 |
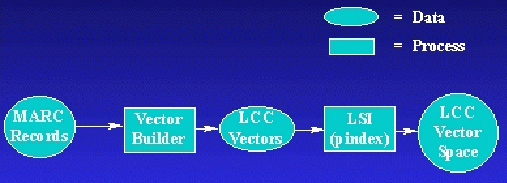
The general design of this component is shown in Figure 2. We want to associate each category in the LCC Outline with a set of terms that are representative of that category. In order to build such a term representation, we begin with a training set, such as MARC records. Each record is processed by a program ("Vector Builder") that extracts the appropriate terms from it and assigns them to the corresponding LCC category. We end up with a representative document for each LCC category ("LCC Vectors") consisting of the terms from all the MARC records that corresponded to that category. These documents are used as input to LSI. LSI constructs a high-dimensional vector space such that each unique term is represented by a different dimension. It places each LCC category as a point, or vector, in this space. Each component of a vector is determined by the number of times that the term for that dimension is used in the category's term-based representation. LSI then employs singular value decomposition to reduce the dimensionality to approximately 100 dimensions whose orientations are some linear combination of the original axes. LSI maintains an index of all the terms as some combination of the reduced space. LSI then places the input documents into this reduced space. In our case, the input documents are the term representations of each of the 4214 nodes in the LCC Outline. These nodes can be viewed as documents in a collection which LSI attempts to retrieve based on their relevance to queries. The end product of this component, the "LCC Vector Space", is used by LSI in both of the following two sections.
Suppose, for example, that instead of using an LSI-based vector space, we used an inverted term index, as does Cheshire [9]. We would need this index both at the source, to build the profile, and at the client, to handle the subject query-mapping. We would not, however, need to retrieve this index at query-time. The acquisition of the index (or LSI space, etc.) is required only once. In other words, this method is independent of the particular IR system used. We prefer LSI because it indexes based on term groupings, rather than on individual terms. Thus "investment" might be associated with documents which contain "bank" and "finance" even if the word "investment" does not actually appear in all those documents.
Building the relationships between the terms and the LCC nodes
requires a training set which associates terms with LCC categories.
One way of doing this is simply to use the descriptive text
associated with each category, such as "Pediatrics" associated
with "RJ 1-570" as described above.
While we did incorporate these terms, they did not provide a
rich enough set of words.
In order to enhance this set, we
used the 1.5 million MARC records for the items held at
the UCSB library. MARC record
format is a national standard for the exchange and
distribution of cataloging data, backed by the
Library of Congress.
From each record, we extract the LCC number,
title, and subject heading information.
We assign the terms from the title and subject heading fields to the
LCC category associated with the LCC number.
In so doing, we have acquired over 410,000 unique terms
for the 4214 node LCC hierarchy.
On average, there were 371 MARC records per node, with a median of
43; 414 nodes had zero MARC records.![[*]](foot_motif.gif) For example, there were 229
MARC records that were placed directly into "RJ 1-570: Pediatrics",
as well as 1679 records distributed among its 14 children. The 229 records
generated, after removing duplicates within each record, over 2600 terms.
These consisted of, after removing stop-words, over 700 unique terms, including
the ten most frequent terms shown in
Table 3 in decreasing order by frequency.
For example, there were 229
MARC records that were placed directly into "RJ 1-570: Pediatrics",
as well as 1679 records distributed among its 14 children. The 229 records
generated, after removing duplicates within each record, over 2600 terms.
These consisted of, after removing stop-words, over 700 unique terms, including
the ten most frequent terms shown in
Table 3 in decreasing order by frequency.
| Frequency | Term |
|---|---|
| 141 | children |
| 101 | child |
| 67 | infants |
| 66 | pediatrics |
| 65 | health |
| 43 | mental |
| 42 | feeding |
| 30 | nutrition |
| 29 | care |
| 27 | breast |