 |
D-Lib Magazine
November/December 2010
Volume 16, Number 11/12
Table of Contents
PDF/A: A Viable Addition to the Preservation Toolkit
Daniel W. Noonan
The Ohio State University Archives
noonan.37@osu.edu
Amy McCrory and Elizabeth L. Black
Ohio State University Libraries
{mccrory.7, black.367}@osu.edu
doi:10.1045/november2010-noonan
Printer-friendly Version
Abstract
PDF/A, the archival version of the PDF file format, is an International Standards Organization (ISO) vetted, open source tool that can be added to the librarian's and archivist's preservation toolkit. This article describes the format itself, the lessons learned as the authors investigated the tools readily available for creating PDF/A files and the design of the pilot to test implementation of the use of the format in The Ohio State University's repository, the Knowledge Bank. Further, we identify issues in conversion of diverse original formats; strategies for time-saving batch conversion; and considerations in deciding whether to attempt full or partial compliance with the standard.
Introduction
In the fall of 2007, a workgroup within The Ohio State University Libraries' (OSUL) Digital Initiatives Steering Committee was tasked with investigating the utilization and viability of PDF/A as a preservation tool. Our charge evolved from investigating the PDF/A format to determine if OSUL should begin utilizing it for inclusion of new objects in the Knowledge Bank (KB), to determining if OSUL should consider migrating the current PDFs in the KB to the PDF/A format, to completing the AIIM [1] online PDF/Archive Training Course, reporting on experience and lessons learned, to conducting additional testing and developing next steps for implementing PDF/A as an acceptable and preferred preservation format.
Over the two year investigatory period we tested various creation and conversion tools, examined the creation and/or conversion from various file formats to PDF/A, conducted a limited investigation into which other institutions were utilizing PDF/A, prepared recommendations for the adoption of its use as it offered a better chance for long-term preservation, and recommended the establishment of guidelines for a pilot implementation in The Ohio State University's Knowledge Bank. This article will focus on the latter portions of this process.
PDF/A Defined
PDF/A, the archival version of the Portable Document Format (PDF) file format, is an International Standards Organization (ISO) vetted, open source tool that can be added to the librarian's and archivist's preservation toolkit [2]. ISO 19005-1 is based upon the Adobe® Acrobat® PDF reference version1.4 and defines PDF/A as:
"...a file format based on PDF, known as PDF/A, which provides a mechanism for representing electronic documents in a manner that, preserves their visual appearance over time, independent of the tools and systems used for creating, storing, or rendering the files [3]."
The PDF/A Competence Center notes that the PDF/A standard does not define an archiving strategy or the goals for an archiving system, however it identifies a "profile" for an electronic document that ensures the document can be reproduced in years to come. The key element for success is the requirement for PDF/A documents to be wholly self-contained — that all of the information (including all visible content like text, raster images, vector graphics, fonts, color information, et al) necessary for displaying the document in the same manner every time is embedded in the file. A PDF/A document is not permitted to be reliant on any information from direct or indirect external sources, for example links to external image files or fonts that are not embedded [4].
The PDF/A-1 standard provides two levels of compliance:
- PDF/A-1a denotes "full compliance" and ensures the preservation of a document's logical structure and content text stream in natural reading order. The text extraction is especially important when the document must be displayed on a mobile device (for example a PDA) or other devices in accordance with Section 508 of the US Rehabilitation Act. In such cases, the text must be reorganized on the limited screen size (re-flow). This feature is also known as "Tagged PDFs."
- PDF/A-1b denotes "minimal compliance" and ensures that the text (and additional content) can be correctly displayed, but does not guarantee that extracted text will be legible or comprehensible. It therefore does not guarantee compliance with Section 508 [4].
