 |
D-Lib Magazine
November/December 2014
Volume 20, Number 11/12
Table of Contents
Towards Semantometrics: A New Semantic Similarity Based Measure for Assessing a Research Publication's Contribution
Petr Knoth and Drahomira Herrmannova
KMi, The Open University
{petr.knoth, drahomira.herrmannova}@open.ac.uk
doi:10.1045/november14-knoth
Printer-friendly Version
Abstract
We propose Semantometrics, a new class of metrics for evaluating research. As opposed to existing Bibliometrics,Webometrics, Altmetrics, etc., Semantometrics are not based on measuring the number of interactions in the scholarly communication network, but build on the premise that full-text is needed to assess the value of a publication. This paper presents the first Semantometric measure, which estimates the research contribution. We measure semantic similarity of publications connected in a citation network and use a simple formula to assess their contribution. We carry out a pilot study in which we test our approach on a small dataset and discuss the challenges in carrying out the analysis on existing citation datasets. The results suggest that semantic similarity measures can be utilised to provide meaningful information about the contribution of research papers that is not captured by traditional impact measures based purely on citations.
Keywords: Citation Analysis, Research Evaluation, Semantic Similarity, Research Publication Datasets
1. Introduction
Ever since the idea of using citations for research evaluation was introduced [Garfield, 1955], citation analysis has received a lot of attention and many theories and measures based on citations have been produced. Citation analysis has become the de-facto standard in the evaluation of research. Among the main advantages of evaluating papers based on the number of citations they received is the simplicity of such measures and the (relatively) good availability of the citation data for such purposes.
However, citations are one of many attributes surrounding a publication and by themselves provide an insufficient evidence of impact, quality and research contribution. This is due to a wide range of characteristics they exhibit, including the variations in sentiment (positive, negative), the semantics of the citation (comparison, factual information, definition, etc.), the context of the citation (hypothesis, analysis, result, etc.) and the motives for citing [Nicolaisen, 2007], the popularity of topics and the size of research communities [Brumback, 2009; Seglen, 1997], the time delay for citations to show up [Priem and Hemminger, 2010], the skewness of their distribution [Seglen, 1992], the difference in the types of research papers (theoretical paper, experimental paper, case, survey) [Seglen, 1997] and finally the ability to game/manipulate citations [Arnold and Fowler, 2010; PLoS Medicine Editors, 2006].
The last decade has seen a steady growth of research aimed at finding new approaches for the evaluation of research publications, such as Webometrics [Almind and Ingwersen, 1997] and Altmetrics [Priem, et al., 2010], which rely on usage data instead of citations. The traditional research strand has focused on mitigating the issues related to the use of citations for impact assessment. For example, a recent study analysed the distribution of citations within scientific documents with regard to the traditional IMRaD structure (Introduction, Methods, Results and Discussion) [Bertin, et al., 2013]. Other researchers have used full-text to predict future influence of papers [Yan, et al., 2012] or to evaluate research proposals [Holste, et al., 2011]. [Glenisson, et al., 2005] have compared full-texts and abstracts of articles for clustering tasks and developed a hybrid approach for mapping scientific articles using both full-text and classical bibliometric indicators. In parallel to this work, the Open Access movement has recently brought a change making it possible to freely access and analyse full-texts of research articles on a massive scale, creating new opportunities for the development of impact metrics.
In this paper, we present an approach for assessing the impact of a paper based on its full-text (Section 2). In this context, we use the term impact to refer to the research contribution to the discipline, which we believe is independent of the number of interactions in a scholarly communication network, but depends primarily on the content of the manuscript itself. We propose to call the class of methods using full-text to assess research value Semantometrics. Based on this assumption, we developed a formula for assessing the research contribution of a paper and empirically tested it on a small data set (Section 4). Furthermore, we analyse existing publication datasets, describe their limitations for developing new metrics based on full-text (Section 3) and discusses the challenges in developing datasets without these limitations (Section 4).
2. Hypothesis
Our hypothesis is based on the premise that the publication's full-text is needed to assess the publication's impact. While this might sound trivial, to the best of our knowledge no automated impact metric has utilised the full-text so far. Our hypothesis states that the added value of publication p can be estimated based on the semantic distance from the publications cited by p to the publications citing p. This hypothesis is based on the process of how research builds on the existing knowledge in order to create new knowledge on which others can build. A publication, which in this way creates a "bridge" between what we already know and something new which will people develop based on this knowledge, brings a contribution to science. A publication has a high contribution if it creates a "long bridge" between more distant areas of science.
