D-Lib Magazine
March 1998ISSN 1082-9873
The Internet Knowledge Manager, Dynamic Digital Libraries, and Agents You Can Understand
Adrian Walker
IBM Research Division
Hawthorne, New York

Abstract
People represent knowledge as symbols, words, concepts, pictures, and so on. A change in the way human knowledge is represented in software can trigger a major change in business practices. For example, the invention of Hypertext Markup Language (HTML) has triggered the development of the Web, and of successful Web-based businesses.
Knowledge Management is currently viewed as important to the success of large enterprises and of linked economies. A Digital Library for business, in which authors have rights and royalties, can be viewed as a means of doing Knowledge Management in a linked economy. Authors are persuaded, partly by royalties, to share their knowledge and make it explicit as text, audio, and video "documents". Software is used to: find, mix and match, and deliver parts of the documents; to ensure that rights are respected; and to calculate royalties.
The Internet Knowledge Manager is an environment that provides an understandable way of representing knowledge as readable agents that can also be run as software. It uses some new technology to add a new way of using the World Wide Web. With the IKM, you can use a standard Web browser to write and run your own agents, and you can do this in English, without programming. Since agents are written in English, they can be placed in a Digital Library, and selectively retrieved using ordinary text search techniques. Thus, the IKM adds a new way in which human knowledge can be represented in software, and it could trigger new ways of doing business on the Web.
I show a simple example of writing and running an IKM agent for transfer pricing, and I describe how the new technology works.
1. Introduction
People represent knowledge as symbols, words, concepts, pictures, and so on. Written human languages have evolved from pictures, to ideograms, to languages that we can write on paper to communicate abstract concepts to one another. As we move from paper to information systems, developments in the way our knowledge is represented in software are becoming important to success in business. Indeed, a change in the way human knowledge is represented in software can trigger a major change in business practices. For example, the invention of Hypertext Markup Language (HTML), together with its development at CERN, has triggered the development of the Web. The result is a new family of Web-based businesses.
However, it can be argued that we have only just begun to represent business knowledge on the Web. In this view, people, rather than the Web or other software systems, have much of the knowledge that makes organizations efficient and profitable. In fact, Knowledge Management [DavPru97], [Hua97], has recently come to be viewed as important to the success of large enterprises. Such enterprises may represent more or less single entities, like governments or multinational corporations, or they may be sets of relationships based on linked economies, such as countries that trade with one another, or supplier networks among manufacturers.
Many efforts in Knowledge Management aim to take implicit knowledge held by a few people, to make it explicit in suitable contexts, and to make it a basis for informed actions by the whole enterprise. Several things are needed to bring isolated pockets of valuable knowledge into a useful common context. First, the people who have the knowledge must be persuaded that it is in their interest to share it, and to help to make it explicit. Second, we need an understandable way of representing the knowledge. Third, we will often need software that uses the knowledge.
A Digital Library (DL) for business can be viewed as a means of doing Knowledge Management in a linked economy. Consider a scenario like this. A business consultant has knowledge about cost-saving ways of complying with international tax rules on transfer pricing. She is persuaded to become an author, to make her knowledge explicit, and to place it in the DL. It is in her interest to do this, because the DL software protects her rights, and pays royalties. So, from her point of view, the DL is a safe and efficient way of delivering her knowledge to customers. She sees her investment in knowledge repaid in more fees than she would get by traditional methods alone.
To make this scenario work, the DL must provide an understandable way of representing the consultant's knowledge, of protecting her intellectual property rights, and of compensating her for the use of her knowledge. Some of the knowledge is represented as text, audio, and video "documents". The DL organizes the knowledge partly by information about the documents -- often called metadata -- that is represented in tables in a database. The metadata not only helps to organize the knowledge, but also helps to record and administer the rights and royalties. The DL software is a set of functions and services that allows customers to use the collection to find, mix and match, and receive documents. The software also ensures that the authors' rights are respected, and it tallies royalties and fees. Since the library is digital, it is for the metadata to record not only whole documents, but also parts of documents. The parts can then be assembled in many ways into new, customized documents. In this scenario, the IKM can be made part of the DL software to help to keep track of the rights and royalties.
In the scenario, there is a sense in which the knowledge that the consultant has placed in the DL acts on her behalf. But so far, the knowledge just consists of documents that a customer can combine and customize. In a face to face engagement with a customer, the consultant would, in addition, bring her know-how and experience of other consulting cases to bear. She would reason about similarities and differences with other cases, and she would do "what if" calculations. So, if the DL is to act more fully on her behalf, it also needs an understandable way of representing and using her know-how. In a sense, it needs to become her "agent". How can such an agent be written down in an understandable way ? How can it be kept up to date with knowledge that may change from week to week?