Currently ISO is developing Part 2 (or PDF/A-2) of the standard, that addresses some of the added features within Adobe® Acrobat® PDF versions 1.5, 1.6, and 1.7. PDF/A-2 should be backwards compatible, i.e., all valid PDF/A-1 documents should also be compliant with PDF/A-2, whereas, PDF/A-2 compliant files will not necessarily be PDF/A-1 compliant. PDF/A-2 reached the status of "working draft" in January 2008. Further, in July 2008, Adobe's PDF Reference 1.7 became ISO 32000, and control of the PDF Reference passed to the international community [5].
Environmental Scan
As part of our initial charge we conducted a limited environmental scan to ascertain what several other peer institutions were doing — whether the institution had adopted the standard, and further whether they had implemented its use. Very few institutions were even experimenting with the PDF/A format, let alone having adopted it as tool. Early adopters were predominantly in Europe. Towards the end of our project, we conducted a somewhat broader, yet informal environmental scan via an on-line survey. We received fifty-four responses of which seventeen, or 31.5%, noted that their institution had adopted the use of PDF/A as a preservation tool. Of the seventeen adopters 13 have actually implemented its use. An additional three respondents have implemented the use of PDF/A without an official adoption of its use as a policy [6].
Conversion Testing
Following our early investigations testing various creation and conversion tools and examining the creation of and/or conversion from various file formats to PDF/A, we recommended the adoption of the use of PDF/A as an additional preservation tool for OSUL. We further recommended the establishment of guidelines for a pilot implementation in The Ohio State University's Knowledge Bank.
In order to determine the possibility of success for a PDF/A conversion program, we devised a series of tests utilizing three different methods to convert:
- existing PDF files to PDF/A
- word-processing documents to PDF/A
- existing hardcopy documents to PDF/A via scanning
After spending over a year experimenting with various conversion tools and file types, we settled upon conducting implementation testing with existing tools that we had already licensed, Adobe® Acrobat® Pro and Microsoft Word.
The tests revealed a number of issues that may impede achieving compliance with PDF/A-1a. While by no means exhaustive, the following list includes issues commonly encountered across the various conversion tests:
- Fonts not embedded: PDF/A-1a requires that fonts be embedded in the document. Font embedding ensures that documents are correctly rendered regardless of the font set available on a given computer.
- Device specific color: PDF/A-1a requires that the file be rendered in a universally available color model, such as a commonly used RGB or CMYK type. An embedded color profile specific to the scanner that created the file will prevent compliance.
- Tagging: Tagging is the function that makes the structure of the document understandable to screen readers. Lack of tagging leaves the document inaccessible from a Section 508 point-of-view, and therefore not PDF/A-1a compliant. While there are automated ways to add tags, a PDF may still have document sections that are not identified as text, image, or other structural elements, thus requiring manual tagging.
- Language specification: The reading options in the advanced document properties allows one to specify a language which enables some screen readers to switch to the appropriate language; a lack of a language specification could render a document inaccessible and not complaint with PDF/A-1a.
- Transparency: Presence of transparency, layers, and other visual elements are not allowed in PDF/A-1a and must be flattened to make it compliant.
Any or all of the above problems may occur when a conversion to PDF/A-1a is attempted. Adobe® Acrobat® Pro provides a number of tools that can be used to detect, and change, a file's non-compliant properties. Batch processes can also be set up and run to change the same properties across a group of files. Most of the tools are accessible through the Advanced menu bar item, with many powerful file processing options available under the Preflight sub-menu.
Test Case 1: Conversion from Existing PDF Files
Our working group tested a batch of PDFs created via scanning by an outside contractor. Before attempting conversion to PDF/A-1a, we used the Preflight>PDF/A Compliance>Verify Compliance with PDF/A-1a tool to test for non-compliant properties in the first file of the batch. The resulting report showed that the PDF was not tagged, and that a device-specific color profile was embedded in the file. We successfully fixed these problems through the use of two tools in the Advanced>Accessibility>Add Tags to Document menu and Preflight>PDF Fixups>Convert to sRGB tool (Figure 1). As in many software programs, there are often multiple menu options for fixing a given compliance problem. This article presents only a few of them. It is worth exploring and testing the various tools under the Advanced and Document menus. Having fixed the problems, we once again ran the Verify Compliance with PDF/A-1a tool, this time receiving a report that the file was compliant. At this point, we were able to successfully run the Advance>Preflight>Convert to PDF/A-1a tool.