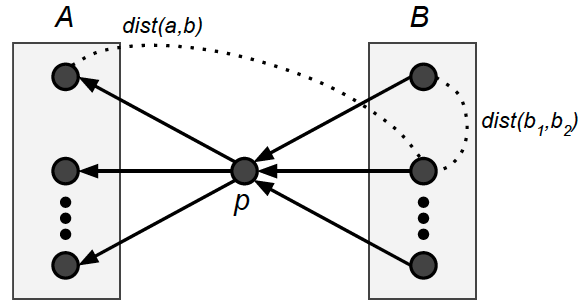
Figure 1: Explanation of Contribution(p) calculation.
Building on these ideas, we have developed a formula assessing the publication's contribution, which is based on measuring the semantic distance between publications cited by p to the publications citing p.
The numerator and denominator in the first fraction of the formula are calculated according to the following equation.
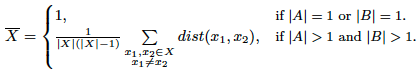
In the formula, B is the set of publications citing publication p and A is the set cited by p (Figure 1). The sum in the equation is used to calculate the total distance between all combinations of publications in the sets A and B. It is expected that the distance is estimated using semantic similarity measures on the full-text of the publications, such as with cosine similarity on tf-idf document vectors. Currently, we are experimenting with a range of these methods. The second fraction in the equation is a normalisation factor adjusting for all the combinations between members of the sets A and B, which results in an average distance between members of the two sets. The first fraction in the above equation is another normalisation factor, which is responsible for adjusting the contribution value to a particular domain and publication type. It is based on measuring the average inner distance of publications within the sets A and B.
The underlying idea is that, for example, in the case of a survey paper, it is natural that publications within the set A and also within the set B will be spread quite far from each other. However, this is not a sign of the paper's contribution, but rather a natural feature of a survey paper. On the other hand, we believe that if a paper uses ideas from a narrow field, but has an impact on a very large field, it is a sign of the paper's contribution. In both cases, the first fraction of the formula appropriately adjusts the value of the metric.
In practical terms, our method for assessing the contribution of a paper means that a paper with high impact does not need to be extensively cited, however it needs to inspire a change in its domain or even define a new domain. This can be manifested by the changes in the vocabulary which are the result of a specific publication. Consequently, a very active scholarly debate about a survey paper in a specific subject generating many citations will have a lower impact than a paper developing a new strand of research. An important feature of this idea is that our method does not require as long delay for assessment as the widely used citation counts (typically decades) and can be therefore applied also to fairly young researchers. It is hard to manipulate, it respects that scientific communities have different sizes in different disciplines, it is not focused on the quantity of publications as the h-index, but rather on the qualitative aspects. Experimenting with such measures was not possible in the past as there was, to the best of our knowledge, no collection that would combine the information on citations with the access to the full-texts.
3. Analysing Publication Datasets
In order to test our hypothesis, it was necessary to acquire a dataset which would meet the following criteria:
Availability of full-text is a prerequisite for testing our hypothesis as the calculation of similarity requires this information.
Density of the citation network refers to the proportion of references and citation links for which we can find articles and access their full-texts. This requirements has proved to be hard to satisfy. In order to carry out a representative test of our hypothesis, it was necessary to ensure that our dataset contains a significant proportion of articles citing a publication as well as documents cited by the publication. If a mean number of references per publication is ≈ 40 [Abt and Garfield, 2002], then the complete set of publications needed for the assessment of contribution of one publication would consist of 80 publications (we can expect the mean number of received citations will be approximately the same as mean number of references). If we wanted to examine the contribution of 100 publications, we would need a set of ≈ 8000 articles. Obtaining such set is time consuming due to restrictions on machine access to publications and subscription access rights.
Multidisciplinarity is important due to the assumption that transferring knowledge between different research areas is an indication of a publication's research contribution. As a consequence, the dataset to test our hypothesis needs to contain a significant proportion of articles cited by the publication under evaluation as well as articles referencing the publication, and primarily those from different subject areas.
