
D-Lib Magazine
October 1999
Volume 5 Number 10
ISSN 1082-9873
Semantic Research for Digital Libraries
Hsinchun Chen
McClelland Professor of Management Information Systems
Director, Artificial Intelligence Lab
Management Information Systems Department
University of Arizona
[email protected]
Introduction
In this era of the Internet and distributed, multimedia computing, new and emerging classes of information systems applications have swept into the lives of office workers and people in general. From digital libraries, multimedia systems, geographic information systems, and collaborative computing to electronic commerce, virtual reality, and electronic video arts and games, these applications have created tremendous opportunities for information and computer science researchers and practitioners.
As applications become more pervasive, pressing, and diverse, several well-known information retrieval (IR) problems have become even more urgent. Information overload, a result of the ease of information creation and transmission via the Internet and WWW, has become more troublesome (e.g., even stockbrokers and elementary school students, heavily exposed to various WWW search engines, are versed in such IR terminology as recall and precision). Significant variations in database formats and structures, the richness of information media (text, audio, and video), and an abundance of multilingual information content also have created severe information interoperability problems -- structural interoperability, media interoperability, and multilingual interoperability.
Federal Initiatives: Digital Libraries and Others
In May 1995, the Information Infrastructure Technology and Applications (IITA) Working Group, which was the highest level of the country's National Information Infrastructure (NII) technical committee, held an invitational workshop to define a research agenda for digital libraries. (See http://Walrus.Stanford.EDU/diglib/pub/reports/iita-dlw/main.html.)
The participants described a shared vision of an entire Net of distributed repositories, where objects of any type can be searched within and across different indexed collections [11]. In the short term, technologies must be developed to search across these repositories transparently, handling any variations in protocols and formats (i.e., addressing structural interoperability [8]). In the long term, technologies also must be developed to handle variations in content and meanings transparently. These requirements are steps along the way toward matching the concepts being explored by users with objects indexed in collections [10].
The ultimate goal, as described in the IITA report, is the Grand Challenge of Digital Libraries:
deep semantic interoperability - the ability of a user to access, consistently and coherently, similar (though autonomously defined and managed) classes of digital objects and services, distributed across heterogeneous repositories, with federating or mediating software compensating for site-by-site variations...Achieving this will require breakthroughs in description as well as retrieval, object interchange and object retrieval protocols. Issues here include the definition and use of metadata and its capture or computation from objects (both textual and multimedia), the use of computed descriptions of objects, federation and integration of heterogeneous repositories with disparate semantics, clustering and automatic hierarchical organization of information, and algorithms for automatic rating, ranking, and evaluation of information quality, genre, and other properties.This paper is a short overview of the progress that has been made in the subsequent four years towards meeting this goal of semantic interoperability in digital libraries. In particular, it describes work that was carried out as part of the Illinois Digital Libraries Initiative (DLI) project, through partnership with the Artificial Intelligence Lab at the University of Arizona.
Attention to semantic interoperability has prompted several projects in the NSF/DARPA/NASA funded large-scale Digital Libraries Initiative (DLI) to explore various artificial intelligence, statistical, and pattern recognition techniques. Examples include concept spaces and category maps in the Illinois project [12] and word sense disambiguation in the Berkeley project [14], voice recognition in the Carnegie Mellon project [13], and image segmentation and clustering in the project at the University of California at Santa Barbara [6].
In the NSF workshop on Distributed Knowledge Work Environments: Digital Libraries, held at Santa Fe in March, 1997, a panel of digital library researchers and practitioners suggested three areas of research for the planned Digital Libraries Initiative-2 (DLI-2): system-centered issues, collection-centered issues, and user-centered issues. Scalability, interoperability, adaptability and durability, and support for collaboration are the four key research directions under system-centered issues. System interoperability, syntactic (structural) interoperability, linguistic interoperability, temporal interoperability, and semantic interoperability are recognized by leading researchers as the most challenging and rewarding research areas. (See http://www.si.umich.edu/SantaFe/.)
