 |
D-Lib Magazine
November/December 2011
Volume 17, Number 11/12
Table of Contents
A Semantic Registry for Digital Library Collections and Services
|
James E. Powell
Los Alamos National Laboratory
jepowell@lanl.gov
|
Krista Black
Los Alamos National Laboratory
krista@lanl.gov
|
Linn Marks Collins
Los Alamos National Laboratory
linn@lanl.gov
|
doi:10.1045/november2011-powell
Printer-friendly Version
Abstract
The Semantic Web has to date promised far more than it has been able to deliver. Libraries have been understandably cautious about investing extensively in ontology creation, mapping data to semantic representations, or tackling the hard problems of semantically describing collections and services. We look at the evolution of network addressable services, to service oriented architectures, and now toward semantically enhanced service oriented architectures. We also investigate various library technology standards that might influence semantic service and collection descriptions, as well as semantic registries. Next, we describe our own efforts to build a semantic registry of services and collections, for semantic metadata collections. Finally, we speculate about how these standards may evolve in the future.
Introduction
Excitement during the first decade of the Web spawned speculation that future software, combined with a new open data model, would enable applications that could schedule a vacation for you, proactively monitor your house while you are away, or perform extensive information retrieval tasks without supervision.[1] This type of technology was also expected to revolutionize Library technology by offering better information retrieval and analysis capabilities, with some experts envisioning these tasks performed by smart software agents. However, these scenarios have yet to be fulfilled.
In reality, there are complex problems to overcome in order for this vision to become a reality. A technology that may help realize this vision is a registry — a repository of specialized data that describes datasets and the functionality of various network-addressable services (such as Web services). But a registry is not enough; the registry must accommodate semantic descriptions for data sets and services. These would describe what a dataset contains, and what a service does, in a machine comprehensible form. A semantic registry could enable adaptive and unsupervised process orchestration; that is, selection and synchronous or asynchronous chaining of discrete tasks to solve a complex problem.
This paper highlights some of the developments and challenges in developing registries. We then discuss how the Los Alamos National Laboratory's Research Library used current standards, including the Information Environment Service Registry (IESR) [2] and Research Support Libraries Programme Collection Description (RSLPCD) [3] elements, in an ad-hoc ontology to semantically describe services and collections.
An Example Web Service
Many tasks can be performed online via Web services, which are discrete network-accessible software capabilities. A Web service typically requires input parameters and returns a response based upon the work that was performed with those parameters. Consider a REST-based zip code lookup Web service, accessible via a URL at http://myserver.com/zipcode. This service requires at least city and state parameters and optionally accepts a street address. A minimal request might look like this:
http://myserver.com/zipcode?city=los+alamos&state=New+Mexico
Since there is only one zip code for Los Alamos, NM, it returns: 87544. Behind the scenes, this service may have performed a SQL query against a relational database it has access to, or queried another service such as geonames.org, to retrieve the requested information. In order to use the service, users (programmers) must know its web address, what parameters it needs, the parameter types (e.g., integer, data, string, etc.), and what kind of data the service returns. A syntactic (e.g., XML) interface description, such as a Web Application Description Language (WADL) [4] file for the service, can answer those questions. SOAP (Simple Object Access Protocol) [5] and WSDL (Web Services Description Language) [6] provide a more feature rich model for accomplishing essentially the same thing.
Where Are the Registries?
In the above example, the service described might be of interest to many developers, but how would they discover it? One option is a Web page describing the service and another is a registry containing service metadata, interface descriptions, and other the information that users need in order to access and effectively use the service. A registry can point users to these interface descriptions and services. But registries are not common. Systems based on a Service Oriented Architecture (SOA) [7] chain a series of services together, but they usually have an internal registry which is tightly coupled to the environment. Other systems use a process called choreography, in which a set of services that solve a given problem have some awareness of one another, making them interdependent. The rarity of registries and registry standards, and the closed nature of service-oriented environments illustrates that registries have not yet matured.
Despite the paucity of registries and registry standards, there are some examples worth mentioning. Rather than provide an exhaustive survey, we will look briefly at service frameworks and then focus on two broad categories of problems where registries have been employed: 1) registries that expose services, and 2) registries that expose data and collections, or, as the problem has been referred to in libraries, collections and their catalogs.
