 |
D-Lib Magazine
November/December 2011
Volume 17, Number 11/12
Table of Contents
Weaving Content with Coordination Widgets
Robert B. Allen
rba@boballen.info
doi:10.1045/november2011-allen
Printer-friendly Version
Abstract
Text is a texture of interwoven threads that enable comprehension. Beyond the words themselves, conventions and structures, which we call coordination widgets, have been developed to support the reader's comprehension and navigation of text. These coordination widgets include Tables of Contents, Structured Abstracts, Reference Lists, and Footnotes. Although they are known to every reader, they are rarely considered as a group. The widgets depend on a high degree of structure in the text and are related to the structural descriptions of composite hypertexts. They also depend on the type of descriptive material that links to the text. We develop a framework for these widgets that builds on hypertext structure, discourse elements and genre theory. The framework both describes traditional widgets that have been developed to support paper-based publishing, and can be applied to environments for supporting interaction with electronic text. As eBooks and eReaders proliferate, the need grows for tools to support better navigation and comprehension of electronic text. Ultimately, the widgets, and the proposed framework, point the way to a new generation of publishing standards for interacting with multimedia and hypermedia environments.
Keywords: Citations, Discourse, eBook, eReader, eScience, Genre, Hypertext, Interactivity, Reading, Structured Abstracts, Tables of Contents
1. Introduction
Texts include more than words; they are supported by a range of content coordination widgets. These widgets are conventions and structures that enrich the reader's interaction with the words. They help support comprehension and navigation of the text and provide cohesion for readers. Many of these widgets emerged with the introduction of printing but the advent of eBooks and eReaders should spark a new generation of tools with interactive services. As eBooks proliferate, the need grows for tools to support better navigation and comprehension of electronic text.
The emergence of eBooks demonstrates the enduring value of a complete, integrated conceptual presentation, in comparison to that of widely available hypertext presentations that are often fragmented and disjointed. While a general framework has been developed for bibliographic metadata applied to complete works (e.g., [25]), the interactivity of eBooks highlights that there is no comparable framework applicable to the internal structure of the works, or to the content coordination widgets linking to the internal structure.
A framework for content coordination would have practical applications. A consistent framework would enable more effective user interaction with text browsers and eReaders. Consider the treatment of footnotes by some eReaders; they are simply formatted as a part of the static page. Scrolling or jumping to them and then returning to the text can be tedious. It would be possible to code each widget separately but a unified framework would facilitate interaction among them. Moreover, a general framework might suggest new widgets that will contribute to emerging semantic publication standards.
A framework might also encourage greater consideration of the cognitive effects of coordination widgets on reading comprehension. As a step toward the clearer specification of discourse and genres, we describe combinations of low-level discourse elements as Macro-Units and of structured genres as Genre Templates. Both of these relatively high-level structures are useful for describing sub-structures of works. The slots required by different Structured Abstracts are explicit examples of Genre Templates. In addition, we extend discourse and genre perspectives to consider how coordination widgets add cohesion to works. Our analysis is a first step that is consistent with deeper cognitive analyses of textual discourse-based cohesion (e.g., [28]).
In Section 2, we consider examples of content coordination widgets. We consider linking and anchor structures in Section 3, and introduce a framework for describing the widgets. We consider in Section 4 how the framework might be standardized and conclude by describing opportunities for developing a new generation of interactive widgets.
2. Some Examples of Content Coordination Widgets
2.1 Tables of Contents
Chapter and section headings help to orient readers and provide short conceptual previews of the associated text. When extracted from the main body of the document and collected, the headings form a Table of Contents (TOC). While the hierarchical structure of TOCs is readily adapted to hierarchical browsers (e.g., [9]), the actual TOC structure is often a more complex hierarchy. In fact, there is little empirical data about the structure of TOCs. A survey of the TOCs of some chemistry textbooks found that often there is a rich conceptual structure within the hierarchy. In one case, successive chapters examined solid, liquid, gaseous, and plasma phases of matter and then proceeded to other topics. In another case, the headings reflected a workflow that described the steps in the synthesis of a chemical compound. The grouped topics and the workflows were complex structures within the TOC hierarchy but they were not always clearly indicated.
