![]()
D-Lib Magazine
November 2002
Volume 8 Number 11
ISSN 1082-9873
In Brief
Report on ISMIR 2002 Conference Panel I: Music Information Retrieval Evaluation Frameworks
Contributed by:
J. Stephen Downie
University of Illinois at Urbana-Champaign
Urbana-Champaign, Illinois, USA
<[email protected]>
At the inaugural International Symposium on Music Information Retrieval (ISMIR 2000) [1], organizers challenged attendees to begin thinking about what a formal framework for meaningful Music Information Retrieval (MIR) / Music Digital Library (MDL) evaluation might look like. At ISMIR 2001, Bloomington, Indiana, an informal session to discuss the creation of standardized MIR/MDL test collections, tasks and evaluation metrics was convened that resulted two important outcomes.
First, it led to the adoption of a formal resolution expressing the pressing need to establish a MIR/MDL evaluation framework that could be used by all in the multidisciplinary and multinational MIR/MDL research community. This resolution now bears the signatures of 90+ researchers and interested parties. It also faithfully represents the astonishing breadth of disciplines and nationalities of those engaged in MIR/MDL research (http://music-ir.org/mirbib2/resolution).
Second, I was able to secure exploratory funding from the Andrew W. Mellon Foundation to gather community input on this important topic. As part of the information gathering process, White Papers [2] were solicited and two special meetings were convened:
Meeting #1: The Workshop on the Creation of Standardized Test Collections, Tasks, and Metrics for Music Information Retrieval (MIR) and Music Digital Library (MDL) Evaluation was held at the Second Joint Conference on Digital Libraries (JCDL 2002) in July of 2002 (http://www.ohsu.edu/jcdl). Dr. Ellen Voorhees, Project Manager of the National Institute of Standards and Technology's, Text REtrieval (TREC) Conference (http://trec.nist.gov), presented the keynote address. Her talk (and White Paper) focussed on the potential applicability of the TREC evaluation paradigm to the needs of the MIR/MDL community. The creation of a TREC-like evaluation model was a theme played out by the other presenters. "TREC-like" is used here deliberately as attendees made it clear that MIR/MDL systems, because they deal with music, are not directly analogous to text retrieval systems. Issues raised for more detailed examination included the successful integration of multiple formats (i.e., audio, symbolic representations, scores, and metadata), analysis of real-world queries (i.e., needs and uses), and the set of tasks to be examined (i.e., educational uses, scholarly uses, recreational uses, etc.).
Meeting #2: The Panel on Music Information Retrieval Evaluation Frameworks was held in Paris, 17 October as part of ISMIR 2002. Dr. Edie Rasmussen, Professor at University of Pittsburgh's, School of Information Sciences, delivered the keynote White Paper. Dr. Rasmussen further developed the TREC-like evaluation theme by providing her personal insights on the strengths and weakness of the TREC approach. So strongly did the TREC leitmotif run through the remaining White Papers that the session soon coalesced into a veritable choral unison of "How do we move forward on making a TREC-like evaluation scenario for MIR/MDL a reality?"
Much work has yet to be done before the MIR/MDL community has the TREC-like evaluation framework it so urgently requires. Copyright hurdles with regard to the acquisition of the necessary music materials (i.e., audio, symbolic representations, scores, metadata) are among the most difficult to surmount. Arriving at a community consensus about the specific tasks to be evaluated and the metrics to be used in their evaluation will not be simple. Consensus about the nature of "relevance" as it pertains to MIR/MDL queries is another open question. Notwithstanding these real problems, there are some recent developments that suggest that real progress can be made.
We have now obtained agreements-in-principle from two significant rights-holders to construct the world's first-and-only, internationally-accessible, large-scale MIR/MDL testing and development database. HNH Hong Kong International, Ltd. (http://www.naxos.com), which is the owner of the Naxos and Marco Polo recording labels, has agreed, in principle, to let the MIR/MDL community have access to its entire catalogue of Classical, Jazz, and Asian digital recordings. This generous gesture represents approximately 3,000 CDs or about 3 Terabytes of digital music information. All Media Guide, <http://www.allmusic.com>, has also agreed, in principle, to let us add to the collection its vast database of music metadata including descriptive catalogue records, discographies, and recording classifications. Details concerning the proposed system to house this collection, which we hope will form the foundation for the development of a TREC-like evaluation MIR/MDL paradigm can be found at <http://music-ir.org/evaluation/support>.
In conclusion, I would like to stress one thing. While there is community consensus on the need for TREC-like evaluation of MIR/MDL systems, there is also consensus that other evaluation methods not be ignored. To this end, I would like to solicit input from D-Lib Magazine readers who have experience in, and opinions on, non-TREC-like evaluation techniques. I will be submitting my recommendation report to the MIR/MDL community on MIR/MDL evaluation in April 2003. Before finalizing my recommendations, I will be soliciting one more round of White Papers. I would especially appreciate incorporating White Papers that examine the role non-TREC-like evaluation techniques can play in creating more comprehensive understanding of MIR/MDL systems, their uses, and their users.
Notes
[1] Links to this and the other ISMIR meetings can be found at <http://music-ir.org>.
