D-Lib Magazine
September/October 2014
Volume 20, Number 9/10
Table of Contents
The HZSK Repository: Implementation, Features, and Use Cases of a Repository for Spoken Language Corpora
Daniel Jettka, Universität Hamburg, Germany
daniel.jettka@uni-hamburg.de
Daniel Stein, Universität Hamburg, Germany
ds@daniel-stein.com
doi:10.1045/september2014-jettka
Printer-friendly Version
Abstract
This article describes the process of the conception and implementation of a digital repository which is based on the software framework Fedora, Islandora, and Drupal. The main data type that is to be organized, maintained, and distributed with the repository is spoken language corpora, with a focus on multilingualism, which means that the content of the repository may be of special interest to researchers of linguistic, translational and socio-psychological studies. We concentrate on the technical requirements that had to be fulfilled with regard to our status as an official center of the Common Language Resource Infrastructure Network (CLARIN), a pan-European initiative in the context of the Digital Humanities. In particular, the requirements include preparation of information for the description of resources providing a source for metadata harvesting, registration of persistent identifiers for the long-term access and citeability of resources, implementation of a federated content search module, dealing with privacy restrictions, and the possibility to provide a single sign-on method via Shibboleth. The HZSK Repository ultimately passed two assessment processes: the assessment of the Data Seal of Approval, and a CLARIN-internal assessment procedure.
Keywords: Spoken Language Corpora, Repository, Research Infrastructure, Digital Humanities, CLARIN, Fedora, Islandora
1. Introduction
The digital repository we are presenting in this paper was created for the organization, maintenance, and distribution of spoken language data (speech corpora) that are hosted by the Hamburger Zentrum für Sprachkorpora (Hamburg Center for Language Corpora, HZSK) at the Universität Hamburg. The repository is connected to the European CLARIN network, and therefore has to fulfill specific requirements in order to be interoperable with the other CLARIN centers' repositories and infrastructure. Since the data are requested by researchers from different academic areas and with different levels of expertise in Digital Humanities, we aimed at offering a comfortable and easy-to-use web interface.
The structure of the article is as follows: in the next section we give a brief overview of the existing language data and discuss the need for organizing and distributing the data through a digital repository. In the following section we discuss the technical requirements that were formulated and/or implemented by CLARIN that had to be met in order to become a part of the repository network that was established in the implementation phase of CLARIN between 2011 and 2014. In Section 4 we present several use cases which demonstrate the benefits of the repository for researchers from different academic fields that use the corpora from the HZSK Repository,and in Section 5 we focus on developments that we plan to realize in the next project phase (2014-2016).
2. Spoken language data at the HZSK
The data managed and distributed by the HZSK are mainly corpora of spoken language (Hedeland 2011), i.e. collections of digital audio and video files with corresponding aligned textual transcriptions and extensive metadata. In contrast to other kinds of audiovisual or multimedia archives, spoken language corpora are designed by researchers (mainly linguists) in order to analyze specific phenomena, e.g. bilingual code-switching. For this purpose, well-defined conventions are used for the transcription and annotation of the audiovisual resources on multiple descriptive levels such as phonology, morpho-syntax, semantics and/or pragmatics. The attached metadata include information about the circumstances of the recorded speech events as well as the characteristics of the involved speakers (e.g. socio-biographical information).
As the creation of corpora is very expensive in terms of money and time, and furthermore demands particular specialist knowledge (technical as well as linguistic/scientific), the long-term accessibility and the re-usability of the data for other researchers are very important issues. The bandwidth of these disciplines, which includes Linguistics, Social Sciences, and Psychology, is also represented in the HZSK corpora, along with differences in terms of involved languages, experimental settings, and/or the mixture of the participants, e.g.:
- Dolmetschen im Krankenhaus ("Hospital Interpreting", DIK) (Bührig 2011): Audio recordings of various kinds of doctor-patient communication in hospitals. The persons interpreting are bilingual hospital employees or relatives of the patients, who are all adults living in Germany but with varying knowledge of German. This corpus is interesting for researchers with a focus e.g. on community/lay interpreting.
