|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Andreas Aschenbrenner Tobias Blanke David Flanders Mark Hedges Ben O'Steen |
![]()
|
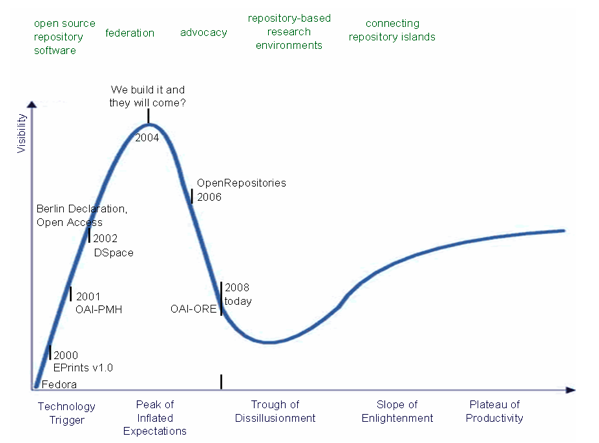
Over the past few years, repositories have been created as a product intended to foster dissemination of scholarly works, a shared objective for most academic institutions. Because of this, repositories have grown at a rapid pace over the past decade, with the software trinity of EPrints, DSpace and Fedora leading the field. The openness and willingness of these repository systems to evolve has greatly increased the ability of repositories to disseminate scholarly works; however, the repository community is still in its infancy, and further change as a holistic community is required to support both the users of the systems (institutions) and the users of the resources within the systems (scholars). Increasing variability can be seen with regard to repository users and institutions. Small organizations are looking for ways to benefit from repositories, and even today, a large number of users still do not have any access to a domain-specific repository. At the other end of the spectrum, there are repositories that are continuously expanding in size and functionality. For many of these, concerns have switched from 'how to get a repository working' to 'how the repository can scale' – both technologically and organizationally. Infrastructure initiatives such as, for example, the Fedora installations at NSDL ([1,2]) and Max Planck's eSciDoc ([3]) are precursors to huge repository-based research environments of the very near future. Because of this diversity in repository sizes, contexts and user requirements, multiple architectures are required to support them with regard to their manageability, cost efficiency, and the functionalities they offer – all the while keeping the real end user (the Scholar) at the focal point of development. This article focuses on the "what" and "why" of repository architectures and discusses how repositories could be used in today's changing Web landscape. It begs the question of the reader: "How else can the underlying architecture of repository environments change to support repository managers and – most important – the end user?" Fast-forwarding the repository evolutionDigital repositories have evolved rapidly over the last few of years. By October 2008, the OpenDOAR directory1 – a portal for voluntary repository registration – listed more than 1,200 operational repositories covering a range of contexts and tasks. Using the "hype curve" metaphor, which characterizes the adoption cycle of new technologies, this section of the article sketches where we are and what may be in store for the future of repositories.2
Rather than the number and size of repository initiatives, the availability of software and its interoperability are key indicators of the maturity of the field. In the late 1990s, repositories were often homegrown and built from scratch. With the dawn of the 21st century, several initiatives started to share their software source code openly. For some time, there were so many open source repository packages emerging, it was hard to track them all [4,5]. Today, the majority of repository communities have coalesced around a trinity of nodes (as prominently represented in the OpenRepositories3 conference series): these nodes are EPrints4 (University of Southampton), DSpace5 (Massachusetts Institute of Technology), and Fedora6 (Cornell University and the University of Virginia). Overall, the availability of repository software stabilized extremely quickly. However, the repository universe is not limited to this trinity, and the current equilibrium may change at any time as novel repository-like systems emerge in related fields such as e-Infrastructure (e.g., iRODS,7 gCube8), Semantic Web platforms (e.g., Talis Triple Store,9 Tupelo10), commercial companies (e.g., Microsoft [6], IBM [7]), content-type specific repositories (e.g., Flickr, YouTube, SlideShare), and the so-called Web 2.0 personal document repositories (e.g., GoogleDocs, Zoho). While technology continues to evolve, it is the social and political issues that have the most significant effect on the scholarly user and whether or not that user decides to use a repository, respectively an application built upon repository software. Because the repository's primary mission is to disseminate the university's or research institution's primary output, some repositories have seemed to forget that researchers – rather than institutions – are the most important users of repositories. Consequently, many repositories have struggled to obtain deposits [8, 9]. After the steep rise of repositories as dissemination platforms in the early part of this century, the lack of user adoption has posed a severe challenge to the repository community. This made repository evolution dip towards the "trough of disillusionment" (see Figure 1). That's because the benefits of repositories were not made sufficiently clear to the scholarly user. Although advocacy coupled with easier deposit has changed this situation for the better, we still await the most