[2] The White Papers from both meetings, along with the project outline for the Establishing Music Information Retrieval (MIR) and Music Digital Library (MDL) Evaluation Frameworks: Preliminary Foundations and Infrastructures Project, can be found at <http://music-ir.org/evaluation/wp.html>.
Report on ISMIR 2002 Conference Panel II: OMRAS Approach to Music Information Retrieval in the Real World
Contributed by:
Tim Crawford
Centre for Computational Creativity
City University, London
London, United Kingdom
<[email protected]>
The OMRAS project (Online Music Recognition and Searching: <http://www.omras.org>) was awarded three years of research funding in 1999 from the International Digital Libraries Initiative, jointly administered by the National Science Foundation (NSF) Digital Libraries Initiative in the US and the Joint Information Systems Committee (JISC) in the UK (See <http://www.dlib.org/dlib/june99/06wiseman.html>). OMRAS was a direct catalyst of the ISMIR conferences (see The History of ISMIR below). The first International Conference on Music Information Retrieval (ISMIR) was organized largely by OMRAS staff, and the series would have been much less likely to receive the generous support of the NSF without the existence of OMRAS.
The panel sought to show how a very diverse group of OMRAS researchers were able to combine their various insights and talents in a complex project drawing on several distinct academic disciplines. The entire OMRAS team was present, together with a distinguished external panelist with experience in several of these areas:
- Tim Crawford, Music, Centre for Computational Creativity, City University, London: panel moderator, UK team leader and general OMRAS coordinator (probabilistic harmonic description);
- Dr. Donald Byrd, School of Music, Indiana University: US team leader, composer and developer of Nightingale Search module (score notation searching);
- Matthew Dovey, Oxford University: designer of OMRAS (system architecture and integration strategy);
- Prof. Mark Sandler, Electronic Engineering, Queen Mary College, London: (audio team leader);
- Jeremy Pickens, Center for Intelligent Information Retrieval, University of Massachusetts: Ph.D. student (IR aspects and Java programming, language modeling, evaluation);
- Juan-Pablo Bello and Giuliano Monti, Electronic Engineering, Queen Mary College, London: Ph.D. students (monophonic and polyphonic audio music transcription);
- Dr Jose Montalvo, School of Music, Indiana University: composer and research assistant (system integration and Java programming);
- Dr Ichiro Fujinaga, McGill University: external panelist (Optical Music Recognition expert and collaborator on the Levy Sheet Music Collection OMR/MIR project at Johns Hopkins University)
The principal intention of OMRAS was to investigate some of the various techniques that might form part of an integrated real-world MIR system. It was never conceived as a single 'killer application', but rather as a suite of modules that might be custom-assembled into a system according to the requirements of the user. Thus, it might take different forms according to whether the user is a musicologist investigating a historical composer's use of musical motives or themes, for example, or simply a music-lover attempting to track down a familiar tune.
An unusual feature of the OMRAS approach is the attempt to bridge the gap between the separate domains of digital audio and symbolic music notation. While most MIR efforts are restricted to a single one of these domains, OMRAS tackles head-on the issues raised by the difficulties of polyphonic music recognition, which include the necessity for search strategies that are robust against input error of various kinds, in the belief that all 'real-world' applications in MIR must inevitably face these problems at some point.
These features of the project formed the basis for the panel discussions. After an introduction to the project from Tim Crawford, Matthew Dovey introduced the OMRAS system architecture and mentioned some of the advantages it offers. Jeremy Pickens then spoke briefly about CIIR's work on Language Modeling as a means of efficient text-document retrieval that inspired the OMRAS research on Music Modelling, before leaving to represent OMRAS at the parallel MIR Evaluation panel session. Donald Byrd gave a demonstration of the current version of his Macintosh program Nightingale Search, in which a comprehensive set of exact matching routines for pitches and durations within individual voices are implemented for passage-level retrieval within musical scores. He also gave an update on its Java version that, when complete, will allow OMRAS to incorporate the essential display features of Nightingale as an optional module for display, playback and music query-building.
After a short break Giuliano Monti ran through the essential features of OMRAS's audio front-end music-transcription programs. At present there are two distinct programs, developed as a contribution to their degrees by the two Ph.D. students funded by OMRAS, himself and Juan-Pablo Bello. While the routines will remain available to the development team in this form, at some point their best features will probably be combined together with other work in a future implementation. At present, the audio programs attempt to transcribe as many notes as possible from the raw audio, a task that is extremely hard, if not impossible in the general case; individual notes are frequently not even human-perceptible in any but the simplest polyphonic textures. An alternative approach is to extract more general musical features, and use the techniques being developed within OMRAS to match these features with what can be derived from symbolically encoded music.
In his response to the OMRAS presentations, Ichiro Fujinaga stressed the importance of the project to the MIR community and to ISMIR in particular. He then raised the topic of the management of research within a complex multi-partner project. This led to a lively discussion with contributions from several members of the audience with similar experiences. A point of agreement was in the importance of a well-organised development framework such as OMRAS's, although all the contributors to the discussion admitted that this was an ideal rather than a reality: in practice it was not easy to work scrupulously within any given framework and a certain amount of flexibility was also necessary. Further discussions arising from comments from the floor included the perennial matter of test collections and the teasing open question of musical style-dependency in the OMRAS harmonic-modeling approach; the OMRAS panel members were gratified to learn that although further experimentation on a wider range of music is clearly needed the balance of opinion seemed to be that the prospects are good. It will be interesting to see how well this judgement bears the test of time.
