|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Andrew Treloar David Groenewegen Cathrine Harboe-Ree |
![]()
AbstractThis article describes the work currently underway at Monash University to rethink the role of repositories in supporting data management. It first describes the context within which the work has taken place and some of the local factors that have contributed to the inception and continuation of this work. It then introduces the idea of a Data Curation Continuum and describes the various continua that might be applicable in a repository data management context. The article then discusses some of the implications of this approach, before reviewing related work. 1 IntroductionThe work being done at Monash University on rethinking the role of repositories in supporting data management has grown out of a number of local factors that distinguish Monash University from other institutions: its size and focus on e-Research, an Information Management Strategy, and a range of inter-related and innovative projects. Monash UniversityMonash University is Australia's largest and most internationalised university. In addition to its six Australian Campuses, it has campuses in Malaysia and South Africa as well as centres in London and Prato (Italy). Monash University has over 50,000 students and 6,000 equivalent full time staff. Its current strategic direction is focussed on achieving excellence through a cross-disciplinary, multi-campus, international approach. Consistent with this the university has invested strongly in information technology to support research, teaching and administration. One manifestation of this has been a recent strategic investment in e-Research (what the UK would call e-Science, and the US calls cyberinfrastructure (Atkins, 2003)). This has taken the form of the establishment of the Monash e-Research Centre, as well as significant investment in network, storage and grid computing infrastructure. Monash has also been a leader in the establishment and operation of Australian government funded research projects in this area, such as the institutional repository project (ARROW) and two projects on researcher workflow and data management (DART and ARCHER). See below for further information about these projects. Information Management StrategyIn 2003, a group was formed to develop an Information Management Strategy for the university. The initial membership (later augmented) included the Executive Director (ITS), the University Librarian, the Head of the Centre for Learning and Teaching Support, the Manager of Records and Archives, and discipline experts from the School of Information Management and Systems. The resulting strategy (Monash 2005) took an explicitly holistic approach that did not see information as belonging to only one part of the university. The strategy was adopted as one of the University's key priorities for 2006, and it retains an ongoing importance. The strategy articulated a set of principles, including statements about information being of corporate importance and available to anybody, anytime, anywhere and anyhow, as appropriate. These principles have informed a range of initiatives since then, including the ARROW, DART and ARCHER projects. For more details about the strategy, see Treloar (2005a, 2006a), and Palmer (2007). ARROW OverviewAlso in 2003, a consortium consisting of Monash University (lead institution), together with the University of New South Wales, Swinburne University of Technology, and the National Library of Australia, was successful in receiving funding for the Australian Research Repositories Online to the World (ARROW – http://arrow.edu.au/) project. This project aimed to identify and test software or solutions to support best practice institutional digital repositories that would contain e-prints, electronic theses, e-research and electronic journals. The project has partnered with a commercial software developer (VTLS Inc.) to develop a number of open source software modules and VITAL, a licensed commercial offering built on top of these modules. The current offering provides a rich product on top of the Fedora open source repository platform (Lagoze et. al. 2006). Fifteen of the forty universities in Australia have licensed the VITAL software solution to support an institutional repository. For more details about ARROW, see Payne and Treloar (2006) and Treloar and Groenewegen (2007). DART OverviewIn August 2005, the Dataset Acquisition, Accessibility and Annotations e-Research Technologies (DART – http://dart.edu.au/) project came into existence. The DART request for funding built on the work already done in the ARROW project in establishing the basis for institutional research publication repositories, as well as antecedent activity at each of the DART partners (Monash University – lead institution, James Cook University, and the University of Queensland). It did this by extending its concerns into the areas of large datasets and sensors, as well as annotation technologies and collaborative, composite documents. In particular, the DART project sought to investigate the most appropriate response to the challenges inherent in:
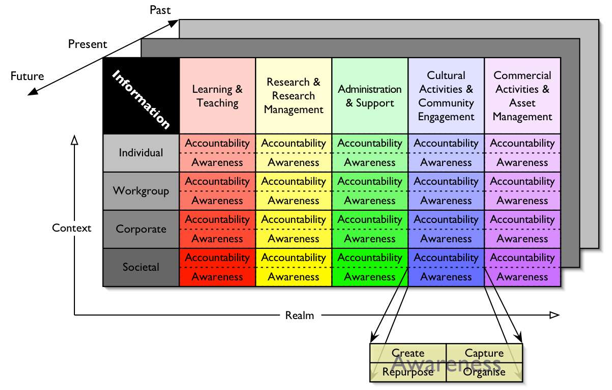
2 Data Curation and RepositoriesInitial approach"For every problem there is a solution which is simple, obvious, and wrong." Albert Einstein. The original view of the ARROW project was that there should be a single repository underpinning a range of different content types to support the various spheres of activity of the university: research, teaching and administration. As Monash University has tried to put this into practice, it has become apparent this appears to be one of those simple, obvious and wrong ideas. In theory, a single repository could probably be implemented, but Monash University has found this to be a problematic approach in practice. This is because the differing sorts of objects that might be stored in a repository can vary widely. In addition, there are characteristics of the management of and access to these objects that also differ. These differences cannot easily be accommodated from a common repository infrastructure. This is particularly true once one moves from a repository of publications and discrete objects to a repository that might also contain data generated by e-research. Building on information managementMonash University's current thinking about repository management builds on its successful Information Management Strategy, which adopted a multi-dimensional view of information. This approach was informed by a body of theoretical work developed by researchers in the School of Information Management and Systems. They developed the notion of an information continuum, based on a multiple-axis analysis of the various characteristics of information in organisations (Schauder, et al. 2004). Figure 1 is one way to represent these five different dimensions on a two-dimension surface.
