|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Robert Chavez Timothy W. Cole Jon Dunn Muriel Foulonneau Thomas G. Habing William Parod Thornton Staples |
![]()
AbstractMetadata records harvested using the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) are often characterized by scarce, inconsistent and ambiguous resource URLs. There is a growing recognition among OAI service providers that this can create access problems and can limit range of services offered. This article reports on an experiment carried out by the Digital Library Federation (DLF) Aquifer Technology/Architecture Working Group to demonstrate the utility of harvestable metadata records that include multiple typed actionable URLs ("asset actions"). The experiment dealt specifically with digital image resources. By having for all images a consistent set of well-labeled URLs (e.g., pointing to thumbnails, in-context presentations of images on data provider's Website, or medium and high resolution views), the service provider was able to insure consistent results across repositories of content from multiple institutions. With predictable retrieval, advanced features such as thumbnail result displays, image annotation and manipulation, and advanced book bag functions are possible. It was even possible to overlay for use with this widely dispersed content a locally developed digital object collector tool from the University of Virginia. Results illustrate the potential of asset actions and support the need for further work at the community level to define and model actionable URLs for different classes of resources, and to develop agreements on how to label and convey these URLs in concert with descriptive metadata. 1 IntroductionInitially, most service provider implementations of the Open Archive Initiative Protocol for Metadata Harvesting (OAI-PMH) focused on cross-repository search and discovery functionality. Ubiquitous descriptive metadata formats such as unqualified Dublin Core (DC) allow data providers to include in each harvestable metadata record one or more URLs pointing to a resource. Missing from such schemas is a way to indicate precisely to what view, version, or part of a resource the included URLs link. For use models where the main objective is discovery, undifferentiated generic URLs may be adequate. However, experience has shown wide variation in what metadata-embedded URLs link to and in the ways in which URLs are included in harvestable metadata records. This can create frustrations for end-users [1] and difficulties for service providers wanting to provide more sophisticated services. Tourte, for example, describes how such variability hampered development of a Web service reliant on harvested metadata records to locate, harvest, and analyze full text of ePrints resources [2]. This article reports on a prototyping and demonstration experiment carried out by the DLF Aquifer Technology/Architecture Working Group. Four data providers, one tool provider, and one OAI service provider participated in the experiment – Indiana University, Northwestern University, the Chicago Historical Society, Tufts University, the University of Virginia (UVa), and the University of Illinois at Urbana-Champaign (UIUC). The genesis of the experiment, a brief description of experiment objectives and XML schemas used, and descriptions of data provider, tool, and service provider implementations are outlined below. The experimental portal that was built remains publicly accessible [3]. While this experiment was limited in scope and dealt exclusively with digital image resources, the approach is extensible to other content types. Further experimentation is being considered involving textual, multimedia, and aggregate resources and considering additional characteristics of actionable URLs for such resources (e.g., persistence, provenance, conditions of use). We are also exploring ways intermediaries might generate or broker views and lists of actionable URLs for resources hosted elsewhere. While we believe the technical details of the implementation described here are adaptable well beyond the DLF Aquifer Project, a more important outcome is further confirmation that community agreement on how to express and associate typed actionable URLs with individual distributed digital library information resources can be powerful. The availability of actionable URLs will support not only more advanced portal designs but also will facilitate reuse of locally developed tools and applications in additional contexts. The utility of actionable URLs also may stimulate new DL services that can mediate and/or derive actionable URLs for resources stored elsewhere. 2 Asset Actions Experiment Genesis, Objectives, and Technical Details2.1 The Genesis of the Aquifer Asset Actions ExperimentThe asset action set idea originated at the UVa Library as a way to selectively expose content as a set of standardized behaviors or views. The concept developed from discussions among UVa, Tufts and representatives of the Open Knowledge Initiative (OKI) when planning a bridge between Fedora-based repositories and the planned Visual Understanding Environment (VUE) project [4], using the OKI Digital Repository Open Service Interface Definitions (OSID). Later that spring, when UVa was planning the implementation of its digital object collector tool, the OKI concept of an asset came back to spark the idea of how a functional view of a unit of content could be transported among services. Given that UVa's digital library architecture is built on Fedora's ability to deliver behaviors for content through