2.2 Abstracts and Structured Abstracts
The discourse structure of the text of traditional Abstracts has been extensively studied (e.g., [21]) and to an extent Structured Abstracts simply attempt to make those structures explicit. Structured Abstracts (e.g., [14]) provide such overviews by focusing on the specific aspects of the content that are based on the structures expected for a given genre. By comparison, TOCs capture some of the top-level structure as defined by the author but they do not necessarily capture the salient points that may be most useful to readers who want an overview.
Many technical research publications have adopted Structured Abstracts. Editorial policy determines the required features and reflects the document structures expected by a specific community. A community may support several standards. For instance, the American Dental Association policy for publications dealing with Clinical Practices requires the following sections in Structured Abstracts:
Background, Methods, Results, Conclusions, Clinical Implications
For Case Descriptions, the American Dental Association requires:
Background, Case Description, Clinical Implications
The specifications of Structured Abstracts thus reflect the approaches of researchers and the values of their communities. In other words, they are outlines of genres, and therefore, we call them Genre Templates. Genre Templates imply a structure but are not purely structural. They go beyond structural hypertext models and, as we describe below, beyond current proposals for standard web formats.
2.3 Citations and the Reference List
Citations may appear to be simple hypertext links. Consider an example from [31]:
Example 1: |
For example, reducing oxygen concentration increases ROS production by mitochondrial complex III in vertebrate cells [34],[35],... |
The referents of the Citations in this example are clear — two articles. From the text, it is also relatively clear what we expect the articles to show. Nonetheless, it would be helpful to have a rich description of each work, as well as a comparison of how they differ. Approaches for navigating citations based on discourse claims have been proposed by [7] and [23]. These are promising but the problem is challenging. For instance, Citation anchors and roles can be ambiguous.
Consider a second example Citation from [31]:
Example 2: |
In particular, mitochondria are crucial in energy metabolism and as such have been implicated in the aging process by one of the very first theories of aging [2], the rate-of-living theory of aging [3], which suggested that the rate of aging is proportional to the rate of energy metabolism (reviewed in [4]). |
In Example 2, it is less clear what the anchors for these Citations should be. For instance, how the first differs from the second and where the anchor should be for the cited review article.
Beyond the Citations themselves, the Reference List which (when it exists) collects all the cited references, is a distinct coordination element. Readers who are familiar with the literature in a field can often use a Reference List to quickly understand the scope and approach of a work.
2.4 Additional Examples of Content Coordination Widgets
Considered broadly, coordination widgets are aspects of a document that go beyond the text and help to support navigation or create coherence. There are many other widgets besides TOCs, Abstracts and Citations. Within a text, they include Tables and Figures, Indexes, Glossaries and Footnotes.
Indexes are navigational aids for readers, and to a limited extent, they indicate a book's structure by showing how the use of terms and sub-terms are clustered. A Back-of-the-Book Index involves selection and inclusion of terms based on a book's focus and expectations about what readers are likely to be looking for. Unlike most algorithmic indexes, Back-of-the-Book Indexes do not list all the terms that appear in a text [24]. Moreover, they may occasionally list concepts discussed in the text, although terms typically associated with those concepts do not actually appear.
Glossaries provide definitions of terms and identification of names that appear in a document. They are similar to semantic annotations [18], which are machine-processable (often frame-based) descriptions of proper nouns.
Plot synopses and summaries share some aspects of Structured Abstracts. They provide a structured overview of stories, including attributes such as characters and setting.
Footnotes serve two functions. The first is as a way to present Citations. The second function is to provide a framework for unstructured comments (essentially annotations) by the author (e.g., [11]).
There are other widgets but not all of them contribute to content coordination (see Figure 3 below). For example, Colophons describe non-content aspects of the printed edition such as the details of the font used. A Preface is generally a personal note from the author, which may or may not provide useful insights into the text.
3. A General Framework
A basic model for content coordination widgets is shown in Figure 1. The three components of this framework are the anchors, the links, and the source model. Typically, the anchor text is within the article that is being read. For instance, a Table of Contents points into the anchor text. However, for citations, the source is the article with the citation, and the anchor is in the cited article.
