|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Terry Reese |
![]()
AbstractFrom the creation of A-Z lists [1], to the purchase of third-party products like Serials Solutions [2], libraries have traditionally struggled to integrate access to electronic resources and their traditional print collections. To help alleviate this problem, many aggregate journal vendors have begun providing MARC records for their customers to load into their Integrated Library Systems (ILS). However, many libraries often avoid using these record sets because the high volume of records represent a potential maintenance disaster as users have to deal with issues like fixing obsolete data and removing resources no longer licensed by the library. In addition, the sheer volume of record sets tends to restrict a library's ability to customize the record sets to suit their individual needs. To meet these challenges, the Oregon State University (OSU) library developed an aggregate record management application, dubbed the ERW, that allows libraries to take multiple aggregator record sets and produce a single, de-duplicated data set containing custom MARC data defined by the individual library. IntroductionThe development and acceptance of electronic journal publications by the research community has been in some ways both a blessing and a curse for libraries. On one hand, electronic journals (e-journals) provide 24-hour desktop access to research materials, without the traditional constraints of users physically having to visit the library. On the other hand, e-journals represent a potential maintenance nightmare for many Technical Services departments charged with providing uniform access to these ever-changing resources. How does one "fit" e-journals into a library's central database without unbalancing current processing workflows? And how does one easily communicate vital information like journal coverage and availability to patrons? These are not easy questions, and frequently, the lack of a suitable or affordable answer has led to the creation of many disparate access solutions like static e-journal lists, secondary web databases and the creation of third-party e-journal management solutions. Like most libraries, Oregon State University (OSU) has struggled with the question of e-journal management since subscribing to its first e-journal. However, discussions regarding how to manage e-journals didn't begin in earnest until the fall of 2000 when the library started licensing aggregator e-journal titles via EBSCOhost [3]. Until that time, the library maintained a fairly manageable e-journal collection, providing a single access point via an A-Z list for all e-journal titles and cataloging selected e-journal titles for display in the local Online Public Access Catalog (OPAC) [4]. While the A-Z list was not searchable at that time, it was small enough that patrons could quickly browse the list to discover whether their desired resource was available. However, this changed when the library started licensing multiple aggregator databases through EBSCOhost. Overnight, the A-Z list became obsolete, as the number of unique licensed e-journal titles jumped from approximately 800 titles to over 3,400 titles. What's more, unlike the library's past e-journal subscriptions, the total number of titles available via the licensed aggregators was in a constant state of flux as new e-journal titles would be added or removed from each aggregator's database profile. Titles to which the library had access one month would be replaced by another title the next. Moreover, the library found that these e-journals were especially susceptible to embargo date [5] fluctuations, as new and existing e-journals worked to make more and more full-text articles available online. The ephemeral nature of these resources made providing access through an A-Z list difficult; providing access through the library's OPAC was nearly impossible. As a result, for the following year (2001), OSU provided access to all EBSCOhost e-journal titles through a single link to the EBSCOhost home page while other options were considered. These discussions were accelerated towards the end of that academic year due to the fact that the EBSCOhost e-journals made up nearly 80% of OSU's e-journal title usage. At the time of these discussions, OSU was able to locate only one third-party vendor that offered aggregator content tracking: Serial Solutions. However, at the time, Serial Solutions only offered a searchable list of e-journals [6] to replace the library's A-Z list. While this list solution would have been superior to what OSU then had in place, it did not provide the type of centralized and integrated access desired. Rather, it required patrons to search an additional resource database in order to access the library's e-journal holdings. It was agreed that the best-case scenario would be to provide access to the EBSCOhost e-journal titles through the OSU library OPAC, since this is where our patrons traditionally have gone to locate all other library materials. Moreover, since EBSCOhost provided downloadable CONSER [7] records for its full-text titles, Technical Services was charged with coming up with a method for using these MARC records in our OPAC. While investigating different ways to utilize the MARC records, Technical Services observed a number of issues surrounding the use of these records in the library's local OPAC. First, while the records provided by EBSCOhost were CONSER MARC records, small changes had been made to the record numbers (MARC [8] field 001 [9]) of each record, thus invalidating the record numbers within our local system. This invalidation manifested itself as an error during the record-loading process, making the provided records incompatible with our local system. These incompatibilities were compounded by the fact that our local system utilizes the record number to perform maintenance tasks such as