D-Lib Magazine
September 1999
Volume 5 Number 9
ISSN 1082-9873
The ISI® Web of Science® - Links and Electronic Journals
How links work today in the Web of Science, and the challenges posed by electronic journals
Helen Atkins
Director, Database Development
Institute for Scientific Information® (ISI®)
[email protected]

Introduction
Since their inception in the early 1960s the strength and unique aspect of the ISI citation indexes has been their ability to illustrate the conceptual relationships between scholarly documents. When authors create reference lists for their papers, they make explicit links between their own, current work and the prior work of others. The exact nature of these links may not be expressed in the references themselves, and the motivation behind them may vary (this has been the subject of much discussion over the years), but the links embodied in references do exist.
Over the past 30+ years, technology has allowed ISI to make the presentation of citation searching increasingly accessible to users of our products. Citation searching and link tracking moved from being rather cumbersome in print, to being direct and efficient (albeit non-intuitive) online, to being somewhat more user-friendly in CD format. But it is the confluence of the hypertext link and development of Web browsers that has enabled us to present to users a new form of citation product - the Web of Science -- that is intuitive and makes citation indexing conceptually accessible.
A cited reference search begins with a known, important (or at least relevant) document used as the search term. The search allows one to identify subsequent articles that have cited that document. This feature adds the dimension of prospective searching to the usual retrospective searching that all bibliographic indexes provide.
Citation indexing is a prime example of a concept before its time important enough to be used in the meantime by those sufficiently motivated, but just waiting for the right technology to come along to expand its use. While it was possible to follow citation links in earlier citation index formats, this required a level of effort on the part of users that was often just too much to ask of the casual user. In the citation indexes as presented in the Web of Science, the relationship between citing and cited documents is evident to users, and a click of the mouse is all it takes to follow a citation link.
Citation connections are established between the published papers being indexed from the 8,000+ journals ISI covers and the items their reference lists contain during the data capture process. It is the standardized capture of each of the references included with these documents that enables us to provide the citation searching feature in all the citation index formats, as well as both internal and external links in the Web of Science.
What makes it work The Reference Cycle
The key word in the paragraph above is standardized. References are not captured exactly as they appear in the articles. By imposing strict rules for data capture ISI ensures, as much as possible, that all the occurrences of references to the same cited work can be identified and linked together when they appear in disparate documents. The ability to do this is enabled by the creation of unique keys to represent each document. For over 50 years, ISI has captured the source data of articles, and that makes it possible to match and provide links for a great number of references in incoming, new documents.
Once references have been captured, they are "unified." The process of capture and unification of references is complex. A simplified overview will serve to lay the groundwork for understanding how links are implemented in the Web of Science.
As journals and their articles are indexed, unique, algorithmic keys are constructed for each source item. Indexing at ISI is cover-to-cover, so source items may include articles, letters, reviews, corrections, editorials, and a variety of other document types that are found in journals. All the previously constructed keys are stored and are subsequently used to aid capture of current references. As new articles are indexed, staff create and enter the algorithmic key that corresponds to each reference (more recently, this process is also being done by computer). If a match is found to a previously stored key, this indicates that we have most likely captured the article to which the reference refers in the past, and thus we already know the complete bibliographic information that would be included in the reference. No additional information is needed from the journal in these cases, so capture of that reference is complete with just the algorithmic key. If no match is found, then the reference is entered by a staff person in a highly structured form. Later on in the data processing flow, these initially non-matched citations will be further analyzed, and many will eventually be identified and unified to stored references, often correcting errors that authors have made in their reference lists. In addition to the stored keys that correspond to the indexed source items, there are unique keys created and stored for many items that we have not indexed, but that have, over the years, been cited many times.
The standardized capture and further unification of references has three main benefits: 1) it allows for speed in data capture since the key needed for matching is quite short; 2) it enables the presentation of more consistent references to customers, regardless of the number of variants presented in the source journals; and 3) it enables internal and external links in ISI products.
Web of Science Internal Links
The unique keys generated in data capture for each source item and its associated references travel with the data and form an index in the Web of Science. This index is able to relate references in newly added data to the original source items already in the database. Each week when new data are loaded, the keys associated with the incoming references are matched against the existing index of keys in the Web of Science; where matches can be made, links are created.
