 |
D-Lib Magazine
November/December 2015
Volume 21, Number 11/12
Table of Contents
NLP4NLP: The Cobbler's Children Won't Go Unshod
Gil Francopoulo
IMMI-CNRS + TAGMATICA, France
Joseph Mariani
IMMI-CNRS + LIMSI-CNRS, France
Patrick Paroubek
LIMSI-CNRS, France
Point of contact for this article: Gil Francopoulo, gil.francopoulo@wanadoo.fr
DOI: 10.1045/november2015-francopoulo
Printer-friendly Version
Abstract
For any domain, understanding current trends is a challenging and attractive text mining task, especially when suitable tools are recursively applied to publications from the very domain they come from. Our research began by gathering a large corpus of Natural Language Processing (NLP) conferences and journals for both text and speech, covering documents produced from the 60's up to 2015. Our intent is to defy the old adage: "The cobbler's children go unshod", so we developed a set of tools based on natural language technology to mine our scientific publication database and provide various interpretations according to a wide range of perspectives, including sub-domains, communities, chronology, terminology, conceptual evolution, re-use, trend prediction, and novelty detection.
Keywords: Terminological Extraction, Text Mining, Language Resources, Natural Language Processing
1 Introduction
The work presented here deals with the collection, use and deployment of a corpus of scientific papers gathering a large content of our own research field, i.e. Natural Language Processing (NLP), covering both written and speech sub-domains and extended to a limited number of corpora, for which Information Retrieval and NLP activities intersect. This corpus was collected at LIMSI-CNRS (France) and is named NLP4NLP. It contains currently 64,128 documents coming from various conferences and journals with either public or restricted access. This is almost all the existing published articles in our field, aside from the workshop proceedings and the published books. The approach is to apply NLP tools on texts about NLP itself, taking advantage of the fact that we are knowledgeable about the domain ourselves, something very useful for appreciating the pertinence of the results returned by automatic tools when dealing with author names, domain terminology or evolving trends.
The aim of this article is to describe the corpus and the companion toolkit as well as some extracts of the linguistic results, however, the space limitation does not allow to present a full linguistic study of the computation results.
2 Existing Corpora and Other Studies
There are numerous NLP corpora on the Web; the most famous is the ACL Anthology which offers a little more than 20,000 ACL documents [Bird et al., 2008] to which could be added a series of documents coming from other sites such as the 4,552 from LREC and the 1,019 from TALN. Other sites exist, such as SAFFRON which displays results processed from ACL Anthology, LREC or CLEF. The site managed at the University of Michigan by the CLAIR group is more focused on ACL and provides search functionalities supported by more elaborate numerical computations [Radev et al., 2009]. Although these sites are extremely valuable for the community, their main weakness is that the scientific perimeter is limited to papers dedicated only to written processing or text transcriptions, except for LREC, a conference which covers both written and spoken language processing. This situation is understandable because the conferences on speech are mostly managed by two large associations which are ISCA (for Interspeech, ICSLP and Eurospeech) and the IEEE Signal Processing Society for the ICASSP conferences. Comparatively, the ACL Anthology corpus represents only 35% of our corpus, the remaining part being made of publications essentially from ISCA and IEEE Signal Processing. Since our laboratory works both in the written and spoken language domains, we had to address both. It should be added that our investigation perimeter is restricted to NLP and speech; in particular it is much smaller than the one encompassed by more general sites like Google Scholar or Research Gate.
Various studies were conducted on scientific publications, notably in 2012 the workshop organized by ACL in Jeju (South Korea): "Rediscovering 50 years of Discoveries in Natural Language Processing" [Banchs, 2012]. There was also the work of Florian Boudin [Boudin, 2013] and the studies presented for the 25 years of ISCA during Interspeech 2013 [Mariani et al., 2013] and for the 15 years of LREC during LREC-2014 [Mariani et al., 2014]. ACL and LREC conferences have been compared recently in [Bordea et al., 2014]. All these works study the content of the texts, in contrast with studies which process only keywords and metadata like [Hoonlor et al., 2013] from ACM and IEEE Xplore DL.
3 Objectives
Our aim is not solely to collect documents but to use them to better understand our field and to summarize knowledge as well as to offer advanced bibliographic services. An example application is, for instance, to determine automatically which are the most popular terms today, and to compute who first introduced these terms.
4 Organization of Documents
We define sub-corpora (for instance COLING) as either a conference or a journal. For each document, there are two elements: the textual content and its metadata. Originally, the textual content is in PDF format, of two kinds:
- the PDF holds only scans of the original document;
- the text of the original document is searchable and retrievable from the PDF file.