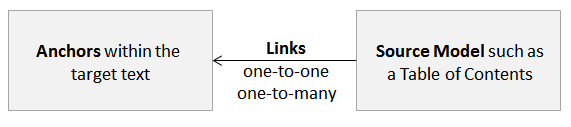 |
Figure 1: The basic model for content coordination widgets consists of three parts. The links may be simple or complex. The anchors reflect the conceptual structure of the text. Source models cover a range of materials that may range from integral material (figures, tables) to supplemental materials (related data sets) to formally associated materials (adaptations, translations). Typically, one or more of these three parts is composed of several pieces. |
While the simplest links are one-to-one, they may also be one-to-many links (e.g., from an index term to text) and many-to-many (e.g., mappings between two versions of a document). Links may be viewed through the lens of hypertext frameworks. The structures of the widgets' anchors are closely related to hypertext, and the Open Hypertext Systems (OHS) framework [19] provides a general framework for describing them. The OHS model is a comprehensive framework for the possible structures of hypertexts, and it supports many attributes, such as multi-headed anchor links. [30] notes the overlap between the OHS, and recent directions for the Semantic Web, that emphasizes role labels. However, the OHS is purely structural and does not consider the nuances of content; neither do hypertext data models such as OAI-ORE [13]. Composite hypertexts [12] are combinations of hypertext features that resemble coordination widgets, but again, they emphasize structure and pay little attention to the content they present.
3.1 The Internal Structure of Documents
Content coordination widgets are typically associated with a formal publication that is with a document that is a complete, polished conceptual unit. Nonetheless, the exclusive focus on such works is being challenged by the increasing emphasis on hypertext and the potential for reusing chunks of text (e.g., [13, 20]). However, synthesizing a set of text fragments into a coherent secondary document (perhaps as anchors of widgets) will be difficult. Clearly, a systematic description of the structure will help.
Techniques are being developed for modeling those structures. XML is often used to define structure, but technically, it is just a grammar without any content. Discourse elements are based on the communicative functions of the text. Discourse analysis examines the coherence of texts by breaking them into structural units based on their function and then considering how those functional units combine to create a coherent presentation. Narrative structure may arise from causal relationships. The elements proposed by Rhetorical Structure Theory (RST)[16] are among the most widely used in discourse analysis. However, RST is fine-grained and rarely used to analyze full documents.
Some approaches to discourse introduce functionally oriented combinations of elements. For example, VinDijk [29] has examined discourse Macro-Structures. His focus is on using Macro-Structures to describe the reader's cognition of topics in texts rather than on the nature of the structural units. By comparison, other approaches to discourse emphasize coordinated structures. For instance, Toulmin [27] describes higher-level argumentation and models argumentation with five related elements. While Toulmin's argumentation structures are clearly related to VanDijk's Macro-Structures, they are not necessarily the same. We call explicit structures such as Toulmin's "Macro-Units".
The broader, formal conceptual structure of an entire document is specified at the level of genre. For instance, Swales [26] describes the familiar IMRD (Introduction, Methods, Results, Discussion) structure of scientific argumentation as a "genre". Higher-level genre structures such as Swales' IMRD and those covered by Structured Abstracts could be considered as Genre Templates which we described in Section 2.2.
3.2 Types of Source Content
The source contains the content (based on either an implicit or an explicit model) from which the links originate. The widgets shown in Figure 2 include links to the conceptual content, and place different types of source content onto two dimensions. The first dimension (comprehension/navigation) refers to the way the readers use the widget, while the second dimension is the relationship of the source material to the target text. The relationship of the content model to the target content ranges from Integral to the document to collection-oriented tools that lead the user to a particular document. This dimension shares and greatly extends some of the Relationships mentioned in [8].
The Integral widgets are part of the target work and are generally essential to it. Other widgets Supplement the target or are from Formally Associated texts. The placements in Figure 2 are generalizations. For instance, Abstracts may or may not be part of the original work; they might be either Integral or Supplemental.