- Hamburg Corpus of Argentinean Spanish (HaCaSpA) (Gabriel 2011): Audio and video recordings of experimental read and spontaneous speech from adult speakers of Porteño Spanish in Argentina. Speakers are 18-69 years old and from two geographic areas. This corpus is interesting for researchers with a focus e.g. on Latin American dialects.
- Hamburg Adult Bilingual Language (HABLA) (Kupisch 2011): Audio recordings (semi-spontaneous interviews) with German/Italian and German/French bilingual speakers aged approximately 15-55 years at the recording sessions. This corpus is interesting for researchers with a focus e.g. on language attrition, i.e. the loss of mother tongue skills due to non-practice.
The language resources that are hosted at the HZSK were mainly created with the free EXMARaLDA software suite for spoken language transcription, management and analysis (Schmidt/Wörner 2014). EXMARaLDA was developed by the HZSK and the Institut für Deutsche Sprache (IDS) in Mannheim and mainly consists of the transcription and annotation tool Partitur Editor, the corpus management tool Coma, and a tool for corpus querying and analysis called EXAKT.
3. The HZSK Repository
The new HZSK Repository is built on the basis of three open source components that combine to build a reliable and powerful repository solution: Fedora Commons (Staples 2003) as the repository framework in conjunction with Islandora (Stapelfeldt/Moses 2013) and Drupal as the solution for the user interface.
The former storage and distribution environment of the HZSK was based on a custom file server architecture, which had certain disadvantages regarding security, version management, data redundancy, and user management possibilities. In the following paragraphs we describe several aspects of the HZSK repository, explain certain decisions we made in the progress of creation, and contrast it to the former HZSK data storage environment.
3.1 Basic infrastructure
3.1.1 The Fedora repository system, and the Islandora software framework
Fedora Commons (the Flexible Extensible Digital Object Repository Architecture) — a widespread digital repository framework — is used to store the data and connect resources using Resource Description Format (RDF) relationships that are managed in an internal triple store system ("Mulgara"). Due to the open framework of Fedora, it is in principle possible to directly request and access the data without relying on other components. However, a comprehensive solution exists in the form of the Islandora software framework that connects Fedora to the well-known content management system Drupal, which offers a suitable website frontend (and also a web-based backend, e.g. for the user management) as well as a large number of additional modules. The Islandora system is used to manage, connect and display the data from Fedora in a Drupal-based website. Figure 1 illustrates the individual components and their interconnected functionalities:
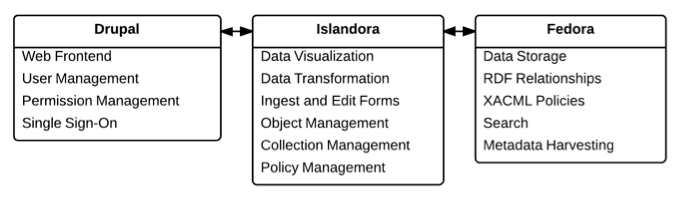
Figure 1: The main components of the HZSK Repository and their functionalities.
Fedora is a freely available, open-source, community-driven project that makes use of open standards and protocols like DC (DublinCore metadata), RDF, XACML, XML, OAI-PMH, LDAP, SOAP, and REST web services. It can be used as the basis for various information management schemes in a large number of different use cases. To set up a Fedora repository, it does not take much more than the Java SE Development Kit (JDK), a database (MySQL, Oracle, PostgreSQL, or Microsoft SQL Server), and an application server, that implements Servlet 2.5/JSP 2.1 or higher; e.g. Tomcat). A Fedora repository can be used to store any kind of digital content in any format (e.g. documents, videos, images, metadata), and the relationships between these items.