The metadata we considered for our study comprise the corpus name, the year, the authors (with the given name(s) well identified from the family name(s)), and the document title. Metadata have been cleaned by an automatic processing and manually checked by some experts of the domain. The metadata can be considered "cleaner" than the ones generally available, in the sense that we fixed, in general, various typos and inconsistencies that are in the version publicly available. As an extra resource, we also have the ISCA member registry which permits us to determine author gender for people with an epicene given name. Moreover, a manual identification of gender for LREC authors with an epicene given name has also been performed, because we made a dedicated study on LREC [Mariani et al., 2014].
5 Corpus
Currently, the global NLP4NLP corpus comprises 34 sub-corpora:
| short name |
# docs |
format |
long name |
content rights |
period |
| acl |
4,264 |
conference |
Association for Computational Linguistics |
free access |
1979-2015 |
| acmtslp |
82 |
journal |
ACM Transaction on Speech and Language Processing |
private access |
2004-2013 |
| alta |
262 |
conference |
Australasian Language Technology Association |
free access |
2003-2014 |
| anlp |
329 |
conference |
Applied Natural Language Processing |
free access |
1983-2000 |
| cath |
932 |
journal |
Computers and the Humanities |
private access |
1966-2004 |
| cl |
776 |
journal |
American Journal of Computational Linguistics |
free access |
1980-2014 |
| coling |
3,833 |
conference |
Conference on Computational Linguistics |
free access |
1965-2014 |
| conll |
842 |
conference |
Computational Natural Language Learning |
free access |
1997-2015 |
| csal |
718 |
journal |
Computer Speech and Language |
private access |
1986-2015 |
| eacl |
900 |
conference |
European Chapter of the ACL |
free access |
1983-2014 |
| emnlp |
2020 |
conference |
Empirical Methods in Natural Language Processing |
free access |
1996-2015 |
| hlt |
2,266 |
conference |
Human Language Technology |
free access |
1986-2015 |
| icassps |
9,534 |
conference |
International Conference on Acoustics, Speech and Signal Processing — Speech Track |
private access |
1990-2015 |
| ijcnlp |
1,217 |
conference |
International Joint Conference on NLP |
free access |
2005-2015 |
| inlg |
227 |
conference |
International Conference on Natural Language Generation |
free access |
1996-2014 |
| isca |
18,369 |
conference |
International Speech Communication Association |
free access |
1987-2015 |
| jep |
507 |
conference |
Journées d'Etudes sur la Parole |
free access |
2002-2014 |
| lre |
276 |
journal |
Language Resources and Evaluation |
private access |
2005-2014 |
| lrec |
4,552 |
conference |
Language Resources and Evaluation Conference |
free access |
1998-2014 |
| ltc |
299 |
conference |
Language and Technology Conference |
private access |
2009-2013 |
| modulad |
232 |
journal |
Le Monde des Utilisateurs de L'Analyse des Données |
free access |
1988-2010 |
| mts |
756 |
conference |
Machine Translation Summit |
free access |
1987-2013 |
| muc |
149 |
conference |
Message Understanding Conference |
free access |
1991-1998 |
| naacl |
1,186 |
conference |
North American Chapter of ACL |
free access |
2000-2015 |
| paclic |
1,040 |
conference |
Pacific Asia Conference on Language, Information and Computation |
free access |
1995-2014 |
| ranlp |
363 |
conference |
Recent Advances in Natural Language Processing |
free access |
2009-2013 |
| sem |
950 |
conference |
Lexical and Computational Semantics / Semantic Evaluation |
free access |
2001-2015 |
| speechc |
549 |
journal |
Speech Communications |
private access |
1982-2015 |
| tacl |
92 |
journal |
Transactions of the Association of Computational Linguistics |
free access |
2013-2015 |
| tal |
168 |
journal |
Revue Traitement Automatique du Langage |
free access |
2006-2014 |
| taln |
1,019 |
conference |
Traitement Automatique du Langage Naturel |
free access |
1997-2015 |
| taslp |
6,535 |
journal |
Transactions on Audio, Speech and Language Processing |
private access |
1975-2015 |
| tipster |
105 |
conference |
Tipster DARPA text program |
free access |
1993-1998 |
| trec |
1,756 |
conference |
Text Retrieval Conference |
free access |
1992-2014 |
It should be noted that the majority (90%) of the documents comes from conferences, with the rest coming from journals. The overall number of words is 18M. Initially, texts are in four languages: English, French, German and Russian. The number of texts in German and Russian is less than 0.5%. They are detected by the automatic language detector of TagParser and are ignored [Francopoulo, 2007]. Three percent of the texts are in French. They are kept with the same status as the English ones. This is not a problem because our NLP pipeline is bilingual. Note that TagParser is an industrial multilingual NLP pipeline and the motivation for using TagParser was that this parser is a well known to us, and much more rapidly usable.
