 |
D-Lib Magazine
September/October 2011
Volume 17, Number 9/10
Table of Contents
A New Way to Find: Testing the Use of Clustering Topics in Digital Libraries
|
Kat Hagedorn
University of Michigan
|
Michael Kargela
University of Michigan
|
Youn Noh
Yale University
|
David Newman
University of California-Irvine
|
Point of contact for this article: Kat Hagedorn, khage@umich.edu
doi:10.1045/september2011-hagedorn
Printer-friendly Version
Abstract
Using a topic modeling algorithm to find relevant materials in a large corpus of textual items is not new; however, to date there has been little investigation into its usefulness to end-users. This article describes two methods we used to research this issue. In both methods, we used an instance of HathiTrust containing a snapshot of art, architecture and art history records from early 2010, that was populated with navigable terms generated using the topic modeling algorithm. In the first method, we created an unmoderated environment in which people navigated this instance on their own without supervision. In the second method, we talked to expert users as they navigated this same HathiTrust instance. Our unmoderated testing environment resulted in some conflicting results (use of topic facets was high, but satisfaction rating was somewhat low), while our one-on-one sessions with expert users give us reason to believe that topics and other subject terms (LCSH) are best used in conjunction with each other. This is a possibility we are interested in researching further.
Introduction
Encouraging the use of resources appropriate to the task is the job of every reference librarian. What if it were easier to do this online because the description of the resources themselves could automatically be extracted and placed in context for both the librarian and the end-user? Semantic extraction and natural language processing are, by this point, standard methods for pinpointing relevant materials in research tools [Halskov & Barrière (2008), Moens et al. (2000)], as well as in the library world [Hearst (2006), Krowne & Halbert (2005)], however the investigation of its utility within digital libraries is still being explored [Mimno & McCallum (2007)]. In particular, there has been little work on evaluating the end result of automated extraction, with end-users, in a specific context.
Topic modeling is a decade-old tool that extracts underlying topics from descriptions of textual documents. It can do this with the full-text of documents, and has been designed to work with descriptive metadata as well. The topic modeling algorithm we are using has been proven to be accurate and useful when extracting topics from very short descriptions of documents, or short documents themselves [Hagedorn et al. (2007), Newman & Block (2006)].
As we were investigating opportunities to test topic modeling in digital libraries, the HathiTrust Digital Library was beginning to gain momentum. HathiTrust suited our investigation perfectly — persistent access to an aggregation of digitized materials that were robustly described by MARC metadata. In particular, HathiTrust had recently made the decision to use VuFind as the catalog for discovery and access, which had an interface designed for use of facets to limit searches. We were able to develop a separate interface to HathiTrust (since one of the grant team members was a HathiTrust developer) that could incorporate our topic modeled terms as facets.
As we used the algorithm to create the topics themselves and as we built the special HathiTrust instance, we developed the end-user studies that would test how well the topics worked for the end-user in helping them find new and relevant resources. The studies were designed in two parts: a larger, hands-off, unmoderated study, and a much smaller, face-to-face, moderated study. Both studies were designed to test different aspects of topic modeling, and ultimately, each was successful in its own way.
How Topics Were Created
The topic model algorithm works by learning "topics" from collections of text documents. Specifically, the algorithm looks for patterns of terms that tend to occur together in documents. For example, finding co-occurrences of "oil" and "canvas," or "ink" and "scroll" is unsurprising given the subject matter of the HathiTrust instance we used. In general, the descriptive metadata (records) associated with each volume in the instance includes such fields as title, subject and description. This metadata tends to be highly variable in length and content that is useful for describing what the volume is "about." After removal of stopwords (such as "the" and "and"), records contain on average only 25 useful words. To make up for this limited per-record amount of textual description, we learned topics for this collection by running the algorithm against the full text of 27,710 digitized volumes in the HathiTrust instance. See below for more particulars about the collection.
Topics learned by the algorithm are displayed as a list of words ordered by importance to the topic. Typically, the top 10 terms in a topic are displayed, and that is sufficient to convey the gist of that topic. Here are three randomly selected example topics learned from our collection:
- mural artist painting figure life relief school paint theme mosaic...
- gold silver ivory metal copper inlaid leaf gilded red precious...
- frescoes fresco saint angel altarpiece figure altar church scene chapel...
