest. Locally the materials will be archived and accessed through CONTENT; the repository will become part of the Library of Congress's American Memory site in the autumn of this year. This application is encouraging the development of "smart objects" in the CONTENT system -- text which "knows" it must be scrolled, pictures which "know" their frame sizes and video/audio objects that actually play upon selection.
University of Washington Libraries
Asahel Curtis Collection
Henry Art Gallery
Jacob Lawrence ExhibitFigure 1. CONTENT user collections Slide collections for education and research
While library and museum materials are being digitized, the faculty has discovered the Webs great advantage over analog slide projection in the classroom. One of the lessons learned within the Museum Education Site License Project4 (MESL) was, "Because faculty content needs can be robust and shifting, a digital image distribution scheme will almost certainly also need to give faculty the option of integrating locally produced material. (Many MESL universities reported having to supplement the MESL database with custom images drawn from their slide libraries.) Future systems must be both extensible and easy to supplement."5
Three archives represent faculty teaching and research collections and serve as testbeds for collaborative digitization of instructional materials of interdisciplinary interest. The first to be opened for public view, "Cities and Buildings," contains over 4,000 images depicting world architecture. Begun as a project of the Center for Advanced Research Technology in the Arts and Humanities (CARTAH), the original design for the project sprang from graduate student and faculty interest in making the visual resource collection more accessible to students. As one of the original website designers states, "Use of photographs on-line leads immediately into legal thickets, so (we) adopted a model of using only images contributed by the holder of the copyright for use in on-line education or older materials clearly in the public domain."6 Today those images are also being supplemented with material borrowed from the University of Washington College of Architecture and Urban Planning, and the School of Art Slide Libraries, each with written permission of the original donor.
The designer describes the set of applications and scripts used to begin the original project as a "boutique" application, and explains that "Unfortunately, (the original version) is a static website of geographically oriented lists with no search capacity and limited meta-data. Not surprisingly, it has reached some very real practical limits." The Cities and Buildings Architectural Photograph Collection represents the migration of the successful web site to CONTENT. This enables students and colleagues worldwide to access -- through full-text searching of Dublin Core (DC) metadata -- high-quality images of structures important for their architectural, artistic and historical content. Searching the repository by itself will retrieve images and display their vernacular field labels that have been mapped to DC through collaboration among scholars, library staff and graduate students in library and information science, art and architecture. Searching the archive in combination with other databases will produce relevant records displaying their DC-tagged defaults. This collection is currently slated to grow by over 25,000 images contributed by scholars in diverse fields from around the world. Most critical to the growth of the collection, the distributed nature of CONTENTs acquisition and maintenance facilities ensures that the collection can be continually enhanced and maintained by the slide donors themselves.
Other projects to digitize slide collections are also underway. The University of Washingtons Astronomy department shares a collection of 35 mm slides of stars which are currently being digitized and catalogued by students of astronomy working from distributed input stations across campus. One botany professor has compiled over 4,500 slides examining the plant succession after the 1980 earthquake on Mt. St. Helens; that repository is also being prototyped for development into a fully-searchable CONTENT database for teaching and research.
Content Design and Features
The CONTENT database system for visual media
Cost studies by the Museum Education Site License Project examined the various cost centers involved with digitization projects on campus, and determined that functionality "appears to be the largest cost center because it represented the time spent constructing a local application for the delivery of data to users on each campus. This involved not only the design of a delivery system, but also working with application tools such as search engines that act on the data." 7 We are fortunate at the University of Washington to benefit from the multiyear development already represented in CONTENT version 2.1. CONTENT is designed for large archives of digital assets. It is a highly scalable database system, managing resources which can grow from tens of objects to millions of objects. A full description of CONTENT and beta software can be obtained at: < http://content.engr.washington.edu/ >.
At the University of Washington, the payoff for everyone is evident in the resulting software and the databases we are building. CONTENT is a client-server application with full-text, concept-based searching, providing storage and access to visual media. CONTENT is fast -- both in database building and in searching -- able to search a database of millions of objects and identify desired items in less than one second. CONTENT has rich metadata support and uses open Web-based standards. Its Web-based interfaces are easy to use for the database administrator and searcher.
