D-Lib Magazine
July/August 2010
Volume 16, Number 7/8
Table of Contents
nature.com OpenSearch: A Case Study in OpenSearch and SRU Integration
Tony Hammond
Nature Publishing Group
t.hammond@nature.com
doi:10.1045/july2010-hammond
Printer-friendly Version
Abstract
This paper provides a case study of OpenSearch and SRU integration on the nature.com science publisher platform. These two complementary search methodologies are implemented on top of a common base service and provide alternate interfaces into the underlying search engine. Specific points addressed include query strings, response formats, and service control and discovery. Current applications and future work directions are also discussed.
Introduction
This paper provides some details on the nature.com OpenSearch [1] service that Nature Publishing Group (NPG) launched early Q4, 2009 and which may be of interest to other implementors. This was the result of a short (2-month) but intense development following an earlier incubator proof of concept. The impetus for this project was to provide a new resource discovery channel for nature.com — a structured search facility using the emerging digital library standard for information retrieval: SRU [2]. Fig. 1 shows a remote search interface to this service using a standalone desktop widget.
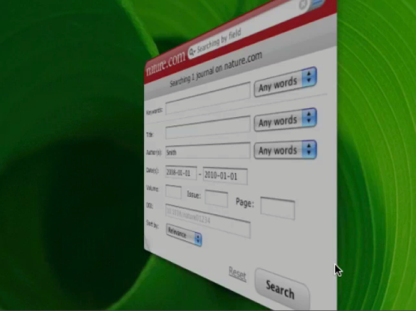 Fig. 1: nature.com OpenSearch accessed remotely via a desktop widget.
Fig. 1: nature.com OpenSearch accessed remotely via a desktop widget.
The reasons for seeking to develop an SRU service were various. We wanted to be able to provide an off-site search functionality to complement our hosted search. We were also accustomed to fielding queries about our support for Z39.50 [n1] with all the promise of federated searching that Z39.50 extended. Concurrently we had been following the development of SRU as a next generation replacement for Z39.50. This Web-based technology mix (XML over HTTP) projected a much better return on investment for us than building (or commissioning) a service based on what is essentially a pre-Web technology — one with its own wire protocol and architectural reference points. Further, the work on search web services in OASIS augured well for SRU becoming a standards-based query language and search protocol. And at the same time although we were disposed to adopt the newer semantic search alternatives (e.g. SPARQL [n2]) we judged that we were not ready to make that leap in a single tech iteration. That is, we would confine ourselves at this time to a traditional records-based search rather than any more granular level of results.
So, SRU it was.
As the project developed, however, we found that our attention shifted somewhat from the query axis that is SRU's main selling point and came to rest more on the structured result sets and on the advantage to remote applications that this affords. That is, we started to focus more on the OpenSearch [3] methodology beyond the SRU protocol as being the more accessible search paradigm for applications at large. The nature.com OpenSearch implementation makes use of both technologies: it builds on a solid SRU base service but also presents a rich set of OpenSearch-type result formats. Both interfaces are equally supported in nature.com OpenSearch.
Technologies
In the Jan/Feb 2009 issue of D-Lib Magazine [4], Ray Denenberg gave an update on the work ongoing in the OASIS Search Web Services Technical Committee [5]. This work aims to standardize SRU and to reconcile it with the differently originated OpenSearch as well as with other records-oriented search methodologies.
SRU is an initiative to bring Z39.50 functionality to the Web and is firmly grounded in both structured queries and responses [n3]. Specifically a query can be expressed in the high-level query language CQL [n4] which is independent of any underlying implementation. Result records are returned using any registered W3C XML Schema format and are transported within a defined XML wrapper format for SRU. The SRU 2.0 draft provides support for arbitrary result formats based on media type.
OpenSearch by contrast was created by Amazon's A9.com [n5] and is a simple means to interface to a search service by declaring a URL template and returning a common syndicated format. It therefore allows for loosely organized result sets while not constraining the query. There is support for search operation control parameters (pagination, encoding, etc.), but no constraints are placed on the query string which is regarded as opaque. OpenSearch is thus a means to interface to arbitrary search APIs (both standard and proprietary) and to retrieve results using a common list-based format. OpenSearch is a plug-and-play technology.
One can summarize the respective OpenSearch and SRU functionalities as shown in Table 1.
Table 1: Functional comparison of OpenSearch and SRU

Implementation
The timing for this project was opportune in that we had already been running for a couple years and more a prototype instance of an SRU server (with basic CQL capability) as a proxy interface to our existing ASP-hosted search. This afforded us some ready familiarity with the record formats that we would ultimately be delivering and provided a useful reference implementation for development purposes. During this same period we had also settled on MarkLogic Server as the basis for our XML repository with one of the first services implemented being a new search application for nature.com. A further timing fortuity was the concurrent development through OASIS of SRU 2.0 with its support for OpenSearch and the willingness of the software package developer to make changes for us to accommodate this new functionality.
