D-Lib Magazine
July/August 2016
Volume 22, Number 7/8
Table of Contents
The Pathways of Research Software Preservation: An Educational and Planning Resource for Service Development
Fernando Rios
Data Management Services, The Sheridan Libraries, Johns Hopkins University
rios@jhu.edu
DOI: 10.1045/july2016-rios
Printer-friendly Version
Abstract
Research communities, funders, publishers, and academic libraries have put much effort towards ensuring that research data are preserved. However, the same level of attention has not been given to the associated software used to process and analyze it. As a guide to those tasked with preserving research outputs, a novel visual representation of preservation approaches relevant to research software, termed the Pathways of Research Software Preservation, is presented. The Pathways are discussed in the context of service development within the Data Management Services group at Johns Hopkins University.
1 Introduction
In many fields, the computer programs used to view, process, analyze, and create data (i.e., research software) form an integral part of the research workflow [6], and are often even the product of it. There are many reasons for preserving this software, including, meeting contractual obligations, encouraging reuse, enabling research reproducibility, and preserving heritage value [3]. These reasons mirror the goals of data preservation, a task which many institutional libraries have been helping their faculty and graduate students address for the past several years.
Although publishers, funders, and research communities have not articulated the need for software and code preservation to the same degree as has been done with data, this is beginning to change as the emphasis on transparency, openness, and reproducibility in research increases [11, 6].
While research software and digital data share many challenges with respect to preservation and management, comparatively fewer solutions have been put forth and agreed upon in the software realm. As a result, many issues remain in regards to identifying and capturing metadata, dependencies, support for attribution and citation, infrastructure development, and developing appropriate workflows to enable service provision. In order for those charged with preserving research software to begin crafting plans to address those challenges, a high-level view of research software preservation approaches is needed. Such a view is encapsulated in the "Pathways of Research Software Preservation" presented in Figure 1 below. Although research software as defined at the beginning of this section can include standard software packages (e.g. file viewers, plotting, scripting environments etc.), this discussion focuses on software produced as part of the research process.
2 Motivation for a Visual Representation
The development of a visual representation of software preservation was driven by three needs in the Data Management Services group at Johns Hopkins University (JHUDMS). The first was a need to briefly summarize the major approaches to software preservation and their relation to research software and research data management (RDM).
The second was a need to evaluate our capacity to offer software preservation services including consulting (e.g., navigating funder or publisher requirements, addressing specific preservation needs), training (e.g., best practices), and archiving (e.g., infrastructure development to enable archiving in the Johns Hopkins University (JHU) Data Archive).
The third reason is related to the second and corresponds to the need for a roadmap. The idea is that a high-level view of what is possible will help guide the development of human and infrastructure resources for potential future service provision. Additionally, in this respect, interactions with other library and technological staff (and researchers as well) are critical for success. Therefore, having a visual communication tool to explain what JHUDMS is trying to achieve and how software fits into digital preservation is invaluable.
3 Previous Work
Visualizations are popular for conveying an overview of the data management process to those who may not be familiar with all of its aspects. This is plainly evident by the large number of hits returned if one conducts an Internet search on the term "research data lifecycle".
Figure 1 is based on a synthesis of the software preservation literature. Although the focus here is research software, the review included work from those involved in preserving video games, software-based art, and other software of historical importance. Therefore, with slight modification, this visualization should be adaptable to those cases as well.
Since a review of the literature is not the purpose of this paper, the reader can refer to [12], [22], [8], [3], [6], [15] and [9] for background information regarding software preservation.