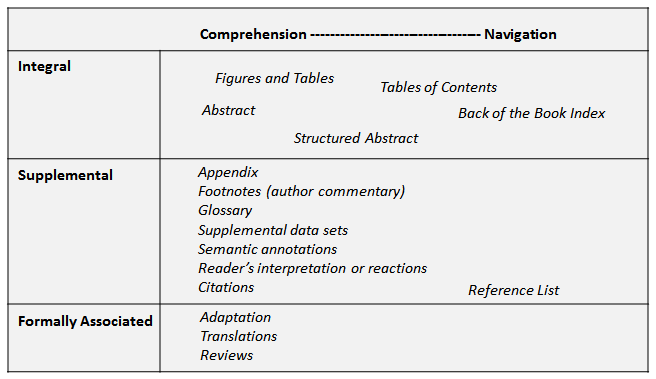 |
Figure 2: Grid of source content and work-oriented widgets. The two dimensions reflect the reader's use of the source content and the type of relationship of the text to the source content. |
Widgets such as Glossaries provide links connecting significant terms to definitions. In some cases, proper names in the document are simply listed, or they may be linked to short biographies as well as to glossaries of proper nouns. This is an example of linked data that has become of great interest to the Semantic Web community where the links are to machine processable records and are often termed semantic annotations. The notion of linked data may be extended to develop models of how terms and concepts are inter-related, of how those terms can be integrated with models (e.g., [3]) and with causal (conceptual) processes such as those described in [2]. Annotations, whether personal or social [17], are most interesting when they reflect a consistent topic, approach, or theme (i.e., a model).
Some other types of annotations relate to non-conceptual aspects of a document. These are shown in Figure 3. These annotations range from copy edits to grammatical tagging. Discourse and narrative tags are both illustrative and notable because they may define the anchor specifications (see above); as such, they are incomplete widgets. Other examples listed in Figure 3 also show linking but they do not amplify conceptual aspects of the text.
- Linguistic and Stylistic Notes
- Discourse and narrative tag
- Parse trees
- Copy edits
- Rights
- Preservation
- Technical
- Use
- Page numbers
- Preface
- Colophon
Figure 3: Several types of non-conceptual annotation widgets.
As shown in Figure 4, there are conventions and techniques that provide coherence beyond individual works; to a broad domain such as a collection, to the universe of topically related documents found on the Web, or to a broad understanding of a domain to the target text. Some of these tools, such as bibliographies, are termed "readers aids". However, that phrase is over-broad and could apply to all of the content coordination widgets, which would cause confusion.
Guided Tours are among the types of composite hypertexts described by [12]. As with other types of composite hypertexts, the content of guided tours was underspecified. For instance, the Guided Tour could tell a story or might explore different viewpoints about an issue.
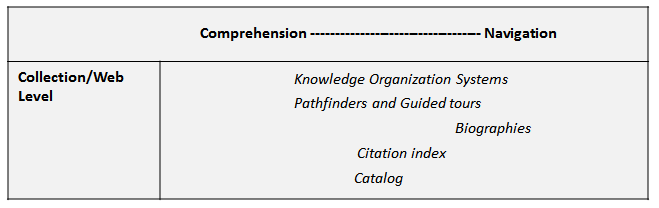 |
Figure 4: Several types of collection-level annotation structures. |
4. Future Directions
Text is often supported by an array of coordination widgets. We have provided a general framework for describing how they contribute to the understanding of the text. This framework may be useful for complex works such as text books in which there are many sorts of widgets. While we have focused on widgets associated with reading and accessing information in texts, widgets can also provide advance conceptual organizers [4]. Indeed, the use of advance organizers to enhance reading comprehension and support learning [22] is one area where the cognitive activities associated with the widgets has been well studied.
4.1 Standards
Initially, text markup would be used to implement the framework. If the standards for the framework were built on XML, XLINK, and RDF, they would need to be greatly extended to support the standards. The current generation of high-level standards such as TEI-XML and EPUB provide only elementary functionality for widgets such as TOCs. METS [15] is a flexible standard for describing complex documents but would also need to be greatly extended. In addition to markup, standard data structures increasingly are being developed with frameworks, such as schema.org and microformats.org. However, those frameworks still show little flexibility. A new generation of standards built on a full-fledged programming language may be needed for handling time-varying content such as multimedia and hypermedia.
4.2 Multi-Layer Discourse Models
Discourse is multi-layered, but the relationships among the layers are often not examined closely. Approaches such as RST emphasize low-level elements. Genres are distinguished from discourse by providing a still higher level of, and often more explicit, conceptual organization. Thus Swales' IMRD structure [26] provides a Genre Template for scientific research reports. The Templates described for Structured Abstracts are even more detailed. Moreover, Templates affect the types of Macro-Units that are found. Not only do sense-carrying units support navigation in Tables of Contents and Citation links, the distribution of Citation Roles is highly correlated with the genre, and discourse type, of the sections in which the Citation Roles appear. In turn, Macro-Units affect the types of low-level discourse elements that are found [21]. Unlike traditional metadata that is applied to an entire work, widget-based metadata might be applied at the level of sentences or of discourse elements. Such metadata might consist of terms drawn from a content ontology or from discourse or genre labels. Although there is not agreement about the best set of discourse and genre elements, such sense-carrying units seem essential for interaction with texts by anchoring widgets.