Exposing Services
Distributed service architectures to take advantage of networks emerged as soon as computers could communicate with one. Standards such as CORBA (Common Object Request Broker Architecture) and RPC (Remote Procedure Calls) provide basic means for application components to communicate over a network and between computers, as did Java's RMI (Remote Method Invocation) library. These technologies assumed the services they accessed were known, trusted, and well-documented. So there typically was no service registry where services were described and published, since there was no compelling need for one. Web services leverage Web protocols to provide Web addressable executable applications, allowing for RPC-like functionality over the Web. The earliest examples are CGI programs, executed by the Web server, and addressable via a Web form or URL from a Web browser. SOAP and REST services are more common now.
In the library world, Z39.50 was developed as a comprehensive protocol to describe search and retrieval services for catalogs of metadata. There were enough Z39.50 services to merit work on catalogs for them. ZeeRex, was developed specifically to address that need. SRW/SRU are library-developed SOAP and REST-based models for accomplishing essentially the same task and exposing them as Web services. [8]
Content discovery and negotiation services such as the OpenURL represent another type of service. OpenURL connects users to subscription-based content by leveraging local metadata as input parameters to the resolver service. [9] OpenURL and the link resolver model are successful because specific metadata about the item that is being sought such as title, author name, publication date, or unique object identifier are available, and provide enough information to find some version of the object the user wants to retrieve. Still another common digital library service is OAI-PMH. OAI harvesting targets expose locally managed collections of metadata, such as that found in digital object repositories.
Digital object repositories are designed to handle curation, discovery, and rendering of digital objects into perpetuity. Fedora was designed with some crucial abstractions that return the focus to data, while enabling modular and adaptable services. [10] It is a distributed object oriented repository architecture that builds upon the notion of data and object models. Software tools called disseminators play a crucial role in exposing data to users. Behaviors refer to how services and data come together in the repository to support user activities. A digital object is also a datastream, aggregations become collections and collections of collections. A baseline METS (Metadata Encoding and Transmission Standard)-based metadata description is associated with objects, but search is merely one of the many capabilities of Fedora. Fedora has a distinct advantage over generic service oriented architecture. It was designed to accommodate undefined and as yet unknown data types, and web browsers and devices, with ease. Client functionality could be delivered from server-side disseminator code, or implemented in true-client server fashion to take advantage of the distinct capabilities of a web browser or device. Fedora embraces an object-oriented model, which bundles data with services. The different types of data output from e-science (raw, research, reference), as well as the unique metadata requirements and perhaps the need to search the data itself, continue to drive the development of open, standards compliant, modular and dynamically composable (SOA-like) architectures.
Exposing Collections and Datasets
Libraries obviously have an interest in data-oriented registries, because they provide searchable metadata collections and digitized content. [11] Search engine providers have also become involved in developing standards for describing access to collections of data. Many businesses are less interested in general purpose exposition of their data, either for privacy or proprietary reasons. Even so, library catalogs and databases remain disconnected and poorly described, in part because of the scope of the problem. This has become more of an issue in recent years as libraries have tried to provide unified services to users via techniques such as metasearch.
OpenSearch [12] is a collection of technologies that provide a method for publishing search results in a standard format. It is used to describe a searchable collection, as well as the interface for searching that collection. Preservation interests and content digitization have surfaced other considerations for registries, including descriptions for software for rendering data. In those cases, it is important to describe the format of the data and identify renderers either explicitly, or via compatibility requirements. Even Web browsers and servers have influenced this domain, with the MIME type specification and content negotiation feature of the HTTP protocol underlying the Web. A library-centric standard for registries, ISO 2146 [13], attempts to capture not only the core registry functionality (service descriptions), but other "roles" that can be assumed in digital library transactions, including activities, parties, and collections.
Registries
With the advent of Web services, the service registry became more important, because exposing a service is only half the battle — you also have to publish it. Microsoft championed one of the few registry standards, Universal Discovery Description and Integration (UDDI) [14], to support the discovery and integration of discrete services, which never gained much traction. The problem with centralized registries is that it is difficult to build a business model to support them. Services come and go, some have very restrictive access policies, or frequently changing interfaces, so registry content rapidly falls out of date. The ORCA project, the OCKHAM registry, and JISC 's Information Environment Service Registry are some examples of library service registries. Two of these are no longer fully functional and the third (IESR) is more focused on connecting users or would-be discovery service aggregators, such as administrators of portals, metasearch tools, or IMS (Instructional Management Systems) with the public Web interfaces to resources [15].
