 |
D-Lib Magazine
May/June 2014
Volume 20, Number 5/6
Table of Contents
The Odysci Academic Search System
Reinaldo A. Bergamaschi, Henrique P. de Oliveira, Akihito Kumon Jr.
Odysci, Inc.
{rberga, henrique, akihito}@odysci.com
Rodrigo C. Rezende
Microsoft Corporation
rorezend@microsoft.com
doi:10.1045/may2014-bergamaschi
Printer-friendly Version
Abstract
Web-based academic search systems have enabled researchers to find and access scientific publications worldwide in a way that was not possible ten years ago. Nevertheless, the quality of such search systems can vary considerably in coverage, ranking quality, entity resolution and indexing time. This paper describes the Odysci Academic Search System including all steps necessary from acquiring a document to making it available for user search. We describe in detail the steps for data import, data de-duplication, data indexing, search process, ranking of results, parallel processing and finally user experience, including many practical aspects commonly overlooked in publications, but important to make the system work well and provide a good user experience.
1. Introduction
Web-based academic search engines have provided researchers the means to find relevant scholarly published information in an unprecedented manner. As with other web-based information, this has democratized information access, allowing scientists from less rich institutions and less developed countries similar levels of access as their richer counterparts.
The last ten years or so have witnessed the appearance of several paper repositories and search engines, such as DBLP [1], Citeseer [2], Google Scholar [3] [4], ArnetMiner [5], MS Academic Search [6] [7], PubMed [8], SpringerLink [9], ScienceDirect [10], among others. Most of the non-commercial academic search systems were developed with specific research goals, and their publications usually tend to focus on specific algorithms and do not cover many of the significant problems involved when putting together a whole system.
This paper describes the Odysci Academic Search System, including its software architecture, information extraction and retrieval algorithms, entity de-duplication, ranking algorithms and user interaction. Currently Odysci covers published papers in the computer science, electrical engineering and math-related areas.
Odysci's primary goals are:
- Provide correct metadata for the papers. This involves making sure that information about papers, authors, citations, etc. is correct, not duplicated, nor wrongly merged.
- Provide cross-linked information. Users should be able to easily access cross-linked information, such as papers within a conference, papers by a given authors, papers citing the same paper, etc.
- Provide relevant rankings as a result of generic searches. This implies identifying the intent of the query, whether the keyword is an author name, or title, etc. and returning the best ranked papers according to a range of criteria.
- Provide automated and unsupervised import mechanisms to allow for fast and extensible coverage.
- Provide a useful and efficient user experience, including specialized search capabilities, ability to receive alerts, embedded conference pages, embedded author publication pages, etc.
2. System Architecture
Odysci uses a client-server architecture as depicted in Figure 1. Its main components are:
- Search Interface: search box allowing unstructured as well as structured searches.
- Web Server: component responsible for all interactions between the user and the back-end Application Server. It uses the Apache server, PHP, Javascript and Ajax for client-side actions.
- Application Server: component responsible for all back-end operations. It uses the Glassfish server, and all programming uses Java. All communication with the Web Server is done using REST calls [11].
- Back-end Technologies: Odysci uses Lucene [12] and Solr [13] for indexing and Mysql and JPA/Hibernate for database and data modeling.
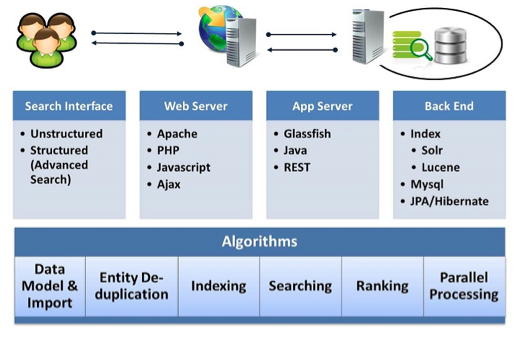
Figure 1: Odysci System Architecture
Figure 1 also shows the main algorithmic areas that we focused on, in order to implement the primary goals outlined in the Introduction. These were:
- Data Model and Import: to allow for automated and unsupervised data entry;
- Entity De-duplication: to prevent the creation of incorrect data (i.e., duplicated authors) which could impact the ranking of papers as well as the user experience;
- Indexing: several of the algorithms rely on specific indexes created in particular ways for the data being represented;
- Searching: algorithms were developed to allow for special types of advanced search, for example, searching for papers written by authors who worked at a given university;
- Ranking: several algorithms were developed for combining query-independent ranking with query-dependent metrics;
- Parallel Processing: a distributed and concurrent queue-based flow was implemented to handle the complete data import, from acquiring the paper to having it indexed and ready for search.