de-duplication and record overlay. If the record numbers were incompatible, then the records themselves could not be overlaid on a continuing basis, and de-duplication of titles between disparate aggregate databases would never occur. To assess how serious the overlay and de-duplication problem might be, staff test-loaded several small record sets into its local system, and they found that, in some cases, five duplicate titles would be generated in the system if a particular title existed in each separate aggregator database. In addition to the duplication, staff found that manual manipulation would be required on an ongoing basis to reflect the library's current holdings and to supply any locally defined data to each record. To address the problems noted above, I developed a small script-based application called the ERW ("Ebsco" Records Wizard), named after the aggregator that precipitated its creation. Although the application continues to be called the ERW at OSU, the name has come to be a bit of a misnomer, for while the ERW was initially designed solely to be a management tool for the EBSCOhost record sets, it has been enhanced so that, currently, the application can support the management of nearly all vendor supplied MARC record sets. Nevertheless, in this article I will continue to refer to the application as the ERW. Through the use of the ERW, OSU has been able to reduce the amount of staff time needed for record management for many of its licensed e-journals to a couple minutes a month, and the ERW is a tool that can be run by virtually anyone in the library [10]. The main goal of this article is to describe the design and salient features of the ERW, as well as provide a short description of the monthly workflow associated with its use. This will be followed by a brief description of the impact this tool has had on e-journal access at OSU. Finally, for libraries interested in experimenting with the ERW or modifying its source code, information on downloading the tool is provided. ERW features and functionWhen constructing the first prototype application, I set out to answer the two issues noted above: de-duplication and record overlay. However, after an initial testing period, library staff identified five distinct features for the program.
The main impetus behind the design of the ERW was to create a flexible, easy to modify tool that could be used to safely manage varying e-journal records. While the program allows library staff to create a single profile that can be used over multiple editing sessions, the program also allows staff the ability to customize any MARC record set using global editing options. Staff also have the ability to modify the program's source code to customize the program as needed. How it worksThe ERW makes use of two freely downloadable technologies. The first is Microsoft's Windows Scripting language [14], or to be more precise, Microsoft's VBScript. The reason this scripting language was chosen is that it is easy to use, is familiar to many non-technically oriented users and is a part of the Microsoft Windows operating system after Windows 98/Windows 2000. The second free component is MarcEdit [15]. MarcEdit is a locally developed MARC editor that includes a scriptable library capable of handling the processing of data in MARC format. To utilize the program, ERW users need to do three basic things:
One of the primary challenges of using a scripting language to construct the ERW was that scripting languages tend not to provide the functionality needed to create a Graphical User Interface (GUI). To overcome this barrier, the ERW was designed to "encapsulate" Microsoft's Internet Explorer using a Windows Script Component (WSC). A WSC is a specialized XML file (see Figure 2) with embedded VBScript commands allowing the file to function like a compiled library on one's computer. This enables the user to define properties and methods, and react to events performed within the host application.
With this component, the ERW provides a familiar interface for users to manage their journal data. Record de-duplicationAs noted above, a major challenge associated with using aggregator-supplied MARC records is that a large number of duplicate records exist between the different aggregator databases. Moreover, because different vendors make different customizations to their records, finding a good match point on which a de-duplication process can be run is challenging. However, the ERW employs a multi-layered approach to handle de-duplication of data and gives users control over 1) what record they want to use as the master record and 2) what the match point should be within each record set. To simplify the process, the ERW adopted a simple user-defined model of weighting record sets, so that ERW users could easily identify which record set should be utilized as the master set. The ERW takes the user-defined data and uses it when concatenating the records. The process itself uses the following multiple overlay points: ISSN [16], MARC field 001, and MARC field 245$a. This provides a reasonable assessment of each MARC record and its uniqueness within the record set.Record overlayTo address the record overlay issue, I developed two distinct methods of providing overlay within local systems. For local systems like Innovative Interfaces, which uses a numeric form of the MARC field 001 as an overlay point by default, the program provides the option to replace the existing control field (MARC 001 field) information and use a numerical digit starting at 999999999 and then subtract one digit for every record processed. In essence, this allows ERW users to reserve these higher control numbers within their local online systems for e-journal maintenance, and since OCLC's current control numbers start at around 500000000, it will take quite a few years before a conflict occurs. However, when the likelihood of conflict does occur, users can simply remove all the records at one time and raise the numeric digit. At OSU, the library utilizes this method within the local catalog, because it provides the safest method of record overlay. The main benefit of using this overlay method is that it frees the program from having to do a direct title-to-title overlay match. Since using a numeric form of the MARC 001 field as an overlay point can sometimes be conceptually difficult to visualize, let me give an example. If one month a library were to process three e-journal titles with the ERW, the record load would look something like this:
Then, if the following month five titles were processed with the ERW and within those five titles, Titles 1 and Titles 3 were in this record set but Title 2 was not, rather than forcing the ERW to make Title 1 and Title 3 updates on the current records for Title 1 and Title 3, the ERW simply ignores the records contents and overlays on the control number, meaning that records are overlaid and generated depending on the order in which they are processed in the corresponding aggregator MARC files. Thus, the record load for the second month would look like:
As one can see from the example above, while Title 1 and Title 3 were not necessarily updated on the records created during the previous month, each record's contents were indeed updated during the record loading process-and what is more, Title 2 has been correctly removed from the database. So long as the number of records processed increases or stays the same every month, no additional work will need to be done outside of loading the processed records into one's local database. However, if the number of titles decreases, staff would need to delete any additional records in their local database. Fortunately, this method of record overlay allows staff to easily isolate the group of records needing to be deleted. Using the five-record example above, if the number of records loaded dropped to two, staff would simply need to isolate records with Control Numbers: 999999996–999999995 and delete those records. The second overlay method supported by the ERW enables stripping the control field and specifying a different overlay point, or keeping the record's current control field and using it as the overlay point. Options DialogDuring the original design and testing of the ERW, I found numerous occasions where staff required more functionality than the original program provided. To meet this need, an Options Dialog was designed. The Options Dialog operates separately, but in relationship to, the ERW. From the Options Dialog, users can specify the following:
Once defined, these options are applied to all future instances of the ERW, unless changed by the user. Moreover, the Options Dialog presents the options in an interface that can be understood and used even by the most non-technical staff members. Workflow evaluationWhile the design group was able to create a flexible application that appeared to meet many of the library's needs, the last major question to be answered revolved around workflow. The library didn't want to trade one unwieldy maintenance process for another, so over a 6-month period, statistics were collected outlining the amount of time staff needed to generate a finished record set. For 6 months, the program was used to process approximately 9,000 e-journal titles, which when de-duped, became 3,400 unique titles. The program was run once a month after new MARC record sets became available from the vendors. The statistics gathered revealed the following average processing times:
The total time required each month for the entire process was just under 3 hours; however, this number is a little misleading since the Batch Data Load into the local system only requires the user to start the process and the process then continues without user interaction until completed. Therefore, during the 6-month analysis period, the process took about 15 minutes in terms of staff time. Today, OSU processes nearly 17,000 journal titles through the ERW for a total of 6,000 unique titles, and aside from the batch system load, all other aspects of the process have been reduced so that an average record load takes approximately 9 minutes of staff time per month. However, the ERW's workflow benefits extend beyond the monthly loading of records. Because e-journal holdings are constantly subject to change, the ERW can help streamline maintenance of these records throughout the month. At OSU, for example, a large group of e-journal titles (approximately 500) was removed from OSU's EBSCO profile. Rather than having to search the library's database and remove each catalog record individually, a member of the Technical Services staff downloaded the new EBSCO holdings files and reprocessed the records using the ERW. Once the records were reprocessed, the staff member simply had to re-load the processed file into OSU's database and delete the remainder. The entire process was completed in 2 ¾ hours, with 2 ½ hours of that time spent by the system processing the new record load. A second example illustrates how easy it can be to add a large group of new titles to one's local database. In June 2003, OSU purchased access to a new aggregator database via EBSCOhost, thereby nearly doubling OSU's e-journal titles accessed through the vendor. However, the total time needed to process our e-journal titles via the ERW didn't increase, and the only workflow change for staff involved the downloading of an additional MARC file from EBSCOhost. ERW e-journal usage impactUnfortunately, because most e-journal vendors provide sketchy usage statistics, it is very difficult to get a true quantitative tool to measure the impact these records have on e-journal usage. However, that said, EBSCOhost does provide a variety of usage data that log the number of users accessing their system, and we used those numbers as a base to measure the impact that the ERW has made on e-journal usage at OSU. We modified the records loaded into our local OPAC so that they passed through a counter before redirecting users to their desired e-journals. The counter simply recorded how many users were accessing e-journals through the library's OPAC, as opposed to other access methods (like the aggregator's homepage). What we found was encouraging and is shown in Table 1 below. Table 1: Comparison of e-journal usage before and after using the ERW