The ORCA project utilized ISO 2146. This standard focused on various digital and traditional library workflow problems, many of which involved metadata and searching. The standard identified four registry object types: collections, parties, activities, and services. Registry entries were intended to expose objects describing these entities, and facilitate their use in providing library services to patrons through interlibrary loan, online search, metasearch tools, and portals. The level of specificity it supports tends to limit its application to the library services domain, rather than to the larger problem of generalized service registries. The design allows for the use of other standards to support things like syntactic descriptions of data and service access policies (XACML) and external authentication solutions. It does not seem to anticipate the possibility of semantic registries.
Registries crop up in unexpected places, including, perhaps, in your own pocket. Android-based phones maintain a dynamic registry of services that have registered a specific capability [16]. Android is a Linux-based operating system developed for mobile devices by Google. Android's dynamic registry employs a model called "intents". Intent filters allow an application to indicate that it is either a provider or a consumer of a data type or service. Data or services are provided and accessed between applications without a provider or consumer having to have explicit knowledge of each other. For example, an application that wants to add an event to a user's calendar need not have knowledge of the specific calendar application an individual is using on their phone; it just needs to express intent to create events. Loose coupling within the Android OS facilitates data and resource sharing without the explicit formalization of a registry. Instead, Android automatically keeps track of capabilities registered by programs, and matches those with requests for functionality on an as-needed basis.
Registries containing syntactic descriptions for services and collections are useful if a human is available to make sense of parameters and parameter types, and write code that conforms to the interface requirements. However, if an application's goal is to find appropriate services, map between parameters that are similar, determine automatically how to match up the parameters it has with the requirements of the service, and to understand the response supplied by the service, the services and their interfaces need to be described semantically. A semantic registry description of the zip code service described earlier would include data about what a zip code actually is. It would express in some machine-comprehensible way that a zip code is a numeric or alpha-numeric value corresponding to a geographic region traditionally associated with mail delivery to residential and business locations. This would yield clues to applications and developers about when the service might be useful in fulfilling a particular information need.
A Semantically Enhanced Service Architecture (SESA) [17] would leverage semantic descriptions of services, which could be stored in a semantic registry. Registry entries would be goal-oriented, which means there needs to be a way to describe the task performed by a service. Entries would describe services with a sufficient level of granularity to enable mixing and matching of alternate services and to facilitate choreography of multiple services. Service entries would include semantic descriptions of service functionality, functional interface descriptions including semantics about inputs and outputs, and other semantics, such as the applicable knowledge domain of a service. Collection descriptions would be first-class entities in a semantic registry. There ought to be statements about the data that is available, as well as the services that can be used to explore it. A semantic registry might also provide a description of the quality of a given service, either through explicit quality statements or service-provided or crowd-sourced rating schemes. It might also describe mediators that can assist with data matching or conversion as needed. Finally, the best solution is both platform and programming language-agnostic, as adept at handling requests between far flung servers as it is negotiating between apps on a cell phone.
From a Syntactic to a Semantic Registry
Digital libraries contain both services and collections, and collection objects and even individual data elements can have services. Databases and catalogs remain notoriously difficult to describe, since they have diverse coverage and scope while representing entities in their own right [18]. That makes datasets, and especially library metadata collections, especially difficult to describe semantically. Library services are rarely componetized to the extent that they can be mixed and matched at different levels for different purposes. But like any information environment, discrete services can be of value. Outside of Fedora, JISC's IESR and RSLPCD standards represent the best efforts to tackle this problem in a library context, in a standard way. And although these standards are primarily syntactic, the creators were clearly anticipating their use in a semantic context.
In the two projects described below, the Los Alamos National Laboratory Research Library used elements from IESR and RSLPCD to describe services and collections. One project used a syntactic representation to describe services and collections, while the other uses the Semantic Web Resource Description Framework (RDF) to create a semantic registry. This semantic registry only tackles a few of the challenges enumerated above, but we found Semantic Web standards well-suited to describing collections and services, and relationships between them.