The following sections present details about these algorithms.
3. Data Model and Data Import
The main entities associated with any given paper are: title, authors, authors' affiliations, publication venue (conference or journal), publication date, place of publication (i.e., where the conference took place), doi/url, list of references, publisher. Figure 2 illustrates the main entities and their relationships.
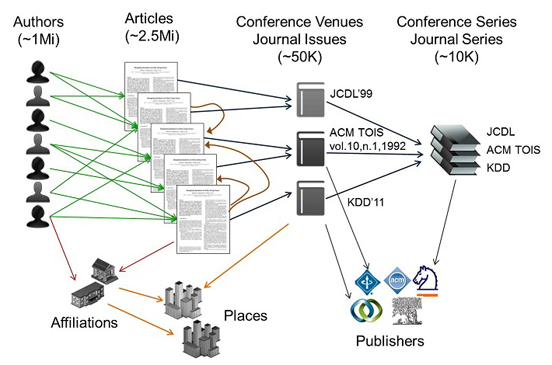
Figure 2: Entities and Their Relationships
These entities are all represented and stored as Object-Oriented Models and stored using a relational database (MySql). Specific algorithms may choose to create separate graph structures representing the entities and their relationships as temporary data-structures for more efficient processing.
All entities are uniquely identified. For example, two different authors are mapped to two distinct entities even if they have exactly the same name. In Section 4 we will present the entity resolution algorithms for differentiating such cases. Once an entity is uniquely identified, it is assigned a global id, a 128-bit number which is valid for the life of the entity. Global Ids have parts randomly generated (i.e.,not sequentially assigned.) to avoid sequential crawling.
The Data Import flow is depicted in Figure 3. The raw data is acquired from several sources, namely: publishers, web pages, conference pages, online repositories, public databases. The data provided by publishers is usually in the form of an XML metadata file with the paper details already segmented, that is, strings representing title, author names, publication venue, list of references, etc., are tagged. Data obtained from conference and journal web pages need to be crawled and parsed. Although we make use of parsing templates, this process always requires a certain degree of manual customization to begin with. Public databases are usually provided as OAI RDF files and also need to be parsed individually, but the individual fields are tagged. For each new source of data, the acquisition process needs to be adapted and possibly new parsers developed, but once done, it does not require constant tuning.
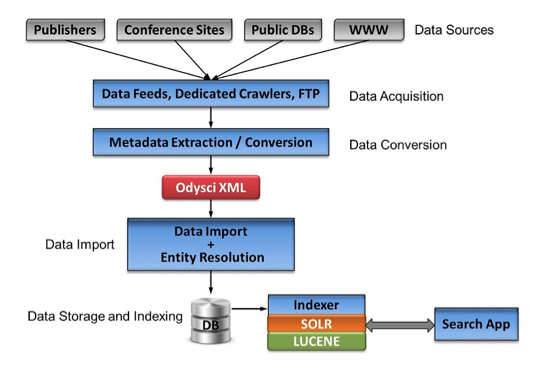
Figure 3: Data Import Flow
This acquisition process collects as much data about a paper as possible. This may include: paper metadata (tagged fields), full text (usually PDF which is converted to text), other untagged metadata (for example, a string which contains title, authors, conference name, date, but without field segmentation). The list of references is either given or extracted from the full text (using ParsCit [14]). If references are given, the citations in the text may be identified and the phrases around them extracted as the context of the references.
In all cases, the data is extracted, i.e., title, authors, affiliations, conference/journal name, date, references, and written to an XML file following our own predefined Odysci schema. The data in this file has been segmented but not de-duplicated. Everything is still represented as strings.
The Data Import process takes an Odysci XML file, breaks it up into individual entities and proceeds to resolve them. At this point, the algorithms have to determine if each entity is a new one or already present in the repository. If the entity is new, it is persisted in the database; if it exists, it may have to be updated. Take for example the import of a brand new paper. The document entity will be new, however the other associated entities may not. The authors may exist in the database, but the affiliation of an author may be new, and so on. The Import process analyses every single entity being inserted and determines if it needs to be persisted as new, updated, or discarded (if fully present). Section 4 details the algorithms involved in this process.