disseminators, and its web services orientation, it was natural to develop user access tools that could use packages of actionable URLs as input. Every object in their Fedora repository has a default disseminator that delivers a very basic set of behaviors that can be addressed in exactly the same way, regardless of the type of object. Each object also has disseminators that are true for all members of their particular class, basic image behaviors for image objects, basic text behaviors for text objects, etc. Objects also have a variety of other disseminator methods that are intended to support these high-level behaviors, as well as behaviors that are needed for management functions. One appeal of the asset actions approach was that it was a way to expose only some of the object's behaviors. Even more important, asset actions were seen as a way to generalize behaviors across repositories. UVa had been discussing how to coordinate behaviors with other Fedora users, particularly with Tufts and Northwestern, both of which had developed elaborate disseminator-based architectures on top of Fedora. It was obvious from the beginning that the different environments within which each was operating was resulting in different approaches. The asset actions approach was immediately appealing as a way to coordinate at least high-level concepts of behavior across content from different repositories. UVa was also able to adapt a non-Fedora system to the use of asset actions. The Robertson Media Center at UVa had developed a PHP/MySQL-based system that faculty and students used to build their own collections of digital resources and deliver them through web pages. It was relatively easy to add a collection function to their system that could deliver asset actions to the same collector tool the Library was using, allowing users to use their own resources with those from the Library in standardized ways. UVa, Tufts and Northwestern continued to develop the idea, discussing asset actions for images and texts. At a Coalition for Networked Information (CNI) meeting in the spring of 2004, people from those institutions, joined by people from ArtSTOR and Johns-Hopkins University Library, met to hammer out the first version of the default and basicImage action sets. Work continued in a desultory fashion until the Aquifer Technology/Architecture Working Group became interested in the concept as an approach Aquifer could use to do more than just search harvested metadata. 2.2 Experiment ObjectivesOne of the major goals of the Digital Library Federation (DLF) Aquifer project [5] is to enable "deep sharing" of digital library content across institutional and technological boundaries. Members of the DLF Technology/Architecture Working Group (see roster at [6]), formed in the spring of 2005, recognized early on that this would require the development of standardized low-barrier-to-entry interoperability mechanisms, allowing digital content providers to expose the components and views of their digital objects to a variety of tools that scholars might be using for collecting, annotating, editing, and otherwise repurposing digital content. Consistent with this goal, in December 2005 the Working Group – with additional participants from Tufts and Northwestern – decided to initiate an experiment on the feasibility of supporting asset actions in an OAI-PMH context. Participants from Indiana University, Northwestern, and Tufts volunteered to provide asset actions for a portion of their digital collections (Northwestern also mediated content from the Chicago Historical Society), while staff from UIUC and UVa volunteered to work together to create a demonstration web portal. This portal would integrate UIUC's work on OAI-based search portals with UVa's collector tool. The objectives of this experiment were to demonstrate the aggregation and reuse of digital objects in new contexts while allowing data and service providers to test ease of implementation. The data providers and portal were successfully implemented in time for a demonstration at the DLF Spring Forum in Austin, Texas, in April 2006 [7]. 2.3 XML Schemas UsedImplementing asset actions for OAI-PMH required expressing packages of actionable URLs in XML, which could be validated against a schema written in W3C XML Schema Language [8]. For the purposes of this experiment, descriptive metadata and asset actions were harvested together. To allow harvest of asset actions in combination with descriptive metadata expressed in either simple DC or the Metadata Object Description Schema (MODS), two additional schemas were required. Figure 1 shows the XML schema used to validate asset actions expressed as XML. Figure 2 shows the XML schema declaring an element to contain DC metadata in combination with asset actions. Figure 3 is an example of a valid XML node containing asset actions for a basicImage object. In anticipation of further experimentation, the schema in Figure 1 is minimally prescriptive. It requires presence of one actionGroup and one action per actionGroup and forbids repeated actionGroup elements of the same name and repeated action elements of the same name within any actionGroup. During development an additional, more prescriptive XML schema was created as a proof of concept [9]. Also considered were schemas making use of XLINK and/or explicitly typed XML elements. Future work might explore other schema languages for enforcing asset action rules and agreements and/or harvesting asset actions separately from descriptive metadata.
Figure 1 - XML schema for asset action package of actionable URLs.
