|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
William Y. Arms, Selcuk Aya, Pavel Dmitriev Blazej Kot Ruth Mitchell, Lucia Walle |
![]()
1. A Web Library for Social Science ResearchAs libraries change, scholarship is also changing. For centuries, academic researchers have combed through the collections of libraries, museums, and archives to analyze and synthesize the information buried within them. As digital libraries expand, we can look forward to a day when humanities and social science scholars replace much of this tedious manual effort with computer programs that act as their agents. This article describes a library that is being built for such research. The collections are some ten billion Web pages from the historical collections of the Internet Archive [1]. Initially, the primary users are social scientists. The digital library challenge is to organize the materials and provide powerful, intuitive tools that will make a huge collection of semi-structured data accessible to researchers, without demanding high levels of computing expertise. For this purpose, it is helpful to consider the design of the library from two perspectives: The Research Perspective
The Technical Perspective
This article emphasizes the first of these perspectives, the Web library as a digital library to be used by academic researchers. A separate technical paper [2] describes the library as a high-performance computing application. The technical paper also describes the preliminary experiments in scalability and the design choices that were needed to manage billions of Web pages. 1.1 The Web Collection of the Internet ArchiveResearch on the history of the Web would be impossible without the foresight of Brewster Kahle, who founded both the Internet Archive and its commercial associate, Alexa Internet, Inc., now owned by Amazon. The Internet Archive is a not-for-profit organization created in 1996 to archive digital information and preserve it for future generations. Approximately every two months since 1996 the archive has added to its collection a crawl of the openly accessible Web. This collection is a treasure trove of information for researchers. It is by far the most complete record of the Web that is available to the public, and much of its early content is believed to be unique. Many of the crawls come from Alexa Internet. Amazon, which now owns Alexa, has recently made the Alexa corpus available for the commercial development of search engines and other Web applications [3]. The organization of the collections at the Internet Archive was originally guided by the need to minimize hardware costs. The files are stored on small servers, in roughly the order that the data is received. They are heavily compressed and the only access is through a simple index, which is organized by URL and date. The Internet Archive provides public access through its Wayback Machine. To use this, a user supplies a URL. The Wayback Machine responds with a list of pages with that URL from any date. The user can then select a version of the page to be viewed. The Wayback Machine is heavily used with millions of hits per day. An example of its use is forensic law, to gather evidence about what was public knowledge on a certain date. The Wayback Machine is a splendid service, but the cost-effective use of small server computers limits flexibility. The data is organized primarily for archiving and to serve a high volume of requests to access individual files, not for scholarly research. Considerable computing expertise is needed by researchers who wish to explore the materials in greater depth. For example, Web pages from a single crawl are scattered across servers; it is not easy to find them all or to process them as a set. The only way to find all links that point to a page is to scan through the entire crawl. 2. The User's Perspective2.1 Computational Social ScienceThe Web is an appealing corpus to develop new approaches to social science research because of its relevance to so many disciplines. The content of the Web provides contemporary evidence about events in society at large, while the Web itself is of great interest as a cultural artifact. There are, however, significant challenges in using Web data for social science research. Panel 1 describes how a sociologist views the challenges.
The initiative for creating a Web library at Cornell came from the research interests of two groups of users: social scientists, primarily from sociology and communication, and computer scientists with interests in information science. In 2005, the National Science Foundation's program for Next Generation Cybertools provided a major grant in, "Very Large Semi-Structured Datasets for Social Science Research". This grant is supporting both the development of the Web library and a broad program of sociology research. Panel 1 is from the proposal. In addition, Cornell's Institute for Social Science has embraced this work through its theme program for 2005-2008, "Getting Connected: Social Science in the Age of Networks" [5]. 2.2 User RequirementsWhen computer scientists with limited knowledge of social science interact with social scientists who are unfamiliar with the capabilities and restrictions of high-performance computing, the initial discussions are often circular. For example: social scientists would like to have instantaneous snapshots of the Web, but the demands of Web crawling mean that the data in any crawl is actually collected over a period of several weeks. During spring and summer of 2005, students from computer science and the information science program interviewed about fifteen Web researchers to understand their requirements [6]. The researchers included social scientists (in sociology, communication, and information science) and computer scientists; they ranged from graduate students to MacArthur fellows and a Turing Award winner.