The importance of semantic interoperability extends beyond digital libraries. The ubiquity of online information as perceived by US leaders (e.g., "Information President" Clinton and "Information Vice President" Gore) as well as the general public and recognition of the importance of turning information into knowledge have continued to push information and computer science researchers toward developing scalable artificial intelligence techniques for other emerging information systems applications.
In a new NSF Knowledge Networking (KN) initiative, a group of domain scientists and information systems researchers was invited to a Workshop on Distributed Heterogeneous Knowledge Networks at Boulder, Colorado, in May, 1997. Scalable techniques to improve semantic bandwidth and knowledge bandwidth are considered among the priority research areas, as described in the KN report (see http://www.scd.ucar.edu/info/KDI/):
The Knowledge Networking (KN) initiative focuses on the integration of knowledge from different sources and domains across space and time. Modern computing and communications systems provide the infrastructure to send bits anywhere, anytime, in mass quantities - radical connectivity. But connectivity alone cannot assure (1) useful communication across disciplines, languages, cultures; (2) appropriate processing and integration of knowledge from different sources, domains, and non-text media; (3) efficacious activity and arrangements for teams, organizations, classrooms, or communities, working together over distance and time; or (4) deepening understanding of the ethical, legal, and social implications of new developments in connectivity, but not interactivity and integration. KN research aims to move beyond connectivity to achieve new levels of interactivity, increasing the semantic bandwidth, knowledge bandwidth, activity bandwidth, and cultural bandwidth among people, organizations, and communities.Semantic Research for Digital Libraries
During the DLI, which ran from 1994 to 1998, significant research was conducted at all six projects in the area of semantic retrieval and analysis for digital libraries. Among the semantic indexing and analysis techniques that are considered scalable and domain independent, the following classes of algorithms and methods have been examined and subjected to experimentation in various digital library, multimedia database, and information science applications:
- Object Recognition, Segmentation, and Indexing:
The most fundamental techniques in Information Retrieval involve identifying key features in objects. For example, automatic indexing and natural language processing (e.g., noun phrase extraction or object type tagging) are frequently used to extract meaningful keywords or phrases from texts automatically [9]. Texture, color, or shape-based indexing and segmentation techniques are often used to identify images [6]. For audio and video applications, voice recognition, speech recognition, and scene segmentation, techniques can be used to identify meaningful descriptors in audio or video streams [13].
- Semantic Analysis:
Several classes of techniques have been used for semantic analysis of texts or multimedia objects. Symbolic machine learning (e.g., ID3 decision tree algorithm, version space), graph-based clustering and classification (e.g., Ward's hierarchical clustering), statistics-based multivariate analyses (e.g., latent semantic indexing, multi-dimensional scaling, regressions), artificial neural network-based computing (e.g., backpropagation networks, Kohonen self-organizing maps), and evolution-based programming (e.g., genetic algorithms) are among the popular techniques [1]. In this information age, we believe such techniques will serve as good alternatives for processing, analyzing, and summarizing large amounts of diverse and rapidly changing multimedia information.
- Knowledge Representations:
The results from a semantic analysis process could be represented in the form of semantic networks, decision rules, or predicate logic. Many researchers have attempted to integrate such results with existing human-created knowledge structures such as ontologies, subject headings, or thesauri [7]. Spreading activation based inferencing methods often are used to traverse various large-scale knowledge structures [3].
- Human-computer Interactions (HCI) and Information Visualization:
One of the major trends in almost all emerging information systems applications is the focus on user-friendly, graphical, and seamless Human Computer Interactions. The Web-based browsers for texts, images, and videos have raised user expectations of rendering and manipulation of information. Recent advances in development languages and platforms such as Java, OpenGL, and VRML and the availability of advanced graphical workstations at affordable prices have also made information visualization a promising area for research [5]. Several digital library research teams including Arizona/Illinois, Xerox PARC, Berkeley, and Stanford, are pushing the boundary of visualization techniques for dynamic displays of large-scale information collections.
The Illinois DLI Project: Federating Repositories of Scientific Literature
The Artificial Intelligence Lab at the University of Arizona was a major partner in the University of Illinois DLI Project, one of six projects funded by the NSF/DARPA/NASA DLI (Phase 1). The project consisted of two major components: (1) a production testbed based in a real library and (2) fundamental technology research for semantic interoperability (semantic indexes across subjects and media developed at the University of Arizona).