Oppie
In 2008, the LANL Research Library initiated a project to develop a digital library system that conformed to a number of commonly used standards in libraries and utilized a service oriented architecture model. The system was intended to provide end user access to a collection of approximately 93 million bibliographic records which described papers, reports, patents and other material. The records were in MARC XML format, stored in discrete collections corresponding to their sources, in an aDORe digital object repository. Librarians and developers working on the project decided to parse the records and index a subset of the bibliographic content using Apache's Lucene and Solr open source products. Various services exposed the indexed collections directly, or through orchestrated sequences of service calls via predefined workflows, that resulted in useful functionality being made available to the end user. Thus, one phase of the project involved developing a model for representing collections and services. Services and collections were described using elements from IESR and RSLPCD. The resulting "registry" was a large XML document containing all of these descriptions. It could be used by the Oppie system and its various services to make determinations regarding authorization of a user to access a service or collection, identify a collection, select appropriate services for a collection, and construct appropriate service requests against a given service.
 Figure 1: An Oppie collection description.
Figure 1: An Oppie collection description.
InfoSynth
InfoSynth was a project born out of requirements that differed markedly from the Oppie project. First, InfoSynth is designed to provide access to focused, topically specific collections of data. Data sources include the aforementioned aDORe repository, but also data from any OAI-PMH compliant repository, RSS news feed data, and other data sources where the content is encapsulated in XML elements, and can be readily mapped into a standard set of bibliographic style statements, such as <object> hasTitle "some title", <object> hasCreator "some author". These psuedo-code triples are a more human-friendly rendition of the actual data. XML data from these varied sources is collected per some criteria (e.g. a search result set, or filtered extraction based on keywords), and values are mapped into RDF triples. Predicates are selected from appropriate ontologies (FOAF, RDF Dublin Core), or (rarely) borrowed from existing XML schemas. In some cases, data is augmented via calls to external services, for example, to provide greater specificity regarding the location of a placename.
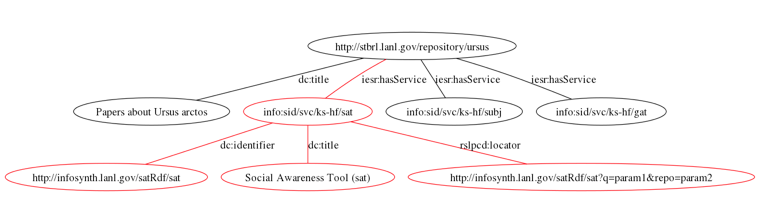 Figure 2: Partial graph of an InfoSynth collection and service entry.
Figure 2: Partial graph of an InfoSynth collection and service entry.
The result of these processes is a topical collection, normalized to RDF. It might be merged with data from other sources on the same topic. The resulting collection is presented as a discrete collection within the InfoSynth system. Various services allow the user to explore the data via textual search, overlayed onto maps, or as subgraphs representing a subset of nodes and edges concerned with a particular data element and relationships among them. But even more so than the Oppie project, this system needed a mechanism for describing these collections and specifying which services were appropriate for each collection. After all, a collection might represent the objects returned in response to a very complex query, or an aggregation of data from a number of different sources. Users might want to see how it was constructed, what the sources were, when it was assembled, or other information that would allow them to evaluate the utility of a collection for their purposes. Since sources are varied, some source data may lack an element common to other sources, such as authors, in which case it would be pointless to offer users a co-authorship visualization option for that collection.
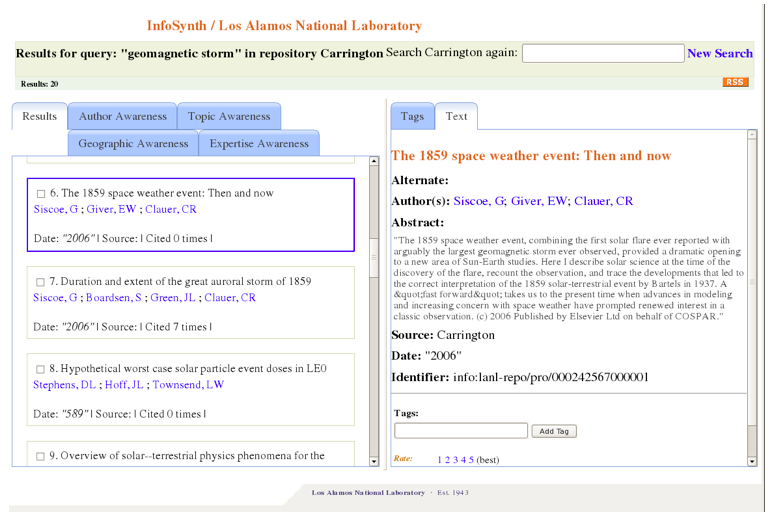 Figure 3: InfoSynth query in "Carrington" collection, with service tabs.