Islandora is an open-source software framework that focusses on the collaborative management, and discovery of digital objects, and provides a comprehensive and interoperable starting point for the implementation of a graphical interface to a Fedora repository. Based on Drupal, Fedora and Solr, Islandora includes multi-language and functionality support via Drupal. The use of modular Solution Packs that define specific data models and associated behaviors (e.g. for audio, PDF, images, books), which can be shared with and used by the Islandora community, facilitates the re-use of software components that are implemented and used for the extension of the Islandora core functionality.
3.1.2 Data storage and accessibility
The HZSK Repository, including all data that are stored within it, is regularly backed up by the computing center of the Universität Hamburg. The long-term accessibility is one of the most important and carefully managed features of the repository. This not only includes the architecture of the repository itself, but also the file formats which are used to represent the data. Audio and video data are at a minimum stored in formats with lossless data compression, and textual data like transcriptions and annotations are on the one hand provided in a readable and understandable XML format (the EXMARaLDA format) and on the other hand as XML-based export formats that facilitate their use in different software tools, for instance ELAN, and FOLKER, or are related to ISO/DIN standardization efforts like the format of the Text Encoding Initiative (Schmidt 2011). The Fedora repository system itself uses XML for the structured storage of the integrated data so that it is possible to transfer the data into other systems without extensive effort.
The use of widespread protocols like REST webservices, which forms the basis of the architecture of Fedora and Islandora, or OAI-PMH, that serves to make metadata available, and SRU for the processing and answering of external search queries, provide for a high level of compatibility with external architectures.
3.2 Features and interoperability with CLARIN
3.2.1 CLARIN requirements
As the HSZK is a center in the CLARIN infrastructure, it has to conform to certain standards in order to be interoperable with the other centers, for instance with regard to data processing methods, metadata formats and harvesting, federated content search, and single sign-on. For example, the CLARIN centers agreed to use the common metadata framework of the Component MetaData Infrastructure (Hedeland 2011) for the description of the resources and services, and to provide for automatic metadata harvesting. CMDI metadata fields can be annotated with data categories from ISOcat which increases the interoperability and prospective use of the metadata records.
Spoken language corpora pose particular privacy requirements as recordings often contain personal data (an obvious example is the DIK corpus mentioned above). In order to prevent unauthorized access, the HZSK Repository is protected on the level of high-order collections (i.e. corpora) using policies defined in the eXtensible Access Control Markup Language (XACML). They are stored as a datastream (POLICY for Content Objects, COLLECTION_POLICY for Collection Objects) in every Fedora object that belongs to a corpus. This makes it possible to protect the resources from unauthorized access. The metadata CMDI datastreams, however, are always freely available, so that the metadata that is automatically harvested by CLARIN.
3.2.2 Access control
In accordance with the agreements between the HZSK and the creators/rights holders of the corpora regarding the corpora's accessibility and terms of use, it is possible to control access to the data on a personal basis if necessary. The user management module of the content management system Drupal, which is connected to Fedora by the Islandora framework, allows for an easy and efficient control of access rights to complete corpora as well as particular parts of them. This is a considerable advancement in the management of corpus users in comparison to the former procedure at the HZSK in which the single server directories were secured by the use of htaccess and htpasswd files.
The resources at the HZSK are under different security levels which are defined as follows:
PUB is freely accessible and distributed publicly. The distribution of these materials is not restricted by copyright or personal data protection issues. It is not necessary to provide user credentials to access these resources.
ACA language resources can be accessed only by researchers for research purposes. The end-user does not need to ask for usage permission but can access the resources with a valid account from a research institution that is included in the CLARIN trusted domain.