The Testbed
This section is a brief summary of the testbed. Readers can find more details in [12].
The Illinois DLI production testbed was developed in the Grainger Engineering Library at the University of Illinois at Urbana-Champaign (UIUC). It supports full federated searching on the structure of journal articles, as specified by SGML markup, using an experimental Web-based interface. The initial rollout was available at the UIUC campus in October 1997 and has been integrated with the library information services. The testbed consists of materials from 5 publishers, 55 engineering journals, and 40,000 full-text articles. The primary partners of the project include: American Institute of Physics, American Physical Society, American Astronomical Society, American Society of Civil Engineers, American Society of Mechanical Engineers, American Society of Agricultural Engineers, American Institute of Aeronautics and Astronautics, Institute of Electrical and Electronic Engineers, Institute of Electrical Engineers, and IEEE Computer Society. The testbed was implemented using SoftQuad (SGML rendering) and OpenText (full-text search), both commercial software.
The Illinois DLI project developers and evaluators have worked together very closely on needs assessment and usability studies. The production testbed has been evaluated since October 1997. Six hundred UIUC user subjects enrolled in introductory computer science classes have used the system; and their feedback has been collected and analyzed. We expect to have collected usage data for about 1500 subjects at the end of the study. Usage data consists of session observations and transaction logs.
After four years of research effort, the testbed successes include:
- Willingness to build custom encoding procedures for SGML. This enabled the testbed to succeed in federating journals from different publishers with differing use of SGML, where Elsevier and OCLC failed.
- Canonical encoding for structure tags. The testbed can federate across publishers and journals.
- Willingness to build custom software for searching. The Illinois DLI system is able to show multiple views on the Web and has advanced structure search capabilities.
- Production repositories for real publishers. The project became the R&D arm of several scientific publishers and generated valuable contributions to the scientific publishing industry.
- Changing the nature of libraries with research. The project enables a research prototype to become a standard service capability for engineering libraries.
However, in the nature of research, we also have experienced many testbed difficulties:
For the user interface, the project originally planned to modify the Mosaic Web browser (which was developed at UIUC). When the Web became commercial, Mosaic was quickly taken out of the control of the developers. Custom software is hard to deploy widely: the Web browser interface has widespread support, but the functionality was too primitive for professional full-text search and display.
Several practical difficulties were found in using SGML for this project. Plans to use standard BRS as full-text backend had to be abandoned. It proved essential to use an SGML-specific search engine (OpenText).
Good-quality SGML simply was not available. We had to work with every publisher, since nothing was ready for SGML publishing.
SGML interactive display proved not to be of journal quality. Physics requires good-quality display of mathematics, which is very difficult to achieve.
As the project comes to its end, several future directions are being explored:
- Technology transfer to publisher partners: Several partners have expressed interest in receiving the testbed technologies. A contract has been developed with the American Institute of Physics to clone the testbed software and processing. A similar contract is under development with American Society of Civil Engineers.
- Testbed continuance by university library: An industrial partnership program has been established between the UIUC Library and publishers. A UIUC spin-off company has been formed to provide software and future services.
Semantic Research in Illinois DLI Project
The University of Illinois DLI project, through the partnership with the Artificial Intelligence Lab at the University of Arizona, has conducted research in semantic retrieval and analysis. In particular, natural language processing, statistical analysis, neural network clustering, and information visualization techniques have been developed for different subject domains and media types.
Key results from these semantic research components include:
- Scalable semantics become feasible:
Statistical and neural network clustering proves useful and feasible interactively and for large-scale collections. Specifically, the AI lab has developed a noun phrasing technique for concept extraction, a concept space technique for building automatic thesauri, and a self-organizing map (SOM) algorithm for building category maps. More details are provided below.
- Semantic indexes for large collections:
Two large-scale semantic indexing simulations were performed in 1996 and 1997, respectively. We analyzed 400,000 Inspec abstracts and 4,000,000 Compendex abstracts to generate about 1,000 engineering-specific concept spaces (automatic thesauri) using the NCSA supercomputers (Convex Exemplar and SGI Origin 2000). Results of such computations could be used for semantic retrieval and vocabulary switching across domains [4].