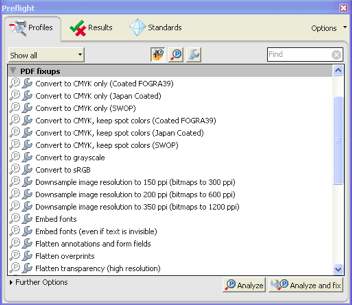 Figure. 1: Preflight offers a number of "fixups" to correct non-compliant features.
Figure. 1: Preflight offers a number of "fixups" to correct non-compliant features.
Our next step was to assign tags to the entire batch of PDFs. This can be done through the Advanced>Document Processing>Batch Processing tool, by choosing the commands New Sequence, Select Commands, and Document>Make Accessible sub-menus. For the last two steps in the process, we employed Preflight Droplets, which offer a simple, graphical interface for running a batch process. The user selects a command from the Preflight menu, then clicks Options and Create Preflight Droplet to save the command and create a small graphic symbol. Dragging files onto the symbol runs the process. We created Droplets for converting the files to sRGB color, and for batch conversion to PDF/A-1a.
While this test group was successful, additional tests with other PDF batches showed that such conversions are not always simple. Non-accessible documents will reveal many elements that cannot be identified as text, image, or other. Such documents require human review and identification of problematic elements. In some cases, this may require many hours working with a large batch of documents. The decision must be made as to whether accessibility of all documents is worth the cost in staff hours. Each institution will likely set a threshold for compliance, with certain groups of files chosen for conversion to PDF/A-1a, and others assigned conversion to the less rigorous PDF/A-1b standard.
Test Case 2: Conversion from Word-Processing Documents
Existing word-processing documents can be converted to PDF/A in one of two ways. The file can be opened and converted with a PDF conversion tool and then saved as PDF/A. It can also be saved as a PDF within the word-processing program. For our tests, we used Adobe® Acrobat® Pro 8.1 and 9.0 (Acrobat® Pro) and Microsoft Word 2007 (Word 2007).
A Word 2007 document was opened in Acrobat® Pro and saved with PDF/A chosen from the file format drop-down menu; next the Settings option was selected, revealing a menu of choices about the file properties (Figure 2). In addition, an Apply Corrections check box is offered; checking this will apply a number of standard compliance measures, such as embedding fonts and flattening layers. In our case, these were not enough to ensure full compliance (Figure 3), and further steps using Preflight Fixups was required.
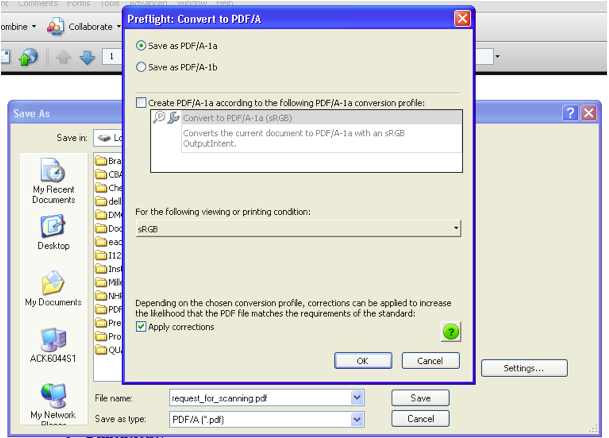 Figure. 2: A file set to be saved as PDF/A-1a in Adobe® Acrobat® Pro 9.0, with sRGB selected as the color model.
Figure. 2: A file set to be saved as PDF/A-1a in Adobe® Acrobat® Pro 9.0, with sRGB selected as the color model.