Suppose you are the consultant in this scenario. For present purposes, an "agent" is a piece of software that acts for you. The Internet Knowledge Manager is an environment that uses some new technology to add a new way of using the World Wide Web in scenarios like this one. Currently, most people use Netscape or the Internet Explorer to find and receive documents, or to run existing programs. With the IKM, you can also use a standard Web browser to write and run your own "agents", and you can do this in English, without programming. The IKM provides an understandable way of representing knowledge, as readable software agents. Thus, the IKM adds a new way in which human knowledge can be represented in software and in a Digital Library, and it could trigger new ways of doing business on the Web.
Next, I show a simple example of writing and running an agent for transfer pricing. Then, in Section 3, I'll describe how the underlying IKM technology works. Finally, in Section 4, I'll discuss status and conclusions.
2. A Simple Example of Writing and Running a Transfer Pricing Agent
A multinational enterprise will normally transfer goods, and intangibles such as trademarks, between its units in different countries. For the purposes of taxes in the different countries, the enterprise must assign transfer prices. For example, if the BCD corporation in the USA buys a part from its subsidiary BCD-UK plc, it must assign a price to the transaction for tax purposes in the USA and the UK. If the assigned price is low, then more of the BCD corporation's taxable profit will appear on the USA books, where taxes may be lower. One way of estimating a fair transfer price is to find a price paid for a similar "arm's length" transfer, that is, for a comparable uncontrolled transaction, between two separate enterprises. In this example, suppose the BCD corporation also buys the part from the WXY corporation for $100, and that it does not control the WXY corporation. Then $100 could be a fair transfer price for international tax purposes. However, it is often not possible to find an arm's length transfer that the enterprise and the tax authorities in the different countries agree is similar to the controlled transaction. So the US government, the Organization for Economic Cooperation and Development, and others, have proposed several different methods of finding transfer prices. There is a large and growing body of business and government literature about these methods.
When there are several transfer pricing methods that are justifiable to the tax authorities, it is clearly in the interest of the enterprise to pick a method that maximizes profit. On the other hand, each tax jurisdiction will naturally try to ensure that transfer prices are not manipulated so that an unfair portion of profit is reported to another jurisdiction in which the taxes may be lower. Some countries may extract serious penalty payments, for example, by adjusting the reported transfer prices, from enterprises that do not adequately document and justify the reasons for the prices in their reports. Moreover, when several methods of estimating a transfer price can reasonably be used, the "best method rule" allows the selection of the most reliable method.
Let's suppose we have a Digital Library of actual transfer pricing cases and of tax regulations. We said that, since the library is digital, it is reasonable to catalog not only whole documents, but also parts of documents. The parts can then be assembled in many ways into new, customized documents. The metadata for the items in the library has information about these documents, such as
- what transfer price methods a part of a document is about
- the authors and subjects of the parts of each scenario
- which industries, products, and countries are mentioned
- the transfer pricing rules and practices for each country
We could use the IKM environment to write and run an agent that uses the metadata to suggest ways of matching a new transfer pricing scenario to cases in the library. The agent could help to document and justify the reasons for the match. Such an agent could also find payments due to the authors of the parts of the documents that are used, as in "The Internet Knowledge Manager, and its Use for Rights and Billing in Digital Libraries" [Wal98]. To do this, the IKM could work with Cryptolopes [Cryp97], and other means of safeguarding digital library contents [GlLo97].
This approach would not only exploit the fact that a DL can be used to retrieve and mix and match parts of documents. After all, a knowledgeable person could do that, with some effort, using ordinary Boolean and text search techniques, although keeping track of the rights and billing could be quite demanding. The possible value add of the approach is that much of a transfer pricing consultant's know-how is written as an agent. It is then easier for many less knowledgeable people to use the agent and the DL to find appropriate transfer prices, and to use the readable knowledge in the agent to show the tax authorities that the prices have been set by a "most reliable method". The consultant can focus on what she does best, namely keeping the knowledge in the agent up to date. She can also add data and knowledge about how her rights should be protected, and how she wants her customers to be billed.
To make this more concrete, here is an example of how to use the IKM environment to write and run a simple transfer pricing agent. The agent is based on this paragraph, that I have adapted from An Introduction to International Taxation from a U.S. Perspective [Tax98].
BCD-UK plc manufactures a product and sells that product to its parent corporation, BCD. BCD-UK plc also sells the product to WXY Corp, that it does not control, at a price of $100 per unit. Except for the volume of each transaction, the sales to BCD and to WXY Corp take place under substantially the same economic conditions and contractual terms. In uncontrolled transactions, BCD-UK plc offers a 2% discount for quantities of 20 per order, and a 5% discount for quantities of 100 per order. If BCD purchases the product in quantities of 60 per order, in the absence of other reliable information, it may reasonably be concluded that the arm's length price to BCD would be $100, less a discount of 3.5%.