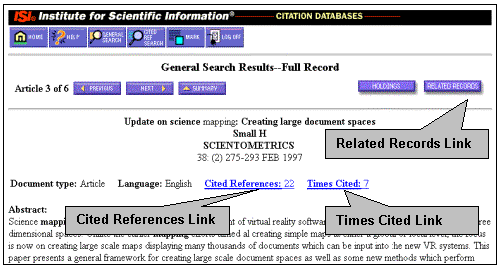
These links support a number of current product features, which are described below and are illustrated in a series of figures that appear at the end of this article. These links are all reached from the Web of Science full record (Figure 1).
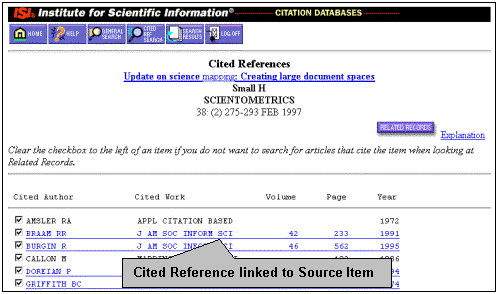
Reference Links (Figure 2)
Reference Links link from an articles references in one Web of Science record to the corresponding source records in the database, where the user can see complete bibliographic information. These types of links are enabled for referenced items that were captured and indexed previously as source items. The references that match to previous source data appear highlighted and underlined in the cited reference display.
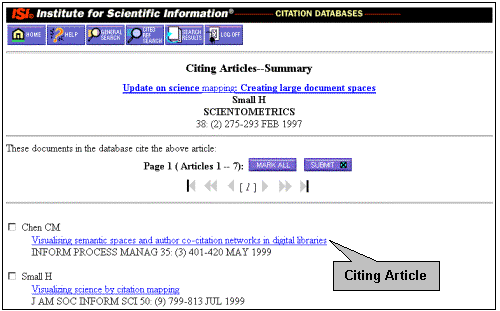
"Times Cited" Links (Figure 3)
"Times Cited" Links are from an articles bibliographic display (full record) to those articles subsequently published and indexed in the database that have cited that article -- a wonderfully intuitive cited reference search! As matches are found for reference links (as above), not only are the references highlighted and linked to the older, cited articles record, but that records "Times Cited" count is incremented. A user following the link labeled "Times Cited" on one record will be led to other records that have cited it. (This in no way can substitute for a thorough cited reference search, which may allow the user to identify additional variant citations [where the keys did not match], but may give an indication of the relative attention the article has received since publication.)
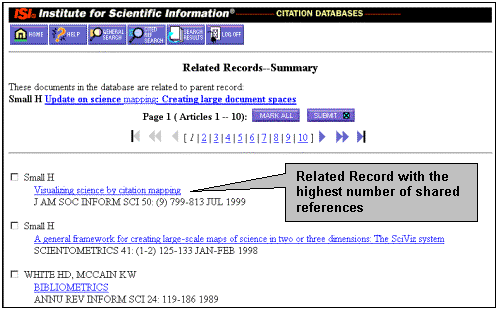
Related Records® Links (Figure 4)
Related Record® Links link from one article to other articles that are related to it by virtue of the fact that they share one or more references in common. This relationship is more formally called bibliographic coupling. The user starts with a selected article of interest, clicks on the Related Records button, and the program identifies and then ranks the additional papers retrieved according to the number of references they have in common. In this case, the keys for the references of the article selected are searched against those for all the other records in the file to find those with matching keys. The more keys in common, the more shared references, the more related the articles are.
Web of Science External Links
After working out and implementing the various internal links that provide useful navigation for Web of Science users, the next natural step was to explore the potential for establishing links to data external to ISI products. Before proceeding, we conducted extensive research into the potential of various standard identifiers that might aid in this venture. Each of the candidates (Digital Object Identifier [DOI], Serial Item and Contribution Identifier [SICI NISO Z39.56 1996], and Publisher Item Identifier [PII]) was found to be lacking for various reasons that will not be expanded on in this forum. The decision was made to use internal keys to move ahead with links. With the understanding that we might come back later and reconsider this stance, we felt most comfortable initially with our ability to create external links based on the same identifiers that have worked so well for our internal links.