The information dimensions identified for the Monash University Information Management Strategy were as follows:
Using this typology, a piece of information might be characterised as dealing with Research & Research Management, intended for a Workgroup context, used for Accountability purposes, and Created in the Past. For more on this approach to information categorisation, see Treloar 2005a, Treloar 2006a, Palmer 2007. 3 Data Curation ContinuaThe information management dimensions were largely quantised to have particular values (with the exception of Time). An analysis of the research data management space, informed by user requirements, a literature review, and the use-case work undertaken in the DART project, suggested that it might be more difficult to identify specific values along each dimension. Instead, it was decided to have continua that graduated between two endpoints. So, what might be the relevant continua for data curation, and what would the endpoints of these continua look like? The Data Curation Continua identified so far are represented in Table 1.
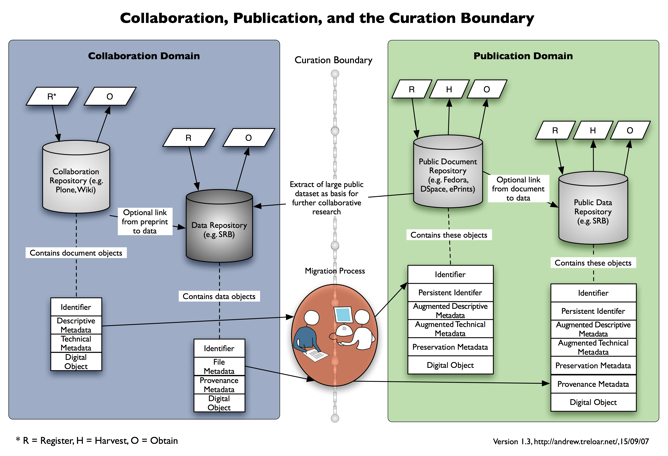
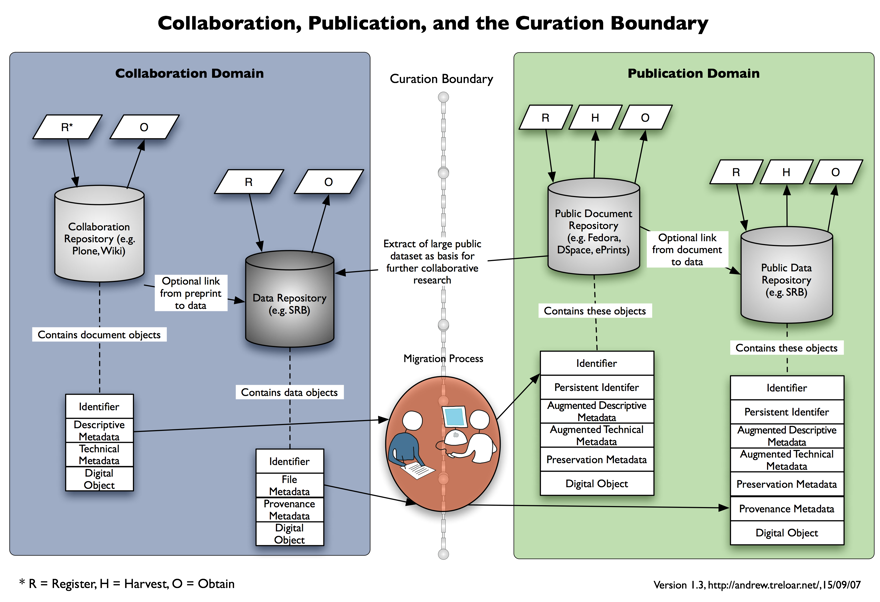
Table 1: Data Curation Continua MetadataAt one end of the continuum, objects will contain the minimum metadata needed by the object's creators and users. This will often be a mix of simple descriptive metadata (filename, creator) and discipline-specific technical metadata. The drivers for minimal metadata are the combination of lots of objects (see below), insufficient time to provide extensive metadata for each object, automatic generation/capture of the objects, and no business case for providing better metadata. At the other end of the continuum, objects will contain much richer metadata. This might include provenance metadata (indicating what operations have been performed on the object), more detailed descriptive metadata, and preservation metadata to facilitate curation. Item CountOne end of the item count continuum describes repositories with lots of items. These may be different versions of data objects, the results of failed or inconclusive experiments, or objects that should have been purged but have not been as yet. For large projects or institutions, the object count could run into the millions. The other end of the continuum describes repositories with many fewer items. This is because the objects have been winnowed and selected. This selection may be on the basis of an institutional data management policy or because the objects have been referenced in a publication. Object SizeObject size is another possible continuum. Of course, repositories will contain objects of many different sizes – this continuum is based on the most common object size. Many e-research projects now routinely work with very large (i.e., multi-gigabyte) objects. These may either be single files, containers of files, or complex databases. Other types of repositories (typically publication-focussed institutional repositories) are designed to work with smaller (megabyte-sized) objects. The size continuum is actually quite critical – a number of pieces of repository software have made design decisions on the basis of object size or type, and repository managers are now having to revisit these decisions to support larger/different objects. Object 'Fixity'Fixity refers here to whether the objects change once ingested into the repository. Researchers often want data objects that are continually changed or updated as the research project progresses. A good example is a record of climate data that grows each time new values are collected. Such a changing data object is not appropriate if it is linked to a publication as part of the permanent scholarly record. For this purpose it is preferable to have a snapshot of the data object or an extracted subset. Management Responsibility/ControlAnother continuum that can be used to characterise data curation practices is defining who is responsible for the management of the data (or who has control over it). Research data objects in the collaboration space are often managed by the researcher, members of the research team, or local IT staff. These managers may not have the skills or the commitment needed for long-term curation. At