| ||
D-Lib Magazine
|
|
|
Thomas B. Hickey Edward T. O'Neill Jenny Toves OCLC Research |
![]()
AbstractOCLC is investigating how best to implement IFLA's Functional Requirements for Bibliographic Records (FRBR). As part of that work, we have undertaken a series of experiments with algorithms to group existing bibliographic records into works and expressions. Working with both subsets of records and the whole WorldCat database, the algorithm we developed achieved reasonable success identifying all manifestations of a work. BackgroundThe IFLA report Functional Requirements for Bibliographic Records [IFLA] is having a profound impact on how people look at bibliographic data. By presenting ideas about the data relationships of bibliographic records with the right mixture of practice and theory, the report has been able to capture the imagination of a wide range of both practitioners and academics. It seems clear that, at a minimum, anyone interested in the relationships between bibliographic items needs to take FRBR into account (e.g., [Lagoze and Hunter]). Starting in late 2001, we undertook a series of experiments designed to explore the implications of FRBR and look into the practical difficulties of implementing its approach within the context of OCLC's WorldCat database. The work reported here parallels other work done at OCLC [Bennett, Lavoie & O'Neill] as well investigations into FRBR by other organizations [Hegna] [BIBSYS]. Functional Requirements for Bibliographic Records (FRBR)Using entity-relationship analysis originally developed for relational databases, the IFLA Study Group on the Functional Requirements for Bibliographic Records identified three groups of entities:
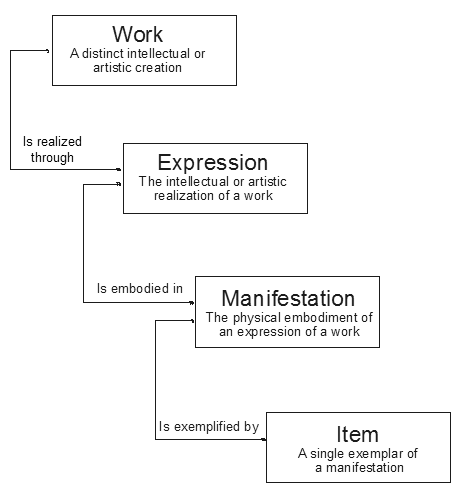
The Study Group then analyzed these in relation to the 'generic tasks' of finding, identifying, selecting and obtaining access to materials. The most innovative part of the report dealt with the first group of entities, describing the hierarchical relationships that cluster bibliographic items into manifestations, expressions and works. This group is the one on which our work at OCLC Research has concentrated. The concept of what constitutes a work is fairly intuitive. The prototypical work is Shakespeare's Hamlet. There are many versions of Hamlet, and for each version the text may be embellished, edited, translated, performed, etc. The creation of each of the versions of a work that entails intellectual effort is considered an expression of the parent work. These expressions, in turn, may be published, possibly in multiple formats, type settings, etc. Groups of essentially identical items produced are grouped together into manifestations. It is at this manifestation level that most library cataloging is done, although additional item-level information is needed to track specific items. The FRBR report shows this graphically in Figure 1 below [IFLA 3.1].