The ellipsis at the end of the topic indicates that the list of words continues, but is arbitrarily cut off (e.g., after the top 10 terms). Note that the topics do not necessarily represent thematic concepts or word groupings that humans may create. Instead, they are showing which terms tend to co-occur together in metadata records. Note also that a term (e.g., "figure") can appear in multiple topics. Like a cataloger would, the algorithm assigns a small number (1 to 4 in this case) of relevant topics to each record (volume).
The topics in their native form (as lists of terms) are not particularly useful in user interfaces. We addressed this by creating a short label for each topic. Labels are often best created by subject matter experts who can suggest representative words or phrases. While there is some information lost in this labeling process, it is a practical approach to displaying learned topics in an interface. In this case, three students from Yale, who were knowledgeable in the subject area of the collection, each independently labeled all our topics in their native form. Afterwards, one more student performed a final review of the three labels for each topic, and chose one or created a new label. The grant team members reviewed all the students' labels prior to using them in our interfaces. For the rest of this article, we will call these labels "topics."
Methods for the Unmoderated Study
Three hundred and six people took the unmoderated study that we ran at both the University of Michigan and Yale University in June 2010. Of these, there were 253 completed tests at Michigan and 53 completed tests at Yale. The majority of the participants were undergraduate students: 140 undergraduates, 80 graduate students, 68 unknown (primarily from Yale which didn't gather status data), 17 university staff and 1 alumnus. Each participant who fully completed or completed a significant portion of the study was given a $15 Amazon gift certificate.
The participants used our special instance of the HathiTrust website, which we built between January and February of 2010. This instance contained a snapshot of HathiTrust at the time and included 27,710 digitized volumes corresponding to 18,881 records from the "N" (fine arts) Library of Congress Subject Heading (LCSH) classification that were primarily in the English language, and that linked to both in-copyright and full-view-access volumes. (We suppressed that linkage for the purposes of this study.) A search of the records always included associated topics. For instance, if the algorithm assigned the topics "Christianity," "painting," "Indian architecture," and "beauty" to a volume, a search including any of these terms would bring up that record. The topics were included in the left-hand column of the HathiTrust instance, with the other options for narrowing the search. We will call these narrowing options "facets" throughout this study, and the specific facet for narrowing by topic we will call "topic facets."
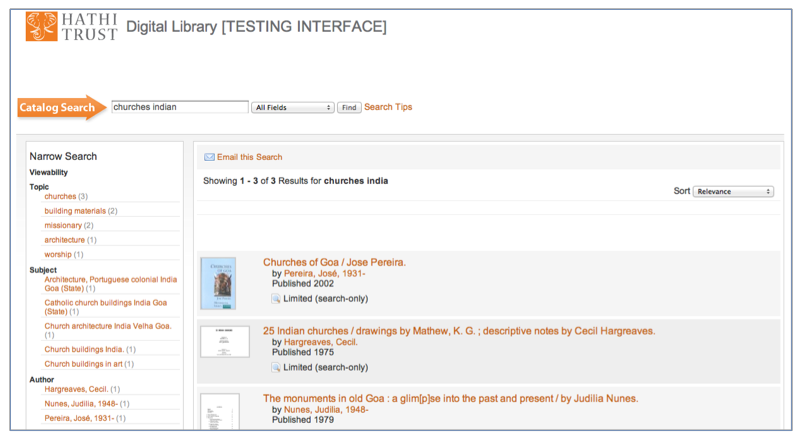 Figure 1: HathiTrust Digital Library Testing Interface
Figure 1: HathiTrust Digital Library Testing Interface
We used Morae software to capture video of the unmoderated study interactions (not a video of the participant, but a video of all their movements on the computer screen). Since there would be no person available to ask or answer questions from the study participant, we wanted to use a product that could record and calculate the participants' answers automatically, as well as provide a recorded video file of the entire interaction. Each institution built additional technical pieces so that the participantS could navigate to, and access the test.
Participants were required to log on to the machine using their institutional ID, sign a consent form, read the instructions and perform the tasks. They were given 3 tasks, each of which had a series of questions to be answered. They searched the HathiTrust instance to find results that they felt answered the questions.
The tasks and questions were designed to utilize the unmoderated testing environment by allowing the participant to freely find results and records that suited the task, while at the same time requiring them to describe the results and records they found by answering follow-up questions.