fundamental change needed, which is to see repositories become a natural part of the user's daily work environment. To increase the value of the repository to the user, some repositories are focusing more on features such as: preservation of the user's intellectual assets (read: trusted digital repositories [10]), scientific collaboration through reuse (publications as well as primary data) [11], and embedding repositories into the user's scientific workflows and scholarly workbench ([2]). And who knows what's next for the ongoing repository evolution? Will the repository community be able to move away from the traditional institutional repository mediated-deposit model (the "peak of inflated expectations") and into an information environment where repositories are interweaved with other systems for the mutual growth and benefit of the Scholar (i.e., can we climb the "slope of enlightenment")? Where are we heading?Local repositories: does every institution need one?Today, deploying one of the repository software packages on a local box is a routine job for an experienced technician. An out-of-the-box deployment may be done in a matter of a few days. But this is really akin to buying a bike: knowing how to ride that bike – much less ride it effectively – is a different matter altogether. First of all, the repository installation needs to be customized and embedded into the local environment. Potential depositors need to be informed and their contributions elicited. And there are numerous other tasks for rendering a generic software instance into a living institutional service as well. Furthermore, beyond communication and branding, there is still a world of issues with which repositories must deal before their services become "trustworthy" [12]:
And there will be other questions as well, each offering a challenge for the repository and an opportunity for the user. In the face of these issues, local repository islands become insufficient. A single institution cannot and does not need to tackle all these questions alone; tasks and responsibilities can be shared across several institutions. Adoption patterns: do users only trust themselves and their own institutions?Research into user needs identifies a variety of leverage points for repository adoption [8,9]. The dissemination of research usually ranks low in the list of what triggers use of repositories, because journal publication patterns are already well in place and they are often (rightly or wrongly) considered the most reliable route to scientific credit. Preservation of research artifacts ranks much higher as a reason users engage with repositories, particularly in the case of research data that is valuable and unique. The top-ranked motivators, however, are mechanisms for collaboration across institutions and across disciplines, from co-authoring to conducting actual research. While the above has necessarily been a very brief account of user needs, it clearly highlights the necessity for links between repositories on multiple levels: content, tools, and users. At the same time, the claim that in order to establish trust, the repository has to be operated by the user's home institution has never been substantiated. Users merely ask for "someone else to take responsibility for servers and digital tools" [9], whether or not that other agent is the user's current home institution. Trust in a stable and secure repository service is established through the repository's policies, status among peers, and added-value services. Towards an open repository environmentThere is clearly a thrust for opening up repositories on both the system and the application levels. Setting up a repository is no longer merely a binary decision of 'yes' or 'no'. Increasingly, repository components can be mixed, and external services can be employed to fit an institution's capabilities and needs. Repository storage does not have to involve setting up storage racks and installing protocols, because now repository managers may choose an adequate service-level agreement from on-demand storage providers; preservation services can be latched on any number of repositories just like, e.g., services for repository statistics, domain-specific analyses, and user notification; and users can embed repository content and services into their scientific workflows. The opportunities provided by open and shared repository environments are getting clearer; however, today actual implementations have yet to be linked into a coherent framework, and they often involve a lot of hacking and customization by repository staff. The following sections of this article identify existing prototypes and suggest exemplar cross-repository patterns for interoperation of repositories across the information environment. Furthermore, it should be noted that the authors of this article do not see "success" for repositories as a given, i.e., we are not sure if the community can pull itself up from the 'trough of disillusion'. Nevertheless, we believe that the collaborative nature of the community will spur repositories towards open, shared repository environments and to an eventual 'plateau of productivity'.