As noted above, our XML records to support resource discovery are now being maintained in a MarkLogic instance (actually three instances as dictated by our 3-tier deployment strategy: test, staging and live). We had initially been worried that we might have to start with XQuery from scratch, but we already had XQuery library components available to us that supported our existing user-facing search service. We were also concerned about their generality as implemented but ultimately decided that they would be fit for purpose as most queries would necessarily be forms-driven and so would be fairly simple (i.e. a flat set of boolean-connected search clauses). We would thus leave it to the CQL parser to handle any query complexity.
For our implementation we chose to use the 'oclcsrw' package [6] from the SRW/U open source project [7] at OCLC. This was an implementation of the SOAP-based SRW web services protocol that also supported the REST-based SRU protocol. While we had no especial interest in SRW we were not averse to having the wider generality it would afford as long as it did not cause us any additional overhead. In practice, the SRW layer was largely transparent and we were able to focus on the SRU functionality alone.
SRU provides for three service functionalities: description ('explain'), search ('searchRetrieve'), and browse ('scan'). Due to time constraints we decided not to support a general 'scan' facility, and instead to restrict our application to a very limited 'scan'-type functionality for one index only which would at least allow downstream applications to list out our full product set (or list of journals).
The 'oclcsrw' package is based on SRU v1.1, which is the last SRU version to define an SRW interface. From the SRU point of view the main difference with respect to the latest stable version v1.2 is its support for 'sort' which must be handled by the URL parameter 'sortKeys' and which is a prescription for operating a sort function over the XML result set records. By contrast SRU v1.2 supports sorting by adding this into the CQL grammar so that it can be handled at the language level and is independent of any particular implementation.
The standard 'oclcsrw' package was built to deliver only SRU-based XML as an output format, whereas if we were going to fulfil our wider OpenSearch ambitions we would need to support other list-based XML formats — notably RSS and Atom — and text formats — notably HTML and JSON. We were fortunate in gaining Ralph LeVan's attention at OCLC and he was also interested in adding support to the package to allow alternate formats to be returned according to media type, either by standard HTTP content negotiation or explicitly using the new SRU 2.0 parameter 'httpAccept'. This was timely for us and we are very grateful for his help in adapting the software at short notice. The simple solution he implemented was to make a configurable (by properties file) pairing between media type and XSL stylesheet which transforms the output SRU/XML. Table 2 shows the media types supported by nature.com OpenSearch.
Table 2: Media types supported by nature.com OpenSearch
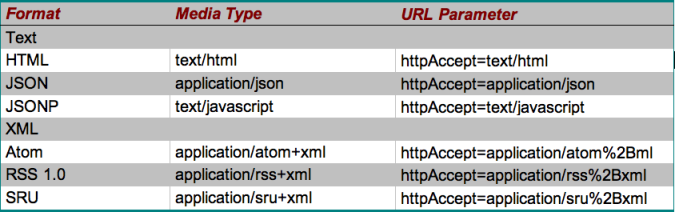
We have included the familiar OpenSearch syndication formats: Atom and RSS [n6]. In addition to this we have included JSON as a simpler transport alternative to XML, and a variant form — JSONP (JSON with Padding) — to support cross-site scripting. The JSON is structured as a direct mapping of the Atom feed, with a couple of obvious changes due to JSON limitations (e.g. use of array property values where property key must be unique and cannot be repeated).
Functionally the nature.com OpenSearch service presents two distinct interfaces as shown in Fig. 2.
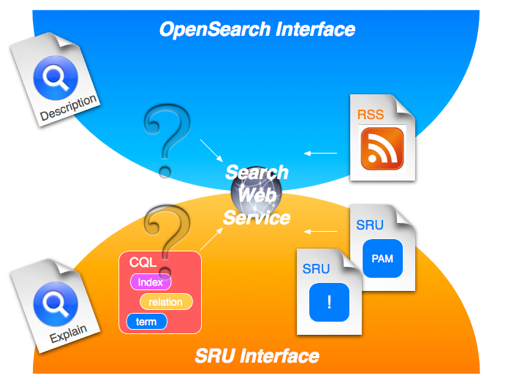 Fig. 2: Search web service interfaces supported by nature.com OpenSearch.
Fig. 2: Search web service interfaces supported by nature.com OpenSearch.
Some of the observations presented above were first outlined in a couple of posts to CrossTech last year where further details may be found [8,9].