In the first task we asked the participants to perform a general search for urban planning, as if they were part of an introductory architecture class. We asked the participants if they were satisfied with both the results they found, and the book they chose that seemed the best fit (on a 5-point Likert scale). For task 2, we asked them to do a different search in the same subject area and this time use the facets column to refine their search. We asked if they found the facets column useful. For the final task, we asked them to specifically focus on the topic facet. The following is the final task as it was asked in the test. (Full testing script is available upon request.)
|
Task 3: At the end of the semester, your professor asks for a final overview — the architecture of religious buildings. Search for architecture first.
You'd like to dive a bit further into architecture to just view a list of items related to religious buildings. Use the "Topic" section of the "Narrow Search" column on the left to do this.
Then, from what you found, click the title for a book that seems like the best fit. (You will not have access to the book itself, just a record describing the book, so use your best judgement.)
- Were you satisfied with the book you chose? (Scale 1-5)
- Were you satisfied with the results you found on architecture and religious buildings? (Scale 1-5)
- Did you find the "Topics" listed in the "Narrow Search" column on the left useful in refining your results? (Scale 1-5)
- If you were to use this website again, would you use the "Topics" in the left column to help you refine your search? ("Yes", "No", "Not Sure")
- Is there anything about this website that you would change? (Comment box)
|
For each task, the following data was analyzed: the final search term and search filter (drop-down) used, the total number of facets selected, the number of topic facets selected, and the ranking of the record selected within the search results (e.g., record #2 in the list of 20).
Results of the Unmoderated Study
With such a large number of results, we chose to focus on those that would be most interesting when compiled and when compared with each other.
Compiled results
When participants were asked to use any facet, 73% of chosen facets (216 out of 296) were topic facets (Task 2). When they were asked to look specifically at topic facets, unsurprisingly, this increased — 83% of chosen facets (256 out of 308) were topic facets (Task 3). It's worth noting that even when participants were asked to use topic facets, 53 out of 240 (22%) didn't use them. When they were asked to look at all facets, the same percentage (56 out of 252) did not use any topic facets.
Even though topic facets were heavily used across the last two tasks, satisfaction rating dropped when participants were asked to look specifically at the topics. See Table 1. (Positive responses were calculated as participants choosing either a 1 or a 2 on the Likert scale for satisfaction.)
Task 2 questions
(when asked to look at all facets) |
Task 2 satisfaction range |
Task 3 questions
(when asked to look specifically at topic facets) |
Task 3 satisfaction range |
| Were you satisfied with the book you chose? |
77% satisfied |
Were you satisfied with the book you chose? |
50% satisfied |
| Were you satisfied with the results you found? |
71% satisfied |
Were you satisfied with the book you chose? |
35% satisfied |
| Did you find the "Narrow Search" column on the left useful in refining your results? |
78% satisfied |
Did you find the "Topics" listed in the "Narrow Search" column on the left useful in refining your results? |
44% satisfied |
Table 1: Satisfaction percentages across Task 2 and Task 3
As a final question, we asked participants if they would use the topic facets again in this interface, and a majority, 180 out of 240 (75%), said "yes."
Correlated results
For correlation between two variables, our first step was to determine if the Michigan and Yale data could be combined for further analysis. We performed both Chi-square and Fisher's Exact tests for all three tasks. To determine if the data for both schools could be combined for further analysis, we compared the mean satisfaction ratings with the total number of facets selected and the mean satisfaction ratings with the number of topic facets selected. Statistically significant differences between the schools were found for Task 3 (p < .01) for both tests. The populations were kept separate in the analysis for that task. We were also not able to differentiate the data by gender, as that was data not gathered at Yale or Michigan.
We ran Spearman Rank Correlation, and we also ran One-way ANOVA tests to determine if there were statistically significant variances between the variables we were correlating. Of the three tasks, the following were statistically significant comparisons:
- Satisfaction with the subject's chosen book when all facets are selected (Tasks 2 & 3; Table 2)
- Satisfaction with the subject's chosen book when just topic facets are selected (Task 3; Table 3)
- Satisfaction with the usefulness of the facets column when just topic facets are selected (Task 2; Table 4)
- Satisfaction with search results when all facets are selected (Task 3; Figure 1)
- Satisfaction with search results when just topic facets are selected (Task 3; Figure 1)
| Total Facets Selected |
Average Satisfaction Score Task 2 |
Average Satisfaction Score Task 3 |
| 0 |
2.034483 |
2.116279 |
| 1 |
1.865854 |
2.666667 |
| 2 |
2.125000 |
2.673469 |
| 3 |
2.444444 |
3.136364 |
| 4 |
3.000000 |
3.166667 |
| 5 |
3.000000 |
n/a |
Table 2: Task 2 and Task 3, all facets selected, satisfaction with the subject's chosen book.