the other end of this continuum is management by a dedicated group within the university. Such a group, which might be a virtual team, would ideally include specialists drawn from a range of disciplines: records and archives, library, information technology, and e-Research. PreservationOne of the processes that can be applied to data objects is evaluating the degree to which preservation occurs. In the case of a research group, the preservation horizon is unlikely to be more distant than the end of the current project or the requirements of the grant that is funding the work. An institution might well have a longer-term focus, one that is concerned with the long-term scholarly record, national codes of conduct, or institutional obligations enshrined in legislation. AccessThe work of investigators in the DART project has indicated that many researchers are extremely conservative when it comes to granting access to research data. This appears to be associated with increasing competition in attracting research funds and having articles accepted by high-value publications. The recent move in Australia towards assessment of institutional research performance based on quality metrics (the Research Quality Framework – DEST 2007) is only intensifying this. As a result, many researchers want tightly controlled access prior to publication. It is theoretically possible to provide the levels of access control demanded by researchers in a repository that also hosts open-access content, but separation of the two types of repositories may be a preferred solution. Post publication, there is some evidence that open access leads to increased accessibility and increased citation rates. This may encourage researchers to be less restrictive about access. ExposureThe access continuum on its own is not enough to ensure the benefits of open access. The contents of the repository also need to be exposed and discoverable. This can be via a range of techniques: search engine spidering, OAI-PMH harvesting, RSS feeds, and/or SRU/SRW access through federated search techniques. At one end of this continuum, there is limited or no exposure to such harvesting software, meaning that even data objects with no access restrictions are unlikely to be discovered. At the other end of this continuum, the contents of repositories (such as the ARROW repositories) are exposed using a range of technologies to provide the maximum accessibility. 4 Implications of the Data Curation ContinuumImplementationThe way in which Monash University is currently applying the Data Curation Continuum approach is to make a choice about where to place a dividing line on each continuum. The sum of these choices serves as a way of defining two different types of repositories. To the left of this notional dividing line is a Collaboration Repository. It is the point at which the researchers are most actively working with and analysing their data. This is characterised by having less metadata, more items, larger objects that are often continually updated, researcher management, less preservation, mostly closed access and less exposure. In the Monash context, this would be a DART or ARCHER repository. To the right of the dividing line is a Publication or Preservation Repository. At this point the research is 'finished' in the sense that some results are available for public viewing. This is characterised by having more metadata, fewer items, smaller objects that are usually static or derived snapshots, organisational management, more preservation, mostly open access and more exposure. In the Monash context, this would be an ARROW repository, or a combination of ARROW and a public data repository. Figure 2 shows a repository-neutral version of these two sorts of repositories. The functions being provided for each repository are shown in terms of OAI/ORE transactions (Van de Sompel, et al. 2006, Open Archives Initiative 2007). It is, of course, entirely possible for an institution to have multiple repositories at each end of the continuum, but we anticipate that the likely practice at most universities will be a number of collaboration repositories (perhaps grouped by discipline or research group), and one or two institutional publication repositories.