An Example
In this section we present an example of selected semantic retrieval and analysis techniques developed by the University of Arizona Artificial Intelligence Lab (AI Lab) for the Illinois DLI project. For detailed technical discussion, readers are referred to [4] [2].
A textual semantic analysis pyramid was developed by AI Lab to assist in semantic indexing, analysis, and visualization of textual documents. The pyramid, as depicted in Figure 1, consists of 4 layers of techniques, from bottom to top: noun phrasing indexing, concept association, automatic categorization, and advanced visualization.
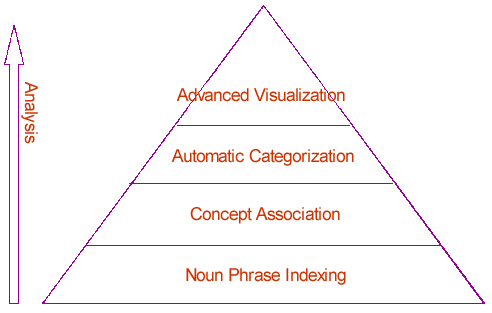
Figure 1: A textual semantic analysis pyramid
Noun Phrase Indexing: Noun phrase indexing aims to identify concepts (grammatically correct noun phrases) from a collection for term indexing. Known as AZ Noun Phraser, the program begins with a text tokenization process to separate punctuations and symbols and is followed by part-of-speech-tagging (POST) using variations of the Brill tagger and 30-plus grammatic noun phrasing rules. Figure 2 shows an example of tagged noun phrases for a simple sentence. For example, "interactive navigation" is a noun phrase that consists of an adjective (A) and a noun (N).
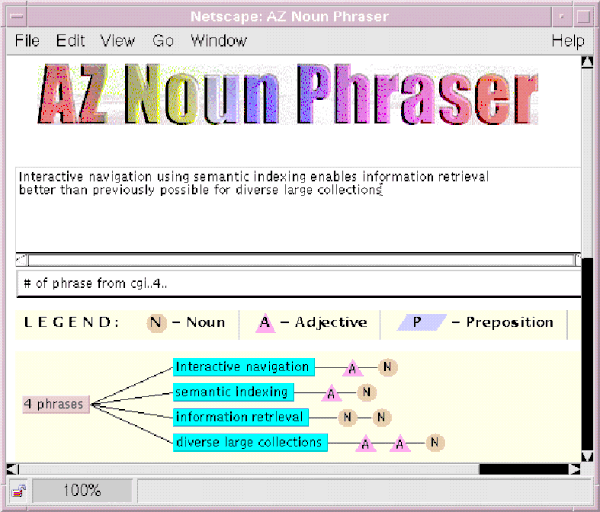
Figure 2: Tagged noun phrases
Concept Association: Concept association attempts to generate weighted, contextual concept (term) association in a collection to assist in concept-based associative retrieval. It adopts several heuristic term weighting rules and a weighted co-occurrence analysis algorithm. Figure 3 shows the associated terms for "information retrieval" in a sample collection of project reports of the DARPA/ITO Program - TP (Term Phrase) such as "IR system," "information retrieval engine," "speech collection," etc.
