 |
T A B L E O F C O N T E N T S
S E P T E M B E R / O C T O B E R 2 0 1 4
Volume 20, Number 9/10
10.1045/september2014-contents
ISSN: 1082-9873
E D I T O R I A L
Traditional Roles
Editorial by Laurence Lannom, Corporation for National Research Initiatives
A R T I C L E S
The HZSK Repository: Implementation, Features, and Use Cases of a Repository for Spoken Language Corpora
Article by Daniel Jettka and Daniel Stein, Universität Hamburg, Germany
Abstract: This article describes the process of the conception and implementation of a digital repository which is based on the software framework Fedora, Islandora, and Drupal. The main data type that is to be organized, maintained, and distributed with the repository is spoken language corpora, with a focus on multilingualism, which means that the content of the repository may be of special interest to researchers of linguistic, translational and socio-psychological studies. We concentrate on the technical requirements that had to be fulfilled with regard to our status as an official center of the Common Language Resource Infrastructure Network (CLARIN), a pan-European initiative in the context of the Digital Humanities. In particular, the requirements include preparation of information for the description of resources providing a source for metadata harvesting, registration of persistent identifiers for the long-term access and citeability of resources, implementation of a federated content search module, dealing with privacy restrictions, and the possibility to provide a single sign-on method via Shibboleth. The HZSK Repository ultimately passed two assessment processes: the assessment of the Data Seal of Approval, and a CLARIN-internal assessment procedure.
Exposing Data From an Open Access Repository for Economics As Linked Data
Article by Atif Latif, Timo Borst and Klaus Tochtermann, ZBW — German National Library of Economics
Abstract: This article describes an approach to publishing metadata on the Semantic Web from an Open Access repository to foster interoperability with distributed data. The article describes two significant movements which led to the application of Semantic Web principles to repository content: the development of Open Access repositories and software systems implementing them, and the Semantic Web movement, especially within libraries and related institutions. The article provides both conceptual and practical insight into the process of converting a legacy relational dataset to machine understandable semantic statements, a.k.a. 'triplification', and gives an overview of current software frameworks that can fulfill this goal. One important outcome of this effort and proof-of-concept is that a repository's content can be straightforwardly published as Linked Open Data. Another result is the ability to link to valuable external datasets, enabling a repository's data to become more contextualized and 'meaningful'. Finally, SPARQL querying shows the potential of triplifications to surpass the querying and use of local data. From both practical and software engineering points of view, the article describes an approach towards publishing a repository's content as Linked Open Data, which is of interest to librarians, repository managers and software developers who work for libraries.
The Role of a Digital Repository in a Library-Managed Open Access Fund Program
Article by Heidi Zuniga, University of Colorado Anschutz Medical Campus
Abstract: Developing partnerships between various library and campus programs or initiatives can be beneficial in today's digital information climate. This article discusses the development of an open access author fund at the University of Colorado Anschutz Medical Campus Health Sciences Library and the subsequent partnership with the library's digital repository, in which the articles supported by the fund were added to the repository. It also details the workflow used for tasks such as checking into copyright issues, issuing deposit agreements and handling paperwork and correspondences as part of the repository ingest process. The partnership resulted in benefits for the fund program, the repository, and the fund recipients.
Library of Congress Recommended Format Specifications: Encouraging Preservation Without Discouraging Creation
Article by Theron Westervelt, Library of Congress
Abstract: The Library of Congress has a fundamental commitment to acquiring, preserving and making accessible in the long term the creative output of the nation and the world. The Library has devised the Recommended Format Specifications to enable it to identify what formats will most easily lend themselves to preservation and long-term access, especially with regard to digital formats. The Library has done this to provide guidance to its staff in their work of acquiring content for its collection, but also seeks to share this with other stakeholders, from the creative community to vendors to other libraries, each of which has a need and interest in preservation and access. To ensure ongoing accuracy and relevancy, the Library of Congress will be reviewing and revising the specifications on an annual basis and welcomes feedback and input from all interested parties.
Selecting Newspaper Titles for Digitization at the Digital Library of Georgia
Article by Donnie Summerlin, Digital Library of Georgia
Abstract: Newspapers have been a significant target for digitization over the last decade, and libraries, archives, and other cultural institutions must decide how best to utilize their limited funds to digitize a select number of newspaper titles for public consumption. This case study examines the Digital Library of Georgia's newspaper digitization selection process and how it incorporates national standards with its own project-specific criteria. The article includes a discussion of the roles played by user demand, content significance, funding, copyright, optical character recognition, and microfilm holdings in the decision making process, with the ultimate goal of creating highly used, well-regarded, and cost effective online newspaper archives.