Figure 2 - Schema defining container for combined asset action package and DC metadata.
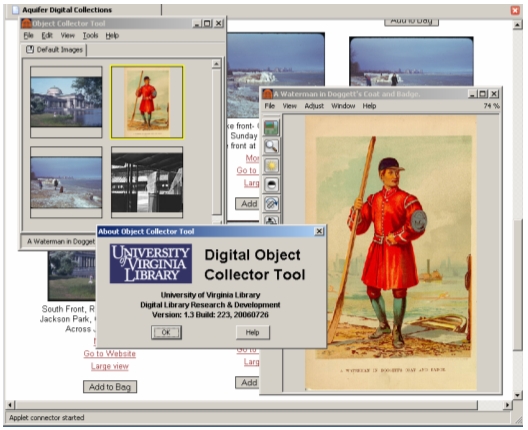
Figure 3 - Asset action package expressed as XML for a basic image object. 3 Data Provider Implementations3.1 Indiana UniversityIndiana University chose to make a portion of its Charles W. Cushman Photograph Collection [10] (approximately 1,000 out of 14,500 total items) available to the experiment. This collection consists of Kodachrome color slides taken between 1938 and 1969 by an IU alumnus of scenes spanning a wide social and geographical spectrum. The images are made available on the web via a Java web application developed using the Apache Struts framework with an Oracle backend database. DC and MODS descriptive metadata for the images is made available for harvesting via the OAI-PMH protocol using a modified version of the PHP OAI Data Provider from the University of Oldenburg [11]. Since MODS metadata were already available, IU staff chose to package the asset action metadata with MODS and configured the PHP OAI Data Provider to store and serve this as an additional metadata format. URLs were already available via the Cushman collection web site for most of the default and basicImage asset actions, and the missing ones (getLabel and getDCRecord) were easily implemented as XSLT transformations against the OAI-PMH GetRecord verb request. Total implementation time was less than one day. 3.2 Northwestern University and the Chicago Historical SocietyThree collections were adapted for asset actions by Northwestern University: Northwestern University Library (NUL) World War II Poster Collection, African Posters from the Melville J. Herskovits Library of African Studies at Northwestern University, and the Chicago Historical Society (CHS) Image Collection from The Encyclopedia of Chicago. Cocoon was used to implement these collections' various asset actions by transforming their native descriptive metadata. The CHS metadata was available from an in-house relational database at CHS. Cocoon was configured to access the database and provide native records as XML to various Cocoon pipelines. Each pipeline implemented a different asset action through specific XSLT transformation of the native metadata. For example, a pipeline for getLabel transformed a metadata record to a simple text string using the record's title field. Similarly, a pipeline for getDCRecord transformed the entire record to OAI Dublin Core. Images for this collection are available for any size through a scaling image server and named with identifiers available in the items' metadata, so providing URLs for the variously sized basicImage asset actions was easy. These various asset action URLs were in turn packaged by another Cocoon pipeline for the full OAI record. The same approach was used for the NUL collections although their source metadata was MARC XML. Like the CHS collections, XSLT transformations were used to convert the MARC XML for various asset actions. Images were derived from the 856 field in each MARC XML record, providing a link to a screen-sized image. The thumbnail image for each item, though web-accessible, was not explicitly referenced in the MARC record. Consistent path naming for screen-sized and thumbnail images however, allowed the MARC to OAI transformation to produce reliable links for both thumbnail and full size images for their Basic Image asset actions. These various URLs were packaged by another Cocoon pipeline for the full OAI record with asset actions Exposing asset actions for these collections using Cocoon took about half a day to implement. 3.3 Tufts UniversityThe Tufts University contribution to the asset actions experiment consisted of a subset of images from the Bolles Collection on the History and Topography of London (roughly 1,000 of 12,000 total images). The total Bolles collection consists of digital texts (approximately 11,000,000 words), and images (approximately 12,000, including geo-referenced maps) representing books, images, and maps of 18th and 19th century London and its environs [12]. The Bolles collection is managed in the Tufts digital repository, which utilizes a Fedora repository architecture, and is made available via the Tufts Digital Library. Within the Tufts digital repository, image asset actions were implemented as a Fedora behavior. The Tufts repository could disseminate most of the actions required (i.e., a thumbnail, a screen-sized image, a maximum-sized image, a dynamic image, OAI-DC metadata, etc.) via pre-existing image behavior definitions. The task of the asset action behaviors is to assemble the component actions required