For the work Hamlet, an expression might be a version of Hamlet by a particular editor, a manifestation would be a particular typesetting of that text, and the item would be an actual copy of an individual book someone could read. Coming up with an efficient method of both grouping a large database according to FRBR and supporting the addition of new items to those groupings—ideally in real-time—is the challenge we face. Our research target is the WorldCat database. WorldCat consists of approximately 48 million bibliographic records with a new manifestation-level record added every 15 seconds and updates to existing records occurring every 5 seconds. Although the size of the WorldCat database presents special challenges, we feel that the benefits of using it as our target will be correspondingly large, since as the database grows, the number of records that can be grouped with other records grows as well—not only in absolute terms, but also in relation to the whole database. In other words, the ratio of records/works is increasing, and the percentage of new records that will match an existing work already in the database is also going up as the database grows. Identification of ExpressionsOur initial approach to FRBR was to strictly follow the Study Group's definitions of works and expressions and to see how closely we could approach that algorithmically. Since the identification of expressions posed the most obvious problems, we manually extracted from OCLC's WorldCat a set of records representing a single work, thereby avoiding the need for automatic identification of works. Following earlier experiences with Smollett's Humphry Clinker [O'Neill & Vizine-Goetz], we pulled 186 records representing monographs. These monographic records were then extensively analyzed, to the point of physically examining representative copies for each of the expressions whenever possible. Bennett [Bennett] identifies six main types of materials that have numerous manifestations and expressions:
Humphry Clinker falls into the category of work where the original text has remained relatively constant, but for which numerous illustrations, introductions, notes, bibliographies, etc., have been added in the creation of various editions over the years. Of course, the extensive investigation of a single work, or even single type of work, will not show all the problems associated with constructing FRBR relations; nevertheless, we have found the in-depth study of the work Humphry Clinker very instructive. In particular, it is our belief that this work well represents an important class of material in WorldCat, and that problems with Humphry Clinker can be extrapolated to a large number of other works. Results obtained from the manual extraction of records have been reported more extensively elsewhere [O'Neill]. What is important to note here is that the manually constructed set provided a basis for evaluating algorithmic approaches to dividing the set into expressions. The expression algorithm identified some 28 expressions in the Humphry Clinker set, versus a manual identification of 41 expressions. A fairly typical example is the Rice-Oxley expression shown below:
Our program is able to algorithmically pull together 10 of the 11 manually identified manifestations of this expression. Four of the expressions included the added entry (700) explicitly identifying Rice-Oxley as a contributor, but the other six expressions only identified Rice-Oxley in the statement-of-responsibility field (245 $c). While it is possible to pull names and roles out of this free-text field, the process is very language dependant and can be unreliable. The following record, which was not identified algorithmically, was identified manually as being in the Rice-Oxley expression:
Rice-Oxley is not mentioned at all! That match would be very difficult to automate in a reliable way. Our conclusion from this experiment is that, with some language and field-specific heuristics, it is possible to closely approach the manual division of records into expressions when such manual division is based solely on the information contained in the bibliographic records. Unfortunately, as O'Neill reports, the division based on this information is so unreliable that we question its usefulness. For instance, the identification of illustrators is not consistent enough to identify expressions based on the illustrations. We found that division into works provides the great majority of the functionality needed by users, and that below works, dynamic division of records into sets based on a particular user's needs, such as by illustrator or translator, would be more appropriate. Our experience, which reportedly has been the experience of other groups as well [ELAG], has led us to concentrate on the identification of works and, to a great extent, to abandon our experiments on identification of expressions for now. Data SetsIn addition to the Humphry Clinker dataset, we have experimented with a number of WorldCat subsets, including Shakespeare, the Bible, fiction, and a random sample of 1,000 records used to manually estimate the number of works in WorldCat. We can also extract sets based on a particular library's holdings or cataloging, and we have done that with Library of Congress records and those held by a mid-sized public library. Of course, our primary target is the full WorldCat database, and we have run experiments with it as well. Current Work-set AlgorithmFor our study, we concentrated on the level above the FRBR concept of a work, sometimes called a work-set or super work. The intention is to extend the FRBR work to include additional formats. For example, both the book and movie versions of Gone With the Wind would be collected together as a work-set if they both have the same title and are attributed to the same author. The basic work-set algorithm is fairly straightforward:
The original key is typically constructed from the MARC 1XX (author main entry) and 24X(title) fields (although a uniform title (130) will take precedence). For normalization we are using standard normalization [NACO]. For author names we include the standard MARC21 [MARC] subfields (a, b, c, d, and q) needed to guarantee a unique name, using '\' to preserve information about where subfield codes occur. Authority LookupWhen constructing the keys for the algorithm, names and titles are looked up in the LC name authority file, and the established form of the name and title is used. If more than one established form is found for a name, then the established form most often used in WorldCat is used in the algorithm key. For example, given a record containing:
The normalized key generated for this record would usually be:
(The 4 just before the $a in the 245 field above indicates that the first four characters of the title should be skipped, so The was dropped from Wonder) However, the author will be changed to the form in the 100 field in the authority record using the 400 cross-reference field:
The title will change based on another authority record:
Giving the final key of:
For authors covered by the authority file, the differences can be quite dramatic. Table 1 shows Humphry Clinker records clustered without authority lookup and Table 2 shows Humphry Clinker records clustered with authority lookup.