At the present time, links exist between Web of Science records and full text data, patent records, and genetic sequence data.
Full-Text Links
Full-text links are in place between Web of Science records and corresponding full-text journal articles at publishers and aggregators sites. Where publishers desire enhanced references, additional links have been created that work in the opposite direction -- from references in the full text to corresponding Web of Science records. (More detailed information is available on the ISI Web site regarding the publishers and aggregators with whom we are working. See http://www.isinet.com/isilinks.)
Full-text links are accomplished in the following way: the participating publishers send metadata to ISI for each article. This metadata includes basic descriptive bibliographic information, a publisher-assigned unique identifier, and the URL at which the item may be found. Links software developed at ISI takes the publishers bibliographic information and generates the same type of keys for their data as are used internally. A links table is then populated with this information. Where the keys generated for the publishers data match keys for ISI records, hotlinks are created between the full text and the Web of Science record. The links are made known to the user by including a button on the Web of Science full record with wording that indicates the source of the full text (e.g., "IDEAL" for links to Academic Press). Links from the references in the full text to ISI records are constructed in much the same way.
Patent Links
Patent data in the Derwent Innovations Index® is also linked to the Web of Science. Cited journal literature in the patent records is linked to Web of Science full records, and cited patents in reference lists of Web of Science records are linked to the full patent records in the Derwent file. Cited patents are, of course, linked to patent documents by means of the patent numbers, but the literature citations in patent records are processed, parsed, and analyzed. The bibliographic information these references contain is identified, and the same algorithmically-derived unique keys are created for these references. The keys are matched against those already in the Web of Science, and where matches are found, links are made between the references in the patent record and the appropriate Web of Science full records.
Sequence Data Links
ISI has been working in cooperation with the National Library of Medicines National Center for Biotechnology Information (NCBI http://www.ncbi.nlm.nih.gov) to establish ongoing links between the Web of Science and GenBank. The complete GenBank file was initially processed to identify those literature references that could be found as source items in the Web of Science. Now, on a regular basis, sequence records that are newly deposited which contain literature references, and those that have been updated to include new literature references are accessed. Most GenBank references are already parsed and keys are generated fairly easily. A links table for these data is created which includes the unique identifiers assigned by NCBI for the sequence records. Hotlinks are added to the appropriate Web of Science records for "DNA Sequence" and/or "Protein Sequence." A user may select these buttons on a Web of Science record and link directly to the GenBank record - or records -- that have cited it.
Links to Full Text and the Challenge of E-journals
Currently, accurate links between Web of Science records and corresponding full text articles are largely dependent on the ability to match algorithmically-constructed keys. As these keys are based on bibliographic data, any major trends in publishing that have an effect on the quality, quantity and consistency of these data will also affect links. As publishers begin to put their content online, they have often become quite creative and are making interesting choices in presenting their journals. While these choices may not immediately affect their main readership (end users), they may have downstream effects that are problematic for other user communities, including secondary publishers and libraries, and eventually for the end users as well.
Some of the recent innovations publishers have introduced in the electronic versions of their established journals bear watching. These have ramifications in a number of areas, two of which are described below.
Completeness
Version control in this context does not refer to the traditional version control issue, where it is important to distinguish a work at its various stages (manuscript, preprint, first submitted version, first published version, published version with comments), but to the various finished versions of published journals that differ with regard to their content. The differences exist not just between print and electronic versions, but sometimes between the various electronic representations (e.g., HTML, PDF). Determination of the complete or authoritative version of a journal is no simple task. There are a number of variations that exist:
- Print is authoritative and complete (more content in print -- only major or selected articles appear online)
- Electronic is authoritative and complete (more content online - e.g., additional articles, data files)
- Neither is complete nor authoritative (need to access both print and electronic for complete content)
- The two are somewhat equivalent, but individual articles may differ depending on the version accessed (see the editorial in the British Medical Journal on their ELPS articles http://www.bmj.org/cgi/content/full/318/7188/888 )
While ISI indexing is cover-to-cover, including all the significant content in each issue, the publisher may not consider all these items important enough for reference linking. Indexing is done from the most authoritative version of the journal. Because some publishers dont always send metadata to correspond with all the content that has been indexed, the result for customers is that not all the records for these journals in the Web of Science will have links to full text.