RES language resources have additional restrictions, which require permission from the rights holder. These resources may contain material for which usage is limited due to copyright and/or personal data protection issues. In practice, these language resources require using both a valid account from a research institution to authenticate the end-user, and sending a separate application to the rights holder for authorization, possibly including a research plan for the resource
In addition to the Drupal-based management of repository users, the possibility of granting users access to (ACA) corpora which do not have unduly severe accessibility rights has been considered. Accordingly, corpora which are generally available to the scientific community are secured by the use of the Shibboleth system which allows for the single sign-on of users from universities or institutions which are registered for the CLARIN-EU Service Provider or the German Research Net (Deutsches ForschungsNetz DFN). As a test case the Hamburg MapTask Corpus HAMATAC (Schmidt 2011) currently is accessible via Shibboleth authentication. Nevertheless, it is still possible to create individual Drupal accounts for accessing ACA corpora, which is necessary for users who do not have an account at a participating institution.
3.2.3 Data model
After the decision was made to replace the existing architecture with a repository based on the components mentioned above, we needed to adapt the existing data model so that it could be expressed with Fedora's "Digital Object Model" and the internal relationships. Additionally, due to the higher flexibility of the underlying RDF relationships we were able to add certain aspects to the data model (in comparison to the possibilities offered by a server file system). The data model of the HZSK corpora is based on the data model of the EXMARaLDA Corpus Manager Coma and is displayed in Figure 2. It defines a corpus as a set of "communications" and another set of units called "speakers" (which may have one or several roles). Each communication has at least one participating speaker and contains several kinds of data that belong together. This may be a recording (audio and/or video), a transcription (which is a standoff XML file), and, if present, additional data, e.g. images or texts/instructions that were given to the speakers. We refer to these kinds of resources as "Content Objects". Additionally, there exists structured metadata files documenting in detail the communications and the speakers involved. While a communication may contain several Content Objects of the same type, each Content Object must be part of only one single communication. Speakers, on the other hand, may be part of more than one communication.
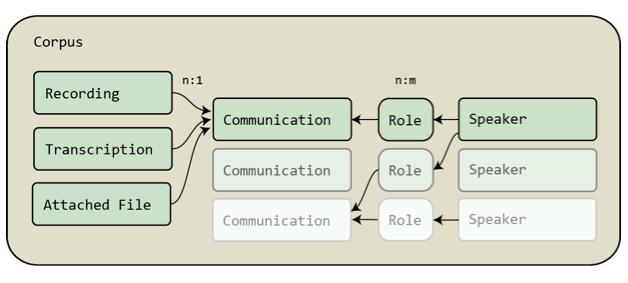
Figure 2: The Coma data model.
The data model used by Fedora has to be modeled in RDF and needs to fulfill several requirements in order to work with the Islandora architecture. Those requirements include the need for a structure that may be browsed in the manner of a file system, i.e. we needed to define collections that may be associated as containers for data. Accordingly, the Coma data model (see Figure 2) had to be adapted to those requirements, as can be seen in Figure 3. In terms of a file system, the Concept Objects (or Collection Objects in Islandora terms) represent the directories and the Content Objects represent the files inside of them. However, in comparison to a hierarchical file system a Fedora repository is able to represent multi-parentship relations between directories and files, so that it is for instance possible to browse all recordings in the "Recordings" collection and to see a special recording in conjunction with the connected transcription and additional data in the respective "Communication" collection.
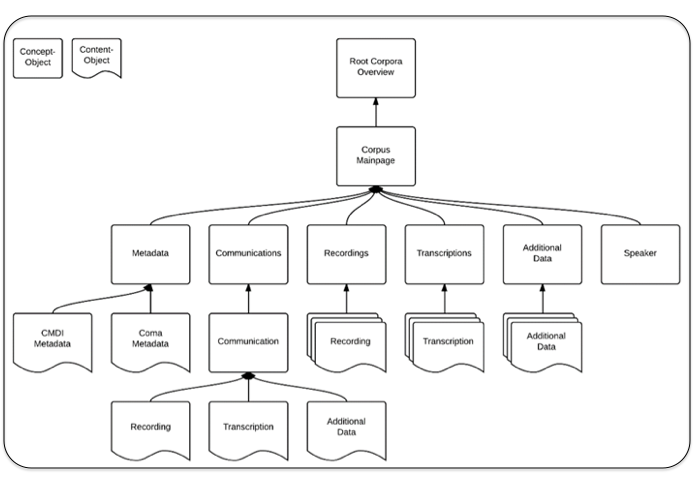
Figure 3: The data model of HZSK corpora as implemented in the repository.