4 Pathways of Research Software Preservation
4.1 Overview
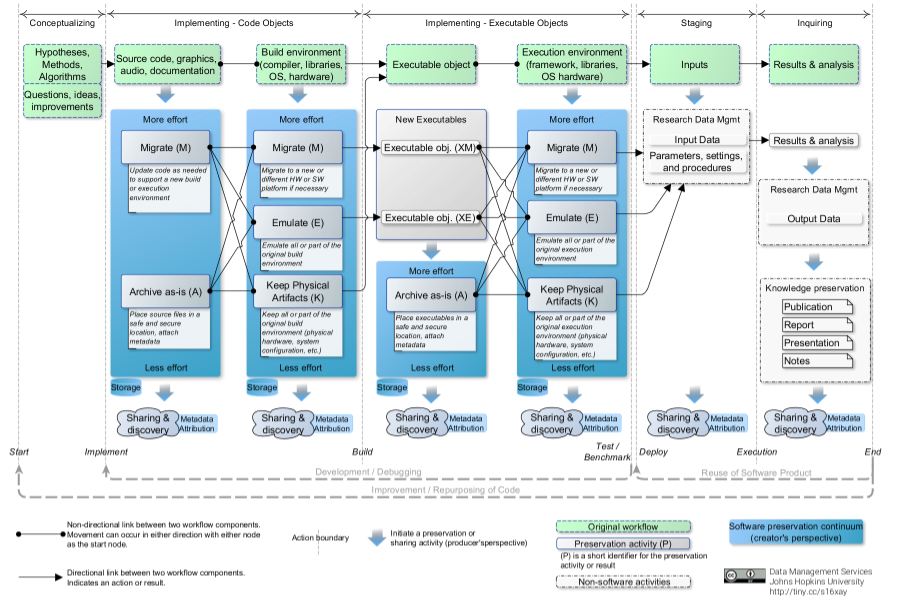
One way to break down the development and use of software in the research process is via a set of general phases: developing concepts and theory (Conceptualizing), writing the software (Implementing — Code Objects), obtaining all objects required for execution (Implementing — Executable Objects), collecting inputs and setting parameters (Staging), and making use of the results (Inquiring). The phases are shown in Figure 1 as the labeled arrows spanning each of the vertical dashed lines. Furthermore, each phase is composed of certain tangible components indicated by the green boxes with a dashed outline. Intangibles, such as tacit information, are not considered here.
These particular phases (and associated components) were chosen because they separate the process of conceptualizing, developing, and using software for research into logical blocks that are preservable and shareable independently of the others while retaining the natural separation between software-related activities (e.g., implementation, compilation, execution, etc.). Although other choices of phases are possible, they may not capture salient details. For instance, since code and executable artifacts often exist together (e.g., during development), combining the two implementation phases into a single phase is possible. However, if this were to be done, conceptualizing the preservation and sharing of each individual piece would become more difficult as the differences between preservation approaches of source code vs executables may not be easily representable. Finally, although this discussion focuses on the phases that produce source code or executables, the figure also includes preservation activities that take place at the other stages of research which are linked to software but are not software. An example is the use and preservation of data as input to or output of software via research data management. Although present in the figure to acknowledge their importance, those activities are not elaborated on here.
The dashed vertical lines represent events between the different phases of research software . The sequence of components in the dashed boxes, from left to right, represents the "original" software workflow (i.e., the workflow that is the target of preservation) as viewed from the software creator's perspective. The creator's view is adopted because the preservation outcome hinges on choices they make.
The downwards arrow below each component indicates a movement to one of several potential preservation activities associated with that component. The activities are arranged in a continuum of effort, indicating the effort the creator may need expend to carry out that activity, assuming that the infrastructure to carry it out already exists. The continuum culminates in the potential sharing of that preserved component.
Components and preservation activities are connected by arrows or lines. The arrows indicate movement to the next phase via an event, while the lines merely indicate a relationship between two components/activities within the same phase. Also note that not all phases or components may apply to all cases. For example, if using a scripting language, the build and execution events might occur synchronously and the Build Environment and Execution Environment components will be the same.
The following discussion focuses on the two implementation phases as the work done in these phases are the main targets of research software preservation.
(View larger, more detailed version of Figure 1.)
Figure 1: The Pathways of Research Software Preservation. The development and use of research software as viewed from the creator's perspective can be broken down into five phases which are separated by events. The implementation phases, separated into Code Objects and Executable Objects, are linked by the Build event and have tangible software components which can be preserved and shared. The other phases also have preservable components which can be handled using established RDM approaches.