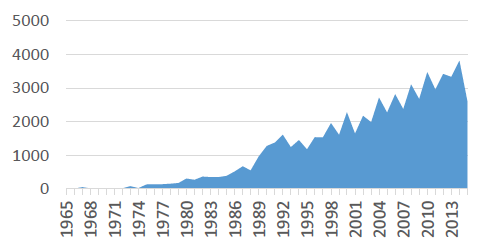
Figure 1: Number of documents over time
As shown in Figure 1, the number of documents started to climb in the 90's. There are 3,336 documents in 2013, then 3,817 in 2014 but only 2,591 documents in 2015, because it is too early in the year (September) and some conferences are not yet published.
6 Source Data Model
As a convention, we use "Document" for an article which has been published in a given conference or journal. We use "Paper" for the physical object which holds a unique identifier. The difference is subtle, as we will show. In fact, it could be observed that the total of the cells of the table does not give exactly a grand total of 64,128 documents but slightly more (67,105) because a small number of conferences are joint conferences for a given year, which means that a single paper matches two different documents which respectively belong to two different corpora. Quantitatively, this is not an important numeric phenomenon, because it is marginal with respect to the grand total, but these situations make the handling of sub-corpora more complex. More precisely, an algorithm operating at the level of a corpus must process all the contents of the sub-corpus, but an algorithm operating at the level of the whole database must take care to avoid processing the same content twice. In the same vein, we call the representation of somebody who published within a given sub-corpus "Author", and we call the representation of an author over the whole database "Person". Of course, an "Author" instance is associated with a "Person" instance.
We use the Unified Modeling Language (UML) to specify the data structure [Rumbaugh et al., 2004]. In Figure 2 below, the specification is organized as a "Russian dolls" structure with a corpus belonging to the whole database (see NLP4NLP class in the diagram). An event is aggregated within a corpus dated with a specific year. A document is aggregated within an event and finally, an author is aggregated within a corpus. In contrast, the notions of "Paper" and "Person" do not belong to a specific event: they are global to the whole database. They are simply referenced and possibly shared by different events.
This structure is rather basic and constitutes the source data model. The various tools will then be able to start from these data, to make complex computations and finally to adorn this structure with their results, which in turn could be used by other tools. However, the basic skeleton of the data model remains the same.
The UML data model (Figure 2) is specified as follows, according to the standard UML conventions such that:
- a box is a class,
- a box has a name and optionally some attributes,
- a line with a diamond represents the aggregation (i.e. a "part of" relation),
- an arrow means an oriented association.
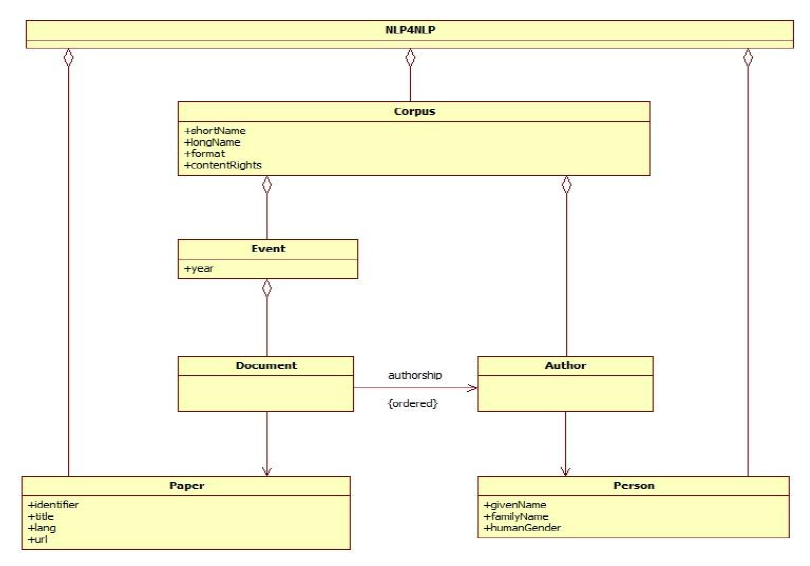
Figure 2: Source Data Model
7 Preprocessing Part#1
Textual contents and metadata are built independently in parallel. For PDF documents, we use PDFBox in order to extract the content. When the PDF document is not a text but a sequence of images, we apply an OCR by using Tesseract. The result is not perfect and a small number of errors are detected using the PDFBox API. The texts are then homogenous and coded in Unicode-UTF8.
8 Quality Evaluation and Calibration
Before going into the details of the tools, let's mention an important step which is the calibration of the preprocessing. For each corpus, an automatic parsing is performed with TagParser for identifying out-of-vocabulary (OOV) words in the documents. When an unknown word is found there are two solutions: either it is really a OOV word or it is a preprocessing error. The lexicon coverage being large, the number of OOV words is generally low. The number of inflected forms is 300K for English and 700K for French. To complement this language specific lexicon, a multilingual database called "Global Atlas" based on 1.1M proper nouns has been added to cover cities, organization names, etc. [Francopoulo et al., 2013].