Report on ISMIR 2002 Conference Panel III: Similarity in Music
Contributed by:
Ludger Hofmann-Engl
Panel Moderator
The Link
Surrey, United Kingdom
<[email protected]>
Over the last few years, it has become apparent that a sound knowledge of musical similarity lies at the very heart of a successful and efficient retrieval of musical information. However, until now researchers have been working either in isolation or in small teams unable to integrate the knowledge of research undertaken in related disciplines. Even worse, a number of similarity algorithms have been developed (such as dynamic programming) without evaluation and comparison on a meta-level.
The panel "Similarity in Music" took place on Thursday, 17 October 2002 during the 3rd international conference on music information retrieval at IRCAM, Paris. The panel was moderated by L. Hofmann-Engl. It brought together the following experts from various disciplines in order to discuss fundamental issues of musical similarity:
- Simha Arom, ethnomusicologist, France, who spoke of "Melodic Similarity in African Music."
- Irène Deliège, director of the Unité de Recherche en Psychologie de la Musique, Université of Liège, Belgium and editor, Musicae Scientiae, The Journal of the European Society for the Cognitive Sciences of Music, whose talk was "The concept of similarity in the psychological investigation of listening to music."
- Eric Isaacson, Associate Professor of Music Theory, Indiana University, USA, who discussed "Similarity in posttonal music."
- François Pachet, Sony Computer Science Laboratory, Paris, on "Music SimilaritieS."
- Eleanor Selfridge-Field, Center for Computer Assisted Research in the Humanities, Stanford University, USA, on "Why is the concept of music similarity so important in art music of the European tradition?"
- Geraint Wiggins, senior lecturer, Department of Computing in City University's School of Informatics, UK, on "Horses for courses or How to choose an algorithm to do what you need."
The size of the audience fluctuated between 30 and 40 attendees at any particular time due to the overlap with two other panels being conducted concurrently.
Panel III had as its purpose to illustrate the complexity of the issue at hand (touching cognitive, cultural and music theoretical aspects) as well as to offer a forum to exercise a critical review of existing models. It was shown that similarity measures used, for instance, for the analysis of post-tonal music (E. Isaacson) might differ greatly from the needs of musical similarity in other contexts.
It was interesting to note that the gap between the music psychological insight (represented by I. Deliège) and the current state of the awareness of cognitive knowledge within the MIR scene was so acute that even formulating questions appeared to be an impossible task. However, some strong critique (G. Wiggins & E. Selfridge-Field) on dynamic programming and the insufficient structure of existing databases seemed to offer a starting point for a future evaluation process.
S. Arom raised the question whether musical similarity is cultural-dependent, sparking lively discussion and leaving the audience with the feeling that this will remain a very serious question indeed.
Not only during the panel on similarity but also during the entire conference, there was a clear tension between the goals motivated by academic research and the goals motivated by industrial purposes. It appears that unless academic research receives sufficient funding, erratic models as implemented within industrial settings might dominate the scene.
Clearly, the interaction between different disciplines is slow and awkward at present, but the panel offered a first step in the right direction.
The History of ISMIR - A Short Happy Tale
Contributed by:
Donald Byrd
Indiana University
Bloomington, Indiana, USA
<[email protected]>
Michael Fingerhut
IRCAM - Centre Pompidou
Paris, France
<[email protected]>
The ISMIR series of conferences grew from a conjunction of three loosely related events that occurred in late 1999.
1. Perhaps the most important factor was OMRAS (Online Music Recognition and Searching), a three-year project for which funding had been granted by the International Digital Libraries programs run by JISC (UK) and NSF (US) as a collaboration between the Center for Intelligent Information Retrieval at the University of Massachusetts, Amherst (US) and King's College London (UK). The US team was led by Donald Byrd, the UK team by Tim Crawford.
In the spring of 1999, Stephen M. Griffin, as program director for the NSF Digital Libraries Initiative Phase 2 (DLI2), notified Byrd that he would receive the full funding he had requested for the US part of OMRAS, but informally requested that Byrd organize a workshop on music information retrieval (music IR) as part of the project.
2. That August, the Fourth ACM Digital Library Conference (DL'99) was held in Berkeley, CA, and was followed immediately by the ACM SIGIR'99 conference, held at the same place. J. Stephen Downie (University of Illinois, Urbana-Champaign), David Huron (Ohio State University), and Craig Nevill-Manning (then of Rutgers University) had organized a small workshop on music IR at SIGIR 99, and Downie was already thinking of a larger-scale meeting as a follow-on event to that.
Byrd attended DL'99, where he met Downie. With the encouragement of Bruce Croft, director of the Center for Intelligent Information Retrieval and a very well-known researcher in the text IR world, they decided to join forces to plan a larger-scale event instead of a workshop in the normal sense. The University of Massachusetts subsequently submitted to NSF a proposal to fund the "International Symposium on Music Information Retrieval" (ISMIR) as a supplementary grant to OMRAS.
3. Later that year, Crawford, together with Carola Boehm (Performing Arts Data Service, Glasgow University), organized another early workshop on music IR—this as part of the "Digital Resources for the Humanities" conference held in London in September 1999.