Most important for scalability and sustainability, the design of CONTENT allows distribution not only of storage, but also of cataloging and scanning tasks. It supports multiple, asynchronous database building so that archivists, librarians and scholars can collaborate to define rich and complex metadata. Hierarchical thesaurus function has been implemented and is being enhanced. The dictionary is an auto-generated list of all words that exist for all fields. Controlled vocabulary and thesaurus functions are available. The addition or modification of objects is secured by password. Item-level Dublin Core records are supplemented with collection-level records in both MARC format (in the library catalog) and automatically cross-walked SQL records in the Digital Registry. Expensive professional cataloging traditionally provided by libraries can be supplemented -- or replaced by -- distributed metadata description.
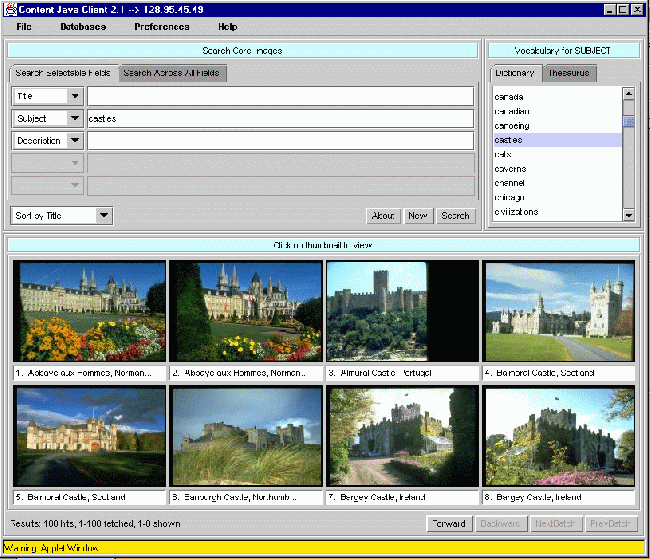
The user interface
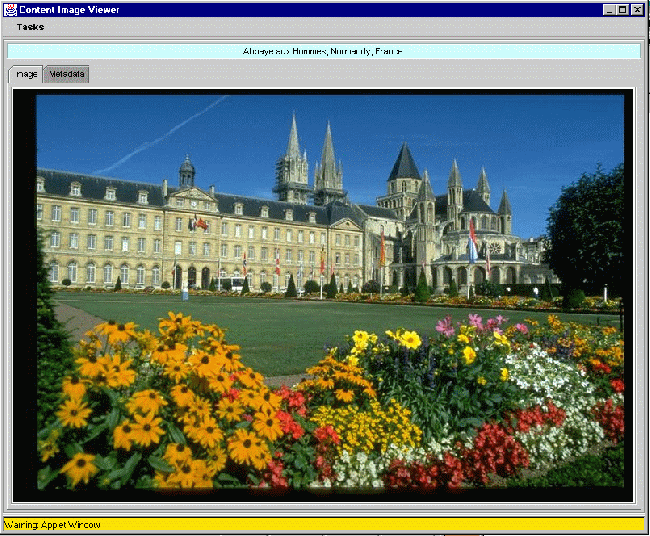
The software package consists of a server, which can run on NT or Linux, user clients in Visual Basic or Java, an image acquisition application, and administrative tools. The user interface is shown in figure 2. The search terms are entered in one or more of the metadata fields. Each field is a full text search and can be supported by a dictionary and thesaurus. Objects found in the search are displayed as thumbnails. Clicking on the thumbnails brings up the service image (shown in figure 3). The metadata for each image is stored separately and is linked through internal pointers. The description is fielded, as described above, and is encoded in html allowing active links to other web pages. Later this year we will fully implement XML encoding according to the Resource Description Framework8 (RDF), creating namespaces deemed necessary to resource discovery in various disciplines and support a number of object players including one for compound documents.
Search fields are definable by the archive administrator and support the Dublin Core metadata elements as a default. Fielded and full-text Boolean searching are supported as is searching across multiple databases. Any or all fields can have an associated vocabulary, controlled at input through a validity checking mechanism.
Figure 2. CONTENT Search Client
Figure 3. Full image display
An additional feature popular with users is the workbox function. This feature is implemented such that a user can select a set of images and store them in a named workbox. The ability to save the results of searches allows the user to access these results in a variety of ways at a later time. In addition to being recalled later, this list of images can be saved as html and sent to a colleague or used in CONTENTs slideshow mode for a presentation. The slideshow mode supports full screen display of a sequential list of images. Different versions of the presentation can be formatted and saved.