for the image asset action set from local Tufts repository image object disseminations; for example, the local getHighRes image disseminator to the asset action getMaxSize, and so on. By using this approach, all image objects deposited in the Fedora repository subscribe to, and in turn inherit, the behaviors of the basicImage asset actions. As a result, OAI-PMH packages could be easily generated for harvesting from the repository via XSLT transformations run against those objects selected for the experiment. For example, a call to the getFullAssetAction disseminator retrieves a fully formed asset action package (getAssetDefinition) for any image object in the repository, which can then be inserted into an OAI-PMH package along with the object's metadata. The process of assembling the OAI-PMH packages for 1,000 objects took a few hours to implement. A similar approach will be used to generate OAI-PMH packages for the text asset actions experiment. 4 The Digital Object Collector ToolIn order to demonstrate the potential of asset actions, UVa offered their Digital Object Collector Tool (DOCT) and promised to make minor modifications to the tool if they proved necessary. In particular, UVa expected that the Aquifer Technology/Architecture Working Group would be a good group to review the asset actions schema and make recommendations for improvement. A new, more robust version of the schema was developed, and the tool was modified to use it. The tool was integrated into a search portal built by UIUC (described below) for the data described above, in the same way that it was used at UVa. The DOCT, already in use with the digital library interface at UVa [13], is a Java Webstart application that is started up by a connector applet on a web page that offers a resource for collection. When a user right clicks on an image and selects "Add To Collection" (see Figure 4), the connector applet looks to see if an instance of the DOCT is already running on the user's machine. If so, the applet connects to the already running instance of DOCT and sends it a URL that can be used to retrieve the full XML instance containing the asset actions for the resource being collected (getAssetDefinition). The DOCT then uses the URL to retrieve the asset action set and adds it to the current collection. If the DOCT is not running, the connector applet starts it up; if the client does not already have the software installed, it gives the user the opportunity to do so and continue. The DOCT maintains collections as XML nodes of asset actions wrapped in its own set of collection tags. The tool manages collected assets as chunks of XML. When it first retrieves the XML, the tool can use the default actionGroup for all of its collection functions. By default, the DOCT uses the getPreview action to display the preview for the resource in the active collection pane (see Figure 5). If the view for the active collection is set to "Titles Only", the action getLabel is used to list the resource as a string of text. When the user right clicks on the resource in either view, a menu is offered that includes an "Image Description" choice. When that choice is made, the DOCT looks for an actionGroup named "metadata"; if found, DOCT uses the viewDescMetadata action from that group to display the descriptive metadata as HTML; if that UVa-specific group is not present, the tool uses the getDescription action from the default group to retrieve the DC metadata, which it then formats and displays in HTML.
The DOCT also has some image specific functionality built into it. A slide show function can be initiated for the active collection that displays the collection, either one image at a time or two side-by-side. It looks for the basicImage actionGroup and uses the getScreenSize action to display the image in the show. If that group is not present, the resource is skipped. The collection can also be saved as a set of linked web pages in one of three formats: thumbnail and metadata on each page, screen-sized image on each page, or the collection on pages with rows of thumbnails. In all cases, the HTML files are created with the URLs from the actionGroup inserted in the appropriate places, and saved to the user's machine. In the Aquifer experiment, all of the data providers submitted OAI records for image resources that included asset action sets with both the default and basicImage action groups. The OAI search interface that UIUC developed could be used to find image resources, which could then be collected by clicking on the thumbnail. A slideshow could be seamlessly created for collections drawn arbitrarily from the four providers.
