| ||
D-Lib Magazine | |
| Adam Hodgkin |
![]()
Lexicographer. A writer of dictionaries, a harmless drudge. Samuel Johnson Dictionary of the English Language (1775). Reference services on the web: aggregationIt has been obvious for some years that the web will become an extraordinarily powerful medium for electronic publishing. So it is surprising that most of the early innovators in web publishing have been amateurs and enthusiasts, usually with little or no interest in commercial development. Perhaps the best example of this is Paul Ginsparg's e-Print archives — an initiative that anticipated commercial publishers in the scientific journals field by years [1]. In the reference field we see the same pattern: scores of dictionaries appeared on the web long before publishers began to launch serious web reference services. In fact, some of the early innovations were from commercial publishers operating non-commercially, but in the spirit of other web pioneers. The Merriam-Webster dictionary is one of the best examples. It has been much used and has become a notable web landmark, but it is primarily a publicity and brand-building exercise for the publisher who has conceived and supported the service [2]. . The Merriam-Webster dictionary is not an isolated instance; hundreds of dictionaries have been placed on the web, either directly by their publishers, or by academics with the co-operation of an original publisher. One of the obstacles that has stood in the way of commercial publishers making a return from web distribution of their copyrights is that individual books are really too small to be worth developing into a dedicated web operation. Very large books such as the Oxford English Dictionary and the Encyclopedia Britannica provide an exception to this rule, but few books are large enough to justify an annual subscription for online access. One way round this problem is to develop an aggregation service through which a collection of reference books can be given additional weight and visibility, sufficient to warrant active web distribution. Two pioneers of the aggregation approach were Infoplease and Bartleby. These businesses were set up to make money from selling advertising. The commercial proposition was that the users could be given free information from highly regarded reference works, while 'paying' for this service with their 'eyeballs'. Infoplease is a Boston-based company that aggregated three reference books into a site that became especially popular with home-users and high-school students. It has now been absorbed into the Pearson media operation. Bartleby.com has been even more ambitious, organising a score of reference titles and hundreds of full-text classics into a highly trafficked research site particularly popular with university students. Together, Infoplease and Bartleby have demonstrated the advantages accruing to users through an aggregation model for web reference services. The advantages are at least three:
These advantages are very important because they are all scalable. The bigger the reference service becomes, the greater its potential as a web magnet; the more books in the aggregation, the greater the economies of scale in development and production, and the greater the potential for powerful searches across a complete collection of books. Scalability is a fundamental asset in developing a web service, and publishers have now seen the potential for aggregating reference services and offering subscriptions to these services. Consequently, some reference publishers have established frameworks within which they can deliver all their reference works on-line. The Gale Group and H W Wilson were early pioneers of this approach, and Oxford University Press has recently launched 'Oxford Reference Online'. However, a snag with publisher-aggregated collections is that services aggregated at the publisher's end may appear fragmented and disaggregated at the user's end. Rarely do libraries or readers organize their books on the basis of the publishing house from which they come. An alternative would be to aggregate works from a variety of publishers around a market focus: an early and innovative example is the KnowUK service established by Chadwyck-Healey, now part of the Proquest group [3]. One of the problems with a scalable aggregation service is that it is not completely obvious where (or whether) the aggregation process should stop — KnowUK neatly solves this problem by demarcating a UK national focus, but this is also a significant limitation. The market for such a service will be predominantly in a geographical region, but the web knows no boundaries. Reference services as they should become: integrationAn aggregated collection of reference works has the great advantage that the whole collection of material can be searched at once. But searching is only one of the useful and necessary modes of electronic access, and it is not always the best strategy. Browsing is, in many ways, the more discriminating and more subtle form of investigative reading, whether for the student or for the innovating researcher. Browsing is an especially important mode for reading/research when the user is close to the target of research — but not quite 'there' — and may not yet know precisely what the target is. We are likely to adopt a browsing strategy when we are learning, exploring, considering and hypothesising. Let us note, it is not simply a beginners' strategy; browsing is extremely important to most creative work. We are more likely to browse when our reading is deep, not simply a matter of finding the straightforward fact. We will resort to a search engine when we know what we don't know. When we don't know what it is that we don't know, a search engine will not help us; in those circumstances, browsing will be a sensible strategy. Browsing is a slightly fuzzy concept, but it is not just for this reason that it is far less amenable to computerised automation than the classic problem of full-text searching. Other features make browsing a tough problem. 'Browsing' depends on meanings rather than simple pattern matching, and 'browsing' is very user-driven and interest-relative. Two readers might browse in very different directions, and the same reader might browse in a different way when he looks at a book in the context of different activities. Reference books are almost by definition browsable. They are designed to be consulted, not primarily to be read from cover to cover, so we need to understand the way reference information can be used in a world of electronic documents where consulting the dictionary is not a matter of leafing through the pages of one book whilst reading another. Since browsing is a very different type of search strategy than full-text searching, and since browsing is context-relative and meaning-dependent, it is desirable to find ways of encouraging browsability when building and using a large aggregation of reference resources. One strategy would be to develop a framework of context-relative and meaning-dependent hyperlinks through which one could improve the browsing possibilities for the user. A framework for browsing and integrating a collection of reference books is a feasible ambition with web technologies. The author of this article, together with three colleagues, in 1999 founded a company, xrefer.com Ltd. whose goal is to aggregate reference services within a framework of integrated reference links. Our vision for an integrated reference service starts with the proposition that a properly web-enabled reference service will be one in which the reference components, web-enabled books, or reference sources, should themselves become a fully networked and integrated reference resource. We also set the objective that the reference service should be scalable. If we had used a method through which human editors build the navigation system, the method would not be scalable; if human editors were involved in judging the appropriateness of potential links, then as more books were added, there would be an increasing demand for human editorial judgement. Human editorial decisions are crucial in the xrefer system, but they are only allowed to influence the results through the way in which the texts are marked up and the way in which algorithms or 'business logic' interprets these xml texts. The starting point for our integration system was to use and reuse the cross-references and other navigation devices already in the printed reference books. This starting point led us to suppose that we could build a framework of 'extended references' (which we term 'xreferences') whose purpose is to aid users in navigating a collection of reference books in much the same way as the humble cross-reference allows a user to navigate a single volume [4]. xrefer's approach to integrationThe classic