3.2.4 Version management and persistent identifiers
Language corpora are not necessarily, but certainly can be, subject to continuous changes. A reliable version and revision management policy, as well as the preservation of possible citation of individual parts of the resources, are therefore crucial to hosting this kind of data. At this time, the versioning policy for the HZSK Repository states that only complete corpora are versioned. This means that changes or corrections of content — which normally only apply to transcriptions or metadata and not to recordings — are regarded solely for the integration of a new corpus version. Persistent identifiers (PIDs) are registered for new corpora or corpus versions and corpus parts by using the REST interface of the EPIC API for the Handle System, following the guidelines defined in http://tinyurl.com/hzsk-versioning. In this context, it is noteworthy to say that it is possible to refer to individual datastreams of content objects with part identifiers (with an @suffix), which is for instance useful in the case of recordings or images which can have datastreams for different file formats (e.g. wav and ogg for audio files).
For the further development of the HZSK Repository it is planned to allow users to collaboratively create resources and insert them into the repository. The publication process of corpora will still include final steps like checking data consistency and registration of persistent identifiers. However, the versioning mechanism of Fedora using timestamps for single datastream versions is a crucial feature that will facilitate the collaborative creation of language corpora.
3.2.5 Interfaces
3.2.5.1 Graphical user interface (GUI)
The graphical user interface of the HZSK Repository is a key component of the architecture and can be accessed through the HZSK website. The GUI was created with the help of Islandora which makes it possible to control it to a great extent from the Drupal backend. The display of Collection and Content Objects is facilitated by the use of XSLT stylesheets that are stored and can be modified in the Islandora-specific datastream COLLECTION_VIEW for Collection Objects, or by creating custom content models for different types of Content Objects. The web-based dissemination of the resources of the HZSK Repository is to a great extent based on the existing CMDI metadata in order to give users as much information about the corpora as possible (see the Appendix for some impressions). For the export and display of spoken language transcriptions (initially provided as EXMARaLDA transcriptions), REST webservices have been implemented and deployed to the HZSK server, which are directly called from the repository front-end. This way, several transcription formats (including ELAN, Praat, FOLKER) and display methods can be generated on-the-fly.
3.2.5.2 Search interfaces
In addition to the exploration of the resources by browsing the graphical interface, currently there exist two search mechanisms. Users can search in the metadata by using a search form on the repository website. The corresponding search index and functionality has been created with the help of Apache Solr and Fedora's GSearch module, and will be extended to support searching the content of transcriptions in the near future. Additionally, an SRU (Search/Retrieval via URL) endpoint was implemented, which allows for the processing and answering of remote search requests, e.g. from the CLARIN Aggregator, an interface to a Federated Content Search that includes all CLARIN repositories. Due to data privacy restrictions, at this time only ACA corpora (e.g. HAMATAC, also see Section 3.2.2) from the HZSK Repository are included in the Federated Content Search.
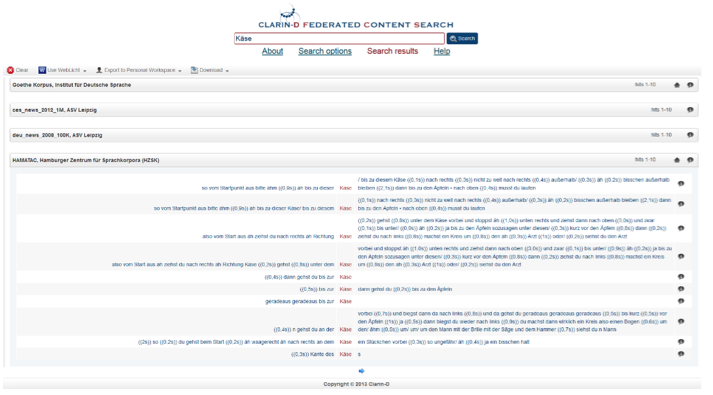
Figure 4: Search results of the Federated Content Search in the CLARIN Aggregator (29.04.2014).