Query — Resource Discovery
The big thing that SRU brings to search is the query language CQL [10], which is a development based on Type-1 queries [n7] from Z39.50. In essence, CQL is a very simple grammar being nothing more than a boolean-connected set of search clauses (which are simple triples of index, relation and term). Search clauses can be nested. Indexes and relations are drawn from publicly registered 'context sets' which allows for a general extensibility of the language. They are also namespaced by context set and queries can thus contain a mix of elements from different context sets.
To relate CQL to the Lucene QueryParser API [11] (another well-known query grammar) we would note that CQL presents a more uniform grammar with a larger set of elements and that it has a clearer recognition of relations as well as making use of namespacing to import indexes and relations from publicly registered context sets. By contrast, the Lucene syntax is simpler (but less expressive) and certain constructs (e.g. 'field:term') are more commonly encountered in proprietary syntaxes offered by familiar search engines such as Google. However, the Lucene API does not use publicly declared index sets so indexes are specific to the particular implementation. Relations insofar as they are defined are fixed by the grammar and are less regular in form.
OpenSearch knows nothing of structured queries and is really confined to simple keyword search. It is possible to send a CQL query string to an OpenSearch server, as long as the client is aware of CQL. A server expecting a CQL query will succeed if it is a valid CQL string, or in the following cases (see A and B in Table 3) where it may coincide with a valid CQL string: simple bare word or quoted string. For more complex cases — unquoted strings and mixed quoted strings (see C and D in Table 3) — the CQL parser will fail [n8]. Table 4 shows how keyword queries may be mapped into CQL queries.
Table 3: Analysis of valid CQL query strings

Table 4: Keyword query strings mapped to CQL

It was our intention to serve two different communities: CQL-aware users and non-CQL-aware users. Note that our default query parser was CQL-based so we had a potential problem dealing with non-CQL users. We therefore used a trick to manage CQL and non-CQL query strings. We hardwired a parameter 'interface' with value 'opensearch' into our OpenSearch URL templates so that we could test for this and apply some string preprocessing to turn a keyword list into a CQL string. But this gave rise to a further problem. If we had a CQL-aware OpenSearch request how could it signal that it was sending a valid CQL string and did not require preprocessing since the 'interface' parameter was hardwired? The answer we came up with was to make use of an optional SRU 2.0 parameter 'queryType' with value 'cql' which an application could use to flag that while this was an OpenSearch interface it was indeed talking CQL. But the OpenSearch parameters are fixed by the specification and any new parameters need to be defined through an OpenSearch extension. We thus defined such an OpenSearch extension for SRU (see Annex A).
Results — Resource Descriptions
Native SRU record descriptions are serialized in XML and constrained by a W3C XML Schema. We already had a fairly clear idea of the record data we were looking to return: a core set of bibliographic metadata. We had earlier implemented an OAI-PMH service for nature.com [12] and that likewise required an XML response format governed by a W3C XML Schema. At that time we had turned to PRISM Aggregator Message (PAM) format [13] as this had a very convenient schema definition with a conventional article head/body structuring and we could make use of the head element for our bibliographic data and simply leave the body element empty. The elements supported by PAM covered in large part the DC and PRISM terms that we were also routinely providing through our RSS discovery channel. We thus thought to return the same PAM record structure for SRU.
As noted earlier, however, we had become especially interested in the possibility of returning OpenSearch-style, simple list-based formats such as RSS. This has the clear merit over any given XML schema in being well supported by software libraries and lends itself well to AJAX applications. Based on an earlier proposal from the OASIS work we sketched out some response formats for RSS, Atom and JSON [14]. Our reference was the Atom feed with the RSS being a simple translation. Both Atom and RSS as XML applications already have their own well-defined structures, while JSON is just a data object notation and has no predefined structure. We decided to base a JSON profile on the Atom structure since we were taking that as our reference.
One issue we faced was a consequence of the direct mappings we established between the SRU response format (in particular the record data structure) and the OpenSearch list-based formats. These mappings resulted in the actual data properties returned being 'buried' within the response as they are deeply nested within the record data structure. In fact in our case (using PAM) there was a 4-level deep nesting in the record data structure. We felt that we needed both to honour this nesting in the output format for strict compatibility with the regular SRU response, while at the same time allowing for a 'freer' structuring whereby the data properties themselves could percolate up to the topmost layer in the record data element. For this purpose we noted that there was an existing SRU parameter 'packing' which could assume two values: 'xml' and 'string'. We decided to overlay a provisional third value 'unpacked' to meet the case where data properties were free to migrate to a higher level for easier data access [n9].