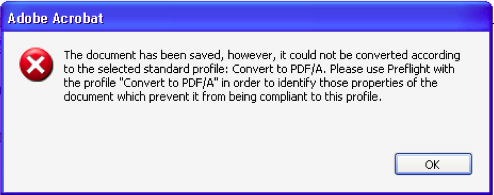 Figure. 3: When the standard Apply Corrections options do not solve all of the compliance problems,
Figure. 3: When the standard Apply Corrections options do not solve all of the compliance problems,
the program refers the user to Preflight for further fixups.
Using the same document, we attempted to save it as a PDF/A using the Options menu available in Word 2007 when saving to PDF. Upon opening this file in Acrobat® Pro and analyzing it with Preflight, we found that it was not compliant with either PDF/A-1a or PDF/A-1b. Further changes to the file would be required to make it fully compliant.
Test Case 3: Conversion from Print Via Scanning to PDF/A
To test the conversion of hardcopy documents via scanning to PDF/A, we utilized Adobe® Acrobat® Pro 9.0 to facilitate the capture process. During the scanning process, creating PDF/A-1a compliant documents at the point of input offers the best chance to avoid problems. Be aware that not all scanning software packages offer these options, so if you are unsure of your scanning software's capabilities in this area, carefully test and analyze it before beginning a large batch job. Further, many of the options described below are only available when TWAIN drivers are installed.
We used the Create>PDF From Scanner option in Acrobat® Pro, choosing the Make Accessible option to ensure tagging of the file on input. There is an additional option Make PDF/A compliant, however it only ensures PDF/A-1b compliance. If your organization chooses to require PDF/A-1a compliance, after creating the document, go to the Preflight menu and apply the necessary fixes to obtain full compliance. We found that utilizing the Make Accessible option and other options such as Add Metadata to be the best way to ensure compliance.
Scanners with optical character recognition capabilities (OCR) are able to scan and create an editable document that could then be converted to PDF; however, this may present other problems. A document containing odd letter sets and handwriting, for instance, was scanned creating a document that was then opened with Word 2007, resulting in nonsense characters in the output. While scanning the same document utilizing Acrobat® Pro produced accurate reproduction of all visual elements, there were still problems with the OCR content, which would necessitate the sort of human intervention and identification described in Test Case 1. When text reproduction of some content is impossible, or undesirable, the latter method of scanning is preferable, at least providing a PDF/a-1b compliant file.
Conclusions:
The working group concluded from our tests that PDF/A is most appropriate for files that are primarily text documents, and that it is significantly easier to get files into PDF/A form if those files are born digital or when one has control over making them digital. Surprisingly, the easiest to make fully PDF/A-1a compliant were those we scanned to PDF/A. The group observed the workflows currently in place for acquiring and ingesting materials into our institutional repository to see where we might best add the PDF/A conversion step. The group chose two workflows: one in which students add their own work and one in which the materials are scanned by library personnel. For the pilot, we will modify the documentation for these workflows to create PDF/A documents instead of the PDFs that are currently produced. The issues encountered will be tracked. We are focusing on new work, because there are more opportunities to control the establishment of the parameters than when attempting to convert legacy files.
For the workflow in which the students produce their own PDF/A, we will encourage students to use a computer that has Acrobat® Pro in addition to Word 2007. Both of these applications are available at computer labs on campus. Our tests showed that conversion to full PDF/A-1a compliance is more likely to be successful if it can be performed from within the Word 2007 application that created the file using the Acrobat® Pro plug-in. While Word 2007 does include the option to create a PDF/A file, the only choice is a PDF/A-1b version. Part of the pilot will be to determine how significant a roadblock this issue will be.
For the workflow involving library personnel handling of materials, we will provide detailed instructions, based on the information presented in this article, to one working group that creates PDFs from scanned materials. The pilot will create and test identified batch programs, determine the training level needed in addition to documentation and provide an opportunity to streamline the processes as we move from experimentation to production. Once the batch tools are created and the documentation and training finalized, they will be shared broadly with all in the Libraries who work with PDF, not just those who work directly with the institutional repository.