Our original expectation was that we will be able to find a subset of publications satisfying all our criteria within the Open Access domain. For this reason we used the CORE [Knoth and Zdráhal, 2012] dataset, which provides access to research papers aggregated from Open Access repositories and journals. However, as many references and citations are still from subscription based (non Open Access content CORE cannot legally aggregate), we found the citation network too sparse for the purposes of our evaluation. However, we believe the situation will soon improve due to the government mandates ratified in many countries worldwide requiring the publishing of publicly funded research through the Open Access route. Consequently, we have experimented with enlarging the dataset by automatically downloading missing Open Access documents from the publishers' websites. However, we have found this task to be very difficult to accomplish due to a wide range of restrictions imposed by publishers on machine access to (even Open Access) publications hosted in their systems. [Knoth, et al.,
2014]
We have therefore analysed several other datasets, in particular the Open Citation Corpus, the ACM dataset and the DBLP+Citation dataset. Although these datasets provide data from different scientific disciplines, none of them contains publications' full-texts and for this reason none of them could be used.
Furthermore we have examined the KDD cup dataset and the iSearch collection. Both datasets are subsets of the physics section of ArXiv database and contain full-texts and citations. The KDD dataset contains around 29,000 while the iSearch collection contains 150K PDFs. Unfortunately, both datasets cover only one discipline making them unsuitable for our experiment.
4. Experiment
With no existing dataset suitable for our task, we have decided to create a new small dataset meeting all the above mentioned criteria. This dataset was created by manually selecting 10 seed publications from the CORE dataset with varying level of citations in Google Scholar. Articles cited by these publications and referencing these publications that were missing in CORE were downloaded manually and added to the dataset. Only documents for which we found a freely accessible online version were included. Publications which were not in English were removed from the data set as our similarity calculation technique was not developed to deal with multilinguality. Table 1 below provides a list of the 10 publications with the number of downloaded English documents. In total we were able to download 62% of all documents found as direct neighbours of the seed documents in the citation network. After removing non-English articles, the set was reduced to 51% of the complete citation network. The whole process took 2 days and the resulting dataset contains 716 PDF documents in total.
| No. |
Title |
Authors |
Year |
|B| (Cit. score) |
|A| (No. of refs) |
Contrib. |
| 1 |
Open access and altmetrics: distinct but complementary |
Ross Mounce |
2013 |
5 (9) |
6 (8) |
0.4160 |
| 2 |
Innovation as a Nonlinear Process, the Scientometric Perspective, and the Specification of an "Innovation Opportunities Explorer" |
Loet Leydesdor, Daniele Rotolo and Wouter de Nooy |
2012 |
7 (11) |
52 (93) |
0.3576 |
| 3 |
Ranking of library and information science researchers: Comparison of data sources for correlating citation data, and expert judgments |
J.A. Li, et al. |
2010 |
12 (20) |
15 (31) |
0.4874 |
| 4 |
The Triple Helix of university-industry-government relations |
Loet Leydesdor |
2012 |
14 (27) |
27 (72) |
0.4026 |
| 5 |
Search engine user behaviour: How can users be guided to quality content? |
Dirk Lewandowski |
2008 |
16 (30) |
12 (21) |
0.5117 |
| 6 |
Revisiting h measured on UK LIS and IR academics |
M. Sanderson |
2008 |
25 (41) |
8 (13) |
0.4123 |
| 7 |
How journal rankings can suppress interdisciplinary research: A comparison between Innovation Studies and Business & Management |
Ismael Rafols, et al. |
2012 |
39 (71) |
70 (128) |
0.4309 |
| 8 |
Web impact factors and search engine coverage |
Mike Thelwall |
2000 |
53 (131) |
3 (10) |
0.5197 |
| 9 |
Web Science: An Interdisciplinary Approach to Understanding the Web |
James Hendler, et al. |
2008 |
131 (258) |
22 (32) |
0.5058 |
| 10 |
The Access/Impact Problem and the Green and Gold Roads to Open Access: An Update |
Steven Harnad, et al. |
2004 |
172 (360) |
17 (20) |
0.5004 |
| |
|
|
|
474 (958) |
232 (428) |
|
Table 1: The dataset and the results of the experiment. The documents are ordered by their citation score. The numbers outside of brackets represent the number of documents in English which were successfully downloaded and processed. The numbers in brackets represent the size of the full set. The last column shows the contribution score. The dataset can be downloaded here.
We have processed these articles using the CORE software and have produced the contribution score for the seed documents. This has been done in two steps:
- We extracted text from all the PDFs using a text extraction library (Apache Tika).
- We calculated the contribution score using the cosine similarity measure on tf-idf term-document vectors [Manning, et al., 2009] created from the full-texts as means for calculating the contribution score.
