|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Beth Goldsmith |
![]()
IntroductionMetadata is an exceedingly broad category of information covering everything from an object's title and date of origin to information about layout, presentation, and rights. Within libraries and digital object repositories, metadata is the cornerstone of the infrastructure required for exchange and use of information. While metadata standards abound, and acceptance and use of these standards is equally widespread, agreement on a common standard is much harder to find. This dilemma was highlighted for the Los Alamos National Laboratory Research Library's Library Without Walls Team in the fall of 2003. At that time, it was decided to implement a standards-based digital object repository to hold the library's 80 million metadata records, 1.5 million full-text records, and several million other complex digital objects. A Repository Team was formed to tackle the project. It was recognized that there was a need to convert the disparate metadata to a consistent vendor-neutral format in order to simplify the increasingly complex task of storing, indexing, exchanging, and displaying the records. The process of determining a suitable standard involved definition of requirements, comparison of available standards, formalization of the adopted standard, and, finally, evaluation of the efficacy of the selected standard. BackgroundThere is no shortage of metadata standards within the digital library and digital repository communities, and the applicability of specific standards to specific datasets is discussed widely in the literature as are endeavors to cross-walk among the standards. Well aware that "no single element set will accommodate the functional requirements of all applications" [1], the Team originally considered retaining the individual metadata types to be ingested into the library's digital repository and providing the heterogeneous data as-is to downstream applications. As tempting as this short-term solution was, the Team rejected the idea due to the inherent difficulties of requiring downstream users to shoulder the burden of deciphering individual formats [2]. In brief, metadata from different sources can be difficult to cross-walk, requiring provenance-specific handling for every dataset. A recent article on metadata interoperability and standardization eloquently supports the viewpoint that users should not have to know or understand the methods used to describe and represent the contents of the digital collection, noting that the diversity of standards within the community, much less within a single repository, engenders significant challenges to users as well as to those responsible for managing the resources [3]. While not quite issuing a call for a uniform standard approach, the authors note that only such a standard will assure maximum interoperability and a high level of consistency. By shouldering the burden of normalization and quality control at the point of ingest, a repository can offer maximum facility to downstream users. Since uniform standardization is only practical at the inception of building a digital repository, the Team accepted the necessity of identifying a standard that would support the wide variety of metadata anticipated for ingestion into the repository. RequirementsThe necessary and desirable characteristics for metadata schemes have been discussed extensively in the literature [1, 4, 5, 6]. Within the Research Library, the only baseline requirement was that the standard should be XML-based in order to permit all transformations, manipulations, and quality tests to be performed with standard XML technologies. With that admittedly broad requirement in place, the Team identified three requirements for a uniform standard for digital repository metadata.
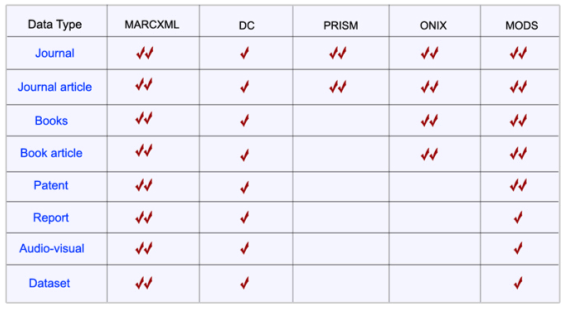
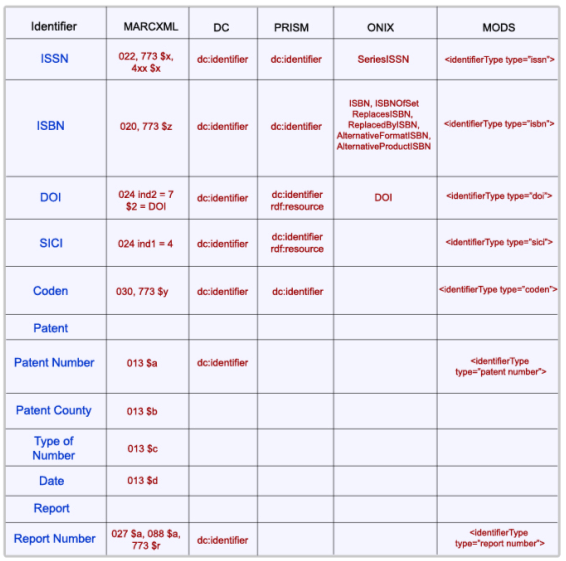
In addition to these requirements, the Team also drew up a short list of desired features for its uniform standard. The first was support for hierarchical data structures to model complex nested metadata. A second desired feature was cooperative management of the standard to insure that changes would be carefully considered and supported. Support for simple and complex use was another. A final aspect was related to familiarity; specifically, while the simplicity or amount of training required for the standard was not a deciding factor, existing experience with the selected standard was deemed to be a significant plus. Comparison and SelectionIn general, metadata standards have been developed in response to the needs of specific resource types, domains, or subjects. Although the team was unable to predict the types of content it might be storing in the future, the bulk of data to be mapped originally was