By comparison with SRU with its 'closed' XML schema the OpenSearch formats are 'open'. However, even though the OpenSearch formats are open the schema remains a chokepoint in determining which data can be passed back from an SRU application. This is something we will need to revisit as we begin to ramp up the data volume in subsequent releases. One possibility would be to circumvent this restriction by implementing a lax schema which would effectively pass any data through. An alternative would be to use the SRU 'extraRecordData' element to bundle additional data along with the main result.
Service Control
Diagnostics handling is one of the key strengths of the SRU protocol. Following on from its Z39.50 legacy, SRU goes so far as to define in excess of 100 separate diagnostic message conditions [15] and returns the messages within the standard SRU/XML wrapper.
OpenSearch, by contrast, pays no heed to diagnostics handling. Nevertheless, for completeness we decided in nature.com OpenSearch to pass the diagnostics messages through to any OpenSearch-type format. This example shows the diagnostics message for an unsupported index as passed through to an Atom feed:
<feed ... xmlns:diag="http://www.loc.gov/zing/srw/diagnostic/" ...>
...
<sru:diagnostics>
<diag:diagnostic>
<diag:uri>info:srw/diagnostic/1/16</diag:uri>
<diag:message>Unsupported index</diag:message>
<diag:details>Index "foo" not supported</diag:details>
</diag:diagnostic>
</sru:diagnostics>
</feed>
Service Discovery
OpenSearch and SRU have their own separate ideas about service discovery. OpenSearch comes to this very much from the Web way of doing things and specifies the addition of an autodiscovery link in a Web page to signal the presence of an OpenSearch service. This is a standard practice in the blogging world for notifying users and applications of related RSS feeds. The inclusion of a link element allows an OpenSearch-aware application to sense the link and act on it accordingly. Some browsers (e.g. Chrome, Firefox, IE7+, etc.) can detect this link and offer to add the OpenSearch to their list of search services. This method is very supportive of dynamic service configurations.
The OpenSearch autodiscovery link points to an OpenSearch description document which details various aspects of the service. Predominant are URL templates for the various result formats supported (by media type), as well as contact details, rights information, input/output encodings, etc. The nature.com OpenSearch service is described by an OpenSearch description document [16].
By contrast, the SRU method relies primarily on registry records which is largely an 'out-of-band' solution. Again a service description document is made available — this time through the 'explain' service. This can be generated by calling the 'explain' operation directly or more simply by calling the service endpoint with no parameters. This is similar to the OpenSearch description document but is more skewed towards cataloguing the indexes and relations available for querying, the result being an XML record in SRU format. The nature.com OpenSearch service also provides such an 'explain' record [17].
The service discovery model for SRU follows Z39.50 practice, whereby these 'explain' records would be aggregated into 'explain' databases, also queryable by SRU. As such, although it provides for distributed discovery it is not nearly so Web-friendly as is OpenSearch which provides autodiscovery links on individual Web pages. New features for the forthcoming SRU 2.0 spec to consider are autodiscovery links and result formats (by media type). Our own approach has been to preempt SRU 2.0 and to provide autodiscovery links on our Web pages for both OpenSearch description documents and for SRU 'explain' records:
<link rel="search" type="application/opensearchdescription+xml"
href="http://www.nature.com/opensearch/opensearch.xml" title="nature.com" />
<link rel="search" type="application/sru+xml"
href="http://www.nature.com/opensearch/request" title="nature.com" />
(Note that SRW also supports a standard web services WSDL description file for SOAP clients but we shall not discuss that further here.)
Applications
Since we deployed nature.com OpenSearch we have begun to reposition it as a common public API for use both by our own hosted and standalone search applications as well as by public applications. Annex B provides a cheatsheet which summarizes this API.
The 'oclcsrw' package implements a native user interface via a search form which is built directly from the service description in the 'explain' record and is useful primarily for test purposes. Such a form is available at the nature.com OpenSearch service endpoint [18] — see Fig. 3.
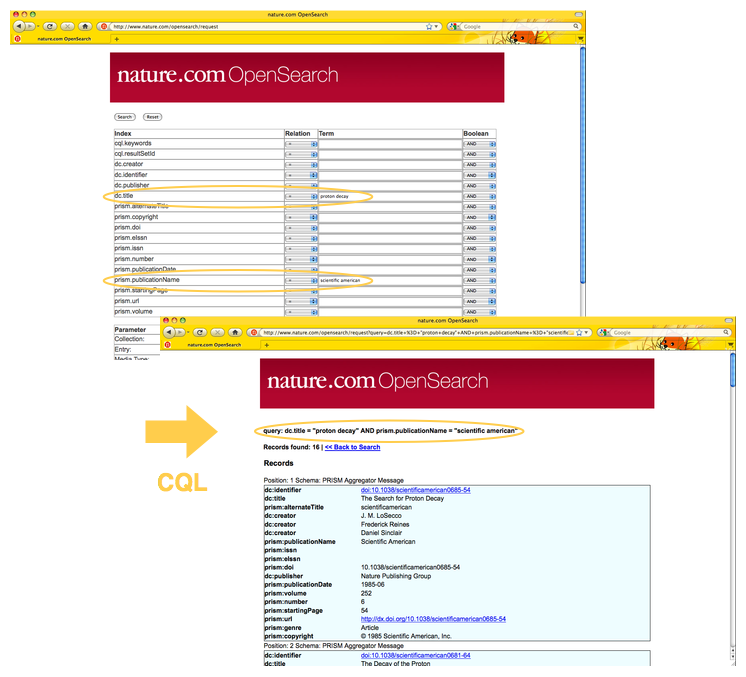 Fig. 3: nature.com OpenSearch form interface.