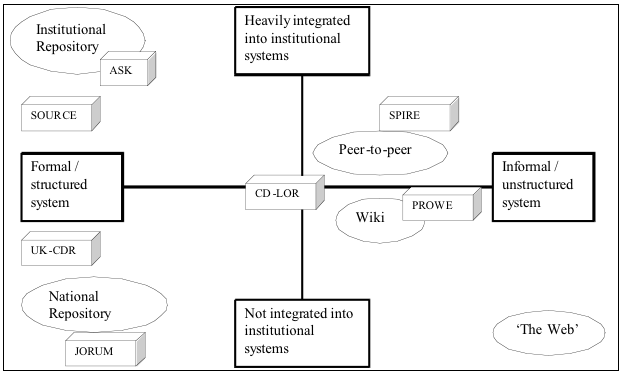
Curation Boundary and MigrationThe space between the two types of repositories is the Curation Boundary. This should not be interpreted to mean that there is nothing related to curation on the collaboration side of the boundary. The process of ongoing curation relies on provenance metadata that should have been captured during the research process. However, the ongoing work of active curation will largely take place on the publication side of the boundary. Researchers are not, in general, focussed on curating their data. This is a task more suited to the professionals who will take responsibility for the data in the publication domain. In this model, there is a process to migrate objects from the Collaboration to the Publication domains. In some cases the movement will be in name only, due to storage or other limitations. As Figure 2 shows, this migration process involves a mixture of human and computer actions. In practice, humans will need to make selection decisions and then use automated assistance to modify and augment the objects as they cross the curation boundary. The University of Hull is currently exploring the role of workflows in facilitating this sort of processing in their RepoMMan project (Hull, 2007). As Monash tests the use of the Data Curation Continuum and the Curation Boundary, it will accumulate a body of knowledge about how best to make the decision to move data or objects across the Boundary. This will probably be based on the final number of continua identified, what combination of continua are deemed most relevant, and how far to the left or the right of each continuum material is deemed to be. A two-way division is also not the only possible place to divide the continua, and Monash University is currently investigating the implications of a three-way split: a researcher team domain, a wider collaboration domain and the publication domain. In this case, the boundary between the researcher team domain and the collaboration domain might be dubbed the collaboration boundary. Part of the migration process over boundaries will need to focus on the object metadata. This will need to be modified and augmented. The modification will occur to the descriptive metadata. In a collaboration repository, this will often be the minimum needed for location and management within a collaboration context. In a publication repository, this will need to be quality-controlled and augmented so as to improve exposure and accessibility. New metadata will also have to be added in a publication/preservation context. One example shown in Figure 2 is adding PREMIS (preservation) metadata to assist with long-term curation. Another part of the migration process shown in Figure 2 is the assignment of a persistent identifier (such as a handle) to the object to facilitate persistent access. The current approach is to only assign a handle once the object is in the publication/preservation repository. An alternative approach is to assign the handle to every object in the collaboration repository and then just update the handle as the object is migrated (Sefton, 2007). This approach facilitates the migration of publications that are linked to data objects prior to publication. As researchers become more comfortable with the new repository-based collaboration environments, it may be worth considering moving to this approach, although this has to be offset against the associated ongoing handle management overhead. Data Management PolicyAnother way of using the continuum is in the realm of data management. Monash University is currently investigating how to implement an institution-wide data management policy as a series of decisions about where to place the curation boundary on each of the above continua. A future paper will describe this approach in more detail. 5 Related workMulti-dimension phase spaceThis article has focussed on two different types of repositories: collaboration and publication. Each type is characterised by its location towards one end of the data curation dimensions. Another way of thinking about this is that the data curation continua constitute a multi-dimensional phase space. Different continua in different combinations will define parts of this phase space. For one instantiation of this, see Figure 3. This shows two continua: integration with institutional systems versus structure. Obviously, other combinations of two continua (or more continua – but harder to visualise!) are possible.