A recent, informal survey conducted with ISI's major academic customers revealed that all the respondents considered completeness in their evaluation of the electronic journals in comparison to the print counterpart. Additionally, 90% considered this to be a very or extremely important factor in that evaluation. Two brief comments from respondents:
" to make full use of its potential as well as provide for our patrons needs its important to make electronic versions as complete as possible."
"It is very annoying when users find something in a journal that we supposedly have a site license to and the item isnt on-line."
ASAP Publishing and Bibliographic Information
When publishers want to present articles as soon as publishable (ASAP publishing), they may post them on the journals web site days, weeks, and sometimes months before they appear in print. This is not a bad practice on the contrary, when it comes to having access to research results, sooner is definitely better. Though when a researcher reads that article online and wants to cite it, what happens depends on the type of information the publisher provides with the ASAP article. The information available varies by publisher, but the main issues are with dates and pagination. In order to match articles with their subsequent citations, the bibliographic data need to concur. If the information for the different versions of the journal doesn't match, then it will be difficult, if not impossible, to know to what the citations refer.
For some publishers, like the Society for Industrial and Applied Mathematics (SIAM- http://www.siam.org/journals/journals.htm ) or the American Physical Society (APS - http://publish.aps.org ), all the bibliographic information related to the article is known at the time of posting. In these cases, there is no problem creating a complete citation to ASAP articles. In fact, the APS stopped using page numbers in favor of article numbers in Physical Review D, and more recently Physical Review C. This avoids problems that might crop up if one version of their articles didnt match the other (see their web site for more information -- http://ojps.aip.org/prd/artnum.html).
For other publishers there are potential problems. They may post ASAP articles as PDF or HTML files with no pagination. (This in itself would not be a problem if there were an article number or some other means to identify the article.) Later, when the issue has been completed and is ready to be printed, the articles are paginated. Sometimes the online versions will be updated to reflect the newly-assigned pagination, but sometimes not. The citations to the different versions will be different enough that they may prevent links from being made not only in ISI products but in other services that gather citations or build links algorithmically (see, for example, Eric Hellmans S-Link-S at http://www.openly.com/SLinkS).
Still other publishers have chosen to solve the problem by means of an identifier. For some ASAP-type articles in Springer Verlags LINK service (http://link.springer-ny.com ) and through the American Chemical Society (ACS http://pubs.acs.org ), the journal-level information may not be known at the time of posting, so the article appears without all the usual journal-level information. This may mean that information such as volume number, issue number, pagination, and date is missing. To avoid some of the potential pitfalls mentioned above, these publishers are assigning and posting a Digital Object Identifier (DOI) on each article as a means of uniquely identifying it. Because the DOI remains constant, it can serve as a continuing link to the journal article regardless of the existence of complete bibliographic information.
Adapting to the New Publishing Model
Changes in journal publishing brought about by the move to the web are here to stay. In following the advice, "lead, follow or get out of the way," ISI is choosing the former two rather than the latter.
First, following the lead of the publishing industry, ISI is monitoring the trends in both small and large enterprises and tuning internal systems to accommodate some of the major changes in publishing. Capture of data from electronic journal files, rather than paper, accounts for a larger portion of data input every day. Capture of new data elements -- for example, article numbers and DOIs -- is on the very short-term horizon. Future implementations of ISI Links may well use the DOI system as a supplement to the internal key system.
Second, publishers are asking for ISI to advise them as they expand their journals on the web, increasing their functionality, and as they start new, web-only journals. Several major publishers have asked ISI to develop standards, guidelines, or perhaps "best practices" for electronic publishing. Working with publishers, NISO, and others, ISI will take a lead in helping to develop guidelines that will benefit all of us.
Acknowledgements
The author is grateful to Bill Arms for being interested enough in what goes on behind the scenes to invite me to tell the story. Many ISI colleagues reviewed and suggested improvements to this paper -- Jay Trolley, John Schwegler, Richard Newman, Jim Pringle, and especially John Adams, who also deserves special thanks for helping me with the figures and HTML.
Copyright © 1999 Institute for Scientific Information
Top | Contents
Search | Author Index | Title Index | Monthly Issues
Previous Story | Next story
Home | E-mail the EditorD-Lib Magazine Access Terms and Conditions
DOI: 10.1045/september99-atkins