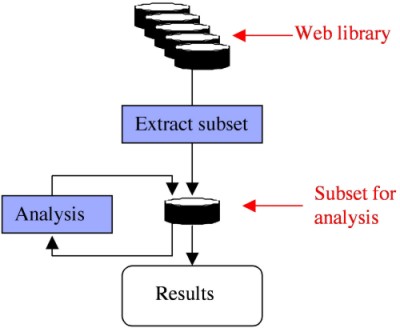
From these interviews and a series of weekly discussions, a design has emerged that is technically feasible yet provides exciting opportunities for researchers. The underlying concept is shown in Figure 1. Few research projects will use the entire Web collection; almost all will use smaller and more manageable sets of data. This distinction has important consequences. The software tools provided to researchers can be divided into two categories: (a) tools to build indexes and extract subsets, which must operate on the entire collection, and (b) analysis tools, which work on comparatively small subsets. The design of the library provides several ways to extract subsets. One way is to extract a view of the collection by a combination of metadata fields, such as date, URL, or MIME type. A second method will be to use the full text indexes that are under development at the Internet Archive. These can be used independently or in conjunction with focused Web crawling, as described below. 2.3 Research ScenariosHere are some categories of research that have been identified and scenarios of how they are supported by the Web library. Focused Web Crawling Focused Web crawling describes a group of techniques used to seek out pages that are relevant to a pre-defined set of topics. It is both a subject of research and an important tool in extracting subsets for other researchers. Automatic selection of materials in an educational digital library was an important motivator in the development of the library. For this purpose, Bergmark applied statistical methods of information retrieval to focused Web crawling [7]; other colleagues use the iVia focused crawler, which applies supervised machine learning methods to select and catalog materials for digital libraries [8]. For research on focused Web crawling the library provides a very large, stable test collection, so that experiments are isolated from the vagaries of running live tests on the actual Web. The Structure and Evolution of the Web Several computer scientists associated with this library study the structure and evolution of the Web by analyzing the graph of links between Web pages. Since the library stores all the links from a given page explicitly in a database, it is straightforward to specify part of the collection, perhaps all pages from one Web snapshot, and build an adjacency matrix showing all the links between those pages. Most current techniques for analyzing Web structure are based on static snapshots of the content of pages retrieved by a Web crawler. Yet the Web itself is dynamic, in its content, its structure and its usage. For example, Kleinberg has used bursts in the frequency of a term to identify emerging topics [9]. Such methods can highlight portions of the Web that are undergoing rapid change at any point in time and provide a means to analyze the content of emerging media like Weblogs. The methodology of such research is to extract a set of Web pages and analyze the terms in them for changes over time. Tools used for such analysis can be statistical techniques or can use methods from natural language processing. Diffusion of Ideas and Practices The sociologists associated with the library are particularly interested in studies of the diffusion of ideas and practices across the social landscape. This is important in many disciplines, including sociology, anthropology, geography, economics, organizational behavior, and population, ecology, and communication studies. The conventional methodology for such research has been to conduct small retrospective surveys. The Web library supports a new methodology. A concept is identified by a set of features, e.g., the phrase "affirmative action" in pages from the ".edu" domain. A corpus of Web pages with those features is identified, perhaps by focused Web crawling. Then automated tools are used to encode those pages for analysis. Social and Information Networks The Web both creates social networks and provides means that can be used to study them. The methodology for studying social networks is similar to diffusion research: extract a set of Web pages and use automated tools to analyze them. For example, a study of the movement of executives among organizations might choose as its corpus the Web sites of the 500 largest U.S. corporations. Machine learning methods are then used to extract names of executives from press releases, financial reports, and similar documents, and to track movements across time. 2.4 PoliciesThe final bullet of Panel 1 highlights the legal and policy issues surrounding the use of Web data for research. Privacy is a particularly sensitive area. With advice from the Cornell general counsel's office and the committee for human subjects research, the library has proposed the draft principles in Panel 2.