reference book is a highly organized resource, with the alphabet providing an order, and cross-references marking links in the ordering. The point of a cross-reference within an entry is to permit instant access from one entry (record) to another. One of the slightly unexpected things that happens when a reference book is ported to an electronic environment such as the web, is that one tends to 'lose' the arrangement of the original book. The alphabetical ordering and the serial page layout form a hierarchical data structure, whereas most computer databases are 'relational'. The user is likely to access the computerised collection of entries through the search engine, and not by leafing through the pages of the text. It is, however, important to retain the original cross-references that provide links between relevantly related entries. These links mark important conceptual relations the compilers wished to emphasise. In building the xrefer reference system, we have come to think of the aggregation as simply a large collection of entries (each of which 'belongs' to the book from which it is taken), with each entry related to others in the system by cross-references and to still others by xreferences. Each book is, in effect, a little network with the links in the network marked by the cross-references. When one aggregates a collection of these self-referenced networks, there is an opportunity to build links between the individual networks; but it is not immediately obvious which entries may be deserving of linking as extended references. In principle, any entry could be linked to any other entry. Indeed, if one allows chains of links, each entry may be related to every other entry [5]. Some rules are needed to generate an automated framework of links. We decided entries that are cross-references in one direction should be treated as xreferences in the other direction. xreferences are, by definition, two-way links. (Compilers of dictionaries and Encyclopedias do not normally adopt this policy.) We also decided that each entry within another book in the collection on the same topic would also be treated as an xreference (so a cross-reference to an entry on 'John Stuart Mill' in one book would elicit xreferences to all the other entries on John Stuart Mill in the other books). This looks pretty straightforward, but there are some important consequences. In particular, it becomes necessary to adjudicate on the inconsistent naming conventions of different dictionaries and reference books. The system needs to know that John Stuart Mill, JS Mill, and Mill, John Stuart (1806-1873), etc. all refer to the same person. Our third decision was that the system would only present users with xreferences that were no more than 'two degrees' related to the starting entry: thus the system counts as xreferences entries that are cross-referenced from entries that are cross-referenced from the starting entry, but no more distant references are admitted. One might have decided to build the system so that the relationship is iterative (references of references of references etc.), but obviously the collection of links will become explosively large if the net is drawn too broadly. As we shall see, even with 'two degree' xreferences there is a problem about controlling and managing the number of links. With these decisions of principle behind us, we were in a position to develop a working system. Developing a production method using texts from 20 different publishers involves a great deal of practical detail, but aside from these messy details, there are three key steps:
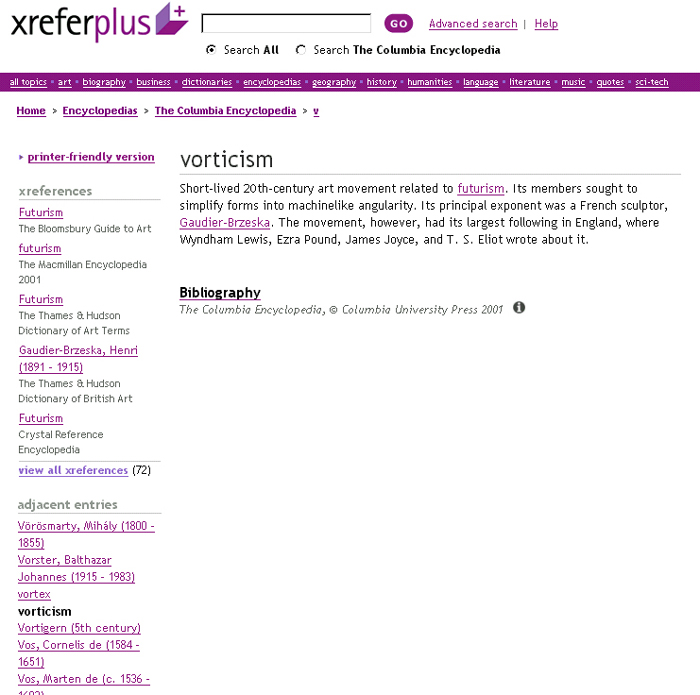
This last step is the area in which the system has to manage some complex data: sufficient to work out that a cross-reference to 'JS Mill' in one book sanctions xreferences to 'John Stuart Mill' in another book. References and xreferences always link entries, and the way xreferences work may be clearer if we consider a typical entry. If a user searches the current version of xreferplus for 'vorticism', the user will find more than 60 hits, with entries on vorticism from ten titles. If the user goes to the entry on vorticism from the Columbia Encyclopedia, this is the content that appears:
|
|
|
Figure 1. A typical entry in xrefer.
|
|
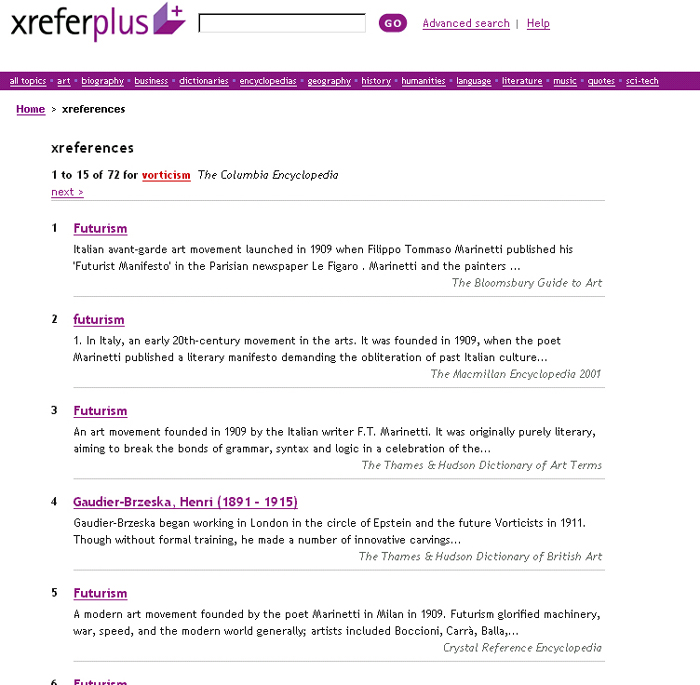
Figure 2. A typical list of xreferences - 15 of 72 for the 'vorticism' entry in Columbia Encyclopedia.