3.2.5.3 Metadata harvesting
Another very important interface to the resources of the HZSK Repository is the installed OAI Provider, which allows for standardized metadata harvesting so that in principle the information can be gathered by any service that is interested in it. Currently, the metadata is automatically harvested by the Virtual Language Observatory (VLO), which represents a central external interface to the metadata of the HZSK Repository and allows users of the VLO to explore and find resources that might be of interest for their research, and then be forwarded to the HZSK Repository. As mentioned above, the metadata is provided in the CMDI format that allows for metadata categories to be connected to ISOcat categories and accordingly specify semantic categories of metadata fields. This allows for a common interface, like the Language Resource facet browser of the VLO, to make available heterogeneous metadata from a large number of different sources (repositories) for exploration and browsing.
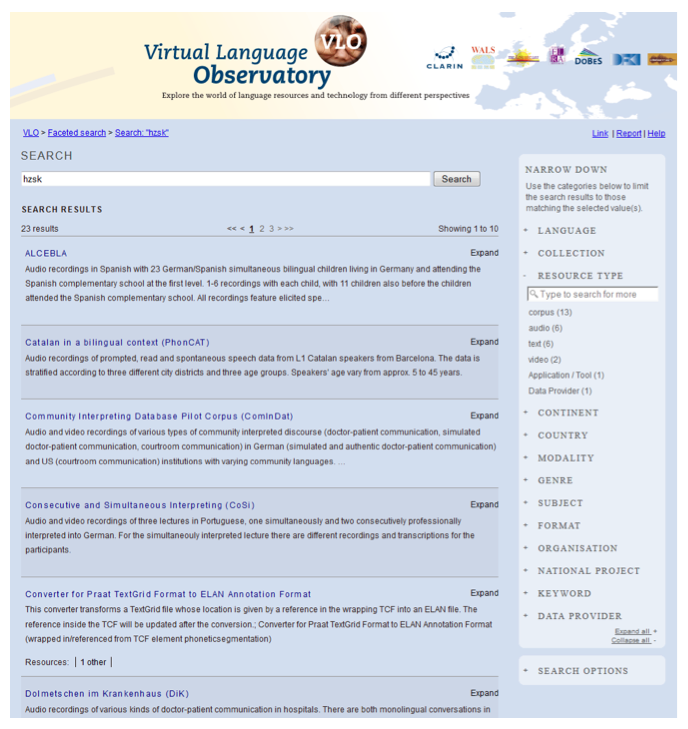
Figure 5: Display of harvested metadata about HZSK corpora in the VLO (Beta Version, 15.05.2014).
The information in the VLO is connected to the corresponding locations of the resources in the repositories and to the CLARIN Aggregator so that users can either navigate directly to the data sources or perform content searches within the resources that are available.
4. Use cases for repository features
The described architecture includes a range of benefits for researchers that are using the HZSK and CLARIN infrastructures. We illustrate these benefits with the following examples. The use cases are based on different needs and potential user types, but could also function as the illustration of a single workflow, starting with the basic investigation of existing resources and ending with the processing of individual data sets and the referencing/citation of research data in publications:
Metadata Search
The user is a linguist in search of data sets to be analyzed that need to fulfill certain requirements, e.g. orthographically transcribed recordings of non-adult Catalan speakers. The user wants to be sure that the corpus contains the desired data before she requests access. For this scenario, the repository offers a metadata search on the website and also delivers metadata to the automatic metadata harvesting facility of the Virtual Language Observatory which allows the user to browse the metadata in a comprehensive and fast way. There are direct references to the resources which allow further exploration of the search results within the interface of the HZSK repository (or other repositories) and give the user additional information about the context and/or related metadata of the instances which have been found. Furthermore, the Virtual Language Observatory provides a direct link to the CLARIN Federated Content Search (for the available resources ). This gives the user the opportunity to continue the metadata search with a search directly in the corpora that she is interested in.