To start using the IKM I first use Netscape, on a machine that can in principle be anywhere on the Internet, to connect to the IKM server in the IBM T.J. Watson Research Center. The IKM server gives me a page like this
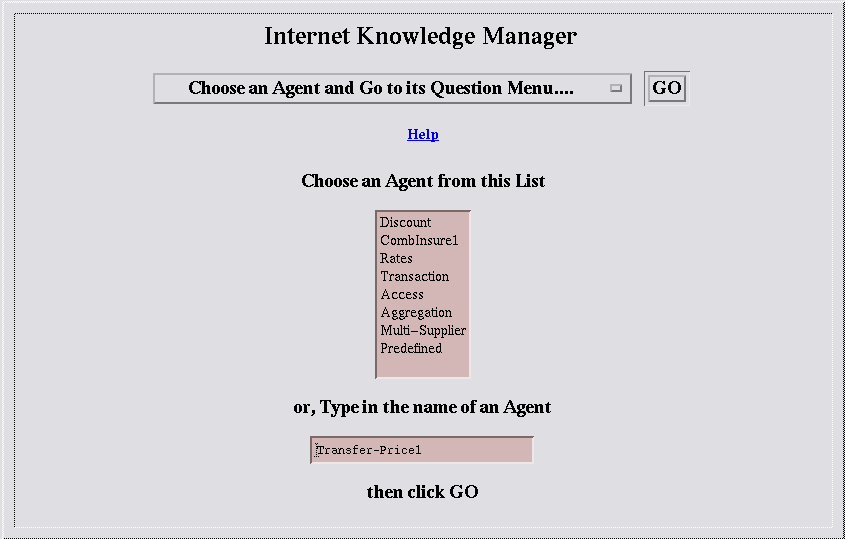
Figure 1: Logging in to the IKMthat I use to log in. I type in my User ID and password, then click the GO button. The result is a start page showing the agents that I have already. These agents are not about transfer pricing. So, I decide to write a new one.
Figure 2: The IKM Start PageSince I'm writing a new agent, I have filled in the bottom slot in the page with its name, Transfer-Price1. Pressing the GO button gets me a page like this:
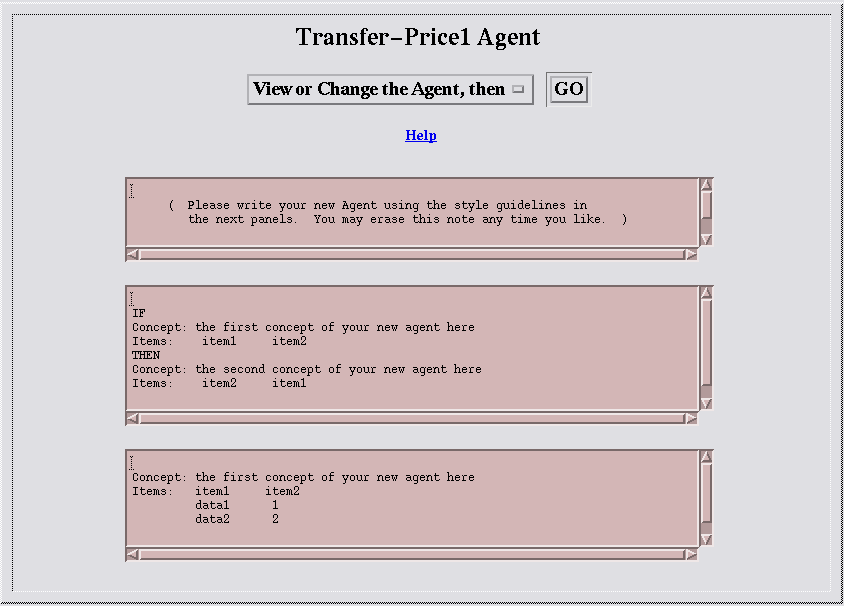
Figure 3: Starting to Write a New AgentThe page suggests that I write my agent as IF-THEN rules, and as tables, using a Concept-Items style. A table has a Concept line that describes what it is about, followed by an Items line that has the headings for the columns of the table. Then, the table has some rows of data.