(NB: 1=high satisfaction, 5=low satisfaction)
| Topic Facets Selected |
Average Satisfaction Score Task 3 |
| 0 |
2.264151 |
| 1 |
2.651515 |
| 2 |
2.714286 |
| 3 |
3.416667 |
| 4 |
5.000000 |
| 5 |
n/a |
Table 3: Task 3, only topic facets selected, satisfaction with the subject's chosen book.
(NB: 1=high satisfaction, 5=low satisfaction)
| Topic Facets Selected |
Average Satisfaction Score Task 2 |
| 0 |
2.410714 |
| 1 |
1.704545 |
| 2 |
1.800000 |
Table 4: Task 2, only topic facets selected, satisfaction with the usefulness of the "Narrow Search" column.
(NB: 1=high satisfaction, 5=low satisfaction)
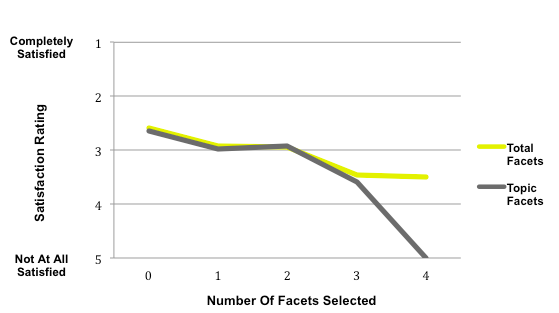 Figure 2: Task 3, all facets and topic facets, satisfaction with search results.
Figure 2: Task 3, all facets and topic facets, satisfaction with search results.
(One person selected 4 facets during one search and we counted this as an outlier.)
Methods for the Moderated Study
Because the results of the unmoderated study were inconclusive, we were keen to try a different methodology that would help us either replicate these results or discover variations on them. Since we had been unable to discuss with participants the choices they made during the original study, we felt that moderated, face-to-face testing was an obvious next step. Also, it was clear that the unmoderated study, due to its test design, had focused in large part on the use of the facets themselves and to a small extent on the content of the created topics themselves.
We specifically sent our request for participation in a one-hour session to the Art & Design and Architecture & Urban Planning schools at the University of Michigan, hoping to find participants with expertise in the areas of art, architecture and art history. We also created a pre-study questionnaire to gauge a participant's expertise. We offered a robust-sized incentive, in the hopes of gathering participants who would be very knowledgeable in general about their field of study, and who also had a specific focus within that field. The result was 8 participants from these schools: 3 undergraduates, 1 graduate student, and 4 doctoral candidates. Each participant received a $50 Amazon gift certificate for completing the study.
These study participants used the very same instance of HathiTrust as the unmoderated study participants. During the sessions, we used a Smartpen (from Livescribe) to record both audio and pen strokes. This assisted us in returning to particular points of interest in the participants' commentaries.
We created a different testing script to use in the sessions. The study was designed specifically to uncover what users thought of the content of the topics themselves, and, in addition, how they felt topics compared to Library of Congress Subject Headings (LCSH), their closest counterpart in our interface. In the first task, we provided the participants with 2 search results that we had chosen in advance. In one, we had done a search for "portrait painting" and in the second we had done a search for "painting" and used the topic facets to limit to "portraiture." We then asked the participants questions about the quality of the two results, and if they would rank one better than the other.
In advance of the testing session, we asked participants to send us search terms from their particular field of study. In this way, we hoped to utilize the expertise of the participants while at the same time essentially randomizing the types of searches and facets they would use. Therefore, in tasks 2 and 3, we asked participants to comment on the quality and ranking of the results of a search performed using their own search terms. We also asked them to compare topic facets with LCSH facets in their search results, and within a record we asked them if they felt there were any topics missing (that should have been assigned). In task 2, they used paper copies of the search results and in task 3 they did their searches online in the HathiTrust instance. The following is the final task as it was asked in the test. (Full testing script is available upon request.)
|
Task 3b: For this task, we would like for you to find a record that interests you from your latest list of results [using their own search terms]. Please click on it. It can be from any page in the listing. Note that you won't be able to look at the book itself, just a summary of the book.