We make the hypothesis that the number of known words divided by the number of words in the texts, is a good indicator of the average quality of the initial data and processing. Of course, this is an approximation of the real error rate. An automatic detailed report is produced to detect abnormal cases with the words ordered in inverse frequency. This mechanism is important to detect early problems. The calibration permits also to make modifications in the preprocessing steps and to compare quantitatively the various engineering steps to ensure homogeneity of the data produced. We tried different tools, for example ParsCit [Councill et al. 2008] which was used for the ACL Anthology studies in 2012. We also tried Grobid [Lopez et al., 2010] but the tool was not able to run on Windows and our machines are Linux, Windows and Mac OSX.
The calibration showed that computing author names, titles and content globally and directly from the PDF is a bad option with regard to the resulting quality. The percentage difference was always between 1.5% and 4%, depending on the year. This is why we do not build metadata from the PDF anymore.
The overall error rate estimation is 2.3%. This rate depends on the type of source file. The documents dated from the 60's until the 80's contain a lot of OCR files that are often of poor quality, so the rate is higher than the modern ones, as shown in Figure 3, but this rate should be related to the fact that the number of documents over this period is low, as shown in Figure 1.
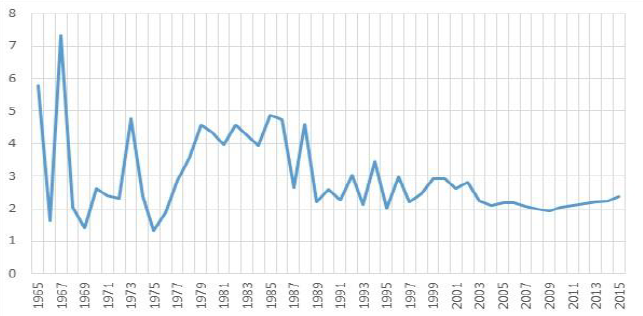
Figure 3: Error Rate Estimation Over Time
9 Preprocessing Part #2
As said earlier, some extraction errors are detected automatically by the PDFBox API, but some others are not. For some texts, PDFBox seems to run smoothly, but the result is in fact rubbish. The calibration allows to track these situations which are difficult to catch. After some trials, we decided to reject a text with more than 9% of errors.
With the extraction stabilized, the rest of the preprocessing can be applied. An end-of-line processing is run with TagParser dictionary in order to distinguish caesura and composition hyphenation. When a caesura is encountered, the two fragments of the word are joined. Then, a set of "pattern matching" rules are applied to separate the abstract, the body and the reference section. The result is an XML structured file.
Concerning the metadata, the author name and the title are extracted from the conference program or the BibTeX material, depending on the source. Each author name is split into a given name and a family name with an automatic check against a large ISO-LMF dictionary comprising 74,000 given names. An automatic matching process is applied between different metadata records in order to normalize author names textual realization (e.g. matching initial with first name or normalizing compound first name typography). Another check is then applied in order to track duplicates caused by a given name versus family name inversion or the presence versus absence of accents. Unlike the first process, this last check does not automatically fix the problems but only diagnoses them. The result is then manually checked by some members of the team who are familiar with the domain.
10 Computation
We developed a set of tools called "NLP4NLP toolkit" in order to study the content of the corpus. The aim is not to invent new algorithms for all the functionalities and research directions (which is obviously impossible), but rather to implement basic algorithms for all the functionalities as a first step, and secondly to study the content and use the system as a bibliographic service. All the tools have been developed by the team members, except when an external tool is mentioned. The implementation has been performed in Java in a portable way. As a third step, in the future, we could then decide to improve a particular functionality and take time to compare the state-of-the-art tools.
Generally, the computation results are presented in flat colored HTML tables in order to be easily read by the team members, but a limited number of results are in tabular format in order to be directly inserted into the R package or Excel.
The NLP4NLP toolkit produces the following results:
Basic counting: the goal is to follow for each corpus the evolution along the time line. The number of different authors is 47,940 for 569 events. The average number of documents for an event is 114 documents.
Coauthoring counting: the goal is to follow the number of coauthors along the time line. The results show that this number is constantly increasing regardless of the corpus. Over the whole archive, the average number of coauthors varies from 1.5 for the Computer and the Humanities journals, to 3.6 for LREC. Some additional counts are made concerning the signature order: is an author always or never mentioned as first author?
Renewal rate: the goal is to distinguish a situation which is characterized by a rather frozen group of authors (possibly over a long period of time), by comparison with a high renewal rate evolution that could be qualified as a "fresh blood" effect.