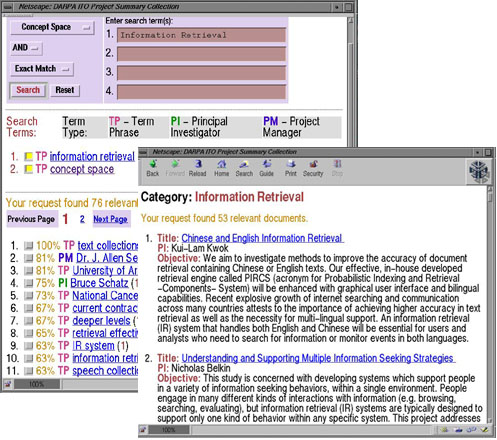
Figure 3: Associated terms for "information retrieval"
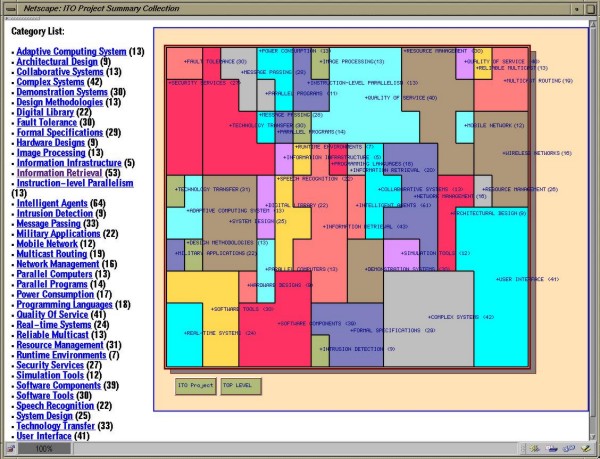
Automatic Categorization: A category map is the result of performing a neural network based clustering (self-organizing) of similar documents followed by automatic category labeling. Documents that are similar to each other (in noun phrase terms) are grouped together in a neighborhood on a two-dimensional display. As shown in the colored jigsaw-puzzle display in Figure 4, each colored region represents a unique topic that contains similar documents. Topics that are more important often occupy larger regions. By clicking on each region, a searcher can browse documents grouped in that region. An alphabetical list that is a summary of the 2D result is also displayed on the left-hand-side of Figure 4, e.g., Adaptive Computing System (13 documents), Architectural Design (9 documents), etc.
[High Resolution Version of Image]
Figure 4: Category Map
Advanced Visualization: In addition to the 2D display, the same clustering result can also be displayed in a 3D helicopter fly-through landscape as shown in Figure 5, where cylinder height represents the number of documents in each region. Similar documents are grouped in a same-colored region. Using a VRML plug-in (COSMO player), a searcher is then able to "fly" through the information landscape and explore interesting topics and documents. Clicking on a cylinder will display the underlying clustered documents.
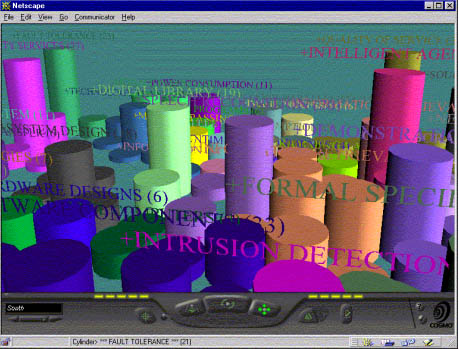
Figure 5: VRML interface for category map
Discussions and Future Directions
The techniques discussed above were developed in the context of the Illinois DLI project, especially for the engineering domain. The techniques appear scalable and promising. We are currently in the process of fine-tuning these techniques for collections of different sizes and domains. Significant semantic research effort for multimedia content has been funded continuously by a multi-year DARPA project (1997-2000).
In the new Digital Libraries Initiative Phase 2 project entitled: "High-Performance Digital Library Classification Systems: From Information Retrieval to Knowledge Management," we will continue to experiment with various scalable textual analysis, clustering, and visualization techniques to automatically categorize large document collections, e.g., NLMs Medline collection (9 million abstracts) and the indexable web pages (50 million web pages). Such system-generated classification systems will be integrated with human-created ontologies (NLMs Unified Medical Language Systems and the Yahoo directory).
Selected semantic analysis techniques discussed above have recently been integrated with several Internet spider applications. In CI (Competitive Intelligence) Spider, users supply keywords and starting URLs for fetching web pages. The graphical CI Spider automatically summarizes and categorizes the content in fetched pages using noun phrases and graphical concept maps. In Meta Spider, users supply keywords to extract web pages from several major search engines (e.g., Alta Vista, Lycos, Goto, Snap). The Meta Spider then summarizes content in all web pages, similar to CI Spider. Both software programs are available for easy free download at the Artificial Intelligence Lab web site: http://ai.bpa.arizona.edu.
Acknowledgments
This work was funded primarily by:
- NSF/CISE "Concept-based Categorization and Search on Internet: A Machine Learning, Parallel Computing Approach," NSF IRI9525790, 1995-1998.