|
There are some points to note about this list of xreferences. First, although the Columbia entry on 'vorticism' has only two cross-references, there are several additional links in the list of xreferences to Columbia Encyclopedia entries. The reason is simply that, as already mentioned, these entries contain cross-references to the 'vorticism' entry, and the system uses these backward links to present entries that will be relevant to many users. The entry, in fact, mentions these additional persons (e.g., Wyndham Lewis and Pound), but this is not the reason the xreferences appear. They are produced simply because the entries about these people in Columbia have explicit cross-references to 'vorticism'. The full list of xreferences also contains links to additional people involved in the movement (Bomberg, Epstein, Kauffer, etc.) because these people are also explicitly referenced from other entries on vorticism. Further, 'Gaudier-Brzeska' appears as the leading xreference, but not because the Columbia entry tells us that he was the principal exponent of vorticism. The system of sorting xreferences does not depend on software interpreting the entry — this is a really hard task (currently impossible). The system for sorting xreferences works from additional information drawn from the whole collection of reference works. What is this additional information? The available information in this case is the set of entries in the xreferplus reference collection that are headed 'vorticism' and the entries to which they are related by the cross-reference relationship. Samuel Johnson famously defined a lexicographer as a writer of dictionaries, or 'harmless drudge', much of the conventional lexicographers work being in its nature routine and methodical. The building of xreferences is most clearly an application of routine and method, which would be numbing drudgery if undertaken by hand. When building xreferences between books, it is necessary to establish that the cross-references within the individual titles are valid (this is the second of the three key production stages mentioned above). It is an obvious requirement, but not trivial to implement. Reference books frequently contain 'hanging' cross-references, and they often have ambiguities that would defeat a computer. A human reader does not need to be told that a cross-reference to 'Dickens' is most likely a cross-reference to Charles Dickens, but an Encyclopedia of English Literature may contain entries for Charles Dickens and Monica Dickens and this obvious ambiguity has to be sorted out. In the xrefer system, this is done by a combination of xml markup and software. The xrefer DTD requires that all apparent cross-references have matching 'targets', and any errors in this regard are dealt with before a book is imported to the system. In most cases, valid targets are established by reference to a set of rules about entries and the objects they are 'about'. These rules amount to some 'business logic' about the subject matter of reference titles: for example, that a pair of entries about a person (or persons) who share the same place of birth and death, and who share the same first names can be presumed to be a pair of entries about the same person. Similar rules apply to titles (e.g., of published works or compositions) and to places. These rules are very useful when attempting to determine which of the many Bachs is the target of a cross-reference in a music book, or whether Charles or Monica is the point of a 'Dickens' cross-reference, but if rules are handy when validating links within a title, a rule-governed process is absolutely essential when trying to determine appropriate references between titles. It is impossible to have a scalable and human-driven system for making xreferences across a collection of reference resources (the more books that go into such a human-powered editorial system, the more explosive the task becomes). While it is not impossible to reprocess texts, it could be very expensive to have to reprocess the texts within a large collection of reference works. Therefore, markup should really be got right as the texts enter the system. It is effectively impossible to build xreferences by hand, and it is moderately expensive yet feasible to reprocess texts in order to improve their xml mark up (it becomes relatively expensive if all previously marked up texts need to be reprocessed). Fortunately, it is relatively inexpensive to improve the algorithms that work on the xml to build xreferences. In fact, this is the way the system has been built. The algorithms used to build xreferences (to fix the reference of apparently co-referential terms) are improved as more content goes into the system. For this reason, we are confident that the potentially explosive growth of xreferences is a manageable problem. If the system starts to generate too many xreferences as the collection of texts increases in size, it is possible to dampen this effect by improving the algorithms that 'focus' the xreferences. The current implementation has better and richer rules for 'persons' than for any other type of entity, but more rules can be proposed, and as more books are added to the system, it becomes more feasible to flesh out the existing rules. For example, once an atlas has been added to the system, it would be possible to associate geographic co-ordinates with all entries that are places. An important factor constraining and working against the explosive growth of xreferences is the fact that reference books have a surprising degree of non-overlap. A set of English language dictionaries, or a collection of general Encyclopedias may share many entry terms in common, but xreferplus contains books where the overlap with other titles is very low [6]. Of course, we have to some extent deliberately sought to reduce overlap, and sought to attract titles that to a degree complement each other rather than tread too closely on the same subject matter. Nevertheless, in the longer term the most important factor for regulating and managing the linking of xreferences is the business logic, the set of algorithms that the system uses to establish the entries to which any entry refers or xrefers. The application of xreferencesWe use a visualisation tool, a Java applet that shows how entries cluster, to help us understand these relationships. A 3D viewer demonstrates how entries in different books are more or less closely related and how groups of entries are arranged and connected by their xreferences. Figure 3 illustrates how the applet allows us to see the connections between various entries related to the 'vorticism' entry in the Columbia Encyclopedia.