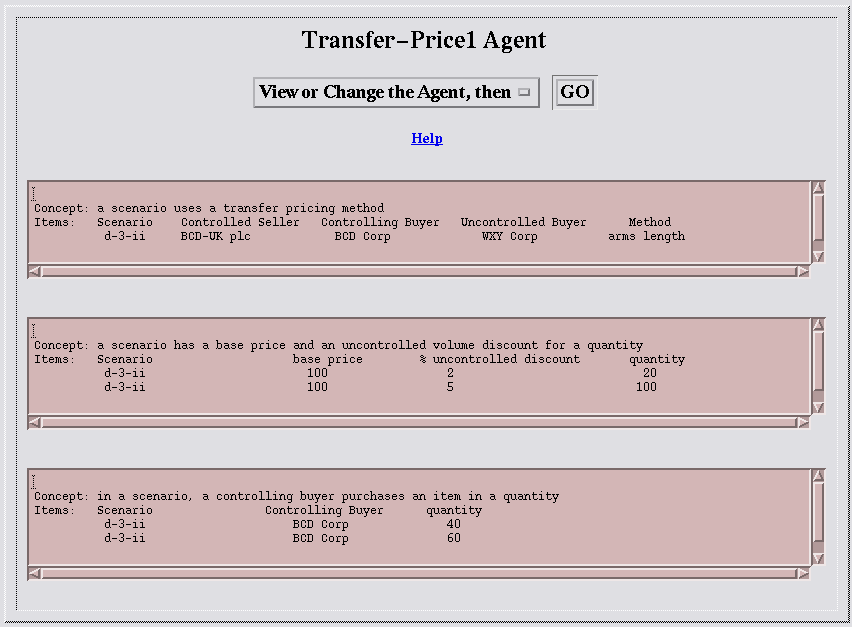
I'll start by writing some tables for the Transfer-Price1 agent. The players in the example are BCD-UK plc, the BCD Corporation, and the WXY Corporation. I'll find the transfer price by the "arm's length" method. So the first table below has just one row of data mentioning the players in the scenario and the pricing method.
Figure 4: Writing Three TablesThe pricing method depends on the base price of $100 for one unit of the product in an uncontrolled sale. If 20 units are sold at a time, there is a discount of 2%. If a batch of 100 units is sold, there is a discount of 5%. So, in the second table, there are two rows of data about the discounts in arm's length transactions.
The third table mentions two example quantities in which BCD makes purchases from its controlled subsidiary, BCD-UK plc.
Now that I'm done with the tables of facts that my simple agent will need, I'll write a rule about how to use the facts to find a transfer price that the tax authorities will regard as reliable.
A rule says that IF one or more pairs of Concept-Items lines are true, THEN so is a conclusion Concept-Items pair.
Figure 5: Writing a RuleAt this point in an example, I'm usually asked whether someone has built a dictionary and grammar of English into the IKM so that it understands the tables and the rule. The answer is "No", as we shall see in the next section, which is about how the IKM works.
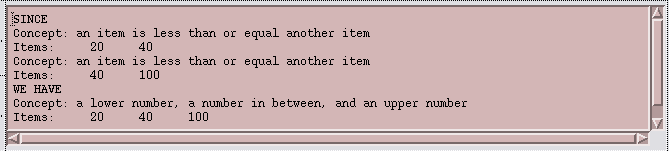
However, I do need to write three more rather straightforward rules, saying what I mean by an interpolation, and how I want the agent to figure percentages.
Figure 6: A Rule about Percentages
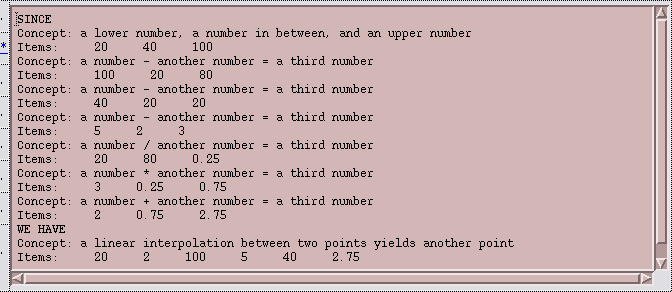
Figure 7: A Rule about Interpolation
Figure 8: A Simple Rule about IntervalsIn actual use of the IKM, I'd expect the DL itself to contain agents with rules about interpolation, percentages, and so on. I could find and retrieve agents, or parts of agents, in the library using an ordinary English text searcher. Or, there could even be agents that help me to find the rules that I need. In this way, the functions of a DL can themselves be come objects within the DL.
Now I have finished writing the agent, and I'm ready to run it. I do this by asking the IKM for a menu of questions my agent can deal with. The IKM sends me this page.