After the data has been fully imported and persisted to the database, then the ranking algorithms are run to generate the query-independent metrics used for ranking (see Section 5), which are also persisted in the database. After that, the indexing process is executed using SOLR and LUCENE. Several indexes are created for different purposes, using dedicated fields and specialized data processing functions for each type of entity.
4. Entity Resolution
Entity resolution is one of the most important steps in data import. It is responsible for the quality of the data, as it makes sure there are: no paper duplicates, no duplicated authors (same person, two distinct entities), no merged authors (two distinct persons, same entity), no duplicated conference venues (two JCDL-2001's as separate entities), no duplicated or wrongly accounted for citations. These types of errors directly affect the value of ranking metrics. For example, if an author is assigned papers belonging to another person (with very similar name), his/her H-Index [15] will change; if a paper is assigned to the wrong conference venue, the conference Impact Factor [16] will change, etc.
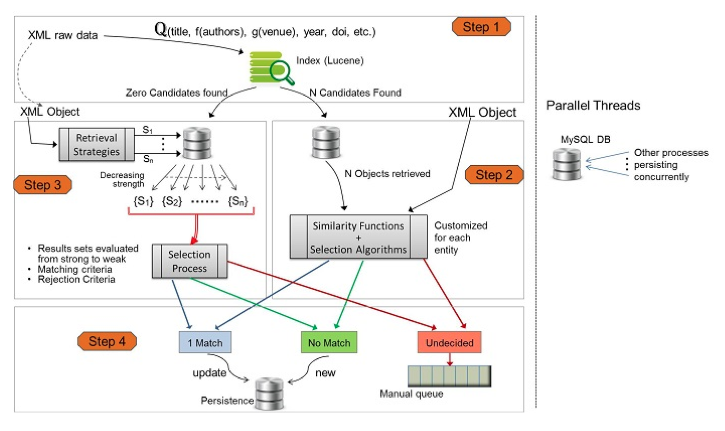
Figure 4: Entity Resolution Process
The main reasons for possible erroneous duplications or mergers of entities are the lack of standardization in how the entities are written in the papers and in references. For example, the conference name "Design Automation Conference" also appears as "Annual Conference on Design Automation", as well as its acronym "IEEE/ACM DAC", but it should not match "European Conference on Design Automation", nor "Design Automation Conference in Europe", nor "EDAC" (which are different events).
Moreover, the PDF or PS data (i.e., papers) is converted to text and these conversions are not infallible. For example, an asterisk ('*') after a name to denote an affiliation is often converted to an actual letter added to the end of the name, and it may just become someone else's last name.
Several works have been published on entity resolution. The LOAD [17] system uses a two step approach, dividing the problem into a high-precision similarity learning follow by a high-precision recall step. LOAD uses information such as email, affiliation, coauthoring and homepage to establish similarity through specialized functions. Our approach also uses all the additional information available, but we generalized the approach by using Lucene indexes and searches to measure similarity.
Although these entity resolution algorithms are heuristics and cannot guarantee absolute correctness, this is an area where Odysci has spent considerable resources, so that the user experience is satisfying (i.e., no author likes to see his/her paper assigned to someone else just because their names are similar), and the ranking metrics are as accurate as possible.
The main computation requirements for the data import process were: (1) reasonably fast, circa 200ms per paper per server; and (2) fully parallelizable at the task level, i.e., multiple imports could run in parallel threads. This parallelism requirement impacts data persistence and correctness. For example, suppose the papers from a new conference are being imported by multiple threads; clearly the new conference entity should be uniquely created and not duplicated by multiple threads. Thus, dynamic modifications to the data repository must be immediately available to the other processes.
The overall entity resolution process uses index-based algorithms to retrieve possible matches and then applies specialized heuristics to gradually refine the list to a single final match or no match (indicative of a new entity). The following subsections present details.
4.1 Index-Based Entity Matcher
A Lucene index is created for entity resolution, with the following characteristics (note: this is the index used for entity resolution/data import only, not for search):
- Index fields are created for each entity, namely title, abstract, author, conference/journal, place, year.
- Additional fields are created for neighboring information, such as lists of co-authors and previous affiliations.
- Each field is indexed according to a strategy which depends on the type of data contained in the field. For example:
- Author names: tokenized using n-grams to allow for abbreviations and misspellings, plus shingling and word reordering.