bibliographic, although not limited to a single format, with accompanying administrative and descriptive data. Accordingly, library-based standards dominated the options that were explored, and after reviewing a variety of options, including locally developed schemas, five were selected for detailed comparison: Dublin Core, MARCXML, MODS, ONIX, and PRISM. Although relatively new at the time of the comparison, MARCXML is based on the MARC 21 format [7], the oldest of the standards considered. MARC 21 formats were developed in the 1960s for representing and exchanging bibliographic information in machine-readable form, and in 2002 the Library of Congress announced the MARCXML framework in order to offer the flexibility and extensibility of working with MARC data in XML [8]. From the outset, MARC and MARCXML standards were perceived as too bibliocentric and rigid. The team was also concerned about MARC's viability and its lack of popularity in the community [9, 10, 11]. Additionally, there were questions about the unwieldiness of traversing XML records that contain only five elements and in which all meaningful addressing must be performed at the attribute level. Despite the limited naming conventions, the sheer number of tag/indicator/subfield combinations further suggested that the complexity of this standard could be problematic. Conversely, although the wealth of available fields should offer a great deal of granularity, this is not necessarily the case; for example, just in the area of subject terms, there are only a limited number of subject domains defined by existing indicators, possibly requiring the use of local tags, indicator codes, or other conventions to maintain the context of subject terms. Dublin Core, in contrast, has a relatively long history as a well-accepted metadata standard. Conceived in 1995, Dublin Core was architected as a semantic metadata standard to support resource discovery [12]. With only fifteen elements, the standard is very accessible and transparent and is in wide use for repositories worldwide. Although the simplicity of this standard makes it distinctly lacking in inherent granularity, Dublin Core is, deliberately, highly extensible. Yet, despite Dublin Core's widespread acceptance, the Team was concerned that, as a container for disparate metadata, this standard would require immediate extension, thus limiting its transparency. Formalized in 2000, ONIX (ONline Information Exchange) is an XML-based scheme developed by publishers to be the international standard for representing book, serial, and video product information in electronic form [13]. While intriguing for the possible breadth of coverage, at the time of comparison the ONIX standard was limited to book metadata, offering extraordinary granularity for monographic metadata, yet limited by its data type specificity. Similarly, PRISM (Publishing Requirements for Industry Standard Metadata) is another recent addition to the metadata standards arena, established in 2001 [14]. PRISM provides a framework for the interchange and preservation of content and metadata and controlled vocabularies listing the values for those elements. Like ONIX, this standard's data type specificity – in the serials arena – limited its appeal. The final standard that was seriously considered was MODS. Developed in 2002, MODS (Metadata Object Description Schema) is a schema for a bibliographic element set "intended to be able to carry selected data from existing MARC 21 records as well as to enable the creation of original resource description records" [15]. Since, by definition, MODS includes only a subset of MARC fields and it uses language-based tags, several of the shortcomings identified for MARCXML, such as lack of granularity and extensibility, are carried forward. While MODS does simplify the complexity of MARC, in so doing it also significantly reduces its flexibility. With individual assessments of the five standards in hand, the Team performed side-by-side comparisons of their handling of specific metadata elements. First, data-type specificity was considered; although the team could not identify every type of metadata that would be worked with in the future, comparing even a small known subset immediately confirmed that PRISM and ONIX were too limited in their extensibility (see Figure 1). A second comparison addressed the standards' transparency and granularity in mapping author types. In the arena of differentiating among author types, Dublin Core and PRISM clearly lacked granularity; while MODS offers granularity, this is accomplished through the use of uncontrolled attribute values, limiting transparency (see Figure 2). It was, however, when the Team evaluated how identifiers were natively handled by the different standards that MARCXML truly rose to the top of the list (see Figure 3).