4.2 Implementation — Code Objects Phase
This phase consists of two components: the source code and the build environment. For the source code component, the Migrate preservation activity, abbreviated as (M), refers to adapting the source code to a new environment where it may be built (compiled and/or assembled into a working package). This may be needed when the original build environment has become obsolete or when the source code is shared and the original build environment is not available. The Archive-as-is (A) activity refers to storing the source files as-is in a trusted repository.
Linked to the source code is the build environment component. All or part of this component can be migrated (e.g., necessary when moving the entire development environment from a 32- to 64-bit architecture). Another option is the emulation (E) approach (note that here, "emulation" is used very loosely and refers to technologies such as virtualization, containerization, or true emulation) where the original environment is captured and simulated to the extent required to ensure adequate performance (i.e., behavior, output [8]) of the preserved software. Simply preserving the original physical system (K), including hardware and software is also valid. The products of preservation, such as migration procedures/build notes in the case of (M), a disk image for (E), or access to the original configuration (K), can then be shared.
The preservation activities associated with the two components in this phase can be linked in various ways, as shown in Figure 1, and detailed below.
- (MM): The strategy of migrating the code and build environments is designated as (MM). This is essentially preservation via active maintenance. Significant effort is required to ensure successful migration of the code and build environments. An example of this occurs when moving both components to a completely different environment (e.g., changing operating system from Mac to Windows). Any differences in functionality between the environments must be reconciled in the code and in the build process.
- (ME) migrate-emulate: This combination of strategies arises if there is a need to continually update the code to support new/updated environments while retaining the capability of building it on the original emulated environment (e.g., for reproducibility purposes).
- (MK) migrate-keep: Similar to the (ME) case except the original build environment is retained, instead of emulating it.
- (AM) archive-migrate: This strategy is appropriate when the software is no longer in active maintenance but the development environment is (e.g., MATLAB). In this case, the new build environment must have backwards compatibility with the preserved code. If it does not, then the code will need to be migrated. See the (MM) case. Although this strategy requires minimal effort to preserve the code, successfully migrating the build environment may, in some cases, require much effort since build scripts, settings, and dependencies must be migrated as well. Tools like Maven can help in this regard.
- (AE): This combination consists of archiving the original code and building it in an emulated environment. This strategy is the most realistic for long-term preservation when code development has ceased and the development environment has become obsolete.
- (AK): Same as (AE) except the original environment is used to build the software. This case is perhaps the simplest but least effective way to preserve software.
4.3 Implementing — Executable Objects Phase
This phase follows the Code Objects phase via the build event and contains two components: the executable software itself and the associated execution environment. When executables are not generated or are hidden, as is the case for interpreted languages (e.g., MATLAB or R), the build and execution environments are considered as one.
Depending on the preservation choices made in the previous phase, the entry point into this phase may vary. Building the software in a different environment than the original or under emulation results in the (XM) and (XE) executables respectively . These are different than the originals and therefore must be validated to ensure their performance is adequate. This underscores the need to have benchmarks or unit tests that allow for such evaluations. If coming from the (AK) case, then the build event should result in software with identical performance to the original.
These executables can themselves be archived. Note that emulation is not applied to the executables themselves but to the execution environment. Preservation of the execution environment is similar to that of the build environment and the links between the preservation activities resemble those in the coding phase except the objective is now retaining the ability to execute the software instead of build it.
4.4 Sharing and Discovery
Each preservation activity in Figure 1 has an associated Sharing & Discovery action at the very end. To support this, there must be appropriate technical, policy and legal frameworks, metadata and attribution structures, and a community culture that supports such sharing. Addressing these issues is a substantially more challenging task than the technical aspects outlined in the figure and is outside its scope. See e.g., [13], [10], [4], [16] and the work of the Software Sustainability Institute [5], [2] for recent efforts in these areas.
