|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Alessandro Senserini Gail Hodge |
![]()
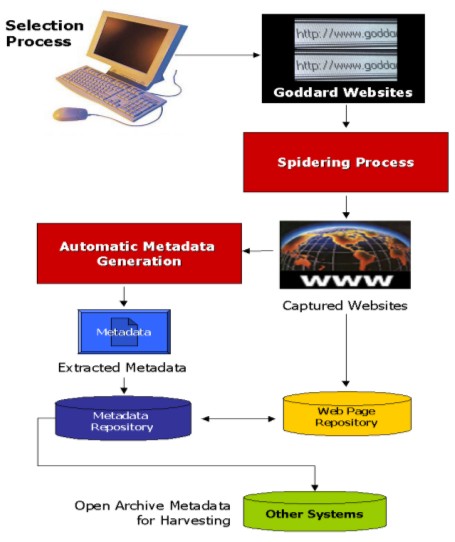
AbstractThe NASA Goddard Space Flight Center (GSFC) is a large engineering enterprise, with most activities organized into projects. The project information of immediate and long-term scientific and technical value is increasingly presented in web pages on the GSFC intranet. The GSFC Library as part of its knowledge management initiatives has developed a system to capture and archive these pages for future use. The GSFC Library has developed the Digital Archiving System to support these efforts. The system is based on standards and open source software, including the Open Archives Initiative-Protocol for Metadata Harvesting, Lucene, and the Dublin Core. Future work involves expanding the system to include other content types and special collections, improving automatic metadata generation, and addressing challenges posed by the invisible and dynamic web. 1.0 IntroductionIn 2001, the NASA Goddard Space Flight Center (GSFC) Library began investigating ways to capture and provide access to internal project-related information of long-term scientific and technical interest. These activities were coincident with NASA GSFC's enterprise-wide emphasis on knowledge management. This project information resides in a number of different object types, including videos, project documents such as progress reports and budgets, engineering drawings and traditional published materials such as technical reports and journal articles. Increasingly, valuable project information is disseminated on the GSFC intranet as web sites. These web sites may be captured as part of wholesale, periodic intranet "snapshots" or when making backups for disaster recovery. However, these copies are not made with the purpose of long-term preservation or accessibility. Therefore, the sites on the GSFC intranet are subject to much the same instability as public Internet web sites—sites that have been moved, replaced or eliminated entirely. The goal of the Web Capture project is to provide a web application that captures web sites of long-term scientific and technical interest, stores them, extracts metadata, if possible, and indexes the metadata in a way that the user can search for relevant information. 2.0 Analytical ApproachIn 2001 and 2002, the GSFC Library investigated the feasibility of capturing selected GSFC intranet sites. The first activity was to review the literature and determine the state of the practice in web capture. Projects such as the EVA-Project in Finland [1], Kulturarw3 in Sweden [2] and PANDORA in Australia [3] were reviewed. Information was gathered from the Internet Archive [4] regarding its approaches. These and other projects are well documented by Day [5]. However, the GSFC requirements differ from those of national libraries or the Internet Archive, because the set of documents is at once more limited in scope and broader than those of interest to these organizations. Most national libraries are concerned with archiving and preserving the published literature of a nation or capturing cultural heritage. This allows the national library to establish algorithms like those developed in Sweden to capture sites with the specific country domain (e.g., "se" for Sweden) or those that are about Sweden but hosted in another country. National libraries (such as Australia) are concerned about electronic journals, books or other formally published materials that are disseminated only in electronic form via the Internet. However, GSFC is interested in a wide range of content types including project documentation such as progress reports, budgets, engineering drawings and design reviews; web sites, videos, images and traditional published materials such as journals articles, manuscripts and technical reports. Unlike the Internet Archive, GSFC is concerned about a small selective domain for which proper access restrictions and distribution limitations are as important as the original content itself. The goal was to capture content of scientific and technical significance rather than information from human resources or advertisements from the employee store. Therefore, a mechanism that captured the whole domain was inappropriate. The GSFC system needed to be more selective; yet that selection could not be based solely on an analysis of the domain components as represented in the URL. This led to the realization that there would need to be some manual web site selection involved. However, the desire was to keep this to a minimum. The result is a hybrid system that combines aspects of many of the projects reviewed while addressing the unique requirements of the GSFC environment. 3.0 System FlowThe hybrid system consists of a combination of human selection, review, and automated techniques based on off-the-shelf software, custom scripts, and rules based on an understanding of the GSFC project domain. The system flow is presented in Figure 1 below. The following sections describe each step in the flow.