More precisely, the distance used in the contribution score was calculated as dist(d1, d2) = 1 — sim(d1, d2), where sim(d1, d2) is the cosine similarity of documents d1 and d2 (the 1 — sim(d1, d2) value is often referred to as distance although it is not a proper distance metric as it doesn't satisfy the triangle inequality property).
The results for each of the 10 documents can be found in Table 1 above. It is interesting to notice there are quite significant differences between the contribution score of publications with very similar citation scores. A closer analysis showed
that our approach helps to effectively filter out self citations to similar work or more precisely gives little credit for them. Also, the publication with the highest citation score does not have the highest contribution score, in fact its contribution score is lower than that of a publication which is cited ten times less. We argue that this indicates that publications with a fairly low citation score can still provide a high contribution to science.
Figure 2 shows a comparison of the contribution score with citation score and with the number of references. The line in each of the plots shows a linear model fit. It can be observed that the contribution score slightly grows with the increasing number of citations. This is an expected behaviour, because the likelihood that a publication provides a high contribution to a number of topics and disciplines generally increases with the citation count, however they are not directly proportional. For instance, we can find publications in the dataset with a lower citation score and a relatively high contribution score. This shows that even publications with low citation score can provide a high contribution to research. On the other hand, with the increasing number of references the contribution score slightly decreases. This shows that increasing the number of referenced documents cannot be used to directly influence the contribution score.
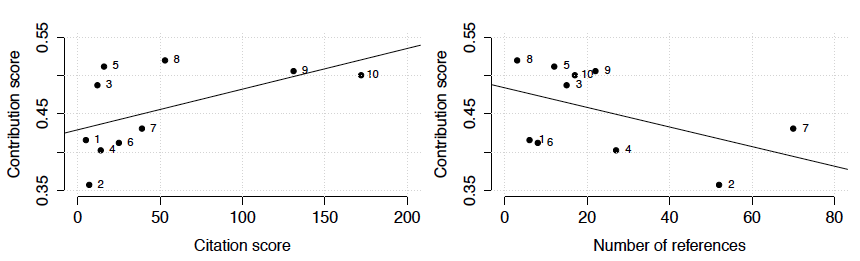
Figure 2: Comparison of the contribution score with citation score and with number of references.
5. Discussion and Conclusions
The use of the current research publications performance metrics (Bibliometrics, Altmetrics, Webometrics, etc.) is, in our opinion, based on a false premise that the impact (or even quality) of a research paper can be assessed purely based on external data without considering the manuscript of the publication itself. Such assumption resembles the idea of judging a lawsuit without the suspect having the opportunity of being in court and is consequently flawed in the same way. We showed that new measures of impact taking into account the manuscript of the publication can be developed. We believe that this idea offers a lot of potential for the study of this class of measures, which we call Semantometrics. The results of our pilot study indicate that our measure based on semantic similarity of publications in the citation network is promising and should be further analysed on a larger dataset.
Furthermore, we have demonstrated the importance of developing datasets on which this class of measures can be tested and explained the challenges in developing them. The primary issue is the citation data sparsity problem, which is a natural consequence of publications referencing work from different disciplines and across databases. As systems created by organisations that have bespoke arrangements with publishers, such as Google Scholar, do not share the data, there is a need for open data providers to join forces creating a single dataset spanning all scientific disciplines. Overall, we believe this situation demonstrates the need for supporting Open Access to research publications not only for humans to read, but also for machines to access. This issue is especially current as the UK copyright exception for text-mining has been recently agreed by the parliament and came into effect in June 2014 [Hargreaves, 2011; Intellectual Property Office, 2014], creating new opportunities for the development of innovative services.
References
[1] Helmut A. Abt and Eugene Garfield. 2002. Is the Relationship Between Numbers of References and Paper Lengths the Same for All Sciences? Journal of the American Society for Information Science and Technology, 53(13):1106-1112. http://dx.doi.org/10.1002/asi.10151
[2] Tomas C. Almind and Peter Ingwersen. 1997. Informetric analyses on the world wide web: methodological approaches to "webometrics". Journal of Documentation, 53(4):404-426. http://dx.doi.org/10.1108/EUM0000000007205
[3] Douglas N Arnold and Kristine K Fowler. 2010. Nefarious numbers. Notices of the American Mathematical Society,
58(3):434-437.