Fig. 3: nature.com OpenSearch form interface.
Since SRU provides for both structured query and structured result sets it is readily used for remote searching or search 'at a distance'. A client application can collect the user's query parameters, bundle them up together on a URI querystring, send that querystring on to the server, receive in response a content entity body with result sets in a structured markup, and finally interpret those results for an appropriate user presentation.
Our standalone client-facing applications have thus far leveraged two different OpenSearch-style media types: RSS and JSON.
To coincide with the initial launch we developed a 'nature.com search' desktop widget [19] which uses the RSS feed (although we could equally have used the Atom or even the native SRU/XML format). Actually we developed two parallel versions of the widget, one for Apple Dashboard (for Mac) and the other for Yahoo! Widgets (for Mac and PC) which are available from Apple Downloads [20] and the Yahoo! Widgets Gallery [21], respectively. The Dashboard version makes use of the WebKit engine while the Yahoo! version uses the Konfabulator engine. Our developer did an excellent job in aligning both presentations and functionalities. (See the YouTube screencast [22] for a demo of the widget in action.) Widget features include simple/advanced search, custom search collections, and a 'peek' panel to show the actual CQL query string sent to the server. Fig. 4 shows a composite of the various widget panels.
More recently we deployed a search gadget for Nature Network's Workbench [23] which uses the JSON response format. This supports a simple search only at this time, although is readily extensible to a more advanced fielded search.
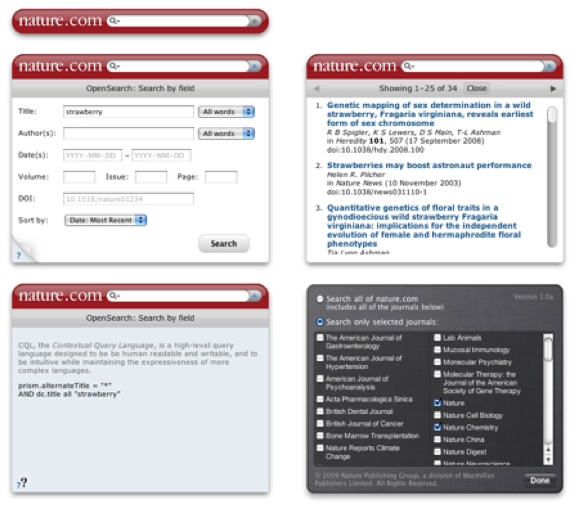 Fig. 4: 'nature.com search' widget composite (early version).
Fig. 4: 'nature.com search' widget composite (early version).
We have also made available an extensive gallery of HTML demo applications which use the JSON interface [24]. (Strictly though for cross-site scripting purposes the corresponding JSONP interface was used.) These AJAX-based demos are very compelling as they show how simple it is to run a search in situ, where results are presented inline with the original queries.
One such demo application 'Clouds' (shown in Fig. 5) provides a simple drag-and-drop search UI whereby individual search fields (with associated booleans) can be dragged and dropped onto a central search cloud prompting an AJAX query with structured results updating on the right. Each result has its own cloud cluster which can be clicked on to expand and the individual search fields (prepopulated from the query) can be dragged back into the main query, so allowing for partial results to be used in requerying.
 Fig. 5: 'Clouds' — a drag-and-drop search app using the nature.com OpenSearch JSON interface.
Fig. 5: 'Clouds' — a drag-and-drop search app using the nature.com OpenSearch JSON interface.
More detail on these various applications can be found in a series of blog posts made following the nature.com OpenSearch launch [25-27].
Futures
We are beginning to consolidate our various search services on top of a common public interface. The immediate priorities are to increase the volume of metadata flow through this interface, to make our record descriptions richer, and to position appropriate search functionality at key points in the user's interaction path with our content.
Beyond this we need to consider how best to address the next goal looming in resource discovery where individual result records are dismantled and atomized and the bare facts (or 'triples' in RDF parlance) can be selectively retrieved from across multiple databases and recombined into higher-order structures. We note that search services like nature.com OpenSearch could play a role in delivering structured information up to dedicated triplestore repositories [n10].