Figure 3: InfoSynth query in "Carrington" collection, with service tabs.
The requirements for a registry for InfoSynth were as follows:
- RDF-based, since all other data in the system was RDF and this allows code reuse when implementing support for the registry;
- Support for collection descriptions, including a label (for human consumption), a unique identifier, a description, and a responsible entity;
- Support for describing the source and basis for a collection, for example, the query or harvest that resulted in the items that reside in the collection, a date stamp, an indication of the extent (size) of the collection, and the primary language of the collection content;
- A mechanism for associating services with a collection;
- Support for describing services, e.g. service identifiers, labels, descriptions, service request URI, and link to optional, external service interface descriptions;
- Support for describing services with no association with any collections; and
- Capability to automatically generate a collection representation and dynamically add it to the registry when a new collection was created.
The resulting semantic registry borrows predicates for RDF statements from the RSLP RDF specification for collection descriptions, which the creators refer to as a "Dublin Core for collections" [19]. RSLP also uses an RDF representation of Dublin Core elements, and we do as well. Our registry descriptions also use elements from the IESR specification, which provides additional elements to describe electronic collections and their associated services. IESR does not include an RDF specification. It is a flat model, designed to be used with other metadata elements. Furthermore, the naming convention for properties is reminiscent of object property naming conventions for ontologies. Elements such as "hasService" are easy to identify and use as predicates within a semantic context, which is what we have done. The resulting vocabulary is more like a taxonomy than a full-fledged ontology. An ontological formalization of the approach (e.g. using RDFS/OWL) would be necessary to enable reasoning and more sophisticated uses.
While our registry solution does not address all the potential roles of a semantic registry, it is a functional and extensible example of some of the potential benefits. Registry contents support important capabilities for InfoSynth. Collection descriptions provide enough detail that a collection could be recreated, or refreshed using description data. Service associations determine what services a user will be able to use to explore a given collection within InfoSynth. For example, some of our collections have no authors, so there are no service associations defined, and thus no tools that support exploring co-authorship networks are provided for those collections. We similarly use information such as a triple describing a collection's primary language to manage modest UI adaptations, such as flowing text right to left in the case of middle eastern languages. Since the collections and their registry descriptions are both described using RDF, InfoSynth can actually support exploration of the registry entries directly, as if they were themselves a collection. Conversely, it is possible to treat a collection description and the collection it describes as a seamless entity (for example, as one large graph), though in practice, from a user perspective, differentiating between them is more intuitive.
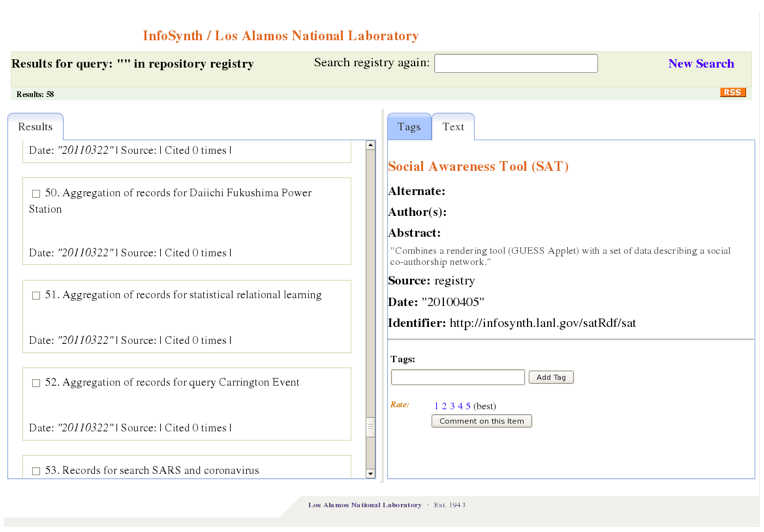 Figure 4: InfoSynth view of semantic registry entries.
Figure 4: InfoSynth view of semantic registry entries.