3. The Technical Perspective3.1 Data Driven ScienceThe Internet Archive's Web collection is huge but not vast. As of February 2006, the total size is approximately 600 terabytes, heavily compressed, or about 5 to 6 petabytes uncompressed. To move data across the country on this scale, to process it, and to manage databases with hundreds of terabytes requires considerable expertise. To develop such expertise, the Web library joined with several other research groups to build a petabyte data store for data driven science [10]. Other partners are from astronomy and computer graphics. The petabyte data store is led by computer science faculty and is housed in Cornell's high-performance computing center, the Cornell Theory Center. The project has received a major equipment grant from the National Science Foundation. The Theory Center has great expertise in distributed cluster computing, including Grid computing, but the petabyte data store chose to acquire two 16-processor symmetric multi-processor computers, each with 32 GBytes of shared memory. The operating system is Microsoft Windows Server 2003. The Web library has essentially sole use of one of these machines. It will have 240 TBytes of RAID disk by the end of next year. At a current system cost of about $2,000 per terabyte and falling rapidly, the cost of expanding the disk system is significant, but not overwhelming. The development of the library is following a process of iterative refinement. From the early interviews a tentative set of requirements and a preliminary design emerged. Prototype components were implemented, a series of benchmarks run, and small but important changes made to the design. Based on these results, a target was set that by the end of 2007 the Web library will have one complete crawl for each year since 1996, online and indexed for research This target requires data transfer from the Internet Archive to Cornell at a sustained rate of 250 GBytes per day. A 100 mbit/sec link was installed from the Internet Archive to Internet2; large-scale data transfer began at the beginning of 2006 and is planned to continue indefinitely. During fall 2005, the first version of the data management software was implemented. The experiments that led to these decisions, and the initial stages of implementation are described in the technical paper [2]. 3.2 Organization of the Collections
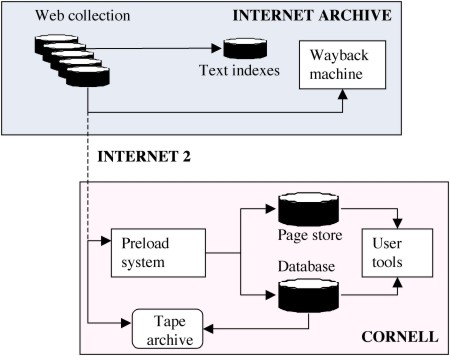
Figure 2 shows an outline of the data flow system and data storage. At the Internet Archive, Web pages are compressed and stored in 100 MByte files, known as ARC files. Corresponding to each ARC file there is a metadata file, known as a DAT file [11]. This metadata is very basic: it includes technical data about the corresponding ARC file, the date and time of the crawl, the URL, the IP address, and some basic information from the HTTP header. Both ARC and DAT files are compressed using gzip. They are stored on a very large number of small servers. At Cornell, the data storage has three components: Database A relational database stores metadata about every Web page. This includes URLs, IP addresses, data and time of capture, MIME types, and other basic information from the HTTP header. It also includes every hyperlink from each page. Page Store The Page Store provides a single copy of each unique Web page. It is indexed by a hash code to remove duplicates and provide fast, direct access to individual pages. Tape Archive All files received from the Internet Archive are stored in a robotic tape archive. This is the raw data that was captured by the Web crawls. In conjunction with the database, the tape archive will eventually provide an indexed mirror of a significant portion of the Internet Archive's Web collection. A relational database was chosen rather than a digital library repository designed for semi-structured data because of scalability requirements. Even with a commercial database system, the prototype revealed performance problems; the preliminary schema and file organization had to be redesigned because logging, back-up, and recovery were overloading the system. The library uses Microsoft SQL Server 2000. 3.3 Services for Researchers
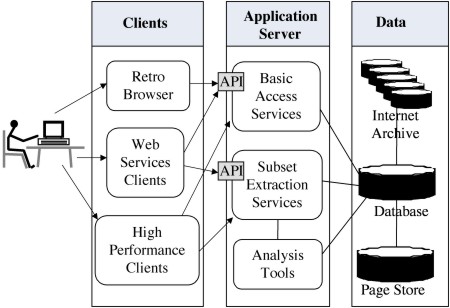
Figure 3 shows the architecture of how researchers use the library. The design anticipates two broad categories of use: Basic Access Services Basic access services allow a client program to access the collections one record at a time. For example, this interface is used for focused Web crawling. Subset Extraction Services Subset extraction services allow the client program to extract a corpus of Web pages, typically by a database view, and to store it for future analysis. Both these sets of services assume that the user interacts with the collections via a computer program. Some client programs are simple scripts that interface through a Web services API. Others are complete programs that are written by the researchers and linked to tools that we provide. 