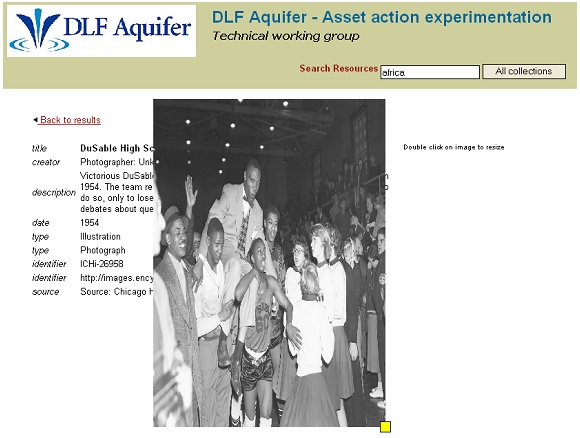
5 Key Features of the PortalThe asset actions portal [3] was built to demonstrate the sorts of functions that can be implemented in a distributed resource environment if pointers to different representations of an object (asset actions) are available to the service provider. The portal illustrates, in the context of cultural heritage image collections, what can be done when extended access to distributed resources is available instead of just access to aggregated metadata records. As anticipated by others [e.g., 14, 15], this sort of extended access to resources enables the building of real distributed digital libraries rather than just union digital library catalogs. 5.1 Functions based on multiple image formatsIn combination with the default asset actions defined for all resources, the asset actions defined for the basicImage class of resources include URLs for three distinct image formats (getThumbnail, getScreenSize, getMaxSize), a pointer to a dynamic view of the image in its original (data provider's) environment (getDynamicView), a pointer to a "Web" (presumably non-dynamic) view of the image in its original environment (getWebView), a label for displaying with the image (getLabel), and a pointer to a metadata record describing the image (getDCRecord). Each asset action includes the necessary information for displaying and knowing whether an application can work with an image (e.g., MIME type). The asset actions portal implements a number of features that take advantage of the multiple image views made available. A simple search box allows users to retrieve images based on harvested descriptive metadata (DC or MODS). The pointers to thumbnails support two display modes for results listings:
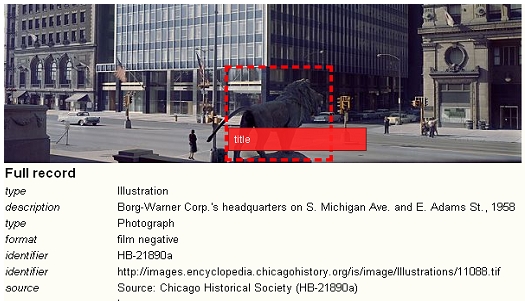
This second mode has proven very efficient for exploring image databases [16], but is less common in OAI-PMH implementations, because most current metadata formats (with notable exceptions of the recently released MODS version 3.2 and an extended qualified DC format promulgated by the National Library of Australia) do not allow data providers to unambiguously specify a URL for a thumbnail [17]. Both views of search results offer the user several options, including: "More info" (shows more information about the image, getDCRecord); "Go to Website" (takes user to the data provider's Website, getDynamicView); "Large view" (retrieves getScreenSize and getMaxSize views of the image); and "Add to Bag" (adds image to a session virtual book bag). The classic view of search results adds options that allow the user to annotate and resize the image dynamically. 5.2 Image manipulation and AnnotationThe resize image link allows the user to double-click on the image and then grab a corner to change its size and proportions (see Figure 6). The image can also be moved on the screen by clicking and dragging it. This function uses the Walterzorn Drag & Drop JavaScript Library [18]. It shows how, with simple URLs to appropriate image views, the user can actually move, modify, and manipulate a distributed image resource within the context of the service provider portal. Images may also be annotated. This feature relies on the getScreenSize asset action. A script allows a user to select a part of the picture. Once a selection has been made, an annotation may be entered in an HTML form. For example, in Figure 7 the selection shown could be annotated either as a Lion statue or described in context as the entrance of a building. The script that allows image portion selection and the creation of an annotation compliant with the Friend of a Friend (FOAF) image schema [19] was borrowed from the semantic Web community [20, 21, 22]. The annotation is saved by the service provider as an RDF record linked to the OAI identifier of the metadata for the image. If it is the first annotation, the DC description of the full image is imported using the getDCRecord asset action. The DC record is included in the RDF FOAF image record together with the selection coordinates and the corresponding annotation. Any other user can then add additional annotations for the image. These are appended to the existing FOAF image record.