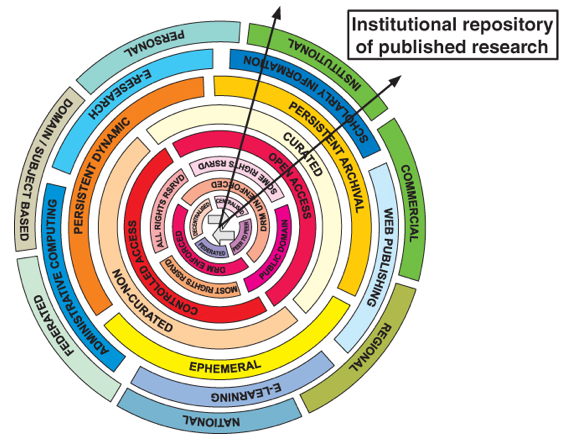
Wheel of FortuneThis is an approach taken by Blinco and McLean (2004). They depict a number of dimensions along which a repository might be structured as a wheel where different combinations of values on a dimension characterise a particular kind of repository. A static version of this wheel is shown as Figure 4, illustrating possible choices for an institutional repository of published research. The main difference between the Blinco and McLean approach and the one described in this article is that the wheel of fortune has quantised values (similar to the approach adopted in the Monash University Information Management Strategy).
Research Information Network reportA Research Information Network report has been drafted in the UK to "...address some of the key issues that arise in managing the unprecedented quantities and varieties of digital data now being created and collected by researchers. It sets out a policy framework of five principles, with associated guidelines, to help ensure that such data are properly looked after." (Research Information Network, 2007) The report characterises research data in terms of
6 ConclusionsThe single repository approach, while initially attractive, suffers from a range of implementation challenges. These challenges can be best understood and addressed when considered in terms of the data curation continua. One set of decisions about what to do for each of the continua leads to two different sorts of repositories. Monash University is calling these collaboration and publication/preservation repositories respectively. This split between repositories is now being implemented using the DART, ARCHER and ARROW repositories at Monash as a testbed. The first result of this is a paper in Science (Rosado et al. 2007) where the final published version points to a dataset which has been migrated across the curation boundary into ARROW (see http://arrow.monash.edu.au/hdl/1959.1/5863). The data curation continua also appear to be useful in an institutional data management context, but this remains to be proven. 7 AcknowledgementThe ARROW, DART and ARCHER projects have been funded by the Australian Commonwealth Department of Education, Science and Training. The funding has been provided through the Systemic Infrastructure Initiative as part of the Commonwealth Government's Backing Australia's Ability - An Innovation Action Plan for the Future. 8 ReferencesAtkins, D. et al., 2003, National Science Foundation Blue-Ribbon Advisory Panel on Cyberinfrastructure, Revolutionizing Science and Engineering through Cyber-infrastructure. Available at <http://www.communitytechnology.org/nsf_ci_report/>. Blinco, K. and McLean, N., 2004, The Wheel of Fortune: A "Cosmic" View of the Repositories Space. Available in animated form at <http://www.rubric.edu.au/extrafiles/wheel/main.swf>.