Gender counting: the author sexual gender is determined from the given name together with a member registry for ISCA and LREC for authors with an epicene given name. The goal is to study the proportion of men and women with respect to time and corpus.
Geographical origin: for a certain number of corpora, we have access to affiliations and we are able to compute and compare the distribution of the organizations, countries and continents.
Collaboration studies: a collaboration graph is built to determine the cliques and connected components in order to understand the groups of authors who work together (in fact, cosign). For each author, various scores are computed, like harmonic centrality, betweenness centrality and degree centrality [Bavelas, 1948], [Freeman, 1978]. We determine whether an author collaborates a lot or not, and whether an author sometimes signs alone or always signs with other authors. We compute a series of global graph scores like diameter, density, max degree, mean degree, average clustering coefficient and average path length in order to compare the different conferences and to understand whether the authors within a given conference effectively collaborate.
Citations: the reference sections of the documents are automatically indexed and the citation links are studied within the perimeter of the 34 corpora. The reference section and the citation links are matched by means of a "robust key" computation, ignoring the variations of typographical case markings, spaces, special characters and articles. This "robust key" is then paired with the family name of the first author to compute the match. The H-Index are computed for each author and conference. The differences are important, starting at 5 for JEP and 11 for TALN (French conferences) to 76 for ACL, and this point highlights the citation problem with respect to the language of diffusion. As for the collaboration study, the citation graphs are built both for papers and authors. We are then able to determine which are the most cited documents compared to the most citing ones. It is easy to compute the publication rate with respect to the citation rate with for instance Kishore Papineni who did not published a lot, but whose document proposing the BLEU score (Bilingual Evaluation Understudy) is cited 1,502 times within our corpus. The most cited author is Hermann Ney with 5,242 citations, with a self-citation rate of 17%. It should be noted that this is not the maximum: some authors have a self-citation rate of 18% over their whole career. It should be added that, aside from self-citations, 54% of the papers are never cited in the NLP4NLP reference corpus, and if the self-citations are considered, the rate decreases to 43%.
We observe that the 10 most cited documents are the following ones:
Table 2: Top Cited Documents
| title |
rank |
corpus |
year |
authors |
# ref |
| Bleu: a Method for Automatic Evaluation of Machine Translation |
1 |
acl |
2002 |
Kishore A Papineni, Salim Roukos, Todd R Ward, Wei-Jing Zhu |
1,502 |
| Building a Large Annotated Corpus of English: The Penn Treebank |
2 |
cl |
1993 |
Mitchell P Marcus, Beatrice Santorini, Mary Ann Marcinkiewicz |
1,149 |
| SRILM — an extensible language modeling toolkit |
3 |
isca |
2002 |
Andreas Stolcke |
1,020 |
| A Systematic Comparison of Various Statistical Alignment Models |
4 |
cl |
2003 |
Franz Josef Och, Hermann Ney |
849 |
| Moses: Open Source Toolkit for Statistical Machine Translation |
5 |
acl |
2007 |
Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, Christopher Dyer, Ondřej Bojar, Alexandra Constantin, Evan Herbst |
842 |
| Statistical Phrase-Based Translation |
6 |
hlt, naacl |
2003 |
Philipp Koehn, Franz Josef Och, Daniel Marcu |
823 |
| The Mathematics of Statistical Machine Translation: Parameter Estimation |
7 |
cl |
1993 |
Peter E Brown, Stephen A Della Pietra, Vincent J Della Pietra, Robert L Mercer |
811 |
| Minimum Error Rate Training in Statistical Machine Translation |
8 |
acl |
2003 |
Franz Josef Och |
715 |
| Maximum likelihood linear regression for speaker adaptation of continuous density hidden Markov models |
9 |
csal |
1995 |
Chris Leggetter, Philip Charles Woodland |
564 |
| Suppression of acoustic noise in speech using spectral subtraction |
10 |
taslp |
1979 |
Steven F Boll |
555 |
Terminological extraction: the goal is to extract the domain terms from the abstracts and bodies of the texts. This tool is important because the results will be the input for the following tools: term evolution, weak signals, term clouds, innovative feature and classification (c.f. infra). Our approach is called "contrastive strategy" and contrasts a specialized corpus with a non-specialized corpus in the same line as TermoStat [Drouin, 2004]. The main idea is to reject words or sequences of words of the "ordinary" language which are not interesting and to retain the domain terms. Two large non-specialized corpora, one for English and one for French, were parsed with TagParser. The English corpus was made up of the British National Corpus (aka BNC), the Open American National Corpus (aka OANC), the Suzanne corpus release-5 and the English EuroParl archives (years 1999 until 2009) with 200M words. The French corpus was Passage-court with 100M words. The parsed results were filtered with syntactic patterns (like N of N) and finally two statistical matrices were recorded. Our NLP4NLP texts were then parsed and contrasted with this matrix according to the same syntactic patterns. Afterwards, we proceeded in two steps. First, we extracted the terms and we studied the most frequent ones in order to manually merge a small number of synonyms which were not in the parser dictionary. Second, we reran the system. The extracted terms are for the most part single terms (95% for LREC for instance). In general, they are common nouns as opposed to rare proper names or adjectives.