Federated Content Search
The user is a university teacher and wants to use concise examples in his course for a particular phenomenon (e.g. code-switching in the case of Turkish-German bilinguals). The user may use the Federated Content Search interface offered by CLARIN, which is connected to the HZSK and other repositories, and search within the data of the corpora of the HZSK, and other language resources that are integrated in the CLARIN-D infrastructure at the same time. This is much more efficient than searching in all the related repositories or resources manually. In addition, the Federated Content Search avoids the risk of missing important data sets due to different access methods and infrastructures. The existing direct references to the resources allow further exploration of the search results within the interface of the HZSK repository (or other repositories) and acquisition of further information about the context and/or related metadata of the instances which have been found.
PIDs
The user is a researcher and writes a scientific article about a corpus linguistic analysis. In order to provide the references to the language resources that were used to obtain the presented results, she may refer to their persistent identifiers (PIDs). The PIDs of individual resources and data sets are given at several places, for instance in the graphical user interface of the HZSK Repository (and in other the other CLARIN repositories, of course), in the listings of resources within the Virtual Language Observatory, and in the overview of search results in the Federated Content Search interface.
Webservices
The user is a social sciences student who wants to prepare a presentation for his master's class. XSLT-based webservices that can be used to download the desired resources (e.g. spoken language transcriptions) in the best matching format (e.g. in the form of a column view in PDF format) are part of the infrastructure of the HZSK Repository. This allows the integration of resources into documents without excessive technical efforts. Another central interface of the CLARIN infrastructure brings together webservices developed at the different CLARIN centers, WebLicht — the Web-based Linguistic chaining tool. Information about existing webservices that can be used to process linguistic data is provided by the CLARIN centers' repositories in the form of harvestable CMDI metadata. By this means WebLicht can detect existing webservices in the CLARIN infrastructure and allow its users to build individual webservice chains to process their own data or data they found in the repositories, e.g. with format converters, morphological analyzers, syntax parsers, named entity recognizers, geolocalizers, and so on.
5. Perspectives
The proposed features of the HZSK Repository are expected to go online no later than with the end of the current CLARIN project phase. For the next project phase several additions are planned, which will mainly focus on further possibilities for the user to add, edit, or analyze the data in the HZSK Repository. Furthermore, it is planned to integrate additional spoken language corpora and other data types (e.g. the Hamburg Dependency Treebank) into the repository.
The collaborative creation of language resources will be an important working package in the next project phase. It is intended to create online tools for the collaborative management of corpus resources, the creation and editing of metadata (based on the EXMARaLDA Corpus Manager-Coma) as well as transcriptions and annotations of audio and video recordings (based on the EXMARaLDA Partitur Editor).
In addition, there will be efforts to implement new visual interfaces to the data inside the HZSK Repository. The spoken language corpora generally are described by extensive metadata. The relations of the metadata about speakers and communications (e.g. geographical, temporal, socio-biographical) and the recordings, transcriptions, and annotations of the content, represents a huge resource for data analysis. By providing a web-based interactive visual interface, in which users will be able to relate individual features of the resources and get direct insight into the connections between these features, it will be possible to generate new hypotheses for research.
6. References
[1] Bührig, Kristin et al. 2011. "The corpus 'Interpreting in hospitals' — possible applications for research and communication trainings." In: Hedeland, Hanna et al. (Eds.), Multilingual Resources and Multilingual Applications Proceedings of the Conference of the German Society for Computational Linguistics and Language Technology (GSCL) 2011. Hamburg: Universität. (Arbeiten zur Mehrsprachigkeit: Working Papers in Multilingualism; Folge B: Serie B; 96).