In moving forward with a research software archiving service, JHUDMS is currently in the process of addressing some of these challenges, including identifying and implementing metadata suitable for use in the JHU Data Archive, and identifying gaps in the development and use of research software (e.g., attribution, licensing, code management) in order to develop training material for JHU researchers.
4.5 Non-software Facets of Research
There are many facets to scientific transparency, reproducibility, and reuse and this paper focuses on one of them: software. As such, Figure 1 is a purposefully narrow view of the scientific workflow and includes only the parts in which software plays an integral research role. Although not discussed, the other facets (e.g., data collection methodologies) are critical to ensuring the entire scientific workflow is reproducible. In terms of data, best-practices have been widely developed and used by the RDM community [14], [21], [1] and reproducing the scientific workflow (including software) has also received attention elsewhere [7], [17], [20], [18].
4.6 Selecting a Pathway — Examples
To illustrate specific pathways, consider the following two cases:
- Case 1, A researcher wishes to preserve and share only his/her source code. Other researchers would download the code and build/execute it in a new environment. In the context of Figure 1, this is a migration of the code, the build, and the execution environments (the path is AMXMM). Code under active development might be represented as the (MMXMM) path instead.
- Case 2, A researcher shares only the executables. Others would download and run these executables, with no possibility to modify the code. This causes the pathway to begin within the Executable Objects phase. The (--AM) case arises when the preserved executable is run in a new environment while the (--AE) case corresponds to executing the software in a preserved emulated environment. The '--' indicates that preservation of the Code Objects phase either does not occur, or remains hidden.
To ensure successful preservation, the creator must take the appropriate steps so that the desired pathway is achievable. For instance, in order for the (--AE) path to work, the creator must ensure that the original execution environment is adequately captured into an image so it may be loaded into emulation software or that there is enough information to reproduce such an environment.
An important aspect of preserving research software is determining which path to take and when to make this selection. Making this determination during the initial phases of the project is ideal since it helps in planning and costing the preservation activity. Helping researchers make these determinations should be part of service provision around data/software management. It should be noted that since service provision around preserving research software is still quite new, there is little in the way of best practices in the matter.
Because software is dynamic, different paths may be taken at different stages in a project. For instance consider an expanded version of Case 1 presented above consisting of a large software project. In the active stage of the project (perhaps several years long) preservation activities may consist of the migration approach, i.e., keeping the code up to date so that it runs on the latest hardware or operating system. However, as it nears the end of funding, perhaps an emulation path may be selected. Of course, these different paths should ideally be planned for in advance to enable appropriate planning and costing.
5 Using the Visualization
5.1 Service Development Study
Over the course of approximately eight weeks (in bi-weekly meetings), JHUDMS used Figure 1 to determine a meaningful and feasible software archiving service. In the first meeting, the figure was presented and used to elucidate the general components and concepts related to software preservation while subsequent meetings explored specific aspects (e.g., challenges and the state-of-the-art in emulation/virtualization for preservation) in greater depth. During these more detailed explorations, the diagram helped anchor the discussion in the context of the other approaches.
Parallel to the discussions, the JHUDMS team was challenged to place preservation use cases within the framework of Figure 1. This activity took place during the second meeting with the purpose of eliciting the team's strengths and weaknesses in order to help determine a feasible way forward in fleshing out the archiving service. Each team member was randomly assigned three test cases from the scenarios presented in [3]. They were then asked to draw a path, by hand, on Figure 1 which they thought best addressed each scenario.