Summary
The nature.com OpenSearch service successfully marries within a single search web service two complementary approaches to resource discovery: OpenSearch and SRU. Users can benefit from the various options at their disposal according to their own needs, from the straightforward plug-and-play of OpenSearch to the structured protocol exchanges of SRU.
Irrespective of the search paradigm followed, structured queries and responses lend themselves directly to remote searching. Rather than being confined to any set-piece application for a site, search now folds back into the general infrastructure. In essence, search becomes a platform for applications. It becomes a utility. It becomes ubiquitous.
Acknowledgements
Special thanks go to Ralph LeVan of OCLC for not only creating the excellent open-source 'oclcsrw' software package but also updating the package to support HTTP content negotiation and making it generally more responsive to OpenSearch requests such as allowing for alternate formats. Thanks are also due to Nawab Siddiqui of Nature Publishing Group for doing the actual hard graft in implementing this service for nature.com and for leaping so agilely into this new terrain. And thanks too to Andrew Mee who developed the desktop widgets for us and produced the YouTube screencast.
Annex A — At the Crossroads
There are two overlaps in specifications between SRU and OpenSearch:
- OpenSearch Extension for SRU [28]
- SRU Binding for OpenSearch [29]
As discussed earlier, in order to support SRU parameters within OpenSearch URL templates we needed to define an OpenSearch Extension for SRU. In coordination with the nature.com OpenSearch release we provided an OpenSearch Community Proposal which is registered on the OpenSearch.org site. This document defines an XML namespace for SRU:
http://a9.com/-/opensearch/extensions/sru/2.0/
It also details all parameters from the SRU 2.0 specification and provides examples of usage. This means that SRU-specific parameters can now be entered alongside regular OpenSearch parameters within an OpenSearch URL template.
The OASIS Search Web Services TC is currently defining SRU 2.0 as a binding of its Abstract Protocol Definition (APD). In parallel to that work an OpenSearch binding is currently in draft. This will map the APD abstraction to the concrete OpenSearch processing model. It details the OpenSearch request parameters and the response elements, as well as documenting the service discovery model — the OpenSearch description document. The expectation is that OpenSearch will receive a standards-based description through OASIS.
Annex B — nature.com OpenSearch API
Reproduced in Fig. 6 is a cheatsheet for nature.com OpenSearch (first published on CrossTech [30]) which summarizes this public search API. This lists the various CQL indexes, relations and booleans that are supported alongside the standard SRU parameters and media types that this service provides. Note that differently to many search APIs which freely mix control and query parameters, SRU partitions control parameters from query parameters by the simple device of allocating a single parameter 'query' which carries the full CQL query string.
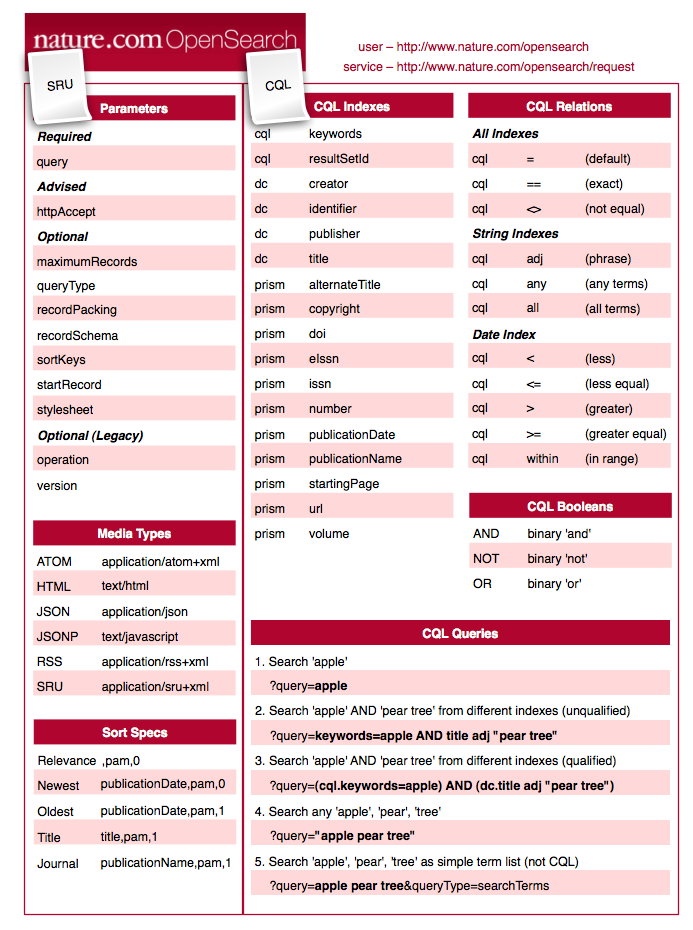 Fig. 6: Cheatsheet for nature.com OpenSearch.