Although nervous about adopting a standard that seemed so antiquated, bibliocentric, and unwieldy, the Team re-visited MARCXML, finding that its strengths outweighed its perceived shortcomings. Utilized internationally and supported by a variety of tools, the MARC standard is pervasive within the library community, making it "both a communications format and a lingua franca for librarians" [16]. It is also far from stagnant, continuing to grow and adapt to changing needs, due in no small measure to input from the community: such recent updates include the addition of a field for pathway components for digital resources, support for Unicode, and the addition of the MARCXML standard itself, decoupling MARC data from MARC structure. Further investigation alleviated concerns about the supposed complexity of MARC: although there are well over one thousand tag/subfield combinations, only thirty-seven are used in 90% of MARC records [17]. This suggests that a great deal can be expressed with a relatively small vocabulary while the standard contains the richness to express much finer shades of meaning by applying the other 1000-plus combinations. Additionally, arguments about the relative transparency of numeric tags instead of named elements transformed from a negative to a positive when the Team noted that the numeric convention avoids the issues of semantic overload that occur when "human readable" names are used. The final reservations about adopting MARCXML, maintaining the granularity and context of the original metadata, disappeared with the realization that the standard does have the capacity to adapt to numerous metadata needs. Principles of UseHaving, with something akin to disbelief, selected MARCXML as a uniform standard for storing vendor-neutral metadata, the Team set about codifying and formalizing its use. At the highest level, it was determined that the MARC 21 standard would become a profile for storage, with MARCXML as the container. Within this framework, it was further determined that the standard would not be modified in any way that would make the metadata inaccessible to downstream applications or other users. The principles developed to guide usage fall into three broad categories: general mapping concepts, standards use, and data integrity [18].
Retaining the granularity, context, and original meaning of the data was the overarching goal in mapping to a vendor-neutral format. Concurrently, the ideal was that any system should be able to load these records into a reasonable representation of bibliographic metadata. Accordingly, the following conventions were adopted:
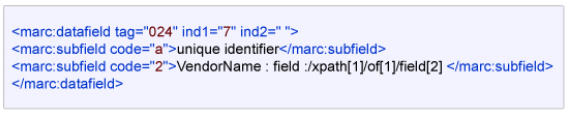
Observations and EvaluationTo date, the Repository Team has mapped approximately 87 million metadata records to MARCXML and must acknowledge that initial concerns about the complexity of MARC were unfounded. So far, the team has been able to map all incoming metadata elements into a total of 88 unique tag/subfield combinations. Of these, only six are required fields, and none are based on locally defined tags. Despite what might appear to be minimal use of the wealth of tags/subfields that are available, the team has verified that the granularity of the original data is not lost. Specifically, where data-specific tags exist, they are used; however, in the areas in which such specific mappings are not available (i.e. control numbers, classification numbers, subject category codes, subjects, and non-MARC Information fields) adoption of the subfield 2 code to identify data-specific context has proven especially effective. The convention readily permits granularity to be maintained while downstream applications can mine records according to the general meaning of the datafield or can be much more specific in their use. The extensibility of the standard has also been demonstrated through the early adoption of a proposed addition to the MARC standard for describing article level data in a new tag (363) and in a new host item subfield (773-q). Another extension that has aided in maintaining granularity is the use of subfield 8 linking pairs for related datafields (e.g. multiple 363-773 pairs; multiple conference and conference sponsor tags). Transparency is maintained by eschewing the use of local tags, using the most specific tag/subfields possible, limiting enhancements to the records, and adopting controlled vocabulary terms to disambiguate usage. With these conventions in place, the Team has been able to test and confirm the efficacy of its mapping principles. Well aware that "the major challenge in converting records prepared according to a particular metadata scheme into records based on another schema is how to minimize loss or distortion of data" [20], the Repository Team selected granularity as the sine quo non for testing its chosen standard. However, it was not enough for the selected standard to contain a list of elements into which each originating piece of data could be mapped; it needed both uniformity, in terms of making the purpose of the data easily known to downstream applications, and context to maintain the sense, order, and linkages among