- Conference names: dedicated set of stop-words, word tokens, plus shingling and word reordering
- Transformations applied to certain fields: synonyms, abbreviations, ordinal/numeral (i.e., to match "1st" with "First").
- Index field structures optimized for efficiency according the type of data stored (e.g., pure text, dates, integers).
- This index is created off-line and updated regularly (typically after a few thousand papers are imported). The updating of this index does not affect the quality of entity resolution because the algorithms also check the databases (see Section 4.3). But it does make the import process more efficient.
The overall entity resolution process relies heavily on indexed information and index queries to retrieve an initial short list of possible candidates quickly. Then more elaborate algorithms are applied to this short list to reach a final decision on whether a given entity is already present or should be considered a new one. Figure 4 above illustrates the steps involved in the entity import and resolution process.
Given an Odysci XML file as input, the fields are identified by tags (e.g., title, author-1, author-2, conference name, etc.) and the corresponding strings are used for building a query which "asks" the index: "Return all papers contained in the index with title T, written by authors A1, A2 and A3, with affiliations F1, F2 and F2, in conference C, in year Y". More formally, this is expressed as the following query (Figure 4, step 1):
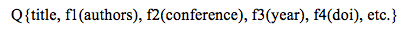
The score returned for this query is a function of the score of each individual field specified in the query. Since most textual fields can be written in different ways (e.g., abbreviated names), the score for each field is a function of the plain score returned by Lucene. This function is customized to be more or less fuzzy, depending on the type of field. For example: a) for Titles a certain small amount of mismatch is allowed; b) for Author names, some mismatch is allowed to compensate for misspellings and multiple forms of writing (abbreviations, last/first name ordering, etc.); c) for Year and DOI exact match is required if present. In addition, for each field, further fuzziness may be allowed for two papers to be considered a possible match. For example, if both authors of a 2-author paper match against 2 out of 3 authors of a 3-author paper, both papers may be considered a match as far as the authors are concerned (even though the numbers of authors do not match). This query is computationally very fast as it uses a single query to the Lucene index.
The overall score of a document is a linear function of the individual field scores (after the application of their own scaling functions) as shown below:
The coefficients ki and the functions ƒi were tuned using a manually created ground truth made of different versions of papers, different ways of writing similar names, etc. If the overall score of a document is greater than a threshold (also empirically determined), this indexed document is considered a possible match. The query Q returns a set of N candidates of (already) indexed documents which may be a possible match for the incoming document. If N > 0 then the process continues with step 2 in Figure 4. If N = 0 then the Real-Time Matcher in invoked as described in Section 4.3.
4.2 Similarity Functions and Selection Algorithms
After N initial candidates are obtained from the index, Step 2 consists in retrieving the corresponding N objects from the database (with all structured data). For efficiency reasons, the Lucene index is not updated every time a new entity is found, but instead a database is used at this stage as the central repository for data consistency. If another parallel thread updates an entity in the DB while this thread is in step 1, then when the entity is retrieved from the DB in step 2, its updated version is obtained.
Step 2 is responsible for selecting the single best match out of N initial candidates. The XML input data is converted to an object representing the paper, which is then compared to the N objects retrieved from the index and database. A number of similarity algorithms are applied in order to select the best match. Given the limited number of candidates, complex algorithms can be used without compromising execution time.
The similarity functions are specific for each type of entity, e.g., title, authors, conference/journal, etc. Each uses its own dictionary, its own segmentation, its own token transposition rules, its own string comparison function and edit distance, its own text-based scoring and its own overall scoring.
As a result of applying the similarity functions, each of the N candidates is given a score, which must be above a certain threshold for it to continue being considered a match. Now, the selection algorithm applies a number of "conditions" such as: a) check for mismatching DOI numbers (on papers), b) mismatching ISBN/ISSN numbers on conference proceedings and journals, c) distinct publication years, and a few others. Some of these conditions, if failed, will rule the comparison as "undecided".
At the end of the selection algorithm, there may be a single matching entity, no matching entity, or "undecided" match. At this point the process goes to Step 4 in order to decide which data should be persisted.
4.3 Real-Time Matcher
If the initial query in Step 1 returns zero matches, it may not necessarily mean that the entity is brand new. Multiple threads may insert new entities in the DB asynchronously with index updates.