Fig. 6: Cheatsheet for nature.com OpenSearch.
Notes
[n1] Z39.50 is the 'gold standard' for library information retrieval in networked systems. A good account of Z39.50's development and its application to the Web has been given by Cliff Lynch [31].
[n2] SPARQL, the SPARQL RDF and Query Language, is a means of querying over RDF triplestores. Syntactically similar to SQL it adopts a template-based approach to querying where complex patterns can be built up and the query engine will backtrack over the rules provided by matching RDF triples that fulfil the query.
[n3] SRU was originally conceived as one of two companion protocols: SRW (Search and Retrieve Web Service) and SRU (Search and Retrieval via URL). SRW was positioned as a SOAP-based web service, and SRU as a REST-based web service. SRW is no longer presented as a separate protocol but rather as a variant of SRU, referred to as 'SRU via HTTP SOAP'.
[n4] CQL, the Contextual Query Language, is a high-level query language designed to be human readable and writeable and to be intuitive while maintaining the expressiveness of more complex languages.
[n5] See this interview [32] with DeWitt Clinton, one of the chief architects of OpenSearch, for a brief history of OpenSearch development.
[n6] Note that we have preferred the RSS 1.0 format for reasons articulated earlier [33].
[n7] It is curious to note that the default Type-1 queries required by any conforming Z39.50 implementation have no string representation. They are commonly rendered in human readable form using Prefix Query Format [34].
[n8] The CQL-Java parser that we are using has been upgraded in version 1.4 [35] to allow for multi-word terms. Note, however, that while this will greatly simplify implementation support it remains a non-CQL feature.
[n9] The SRU 2.0 draft has now split the 'recordPacking' parameter into a new (but same-named) parameter 'recordPacking' with values 'packed' and 'unpacked', and a companion parameter 'recordXMLEscaping' taking over from the old parameter usage with values 'xml' and 'string'. These two parameters more clearly capture the orthogonal concerns of data packing and (XML) data escaping.
[n10] Some early ideas on migrating from a records-based (or graph-based) search to a triples-based search were made in this post to CrossTech [36].
References
[1] 'nature.com OpenSearch.' [Web page.] http://www.nature.com/opensearch/.
[2] 'SRU: Search/Retrieval via URL.' [Web page.] http://www.loc.gov/standards/sru/.
[3] 'OpenSearch.org.' [Web page.] http://www.opensearch.org/.
[4] Denenberg, R., 'Search Web Services — The OASIS SWS Technical Committee Work: The Abstract Protocol Definition, OpenSearch Binding, and SRU/CQL 2.0.' D-Lib Magazine, 15(1/2). January/February 2009. http://dlib.org/dlib/january09/denenberg/01denenberg.html. doi:10.1045/january2009-denenberg.
[5] 'OASIS Search Web Services Technical Committee.' [Web page.] http://www.oasis-open.org/committees/search-ws/charter.php.
[6] 'oclcsrw: An interface framework for exposing local databases via SRW/SRU.' [Web page.] Google Code. Google. http://code.google.com/p/oclcsrw/.
[7] 'OCLC Research Activities: SRW/U.' [Web page.] http://www.oclc.org/research/activities/srw/default.htm.
[8] Hammond, T., 'Aligning OpenSearch and SRU.' [Blog entry.] CrossTech. CrossRef. June 5, 2009. http://www.crossref.org/CrossTech/2009/06/aligning_opensearch_and_sru.html.
[9] Hammond, T., 'Search Web Service.' [Blog entry.] CrossTech. CrossRef. May 30, 2009. http://www.crossref.org/CrossTech/2009/05/search_web_service.html.
[10] 'CQL: Contextual Query Language (SRU Version 1.2 Specifications).' [Web page.] http://www.loc.gov/standards/sru/specs/cql.html.
[11] 'Apache Lucene — Query Parser Syntax.' [Web page.] http://lucene.apache.org/java/3_0_0/queryparsersyntax.html.
[12] 'nature.com OAI-PMH.' [Web page.] http://www.nature.com/oai/.
[13] 'PRISM Aggregator Message.' [Web page.] http://www.idealliance.org/industry_resources/intelligent_content_informed_workflow/about_the_prism_aggregator_message.
[14] Hammond, T., 'OpenSearch Formats for Review'. [Bog entry.] CrossTech. CrossRef. July 23, 2009. http://www.crossref.org/CrossTech/2009/07/opensearch_formats_for_review.html.