Testing the HathiTrust Copyright Search Protocol in Germany: A Pilot Project on Procedures and Resources
Article by Rebecca Behnk, Karina Georgi, Regine Granzow and Lovis Atze, Humboldt University, Berlin
Abstract: There are more than 11 million volumes in the HathiTrust Digital Library. The largest group of non-English books — almost 600,000 titles — is in German. For most of these German works, the copyright status is unknown, which means that only the catalogue records can be made publicly available in the digital library, even if a work has passed into the public domain in Germany and could be made available as a full-text scan. To begin to address this problem, a small pilot project was undertaken by a group of students in the Berlin School of Library and Information Science at Humboldt University (the authors), to investigate potential resources for determination of author death dates for HathiTrust books published in Germany. The authors provide observations on the usefulness of certain resources identified with "diligent search" in recent changes to German copyright law passed in response to a 2012 European Union directive on orphan works. They also discuss additional resources not mentioned in the law that might be useful in conducting such searches. Furthermore, they make recommendations for improvement of the HathiTrust Digital Library search protocol for works published outside the United States, particularly in languages other than English. The project findings will be of interest to policy makers, publishers, librarians and others engaged in efforts to identify digitized books that can be made publicly available in accordance with national and international copyright laws and regulations.
Connecting Systems for Better Services Around Special Collections
Article by Saskia van Bergen, Leiden University Library, the Netherlands
Abstract: During the last few years, several projects to improve physical and digital access to special collections have been undertaken by Leiden University Libraries in the Netherlands. These heritage collections include manuscripts, printed books, archives, maps, atlases, prints, drawings and photographs, from the Western and non-Western worlds, and they are of both national and international importance. The projects were undertaken to meet two key requirements: providing better and faster service for customers when using the collections, and creating a more efficient workflow for library staff. This article describes the infrastructure behind these projects, and the impact of the projects on users to date.
Cultural Computing at Literature Scale: Encoding the Cultural Knowledge of Tens of Billions of Words of Academic Literature
Article by Kalev H. Leetaru, Georgetown University; Timothy Perkins and Chris Rewerts, U.S. Army Corps of Engineers
Abstract: The vast array of academic literature published by the humanities and social sciences disciplines codifies our collective scholarly understanding of how societies function and the beliefs, ideals, and ethnic, religious, and tribal contexts that undergird global societal behavior, yet this material has been largely absent from the recent computational revolution in the study of culture. Applying temporal, geographic, thematic, and citation algorithms to an archive of more than 21 billion words spanning 1.5 million publications from 7 collections, including the entire contents of JSTOR, DTIC, CORE, CiteSeerX, and the Internet Archive's 1.6 billion PDFs, academic literature is seen to offer a powerful new lens onto global culture. Four case studies demonstrate using this archive to map the Nuer ethnic group and identify its top experts, map the literature on food and water security, explore the thematic underpinnings of the Rwandan genocide, and construct a network over the ethnic groups of the world as seen through the combined academic literature of the past half century.
N E W S & E V E N T S
In Brief: Short Items of Current Awareness
In the News: Recent Press Releases and Announcements
Clips & Pointers: Documents, Deadlines, Calls for Participation
Meetings, Conferences, Workshops: Calendar of Activities Associated with Digital Libraries Research and Technologies
|
|
F E A T U R E D D I G I T A L
C O L L E C T I O N
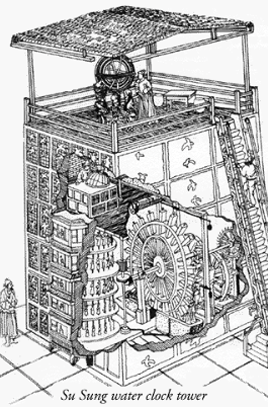
Su Sung water clock tower.
[Courtesy of National Institute of Standards and Technology (NIST).]
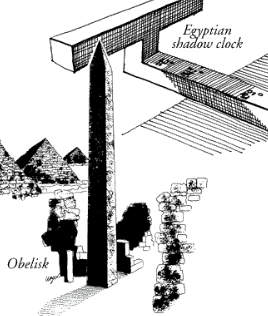
Egyptian shadow clock.
[Courtesy of National Institute of Standards and Technology (NIST).]
"A Walk Through Time" briefly summarizes how people have measured the passage of time, from ancient calendars and early mechanical clocks to atomic clocks providing the most precise absolute measurement of any kind. The exhibit includes examples of how the evolution of timekeeping has impacted technology and society.
For the vast majority of human history, the rotation of the earth — and the apparent motion of the stars, sun and moon across the sky — provided timekeeping far more accurately than the best clockmakers could ever hope to produce. That changed in 1949 with the invention of the world's first atomic clock, using fundamental properties of atoms to allow human-made clocks to surpass the accuracy of astronomical time.
Atomic timekeeping has continued to improve dramatically in the more than six decades since the first atomic clock. Atomic time is now a critical part of our modern technology infrastructure that almost everyone uses every day for modern telecommunications, electric power distribution, GPS (now in nearly every smart phone and cell phone), and many other applications. But most people don't realize that atomic clocks are enabling these technologies.
The "Walk Through Time" website tries to briefly summarize how timekeeping and technology have evolved through history.
D - L I B E D I T O R I A L S T A F F
Laurence Lannom, Editor-in-Chief
Allison Powell, Associate Editor
Catherine Rey, Managing Editor
Bonita Wilson, Contributing Editor
|