We are seeking full PDF/A-1a compliance because these PDFs will also be accessible. The PDF/A-1a standard requires the text to be tagged and marked up, which enables screen reader technology to correctly read the document to disabled persons, thus making it an accessible PDF. Therefore, PDF/A-1a is preferred because it is better for archival and accessibility reasons. There are situations where PDF/A-1a is not attainable, such as with documents that are primarily image-based and do not have alternate text identified; in these cases PDF/A-1b is acceptable, at least from an archival and preservation point-of-view.
PDF/A is a valuable, viable preservation tool that we have recommended as an addition to the digital preservation toolkit at The Ohio State University Libraries. For other organizations we recommend the conversion to PDF/A directly from a born digital object; when that is not a possibility, convert via scanning, conducting the conversion at the point of input. For efficiency, utilize batch processing for conversion workflows, and develop policy, standards, and procedures for your organization/institution.
As with all tools, PDF/A offers benefits but also presents challenges. Now that The Ohio State University Libraries has determined its viability as a preservation tool, work will continue to address the challenges of integrating the tool with existing OSUL digital preservation processes, so that its benefits can be more fully realized.
Notes
[1] AIIM was founded in 1943 as the National Microfilm Association and later became the Association for Information and Image Management. Eventually, like many other professional association, the acronym became the name and is no longer an acronym. AIIM has become known as the professional association for enterprise content management (ECM) practitioners.
[2] In the fall of 2005, ISO adopted this new preservation format standard, ISO-19005-1 - Document management - Electronic document file format for long-term preservation - Part 1: Use of PDF 1.4 or PDF/A-1 (PDF/A-1).
[3] ISO-19005-1 - Document management - Electronic document file format for long-term preservation - Part 1: Use of PDF 1.4 (PDF/A-1).
[4] PDF/A - A new Standard for Long-Term Archiving, http://www.pdfa.org/doku.php?id=pdfa:en:pdfa_whitepaper, retrieved February 17, 2010.
[5] http://pdf.editme.com/PDFREF, retrieved February 17, 2010.
[6] We conducted a survey via SurveyMonkey™ between mid-February and early March 2010 that was promoted via various archives, records management and library Listservs®. We asked the following questions: 1. Has your institution/organization adopted the use of PDF/A as a preservation tool? Yes or No [We stress "tool" not the "silver bullet" and not the only preservation tool within your toolkit]; 2. If you answered yes to the above, have you implemented the use of PDF/A? Yes or No. 3. Please indicate the name of your institution/organization. If you would like feedback from this survey please indicate your name and email address.
About the Authors
 |
Daniel W. Noonan is the Electronic Records Manager/Archivist for The Ohio State University. Reporting to the University Archivist, in collaboration with the Office of the Chief Information Officer, he assists in the design, evaluation, and implementation of electronic recordkeeping systems; provides counsel to academic and administrative offices in electronic records management and preservation best practices; advocates for necessary resources; and develops strategies for long-term preservation and access to electronic records of enduring value. He received his MLS from Rutgers University.
|
 |
Amy McCrory is a Digital Imaging Specialist in the Preservation Department of the Ohio State University Libraries. She received her MLS from Clark Atlanta University. Her professional interests include digital imaging standards, technical metadata, and digital preservation. She recently co-authored "The OhioLINK EAD FACTORy: Consortial Creation and Delivery of EAD," published in Archival Issues, v31, n2.
|
 |
Elizabeth L. Black is an Assistant Professor and Head of the Web Implementation Team at the Ohio State University Libraries. Her team is responsible for the Libraries' web site, web applications and the technical aspects of the university's digital repository, the Knowledge Bank. As a member the Digital Initiatives Steering Committee, she explores standards, formats and best practices related to digital libraries.
|
|