NSF approved the University of Massachusetts proposal, and the first International Symposium on Music Information Retrieval (whence the acronym ISMIR; web site: <http://ciir.cs.umass.edu/music2000>) took place in Plymouth, Massachusetts in October 2000, with Byrd as general chair and Downie as program chair, and with the heavy involvement of Crawford in its organization. The full organizing committee also included Croft and Nevill-Manning. At this meeting, Michael Fingerhut (IRCAM - Centre Pompidou, Paris), who had also taken part in both the preceding workshops, offered to create and host a mailing list for interested participants of the conference, and this is how the music-ir mailing list came into being (http://ismir2002.ircam.fr/mailing-list.html). The principle of alternating the annual meeting each year between the Americas and elsewhere was established at that time. Later that year, Fingerhut was invited to join the ISMIR committee (now called the ISMIR steering committee), and presented IRCAM's candidacy for hosting a future ISMIR.
In October of the following year, ISMIR 2001 (http://ismir2001.indiana.edu) was held at Indiana University (IU), Bloomington, with Downie as general chair and David Bainbridge (University of Waikato, New Zealand) as program chair, and with the financial help of an NSF supplemental grant to the IU "Variations2" Digital Music Library Project. Jon Dunn of IU joined the ISMIR committee at this point; he was followed by Ichiro Fujinaga (then of the Peabody Conservatory of Music, Baltimore, US), Holger Hoos (University of British Columbia, Canada) and Kjell Lemström (University of Helsinki, Finland). It was also decided then to replace the word "symposium" by "conference" but keep the acronym ISMIR unchanged, as it was becoming quite well-known.
ISMIR 2002, the Third International Conference on Music Information Retrieval (http://ismir2002.ircam.fr), took place at IRCAM in Paris, in October 2002, with Fingerhut as general chair and Crawford as papers and posters committee chair, and with the continued financial help of the NSF through Indiana University, as well as that of the City Hall of Paris through its deputy mayor for new technologies and research, Ms. Danièle Auffray, and of the French National Center for Scientific Research (CNRS).
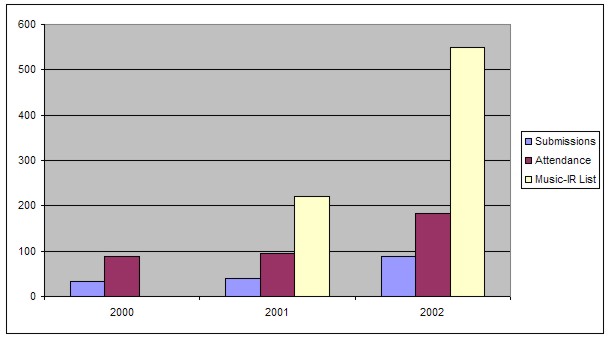
Figure 1: Graph showing growth in interest in music information retrieval and the ISMIR conferences.
The above graph shows the very rapid increase in the identified music information retrieval community (through the music-ir mailing list) and of attendance and contents at ISMIR; it reflects growing interest in this area from both academia and industry, and a continued increase in outreach to related disciplines.
ISMIR 2003 will be jointly hosted by the Library of Congress and Johns Hopkins University, and co-chaired by Susan Manus (LoC) and Sayeed Choudhury (JHU). A call for sites for ISMIR 2004 (outside of the Americas), 2005 (in the Americas) and 2006 (outside of the Americas) is being issued.
PORTAL: Presenting NatiOnal Resources To Audiences Locally
Contributed by:
Liz Pearce
Project Researcher, PORTAL
University of Hull
Hull, United Kingdom
<[email protected]>
The Presenting natiOnal Resources to Audiences Locally (PORTAL) project is exploring possibilities for the meaningful integration of external resources within institutional portals. One of the aims of the project is to highlight issues surrounding the deployment and use of institutional portals within the UK higher and further education sector. The 18-month project will demonstrate how institutionally held information can be used to enable the tailored delivery of external resources to users.
In order to assess the needs of the community JISC serves, the project will undertake a series of user requirements studies to determine both user needs for institutional portals and their requirements for externally provided quality assured content within the portal environment. These studies will inform the development of institutional portals and highlight the scope for the personalization of external resources. The project is currently working with the Resource Discovery Network (RDN), and a number of other content and service providers have expressed an interest in exploring the possibilities for incorporating their resources within a portal framework.
In order to make such integrated access to external resources meaningful for end users the project is looking at synthesising information regarding the resources, users and their institutional context. By exploring the use of existing technologies, such as RSS, OAI and Z39.50, and interfaces based on emerging web services protocols together with data specifications such as EduPerson and the IMS Learner Information Profile, the project will demonstrate the potential for the personalized presentation of resources and functionality to users.
Whilst the focus of the project is the integration of external resources, PORTAL is also undertaking work on institutional portals themselves. An implementation of JA-SIG's open source uPortal, together with associated documentation, form a key project deliverable. In parallel with our own uPortal installation, the project is currently putting together an overview of institutional portal functionality looking at education institutions in the UK, USA and Australia. As the issues surrounding portal technology and user needs emerge, the project will also undertake to explore the issues surrounding institutional portals and virtual learning environments.