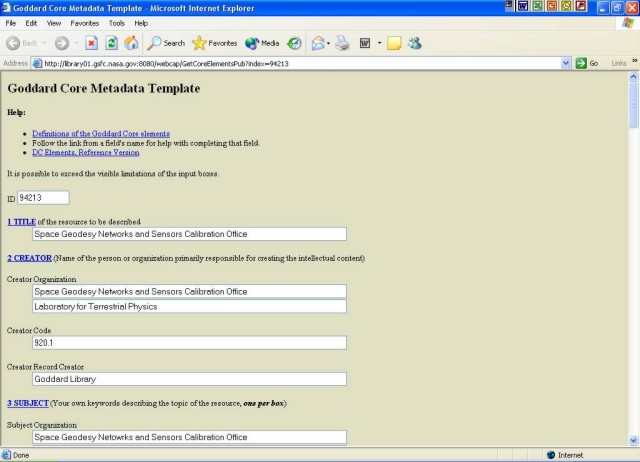
3.1 Web Site SelectionAt GSFC the scientific and technical mission, and the generation of related information (other than that maintained by the Library or prepared for public outreach and education), is centered in four directorates. Based on this knowledge of the GSFC environment, the selection of GSFC URLs began with the homepages for the Space Sciences, Earth Sciences, Applied Engineering and Technology, and Flight Programs and Projects directorates. The higher-level sites, in most cases the homepages for the directorates, were selected manually, along with the next two levels in a direct path, eliminating those pages with non-scientific information such as phone directories and staff-related announcements. These selected URLs became the root URLs for the capture process. The analyst entered the URLs into an Excel spreadsheet along with some characteristics of the site, including a taxonomy of link types; the code number for the directorate; the year the site was last modified; the intended audience for the site; the level from the homepage; whether or not the site contains metatags; and anticipated problems when spidering, such as dynamic images or deep web database content. This initial analysis provided important information about how to collect the sites. It identified anomalies that required human intervention, outlined requirements for the spidering software and provided statistics for the estimation of storage requirements for the captured sites. The spreadsheet created by the analyst became a checklist for the technician who launched and monitored the automated capture process. The technician transferred the spreadsheet back to the analyst after the capture process was completed in order to identify the metadata records to be reviewed and enhanced. 3.2 Web Site Capture3.2.1 Spidering SoftwareA major objective of the early testing was to identify the spidering software that would meet the requirements of the project. At the beginning of this prototype, another concern was the cost. The search engines used for searching the GSFC intranet can index web pages, but they do not capture the actual sites. There was a limited selection of commercially available software to be used for the capture process. For the purposes of this prototype, the GSFC Library selected the Rafabot 1.5© [6]. It is a bulk web site downloading tool that allows limited parameter setting and provides searchable results in organized files. 3.2.2 Capture ParametersParameters were set to ensure inclusion of most pages in the web sites while controlling the resulting content. The key parameters available in Rafabot include the number of levels for the crawl based on the root URL as the starting point, the domains to be included or excluded, file sizes, and mime or format types. The parameters were set to capture the content of pages from the root URL down three levels. While this setting does not result in the capture of all pages in a web site, it prevents the spidering tool from becoming circuitous and wandering into parts of the sites that are administrative in nature. The spider is set to capture only pages in the Goddard domain, because pages outside the GSFC domain (made available by contractors and academic partners) may have copyrighted information or access restrictions. Sites with .txt, .mpeg and .mdb extensions were also eliminated from the crawl. Early testing showed that the majority of these sites are extremely large datasets, large video files and software products. While these objects meet the criteria regarding long-term scientific interest, the spidering time and storage space required were prohibitive. In addition, many of these objects, such as the datasets, are already managed by other archives at GSFC, such as the National Space Science Data Center. In order to be more selective about these formats, future work will address how to establish agreements with parts of the GSFC organization to link to these objects while they physically remain in the other data archives on the center. 3.2.3 The Capture ProcessThe selected root URLs identified by the analysis described above were submitted to the capturing software. This may be done individually or as a text file in batch. Rafabot creates a folder with a name similar to the spidered URL, containing all the web pages captured. Each web page crawled has the name in lowercase, slash characters in the name are replaced with underscore characters, and sometimes the order of the words changes. These transformations occur because Rafabot changes all the hyperlinks in the HTML code of the pages captured to allow navigability off-line. The tool does not mirror the structure of the web site with all its directories, but it creates one folder with all the web pages contained in it. 3.3 Creating the Metadata DatabaseMetadata creation includes the three main components—the metadata scheme, automatic metadata extraction, and human review and enhancement of the metadata. The Web Capture application runs on a Linux platform and has been developed in the Java programming language, including Java Servlet and Java Server Pages (JSP) technologies. This combination allows the developer to separate the application logic, usually implemented with servlets, from the presentation aspect of the application (JSP). Servlet and JSP technologies with the addition of Jakarta Tomcat (servlet engine) provide a platform to develop and deploy web applications. 