|
|
|
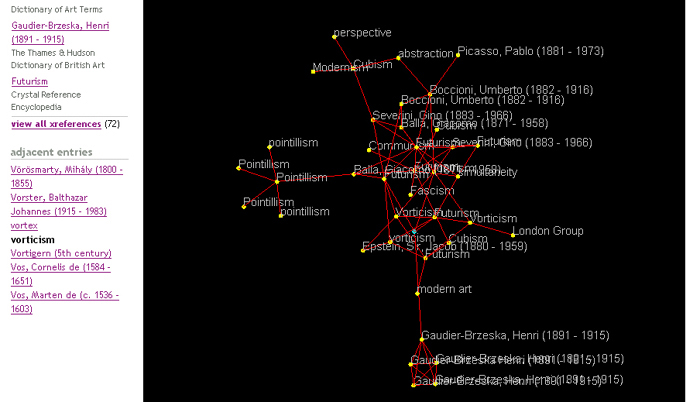
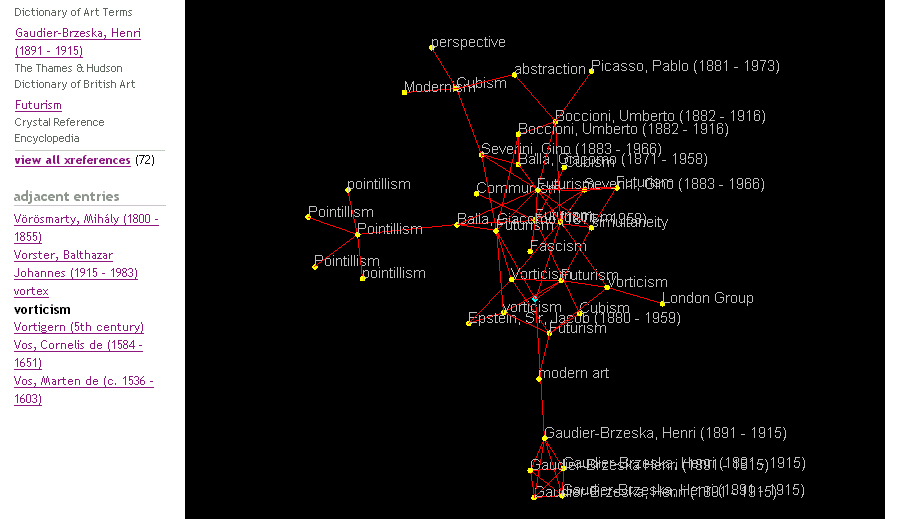
Figure 3. Entries clustered around the 'vorticism' entry in the Columbia Encyclopedia.
(For a larger view of Figure 3, click here.)