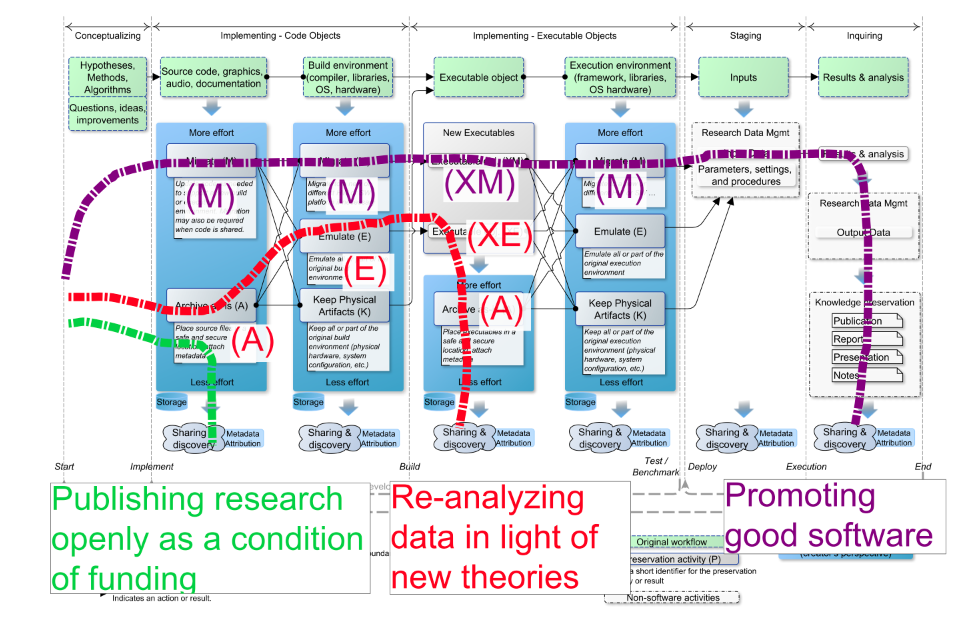
(View larger, more detailed version of Figure 2.)
Figure 2: Pathways identified by a JHUDMS group member (shown as the broken lines) to address three randomly selected scenarios of software preservation. Five other such diagrams (based on different scenarios) were created by other group members.
Figure 2 shows one team member's results (five additional figures were generated, one for each team member). Each graphic was discussed as a group with the graphic's creator explaining the rationale behind his/her decisions. This served as a springboard for a detailed discussion of what parts of the preservation process were possible and desirable to address in the short- and medium-term while remaining mindful of resources and the scope of the services provided by JHUDMS. After discussion in a subsequent meeting, consensus was reached for a short-term initiative around developing a specialized code archiving service which treats software as a first-class research output and integrates with the current workflow for the JHU Data Archive. The goal is to have the ability to archive software produced as part of the research process in any discipline. The software is to be archived as-is and salient characteristics should be captured via a metadata schema.
In determining a path forward to achieve the aforementioned goal, the exercise revealed gaps in JHUDMS's consultative and training services. For example, it was determined that one area where services can be expanded is developing the capability to advise researchers on the best repository to deposit their software in (which may not necessarily be the JHU Data Archive) and how it may be made easier to find. Another area is the development of data/software management planning services.
5.2 Limitations and Lessons Learned
The preservation activities in the Pathways of Software Preservation and the links between them do not specify how each activity should be carried out or how one should specify or describe the links. This is intentional to ensure the broad applicability of the visualization as the specifics of how these things are done can vary widely depending on the domain and goals of preservation. Furthermore, the Pathways do not guarantee successful preservation. For instance, if the metadata or documentation associated with the preserved software is inadequate, it may be difficult or impossible for others to reconstruct the software, or even find it.
Increasingly, researchers are making use of web services such as mapping APIs, online storage services, and cloud-based discipline-specific research tools. However, the Pathways do not fully capture these cases since the distinctions between the build and execution environments, and the executable and source code become blurred. Nevertheless, for truly preserving software that depends on these kinds of services, Figure 1 remains useful as a guide to the different options available for server-side software preservation.
Despite these drawbacks, Figure 1 has demonstrated its usefulness in its main role as a communication tool for information professionals to frame discussions of preserving, archiving, and sharing software. For example, in one conversation with a humanities librarian who dealt with topics ranging from art history, film and media studies, to Islamic studies, the different pathways in the figure served to illustrate how preserving a piece of software-based art might differ from text mining scripts based on the different goals of preservation those use cases may have. In another example, an individual's work in advocating open science was placed within the framework of the figure (specifically, the sharing component) to show how software preservation plays a part in scientific reproducibility. A natural link was discussing how the different preservation approaches might differ when it comes to sharing.