The pros and cons of the contrastive strategy have already been studied, especially with respect to the specific level of the term. Other approaches like the one implemented in Saffron are oriented towards the construction of a domain model based on internal domain coherence [Bordea et al., 2013] and are more focused on discovering intermediate or generic terms. Our strategy favors the leaves of the hierarchy, and is less sensitive to generic terms that can be used in other domains because these terms may be encountered in the non-specialized corpus. With our objective being to study the relation of the specialized terms with respect to the accurate time line, the contrastive strategy is more adequate.
Bibliographic searches on metadata and deep parsing: the parser natively produces an ISO-MAF and ISO-SynAF conforming format. Let's recall that ISO-MAF is the ISO standard for morphosyntactic representations, published as ISO-24611. ISO-SynAF is the specification dedicated to syntax published as ISO-24615. These data are then translated into RDF in order to inject these triplets into the persistent storage Apache-Jena and thus to allow the evaluation of SPARQL queries. It should be noted that instead of processing an indexation and query evaluation on raw data, we index the content after preprocessing. The reason is threefold:
- we avoid low level noise like caesura problems which are fixed by the preprocessing step,
- the query may contain morphosyntactic filters like lemmatized forms or part-of-speech marks, and
- the query may contain semantic filters based on named entities semantic categories like company, city or system names.
Of course, all these filters may be freely combined with metadata. The graphical User Interface is currently character-based and not as sophisticated and user-friendly as the ACL Anthology Searchbench from DFKI [Schäfer et al., 2011].
Term evolution: with respect to the time line, the objective is to determine the terms which are popular. For LREC, for instance, the most popular term over a long period of time is "annotation": this is not surprising because the conference is dedicated to linguistic resources. Next, with slightly lower scores, the popular terms remaining are "WordNet", "parser", "part-of-speech", "tagger" and "lemma". We determine the terms which were not popular and which became popular like "synset", "XML", "Wikipedia", "metadata" and "treebank". Some terms were popular and are not popular anymore, like "encoding" or "SGML". We also study a group of manually selected terms and compute the usage of "trigram" compared to "ngram". Let's add that there are some fluctuating terms (depending on a specific time period) like "Neural Network", "Tagset" or "FrameNet" (see [Mariani et al., 2014] for an extensive study of term trends in LREC, and [Hall et al., 2008] [Paul et al., 2009] [Jin et al., 2013] for ACL Anthology).
Weak signals: the goal is to study the terms which have a too small number of occurrences to be statistically taken into consideration but which are considered as "friends" of terms whose evolution is interpretable statistically. The notion of friend is defined by the joint presence of the term within the same abstract. Thus, we find that "synset" has friends like "disambiguation" or "Princeton".
Innovative feature: based on the most popular terms during the last years, the goal is to compute the author, the document and the conference mentioning this term for the first time. Thus, for instance, "SVM" appears in the LREC corpus for the first time in an Alex Weibel's document published in 2000. It is then possible to detect the conferences producing the most innovative documents.
Hybrid individual scoring: the goal is to compute a hybrid scoring combining: collaboration, innovation, production and impact. The collaboration score is the harmonic centrality. The innovation score is computed from a time-based formula applied to term creation combined with the success rate of the term over the years. The production is simply the number of signed documents. The impact is the number of citations. We then compute the arithmetic mean from these four scores. The objective is not to publish an individual hit parade but to form a short list of authors who seem to be important within a given conference.
Classification: from the extracted terms, it is possible to compute the most salient terms of a document from TF-IDF, with the convention that the salient terms are the five terms with the highest TF-IDF. Then a classification is computed in order to gather similar documents within the same cluster. We use a UPGMA algorithm on a specific corpus. This tool is very helpful, because when we pick an interesting document, the program suggests a cluster of documents which are semantically similar, in the same vein as Amazon proposing a similar object or YouTube proposing the next video.