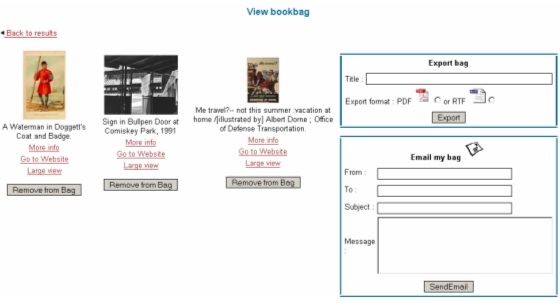
Subsequent users are provided with a "View annotations" option. This function displays prior image selections and their annotations as the user mouses over the image. Lower on the display, the annotated selections are displayed with their annotations. This demonstrates how the annotations stored on the service provider's (UIUC's) file system can be applied dynamically to images maintained remotely by data providers. 5.3 Sharing and exporting the image book bagThrough the portal, users also may dynamically generate documents based on digital object views accessible via asset action URLs. Currently this functionality is part of the portal session's virtual book bag feature. (Unlike the UVa DOCT, this aggregation is maintained on the server rather than by the client, and only for the duration of the search session.) Users may add resources to the book bag when viewing search results. Descriptions, thumbnails and links to resources added to a user's book bag may then be emailed. In addition, views and descriptions of resources added to the book bag may be output as a dynamically generated document in either Adobe PDF or Microsoft Rich Text Format (RTF). Figure 8 shows the interface for this feature. A number of possible usage scenarios can be envisioned for this sort of export. For example, the generated documents could be used as student handouts in a pedagogical setting, or they could be used as the foundation for a scholarly paper – or at least make the digital objects and select metadata accessible in a format that is easily copied and pasted into common document processing environment such as Microsoft Word or PowerPoint.
The script that processes these exports takes as input the title of the document, the format of the output desired (either PDF or RTF) and a list of getAssetDefinition URLs. Using the URLs, the script retrieves and concatenates XML nodes containing asset actions together into one large XML file. The script then applies a single XSLT transformation to this large XML file. This XSLT transforms the file into an XSL Formatting Objects (XSL-FO) file. XSL-FO defines how a document is styled, laid out, and paginated. This XSL-FO file is then processed using either the open source Apache FOP (Formatting Objects Processor) [23] or the commercial XMLmind FO Converter [24], which generate PDF or RTF, respectively. The XSLT that generates the XSL-FO utilizes various asset actions in order to retrieve information that is used to generate the PDF or RTF documents. The getScreenSize action provides the URL to the version of the image that is embedded in the final document. The getLabel action provides the URL to the label to be used with the embedded image in the document. The getDCRecord action provides the URL to the DC metadata from which additional data used in the report is extracted. 6.0 ConclusionsThis experiment has demonstrated that a set of named, typed actions for a resource can consistently expose the resource's characteristics and capabilities for use by Web-aware software tools in various ways. Applied to image objects, this method proved to be a relatively easy way for repository managers to contribute their content to an OAI service provider capable of brokering the use of distributed resources for a variety of applications. Obvious next steps involve extending what has been done for image objects to other types of content. Work is already underway to define action asset sets for texts, and definitions of sets for video and audio objects also are under discussion. Of particular interest are asset action sets for objects that aggregate other objects. For example, the asset actions for an object that represents a collection of images of a building could be used both to investigate the aggregation and to retrieve the asset actions for each of the related image objects. Some actions associated with certain types of objects may require the use of parameters, e.g., to specify which image from an aggregation of images of a building is of interest. More investigation regarding asset actions persistence, conditions of use, access control, and provenance also is needed. For example, a medium resolution view of an image resource might be generally available to all, while the maximum resolution view of that same image might require a user to authenticate before being allowed access. A content provider might be willing to allow a portal