Now that you've selected a record, I'd like to ask you some questions about the Topics and Subjects that were assigned to it:
- Looking at the Topics assigned to the record you selected, do they appear to be appropriate? Please think out loud. Take your time looking things over.
- Looking at both the Topics and Subjects assigned to this record, do you feel that one set of words is superior to the other in describing the record? If so, why?
- Are there any Topics that you feel could be assigned to the record to improve its description/classification?
|
Results of the Moderated Study
Even though the moderated results were small comparably, we were able to gather some quantitative data.
| |
Quality of results |
Superiority / helpfulness of topics |
Appropriateness of topics in records |
| Task 1: review 2 sets of results (our search) |
8 of 8 (100%) = good |
n/a |
n/a |
| Task 2: review topics and LCSH in results (their search) |
5 of 8 (62.5%) = good
3 of 8 (37.5%) = poor |
4 of 8 (50%) = topics superior
3 of 8 (37.5%) = LCSH superior
1 of 8 (12.5%) = neither |
n/a |
| Task 3a: choose and review topic within results (their search) |
6 of 8 (75%) = good
2 of 8 (25%) = poor |
5 of 8 (62.5%) = topics helped
3 of 8 (37.5%) = topics didn't help |
n/a |
| Task 3b: review topics and LCSH in record (their search) |
n/a |
6 of 8 (75%) = LCSH superior
1 of 8 (12.5%) = topics superior
1 of 8 (12.5%) = neither
|
7 of 8 (87.5%) = topics appropriate
1 of 8 (12.5%) = topics not appropriate
|
Table 5: Quality, superiority, helpfulness and appropriateness of moderated study results
Participants' answers about ranking of search results were inconclusive. For Task 1, 5 of 8 (62.5%) didn't prefer either result set. For Task 3a, 3 of 8 (37.5%) thought the ranking was reasonable (i.e., they liked the order of the results), 3 of 8 (37.5%) thought the ranking was unreasonable and 2 of 8 (25%) had no opinion.
In the post-test questionnaire, we asked participants if they thought the use of topics in general brought them accurate results (i.e., the books chosen seemed to match the topics they chose). Of the 8, an overwhelming majority (7 of 8, or 87.5%), answered that they did.
Analysis of Both Studies
Unsurprisingly for the size of the study, analysis of the unmoderated study provides some contradictory conclusions:
- Usage of topic facets stayed high and constant throughout the study. (73-83%)
- Satisfaction rating went down after participants were asked to use the topic facets specifically, but stayed high when participants were asked to look at all facets. (Table 1: all satisfaction ratings, Table 2: book satisfaction, Table 4: facet column satisfaction)
- When participants accessed the facets, they seemed to be less satisfied choosing a facet than choosing no facet. Stated another way, they prefer not to use facets at all. (Table 2 and Table 3: book satisfaction, Figure 1: search results satisfaction)
- Satisfaction rating went down as more facets were chosen for both Task 2 and 3. (Table 2: book satisfaction)
- Participants who used more topic facets had higher satisfaction scores in Task 2, when they were not specifically asked to use them. (Table 4: facet column satisfaction)
Conclusions #2 and #5 are arguably the most interesting because they indicate that the use of, and satisfaction with using, the topics is tied to the use of other facets in the facet column. Analysis of the moderated study bolsters that conclusion, discussed below.
Perhaps more importantly than anything else, there is a statistically significant difference in mean satisfaction across the number of topic facets chosen. (Table 3) The difference peaks at 2-3 facets chosen and then trails off. This implies that limiting by topic may work better when topics are used in conjunction with each other, but not more than 3 at a time.
We would be remiss not to note some aspects of the unmoderated study that should be taken into account:
- Script design is an extremely important factor. No script is perfect, and even a short script can cause users to get frustrated as they maneuver through it. It's possible that lower satisfaction ratings towards the end are due to the design.
- In that same vein, choice of topic facets was high, however, it was the top facet listed in the HathiTrust instance, above "Subject," "Author," etc. Participants may have defaulted to the first facet when not asked specifically to look at topic facets.