Consider, for example, that the system is processing the papers for a brand new conference (one not yet indexed, nor in the DB). Let's say that paper P1 from conference C is being processed by thread T1 concurrently with thread T2 which is processing paper P2 from the same new conference C. Assuming thread T1 is slightly ahead, it will execute step 1, find no matches and insert paper P1 and conference C in the DB as new entities. Thread T2 will execute step 1, and since the index was not updated immediately, it will find no matches either. But thread T2 should clearly not insert conference C as a new entity again.
To be able to handle this situation, we implemented a real-time matcher, as indicated in Step 3, Figure 4. This matcher takes into account the information present in the database (which is the thread-safe persistent repository of all data processed by the parallel threads performing entity resolution).
The comparison between the input XML object and the structured entities present in the DB relies on a set of Retrieval Strategies followed by a Selection Process. A retrieval strategy uses a single field of the entity to access the DB and retrieve similar objects. Using multiple retrieval strategies (i.e., multiple fields), we can retrieve multiple sets of matching candidates. The intersection of these sets are the most likely matches.
If the intersection of the retrieved sets results in 1 or more candidates, then we apply a selection process which filters the candidates based on the "strength" of the matched field, and may reject candidates if strong fields do not match (i.e., DOI).
At the end of this step, there may be zero or one matching entity, or if more than one, it is considered an "undecided" match. At this point the process goes to Step 4 in order to decide which data should be persisted.
4.4 Data Persistence
At the end of the selection algorithms, 3 outcomes are possible:
- There is a single match to a paper already in the database. In this case, the data from the incoming XML is merged into the existing data. For example, an author may have his/her name written in a different way (e.g., including a middle name) in the incoming XML — this new variation is added to the list of alternate names in the author's entity and stored in the database.
- There is no match against any paper already in the database. In this case, the paper will be considered new and inserted in the database. Note that the other attributes of this new paper, such as authors or conference/journal name, may already be present in the database and will be updated if necessary.
- There are 2 or more strong matches against papers in the DB, or the selection algorithm found "suspicious" conditions in them (such as mismatching DOIs). This is an indication of a potential problem in the XML data coming in, or in the data already in the DB. In such cases, the entities are listed in a separate repository for manual inspection ("manual queue" in Figure 4).
5. Search and Rank
The final rank of a document is a combination of its query-dependent metrics (i.e., how important are the search keywords inside this document) and its query-independent metrics (such as: number and quality of its citations, quality of its authors, quality of its publication venue). This section describes the algorithms developed for these purposes.
5.1 Query-Dependent Ranking
Clearly all documents returned to the user after a search must contain one or more of the search terms specified by the user. However, this alone is not sufficient to guarantee a good user experience. The user query must be interpreted to determine what the real intent and scope of the keywords are. For example, if we "know" that the user is searching for keywords in a title, we can look only in the title field of the index. In most cases we do not (unless advanced search tags are used) and the algorithms have to infer the scope of the keyword in order to produce good results.
For the purposes of search, a SOLR Index is built, using several attributes of a paper as separate fields, such as 'title', 'author', 'conference/journal series', 'affiliation', 'place', 'publisher', and 'citations'. When a keyword is looked up in this index, each field produces a score for how relevant the keyword is within the contents of that field in all documents (we will refer to this as the corpus field, e.g., title corpus, author corpus, etc.). This score may take into account single term matches and phrasal matches, depending on the type of field.
However, the scores from different fields and/or different searches are unrelated, thus it is not possible, just by looking at the plain scores, to say that the keyword matched the 'title' field better than the 'author' field, for example.
In order to be able to combine the scores from different fields, we developed an algorithm that converts the scores from different fields into normalized scores that can then be combined linearly to generate a final query-dependent score for the documents.
The normalization algorithm relies on mapping out a wide range of scores that queries to a given field may produce. This is done by submitting thousands of different queries, based on a "Search Training Set', and collecting the individual scores produced by each field for the returned papers. Then, using the scores and the numbers of papers returned, we generate the cumulative distribution function (CDF) of scores for each field, as illustrated in Figure 5. The Training Set queries were partly collected from actual user queries and partly synthetically generated.
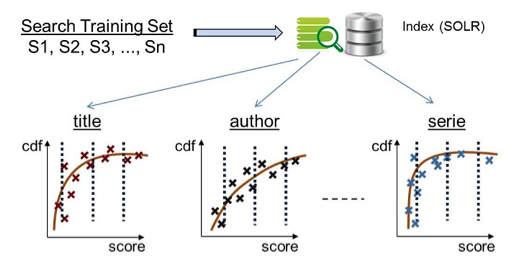
Figure 5: CDF x Score Curves for QD Rank
The CDF x Score curves are smoothed and discretized in bins per range of scores. This is done off-line (not during user search) and the CDF x Score curves are stored.