In its role as a planning tool, the exercise from Section 5.1 showed the utility of the visual approach for evaluating the capacity for software preservation activities. Moving in the opposite direction, the activity exposed a gap in the figure's treatment of software testing. Testing is important in the preservation process to ensure that the software conforms to the required performance, however, this notion was originally omitted from the figure. The omission was corrected and incorporated as an extra event between the Executable Objects and Staging phases.
One last important point is that the use of Figure 1 as an educational tool may lead those not familiar with RDM to believe that research software preservation is a straightforward and "solved" problem. In informal discussions with researchers, some believed that certain actions such as following good software engineering practices or simply placing code in repositories like GitHub were sufficient for preservation. It was not until the figure was explained in more detail that a better appreciation of the nuances of research software preservation and sharing, such as the value of virtualization for the capture of build/execution environments or the challenges in capturing appropriate metadata for reuse, were appreciated.
6 Final Words
Funders, publishers, and institutions are beginning to recognize the need for preserving the software associated with research data. However, approaches to support the need have not yet been articulated to the same level as research data. This paper presented a bird's-eye visual representation of approaches to research software preservation which can be used as an educational and planning tool for all stakeholders. In particular, the visualization was successfully used as an informal way to broadly present the research software preservation landscape and as a platform for more in-depth discussion around specific aspects. Furthermore, it served as a planning tool to determine capabilities and weaknesses for developing a software archiving service for the JHU Data Archive.
As the needs surrounding research software preservation become better articulated by all stakeholders, infrastructure and services to support those needs will continue to evolve. At some point in the process, Figure 1 will outlive its usefulness as a planning tool, at least in its current form. However, as an educational tool, Figure 1 may be useful, perhaps in a condensed form, for helping researchers address software when writing data management plans (DMPs) and/or software management plans [19]. The precise way it can be used in this fashion remains to be determined.
Acknowledgements
Special thanks to Barbara Pralle, Jonathan Petters, and Chen Chiu of JHUDMS for providing valuable comments on a draft of this paper.
References
| [1] |
M. Donnelly. Data management plans and planning. In Managing Research Data, page 224. Facet Publishing; 1st edition, 2012. |
| [2] |
N. C. Hong. Minimal information for reusable scientific software, 2014. http://doi.org/10.6084/m9.figshare.1112528 |
| [3] |
N. C. Hong, S. Crouch, S. Hettrick, T. Parkinson, and M. Shreeve. Software preservation benefits framework. Software Sustainability Institute Technical Report, 2010.
|
| [4] |
J. Howison and J. D. Herbsleb. Incentives and integration in scientific software production. In Proceedings of the 2013 Conference on Computer Supported Cooperative Work, CSCW '13, pages 459-470, New York, NY, USA, 2013. ACM. http://doi.org/10.1145/2441776.2441828 |
| [5] |
M. Jackson. How to cite and describe software, 2012. |
| [6] |
D. S. Katz, S.-C. T. Choi, N. Wilkins-Diehr, N. Chue Hong, C. C. Venters, J. Howson, F. Seinstra, M. Jones, K. Cranston, T. L. Clune, M. de Val-Borro, and R. Littauer. Report on the second workshop on sustainable software for science: Practice and experiences (WSSSPE2). Journal of Open Research Software, 4 (1): e7, 2016. http://doi.org/10.5334/jors.85 |