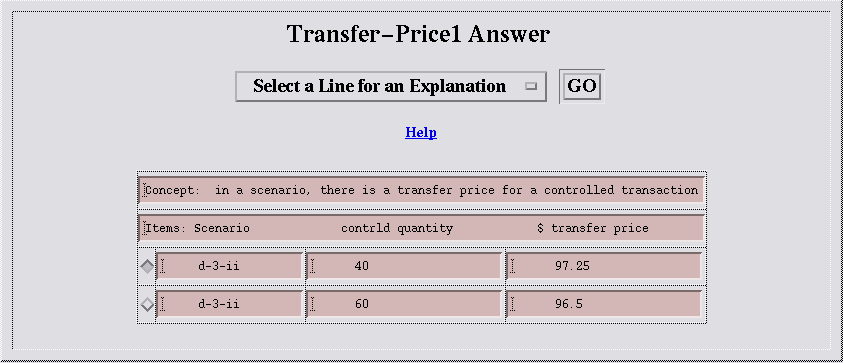
Figure 9: A Menu of QuestionsI pick the top question, and click on GO to ask it. The answer from the IKM is:
Figure 10: An Answer to a QuestionSince the tax authorities are interested in the reliability of the method used to get an answer, it helps that I can select a row of the answer and ask for an explanation. The IKM then generates for me a page consisting of four panels.
The first panel of the explanation gives an overview of why the d-3-ii scenario leads to a transfer price of $97.25 for a controlled purchase of a quantity of 40 of the product.
In the explanation, I can click on a "*"-symbol to the left of a Concept to drill down into detail about how it is justified. This takes me to the panel showing how the interpolation was done, or to a panel showing the percentage calculation.
Figure 11: An Overview Explanation
Figure 12: Detailed Explanation of an Interpolation
Figure 13: Detailed Explanation of a Percentage
Figure 14: Detailed Explanation of an IntervalThen, I can click on the Back button of my Netscape browser to go back up to the top panel of the explanation.
This completes the simple example of writing and running an agent.
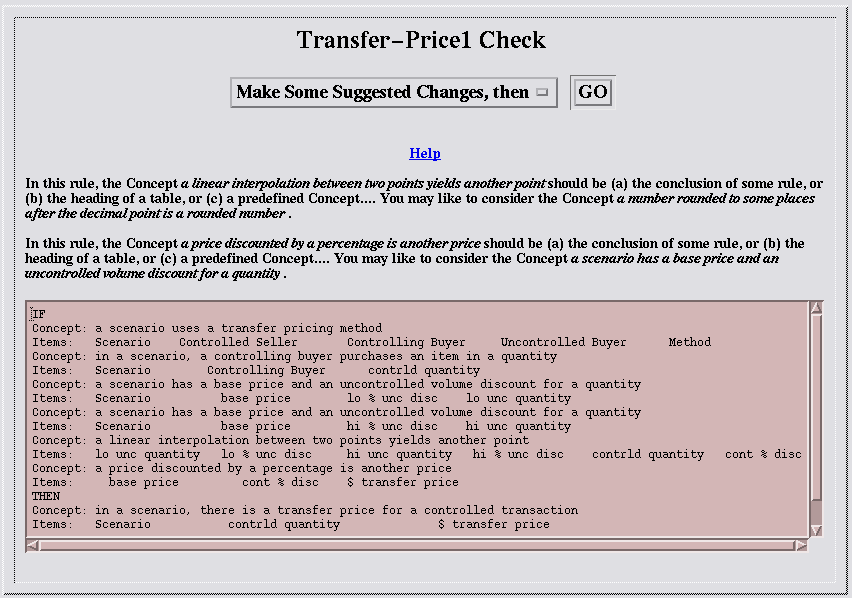
Actually, while I was writing the agent, the IKM environment helped me along by suggesting that I go to a check page containing advice. After I wrote the tables and the first rule, the check page showed
Figure 15: An IKM Check Page for a Partly Written Agentand it helped me along in other ways too. I'll say some more about the check page in Section 3.3.
Transfer pricing is a complex subject. Reliability of a transfer price found by one method depends on whether there is another more reliable method, and on a rich context of knowledge. The knowledge can be partly represented in an agent like the one I have just written, partly represented in documents in a digital library, and partly represented in know-how in the heads of tax consultants. However, there seem to be advantages in gradually moving scenarios, library metadata, and even some of the know-how into agents that work in the IKM environment.
Some advantages are:
- We can run example cases and communicate them precisely to our colleagues anywhere on the net.
- We can build a digital library of runnable agents, and we can use ordinary text search to find the agents we need.
- We can find matches between a new case and cases that are already runnable agents.
I have shown how to write a simple transfer pricing agent, using an ordinary Web browser on a client machine that talks over the Internet to the IKM server. As I write the agent, the IKM generates check pages with helpful advice. Once the agent is written, the IKM automatically generates the pages needed to run the agent as I need them, so that I can ask questions, and get answers and explanations.
Next I'll outline how the IKM server works.