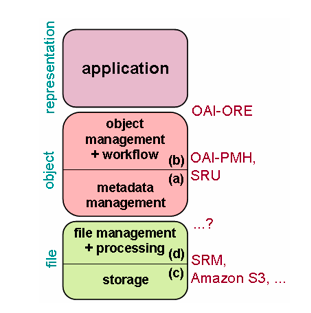
layer - (a) object: metadata Interoperability on a metadata level has clearly been the most active area in digital repositories up to now. Spurred by the Open Access movement, numerous repositories exposed their metadata through standard protocols like the OAI-PMH Protocol for Metadata Harvesting [13] or Zing/SRU [14]. Today, cross-referencing catalogues or object sources can be traced in a multiplicity of applications, including thematic portals that reference and annotate a cross-section of objects from numerous repositories. In July 2008, OAIster,11 a "union catalog" for digital resources, cross-referenced more than 1,000 repositories and their combined 18 million digital resources by way of the OAI-PMH protocol. Quite soon, however, various initiatives started to go beyond a meta-level and began to test exchange of content as well. Among those initiatives is the China Digital Museum Project, which federates the digital artifacts of about 100 university museums, based on a slightly adapted version of the OAI-PMH [15]. At about the same time [16], the successors of the original OAI-PMH team set out to specify an entirely new protocol geared specifically towards content: Object Reuse and Exchange (ORE).
layer - (b) object: content ++ First rolled out in early 2008, the OAI-ORE12 protocol enables the description and exchange of compound digital objects. It aims to be an interface between repositories and other applications, including those that support, e.g., authoring, deposit, exchange, visualization, reuse, and preservation. ORE-enabled applications are only just emerging. The 2008 winning team of the CRIG Repository Challenge implemented a prototype for replicating digital objects between distinct repositories on a content level.13 In ORE-based replication, whole objects are extracted from one source repository and then registered in a destination repository or other application. It is at that point a policy decision must be made regarding whether the components of that object are also copied across. In the case of the prototype, every part of the object from the source repository was replicated to the destination repository. There may be a reference between the various peer systems, but there is no further connection. Because of that, ORE-based replication can be plugged into existing systems basically at any time; there is no requirement, e.g., for the replication mechanism to be ready before the system is launched. What is needed, however, is a shared schema to describe the objects or parts of the objects. This is the case for replication as well as any other ORE-based application. User adoption and actual interoperability will depend on such shared schemas emerging.
layer - (c) storage: hardware virtualization On a significantly lower level in the repository object stack (see Figure 2), the community is moving from a central server model to a distributed storage model. The advantages of a generic storage infrastructure include increased stability, lifting a burden from the application developers, who do not need to care about storage issues and bit-preservation any longer. DSpace and Fedora provided the option of switching storage to the Storage Resource Broker (SRB),14 a distributed storage manager with features like file replication. The repositories employ SRB as a virtual file system, with DSpace and Fedora taking care of file management and higher-level functions. The SRB storage option is attractive for the possibilities it offers for storing large amounts of data, outsourcing hardware management, and reaping increased stability from replication. SRB thereby enables large organizations to establish a single, integrated storage infrastructure that serves multiple applications, potentially with a repository shared among them. The national library of France (BnF) is currently establishing such an environment, where the storage infrastructure accommodates all the library's digital holdings including video, audio, and other formats, and the Fedora-based repository is one possible access point to a subset of those holdings.15 This program by the BnF is expected to work from now until 2009 to establish the storage infrastructure, and subsequently will concentrate on preservation and user-oriented issues. In early 2008, iRODS was introduced as a successor to SRB. In this software for "data management cyberinfrastructure" the creators of SRB implemented two new approaches on: 1) microservices, which operate directly on the raw data and may be distributed to different storage locations, and 2) a rule system, which chains microservices to workflows. Rules operate on object metadata and enable the execution of customised workflows. As an example, the rule system in one iRODS installation replicates on ingest all XML files three times and creates a HTML surrogate; also, the rules in this specific installation define that PDF and XML files cannot be deleted. Initiatives, including the newly launched ASPiS16 and Shaman [17], are currently testing iRODS for its adequacy in preservation environments, where automated tasks such as large-scale format conversion may be processed on a file level. It is not only large institutions such as the BnF that can benefit from shared storage infrastructure. Over the last two years, national initiatives such as e-Science in the UK and D-Grid in Germany17 established a digital infrastructure for both an academic and industry community. At the time of writing, D-Grid provides about 2 petabytes of online storage space and 20.000 cores for computational tasks, and those numbers are growing. Enabled repositories could potentially access these resources, thus offering small institutions an existing storage infrastructure to which to turn. The business world has similar offerings for virtualized hardware infrastructure that, in terms of usability, are further advanced than are the public offerings. The Amazon18 simple storage service (S3) and the elastic computing cloud (EC2) are among the best known of such services, though there are also other services by Amazon, and by companies like Google, Sun Microsystems, and HP. The Fedorazon project set out to link Fedora, EPrints and DSpace with Amazon web services on a storage level. This is particularly attractive for small organizations, as S3 brings on-demand storage, which means these organizations no longer need to worry about hardware issues and the risks involved in maintenance.