The project is funded by the UK Joint Information Systems Committee (JISC) as part of their Focus on Access to Institutional Resources (FAIR) programme. The project is a joint venture between the University of Hull and UKOLN.
For further information about PORTAL, please visit the project website <http://www.fair-portal.hull.ac.uk>
For further information regarding portal activity within the UK tertiary education community, see <http://www.portal.ac.uk>
Rights and Self-archiving: The RoMEO Project
Contributed by:
Elizabeth Gadd
Research Associate
Loughborough University
Loughborough, Leicestershire, United Kingdom
<[email protected]>
In Higher Education today, there are many calls for change in the scholarly communication process. One suggestion is that academics 'self-archive' their research papers either by making them available on their own web pages, or by submitting them to an institutional repository or a subject-based archive (e.g., ArXiv, CogPrints). This is seen as a complimentary mechanism to journal publishing to achieve wider dissemination and impact of research literature. The Open Archives Initiative has developed a protocol by which metadata about the research papers can be disclosed and harvested, making wide dissemination possible.
Even though such research papers are 'given away' by academics, and metadata about them is freely created and disclosed, intellectual property rights issues are still being raised.
Self-archiving may collapse at the first hurdle if academics sign away their right to self-archive through journal publisher copyright assignment forms. Should HEIs get involved to ensure this doesn't happen—to help the academic negotiate with the publisher? Academic authors and publishers will both be surveyed by the project.
Once the paper has been self-archived, how can academics ensure that the rights they want protected (say the right to be named as author, and to stop the text being altered) are protected? Conversely, how can they ensure that other rights given them by copyright law that they may not care for (e.g., to prohibit copying) are waived?
There are also rights issues for data providers and service providers. Data providers may be pleased that their metadata is being harvested, but what if someone then starts selling access to it? Service providers may add value to the metadata they harvest, but who owns the rights in that metadata and how can they protect it?
Finally there are issues for end users. The self-archiving process may cause a number of different versions of the same paper to be available: the unrefereed preprint, the refereed postprint, the refereed version in the printed journal, and a series of electronic versions provided by the publisher's electronic journal. How can they ensure they have access to version with the least copyright restrictions?
To address some of these questions, the UK Joint Information Systems Committee have funded a one-year investigation into the rights issues surrounding the self-archiving movement. The project, called RoMEO (Rights MEtadata for Open archiving), is based at Loughborough University and will run until July 2003. The Project is being directed by Professor Charles Oppenheim, with Professor Stevan Harnad chairing the Advisory Board.
The principal aims of the project are to identify all the rights issues relevant to the self-archiving of research papers in UK HE under the Open Archive Initiative's Protocol for Metadata Harvesting (OAI-PMH) and to consider ways of addressing them. One particular goal will be the development of some simple rights metadata that can be assigned by academics depositing papers in institutional (or other) archives, disclosed by data providers and harvested by service providers under the OAI-PMH.
The members of the Project Team are inviting input from interested parties, in particular academics, publishers, OAI data and service providers, on the rights issues they face throughout the self-archiving process. To contribute, or for more information, please contact Elizabeth Gadd, Research Associate, Project RoMEO, Dept of Information Science, Loughborough University, Loughborough, Leics, LE11 3TU. Tel. 01509 228053, Email. <[email protected]>.
Project web pages are now available at
<http://www.lboro.ac.uk/departments/ls/disresearch/romeo/index.html> and will be updated throughout the course of the project. Our first survey of academic authors is also now available at <http://www-staff.lboro.ac.uk/~lbeag/Academic%20author%20questionnaire.htm>. The project would welcome its wide circulation amongst academic communities.
References
[1] Crow, R. (2002). The case for institutional repositories: a SPARC position paper. Washington DC, The Scholarly Publishing and Academic Resources Coalition.
[2] The Open Archives Initiative. URL: <http://www.openarchives.org>. (Accessed 7 October 2002.)
The Cybrarian Project
Contributed by:
Mr. Atul Sharda
e-Learning Strategy Unit
Department of Education and Skills
London, United Kingdom
<[email protected]>
The Cybrarian initiative (<http://www.dfes.gov.uk/cybrarianproject>) has been developed in order to help address the problem of a digital divide that is emerging across Britain.
An increasing range of popular, commercial and government services are being delivered over the Internet, and Information Communication Technology (ICT) skills are becoming a prerequisite for many jobs. As a result, the Department for Education and Skills, England (DfES) has developed an initiative to assist in reducing the digital divide by facilitating access to the Internet and to learning opportunities for those who currently do not, or cannot, use the Internet because of a lack of skills or confidence, or because of physical and cognitive disabilities.
The vision for the Cybrarian project is to encourage increased Internet usage throughout the UK; to help develop basic ICT skills among users; to provide easy access to information and knowledge services that will be of interest to target users (i.e., informal learning); and to allow target users to become involved in the electronic community and, as a result, to engage more positively in modern society.
The target users will be those who do not yet use the Internet and, in particular, those who are socially excluded or disabled. The total addressable group could be as large as 24 million citizens!
Cybrarian aims to take the fear and frustration out of using the Internet by providing a customised Internet search facility to cater to the individual's online needs, whether these specific needs are due to physical, cognitive or sensory impairments, or to limited ICT skills.