| [7] |
B. Ludascher, I. Altintas, S. Bowers, J. Cummings, T. Critchlow, E. Deelman, D. D. Roure, J. Freire, C. Goble, M. Jones, S. Klasky, T. McPhillips, N. Podhorszki, C. Silva, I. Taylor, and M. Vouk. Scientific Process Automation and Workflow Management. In Scientific data management: challenges, technology, and deployment. Boca Raton: CRC Press, 2010. |
| [8] |
B. Matthews, A. Shaon, J. Bicarregui, and C. Jones. A framework for software preservation. International Journal of Digital Curation, 5 (1): 91-105, 2010. |
| [9] |
J. McDonough, R. Olendorf, M. Kirschenbaum, K. M. Kraus, D. Reside, R. Donahue, A. Phelps, C. Egert, H. Lowood, S. Rojo, et al. Preserving virtual worlds final report, 2010. |
| [10] |
K. E. Niemeyer, A. M. Smith, and D. S. Katz. The challenge and promise of software citation for credit, identification, discovery, and reuse. arXiv preprint arXiv:1601.04734, 2016. |
| [11] |
B. A. Nosek, G. Alter, G. C. Banks, D. Borsboom, S. D. Bowman, S. J. Breckler, S. Buck, C. D. Chambers, G. Chin, G. Christensen, M. Contestabile, A. Dafoe, E. Eich, J. Freese, R. Glennerster, D. Goroff, D. P. Green, B. Hesse, M. Humphreys, J. Ishiyama, D. Karlan, A. Kraut, A. Lupia, P. Mabry, T. Madon, N. Malhotra, E. Mayo-Wilson, M. McNutt, E. Miguel, E. L. Paluck, U. Simonsohn, C. Soderberg, B. A. Spellman, J. Turitto, G. VandenBos, S. Vazire, E. J. Wagenmakers, R. Wilson, and T. Yarkoni. Promoting an open research culture. Science, 348 (6242): 1422-1425, June 2015. http://doi.org/10.1126/science.aab2374
|
| [12] |
T. Owens, editor. Preserving.exe: toward a national strategy for software preservation. National Digital Information Infrastructure and Preservation Program at the Library of Congress, Washington, D.C., 2013. |
| [13] |
H. Piwowar and J. Priem. Depsy: valuing the software that powers science, 2016. |
| [14] |
J. M. Ray. Research data management: Practical strategies for information professionals. Purdue University Press, 2014. |
| [15] |
D. S. Rosenthal. Emulation & virtualization as preservation strategies. 2015. |
| [16] |
V. Stodden. The legal framework for reproducible scientific research: Licensing and copyright. Computing in Science & Engineering, 11 (1): 35-40, 2009. http://doi.org/10.1109/MCSE.2009.19 |
| [17] |
V. Stodden, F. Leisch, and R. Peng. Implementing Reproducible Research. Chapman & Hall/CRC The R Series. CRC Press, 2014. |
| [18] |
D. Thain, P. Ivie, and H. Meng. Techniques for preserving scientific software executions: Preserve the mess or encourage cleanliness? In Proceedings of the 12th International Conference on Digital Preservation (iPRES), November 2-6 2015. http://doi.org/doi:10.7274/R0CZ353M
|
| [19] |
The Software Sustainability Institute. Checklist for a software management plan. v0.1, 2016. |
| [20] |
I. Welch, N. Rehfeld, E. Cochrane, and D. von Suchodoletz. A practical approach to system preservation workflows. Praxis der Informationsverarbeitung und Kommunikation, 35 (4): 269-280, 2012.
|
| [21] |
M. Witt, J. Carlson, D. S. Brandt, and M. H. Cragin. Constructing data curation profiles. International Journal of Digital Curation, 4 (3): 93-103, 2009. http://doi.org/10.2218/ijdc.v4i3.117 |
| [22] |
J. G. Zabolitzky. Preserving software: Why and how. Iterations: An Interdisciplinary Journal of Software History, 1 (13): 1-8, 2002. |
About the Author
Fernando Rios is currently a CLIR postdoctoral fellow in the Data Management Services group at Johns Hopkins University, investigating issues around archiving software and code to support research reproducibility and reuse. He has been active in software development in academia and in industry where he has worked on software projects in the areas of geographic information systems, groundwater modeling, and incident management. He received his Ph.D. in Geography from the University at Buffalo, SUNY.