3. How The IKM Technology Works
In the last section, I showed how to write and run a simple agent for transfer pricing. I used an ordinary Web browser on a client machine to connect to the IKM server. As I wrote and ran an agent, the IKM server program created new pages as needed, and sent them to me.
You can use your own words and phrases when writing an agent. In fact, you can actually write not only in conversational or idiomatic English, but also in technical English, and even in French, German and so on. Moreover, no dictionary or grammar of any of these languages is needed. How is this possible?
In the present state of the art, programs that handle English as a natural language use combinations of different techniques for different purposes. For example, many speech recognition programs use a dictionary of English, plus statistics, but do not use a grammar. Many machine translation and critiquing programs use a dictionary and grammar, but no statistics. Some natural language query systems restrict the words that can be used to a controlled vocabulary.
The IKM supports yet another technique, Direct English Specification, that depends on some New Technology, that in turn depends on a mathematical Theory of Declarative Knowledge. I'll discuss each of these in turn, in the subsections 3.1, 3.2 and 3.3. Let's look first at Direct English Specification.
3.1 Direct English Specification
There's a hint about how Direct English Specification works in the check page that I got when I was half way through writing the transfer price agent. The check page said that there should be a rule with the conclusion sentence a linear interpolation between two points yields another point. Or, failing that, the sentence should be the heading of a table, or should be predefined.
The check page said this because I used the sentence in the IF part of a rule, but I had not yet told the agent what I meant by it. I can say what I mean by a sentence by making it a table heading. When I write a sentence as a table heading, I'm basically saying, "Here are some facts about this sentence and this is what I want it to mean". When I write a sentence as the conclusion of a rule, I'm saying that its meaning is based on the meanings of the sentences I have used in the IF part of the rule.
So, the IKM assigns a meaning to a whole sentence, in context in an agent, rather than to individual words. This avoids some serious problems that a word-by-word approach to assigning meaning would have to solve:
- the dictionary definition of a word can be circular
- the meaning of a word can depend on its context
- it is difficult to compose word meanings into a sentence meaning
- it is difficult to anticipate all of the sentences that people will in future regard as grammatical and meaningful.
So, Direct English Specification
- assigns meaning to a sentence by using it as a heading for a table of facts, and
- assigns meaning to a new sentence, in context, by combining it with other sentences (and possibly with itself) in a rule, and
- only allows the above kinds of sentences in the specification of an agent,
- except for certain predefined sentences, that describe how agents can use software outside the IKM.
The technique is simple, robust, and needs no maintenance of a dictionary or grammar. It also has the advantages that
- you can use your own words and phrases, including jargon, when writing an agent.
- the IKM can explain an answer from an agent, step by step, in English.
- the technique can easily be adapted to French, German, and so on.
- an ordinary text search can find items in a Digital Library of agents.
A rule for the IKM, such as in the simple transfer pricing agent, has some premises in the IF part, and a conclusion, which is the THEN part. A sentence in the conclusion of a rule takes its meaning from the sentences in the IF part. But what if the same sentence is in the IF part and in the THEN part? Is that just circular and therefore meaningless? The answer is fortunately "No". In Section 3.3, I'll show an example of such a rule, and I'll say why it has a useful meaning.
3.2 New Technology
To make Direct English Specification work correctly, the IKM uses some New Technology to run the rules in an agent. When you write rules for the IKM, you basically say what the relevant knowledge is, and you leave it to the New Technology to figure out how to use the knowledge. The IKM uses declarative knowledge, in the sense that when you write an agent, you just specify what knowledge you want used. It's then up to the IKM server to figure out how to use the knowledge you have specified to get results. On the other hand, earlier systems need procedural, step by step instructions about how to use rules. In systems that need procedural knowledge, it can be hard to assign a useful English meaning to the conclusion of a rule.
Most systems that run rules, such as classical expert systems, use one of two methods:
- forward chaining
- pick a rule, establish the premises of the rule, then note that the conclusion is established
- keep doing this till all desired conclusions are found
- back chaining
- select a rule whose conclusion matches something we want to establish
- try to establish the premises of the selected rule
- keep doing this till all the required premises are matched to facts
Suppose you write rules that will be run by one of these methods. Then you will need to think about how efficiently the rules will be run. In some cases, such as with rules in which a conclusion is also a premise, you will need to think about whether a rule will run forever! (Computer Scientists like to call this "infinite recursion". In some cases, it goes on forever. In other cases it uses up so many resources that the computer's operating system eventually shuts it down and tells you there has been an error.) Efficiency, and stopping self-referencing rules, are procedural considerations, in the sense that you have to think about what will happen step by step, when each rule is run. In fact you will also have to think a lot about how all of the rules interact. In effect, when you formulate your rules, you will have to write a program.