We expect that the majority of Cybrarian users will have little or no previous experience with the Internet. Commercial search engines do not cater to Cybrarian target users, who need simplified navigation, personalisation, and concise and coherent results. More often than not, users are overwhelmed by large quantities of indiscriminate information that is largely of little use to them.
Content for Cybrarian's services will be provided by a range of partners and will be presented to users in a way accessible to novice users, those with poor learning or literacy skills and those with poor sight and other moderate disabilities. The range of content provided will be carefully managed to appeal to users' interests and needs and will facilitate informal learning around areas of interest to individual users.
Through unique customisation and Artificial Intelligence capabilities, Cybrarian will provide users with informative and relevant information matched to their needs through an easy to use "accessible" interface.
International Children's Digital Library to Host 10,000 Books
Contributed by:
Jeff Ubois
Program Manager
The Internet Archive
San Francisco, California, USA
<[email protected]>
Later this month, the International Children's Digital Library (ICDL) will announce plans to build a large-scale digital archive of literature for children, ages three to thirteen, containing 10,000 books drawn from 100 different cultures around the world.
The collection is being assembled as part of a 5-year research project to develop innovative software and a collection of books that specifically address the needs of children as readers by offering literature to enable them to understand the global society in which they live. The ICDL will use technology to help expand the collection of every library in the world by providing access to the collection via the Internet.
"This is the beginning of a long term project to provide children around the world with access to literature from different cultures in a way that is intuitive and accessible," said the ICDL's Director, Jane White. "We currently have books from more than 27 different cultures in more than 15 different languages. This collaborative effort by government, commercial, academic, and non-profit organizations will change the way children learn about other cultures, and strengthen libraries worldwide."
The Internet Archive, the largest library of the Internet, and The University of Maryland's Human-Computer Interaction Lab, a leader in children's interface design, are leading the "construction" of the new library.
"Every book that is added to the International Children's Digital Library will be accessible by hundreds of millions of people around the world," said Brewster Kahle, digital librarian of the Internet Archive. "Universal access to all human knowledge and culture is within our grasp, and this library project is bringing publishers, librarians, and researchers together to make a system that works for children."
The ICDL's funders include the National Science Foundation (NSF), the Institute of Museum and Library Services (IMLS), the Kahle/Austin Foundation, and Markle Foundation. Additional partners include The Library of Congress and The American Library Association with additional in-kind contributions, support and advice from Octavo, Adobe Systems Inc., Alma Flor Ada, F. Isabel Campoy, Gerald McDermott, Children's Book Press, HarperCollins Publishers Inc., Random House, Scholastic Inc., Getty Publications, and Children's Book Council.
The ICDL will be formally announced in the Jefferson Building of the Library of Congress on November 20. Speakers at the event will include leaders from the ICDL's supporting organizations. For further information, see <http://www.icdlbooks.org>.
MARC4J Open Source Software
Contributed by:
Bas Peters
Project Owner
MARC4J
<[email protected]>
MARC4J (http://marc4j.tigris.org) is an open source software library for working with MARC records in Java, a popular platform independent programming language. The MARC (Machine Readable Cataloging) format was originally designed to enable the exchange of bibliographic data between computer systems by providing a structure and format for the storage of bibliographic records on half-inch magnetic tape. Though today most records are transferred by other media, the exchange format has not changed since its first release in 1967 and is still widely used worldwide. At the same time, there is a growing interest in the use of XML in libraries, mainly because the Web is moving towards a platform- and application-independent interface for information services, with XML as its universal data format.
MARC4J is designed to bridge the gap between MARC and XML. The software library has build-in support for reading and writing MARC and MARC XML data. MARC XML is a simple XML schema for MARC data published by the Library of Congress. MARC4J also provides a "pipeline" to enable MARC records to go through further transformations using an XSLT stylesheet (for example, to convert MARC data to Dublin Core in RDF/XML). This feature is particular useful since there is currently no agreed-upon standard for XML in library applications.
Although MARC4J can be used as a command-line tool for conversions between MARC and XML, its main goal is to provide an Application Programming Interface (API) to develop any kind of Java application or servlet that involves reading or writing MARC data. The core piece is a MARC parser that hides the complexity of the MARC record by providing a simple interface to extract information from MARC records. Support for XML is implemented using the standard Java XML interfaces as specified in Sun's Java API for XML Processing (JAXP). By limiting itself to the JAXP API, MARC4J is XML processor-independent and easy to integrate in applications that build on industry standards such as SAX (Simple API for XML) and DOM (Document Object Model). The fact that MARC4J is used in a growing number of library projects shows that it serves a particular need.
In the News
Recent Press Releases and Announcements
NISO and EDItEUR to Set Serials Exchange Standard
"November 4, 2002: The National Information Standards Organization (NISO) and EDItEUR are establishing a Joint Working Party (JWP) to explore the development of a common standard format for the exchange of serials subscription information."
"A NISO White Paper released in September 2002 reported that libraries, content aggregators, publishers, and third party service providers are increasingly exchanging information about serials subscription. The White Paper indicated that a standard exchange format would be beneficial to all parties in the supply chain and identified ONIX for Serials as a good foundation for such an exchange format."