DEST, 2007. Research Quality Framework. Available at <http://www.dest.gov.au/sectors/research_sector/policies_issues_reviews/ Jacobs, N., 2006, 'Digital Repositories in UK universities and colleges', FreePint, Issue 200. Available at <http://www.freepint.com/issues/160206.htm#feature>. The Joint Information Systems Committee, 2004. The Data Deluge: Preparing for the explosion in data. Available at <http://www.jisc.ac.uk/index.cfm?name=pub_datadeluge>. Lagoze, C., Payette, S., Shin, E. and Wilper, C., 2006, 'Fedora: An Architecture for Complex Objects and their Relationships', International Journal of Digital Libraries: Special Issue on Complex Objects, Volume 6, Issue 2, April. Available at <http://www.arxiv.org/abs/cs.DL/0501012>. Monash University, 2005, Information Management Strategy. Available at <http://www.monash.edu.au/staff/information-management/>. Open Archives Initiative, 2007, Open Archives Initiative Object Reuse and Exchange. Available at <http://www.openarchives.org/ore/>. Palmer, H., 2007, 'From strategy to action: the information management initiative at Monash University', Proceedings of EduCause AustralAsia 2007, Melbourne, April. Available at <http://www.caudit.edu.au/educauseaustralasia07/authors_papers/Palmer-237.pdf>. Payne, G and Treloar, A., 2006, 'The ARROW Project after two years: are we hitting our targets?', Proceedings of VALA 2006, Melbourne. Available at <http://www.valaconf.org.au/vala2006/papers2006/57_Treloar_Final.pdf>. Research Information Network, 2007, Stewardship of digital research data: a framework of principles and guidelines (Consultation Draft). Available at <http://www.rin.ac.uk/data-principles/>. Rosado, C. J. et al. (2007), 'A Common Fold Mediates Vertebrate Defense and Bacterial Attack', Science Express, August 23 2007. Science <doi:10.1126/science.1144706>. Schauder, D., Stillman, L., and Johanson, G., 2004, 'Sustaining and transforming a community network. The Information Continuum Model and the Case of VICNET'. Paper presented at CIRN 2004: Sustainability and Community Technology, Monash University, Prato, Tuscany, Italy. Available at <http://www.ciresearch.net/conferences/viewabstract.php?id=68&cf=4>. Sefton, P., 2007, Another good use for handles: identifying items in the ICE content management system throughout their lifecycle (blog entry). Available at <http://ptsefton.com/blog/2007/05/16/handles_curation_boundary>. Treloar, A., 2005a, 'Developing an Information Management Strategy for Monash University', Proceedings of Educause AustralAsia 2005, Auckland, April. Available at <http://andrew.treloar.net/research/publications/educause05/A19.PDF>. Treloar, A., 2005b, 'ARROW Targets: Institutional Repositories, Open-Source, and Web Services', Proceedings of AusWeb05, the Eleventh Australian World Wide Web Conference, Southern Cross University Press, Southern Cross University, July. Available at <http://ausweb.scu.edu.au/aw05/papers/refereed/treloar/>. Treloar, A., 2006a, 'The Monash University Information Management Strategy: from development to implementation', Proceedings of VALA 2006, Melbourne, January. Available at <http://www.valaconf.org.au/vala2006/papers2006/56_Treloar_Final.pdf>. Treloar, A., 2006b, 'The Dataset Acquisition, Accessibility, and Annotation e-Research Technologies (DART) Project: building the new collaborative e-research infrastructure', Proceedings of AusWeb06, the Twelfth Australian World Wide Web Conference, Southern Cross University Press, Southern Cross University, July. Available at <http://ausweb.scu.edu.au/aw06/papers/refereed/treloar/>. Treloar, A., 2007, 'DART: Building the new collaborative e-research infrastructure', Proceedings of Educause Australasia 2007, Melbourne, April. Available at <http://www.caudit.edu.au/educauseaustralasia07/authors_papers/Treloar-183.pdf>. Treloar, A. and Groenewegen, D., 2007, 'The ARROW Project: A consortial institutional repository solution, combining open source and proprietary software', OCLC Systems & Services: International Digital Library Perspectives (in print). University of Hull, 2007, RepoMMan Project Aims, Available at <http://www.hull.ac.uk/esig/repomman/project_aims/index.html>. Van de Sompel, H, et. al., 2004, 'Rethinking Scholarly Communication: Building the System that Scholars Deserve'. D-Lib Magazine, September. doi:10.1045/september2004-vandesompel. Available at <doi:10.1045/september2004-vandesompel>. Van de Sompel, H, et. al., 2006, 'An Interoperable Fabric for Scholarly Value Chains'. D-Lib Magazine, October. doi:10.1045/october2006-vandesompel. Available at <doi:10.1045/october2006-vandesompel>. Copyright © 2007 Andrew Treloar, David Groenewegen, and Cathrine Harboe-Ree |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/september2007-treloar
|

{kind=link}