- NSF/ARPA/NASA Illinois Digital Library Initiative Phase 1 project, "Building the Interspace: Digital Library Infrastructure for a University Engineering Community," NSF IRI9411318, 1994-1998.
- National Center for Supercomputing Applications (NCSA), "Parallel Semantic Analysis for Spatially-Oriented Multimedia GIS Data," High-performance Computing Resources Grants (Peer Review Board), on Convex Exemplar and SGI Origin 2000, June 1996-June 1999 (IRI960001N).
- Department of Defense, Advanced Research Projects Agency (DARPA), "The Interspace Prototype: An Analysis Environment based on Scalable Semantics," June 1997-May 2000 (N66001-97-C-8535).
Bibliography
[1] H. Chen.
Machine learning for information retrieval: neural networks, symbolic learning, and genetic algorithms.
Journal of the American Society for Information Science, 46(3):194-216, April 1995.[2] H. Chen, A. L. Houston, R. R. Sewell, and B. R. Schatz.
Internet browsing and searching: User evaluations of category map and concept space techniques.
Journal of the American Society for Information Science, 49(7):582-603, May 1998.[3] H. Chen and D. T. Ng.
An algorithmic approach to concept exploration in a large knowledge network (automatic thesaurus consultation): symbolic branch-and-bound vs. connectionist Hopfield net activation.
Journal of the American Society for Information Science, 46(5):348-369, June 1995.[4] H. Chen, B. R. Schatz, T. D. Ng, J. P. Martinez, A. J. Kirchhoff, and C. Lin.
A parallel computing approach to creating engineering concept spaces for semantic retrieval: The Illinois Digital Library Initiative Project.
IEEE Transactions on Pattern Analysis and Machine Intelligence, 18(8):771-782, August 1996.[5] T. DeFanti and M. Brown.
Visualization: expanding scientific and engineering research opportunities.
IEEE Computer Society Press, NY, NY, 1990.[6] B. S. Manjunath and W. Y. Ma.
Texture features for browsing and retrieval of image data.
IEEE Transactions on Pattern Analysis and Machine Intelligence, 18(8):837-841, August 1996.[7] A. T. McCray and W. T. Hole.
The scope and structure of the first version of the UMLS semantic network.
In Proceedings of the Fourteenth Annual Symposium on Computer Applications in Medical Care, pages 126-130, Los Alamitos, CA, November 4-7 1990. Institute of Electrical and Electronics Engineers.[8] A. Paepcke, S. B. Cousins, H. Garcia-Molino, S. W. Hasson, S. P. Ketcxhpel, M. Roscheisen, and T. Winograd.
Using distributed objects for digital library interoperability.
IEEE COMPUTER, 29(5):61-69, May 1996.[9] G. Salton.
Automatic Text Processing.
Addison-Wesley Publishing Company, Inc., Reading, MA, 1989.[10] B. R. Schatz.
Information retrieval in digital libraries: bring search to the net.
Science, 275:327-334, January 17 1997.[11] B. R. Schatz and H. Chen.
Digital libraries: technological advances and social impacts.
IEEE COMPUTER, 32(2):45-50, February 1999.[12] B. R. Schatz, B. Mischo, T. Cole, A. Bishop, S. Harum, E. Johnson, L. Neumann, H. Chen and T. D. Ng.
Federating search of scientific literature.
IEEE COMPUTER, 32(2):51-59, February 1999.[13] H. D. Wactlar, T. Kanade, M. A. Smith, and S. M. Stevens.
Intelligent access to digital video: Informedia project.
IEEE COMPUTER, 29(5):46-53, May 1996.[14] R. Wilensky.
Toward work-centered digital information services.
IEEE COMPUTER, 29(5):37-45, May 1996.
Copyright © 1999 Hsinchun Chen
Top | Contents
Search | Author Index | Title Index | Monthly Issues
Previous story | Next story
Home | E-mail the EditorD-Lib Magazine Access Terms and Conditions
DOI: 10.1045/october99-chen

![[High Resolution Version of Image]](fig_4v1.JPG){kind=link}