3.3.1 The Goddard Core Metadata SchemeAs part of a larger project to collect, store, describe and provide access to project-related information within the GSFC community and to make it available via a single search interface, the GSFC Library developed the Goddard Core Metadata Element Set, based on the qualified Dublin Core [7]. The primary emphasis of this element set is on resource discovery and evaluation, i.e., helping the user find the document, evaluate its usefulness and locate it whether in paper or in digital form. The Goddard Core Metadata Set was specifically developed to provide better discovery and evaluation in the Goddard context of project management. The extensions to the Dublin Core include important information related to projects such as the Instrument Name, the Project Name, the GSFC Organizational Code, and the Project Phase. The Goddard Core Metadata Set is described in detail in an upcoming publication [8]. The element set is also available online [9]. 3.3.2 Automatic Metadata CreationOnce the Goddard Core Metadata Set was defined, the Digital Archiving Team established mechanisms for creating skeleton records using a series of off-the-shelf and homegrown scripts. When a collection of web pages is submitted through the user interface, the application processes the home page and parses it to extract metadata that can be related to all the web pages included in the crawling results for that root URL. A candidate metadata record is created from three different processes—automatic extraction of common metatags, extraction of GSFC specific metatags, and "inherited" metadata content from higher level pages. The Web Data Extractor© (WDE) [10] is a tool used to help in creating metadata. Given a URL, it extracts metadata information from the web page by parsing the HTML for common metatags. These tags include title, description, keywords, last modified date and content length. A text file with the metadata is created. However, many of these metatags are not routinely used on GSFC web sites. For these "binary" web pages the application extracts only the format (from the suffix file name or Mime type) of the web page in order to fill the 'Format' field of the Goddard Core. The GSFC Web Guidelines require a minimum set of HTML metatags for the first and second level pages of a web site. The metatags include the standard tags like title and keywords, but they also include GSFC-specific metatags like 'orgcode' (organization code within the Goddard Space Flight Center), 'rno' (Responsible NASA Official), 'content-owner', 'webmaster', and the more common 'description' metatags. A script extracts these elements from the HTML. In addition, the contents of many of the metadata elements for lower-level pages can be inherited from the related higher level pages. These elements include Organization and Organization Code. This inherited content is used to fill these elements unless content specific to the lower level page is available based on the metatag extraction processes.3.3.3 Creating the Metadata RecordsThe metadata extracted and extrapolated by the application are merged with the metadata provided by the Web Data Extractor (WDE). Since the punctuation of the URLs has been changed, this is done by parsing the original URL from WDE and the name of the page from Rafabot into tokens or smaller units, which are then matched against each other. This method works for HTML pages but is problematic for non-HTML pages since it is difficult to find a match without the original URL. Following the merge, the resulting metadata is mapped to the Goddard Core elements. The metadata information and other pertinent information about web pages are stored in a MySQL relational database. The web pages themselves are stored directly in the file system. 3.3.4 Editing and Enhancing the Metadata RecordsOnce the candidate metadata information is stored in the database, the Goddard Core Metadata Template allows the cataloger to review, modify and enhance the Goddard Core elements (Figure 2). The analyst accesses the record by the record number provided automatically on a web page created by the metadata creation process. The URL allows the analyst to reference the spreadsheet developed at the beginning of the selection process to look for problematic components such as dynamically generated parts of the page.