These curves are used to infer the scope of the keyword, that is, to estimate the likelihood that the keyword was meant to be part of the title, part of the author's name, part of the conference name, etc. This is done as follows. Suppose the user searches for keyword K, and the title field returns a document D with a score of 0.00543. By looking up the CDF curve, we obtain a value of 0.99. This means that when searching for K in the title field, the title of document D is more relevant than 99% of the titles of other documents The same keyword K when searched in the author field returned a score of 0.078 for document D, but the corresponding CDF value is only 0.57. This implies that when searching for K in the author field, the authors of document D are more relevant than 57% of the authors' names in other documents. The higher CDF for K in the title field indicates a higher probability that the query term K is meant to represent part of a title, as far as document D is concerned.
The final Query-Dependent Rank (QD-rank) for a given query for a given paper is computed using a linear function of the CDFs of the individual fields for each paper returned by the query. Based on a user query (e.g., keywords) and the CDF curves for each field, the algorithm produces a list of fields ordered from highest CDF to lowest for each returned paper. These scores are combined using a set of dynamic weights — higher weights are applied to those fields that better match the user query (based on CDFs), as formalized in the equation below.
The weight functions WTitle, WAuthor, etc. are dynamic; they vary according to the relative value of the CDF scores with respect to the other fields (i.e., the position of the field in the ordered CDF list) for each paper.
For a given query, the equation above is computed for each paper, as its query-dependent score.
5.2 Query-Independent Ranking
Odysci uses a combination of citation-based analysis methods to compute a query-independent rank value for a paper. Citation-based methods have been developed for many years, starting from the groundbreaking work of Garfield [18]. Different citation-based metrics have been developed for authors (H-Index [15]), publications (Impact-Factor [16]) and papers (link-based algorithms such as Page-rank [19] and Hits [20] can also be applied to citations from/to papers).
The Query-Independent rank (QI-rank) computed by Odysci builds a multi-dimensional Euclidean vector using as dimensions the values for: a) an Odysci proprietary algorithm applied to paper citations that takes into account the number, age and connectivity of the citations, b) H-Index for authors (with and without self-citation), and c) Impact-Factor for conferences and journals (2 and 5-year). The final QI-rank is given by the magnitude of the Euclidean vector, as illustrated in the equation below:
Where:
- QI-rankp is the query-independent rank for paper p;
- fO is the function computing the Odysci link-based metric for the links to/from paper p (Lp);
- fA is the Euclidean sum of the Authors H-Indexes of all authors in paper p;
- fS is the Euclidean sum of the 2-year and 5-year Impact-Factors for the Serie (publication) containing paper p.
- KO, KA, KS are constant coefficients used for biasing the weight of each term.
The values computed by each of the functions (fO, fA, fS) are CDF values (between 0 and 1) with respect to the distribution of the scores for all papers. The coefficients K are used to bias the relative importance of each term. Typically, the coefficient KO for the Odysci link-based metric is higher than the H-index metric and higher than the Impact-Factor metric. The actual coefficient values were derived based on experimentation on a ground truth set of papers and manual ranking.
5.3 Final Ranking for a User Search
When a user submits a search, the following steps happen:
- Recall Step:
Using the search terms as filters, the index is asked to return all documents containing the search terms in any field
- Apply the QD-rank:
Using the algorithms in Section 5.1, order the documents according to their QD-rank values. This is illustrated in Figure 6 (a).
- The ordered documents are partitioned in buckets corresponding to ranges of QD-rank values.
- Apply the QI-rank to reorder the documents locally:
Based on the QI-rank values of each document in each bucket, allow local reordering (position swaps), moving documents with higher QI-rank to the top of the list, but avoiding large changes of order (to prevent a document with much lower QD-rank from moving ahead of another one with significantly higher textual content). Figure 6 (b) demonstrates this step.
- The top papers from the final ordered list are returned to the user (1st page results).