[15] 'SRU Diagnostics List.' [Web page.] http://www.loc.gov/standards/sru/resources/diagnostics-list.html.
[16] 'OpenSearch description document for nature.com OpenSearch.' [Web page.] http://www.nature.com/opensearch/opensearch.xml.
[17] (Explain record for nature.com OpenSearch.) [Web page.] http://www.nature.com/opensearch/request?stylesheet=.
[18] (Forms interface for nature.com OpenSearch.) [Web page.] http://www.nature.com/opensearch/request.
[19] 'Desktop widgets.' [Web page.] http://www.nature.com/widgets.
[20] 'Apple — Downloads — Dashboard Widgets — nature.com search.' [Web page.] http://www.apple.com/downloads/dashboard/search/naturecomsearch.html.
[21] 'nature.com search — Yahoo! Widgets.' [Web page.] http://widgets.yahoo.com/widgets/naturecom-search.
[22] 'Introducing 'nature.com search' desktop widgets'. [Video clip.] Nature Video Channel. YouTube. September 30, 2009. http://www.youtube.com/watch?v=sqf_ew4o3U8.
[23] 'Workbench : Nature Network.' [Web page.] http://network.nature.com/workbench.
[24] 'nature.com OpenSearch Demo Apps.' [Web page.] http://nurture.nature.com/opensearch/apps/.
[25] Hammond, T., 'nature.com OpenSearch.' [Blog entry.] Nascent. Nature Publishing Group. October 3, 2009.
http://blogs.nature.com/wp/nascent/2009/10/naturecom_opensearch.html.
[26] Hammond, T., 'Demo Web Clients for nature.com OpenSearch.' [Blog entry.] Nascent. Nature Publishing Group. October 4, 2009.
http://blogs.nature.com/wp/nascent/2009/10/web_clients_for_naturecom_open.html.
[27] Hammond, T., 'Desktop Widgets: nature.com search.' [Blog entry.] Nascent. Nature Publishing Group. October 1, 2009.
http://blogs.nature.com/wp/nascent/2009/10/desktop_widgets_naturecom_sear.html.
[28] Hammond, T., 'OpenSearch Extension for SRU (Draft).' [Web page.] http://www.opensearch.org/Community/Proposal/Specifications/OpenSearch/Extensions/SRU/1.0/Draft_1.
[29] 'OASIS Search Web Services TC Public Documents.' [Web page.] http://www.oasis-open.org/committees/documents.php?wg_abbrev=search-ws.
[30] Hammond, T., 'A Cheatsheet for nature.com OpenSearch.' [Blog entry.] CrossTech. CrossRef. October 22, 2009. http://www.crossref.org/CrossTech/2009/10/a_cheatsheet_for_naturecom_ope.html.
[31] Lynch, C., 'The Z39.50 Information Retrieval Standard — Part I: A Strategic View of Its Past, Present and Future.' D-Lib Magazine, 3(4). April 1997. http://www.dlib.org/dlib/april97/04lynch.html. hdl:cnri.dlib/april97-lynch.
[32] Bisson, C., 'DeWitt Clinton On The Birth of OpenSearch.' [Blog entry.] MaisonBisson.com. May 3, 2007. http://maisonbisson.com/blog/post/11665/dewitt-clinton-on-the-birth-of-opensearch/.
[33] Hammond, T., Hannay, T., and Lund, B., 'The Role of RSS in Science Publishing: Syndication and Annotation on the Web.' D-Lib Magazine, 10(12). December 2004. http://www.dlib.org/dlib/december04/hammond/12hammond.html. doi:10.1045/december2004-hammond.
[34] Hammer, S., Dickmeiss, A., Taylor, M., and Levanto, H., 'YAZ User's Guide and Reference, 4.0.1: Chapter 7. Supporting Tools, Query Syntax Parsers, Prefix Query Format.' http://www.indexdata.com/yaz/doc/tools.html#PQF.
[35] Taylor, M. 'CQL-Java, version 1.4 — Changes'. [Web page.] http://zing.z3950.org/cql/java/changes-1.4.html.
[36] Hammond, T., 'Search: An Evolution.' [Blog entry.] CrossTech. CrossRef. April 28, 2010. http://www.crossref.org/CrossTech/2010/04/search_an_evolution.html.
About the Author
 |
Tony Hammond works for the Platform Technologies group at Nature Publishing Group (NPG). His primary focus is in the general area of description technologies and he has been actively involved in developing industry standards for network identifiers and metadata frameworks. (Currently he is a member of the OASIS Search Web Services TC.) He has had experience working on both sides of the scientific publishing information chain, from large scientific publishing houses to academic research centres. His background is in physics with astrophysics.
|
|