Reuse and plagiarism studies: we define "self-reuse" of an author as the recall of a text by the author himself in a posterior publication, regardless of the coauthors. We define "reuse" as the recall of a text written by a group of authors X by an author Y who does not belong to group X, together with a citation. We define "plagiarism" as the recall of a text written by a group of authors X by an author Y who does not belong to group X, without any citation. In a first implementation, we compared the raw character strings but the system was rather silent. Now we make a full linguistic parsing to compare lemmas and we filter the secondary punctuation marks. The objective is to compare at a higher level than case marking, hyphen variation, plural, orthographic variation ("normalise" vs "normalize"), synonymy and abbreviation. A large set of windows of 7 sliding lemmas are compared and a similarity score is computed. We consider self-reuse and reuse/plagiarism when a given level is exceeded (10% for self-reuse and 3% for reuse/plagiarism). Concerning the results, we did not notice any true cheating. In contrast, we observed some groups of authors (with an empty intersection) who apparently copy/paste massive fragments of texts while engaged in common collaborations. In contrast, self-reuse is a very common and abusive phenomenon.
11 Next Step
Until now, the corpus has been used only by the team members. Some results are given on demand, for instance when a colleague asks which articles contain "Arabic" in the title, or a when colleague asks us to compute the evolution of the use of the terms belonging to a particular semantic topic.
Aside from the Sparql evaluation system which is interactive, the NLP4NLP toolkit is more a collection of batch programs than an integrated workbench like ArnetMiner [Tang et al., 2008], Rexplore [Osborne et al., 2013] or ASE [Dunne et al., 2012]. The problem is that some programs take hours to run; however, this collection of tools is coherent and runs on the same data. Because our main objective is the study of a conference or the comparison of conferences, this organization fits our needs for now.
We have already set up an experimental web site to give more extensive details. We plan shortly to make the source corpus and the computed results publicly available resources. We need to check first with the legal department. In fact, although it seems that this is possible for the majority of the texts (80%) because the texts and metadata already have public access, there are small problems, such as mention of a licence (which is different from one corpus to another) or some tricky details concerning the PDF URL (are we allowed to refer to a copy, or do we need to refer to the original URL, which sometimes is not stable?). In contrast, a certain number of metadata and textual contents belong to Springer, or associations like IEEE. As a result, we will have two corpora: the entire corpus called NLP4NLP, and also ONLP4NLP (O for open) which will be provided as a public resource. The format used for this deployment is RDF so in order to respect W3C recommendations concerning Open Linked Data and to be compatible with the current regional project Center for Data Science (CDS).
References
[1] Rafael E Banchs (ed.) 2012 Proceedings of the ACL 2012 Special Workshop on Rediscovering 50 Years of Discoveries, Jeju, Korea.
[2] Alex Bavelas 1948. A Mathematical Model for Group Structures. Applied Anthropology.
[3] Steven Bird, Robert Dale, Bonnie J Dorr, Bryan Gibson, Mark T Joseph, Min-Yen Kan, Dongwon Lee, Brett Powley, Dragomir R Radev, Yee Fan Tan 2008. The ACL Anthology Reference Corpus: A Reference Dataset for bibliographic Research in Computational Linguistics. LREC 2008, 28-30 May 2008, Marrakech, Morocco.
[4] Georgeta Bordea, Paul Buitelaar, Barry Coughlan 2014. Hot Topics and Schisms in NLP : Community and Trend Analysis with Saffron on ACL and LREC Proceedings, in Proceedings of LREC 2014, 26-31 May 2014, Reykjavik, Iceland.
[5] Georgeta Bordea, Paul Buitelaar, Tamara Polajnar 2013. Domain-independent term extraction through domain modelling, in Proceedings of the 10th International Conference on Terminology and Artificial Intelligence, Villetaneuse, France.
[6] Florian Boudin 2013. TALN archives: une archive numérique francophone des articles de recherche en traitement automatique de la langue. TALN-RÉCITAL 2013, 17-21 June 2013, Les Sables d'Olonne, France.
[7] Issac G Councill, Giles C Lee, Min-Yen Kan 2008. ParsCit: An open-source CRF reference string parsing package, in Proceedings of LREC 2008, May 2008, Marrakesh, Morocco.
[8] Patrick Drouin 2004. Detection of Domain Specific Terminology Using Corpora Comparison, in Proceedings of LREC 2004, 26-28 May 2004, Lisbon, Portugal.
[9] Cody Dunne, Ben Shneiderman, Robert Gove, Judit Klavans, Bonnie Dorr 2012. Rapid Understanding of Scientific Paper Collections: Integrating Statistics, Text Analytics, and Visualization. Journal of the American Society for Information Science and Technology, 2351-2369, 2012.
[10] Gil Francopoulo 2007. TagParser: well on the way to ISO-TC37 conformance. ICGL (International Conference on Global Interoperability for Language Resources), Hong Kong, PRC.
[11] Gil Francopoulo, Frédéric Marcoul, David Causse, Grégory Piparo 2013. Global Atlas: Proper Nouns, from Wikipedia to LMF, in LMF-Lexical Markup Framework, Gil Francopoulo ed, ISTE/Wiley.
[12] Linton C Freeman 1978. Centrality in Social Networks, Conceptual Clarification. Social Networks.