layer - (d) storage: file management While storage interfaces like the ones to SRB and iRODS enable virtualization of hardware nodes, they do not address: packaging of files; the directory structure, where digital objects and their metadata are stored; and other file management repository tasks. The approaches for tackling these tasks vary in current repository systems as to whether they
There is currently no software that can be used to virtualize repository storage that fits under any repository. In addition to enabling a shared storage infrastructure that serves any kind of repository and, potentially, multiple repositories at the same time, standard interfaces above the file management layer could enable the shared development of distributed, low-level functions. Above we described the approach of iRODS "microservices". Both iRODS and a similar approach by IBM [7] hope to increase the overall scalability of systems by taking workflows to the distributed data, and by hiding administrative tasks in the low-level storage layer and automating simple data management tasks. However, the approaches mentioned are tailored to the specific system and its approach to file management. Standard interfaces on the file management level would allow for shared development of file-level repository functions whether files are stored in specific directory structures, packaged with their metadata, or stored together with other files in containers, or whatever approach to file management is employed. One project underway for establishing a low-level web-based storage system is ReST-ORE. This lightweight repository is based on OAI-ORE and ReST, and it offers a minimal set of functions for storing and streaming digital objects in combination with a notification service for propagating changes to higher-level systems. Thereby, changes made through one repository and stored through ReST-ORE will show up in any other repository sitting over the same datastore. Also, the members of the repository trinity – EPrints, DSpace, and Fedora – are currently working on generic storage modules ([18], [19], [20]) that handle storage management, file management, and low-level processing. However, it is unclear whether these generic storage modules will be interoperable and will allow for interfaces that span the repository community. ConclusionsDigital repositories have rapidly become an integral part of higher education and other digital environments. Setbacks with regard to user adoption, and technological dead ends of insular efforts, have not induced a significant dip in the growth of the community. Instead, they have added new perspectives on how repositories can be embedded into their organizational and social contexts. The CRIG19 slogan: "The coolest thing to do with your data will be thought of by someone else" can be seen as a call for open interfaces and repository interoperability. The exemplary cross-repository patterns presented in this article show repositories interacting on various levels of abstraction – from a raw file level to an object level. Once it is possible to compose repository components through standard interfaces, repository managers can investigate which tasks they should take on themselves and which tasks to out-source to suitable service providers. This creates a much-needed competitive market where services can be plugged in with greater ease and for less cost. Repositories are no longer limited to using a software package with a single branded user interface; they can use sets of components mixed and matched to specific user needs. However, for those new perspectives to manifest, the members of the repository community need to move closer together and develop a collaborative agenda. There are so many exciting opportunities, including: generic storage infrastructure with on-demand storage; file-level processing for content analysis; increased scalability; better integration of application environments; and the other opportunities described above. Lightweight preservation services [21], such as linking to community-wide format registries and migration services, may be the only way to tackle preservation adequately. Patterns for these approaches already