The New Technology in the IKM uses both forward and backward chaining, and it swaps between the two automatically. The result is that, for many practical purposes, you don't have to worry about efficiency when you write the rules, and you don't have to worry about whether the rules will run forever. What you are doing is more like writing a specification than writing a program. However, you can run your specification right away, and check that it does what you want. There's a technical paper about the New Technology [Wal93]. But the key point is that, to write and run agents in the IKM, you actually don't have to delve into the details of how the New Technology works.
The difference between the procedural and new declarative technologies is rather like the difference between a manual and an automatic transmission in a car. If you really want to, you can learn about how the automatic transmission in a car works, but most people are happy to have it take care of the details for them. On the whole, we trust automatic transmissions to work correctly. But if we hand over procedural control to the IKM server, how do we know that its methods will draw the correct conclusions from our rules ? How do we know it will run our agents correctly ? This where the Theory of Declarative Knowledge comes in.
3.3 Theory of Declarative Knowledge
This table
Figure 16: A Table of Data from the Simple Transfer Pricing Agent looks rather like a table in a relational database. In fact, we could set up the IKM so that it actually is such a table.
This rule
Figure 17: The Main Transfer Price Rule has a logical flavor. Both the table and the rule are ways of writing things in a kind of mathematical logic.
However the logic that is used for rules and databases is different from the logic that you will find in a classical math book.
In classical logic, a statement like in scenario d-3-ii, BCD Corp purchases an item in a quantity of 40 is
- true, if the statement is present
- false, if the opposite of the statement is present, and
- unknown, if both the statement and its opposite are absent.
In a relational database, however, a fact is either in the database (true), or absent (false). There is no unknown middle ground. This works well for databases, but as people became interested in using rules as well as tables of facts, the non-classical logic of databases caused problems.
Classical logic has a model theory that spells out exactly what conclusions it should be possible to draw from a collection of statements. But as people started using rules together with databases, they found that the new non-classical logic of databases lacked such a theory. In fact, it was sometimes not clear what conclusions it should be possible to draw from some rules and a database.
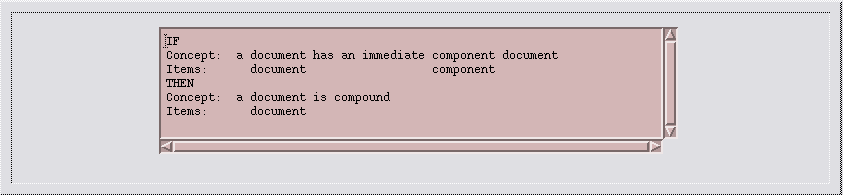
A rule in the IKM can have the same Concept in the IF part and in the conclusion. For example, I use this rule
Figure 18: A Rule About Documents and their Sub Componentsin an agent for payments to the various suppliers of the parts of a compound document [Wal98]. The rule specifies what I mean by a sub component of a document, and it allows the IKM to reason about sub-sub components, and so on.
A rule in the IKM can also ask for a statement in its IF part to be false rather than true. For example, I use these two rules
Figure 19: A Rule About Compound Documents
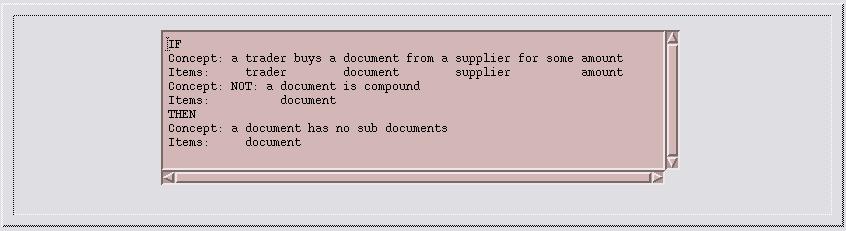
Figure 20: A Rule About Documents that are not Compound to say what I mean by a compound document, and by a document that has no sub documents.
So far, this is fine. I can write a rule with the same concept in the IF part and in the THEN part, and I can write another rule with a NOT in the IF part. But what if someone were to write a rule like this ?
Figure 21: A Problem Rule In the rule, the NOT in the IF part applies to the same concept as the one in the THEN part. Classical logic would actually assign a meaning to the rule, but the rule definitely looks wrong! The reason is that we have shifted from classical logic to a logic of rules and databases in which the rule is interpreted as "if a document does not have a sub component then it does have a sub component".
Of course, we could ask people who write agents not to write such rules. But it turns out that, although the last rule is obviously wrong, there are more complicated examples in which several rules contribute to the same kind of flaw, but in ways that are more difficult for someone writing an agent to notice.
Fortunately, there is a method of testing a collection of rules to see if it is flawed in this way. The method is built into the IKM. So, the IKM check page will warn you about such a flaw in the unlikely event you should write one in an agent you are specifying.