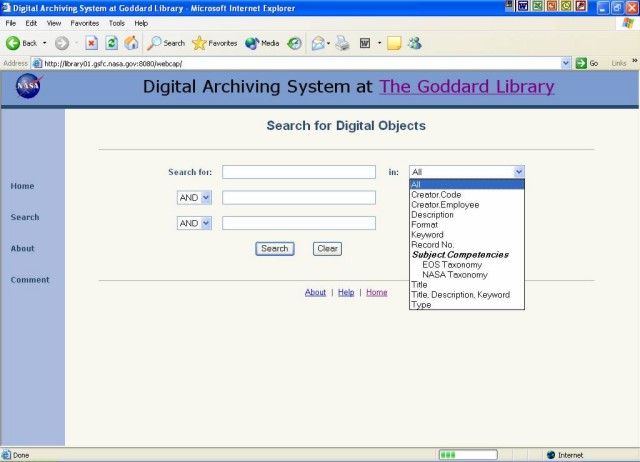
The analyst also corrects or enhances the metadata. Every input box of the form has plus and minus buttons to add or delete instances of an element. Any element, except the record ID assigned by the system, can be edited. Controlled vocabulary terms, a text description and free text keywords are added manually during the review process. Some elements, such as the subject.competencies element, have values selected from controlled vocabularies accessible with dropdown menus. (At this point, all elements are optional and repeatable, but future work will establish a set of mandatory elements based on the requirements for preservation and the GSFC Web Guidelines for meta-tagging.) 3.4 Searching the Metadata RecordsLucene [11] is an open source search engine technology used to index and search the metadata. This technology allows storing, indexing and/or tokenizing the different values of the Goddard Core elements. When an element is tokenized, the text is processed by an analyzer that strips off stop words like "a", "the", "and", which are not relevant, converts the text to lowercase and makes other optimizations before the text is indexed. In this context Lucene indexes and searches only the metadata from the database, but Lucene could be set up to index the full text of the pages (HTML, XML, etc.) or other document formats (Word, PDF, etc.) if tools to extract text from them exist. The search form allows the user to enter terms and select specific metadata elements of the Goddard Core on which to search (Figure 3). Current searchable fields include: title, description, keyword, subject.competencies, creator.employee, creator.code and others. The Subject element has two subcategories: NASA Taxonomy and Earth Observing System Taxonomy. Each taxonomy has a controlled vocabulary that appears on the form as a drop-down menu.
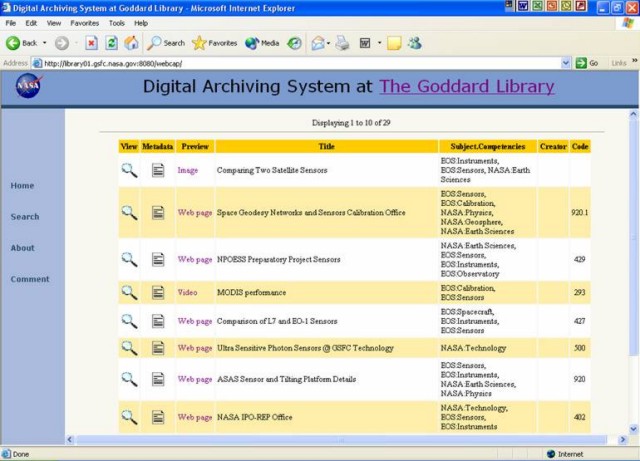
When a search is executed, the results are paged and displayed in a table that contains basic information to allow the user to evaluate the resulting hits (Figure 4). In the prototype, these fields include the Title, Subject (taken from a controlled list of NASA Competences or Disciplines), Creator (the author), and Code (the GSFC code with which the author is affiliated).
