|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Nick Nicholas Nigel Ward Kerry Blinco |
![]()
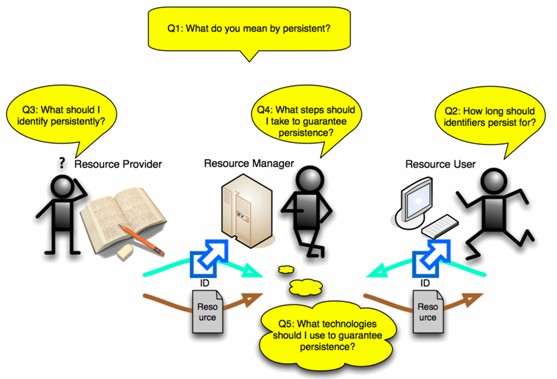
AbstractOne of the main tasks of the Persistent Identifier Linking Infrastructure (PILIN) project on persistent identifiers was to establish a policy framework for managing identifiers and identifier providers. A major finding from the project was that policy is far more important in guaranteeing persistence of identifiers than technology. Key policy questions for guaranteeing identifier persistence include: what entities should be assigned persistent identifiers, how should those identifiers be exposed to services, and what guarantees does the provider make on how long various facets of the identifiers will persist. To make an informed decision about what to identify, information modelling of the domain is critical. Identifier managers need to know what can be identified discretely (including not only concrete artefacts like files, but also abstractions such as works, versions, presentations, and aggregations); and for which of those objects it is a priority for users and managers to keep track. Without working out what actually needs to be identified, the commitment to keep identifiers persistent becomes meaningless. To make sure persistent identifiers meet these requirements, the PILIN project has formulated a six-point checklist for integrating identifiers into information management, which we present here. IntroductionOrganisations and individuals depend on resources made available online. Increasingly, this includes the requirement that well-managed resources remain available and accessible over the long term. To guarantee long-term access, as well as availability, maintaining persistent identifiers for resources is critical and needs to be included in any planning with that goal in mind. The PILIN project (Persistent Identifier Linking INfrastructure) was funded from 2006 through 2008 to strengthen Australia's ability to use global persistent identifier infrastructure, particularly in the repository domain. There is a clear technological component to this work, and the project includes software and service specifications among its outputs. [1] However, it is well known that technology is not sufficient to guarantee persistence: if anything, depending on particular technologies ends up getting in the way of persistence. Guaranteeing persistence of identifiers depends much more on cogent policies to make sure that someone keeps assets online and links up to date, over a well-defined period. It is just as important to be seen as having cogent policies, as to have them: the proper goal of persistence is to establish user trust in using the identifiers. With that in mind, a major focus of the PILIN project was to establish a policy framework for managing identifiers and identifier providers. The policy framework includes guidelines and considerations in formulating and using persistent identifiers; instances of policy documents as exemplars; and documentation of community requirements for identifiers. To make such a framework independent of specific technologies (and able to survive changes in technology), it was also necessary to model identifiers and identifier services, independently of technology. The PILIN modelling includes an ontology, a glossary, and a Service Usage Model. The technology-independent modelling means that PILIN is agnostic as to the choice of identifier scheme: as a result, PILIN used a number of identifier technologies for implementation work, and the Handle System® in particular to develop identifier services. PILIN also produced documentation on how to use HTTP URIs persistently. [2] The PILIN project was cross-community: it was intended to address the needs of the research, library, and learning domains. As the project gathered requirements from various stakeholders for how persistent identifiers should be managed and used, several questions kept coming up on how to create and manage identifiers for persistence. Addressing these questions, we came to realise, leads to a policy checklist against which identifier solutions can be benchmarked. The recurring questions about persistent identifiers were:
Of these questions, the first forced us to do some detailed modelling of identifiers and their qualities, so that persistence could be spelled out properly. The modelling exercise has been extensive, but we summarise our thinking about persistence in particular below. The last question does not have one right answer, and depends on how the other questions are answered and how the identifiers will interact with other computer systems. The middle three questions, however, go to the heart of planning for persistence, and to address them the project came up with a "six-step information and service modelling program", which we describe here. [3] The six-step program is defined at a high level, and needs to be filled out with domain-specific details. It can be thought of as a checklist for thinking to ensure that Q2, Q3 and Q4 are addressed for the given enterprise. Q3 depends on engagement with the resource provider and Q4 on engagement with the resource manager; Q2 engages with the resource user, clarifying what undertaking is being made to them. We start by addressing Q3 and Q4; answering Q2 depends on our answer to Q1, and we consider both together at the end.