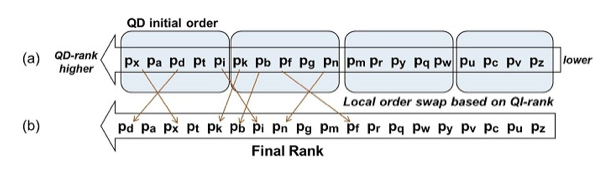
Figure 6: Final Rankings Combining QD-rank and QI-rank
6. Concurrent Processing
Data import is the most demanding process in the Odysci system. It involves data acquisition, data processing, entity resolution, database operations and index operations. All operations except for the database insertions can be parallelized.
We implemented a distributed producer-consumer processing framework using task queues to transfer data between workers. Workers are processes that operate on the data. Scalability is achieved by deploying multiple workers on distributed machines. Figure 7 shows the workers and queues associated with the data import process.
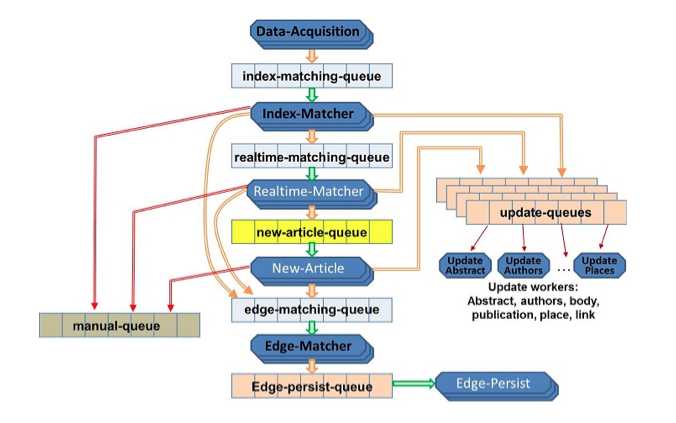
Figure 7: Data Import Concurrency Framework
7. Advanced Search
By indexing in different fields the various entities associated with a paper, it is possible to implement different types of advanced search. In particular we implemented a search by affiliation and place (using the notation @affiliation or @place), which is not normally found in search engines. Some examples of this feature are:
- The search for 'venue:kdd venue@Seattle' returns papers published at the KDD conference but only when it was held in Seattle.
- The search for 'author:Lamport author@SRI' returns papers written by Leslie Lamport while working at SRI.
- The search for 'author@google "ranking algorithms"' returns papers about ranking algorithms authored or co-authored by Google authors.
In order for this to work consistently, we implemented special clustering algorithms for affiliations and places that can combine locations even when written in different ways. For example, the affiliations "IBM Research" and "IBM T.J. Watson Research Center" should be treated as the same location. Special indexes were created for location-based information.
8. Conclusions
This paper presented a comprehensive overview of the Odysci Academic Search System, including its main algorithms as well as practical aspects needed for such a system to work well, with a minimal amount of human supervision and maintenance.
We developed novel algorithms for entity resolution and for ranking. The entity resolution algorithms use a combination of search indexes and specialized similarity functions. The ranking algorithms use query-dependent as well as query-independent methods which are capable of interpreting the scope of the query terms and take into account multiple factors when ranking a paper.
Finally, we present our concurrent framework for running the data import process using multiple concurrent threads. This framework is able to import, de-duplicate and persist 200K papers in the database (and all their entities) in 16 hours on an i7-based workstation with 32GB of RAM.
The system was opened for free public use in 2011 and it has since gathered users in over 50 countries. The overall system contains around 2.5 million documents (papers), 1 million authors, 50 thousand conference venues and journal issues, and 10 thousand conference and and journal series, all in the computer science, electronics, bioinformatics and math-related areas. Expansions to other domain areas are being considered.
9. References
[1] Michael Ley. 2009. DBLP — Some Lessons Learned. In Proceedings of VLDB, vol.2, no.2, 1493-1500.