[4] Marc Bertin, Iana Atanassova, Vincent Lariviere, and Yves Gingras. 2013. The distribution of references in scientific papers: An analysis of the IMRaD structure. In Proceedings of the 14th ISSI Conference, pages 591-603, Vienna, Austria.
[5] Roger A Brumback. 2009. Impact factor wars: Episode V — The Empire Strikes Back. Journal of Child Neurology, 24(3):260-2, March. http://doi.org/10.1177/0883073808331366
[6] The PLoS Medicine Editors. 2006. The impact factor game. PLoS medicine, 3(6), June. http://dx.doi.org/10.1371/journal.pmed.0030291
[7] Eugene Garfield. 1955. Citation indexes for science. A new dimension in documentation through association of ideas. Science,
122(3159):108-11, October. http://dx.doi.org/10.1126/science.122.3159.108
[8] Patrick Glenisson, Wolfgang Glanzel, and Olle Persson. 2005. Combining full-text analysis and bibliometric indicators. A pilot study. Scientometrics, 63(1):163-180. http://doi.org/10.1007/s11192-005-0208-0
[9] Ian Hargreaves. 2011. Digital Opportunity: A review of Intellectual Property and Growth. Technical report.
[10] Dirk Holste, Ivana Roche, Marianne Hörlesberger, Dominique Besagni, Thomas Scherngell, Claire Francois, Pascal Cuxac,
and Edgar Schiebel. 2011. A concept for Inferring "Frontier Research" in Research Project Proposals. In Proceedings of the 13th ISSI, pages 315-326, Durban, South Africa.
[11] Intellectual Property Office. 2014. Implementing the Hargreaves review.
[12] Petr Knoth and Zdenek Zdráhal. 2012. Core: Three access levels to underpin open access. D-Lib Magazine, 18(11/12). http://doi.org/10.1045/november2012-knoth
[13] Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze. 2009. An Introduction to Information Retrieval. Cambridge University Press, online edition.
[14] Jeppe Nicolaisen. 2007. Citation Analysis. Annual Review of Information Science and Technology, 41(1):609-641. http://doi.org/10.1002/aris.2007.1440410120
[15] Jason Priem and Bradely M. Hemminger. 2010. Scientometrics 2.0: Toward new metrics of scholarly impact on the social
Web. First Monday, 15(7), July.
[16] Jason Priem, Dario Taraborelli, Paul Groth, and Cameron Neylon. 2010. Altmetrics: A manifesto.
[17] Per Ottar Seglen. 1992. The Skewness of Science. Journal of the American Society for Information Science, 43(9):628-638, October.
[18] Per Ottar Seglen. 1997. Why the impact factor of journals should not be used for evaluating research. BMJ: British Medical Journal, 314(February):498-502. http://dx.doi.org/10.1136/bmj.314.7079.497
[19] Rui Yan, Congrui Huang, Jie Tang, Yan Zhang, and Xiaoming Li. 2012. To Better Stand on the Shoulder of Giants. In Proceedings of the 12th Joint Conference on Digital Libraries, pages 51-60, Washington, DC. ACM. http://dx.doi.org/10.1145/2232817.2232831
[20] Knoth, P., Rusbridge, A. and Russell, R. (2014), Open Mirror Feasibility Study, Appendix A: Technical Prototyping Report, Jisc report.
About the Authors
 |
Petr Knoth is a Research Fellow at the Knowledge Media institute, Open University. He is interested in topics in Natural Language Processing, Information Retrieval and Digital Libraries. He is an Open Access and Open Science enthusiast — believing in free access to knowledge for everybody and in the development of more effective means of exploiting this knowledge. He acknowledges the necessity of migrating towards better research practices and criticises narrow-minded methods for evaluating research excellence. Petr is the founder of the CORE system for aggregating and mining Open Access content and has led the CORE family of projects (CORE, ServiceCORE, DiggiCORE, UK Aggregation). He was also involved in a number of European Commission funded (Europeana Cloud, KiWi, Eurogene, Tech-IT-Easy, Decipher, FOSTER) as well as UK national (RETAIN, OARR) projects.
|
 |
Drahomira Herrmannova is a Research Student at the Knowledge Media Institute, Open University, working under the supervision of Professor Zdenek Zdrahal and Mr Petr Knoth. Her research interests include bibliometrics, citation analysis, research evaluation and natural language processing. She completed her BS and MS degrees in Computer Science at Brno University of Technology, Czech Republic. Aside of her PhD she participated in research projects at the Knowledge Media Institute (CORE, OU Analyse).
|
|