With these problems ruled out by the testing method, Krzysztof Apt, Howard Blair and I were able to find a Theory of Declarative Knowledge [ABW88] that spells out the meaning of a "flawless" collection of rules and database tables. Our theory says exactly what conclusions it should be possible to draw from such collections. Even more fortunately, there seems to be general agreement that our theory accurately captures people's intuition about the intended meaning of a collection of rules and tables !
Since we did our work on the Theory of Declarative Knowledge, other Computer Scientists have published many papers extending the theory in interesting directions. However, some of these extensions lack practical testing methods. While our Theory serves as a foundation for the IKM for foreseeable practical purposes, it could turn out to be useful in future to extend the IKM so that it can run some collections of rules that currently lead to a check page.
4. Status and Conclusions
The current IKM is a multi-user program running on one server machine. Several people can simultaneously use their Netscape clients to connect to IKM so as to write and run agents. The status of the IKM is "working prototype", or if you like, "version 0.9".
I hope that the transfer pricing example persuaded you that it is simple to use an agent in the IKM, and that it is fairly easy to get the hang of writing new agents. However, this simplicity hides a rather ambitious goal, one that people who use and write agents normally don't need to be concerned about.
The goal is to move away from programming how an agent should work to just specifying what the agent should do. The IKM server program has the complex job of figuring out automatically the how that it must add to achieve the what. As is the case with database management systems, doing this efficiently, for increasingly demanding tasks, is the subject of ongoing research and development.
I have talked about some ways of using the IKM technology to bring together dynamic digital libraries, and some aspects of the kind of human knowledge management that is advocated and practiced by business consultants. I have outlined how DLs, consisting of collections of documents, appropriate metadata, search functions, and agents, can contribute value in the world of e-business. The IKM provides an environment that helps a person with implicit know-how to make it explicit, understandable to others, and runnable as an agent. Knowledge is represented at an English and business level, so that it is easy to understand, share, and change.
Since the Internet Knowledge Manager supports a new way of representing human knowledge in software, it could trigger new ways of doing knowledge management, of using digital libraries, and of doing e-business.
5. References
[ABW88] K. Apt, H. Blair, and A. Walker. Towards a Theory of Declarative Knowledge, In: Foundations of Deductive Databases and Logic Programming, J. Minker (Ed.), Morgan Kaufman, 1988.
[Cryp97] Cryptolope Technology Homepage.
http://www.cryptolope.ibm.com[DavPru97] T. H. Davenport and Laurence Prusak. Working Knowledge: How Organizations Manage What They Know. ISBN: 0-87584-655-6, December 1997.
[GlLo97] H.M. Gladney, J.B. Lotspiech. Safeguarding Digital Library Contents and Users: Assuring Convenient Security and Data Quality. D-Lib Magazine, May 1997.
http://www.dlib.org/dlib/may97/05contents.htm[Hua97] Kuan-Tse Huang. Capitalizing Collective Knowledge for Winning, Execution and Teamwork. Journal of Knowledge Management, Vol. 1, Number 2, December 1997.
[Tax98] An Introduction to International Taxation from a U.S. Perspective.
http://www.intltaxlaw.com/shared/transfer/regs.htm[Wal98] A. Walker. The Internet Knowledge Manager, and its Use for Rights and Billing in Digital Libraries. Proc. First International Conference on the Practical Application of Knowledge Management, 1998.
http://www.demon.co.uk/ar/PAKeM98.[Wal93] A. Walker. Backchain Iteration: Towards a Practical Inference Method that is Simple Enough to be Proved Terminating, Sound and Complete. Journal of Automated Reasoning, 11:1-22, 1993.
Copyright and Disclaimer Notice
(c) Copyright IBM Corp. 1998. All Rights Reserved.
Copies may be printed and distributed, provided that no changes are made to the content, that the entire document including the attribution header and this copyright notice is printed or distributed, and that this is done free of charge.
I have written for the usual reasons of scholarly communication. This report does allude to technologies in early phases of definition and development, including IBM property partially implemented in products. However, the information it provides is strictly on an as-is basis, without express or implied warranty of any kind, and without express or implied commitment to implement anything described or alluded to or provide any product or service. IBM reserves the right to change its plans, designs, and defined interfaces at any time. Therefore, use of the information in this report is at the reader's own risk.
Intellectual property management is fraught with policy, legal, and economic issues. Nothing in this report should be construed as an adoption by IBM of any policy position or recommendation.

Top
| Magazine
Search | Author Index | Title Index | Monthly Issues
Previous Story | Next Story
Comments | E-mail the Editor
hdl:cnri.dlib/march98-walker