[2] Steve Lawrence, C. Lee Giles, and Kurt D. Bollacker. 1999. Digital Libraries and Autonomous Citation Indexing. IEEE Computer, 32, 6, 67-71. http://doi.org/10.1109/2.769447
[3] Péter Jacsó. 2008. Google Scholar revisited. Online Information Review, 32, 1, 102-114. http://doi.org/10.1108/14684520810866010
[4] Jöran Beel, and Bela Gipp. 2009. Google Scholar's Ranking Algorithm: The Impact of Articles' Age (An Empirical Study). In Proceedings of the Sixth International Conference on Information Technology: New Generations (ITNG 2009), 160-164. http://doi.org/10.1109/ITNG.2009.317
[5] Jie Tang, Duo Zhang, and Limin Yao. 2007. Social Network Extraction of Academic Researchers. In Proceedings of the 7th IEEE International Conference on Data Mining (ICDM 2007), 292-301. http://doi.org/10.1109/ICDM.2007.30
[6] Zaiqing Nie, Fei Wu, Ji-Rong Wen, and Wei-Ying Ma. 2006. Extracting Objects from the Web. In Proceedings of the 22nd International Conference on Data Engineering (ICDE 2006), 123-123. http://doi.org/10.1109/ICDE.2006.69
[7] Zaiqing Nie, Ji-Rong Wen, and Wei-Ying Ma. 2007. Object-level Vertical Search. In Proceedings of the Third Biennial Conference on Innovative Data Systems Research (CIDR 2007), 235-246.
[8] PubMed: http://www.ncbi.nlm.nih.gov/pubmed/
[9] SpringerLink: http://link.springer.com/
[10] ScienceDirect: http://www.sciencedirect.com/
[11] Leonard Richarson and Sam Ruby, 2007. RESTful Web Services. ISBN: 978-0-596-52926-0. O'Reilly Media.
[12] Michael McCndless, Erik Hatcher and Otis Gospodnetic. 2010. Lucene in Action, 2nd Edition. ISBN: 978-1933988177. Manning Publications.
[13] David Smiley and Eric Pugh. 2011. Apache Solr 3 Enterprise Search Servers. ISBN: 1849516065. Packt Publishing.
[14] Isaac G. Councill, C. Lee Giles, and Min-Yen Kan. 2008. ParsCit: an Open-source CRF Reference String Parsing Package. In Proceedings of the International Conference on Language Resources and Evaluation (LREC 2008).
[15] J. E. Hirsch. 2005. An index to quantify an individual's scientific research output. PNAS, 102, 46,16569-16572. http://doi.org/10.1073/pnas.0507655102
[16] Thomson Reuters. The Thomson Reuters Impact Factor.
[17] Y. Qian, Y Hu, J. Cui, Q. Zheng, and Z. Nie. 2011. Combining Machine Learning and Human Judgment in Author Disambiguation. In Proceedings of the 2011 International Conference on Information and Knowledge Management (CIKM 2011).
[18] Eugene Garfield. 1983. Citation Indexing: Its Theory and Applications in Science, Technology, and Humanitites. ISBN: 978-0894950247. ISI Press.
[19] L. Page, S. Brin, R. Motwani, and T. Winograd. 1999. The PageRank Citation Ranking: Bringing Order to the Web. Technical Report 1999-0120. Stanford InfoLab.
[20] J. M. Kleinberg. 1999. Authoritative Sources in a Hyperlinked Environment, Journal of the ACM, 46, 5 (September 1999), 604-632. http://doi.org/10.1145/324133.324140
About the Authors
 |
Reinaldo A. Bergamaschi received his PhD in EECS from the University of Southampton, UK in 1989, a Masters degree from the Philips International Institute, Eindhoven, The Netherlands, and a Bachelors degree in Electronics from ITA, Brazil. He worked for 19 years at the IBM T. J. Watson Research Center, Yorktown Heights, NY, in the areas of CAD, power modeling and SoC design. He was a visiting professor at UNICAMP, Brazil in 2008/2009. He is now Founder and CEO of Odysci, Inc., developing knowledge management systems. He is a Fellow of the IEEE, and an ACM Distinguished Scientist.
|
 |
Henrique P. de Oliveira received his Masters degree in Computer Science from the University of Campinas, Brazil in 2009, and a Bachelors degree in Computer Engineering from the same university in 2007. While at the university, he also worked in the organization of the Brazilian Informatics Olympiad, formulating and applying exams and teaching programming to high-school students. Since 2010 he has been a software engineer at Odysci, Inc., developing search and data mining algorithms.
|
 |
Akihito Kumon Jr. received his Bachelors in Information Systems from the Pontifical Catholic University, Campinas, Brazil. He is now a software Engineer at Odysci, Inc., developing web systems in the areas of knowledge management.
|
 |
Rodrigo C. Rezende received his Masters and Bachelors in Computer Science from the University of Campinas, Brazil. He worked as a researcher for the Brazilian Federal Revenue and as a software engineer for Odysci, Inc. mainly in the information retrieval and data mining areas. He is now Software Engineer at Microsoft Corporation, Redmond, US, working with telemetry.
|
|