|
The small blue spot in the middle of the applet marks the Columbia entry, and related concepts appear at varying distances from this point. Out to the west there is a grouping of pointilism entries. Nearer by are entries for vorticism in other books, closely aligned to entries for futurism. Also nearby are entries for cubism and modernism. At a remove, to the south there is a collection of Gaudier-Brzeska entries, which suggests that according to these entries, he is much more connected to vorticism than to any of the other artistic -isms in the map. The applet only projects a two-dimensional snapshot of very complex relations among a large number of entries drawn from a multi-dimensional matrix, so one should not read too much into it. But it helps us to visualise the way in which a collection of entries can be used to generate xreferences that provide browsable links that are context-relative and follow semantic links. We noted earlier that a satisfactory browsing system should be both 'context relative' and should follow links of meaning rather than simple pattern matching. The xrefer system meets these requirements:
However, there are some important limitations. First, consider the issue of context. The example we have considered gives a snapshot of linked concepts relative to the context of the Columbia Encyclopedia entry for vorticism. This snapshot is, in turn, dependent on selections of content and relevance made by the compilers of the Columbia Encyclopedia and other books in the system. It is a strength of the approach that each entry in the system has its own 'perspective on knowledge', but it is also a limitation in that users will often not alight on the entries most relevant to their immediate concerns — e.g., the document that they are currently reading. The xreference tool would be significantly more powerful and general if there could be a way in which a section of free-text could be parsed and appropriate xreferences then proposed to the reader or researcher. This would amount to a method of 'mobilising the reference resources' to support documents other than reference works. The most promising way of approaching this problem seems to be to find ways of extracting appropriate meta-data from free-text and using these meta-data to generate xreferences from a suitable collection of reference titles. One might then be able to supply a collection of reference works that would be particularly relevant to a specialised domain. For example, a collection of medical reference works could operate in the background as a user perused medical textbooks or discussions, throwing up appropriate xreferences as particular documents were being considered. The second limitation to the xrefer system is that it is dependent on the 'general' reliability of the information of the books in the system. The xrefer system is using real world information found in the reference titles to generate meta-data: for example, the system uses a rule of thumb to the effect that: 'Person A with the same forenames, title, place/date of birth and place/date of death as Person B is the same person.' This rule enables the system to generate links between persons who are identified in slightly different ways in different contexts. It is possible to harvest this type of metadata because the names of persons tend to be emboldened or italicised in published reference sources (or in some other consistent fashion typographically distinguished). It is also feasible to capture some of these general truths in rules that can then be used to generate related entities ('vorticism','futurism', etc.). The xrefer system is able to rely on real world facts because the sources xrefer uses are themselves generally reliable. But only 'generally reliable'. What happens when the reference books included in xrefer get the facts wrong? The obvious answer is that xrefer will get the facts wrong also. This is a clear limitation to the extent that published books need revision and tend to be on a relatively slow revision cycle. We have considered whether it might be possible to 'warn' users about potentially misleading information, but this seems to us an area in which it is very difficult for an intermediary to make a helpful contribution without running the risk of usurping the editor's and the compiler's role. It also seems clear to us that the increased use of reference material through the web will create the demand for resources that are on a more rapid revision cycle. Reference books and reference servicesOne of the problems with a successful web aggregation strategy is that it may be difficult to know where to stop. We have started the xreferplus service with 120 titles, but we intend to add many more. If the methods of aggregation lead to increased economies and efficiencies, there is no apparent upper limit to what can be aggregated. Nontheless, one has an intuition that a completely remorseless and omnivorous aggregation strategy will not deliver optimal solutions. It is also not clear who should be making the decisions about what to aggregate and when. Inevitably, in small, new companies with limited resources, editors have made the selections, but it appears to be both desirable and feasible for the reference services of the future that the users (e.g., librarians) and the publishers should directly determine what should be aggregated. For these reasons, we expect that as the market for online reference resources grows, xrefer will become a facilitator and provider of reference services that are, to a large extent, defined and selected by the customer. The first version of xreferplus is a 'one size fits all' anthology of reference works, but we are planning to develop a larger suite of reference resources from which librarians can select the appropriate level of reference service: 100 titles, 200 titles or 300 titles, etc. Any selection of a fixed stock of reference titles is likely to be to varying degrees inappropriate for any one customer. In many specialist libraries, it will be seen as a disadvantage that a reference service uses sources that are not perceived to be relevant to the specialist institute. A strategy that will in due course require libraries to define, customise (and review) their own reference service obviously puts an additional responsibility on the librarian's shoulders; however, we believe that most librarians will welcome the chance to define their own level of service and their own content packages. It seems to us an important principle that as much of the selection process as possible should be left in the hands of the librarian, rather than the aggregator. If we turn our attention from the user to the compilers and publishers of reference