Service interface descriptions remain simplistic in both the syntactic representations in Oppie and the semantic representations in InfoSynth: services are assumed to be REST-based and a locator URL is specified for the service, which accepts parameters in anticipated positions, associated with expected names, and of known types. Much could be done to improve this, but in the case where most services are intended for use with semantic collections, this has proven to be an acceptable solution within InfoSynth, which handles the task of orchestrating service calls.
 Figure 5: RDF/XML serialization of a portion of an InfoSynth collection entry.
Figure 5: RDF/XML serialization of a portion of an InfoSynth collection entry.
Some type of SESA-based approach for service descriptions is necessary to fulfill the vision for a semantic registry. SESA standards are still in flux, with more than a half a dozen standards having been proposed over the last decade. Previous efforts had focused on adding support for semantic annotations to service descriptions (SAWDL, WSDL-S, WSDL 2) [20], developing a way to model semantics of processes (WSMO, WSML) [21], and ontology language extensions for representing a combination of service and process semantics (OWL-S) [22]. A more streamlined approach to associating meaning with services is SSWAP (Simple Semantic Web Architecture and Protocol) [23], which focuses primarily on semantically describing the inputs and outputs of discrete services, and exposing those descriptions via REST services. There are many SESA standards because this is a hard problem. It is tough to describe a service and what it does semantically, and shoehorn an approach into existing standards. And the approach has to be sufficiently expressive to support reasoning and use of rules to select services based on certain criteria, without so much complexity that it becomes computationally impossible to do so. Consider the zip code service described earlier, and then think about all the challenges associated with describing a zip code service so it could be found, called by another service with the semantically and syntactically appropriate input parameters, and integrated into a larger task by orchestrated by some unknown requester.
Semantic registries have several notable advantages over syntactic registries. They are extensible — a new fact about one or more services described in a semantic registry can simply be added to the registry. Semantic descriptions open the door to machine reasoning — a service or a framework executing a set of services could use rules to reason about the suitability of various services to solve a problem in the event that a particular service was not available. Reasoning would also enable loose coupling, and make complex applications less brittle, and less prone to failure. The challenge then becomes engineering an ontology suitable for the task, which may involve borrowing concepts from taxonomic/syntactic approaches such as ISO 2146, IESR, RSLPC, and others. In contrast to smart object models [24], data and collections of data can organically accrue links to new capabilities, such as preservation and sharing of services and scientific workflows shared in environments such as MyExperiment [25], via semantic linking. Perhaps this is a more realistic means of achieving the goal of smart objects — by describing data and services, and formally establishing linkages between them, or allowing machine inferencing to do so. In this case, the "smartness" of the object resides in the graph between the object, its characteristics, and relevant services. A fully SESA-based model might fulfill the predictions of smarter Web, but it awaits standardization and adoption of those standards. Our assumption regarding InfoSynth's semantic registry is that it should be possible to map between our current approach, and future semantic representations for services and datasets, as standards evolve. In the interim, infoSynth's semantic registry is an example of the Internet Engineering Task Force's "rough consensus and running code" [26].
References
[1] Berners-Lee, Tim (May 1, 2001), "The Semantic Web", Scientific American, http://www.sciam.com/article.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21.
[2] IESR, http://iesr.ac.uk/.
[3] "RSLP Collection Description", http://www.ukoln.ac.uk/metadata/rslp/schema/.
[4] W3C, "Web Application Description Language", http://www.w3.org/Submission/wadl/.
[5] SW3C, "Simple Object Access Protocol 1.1", http://www.w3.org/TR/soap/.
[6] W3C, "Web Services Description Language", http://www.w3.org/TR/wsdl.
[7] "Event-driven SOA", http://en.wikipedia.org/wiki/Event-driven_SOA.
[8] "An Overview of ZeeRex", http://explain.z3950.org/overview/.
[9] Van de Sompel, H., Beit-Arie, O., "Open Linking in the Scholarly Information Environment Using the OpenURL Framework", D-Lib Magazine, Volume 7, Number 3, March 2001, http://dx.doi.org/10.1045/march2001-vandesompel.
[10] Thornton, S., Wayland, R., Payette, S., "The Fedora Project: An Open-source Digital Object Repository Management System", D-Lib Magazine, Volume 9, Number 4, April 2003, http://dx.doi.org/10.1045/april2003-staples.
[11] Apps, A., "Using an application profile based service registry", Proceedings International Conference on Dublin Core and Metadata Applications, 2007, http://www.dcmipubs.org/ojs/index.php/pubs/article/viewFile/8/6.