Acquisition and administration of CONTENT databases
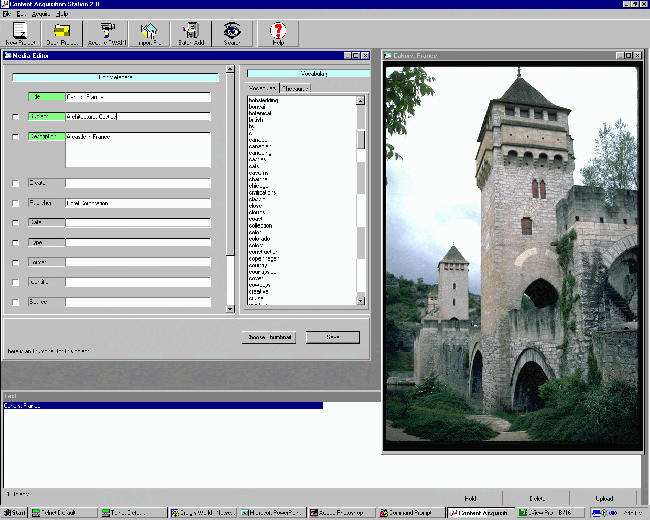
Figure 4. CONTENT acquisition station
The acquisition station is shown in figure 4. This Visual Basic package supports scanning of images, slides, and negatives from any TWAIN-compatible input device. It supports multi-resolution scanning for screen optimization and for archiving purposes. The station performs automated thumbnail generation. The acquisition station will also allow batch import from a file directory containing previously scanned objects and can be used to dynamically add or edit database items.
As mentioned above, the acquisition station offers the option of validity checking to enable the building of controlled vocabulary on selected metadata fields. It also allows the input technician to override the controlled list but reserves the final oversight for the database administrator. Images are uploaded to the server through negotiation with Windows NT security. Because of the distributed design of the CONTENT system, simultaneous distributed metadata entry is possible and controllable. Any PC on the Internet could potentially load the application and operate as an input station.
As has been described conceptually above, CONTENT supports fully configurable metadata. Technically, the authorized administrator names the field, defines its type and characteristics, using as a default a Dublin Core template. Fields are repeatable, and multiple fields can be mapped to a single DC tag. The administrator may choose any term as a visible field label, with the DC tag only visible in multiple database searches.
Administration of CONTENT databases is done through a standard graphical browser. The database administration Web interface allows complete database maintenance to be performed remotely and without costly downtime. Through the administrator Web page, you can rebuild text indexes in real time. There is a gatekeeper function, which requires administrative approval for all additions and changes to the database. To facilitate metadata management, there is a global search and replace. Finally, you can import or export from delimited ASCII files.
Outreach
Because CONTENT is built on open standards, it has been possible to integrate it across several platforms and with other useful local and commercial applications. Originally built on Unix, CONTENT was ported to Intel platforms under NT, in line with the trend on campus compelled by price/performance advantage. A sizable grant from the Intel Corporation, which was shared campus-wide, has enabled us to deploy CONTENT on Intel computers within the Libraries, in partnering faculty offices, in CARTAHs computing lab as well as in UWireds Center for Teaching and Learning Technology. This award enabled us to address in part the comparative infrastructure disadvantage -- compared with science and engineering -- with which humanities departments are all too familiar.
In addition to those housed at the University of Washington, CONTENT is being used at several other locations. The National Park Service is archiving materials from the Klondike Gold Rush. These are to be made available at the Klondike Gold Rush National Historical Park in Seattle. Another application is the Japanese American cultural heritage project known as the Densho Project. The local effort in Seattle has collected more than 70 video interviews with Japanese Americans who lived on the West Coast during World War II. This video footage, along with a large set of support documents will soon be cataloged in CONTENT.

National Parks Service
Klondike Gold Rush National Historical Park, Seattle
Densho: The Japanese American
Legacy Project
Video historiesFigure 5. Seattle Area projects
Metadata consensus building
For better or worse, todays technology enables virtually anyone to publish digitally. Consequently, the need for better navigational and organization methods and tools grows. The roles of the technologist-as-tool-builder and the information professional-as-content-organizer complement each other in expanding ways.
With the availability of inexpensive scanning equipment and the popularity of web-based publishing, a major challenge of our time is to harness the power of metadata to enable access. This is increasingly important as we reach out to non-specialist users within and outside of the academic community. In order to enable sharing of resources across subject domains, formats, databases, servers and institutional "boundaries", the Libraries and CISO promote adherence to and development of international standards. With regard to metadata, for example, we have incorporated a customizable Dublin Core template into the CONTENT acquisition module. We rely on the continuity of the base descriptors to provide the user with more comprehensive resources while insuring a more precise retrieval set.