"The NISO/EDItEUR group will begin work in November 2002 and will be tasked to:
- Recommend specific enhancements to the ONIX for Serials schema and documentation to support exchange of serials subscription information.
- Recommend how the query/response scenarios can be accommodated within the emerging EDItEUR framework for transaction-based exchange.
- Plan, organize and coordinate a pilot project involving publishers, intermediaries, and libraries to demonstrate the feasibility of using ONIX for Serials as an exchange format for serials subscription information."
"The Joint Working Party will be co-chaired by Priscilla Caplan, a member of the NISO Standards Development Committee and Assistant Director of the Florida Center for Library Automation, Gainesville FL and Richard Gedye, Journals Sales and Marketing Director, Oxford University Press, Oxford UK."
"The NISO White Paper, titled "The Exchange of Serials Subscription Information" by Ed Jones is featured on the NISO website at: <http://www.niso.org.html>"
"NISO is the leading accredited standards developer serving libraries and content industries (www.niso.org). EDItEUR is an international trade industry group coordinating development of the standards infrastructure for electronic commerce in books and serials (www.editeur.org)."
For further information contact: Pat Harris at <[email protected]>.
UNESCO and ICA Signed Agreement for Six-Year Cooperation
"October 31, 2002: UNESCO and the International Council on Archives (ICA) will continue to closely cooperate to enhance the management of, facilitate access to, and ensure preservation of, information that is held by public archives worldwide. This is the main thrust of the Agreement that Abdul Waheed Khan, UNESCO's Assistant Director-General for Communication and Information and ICA's Secretary General Joan van Albada signed in Paris today."
"The purpose of this agreement is to establish, for the period corresponding to UNESCO's medium-term strategy (2002-2007), a general framework in which ICA will undertake for UNESCO the execution of certain tasks provided for in UNESCO's programme and/or will undertake initiatives that complement those of UNESCO."
"The Agreement foresees that ICA and UNESCO will co-operate in the framework of the Information for All and the Memory of the World Programmes, and to foster international reflection and debate on the ethical, legal and societal challenges, which the international archival community faces with the advent of knowledge societies."
"Another area of cooperation is to facilitate and widen access to information held by archives through the digitization of information and to strengthen co-operation for the preservation of analogue and digital supports used by records and archives institutions."
"The joint support to training, continuing education and lifelong learning in records and archives management, including the production and distribution of training tools is also included in the Agreement as well as the promotion of the development and use of international standards and best practices in records and archives management."
"ICA that was established through a UNESCO backed initiative in 1948 is the central professional organization for the world archival community with more than 1,500 members in over 170 countries and territories. It brings together professional associations and individual archivists interested in researching, developing, and sharing their full range of archival expertise."
For more information, see the full press release at <http://portal.unesco.org/ci/ev.php?URL_ID=6164&URL_DO=
DO_TOPIC&URL_SECTION=201&reload=1037293066>.
OAIster: Phase 2 Improvements
(The following announcement was issued on 31 October 2002 by Kat Hagedorn, University of Michigan)
"UM DLPS is pleased to announce phase 2 of the OAIster project. This phase includes significant improvements and bug fixes, including:
- Searching using Boolean operators.
- Viewing all your results, no matter the number.
- Revising the search you just made.
- Search terms highlighted in the results.
- Addition of relevancy sorting options."
"Search OAIster now at http://oaister.umdl.umich.edu/."
"OAIster is a service provider using the OAI protocol to harvest repositories of digital object records and make them available to end-users. Currently, we are serving close to a million records from over 100 repositories. The number of records we have been harvesting has more than tripled since our launch at the end of June, and we expect it to continue to increase as the usage of OAI becomes more and more popular."
For more information, contact Kat Hagedorn at <[email protected]>.
GNU EPrints 2.2 Released
(The following announcement was issued on 31 October 2002 by Stevan Harnad, University of Southampton)
"EPrints 2 is free software which creates web based archives, containing documents and metadata."
"Major Changes:
- Added option to have 'subject editors' who may only edit certain eprints, ie. all in one subject, or only books and posters.
- Added support for XML::GDOME which is a faster XML module, but does require some more software. This is strongly recommended for non-demo systems as it's faster and uses less memory."
"For all new features in 2.2 please see: <http://software.eprints.org/newfeatures.php>."
MARC Electronic Records for Wright American Fiction, 1851-1875 Now Available for Online Catalogs
October 29, 2002, Indiana University: "Electronic records for 2,308 titles of digitized nineteenth-century American fiction are now freely available to libraries who wish to add these valuable research aids to their online catalogs. Indiana University and the University of Michigan converted existing microformat bibliographic records to describe the electronic reproduction and, with the cooperation of OCLC, are offering the records to libraries worldwide. A subsequent release for the remaining 250 records is planned for December 2002."
"...The records correspond to the works of American fiction currently being digitized in an ongoing cooperative project of Big Ten university libraries, led by Indiana University. Over half of the nearly 3,000 works listed by Lyle Wright in his landmark 1957 bibliography, American Fiction 1851-1875, are now online and fully searchable. Each title-level record will provide libraries with links to these free public-domain full-text online resources. <http://www.letrs.indiana.edu/web/w/wright2>."