the original vendor elements. The test selected to prove this was roundtripability. Certainly part of the design standard for MARCXML [21], roundtripability allows the recreation of the original record from the mapped version and speaks to the desirability of being able to convert between systems [22]. Such a benchmark not only provides for lossless data conversion, but it also removes ambiguity. Resultantly, MARCXML metadata records are routinely tested using standard XSLT 1.0 stylesheets to verify that they can be returned to their original form. The results for flat-structured data continue to be extremely gratifying, with line-for-line, word-for-word, byte-count identical roundtripability. For more hierarchical records, minor manual tweaking to the automatically generated XML mapping files is required for some attribute information; yet, even without these updates, the hierarchical context information carried in the MARCXML subfield 2 enables correct reconstruction of the original record's structure. ConclusionIn 2003, MARCXML was selected as a uniform metadata standard for the LANL Research Library's digital repository. Reasons for the choice included its relative maturity in the XML standards world, its familiarity in the library community, and its ability to blend well with modern mark-up technologies. Perhaps most important for a nominally bibliographic metadata standard, it can be elegantly extended to adapt to numerous metadata needs. In the two-plus years that it has been used to map metadata records in the library's digital repository, MARCXML has proven itself to be robust and capable in meeting all requirements without breaking the standard while remaining flexible and transparent to downstream use. AcknowledgmentsThe authors would like to thank Irma Holtkamp and Esha Datta for their help in preparing this paper. Notes[1] Duval, Erik et al. Metadata Principles and Practicalities. D-Lib Magazine, 8(4), April 2002. <doi:10.1045/april2002-weibel>. [2] Diane Hillman, Naomi Dushay, and Jon Phipps (2004). Improving Metadata Quality: Augmentation and Recombination <http://metamanagement.comm.nsdl.org/Metadata_Augmentation--DC2004.html>, p.1. [3] Chan, Lois Mai and Zeng, Marcia Lei. Metadata Interoperability and Standardization – A Study of Methodology Part 1. D-Lib Magazine, 12(6), June 2006. <doi:10.1045/june2006-chan>. [4] Beall, Jeffrey, 2006. "Metadata Schemes Points of Comparison." <http://eprints.rclis.org/archive/00005544/01/comparingschemes.pdf>. [5] Kelly, Brian, (2004). Choosing a Metadata Standard for Resource Discovery. <http://www.ukoln.ac.uk/qa-focus/documents/briefings/briefing-63/html/>. [6] Tennant, R. A bibliographic metadata infrastructure for the twenty-first century. Library Hi Tech, 22(2):175-181, 2004. [7] MARC, <http://www.loc.gov/marc/>. [8] MARCXML, <http://www.loc.gov/standards/marcxml/>. [9] Eden, B.L. (editor). Metadata and Librarianship: will MARC survive? Library Hi Tech, 22(1), 2004. [10] Tennant, R. MARC must die. Library Journal (Oct. 15, 2002), 26-27. <http://www.libraryjournal.com/article/CA250046.html>. [11] Tennant, R. MARC exit strategies. Library Journal, (Nov. 15, 2002), 27-28. <http://www.libraryjournal.com/article/CA256611.html>. [12] Dublin Core, <http://dublincore.org/>. [13] ONIX, <http://www.editeur.org/>. [14] PRISM, <http://www.prismstandard.org/specifications/>. [15] Metadata Object Description Schema (MODS), <http://www.loc.gov/standards/mods>. [16] McCallum, S.H. MARC: Keystone for Library Automation. IEEE Annals of the History of Computing, 24(2):34-49, April-June 2002. [17] For details see a fascinating breakdown of all OCLC WorldCat MARC records, detailing the 1347 tag/subfield combinations used across the 55 million records. <http://www.mcdu.unt.edu/wp-content/FANDRFreqCount01BnonLCwemFinal20Dec2005.pdf>. Moen, W.E., et al. Format Content Designation Analysis: Data Report. Frequency Counts for Books, Pamphlets, and Printed Sheets Records Created by OCLC Member Libraries (Set 01_B_nonLC). 2005. [18] Goldsmith, B., Knudson, F., Holtkamp, I., Datta, E., Robinson, L., 2006. Metadata Mapping Principles and Practices. Working guidelines of the LANL Research Library's Repository Team. Available at: <http://purl.lanl.gov/vendors/documentation/RTF/codex-intro.doc>. [19] California Digital Library, 2003. Proposal no: 2003-03: Definition of Data Elements for Article Level Description. <http://www.loc.gov/marc/marbi/2003/2003-03.html>. [20] Zeng, Marcia Lei and Chan, Lois Mai. Metadata Interoperability and Standardization – A Study of Methodology Part II. D-Lib Magazine, 12(6), 2006. <doi:10.1045/june2006-zeng>. [21] MARCXML Design Considerations. December 30, 2004. <http://www.loc.gov/standards/marcxml/marcxml-design.html>. [22] McClelland, Marilyn, et al. Challenges for Service Providers When Importing Metadata in Digital Libraries. D-Lib Magazine, 8(4), 2002. <doi:10.1045/april2002-mcclelland>. (At the authors' request, Figure 2 was replaced on 9/20/06, due to an error in the original figure.) Copyright © 2006 Beth Goldsmith and Frances Knudson |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/september2006-goldsmith
|