- Some participants (10 or 3.2%) were unfortunate enough to perform a search that resulted in a blank page. The Morae software required that we run it on an untested (at the time) operating system, which seems to have resulted in this bizarre behavior. This did not provide a clean testing experience, and frustration is bound to increase as a result of it. (For those participants, those searches were removed from their data.)
As we had hoped, the results of the moderated study did help to explain some of the vagaries of the unmoderated study, as well as giving us some potential answers on what people thought about the topics themselves and how they were useful to their research. We can list these as:
- With a simple search or a search narrowed by a topic, there was no indication that either one was superior or better than the other in terms of quality or ranking. (Task 1)
- For participants' own searches, the quality of the results themselves remained high, validating the corpus of materials for use in this study. (Tasks 2 and 3a)
- Topics were helpful when participants searched and reviewed results (2/3 of the time), however LCSH was considered superior than topics when participants reviewed item records (3/4 of the time). (Task 3a and 3b)
- However, the large majority of participants (87.5%) thought the topics assigned to records were appropriate. (Task 3b)
- Participants thought the topics were accurate, from which we can assume they would trust them enough to use them again. (Post-test questionnaire)
Most interestingly, when participants were asked to look at LCSH and topics together (reviewing both sets of facets for a chosen search), 4 of 8 (50%) found topics superior and 3 of 8 (37.5%) found LCSH superior (Task 2). In conjunction with the findings above that participants found topics helpful, but generally preferred LCSH (subjects), this lends credence to our conclusion that the conjunction of the two types of subject-based limiters is helpful to participants hoping to further refine a search result. Stated another way, participants view topics and LCSH as apples and apples, not apples and oranges. There are direct comments from participants that support this conclusion:
- "They [topics and LCSH] seem to relate well to each other."
- "It [usefulness throughout the study] did switch between topics and subject [LCSH]. So in that sense it's great to have both."
- "I assume they [topics and LCSH] both take a different tack."
- "While the topics [assigned to a record] are certainly addressed by the book, I think as given they misrepresent what the focus of the book is. The subjects [LCSH] give a more 'direct' description of the book."
- "They work really well together, but I think of the topics as the 'big umbrella' and subjects [LCSH] as the things that fit in them."
When asked, all the participants provided additional topic terms for the records they were viewing. This could imply that topics in general are useful enough to add to. It could also mean that the topics lacked specificity overall, and the additions were what participants really wanted to see.
Some topic words opened up new ideas for searches (i.e., serendipitous finding). In one participant's words: "I liked the idea that the topics helped me to broaden my search and what I'm looking for or consider different search terms or options. And to help me narrow by giving me options where I can select the ones I think are relevant and discard the ones that aren't."
Participants found some topics difficult to understand because they can be construed as homonyms. In natural language processing, this is a known problem called "lexical ambiguity" [Jackson & Moulinier, 2007]. For example, in one participant's search, the topic "lighting" showed up as a facet. The participant verbalized the difficulty of this topic as something that could be construed as an architectural concept or as a physical property. One conclusion could be that homogenous subject collections may be better to topic model than more heterogeneous collections. (And that it is difficult to foresee problems with labeling of topic clusters prior to testing.)
There are a number of other important factors and caveats with respect to the moderated work:
- It's possible that participants may be more familiar with LCSH terms when they search library materials, and this could be why they seemed more useful than topics.
- LCSH may have looked more formal to participants since they were capitalized and the topics were not. That may have made LCSH look more credible.
- As with any face-to-face test, participants are far more willing to please the study moderator. We made sure to indicate that the product we were testing was not one we were responsible for (since the topics were not and have not been deployed to HathiTrust in general), however this is common testing behavior.
Conclusions and Further Work
Our analysis shows us that while topic facets were heavily used both when participants were asked to use them and when they were asked to use any facet, participants were more pleased overall when they used topics in conjunction with other facets. This is supported in part by our unmoderated study, which effectively studied the usage of facets but not as effectively the content of those facets. The conclusion is more fully supported by our moderated study, which was designed to study the content of the topics and, in addition, compared topics and LCSH (Library of Congress Subject Headings). This study provided evidence that the topic content was useful when refining a search result, and that using LCSH and topics together was far better than using either facet on its own. In addition, participants commented that having the topics available allowed for serendipitous searching.
We also have results that support the conclusion that using more than one topic at a time to narrow or expand a search can be more effective than using just one topic on its own. And there is evidence that this effectiveness decreases when using more than three topics at a time.