to use a screen size view of an image for an annotation service but not for a service that allows a user to edit and save a modified version of the image. Ideally, action typing should include or otherwise enable a service provider to discover in a machine-understandable way this sort of information – not just pertaining to the resource as a whole, but also specific to each view or dissemination of a resource, i.e., specific to each asset action associated with a resource. New work within the context of DLF Aquifer is planned to address asset action sets for other types of content and to consider other facets of typing asset actions for digital resources. Notes and References1. Sarah L. Shreeves and Christine M. Kirkham (2004). Experiences of Educators Using a Portal of Aggregated Metadata. Journal of Digital Information 5 (3). Available at <http://jodi.tamu.edu/Articles/v05/i03/Shreeves/>. 2. Gregory J. L. Tourte (undated). ePrints UK Technical Documentation, pp. 13-14. Available at <http://www.rdn.ac.uk/projects/eprints-uk/docs/technical/eprints-tech-report.pdf>. 3. Asset Actions - Manipulating distributed digital library objects. Available at <http://rama.grainger.uiuc.edu/assetactions/>. 4. About VUE. Available at <http://vue.tccs.tufts.edu/about/index.cfm>. 5. K. Kott, J. Dunn, M. Halbert, L. Johnston, L. Milewicz, and S. Shreeves (2006). Digital Library Federation (DLF) Aquifer Project. D-Lib Magazine 12 (5). Available at <doi10.1045/may2006-kott>. 6. DLF Aquifer: Bringing collections to life through the Digital Library Federation. Available at <http://www.diglib.org/aquifer/>. 7. Katherine Kott., Perry Willet, Kat Hagedorn, Jon Dunn, Thomas Habing, Thornton Staples (2006). DLF Aquifer: Phase I Accomplishments. Presented at DLF Spring Forum, Austin, Texas, April 10-12, 2006. Available at <http://www.diglib.org/forums/spring2006/presentations/aquifer0406.htm>. 8. XML Schema. Available at <http://www.w3.org/XML/Schema>. 9. More prescriptive XML Schema for action assets. Available at <http://gita.grainger.uiuc.edu/AquiferTechWG/assetactions-v1.3b.xsd>. 10. Indiana University. Charles W. Cushman Photograph Collection. Available at <http://www.dlib.indiana.edu/collections/cushman/>. 11. OAI at the Institute for Science Networking. Available at <http://physnet.uni-oldenburg.de/oai/>. 12. Gregory Crane 2000. Designing documents to enhance the performance of digital libraries: Time, space, people and a digital library of London. D-Lib Magazine 6 (7/8). Available at <doi:10.1045/july2000-crane>. 13. Leslie Johnson (2005). Development and Assessment of a Public Discovery and Delivery Interface for a Fedora Repository. D-Lib Magazine 11 (10). Available at <doi:10.1045/october2005-johnston>. 14. D. Hillmann, N. Dushay, J. Phipps (2004). Improving Metadata Quality: Augmentation and Recombination. In DC 2004. 15. C. Lagoze, D. Krafft, T. Cornwell, N. Dushay, D. Eckstrom, J. Saylor (2006). Metadata aggregation and "Automated digital libraries:" a retrospective on the NSDL experience. In JCDL 2006. 16. Michelle Dalmau (2003). Charles W. Cushman Photograph Collection: Report on the Group and Individual Walkthrough. Available at <http://www.letrs.indiana.edu/~mdalmau/cushman/prototype/designDocs/cushWalkFinalReport.pdf>. 17. M. Foulonneau, T. H. Habing, T. W. Cole (2006). Automated Capture of Thumbnails and Thumbshots for Use by Metadata Aggregation Services. D-Lib Magazine 12 (1). Available at <doi:10.1045/january2006-foulonneau>. 18. Walterzorn Drag & Drop JavaScript Library. Available at <http://www.walterzorn.com/dragdrop/dragdrop_e.htm>. 19. Friend Of A Friend Vocabulary specification (2005). Available at <http://xmlns.com/foaf/0.1/>. 20. Web Kanzaki (2004). Image description 2004. Available at <http://www.kanzaki.com/works/2004/imgdsc/0106.html>. 21. Web Kanzaki (2003). Image description roundtrip. Available at <http://www.kanzaki.com/docs/sw/img-descr20030827.html>. 22. Web Kanzaki (2003). Image annotator. Available at <http://www.kanzaki.com/docs/sw/img-annotator.html>. 23. Apache FOP (Formatting Objects Processor). Available at <http://xmlgraphics.apache.org/fop/>. 24. XMLmind FO Converter. Available at <http://www.xmlmind.com/foconverter/>. Copyright © 2006 Robert Chavez, Timothy W. Cole, Jon Dunn, Muriel Foulonneau, Thomas G. Habing, William Parod, and Thornton Staples |
||||
| |
||||
|
Top | Contents | ||||
| | ||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/october2006-cole
|