In "A Common Model to Support Interoperable Metadata"9, Bearman, et al. discuss the progress and challenges in the Dublin Core communitys efforts to come to agreement on the semantics of the element set. They note, "It is hoped that collaboration over the coming year will result in agreed semantic and syntactic conventions that will support a high degree of interoperability among these communities, ideally expressed in a single data model and using common, standard tools."
By negotiating until we understand the scope and depth of our common ground, we strive to reach this level of consensus in our digitization projects. CONTENT has been designed to enable interoperability in many ways. The Dublin Core is the set of descriptors which appear when searching across databases. When searching one database, each field tag may be displayed as a customized label, and of course fields are repeatable and most are optional. Although the issues are fraught with complexity, catalogers and faculty from the various disciplines work to ensure their data will be useful within and outside of their own field of study; to do this, they must create a common understanding of the basic descriptors used. Then they negotiate the "behind-the-scenes" mapping of the 15-element set to their chosen visible, vernacular terms.
As stated in the Museum and Educational Site Licensing Project (MESL), "An important issue for MESL, which needs to be considered for any future distributions of images and metadata, was how to seamlessly integrate data from one repository into a variety of customized deployment systems. During both years of MESL museums used the MESL data fields inconsistently."10 Although CONTENT allows aliasing the DC labels, authors must have a common understanding of the hidden field names in order for the default descriptors to work in multi-database searches. This practical, local application of international standards is where the ability to reach common ground is really put to the test.
As with so many issues, the state of the technology is not in and of itself the lynchpin of success. Political and cultural diversity is inherently challenging; different subject areas "jargonize" terminology to serve their own need for specificity. A simple fact of interdisciplinary life is that identical material is analyzed by divergent communities using varying language. Whether local communities of interest are able to interoperate can only be shown by collaborative building and managing of real-life applications, as shown in CONTENT development across our region. Likewise, the true test of the robustness of emerging standards is in global communities cross-sector and inter-institutional collaborations such as the Consortium for the Computer Interchange of Museum Information (CIMI) testbed11, and the Museum and Educational Site Licensing Project.
Future Focus -- Expanding the Partnership
As is common throughout higher education today, at the University of Washington instruction and research strive to be increasingly experiential, interdisciplinary, and interactive. The use of visual resources and digital technologies is exploding. With the inclusion of our newly redefined School of Library and Information Science (SLIS), we are expanding and deepening our academic partnerships. SLIS brings to the table the rigorous research and scholarship needed to sustain continuous improvement of our tools and services.
The University Libraries, SLIS, and the College of Engineering have proposed a university-wide Center for the Digital Library. The centers vision is to provide a clearinghouse of expertise that can bring to bear state-of-the-art technologies for every discipline in building cross-domain resources. Our vision weaves together building resources and services with research and development, using local and global experts in database construction, vocabulary building, and usability testing.
The mission of the center will be to improve delivery of the universitys resources and services to the campus community and across regional sectors. The center will conduct its own research and development to further information fluency for the entire K-20 community. We are particularly interested in image retrieval strategies and skills in these communities, and in providing high quality digitized collections organized to optimize the information-seeking strategies employed by these communities.
This symbiotic relationship between building digital collections and research in information science is key. As the early work of the Libraries and CISO shows, digital collections and services provide a real-world testbed for research, which in turn provide insights and mechanisms for improving and expanding collections and services.
Our vision is to extend these working collaborative relationships into a more formal structure in the form of the proposed center. We have seen the benefits of cross-disciplinary collaboration and are continually refining our approach in order to optimize resources and, most importantly, make this ever-expanding set of collections and tools widely and efficiently available. The formation of a university-supported Center for Digital Libraries would provide the tangible support needed for continued success of the projects, and would mark the institutions commitment to transform the academy through a progressive, inclusive approach to technological advance.
Notes and References
Links to specific notes are located throughout the text of this article. The complete listing of notes for the article are at < http://www.dlib.org/dlib/march99/bunker/gbnotes.html >.
Copyright © 1999 Geri Bunker and Greg Zick
Top | Contents
Search | Author Index | Title Index | Monthly Issues
Previous Story | Next Story
Home| E-mail the EditorD-Lib Magazine Access Terms and Conditions
DOI: 10.1045/march99-bunker