[2] Gabriel, Christoph. 2011. "Corpus of Argentinean Spanish". In: Hedeland, Hanna et al. (Eds.), Multilingual Resources and Multilingual Applications Proceedings of the Conference of the German Society for Computational Linguistics and Language Technology (GSCL) 2011. Hamburg: Universität. (Arbeiten zur Mehrsprachigkeit: Working Papers in Multilingualism; Folge B: Serie B; 96).
[3] Hedeland, Hanna et al. 2011. "Multilingual Corpora at the Hamburg Centre for Language Corpora." In: Hedeland, Hanna et al. (Eds.), Multilingual Resources and Multilingual Applications Proceedings of the Conference of the German Society for Computational Linguistics and Language Technology (GSCL) 2011. Hamburg: Universität. (Arbeiten zur Mehrsprachigkeit: Working Papers in Multilingualism; Folge B: Serie B; 96).
[4] Hedeland, Hanna and Wörner, Kai. 2012. Experiences and Problems creating a CMDI profile from an existing Metadata Schema. In: Proceedings of LREC-Workshop "Describing LRs with Metadata: Towards Flexibility and Interoperability in the Documentation of LR", Istabul, European Language Resources Association (ELRA), 37-40.
[5] Kupisch, Tanja et al. 2011. "The E11-Corpus of adult bilinguals (German-French and German-Italian)" In: Hedeland, Hanna et al. (Eds.), Multilingual Resources and Multilingual Applications Proceedings of the Conference of the German Society for Computational Linguistics and Language Technology (GSCL) 2011. Hamburg: Universität. (Arbeiten zur Mehrsprachigkeit: Working Papers in Multilingualism; Folge B: Serie B; 96).
[6] Schmidt, Thomas 2011. "A TEI-based Approach to Standardizing Spoken Language Transcription". In: Journal of the Text Encoding Initiative (1).
[7] Schmidt, Thomas et al. 2011. "HAMATAC — The Hamburg MapTask Corpus".
[8] Schmidt, Thomas and Wörner, Kai. 2014. "EXMARaLDA". In: Durand, Jacques et al. (Eds.), Oxford Handbook of Corpus Phonology, Oxford, University Press.
[9] Stapelfeldt, Kirsta and Moses, Donald. 2013. "Islandora and TEI: Current and Emerging Applications/Approaches." In: Journal of the Text Encoding Initiative, 5. http://doi.org/10.4000/jtei.790
[10] Staples, Thornton et al. 2003. "The Fedora Project: An Open-source Digital Object Repository Management System." In: D-Lib Magazine 9, 4. http://doi.org/10.1045/april2003-staples
Appendix
Graphical User Interface of the HZSK Repository
Corpus Overview (https://www.corpora.uni-hamburg.de/repository)
(View larger version)
Communication collection view (https://www.corpora.uni-hamburg.de/repository/col:demo_com/-/Communications)
(View larger version)
Communication view (https://www.corpora.uni-hamburg.de/repository/com:demo_Anne_Will_Halbes_Wahlrecht)
(View larger version)
About the Authors
 |
Daniel Jettka is a Research Associate in the CLARIN-D project at the Hamburg Centre for Language Corpora (HZSK) of the Universität Hamburg/Germany and currently mainly works on repository management and interfaces for spoken language corpora. After his Bachelor and Master studies in Linguistics, Text Technology, and Computational Linguistics at Universität Bielefeld/Germany and Trinity College Dublin/Ireland, he began to work at the HZSK in early 2012. From mid 2013 until early 2014 he was also employed in a CLARIN-D curation project at the University of Leipzig/Germany that integrated the spoken academic language corpus GeWiss into the CLARIN infrastructure.
|
 |
Daniel Stein is a Research Associate at the Hamburg Centre for Language Corpora (HZSK) of the Universität Hamburg/Germany, and deals with repository management and the creation of spoken language corpora. He studied in Kassel, Palma, Munich, and Barcelona and received a Magister Artium in German and Spanish Studies. Currently, he is writing his PhD thesis in Computational Linguistics.
|
|