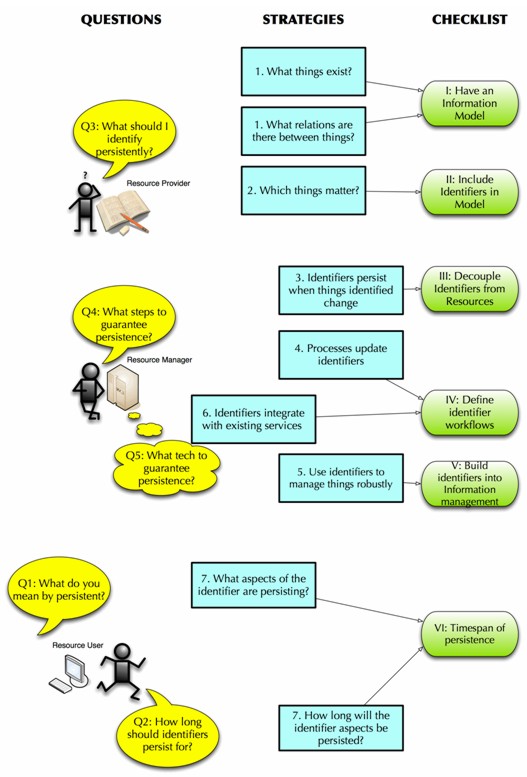
What Should I Identify Persistently?The persistence of identifiers, which is what we discuss here, is a separate issue from the persistence of the resources they identify. In discussing persistent identifiers, we are assuming in what follows that the resources they identify are prioritised to remain available; the persistent identifiers ensure that they remain accessible as well. Plans to ensure that resources remain available (such as Data Management Plans discussed below) need to factor in persistent identifier considerations. Persistent identifiers, however, do not "just happen". Persistence involves a guarantee to the user that the identifiers will be kept up to date, and this requires an ongoing commitment of resources. For that guarantee to be meaningful, identifier managers cannot undertake to identify everything in their domain: they need to decide on the resources for which they will provide persistent identifiers. Our recommendation is to prioritise resources that will be accessed, cited, described, managed, or otherwise engaged with by the user community, over the timespan of persistence. This priority cannot be set by the identifier manager in isolation: it needs the involvement of the user community (often represented by the resource provider), who will have a good idea about how the resource will be used or referred to. It also needs the involvement of the resource manager, who will keep the resource accessible and in good order; they will determine for how long the guarantee is realistic, and what the technical constraints are on maintaining the resource (at least while it is online). Prioritising what to identify, in turn, critically depends on information modelling of the domain. Persistent identifiers can be associated not only with concrete objects such as digital files, but also more abstract concepts, that can be used for discovery and management of resources. Such abstract concepts include families of resources (such as the Works, Expressions and Manifestations modelled under FRBR); [4] aggregations; disaggregations; and transformations of resources. Modelling is needed to define and manage those abstractions. Resource providers and resource managers need to be informed of what abstractions are possible, and how they should be translated to concrete representations. So the question "What Should I Identify Persistently?", maps to two strategies, which depend on engaging the Resource Provider:
These strategies correspond to the two first steps of our policy checklist:
An explicit information model allows the distinction to be made between concrete and abstract entities, as well as representing the relations between them – e.g., version, copy, transformation, choice of granularity. What steps should I take to guarantee persistence?The community of users expects that persistent identifiers will provide persistent discovery and access to resources. But beyond that, there is also an information management concern: the resources being identified should be managed in a way that will reduce the impact on identifier persistence. For example, moving a resource's digital location, in order to guarantee its persistence, should result in a corresponding update of the identifier, to keep the identifier persistent. But it would be better if the digital location of the resource were moved less frequently – and if not every update of the resource had to force an update to the identifier. A clear way to prevent disruption is to ensure that identifier management is integrated into information management. If information management uses one ("local") identifier to interact with the resource, but identifier management uses a different identifier for persistence, then information management and identifier management are decoupled. This DNS-like indirection strategy is commonplace: URLs or record keys are typically used to manipulate resources directly, as local identifiers. These are strictly speaking access keys (locators) for obtaining resources on local systems. They can be used as identifiers, because they still associate a name (the access key) with a resource; but they are only as persistent as the storage arrangements they reflect. On the other hand, persistent identifiers (including Handles, PURLs, and "Cool" URIs) [5] are used to refer to resources more abstractly, and provide indirection to the local identifiers. This