4.3 Interactive and Adaptive Widgets and Interfaces
Beyond the traditional widgets such as a static TOC and Reference List, a new generation of highly interactive widgets may be envisioned, that support access to documents. Interactive versions of several widgets have already been developed or proposed. These include interactive Figures [10] and interactive Tables of Contents [9]. Interactivity could also be incorporated into other widgets such as Citation browsers that could provide structured guides through the cited article based on the point that is being made by the citing article. In addition, the Reference List could be malleable so that the user could choose between displaying the citations in alphabetical order or date order. The enriched widgets we are considering may provide an environment like a workbench, offering a variety of tools for interacting with a text.
We would also expect work-level widgets to interoperate with, and perhaps to merge with, collection-level widgets. For instance, we might expect collection-level annotations to incorporate structured citations to multiple documents. Renear and Palmer [20] provide examples of ontology-based tools that support strategic reading. Moreover, as multimedia and hypermedia documents become more common, we would expect new types of cross-media and cross-modality widgets to be developed. For example, [1] has proposed a Table of Contents browser for videos.
Beyond simple interactivity, the widgets could adapt to the reader's background and knowledge. As texts become more available online and as text processing tools become more powerful, some of those capabilities will be extended to support personalization. This is a type of adaptive hypertext [6]. [5] describes personalized indexing-based indexing. More ambitiously, a citation-following system could provide personalized tutorials for the reader about the key points of the source articles. This could apply text-processing techniques such as summarization, along with dialog management techniques, to enable the user to explore and quickly understand a text.
Conclusion
Most documents, electronic or otherwise, incorporate widgets that enable users to identify, orient, or navigate their content. These activities should be viewed as a whole, related to the processes of reading and learning from content. We have proposed a general framework that will lead to better designed and ultimately more effective coordination widgets for electronic documents, including eBooks, based on concepts from the bibliographic metadata, hypertext, discourse, and Semantic Web communities.
References
[1] Allen, R.B., 1995, Interface Issues for Interactive Multimedia Documents, Forum on Research and Technology Advances in Digital Libraries, 1995, Springer-Verlag, LNCS 1082.
[2] Allen, R.B., 2011, Model-Oriented Scientific Research Reports, D-Lib Magazine, http://dx.doi.org/10.1045/may2011-allen.
[3] Allen, R.B., 2011, Developing a Knowledge-base to Improve Interaction with Collections of Historical Newspapers, IFLA Congress, San Juan PR.
[4] Ausubel, D., 1978, In Defense of Advance Organizers: A Reply to the Critics, Review of Educational Research, 48, 251-257.
[5] Boy, G.A., 1991, Indexing Hypertext Documents in Context, ACM Hypertext, San Antonio TX, 51-62, http://dx.doi.org/10.1145/122974.122980.
[6] Brusilovsky, P.A., Kobsa, A., and Vassileva, J. (eds.), 1998, Adaptive Hypertext and Hypermedia, Kluwer, Dordrecht, Netherlands.
[7] de Waard, A., Breure, L., Kircz, J.G., and van Oostendorp, H., 2006, Modeling Rhetoric In Scientific Publications, International Conference on Multidisciplinary Information Sciences and Technologies, Merida, Spain.
[8] de Waard, A. and Kircz, J.G., 2008, Modeling Scientific Research Articles — Shifting Perspectives and Persistent Issues, Electronic Publishing.
[9] Egan, D.E., Remde, J.R., Gomez, L.M., Landauer, T.K., Eberhardt, J., and Lochbaum, C.C., 1989, Formative Design Evaluation of Superbook. ACM Transactions on Information Systems, 7, 30-57, http://dx.doi.org/10.1145/64789.64790.
[10] Faraday, P., and Sutcliffe, A., 1999, Authoring Animated Web Pages Using "Contact Points", ACM SIGCHI, 458-465, http://dx.doi.org/10.1145/302979.303131.
[11] Grafton, A., 1999, The Footnote: a Curious History, Harvard University Press, Cambridge MA.