We are excited by the possibility that topics and LCSH subject terms can complement each other in academic online searching environments. We are interested in expanding this research into other avenues by changing the variables:
- Trying our method with just metadata records, e.g., what results would we get using all of the records in the Summon service from Serials Solutions?
- Using a much larger, more heterogenous repository, e.g., what results would we get if we topic modeled all of the HathiTrust volumes (currently over 9.5 million)?
- Using a different subject-specific collection, e.g., how would the results differ if we used a collection of Law or Astronomy texts?
- Comparing topics with a different type of classification, e.g., against the Art & Architecture Thesaurus (AAT)?
Acknowledgements
We would like to thank all of the Digital Library Production Service unit at the University of Michigan Library, the HathiTrust staff, our Desktop Support Services, and Giselle Kolenic at our CSCAR (Center for Statistical Consultation and Research) service. Also, we would like to thank Katie Bauer at Yale University, who helped with the test design. This work was funded by a National Leadership Grant (LG-06-08-0057-08) from the Institute of Museum and Library Services.
References
[1] Hagedorn, K., Chapman, S., & Newman, D. (2007). Enhancing search and browse using automated clustering of subject metadata. D-Lib Magazine, 13(7/8). http://dx.doi.org/10.1045/july2007-hagedorn
[2] Halskov, J., & Barrière, C. (2008). Web-based extraction of semantic relation instances for terminology work. Terminology, 14(1), 20-44. http://dx.doi.org/10.1075/term.14.1.03hal
[3] Hearst, M. (2006). Clustering versus faceted categories for information exploration. Communications of the ACM, 49(4), 59-61. http://dx.doi.org/10.1145/1121949.1121983
[4] Jackson, P., & Moulinier, I. (2007). Natural Language Processing for Online Applications: Text Retrieval, Extraction and Categorization. Natural language processing (v. 5). Amsterdam; John Benjamins Publishing Co., 2007.
[5] Krowne, A. & Halbert, M. (2005). An initial evaluation of automated organization for digital library browsing. JCDL'05, Proceedings of the 5th ACM/IEEE-CS Joint Conference on Digital Libraries, 246-255. http://dx.doi.org/10.1145/1065385.1065442
[6] Mimno, D., & McCallum, A. (2007). Organizing the OCA: learning faceted subjects from a library of digital books. JCDL '07, Proceedings of the 7th Joint Conference on Digital Libraries, 376-385. http://dx.doi.org/10.1145/1255175.1255249
[7] Moens, M., Uyttendaele, C., & Dumortier, J. (2000). Intelligent information extraction from legal texts. Information & Communications Technology Law, 9(1), 17-26. http://dx.doi.org/10.1080/136008300111583
[8] Newman, D., & Block, S. (2006). Probabilistic topic decomposition of an eighteenth-century American newspaper. Journal of the American Society for Information Science and Technology (JASIST), 57(6), 753-767. http://dx.doi.org/10.1002/asi.20342
About the Authors
 |
Kat Hagedorn is currently the Project Manager for Digital Projects at the University of Michigan Libraries. She is responsible for coordinating, managing and maintaining momentum on a large variety of text and image digitization and digital collections. She is also responsible for quality review of HathiTrust materials. In addition, she has been doing research in the fields of semantic analysis and automated classification for most of her library career. Kat received her Masters in Information from the University of Michigan.
|
 |
Michael Kargela recently completed his Masters in Human-Computer Interaction at the University of Michigan. He worked for 14 years as an accountant and
Certified Internal Auditor prior to returning to school. He is looking forward to beginning his career in the usability profession. His interests include user research, interaction design and information architecture.
|
 |
Youn Noh is a Digital Information Research Specialist in the Office of Digital Assets and Infrastructure (ODAI) at Yale University. In her role, she supports ODAI's engagement with metadata professionals in Yale's libraries and museums. She also supports research and assessment to facilitate ODAI's data curation activities. She holds a B.A. in Linguistics from Stanford University and a M.L.I.S. from UCLA. She is currently project director on a grant from the Institute of Museum and Library Services to investigate applications of topic modeling for library and museum collections.
|
 |
David Newman David Newman is Research Faculty in the Department of Computer Science at the University of California, Irvine. His research interests include machine learning, data mining and text mining. Dr. Newman received his PhD from Princeton University.
|
|