[12] "OpenSearch", http://www.opensearch.org/Specifications/OpenSearch/1.1.
[13] Pearce, J., Gatenby, J., "New Frameworks for Resource Discovery and Delivery", Staff Paper, National Library of Australia, http://www.nla.gov.au/openpublish/index.php/nlasp/article/view/1216/1501.
[14] OASIS, "UDDI Executive Overview: Enabling Service-Oriented Architecture".
[15] Brack, V., Closier, A., "Developing the JISC Information Environment Service Registry", Ariadne, July 2003, http://www.ariadne.ac.uk/issue36/jisciesr/.
[16] Android Developers, "Intent and Intent Filters", http://developer.android.com/guide/topics/intents/intents-filters.html.
[17] Vitvar, T., Zaremba, M., Moran, M., Zaremba, M., Fensel, D., "SESA: Emerging Technology for Service-Centric Environments", IEEE Software, 2007, http://cms-wg.sti2.org/doc/IEEESoftware2007-VitvarZMZF.pdf.
[18] Heaney, Michael, An Analytical Model of Collections and their Catalogues, Third issue revised, Oxford, 14 January 2000, Online (PDF), http://www.ukoln.ac.uk/metadata/rslp/model/amcc-v31.pdf, 2000-09-13.
[19] Powell, A., Heaney, M., Dempsey, L., "RSLP Collection Description", D-Lib Magazine, Volume 6, Number 9, September 2000, http://dx.doi.org/10.1045/september2000-powell.
[20] W3C, "Semantic Annotations for WSDL and XML Schema", http://www.w3.org/TR/sawsdl/.
[21] W3C, "WSMO-Lite: Lightweight Semantic Descriptions for Services on the Web", http://www.w3.org/Submission/2010/SUBM-WSMO-Lite-20100823/.
[22] Wikipedia, "OWL-S", http://en.wikipedia.org/wiki/OWL-S.
[23] Gessler, Damian, Schultz, Gary, May, Greg, Avraham, Shulamit, Town, Christopher, Grant, David, Nelson, Rex (2009), "SSWAP: A Simple Semantic Web Architecture and Protocol for semantic web services", BMC Bioinformatics, 10: 309, http://dx.doi.org/10.1186/1471-2105-10-309, PMC 2761904, PMID 19775460, http://www.biomedcentral.com/1471-2105/10/309.
[24] Nelson, M. L., Maly, K., "Buckets: Smart Objects for Digital Libraries", Communications of the ACM.
[25] De Roure, D. and Goble, C., "myExperiment — A Web 2.0 Virtual Research Environment", International Workshop on Virtual Research Environments and Collaborative Work Environments, May 2007, Edinburgh, UK.
[26] "The Tao of IETF: A Novice's Guide to the Internet Engineering Task Force", http://www.ietf.org/tao.html.
About the Authors
 |
James E. Powell is a Research Technologist at the Research Library of Los Alamos National Laboratory, and a member of the Knowledge Systems and Human Factors Team where he develops digital library, semantic web, and ubiquitous computing tools to support various initiatives. He has worked in libraries off and on for over 20 years, including eight years at Virginia Tech University Libraries, where he worked on the Scholarly Communications project and participated in several collaborations between the library and the Computer Science department's digital library group. He later went on to assume the position of Director of Web Application Research and Development at Virginia Tech, and to lead the Internet Application Development group, before joining LANL.
|
 |
Krista Black currently works for Los Alamos National Laboratory's (LANL) Information Resource Management division to implement Content Management Systems for the institution's Records and Document Control programs. She worked at LANL's Research Library for three years where she was part of a
team that created Oppie, a search tool for the library's journal articles. She earned her Master's in Library and Information Science from University of North Texas in December 2008.
|
 |
Linn Marks Collins is a Technical Project Manager at the Los Alamos National Laboratory, where she leads the Knowledge Systems and Human Factors Team at the Research Library. Her team focuses on applying semantic web and social web technologies to challenges in national security, including situational awareness, nonproliferation, and energy security. She received a doctorate in educational technology from Columbia University in New York, where her dissertation was on semantic macrostructures and human-computer interaction. Prior to LANL she worked at IBM Research on Eduport and the Knowledge and Collaboration Machine, and at the Massachusetts Institute of Technology on Project Athena.
|
|