"...The nine libraries working to digitize the Wright's listing of American fiction are members of the Committee on Institutional Cooperation (CIC), an academic consortium of the Big Ten universities and the University of Chicago. Indiana University's Digital Library Program is the project host."
"To access the records, go to: <http://www.letrs.indiana.edu/web/w/wright2/marc/index.html>."
For more information, contact Eric Bartheld at <[email protected]>.
Digital Library of Information Science and Technology (DLIST) Launched
(The following announcement was sent to D-Lib Magazine on 23 October by Paul Bracke, DLIS)
"The School of Information Resources and Library Science and the Arizona Health Sciences Library at the University of Arizona have launched DLIST, the Digital Library of Information Science and Technology. DLIST is available at http://dlist.sir.arizona.edu."
"The objective of DLIST is to serve as a repository of electronic resources in the domains of Library and Information Science (LIS) and Information Technology (IT). DLIST is running on Open Archives Initiative (OAI) compliant Eprints v.2 software developed at the University of Southampton. Eprints software, recently heralded as the future of scholarly communication, facilitates the development of institutional and subject archives and self-archiving practices."
"Researchers and practitioners in LIS and IT create a wealth of content not limited to formal papers. To capture this wealth of information and create a library that is as useful as possible, DLIST materials include:
- Published papers
- Data sets
- Instructional and help materials
- Pathfinders
- Reports
- Bibliographies"
"We are actively seeking partners who can contribute to our archive building and collection development efforts. If you have materials of this nature, please consider depositing them with DLIST for use and access to a wider audience."
"We invite authors in the areas of Library and Information Science, and Information Technology to self-register and deposit their papers. Authors can choose to participate by contributing their research papers (either before or after publication)."
For further information contact Paul Bracke <[email protected]>.Nationaal Archief / ECPA launch new preservation gateway
(The following announcement was issued on 22 October by Anne Muller, European Commission on Preservation and Access)
"The Nationaal Archief and the European Commission on Preservation and Access (ECPA) have officially launched GRIP, Gateway for Resources and Information on Preservation. GRIP is an Internet gateway, presenting a core of accessible and recent materials selected by experts which provides an introduction to a great many aspects of preservation. Resources selected for inclusion in GRIP aim to be of interest to a wide audience, including preservation professionals, collection managers, policy makers, librarians, archivists, museum curators, audiovisual specialists and information technologists."
"Currently the GRIP database contains 2248 references to literature, organizations, projects, training activities and discussion lists. It can be searched by category, keywords (descriptors), keyword combinations and free search. Since all references are connected to a thesaurus system, users can browse through GRIP by using related, narrow or broader terms. In many cases the references in GRIP are annotated with short comments by the experts that selected them."
"GRIP also hosts online versions of two publications, namely "Preservation Science Survey. An Overview of Recent Developments in Research on the Conservation of Selected Analog Library and Archival Materials" by Henk J. Porck and René Teygeler and "Preservation of Archives in Tropical Climates. An annotated bibliography" by René Teygeler with the co-operation of Gerrit de Bruin, Bihanne Wassink and Bert van Zanen."
"A team, consisting of experts at the Nationaal Archief, European Commission on Preservation and Access and the ECPA Scientific Advisory Committee, will maintain and regularly update the GRIP database. GRIP also intends to expand the number of on-line publications, providing an open platform for preservation literature."
"Third parties that hold valuable information on preservation are invited to make it available through the gateway. If you have anything to contribute, literature, a database, etc. please let us know. Also, if you have any questions or suggestions, feel free to contact the GRIP editor-in-chief at <[email protected]>."
"GRIP website: <http://www.knaw.nl/ecpa/grip>."
Council on Library and Information Resources and Cornell Launch Web-Based Preservation Tutorial
"October 18, 2002, Washington, D.C.—The Council on Library and Information Resources (CLIR) and Cornell University Library have launched the first in a series of Web-based tutorials on preservation and conservation. Funded by The Henry Luce Foundation, the tutorial is targeted toward libraries and archives in Southeast Asia."
"...The tutorial includes a self-assessment tool that helps users evaluate their level of preservation, an instructional narrative, a resource guide containing information onlocal suppliers of conservation materials and equipment, and a technical glossary with terms in the venacular. The narrative has four major sections.
- Management and Planning
- Preservation
- Building Capacity
- Supporting the Effort"
"The tutorial is found at http://www.librarypreservation.org."
For more information, see the full press release at <http://www.clir.org/pubs/press/2002tutorial_pr.html>.
NYPL's Picture Collection Online Now Available
(The following announcement was issued on 4 October by David Callahan, New York Public Library)
"The New York Public Library has launched the Picture Collection Online (PCO). PCO contains digitized historical public domain images of such subjects as New York City, Costumes, and American History. A total of 30,000 images, all selected from the Reference File of The New York Public Library's Picture Collection, will be available on PCO by late 2003. The site, which is funded in part by a National Leadership Grant from The Institute of Museum and Library Services, is accessible through a link from the Picture Collection homepage or directly at <http://digital.nypl.org/mmpco>."
Copyright 2002 Corporation for National Research Initiatives
Top |
Contents
Search | Author Index
| Title Index | Back Issues
Conference Report | Clips & Pointers
E-mail the Editor
DOI: 10.1045/november2002-inbrief