[13] David Hall, Daniel Jurafsky, Christopher D Manning 2008 Studying the History of Ideas Using Topic Models, in Proceedings of EMNLP 2008, Honolulu, Hawaii, USA.
[14] Apirak Hoonlor, Boleslaw K Szymanski, Mohammed J Zaki 2013. Trends in Computer Science Research, Communications of the ACM, vol 56, n°10.
[15] Yiping Jin, Min-Yen Kan, Jun-Ping Ng, Xiangnan He 2013, Mining Scientific Terms and their Definitions: A Study of the ACL Anthology in Proceedings of EMNLP, 18-21 October 2013, Seattle, Washington, USA.
[16] Patrice Lopez, Laurent Romary 2010. HUMB: Automatic Key Term Extraction from Scientific Articles in GROBID, in Proceedings of the 5th International Workshop on Semantic Evaluation, ACL 2010, Uppsala, Sweden.
[17] Joseph Mariani, Patrick Paroubek, Gil Francopoulo, Marine Delaborde 2013. Rediscovering 25 Years of Discoveries in Spoken Language Processing: a Preliminary ISCA Archive Analysis, in Proceedings of Interspeech 2013, 26-29 August 2013, Lyon, France.
[18] Joseph Mariani, Patrick Paroubek, Gil Francopoulo, Olivier Hamon 2014. Rediscovering 15 years of Discoveries in Language Resources and Evaluation: The LREC Anthology Analysis, in Proceedings of LREC 2014, 26-31 May 2014, Reykjavik, Iceland.
[19] Francesco Osborne, Enrico Motta, Paul Mulholland 2013. Exploring Scholarly Data with Rexplore, in Proceedings of ISWC 2013, Sydney, Australia.
[20] Michael Paul, Roxana Girju 2009. Topic Modeling of Research Fields: An Interdisciplinary Perspective, in Proceedings of RANLP, 14-16 September 2009, Borovets, Bulgaria.
[21] Dragomir R Radev, Pradeep Muthukrishnan, Vahed Qazvinian 2009. The ACL Anthology Network Corpus, in Proceedings of the ACL Workshop on Natural Language Processing and Information Retrieval for Digital Libraries, Singapore.
[22] James Rumbaugh, Ivar Jacobson, Grady Booch 2004. The Unified Modeling Language Reference Manual, second edition, Addison Wesley.
[23] Ulrich Schäfer, Bernard Kiefer, Christian Spurk, Jörg Steffen, Rui Wang 2011. The ACL Anthology Searchbench, in Proceedings of the ACL-HLT System Demonstrations. Portland, Oregon, USA.
[24] Jie Tang, Jing Zhang, Limin Yao, Juanzi Li, Li Zhang, Zhong Su 2008. ArnetMiner: Extraction and Mining of Academic Social Networks, in Proceedings of KDD 2008, Las Vegas, Nevada, USA.
About the Author
 |
Gil Francopoulo is a French linguist and computer scientist. He holds a PhD in computer science from Paris 6 University. Since 1980, he alternates (or combines) an activity in the public research sector and in the private software industry, as well as entrepreneur or employee. He worked, or still work for GSI-Erli, Lexiquest, INRIA, CNRS, Tagmatica and Akio Spotter. In 2008, he co-wrote the ISO standard for electronic lexicons: Lexical Markup Framework (LMF). His current research interests are text-mining, machine learning, predictive modeling, term extraction, named entities detection, semantic knowledge bases and natural language processing. He authored 60 publications. For details, see http://www.tagmatica.com.
|
 |
Joseph Mariani is a Fellow researcher at CNRS (France). He was the general director of LIMSI-CNRS from 1989 to 2000, and head of its "Human-Machine Communication" department. He became Director of the "Information and Communication Technologies" department at the French Ministry for Research from 2001 to 2006, and then served as director of the Institute for Multilingual and Multimedia Information (IMMI), a joint International Laboratory involving LIMSI, the Karlsruhe Institute of Technology (KIT) and the Technical University of Aachen (RWTH) in Germany. He served as president of the European (now International) Speech Communication Association (ISCA), and of the European Language Resources Association (ELRA). He authored more than 500 publications.
|
 |
Patrick Paroubek has been working at Centre National de la Recherche Scientifique (CNRS), a french governmental research agency, in the field of Natural Language Processing since 1993. He holds both a Ph.D in Computer Science from Paris 6 University and an Habilitation à Diriger les Recherches in Computer Science from Paris-Sud University. In 2013, he became president of ATALA, the French scientific association for Natural Language Processing and is collection director for the science and technology publisher ISTE, London. His current research interest concerns the evaluation of Natural Language Processing technology, corpora and linguistic representations, sentiment analysis and opinion mining as well as scientometrics.
|
|