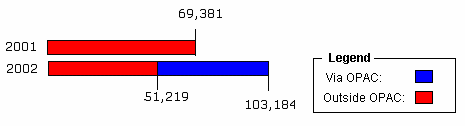
From Table 1, one can see that between 2001 and 2002, over 33,000 additional users made use of the EBSCO journals. However, while the number of logins went up during 2002, the total number of searches recorded by EBSCOhost remained fairly consistent and the number of abstracts viewed in EBSCOhost was notably reduced. I would argue that these two numbers are important for two reasons. First, since OSU only loads full-text journals into the OPAC, the fact that we see a reduction in abstract article usage seems to suggest that library patrons are finding more direct access to full-text e-journals. Secondly, one can see that searches on the EBSCOhost database remain fairly constant. During 2001, EBSCOhost reported that each user made approximately 4.3 searches per session. However, in 2002, this number actually drops to approximately 3 searches per session, which, again, would seem to indicate that patrons were finding more direct access to e-journal articles. I would argue that these numbers suggest that more patrons were starting in resources where they had access to full-text articles, which indicates a greater reliance on the library OPAC to get them to that point. When these numbers are compared against users passing through the OPAC, we also see a difference between the two years (Figure 2):
The graph above shows that of the 103,184 users accessing EBSCOhost, over 52,000 of those logs (blue bar) were passed through the library's OPAC. Between the years of 2001 and 2002, the total number of users accessing EBSCOhost journals via the OPAC actually outpaced those accessing these same journals using other means. Users accessing EBSCOhost outside of the OPAC fell from 69,381 the previous year to just a little over 51,200-or less than half the total. This trend has continued to the present, as users succeed in locating e-journals via the library's OPAC. Thus far in 2003, EBSCO e-journal usage at OSU already numbers over 80,000, and nearly all these users have come to these e-journals via the library's OPAC. ConclusionsBased on an evaluation of OSU's experience with the ERW, it is possible to provide access through the online catalog to thousands of electronic journals stored in different databases without the need for additional staff or expense. However, providing this access has presented many challenges as well. Because users have grown accustomed to finding most of the library's e-journals through the library OPAC, it has put added pressure on the library's Technical Service's department to continue to provide uniform access for resources that cannot be processed via the ERW-a number that has slowly become substantial considering the manual labor involved in record upkeep. On the other hand, the ERW has allowed the library to provide uniform access to its most widely used resources and to do so with minimal staff impact. While we continue to search for the "ideal" method for e-journal management, the ERW provides OSU with a viable alternative for the foreseeable future. ERW source filesSource files for the ERW can be downloaded from <http://oregonstate.edu/~reeset/ebsco/html>. The ERW setup file will install the source files and generate the expected folder structure on the client machine. Included in the ERW setup file is a .chm help file, the .wsc component file, and the Ebsco_Simple.vbs file. Notes[1] An A-Z list is simply a browsable, alphabetical list of e-journal titles. [2] Serial Solutions: <http://www.serialsolutions.com>. [3] EBSCOhost: <http://www.ebsco.com>. [4] Since 1999, OSU cataloged individual paid e-journal titles into the local OPAC. However, for the purposes of the Reference and Instruction department, the A-Z list was the defacto method of e-journal search and retrieval for both public services staff and library patrons. [5] An embargo date is the period of time that new e-journal issues would be withheld from electronic publication. [6] Note: This is no longer the case. Serials Solutions does provide a MARC record management service for e-journals. [7] CONSER is a cooperative online serials cataloging program initiated in the 1970s to provide high quality bibliographic records for serials. <http://www.loc.gov/acq/conser/>. [8] Machine-Readable Catalogue. [9] For information about the MARC 001 field, see <http://www.loc.gov/marc/bibliographic/ecbdcntr.html#mrcb001>. [10] Note: While the ERW is very easy to use, I always recommend that the ERW only be used by staff who understand the types of changes that the ERW does to an aggregator's MARC record set and how those MARC records will interact within their ILS (integrated library system). [11] Information about MARC filed 856 may be found at <http://www.loc.gov/marc/bibliographic/ecbdhold.html#mrcb856>. [12] MARC field 229 is a local field used by Innovative Interface's online catalog to index titles into a journal title index. The local field is used in conjunction with MARC field 222. [13] Information about MARC field 222 may be found at <http://www.loc.gov/marc/bibliographic/ecbdtils.html#mrcb222>. [14] Microsoft's Scripting Website: <http://msdn.microsoft.com/scripting/>. [15] MarcEdit home page: <http://oregonstate.edu/~reeset/marcedit/html>. [16] International Standard Serial Number. Copyright © Terry Reese |
||||||||||||||||||||||||||||||||
| |
||||||||||||||||||||||||||||||||
|
Top | Contents | ||||||||||||||||||||||||||||||||
| | ||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/september2003-reese
|