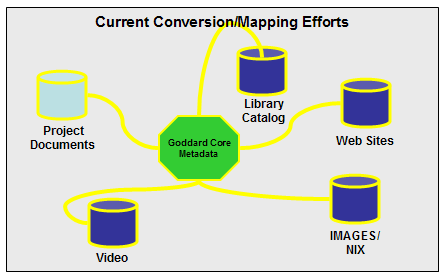
The web page is displayed by clicking on the magnifying glass under "View". This option opens a new resizable window to allow navigation and better examination of the content. The full metadata record is viewed by clicking on the symbol under "Metadata". In addition, the user can preview the digital object in a small size pop-up window by moving the mouse over the corresponding field of the "Preview" column. 4.0 Challenges and Opportunities for Future WorkThis prototype has identified several challenges and opportunities for future efforts. These can be grouped into technical issues related to the web capture, integration with other systems, and extension of the types of digital objects that are included in the system. Some of these activities are already underway, as funding has been identified. 4.1 Technical Issues Related to Web CaptureThe technical issues related to capturing web sites are well documented by Day [5]. While Day is addressing the more general issues related to the capture of web sites from the public Internet, many of these issues and others occur in an intranet environment. We encountered several problems when performing the crawl on the increasingly complex scientific web sites. The most common problem resulted from the increasingly dynamic nature of those web sites. This includes content that is controlled by Javascript and Flash technologies, and dynamic content driven from database queries or content management systems. The crawling tool is unable to crawl a web page containing a search form that queries a database. The "deep or invisible web" is difficult to capture automatically, and there is a need to develop customized software that is able to do this programmatically. Through a related project funded by the GSFC Director's Discretionary Fund, in a partnership with the Advanced Architectures and Automation Branch, the challenges regarding the capture of the invisible and dynamic web were evaluated in more detail, and some preliminary thoughts about how to deal with this problem were explored. The project team has also made contact with other groups working on this issue including the Internet Archive and an international group of national libraries [12]. There were also cases where additional viewer software, such as that required for some 3-D models, was needed in order to provide full functionality. Based on these problems, we identified alternative spidering tools during the course of the project. We believe that tools like WebWhacker© [13] or BackStreet© [14] may provide better results in crawling web pages containing dynamic scripts. Future implementations will test these other tools. We will continue to research better tools for the capturing of web sites and to work with others on the issues related to the capturing of deep and dynamic web content. In order to balance the size and scope of the resulting capture files, some web sites that go to many levels are cut off by the level parameter that was chosen. By analyzing the number of dead-end links when the initial capture is performed, the system could alert the technician that a particular site needs to be recaptured with a parameter that captures sites to more levels. A major concern for full-scale implementation of such a web capturing system is the degree of manual intervention required to select sites. A more automated method for identifying the sites of scientific and technical interest is needed. For example, terms that occur frequently in non-scientific web sites, such as sites that focus on Human Resources, could be used to exclude these sites from the selection and capture process. More automatic metadata creation will require additional analysis of the web content and more complex rules based on the GSFC environment. HTML is the main language used on the web, but web pages are also represented in other formats like PDF, Word, PowerPoint, and different image formats. Automatic metadata generation is gaining more importance in the field of information retrieval, and there are several open source tools that extract metadata from files other than HTML. For example, ImageMagick™ [15], a package of utilities to manipulate image data could be used to retrieve information about the size and resolution of the image. Wordview converts Word documents to HTML or other formats [16]. Extracting metadata from PDF files is particularly important, since most of the project documents are delivered in PDF format. Several tools for converting PDF files to simple text and extraction of metadata headers from PDF files were investigated [17]. This has not been successful to-date because of the instability of the software and the variety of PDF versions in the collection. While there are many avenues for continued development of automated metadata creation in the GSFC intranet environment, it is unlikely that all elements can be created in a completely automatic fashion. For this reason, the GSFC Library has begun working with the webmasters and the authors of web-based objects to encourage the incorporation of compliant metadata in their web pages and the development of tools, applications and training to facilitate the inclusion of metadata when digital objects are created. 4.2 Integrating the Web Capture with Other SystemsIn order to improve the system's interoperability, the GSFC Library has implemented the Open Archives Initiative—Protocol for Metadata Harvesting (OAI-PMH) v. 2.0 [18]. The implementation consists of a network accessible server able to process the six OAI-PMH requests, expressed as HTTP requests, and return the search results in XML format. The server currently acts as a "data provider" as defined in the OAI-PMH framework. The OAI-PMH could be used to contribute to larger metadata repositories either on-center, across NASA or through other consortia. In addition, the OAI-PMH could be used as a "data harvester" to integrate web site searching with other digital objects. 4.3 Extending the System to Handle Other Digital ObjectsDuring the development of the Web Capture System, opportunities for integrating the access to the web sites captured in this project with other digital knowledge assets were identified. Projects to capture digital images, streaming media from scientific colloquia and lecture series held on center, and digital versions of more traditional project documents were initiated. Similar to the Web Capture System, other systems were developed to archive these digital objects with metadata in commercial, third-party or home-grown systems. OAI, XML and the Goddard Core are the mechanisms for bringing the metadata into a central repository for searching across diverse digital objects (Figure 5).