[12] Halasz, F.G., 2001, Reflections on NoteCards: Seven Issues for the Next Generation of Hypermedia Systems, ACM Journal of Computer Documentation, 25, 71-87, http://dx.doi.org/10.1145/48511.48514.
[13] Lagoze, C., and Van de Somple, H., Open Archives Initiative Object Reuse and Exchange, http://www.openarchives.org/ore/1.0/primer.
[14] Lancaster, F.W., 2003, Indexing and Abstracting in Theory and Practice, 3rd ed., Univ. of Illinois Press, Champaign IL.
[15] Library of Congress, METS: Multimedia Encoding and Transmission, http://www.loc.gov/standards/mets/.
[16] Mann, W.C., and Thompson, S.A., 1988, Rhetorical Structure Theory: Toward a Functional Theory of Text Organization, Text, 8(3), 243-281.
[17] Marshall, C.C., 1998, Toward an Ecology of Hypertext Annotation, ACM Hypertext 98, 40-49, http://dx.doi.org/10.1145/276627.276632.
[18] Oren, E., Möller, K.H., Scerri,S., Handschuh, S., and Sintek, M., 2006, What Are Semantic Annotations?, Technical Report, DERI Galway.
[19] Reich, S., Wiil, U.K., Nurnberg, P.J., Davis, H.C., Grønbæk, K., Anderson, K.M., Millard, D.E., and Haake, J.M., 1999, Addressing Interoperability in Open Hypermedia: The Design of the Open Hypermedia Protocol, New Review of Hypermedia and Multimedia, Volume 5, pages 207-248.
[20] Renear A.H., and Palmer, C.A., 2009, Strategic Reading, Ontologies, and the Future of Scientific Publishing, Science, 325, 828-832, http://dx.doi.org/10.1126/science.1157784.
[21] Rimrott, Anne, 2007, The discourse structure of research article abstracts — A Rhetorical Structure Theory (RST) Analysis, Proceedings of the 22nd NorthWest Linguistics Conference (NWLC), (pp. 207 - 220).
[22] Rothkopf, E.Z., The Concept of Mathemagenic Activities, Review of Education Research, 40(3), 1970.
[23] Shotton, D., Portwin, K., Klyne, G., and Miles, A., 2009, Adventures in Semantic Publishing: Exemplar Semantic Enhancements of a Research Article, PLoS Computation Biology, http://dx.doi.org/10.1371/journal.pcbi.1000361.
[24] Stauber, D.M., 2004,Facing the Text Content and Structure in Book Indexing, Cedar Row Press, Eugene OR.
[25] Svenonius, E., 2000, The Intellectual Foundation of Information Organization. MIT Press, Cambridge MA.
[26] Swales, J.M., 1990, Genre Analysis: English in Academic and Research Settings, Cambridge University Press, Cambridge UK.
[27] Toulmin, S., Uses of Argument, 1958, Cambridge University Press, Cambridge UK.
[28] Unger, C., 2006, Genre, Relevance and Global Coherence: The Pragmatics of Discourse Type, Palgrave McMillan, Basingstoke, Hampshire UK.
[29] Van Dijk, T.A., 1980, Macrostructures: An Interdisciplinary Study of Global Structures in Discourse, Interaction, and Cognition, Erlbaum, Hillsdale, NJ.
[30] van Ossenbruggen, J., Hardman, L., and Rutledge, L., 2002, Hypermedia and the Semantic Web: A Research Agenda, Journal of Digital Information, 3(1), http://journals.tdl.org/jodi/ article/viewArticle/78/77.
[31] Yang, W., and Hekimi, S., 2010, A Mitochondrial Superoxide Signal Triggers Increased Longevity in Caenorhabditis elegans. PLoS Biol 8(12), http://dx.doi.org/10.1371/journal.pbio.1000556.
About the Author
 |
Robert B. Allen has explored novel access techniques for digital history such as text extraction from collections of digitized historical newspapers and interactive timeline interfaces. He has also been developing model-oriented scientific research reports. Robert Allen has been a professor at Drexel University and the University of Maryland. He was also a Senior Scientist at Bellcore and a Member of Technical Staff at Bell Laboratories. His PhD is in Social and Cognitive Experimental Psychology from UCSD. Bob was Editor in Chief of the ACM Transactions on Information Systems and Chair of the ACM Publications Board. He will be joining the faculty of the School of Information Management of Victoria University of Wellington in January 2012.
|
|