3.4 Analysis ToolsThe library is steadily building up a set of clients and tools that operate on subsets of the collection. Several colleagues plan to develop more advanced tools, using methods of natural language processing and machine learning, but these are for the future. Retro Browser The Retro Browser [12] is a program that allows users to browse the Web as it was on a certain date; in many aspects it is similar to the Wayback Machine. It uses the basic access services through the Web services API. Subset Extraction and Manipulation The subset extraction client is a demonstration client that uses the subset extraction services API. It provides forms that allow a user to specify parameters that define a subset and to invoke tools that operate on that subset. The Web Graph Prototype code has been written to extract the Web graph from a subset of a crawl and store it as a compressed adjacency matrix. Graphs of over one billion pages can be stored in the computer's main memory, for calculations of graphical metrics, such as PageRank, or hubs and authorities. Full Text Indexes Full text indexes are the biggest technical challenge faced by the Web library. Cutting, the principal author of the Lucene and Nutch search engines, is working with the Internet Archive to create full-text indexes to very large numbers of Web pages. This work uses a modified version of Nutch, called Nutch WAX [13]. It can be used to index large subsets, but neither the Internet Archive nor Cornell has the equipment that would be needed to index the entire collection. As an important first step the Internet Archive plans to mount a full text index to all the pages from 1996 to 1999 or 2000. 4. The FutureIn digital libraries, every development opens new horizons. The Cornell Web library will be a major resource for research on the history of the Web, but it needs to be one of many. Many phenomena of interest to social scientists happen more rapidly than the two monthly intervals between crawls. The Library of Congress is working with the Internet Archive and other partners to build intensive collections that cover special events; the first was the presidential election in November 2000. Usage data is enormously useful to Web researchers, but very little of it is available. Some Web content has been lost forever: much of the historically valuable material on the Web cannot be retrieved by Web crawling; no Web crawl ever covers the entire Web; any polite crawler respects requests by Web sites not to be crawled, including robots.txt files; the early crawls from the Internet Archive did not collect all file types; and some data could not be read when the early tapes were copied onto disk. The development of the Cornell Web library has been influenced by the opportunities and resources available to us. We hope that this library will be valuable to researchers from many disciplines, not only at Cornell, and look forward to cooperating with other teams who have different opportunities and expertise. AcknowledgementsWe wish to thank Brewster Kahle, Tracey Jacquith, John Berry and their colleagues at the Internet Archive for their support of this work. The following Cornell students have contributed to the development of the library described in this article: Mayank Gandhi, Nicholas Gerner, Min-Daou Gu, Wei Guo, Parul Jain, Karthik Jeyabalan, Jerrin Kallukalam, Serena Kohli, Ari Rabkin, Patrick Colin Reilly, Lipi Sanghi, Shantanu Shah, Dmitriy Shtokman, Megha Siddavanahalli, Swati Singhal, Chris Sosa, Samuel Benzaquen Stern, Jimmy Yanbo Sun, Harsh Tiwari, Nurwati Widodo, and Yu Richard Wang. This work has been funded in part by the National Science Foundation, grants CNS-0403340, DUE-0127308, and SES-0537606, with equipment support from Unisys and by an E-Science grant and a gift from Microsoft Corporation. Notes and References[1] The Internet Archive web site and the Wayback Machine are at <http://www.archive.org/>. [2] Arms, W., Aya, S., Dmitriev, P., Kot, B., Mitchell, R., Walle, L., Building a Research Library for the History of the Web. <http://www.infosci.cornell.edu/SIN/WebLib/papers/Arms2006a.doc>. [3] For information about Alexa and some observation about its contributions to Web preservation, see <http://pages.alexa.com/company/history.html>. [4] This extract is from the NSF proposal by Macy, M., et al., Very Large Semi-Structured Datasets for Social Science Research. NSF grant SES-0537606, 2005. [5] Cornell Institute for Social Sciences, Getting Connected: Social Science in the Age of Networks. 2005-2008 Theme Project. <http://www.socialsciences.cornell.edu/0508/networks_desc.html>. [6] These student reports are available at <http://www.infosci.cornell.edu/SIN/WebLib/papers.html>. [7] Bergmark, D., Collection synthesis. Proceedings of the 2nd ACM/IEEE-CS Joint Conference on Digital Libraries, 253-262, 2002. [8] Mitchell, S., Mooney, M., Mason, J., Paynter, G., Ruscheinski, J., Kedzierski, A., Humphreys, K., iVia Open Source Virtual Library System. D-Lib Magazine, 9 (1) Jan. 2003, <doi:10.1045/january2003-mitchell>. [9] Kleinberg, J., Bursty and Hierarchical Structure in Streams. Proc. 8th ACM SIGKDD Int. Conference on Knowledge Discovery and Data Mining, 91-101, 2002. [10] Petabyte Storage Services for Data-Driven Science, Cornell Computing and Information Science, 2004-. <http://www.cis.cornell.edu/projects/PetaByteStore/>. [11] Burner, M., and Kahle, B., Internet Archive ARC File Format, 1996. <http://www.archive.org/web/researcher/ArcFileFormat.php>. [12] Shah, S., Retro Browser. M.Eng. report, Computer Science Department, Cornell University, 2005. <http://www.infosci.cornell.edu/SIN/WebLib/papers/Shah2005b.pdf>. [13] NutchWAX is "Nutch + Web Archive eXtensions". For further information, see <http://archive-access.sourceforge.net/projects/nutch/>. Copyright © 2006 William Y. Arms |
|||
| |
|||
|
Top | Contents | |||
| | |||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/february2006-arms
|