resources, there is an analogous problem. How does one persuade copyright holders to offer their resources through an aggregation service that they do not control? In our dealings with publishers, we have found it helpful to explain that our linking technology is primarily driven by the links already in the various resources. There is no scope for publisher-favouritism. On the whole, a book that is well cross-referenced will be better rewarded than one which is poorly cross-referenced. There are several other factors that determine the relative usage of different titles as well; and only books that are in the system benefit from the revenues generated. Similarly, it is helpful in discussions with publishers that it is clear that copyrights within the service are remunerated entirely according to usage, which is not within our control. However, an aggregation strategy that rewards copyright holders purely on the basis of usage is likely to disappoint some copyright holders, because it fails to take into account the fact that some books are very valuable even though they are little used. The titles in the current xreferplus system generate rewards for publishers or copyright-owners strictly in accordance with the usage of their works through the service. In one way this is a fair system, since each entry and each user is treated the same. Nevertheless, it is potentially quite unattractive to the owner of a very specialist title that is infrequently consulted yet may contain information of great value and quality. An obvious way of meeting the needs of the specialist copyright, and matching its potential to the requirements of the specialist library, will be to offer some books purely on a 'specific-fee' per title basis. Such reference works would be delivered to those libraries that seek to add them to their core reference service. There is a sense in which xrefer's aggregation strategy has led the company to trespass on the traditional terrain of both the librarian and the publisher. From the librarian's (or the end user's) perspective we are providing libraries with a ready-made inter-publisher reference collection. In this sense, the aggregator's mission is to become a kind of electronic library. But from the publisher's perspective (or the compiler's point of view) xrefer looks like a kind of meta-publisher, because we are adding an additional layer of content: a navigational framework which links books from different publishing houses. There are some inevitable tensions in this situation, but it seems to us to be very important that the aggregator should distance his operations from the primary editorial and content collection task, on the one hand, and the role of service definition and content selection on the other hand. Librarians and editors are essential end points of the process and should remain in control of their bailiwick. There is another direction in which the aggregator's ambitions will be stretched. A successful model of aggregating reference works will become a web resource of potential use to many other kinds of web application (instructional, entertainment-oriented, fact-processing services). It is not too far-fetched to suggest that a reference service is potentially an important part of the emerging 'semantic web' [7]. and it will be important for reference aggregators to develop API's and application services that can interact and co-operate with automated services in a wide variety of contexts [8]. In conclusion, it seems to us that a properly comprehensive and scalable reference service needs to:
Aggregated and integrated reference services that can interoperate with other information services on the web should become enormously useful aspects of the semantic web. The work we have done at xrefer on integrating diverse reference titles suggests that metadata, business logic and xml representations of texts held in databases are powerful tools. These are tools which can immediately mobilise and repurpose conventional books for a new life on the web. It will be harder to find solutions or applications that build 'intelligent but novel' links between reference works and 'free text' or 'conversations' or 'case notes' or 'video clips', but solutions will be found. Harmless drudges are already 'out there' organising these domains so as to provide for usable metadata, and standards for deployment are rapidly evolving. The semantic web will be more meaningful and smarter than the web we have now, because nuggets or seams of intelligence and meaning will have been identified and amplified. It will be a web in which the production and distribution of knowledge and meaning is partially automated, although always ultimately answerable to, and generated by, the opinion of human experts. Most of the drudgery will be painlessly automated, but the views of the human expert will still be to the fore. Notes[1] Ginsparg's site <http://xxx.lanl.gov> compares in its scope with the most ambitious commercial services such as Science Direct. [2] Merriam Webster's site at <http://www.m-w.com/dictionary.htm>. [3] <http://www.knowuk.co.uk/>. [4] The reader may wish to investigate xreferences directly from xrefer's free site <http://www.xrefer.com> or seek a free trial of the subscription service xreferplus, which will aggregate about 120 titles (currently 75) at <http://www.xreferplus.com>. [5] For various reasons the topology of a collection of xreferenced books is rather different from the topology of the web, or of the internet. But one can be confident that it exhibits 'small world' behaviour, though with more than 'six degrees' of separation. Barabasi estimates that the web has roughly 19 degrees of separation see: Barabasi A-L, Physics World, July 2001, <http://www.physicsweb.org/article/world/14/7/09> [6] When xreferplus contained 70 books the most frequent entry heading was for 'realism' which appeared 17 times as the title of an entry in approximately 400,000 entries. [7] As the Introduction to the W3 page on the semantic web puts it: 'The Web can reach its full potential only if it becomes a place where data can be shared and processed by automated tools as well as by people.' http://www.w3.org/2001/sw/ [8] The Open URL approach looks like a promising way of handling links between reference resources in different subscription offerings <http://www.niso.org/committees/committee_ax.html> but it is worth noting that the approach we have take at xrefer has focussed on a very different issue than the classic issue of citations, which is the focus of CrossRef and SFX. Copyright 2002 Adam Hodgkin | |
| | |
| Top | Contents | |
| | |
| D-Lib Magazine Access Terms and Conditions DOI: 10.1045/april2002-hodgkin
|
{kind=link}