The authority file was able to bring together variant forms of both the author (smollett, tobias george vs. smollett, tobias) and title (expedition of humphry clinker vs. humphry clinker). The addition of cross references for the translated versions and other title variants to the authority file would further improve the grouping. The indexes to the name authorities have been augmented by adding entries without one or more of the dates when doing that would not result in ambiguity. This seems especially important when some of the records have been controlled using the British Library authority file, and others have been controlled using the Library of Congress/NACO Name Authority file, since the addition or lack of death-dates is a common discrepancy between the two. Notes on Alternative ApproachesAlthough the algorithms presented here are fairly simple, we have unsuccessfully tried a number of more complicated approaches:
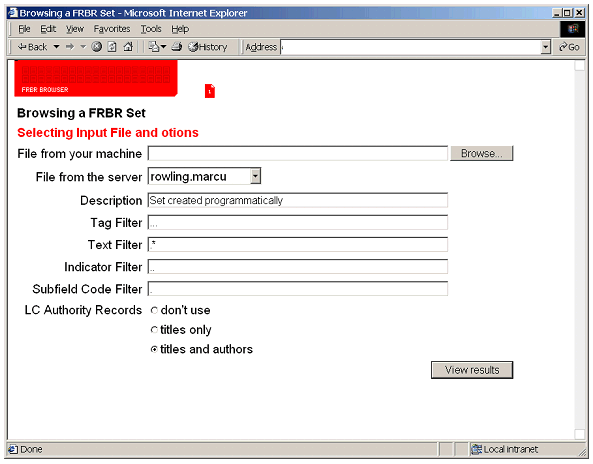
Since using these algorithms may directly affect catalogers, we have gradually developed the guiding principle that good cataloging should result in proper, predictable work-sets. Any heuristic, many of which would probably lower the overall error rate, could potentially fail this test in ways that would be difficult, if not impossible, for a cataloger to predict. A system designed primarily for reference and lookup, however, might well benefit by more intelligent matching to accommodate the variations found in many bibliographic records. Web ToolAs we worked with the datasets and algorithms, it became clear that a tool to display and navigate the created works, expressions and manifestations would be helpful. What started as a simple browser has evolved into a tool that allows us to select variations on the algorithms used, to load sets that have been manually processed, or to compare sets. We now have a visual map of how a set of records is formed into works and expressions.
The simplest use of the tool is as a FRBR browser (see Figure 2 above). The user can select a set of MARC records that exist on the server or on the user's local machine. Once a dataset has been chosen, the user can select variations in the algorithm. The dataset can be filtered for specific tags, text, indicators and/or subfield codes. The user can choose how the authorized headings will be used in determining works. The current choices are to include titles only, titles and authors or neither. Once the user has selected the dataset and the processing options, the set is processed and displayed.