In a recent pilot project, the GSFC Library incorporated metadata from videos, images, web sites and project documents into a single repository that can be searched simultaneously using the Lucene search engine and displayed from a single interface. 4.4 The Longer-Term VisionThe activities described above focus on creating a web site archive. However, the ultimate goal is to preserve the sites that are captured and make them permanently accessible into the future. As with many other projects, the focus has been on capturing the materials before they are lost rather than on preservation strategies [19]. However, ultimately the technologies on which these web sites are built will be replaced with new versions and even newer technologies—going beyond the web as we now know it. To ensure continued availability of these knowledge assets to the GSFC community, the GSFC Library is working closely with others in the area of preservation to determine how to preserve the captured web sites once they are no longer maintained by the current owners or curators. Appropriate preservation strategies, preservation metadata to ensure long-term management, and access and rights management control must be developed in order to accomplish this. Acknowledgements:This work was conducted under NASA Goddard Contract NAS5-01161. The authors gratefully acknowledge the support and encouragement of Janet Ormes and Robin Dixon of the NASA Goddard Space Flight Center Library. Notes and References[1] Helsinki University and Center for Scientific Computing in Finland. "Functional and Technical Requirements for Capturing Online Documents" (EVA-Project). No Date. [2] Royal Library of Sweden. Kulturarw3. [Online]. Available: <http://www.kb.se/kw3/ENG/Description.htm> [April 20, 2004]. [3] National Library of Australia. (2003a). "Collecting Australian Online Publications." [Online]. Available: <http://pandora.nla.gov.au/BSC49.doc> [April 20, 2004]. [4] Internet Archive. (2001). "Internet Archive: Building an 'Internet Library'". [Online]. Available: <http://www.archive.org> [April 20, 2004]. [5] Day, M. (2003). "Collecting and Preserving the World Wide Web: A Feasibility Study Undertaken for the JISC and Wellcome Trust." [Online]. Available: <http://library.wellcome.ac.uk/assets/WTL039229.pdf> [April 30, 2004]. [6] Rafabot is copyrighted by Spadix Software. [Online]. <http://www.spadixbd.com/rafabot/>. [7] Dublin Core Metadata Initiative. "Dublin Core Metadata Element Set 1.1." [Online]. Available: <http://www.dublincore.org/documents/dces/> [April 20, 2004]. [8] Hodge, G., T. Templeton, et al "A Metadata Element Set for Project Documentation." Science & Technology Libraries. [In press]. [9] Goddard Core Descriptive Metadata Element Set, [Online]. Available: <http://library.gsfc.nasa.gov/mrg/htm/ReduceCore(Format)_10-19-04.htm> [November 5, 2004].[10] Web Data Extractor is copyrighted by the WebExtractor System. [Online]. Available: <http://www.webextractor.com/> [May 25, 2004]. [11] Jakarta Lucene open source software from Apache Jakarta. [Online]. Available: <http://jakarta.apache.org/lucene/docs/index.html> [May 19, 2004]. [12] International Internet Preservation Consortium. Deep Web Working Group. [13] WebWhacker is copyrighted by Blue Squirrel. [Online]. Available: <http://www.bluesquirrel.com/products/whacker/index.html> [May 25, 2004]. [14] BackStreet is copyrighted by Spadix Software. [Online]. Available: <http://www.spadixbd.com/backstreet/> [May 25, 2004]. [15] ImageMagick is copyrighted by ImageMagick Studio LLC. [Online]. Available: <http://www.imagemagick.org/> [May 25, 2004]. [16] Automatic Metadata Generation Section: DSpace (October 21, 2003). [Online]. Available: <http://scoop.dspace.org/story/2003/10/21/124126/09> [May 19, 2004]. [17] PDF Box. [Online]. Available: <http://www.pdfbox.org/> [May 19, 2004]. [18] Open Archives Initiative—Protocol for Metadata Harvesting (OAI-PMH) v. 2.0. [Online]. Available: <http://www.openarchives.org/OAI/openarchivesprotocol.html#Repository> [May 19, 2004] . [19] Hodge, G. & E. Frangakis. "Digital Preservation and Permanent Access to Scientific Information: The State of the Practice." Joint Report for ICSTI/CENDI. March 2004. [Online]. Available: <http://cendi.dtic.mil/publications/04-3dig_preserv.pdf> [April 20, 2004].Copyright © 2004 Alessandro Senserini, Robert B. Allen, Gail Hodge, Nikkia Anderson, and Daniel Smith, Jr. |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/november2004-hodge
|