decoupling forces a maintenance dependency between identifier management and information management: if the local identifier changes, the indirection must be updated for the persistent identifier. The ability to perform such updates makes persistent identification possible, and independent of technologies. Failing to actually perform the updates compromises persistent identification, and defeats the purpose of indirection. As already noted, guaranteeing updates is to a large extent a policy issue. But the workflows for managing resources, as determined by those policies, should maintain a loose coupling between local and persistent identifiers: any workflow leading to a change of local identifier must force an immediate update to the indirection of the persistent identifier. Where possible, that update should be automated, rather than manual. Moreover, identifier workflows need to be timed so that persistent identifiers are created when it is least disruptive. If a resolvable persistent identifier is branded onto an object (for example, if a web page has a URI identifying it embedded in the web page), then the identifier has to be created before the object is – but the identifier can only resolve to the object once the object is created, complete with the branded identifier! The typical workaround in this case is to create the identifier beforehand with a dummy resolution or no resolution, and then to update the identifier once the object is updated and stored digitally – but before either the identifier or the object are published. (By "published", we mean that the resource is made available externally, beyond a "curation boundary" – i.e., outside of the group of people working on creating and preparing that resource.) [6] The processes for managing resources should themselves be persistent where possible, and not be bound to particular technologies or local identifiers. The more information management relies on persistent identifiers, the less risk there is that information management will be affected by changes in the local identifier. There is also less risk of the local identifier being used in preference to the persistent identifier – a practice that can ultimately leak outside the "curation boundary" and undermine the persistent identifier framework. To give an example: if version management uses local identifiers instead of persistent identifiers, the local identifier may be circulated to external users, to give them access to a specific version. If the local identifier is changed (perhaps because a new version with a different identifier has been created), the user now has a broken link. If the persistent identifier is used internally for version management to begin with (possibly in conjunction with a version parameter), there is much less risk of two competing identifiers being released externally. So the question "What steps should I take to guarantee persistence?" maps to three strategies, which depend on engaging the Resource Manager:
These strategies correspond to the next three steps in our policy checklist:
Avoiding a tight coupling between resources and identifiers allows the flexibility of indirection, and makes persistence possible despite changes in local identifiers. Well-integrated identifier management restores the looser coupling between resources and identifiers, so that the indirection does not end up broken when the local identifier does change. And leveraging identifiers in information management minimises the dependence on non-persistent identifiers. Persistent identifiers become an added information layer, through which resources are accessed and cited with reliability and accountability. What technologies should I use to guarantee persistence?Relying on a particular technology to deliver persistence in identifiers misses the point of persistence, in a sense: the identifiers should persist through changes in identifier technology, just like any other technological change. And as has often been argued, it is good policy – rather than particular technologies – that establishes persistence. The requirement placed on identifier technologies is merely that they can help realise the strategies just mentioned. For this to happen, it is critical that the identifier technology used is interoperable with the services already used in the enterprise. If that integration does not happen, the persistent identifiers will be kept in a silo separate from the day-to-day management of resources, meaning that they cannot be leveraged for improved information management. Without integration, we are back where we started: the identifiers will not be kept in sync with how the objects are managed, so they will fail to persist. While persistent identifiers need to become an added information layer, that layer is useless unless it interacts effectively with existing information management systems and processes. This leads to a new strategy:
However, this strategy is already addressed in our policy checklist item IV from above:
The workflows do not just integrate identifiers in future information management; they need to integrate them into current processes. That means the existing services used to access resources – that will quite likely remain in use for some time. This also means that, if the persistent identifiers are to support a separate information layer, there must be enough identifier services in place to deal with all information management requirements. Key information management services that should use persistent identifiers include
HTTP-REST is a good example of a URI-driven approach to providing such services: resource creation, update, and deletion, as well as reading/accessing resources, are all mediated through HTTP operations on URIs for the resources. [7] How long should identifiers persist?Once persistent identifiers are released to end users, there is a clear undertaking that the identifier will in fact persist for some time. The question we were asked most often by our stakeholders was, "how long should that undertaking be for?" While we initially answered the question glibly ("Say 25 years"), it became apparent that any enterprise would have its own preferred timespan, which would depend on both business-specific and external factors. So coming up with One Preferred Timespan, like "25 years", would be meaningless. Instead, the concern over persistence is that the identifier is guaranteed to perform as expected, over however long a period makes sense for the enterprise. We define persistence accordingly as the guarantee that the identifier will be maintained over a defined and discoverable timespan – be it 25 years or 25 days. The end user can find out how long the guarantee is expected to last, and can rely on the identifier to remain operational over that timespan; depending on who they are and what they are doing, the timespan does not have to be of archival length, but it must be uninterrupted. Because persistence involves an undertaking from the provider to the end user, the timespan of that undertaking should be made explicit. Consumers of persistent identifiers need to plan for a time when the identifier will no longer perform as expected. Identifier providers may well intend to persist the identifier indefinitely, but when others depend on the identifier persistence, hard limits are preferable to good intentions. To the end user, persistence is an expectation of trustworthiness; identifier providers must establish – and circumscribe – that trust. This area has been substantially explored in the work of John Kunze, and particularly the ?? operator in the ARK persistent identifier scheme [8]. What do you mean by "persistent"?If persistence involves trust, it is a trust that something will happen or that something will not happen. Just declaring that an identifier will persist does not help us work out what exactly is expected to happen. Several things can go wrong with an identifier over time, and these things need to be considered separately. To better understand persistence, we model it as follows:
The common understanding of persistence is persistence of retrievability. This has resulted from the longstanding problem of URIs breaking (no longer allowing retrieval), when the resource pointed to is moved or no longer maintained. But identifiers can be maintained after the resources they pointed to are no longer online; in fact this is essential for archival purposes. In that case, we would expect resolution of the identifier to a metadata record, preserving the association of the identifier with the resource (the arXiv withdrawn paper described above is an illustration of this possibility.) In terms of the long-term lifecycle of identifiers, persistence of resolution is more critical than persistence of retrievability; maintaining such metadata makes for more robust information management overall. So any guarantees of persistence need to be tied down, not only as to the period of the guarantee, but also what aspect of the identifier is being guaranteed. In particular, the longstanding conflation between resolving an identifier and retrieving a resource needs to be separated if the guarantee is to have any meaning after the resource is no longer accessible. So the question "How Long Should Identifiers Persist?" and its associated question "What Do You Mean By 'Persistent'?" map to the following strategies:
Concretely, this corresponds to the final step in our policy checklist:
The emergence recently of Data Management Plans, especially in research, provides a formal, contractual framework for the engagement between data managers and data users. We anticipate that identifier persistence will be an integral part of that engagement [9]. Summary & ChecklistWe have developed a six-point policy checklist for integrating persistent identifiers into information management. It is summarised as follows: With Resource Provider:
With Resource Manager:
With Resource User:
These policies are based on strategies, which in turn are based on key questions about identifiers. A relationship between the policies, strategies and key questions is laid out below:
AcknowledgementsThis article reports on work done under the PILIN project and the PILIN ANDS Transition Project. PILIN was funded by the Australian Commonwealth Department of Education, Science and Training (DEST) under the Systemic Infrastructure Initiative (SII) as part of the Commonwealth Government's Backing Australia's Ability – An Innovation Action Plan for the Future (BAA). The PILIN ANDS Transition Project was funded by the Australian government as part of the National Collaborative Research Infrastructure Strategy (NCRIS), as part of the transition to the Australian National Data Service (ANDS). The authors wish to acknowledge the support and feedback of the rest of the PILIN team. Notes & References[1] PILIN Project: <http://www.linkaffiliates.net.au/pilin2/>. PILIN software outputs: <http://www.linkaffiliates.net.au/pilin2/outputs_software.html>. [2] On the Handle System®, refer to <http://www.handle.net>. The PILIN documentation on using HTTP URIs persistently is PILIN Project 2007. Using URLs as Persistent Identifiers. <http://resolver.net.au/hdl/102.100.272/DMGVQKNQH>. All PILIN project outputs are available under <http://www.linkaffiliates.net.au/pilin2/outputs.html>. [3] The background thinking to the plan is given in more detail in PILIN Project 2007. Persistence of Identifiers Guidelines <http://resolver.net.au/hdl/102.100.272/V89DC0DQH>. [4] IFLA Study Group. 1998. Functional Requirements for Bibliographic Records, Final Report. <http://www.ifla.org/VII/s13/frbr/frbr.pdf>, §3.2: Entities. [5] PURL (Persistent Uniform Resource Locator): <http://purl.org>. "Cool URIs": Berners-Lee, Tim. 1998. Cool URIs don't change. <http://www.w3.org/Provider/Style/URI>. [6] On the "curation boundary", see Treloar, Andrew, Groenewegen, David & Harboe-Lee, Cathrine. 2007. The Data Curation Continuum: Managing Data Objects in Institutional Repositories. D-Lib Magazine 13: 9/10. <doi:10.1045/september2007-treloar>. [7] For the original definition of REST, see Chapter 5 of Fielding, Roy T. 2000. Architectural Styles and the Design of Network-based Software Architecture. Ph.D. Dissertation, University of California, Irvine. <http://www.ics.uci.edu/~fielding/pubs/dissertation/top.htm>. [8] Kunze, John A. & Rogers, Richard P.C. 2008 [2001]. The ARK Identifier Scheme. <http://tools.ietf.org/html/draft-kunze-ark-15>, and Kunze, John A. 2003. Towards Electronic Persistence Using ARK Identifiers. Proceedings of the 3rd ECDL Workshop on Web Archives, August 2003.<http://www.cdlib.org/inside/diglib/ark/arkcdl.pdf>.
[9] On data management plans, see e.g., Chapter 5 of: Fitzgerald, Anne, Pappalardo, Kylie & Austin, Anthony. 2008. Practical Data Management: A legal and policy guide. Legal Framework for e-Research Project & Open Access to Knowledge Law Project, Queensland University of Technology. <http://eprints.qut.edu.au/14923/1/ (On 19 January 2009, the Digital Object Identifier shown at the bottom of the article web page was corrected to read: doi:january2009-nicholas.) Copyright © 2009 Univeristy of Southern Queensland |
|||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/january2009-nicholas
|