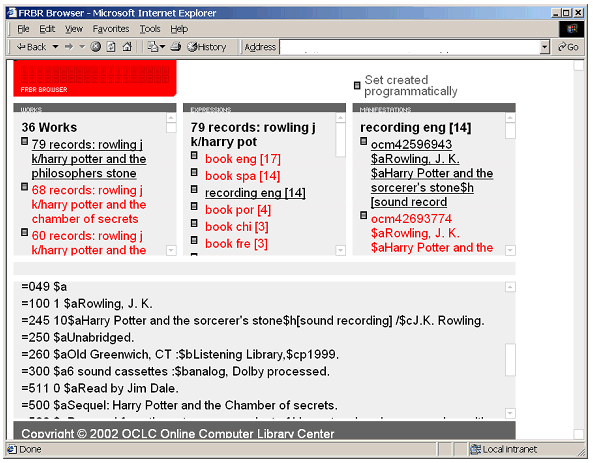
In Figure 3, the top part of the window for the selected dataset is divided into three areas. The upper left area is the list of works created from the input dataset. The middle area is a list of expressions relating to a selected work. An identifier for the selected work displays at the top of the expression list as visual link back to the work. The area upper right is a list of manifestations relating to a selected expression. An identifier for the selected expression displays at the top of the manifestation list as a visual link back to the work. A selected manifestation displays the entire bibliographic record in the bottom half of the window. The most powerful feature of the tool is the ability it gives the user to compare two work sets. It enables the user to compare algorithmic variations against the same input dataset. An example of this would be to see the differences in results between using authoritative names or not using them when categorizing works. The user can also compare an algorithmically created set against a manually created set, which is a good way to check how well the algorithm works.
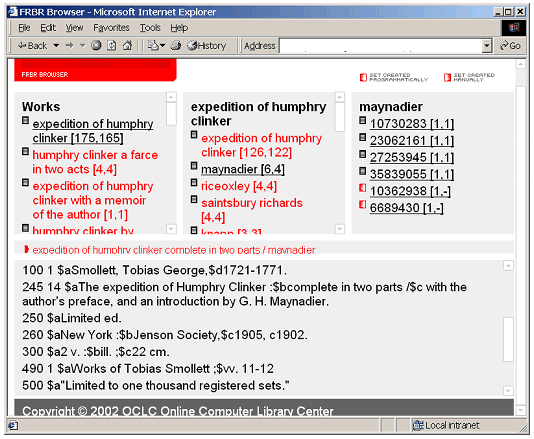
The navigation screen for compared sets (see Figure 4 above) looks much like the screen for browsing a single set. The first difference the user might notice is that the icons beside a work, expression or manifestation now have three variations instead of the single icon A one-sided icon with a pattern on the left side A one-sided icon with a pattern on the right side When a record displayed is from a grouping that did not have a match between the two work sets, then a link will appear immediately above the bibliographic window. The link just above the record and identified by a half circle icon will contain the work and expression groupings leading to this record in the other dataset. In the screen shot in Figure 3, the record shown appears in the work expedition of humphry clinker and the expression maynadier for one dataset and under the work expedition of humphry clinker complete in two parts and the expression maynadier for the second dataset. The user can click on that link and the screen will repaint with the path to this record for the other dataset appearing in the navigation portions of the window. Results on DatasetsRunning the algorithm against collections of records and sorting to show the works with the largest number of manifestation records always provides interesting results. Below are the 15 largest work-sets from all 8,600,000 records in WorldCat with Library of Congress (LC) cataloging:
It is interesting to compare the Library of Congress records with the results from a fairly large public library collection (850,000 records) drawn from WorldCat:
There are a surprising number of similarities between the LC work-sets and the public library work-sets, such as the inclusion of Mother Goose, religious works and composers in both. Probably the biggest differentiators (other than simply size) are the inclusion of treaties in LC and of selections from Schulz's Peanuts series in the public library. Problem SetsThere are fairly obvious challenges to effective clustering by works of large collections, e.g., the collections: Shakespeare and the Bible. While we haven't done a lot of work with either of these collections, it is interesting to see how well the algorithm collects the most common works:
This display is quite 'clean', in marked contrast to what happens with most library catalogs when doing a search for 'Shakespeare'. Shakespeare does present many problems, though, especially because of the wide variety of combinations of Shakespeare's plays that have been published, which causes severe problems when trying to show relationships. Below are the most common work-sets from Bible records:
A strong argument can be made to collapse many of these work-sets into a single 'Bible' work. Special rules will probably be needed for works as complex as this, since special rules are followed in their cataloging. Without special rules, forcing the collapse of Bible records together will result in many other works being collapsed together in error. FutureThe current estimate is that within the 48,000,000 records in WorldCat, there are approximately 32,000,000 different works. We are currently experimenting with the algorithm to see how well it does when compared to a 1,000 record sample from WorldCat that was manually matched against WorldCat to estimate the number of works. We also plan a more extensive investigation into the types of errors the current work-set algorithm is making, both to characterize them and to understand the magnitude and consequences of the errors. Implementation detailsThe great majority of these programs were written in the Python programming language [Python]. The display tool uses Twisted [Twisted Matrix], a Python-based system that facilitates the construction of servers, especially Web servers. MARC21 files were converted into Unicode before processing. Typically, fields are held in UTF-8 encoding and converted to 16-bit Unicode for comparisons and other processing. Experience has shown that UTF-8 encoded MARC21 files are essentially the same size as the original files. The programs can also accept records in LC's Maker/Breaker [Maker] format (which is very useful when manually constructing records for testing) and in MARC-8 encoding (for which Unicode translation is done on fields as needed). References[Lagoze and Hunter] C. Lagoze and J. Hunter. "The ABC Ontology and Model." Journal of Digital Information, Volume 2, Issue 2, 2001-11-01. <http://jodi.ecs.soton.ac.uk/Articles/v02/i02/Lagoze/>. [BIBSYS] O. Husby. How can BIBSYS benefit from FRBR? Lund, April 2002. [Le Boeuf] P. Le Boeuf. "FRBR: toward some practical experimentation in ELAG?" ELAG Conference, Prague, June 6, 2001. <http://www.stk.cz/elag2001/Papers/PatrickLe_Boeuf/PatrickLe_Boeuf.html>. [ELAG] S. Peruginelli. "FRBR: Some comments by ELAG (European Library Automation Group)." FRBR Seminar - Florence, January 27-28 2000. <http://www.aib.it/aib/sezioni/toscana/conf/frbr/perug-en.htm>. [Hegna] K. Hegna and E. Mürtomaa. Data mining MARC to find: FRBR? March 13, 2002. <http://folk.uio.no/knuthe/dok/frbr/datamining.pdf>. [IFLA] IFLA Study Group on the Functional Requirements for Bibliographic Records. Functional Requirements for Bibliographic Records: Final Report. UBCIM Publications-New Series. Vol. 19, Munchen: K.G.Saur, 1998. <http://www.ifla.org/VII/s13/frbr/frbr.htm>. [IFLA 3.1] "Figure 3.1." Functional Requirements: final report. [Bennett et al.] R. Bennett, B. Lavoie, and E. O'Neill. The concept of a Work in WorldCat: An application of FRBR. Working Draft, 2002. [Maker] Library of Congress, Network Development and MARC Standards Office. MARCMaker and MARCBreaker User's Manual. May 1, 2002 <http://www.loc.gov/marc/makrbrkr.html>. [MARC] Library of Congress, Network Development and MARC Standards Office. MARC Standards. <http://www.loc.gov/marc>. [NACO] Program for Cooperative Cataloging, NACO. Authority File Comparison Rules (NACO Normalization). February 9, 2001. <http://www.loc.gov/catdir/pcc/naco/normrule.html>. [O'Neill] E. O'Neill. FRBR: Application of the Entity-Relationship Model to Humphry Clinker. Submitted for publication, 2002. [O'Neill & Vizine-Goetz] E. O'Neill and D. Visine-Goetz. "Bibliographic relationships: Implications for the function of the catalog." In E. Svenonius (Ed.), The Conceptual Foundations of Descriptive Cataloging, p. 167-179. San Diego: Academic Press, 1989. [Python] Python Language Website. July 31, 2002. <http://www.python.org>. [Twisted Matrix] Twisted Matrix Laboratories. <http://www.twistedmatrix.com>.
Copyright © Thomas B. Hickey, Edward T. O'Neill, Jenny Toves | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| D-Lib Magazine Access Terms and Conditions DOI: 10.1045/september2002-hickey
|