exist in live systems; technically it is possible to create open repository environments with shared components, but a collaborative effort towards cross-repository interoperability is still needed to actually advance along this path. Repositories are no longer limited to being composed of a single server that is either hosting software A or software B. Repositories are becoming increasingly versatile as to what services they deliver and how they organizationally arrange for those services. User trust, of course, is shifting, as questions about where a repository is hosted no longer make sense. Rather, trust depends on the impact a service has on users' daily lives and how the service blends into their routine, and trust depends on whether a particular repository's policies and value-proposition works for those users. This is exactly where repositories are advancing on their way towards an open repository environment. Notes1. OpenDOAR - Directory of Open Access Repositories. <http://www.opendoar.org/>. 2. The discussion about the future of repositories touches on many issues and perspectives, and it will continue throughout the existence of repositories. See <http://tinyurl.com/4fsq7l>. 3. OpenRepositories first convened 2006 in Sydney, Australia. <http://www.openrepositories.org/>. 4. EPrints. <http://www.eprints.org/>. 5. DSpace. <http://www.dspace.de/>. 6. Fedora - Flexible Extensible Digital Repository Object Architecture. <http://www.fedora-commons.org/>. 7. Integrated Rule-Oriented Data System (iRODS). <https://www.irods.org/>. 8. gCube. <http://www.gcube-system.org/>. 9. Talis. <http://www.talis.com>. 10. Tupelo. <http://tupeloproject.org/>. 11. OAIster. <http://www.oaister.org>. 12. OAI-ORE, Object Reuse and Exchange. <http://www.openarchives.org/ore/>. 13. CRIG Repository Challenge at the OpenRepositories Conference 2008. <http://www.ukoln.ac.uk/repositories/digirep/index/CRIG_Repository_Challenge_at_OR08>. 14. Storage Resource Broker (SRB), by the San Diego Supercomputer Center (SDSC). <http://www.sdsc.edu/srb/index.php/Main_Page>. 15. French National Library: the SPAR project – preservation of digital material. <http://www.bnf.fr/pages/infopro/numerisation/num_spar.htm>. 16. ASPiS (Architecture for a Shibboleth-Protected iRODS System). <http://www.jisc.ac.uk/whatwedo/programmes/programme_einfrastructure/aspis.aspx>. 17. D-Grid, the German grid infrastructure initiative. <http://www.d-grid.de>. 18. Amazon Web Services. <http://aws.amazon.com>. 19. CRIG - Common Repositories Interface Group. <http://www.ukoln.ac.uk/repositories/digirep/index/CRIG>. References[1] Dean B. Krafft, Aaron Birkland, and Ellen J. Cramer: NCore: Architecture and Implementation of a Fedora-based Digital Library. In: Proceedings of the Joint Conference on Digital Libraries (JCDL) 2008 in Pittsburgh, PA. [2] Carl Lagoze, Dean B. Krafft, Sandy Payette, Susan Jesuroga: What Is a Digital Library Anymore, Anyway? – Beyond Search and Access in the NSDL. D-Lib Magazine, v.11 n.11, November 2005. <doi:10.1045/november2005-lagoze>. [3] M. Dreyer, N. Bulatovic, U. Tschida, M. Razum: eSciDoc – a Scholarly Information and Communication Platform for the Max Planck Society. In: Proceedings of the German e-Science Conference 2007, Baden-Baden. [4] Budapest Open Access Initiative: OSI Guide to Institutional Repository Software, version 3.0, May 2008. <http://www.soros.org/openaccess/software/>. [5] Uwe M. Borghoff, Peter Rödig, et al.: Vergleich bestehender Archivierungssysteme. nestor Deliverable. 2005. <http://nbn-resolving.de/urn/resolver.pl?urn=urn:nbn:de:0008-20050117016>. [6] Lee Dirks, et al.: Research-Output Repositories – An overview of Microsoft Initiatives. In: OpenRepositories 2008, Southampton. <http://pubs.or08.ecs.soton.ac.uk/84/1/Research_Output_Repositories_-_Microsoft_Initiatives.pdf>. [7] Michael Factor, et al.: Preservation DataStores: Architecture for Preservation Aware Storage. In: IEEE Conference on Mass Storage Systems and Technologies 2007, San Diego, USA, September 24-27, 2007. [8] Andrea Foster: Papers Wanted: Online archives run by universities struggle to attract material. Chronicle of Higher Education, June 25, 2004. [9] Nancy Fried Foster, Susan Gibbons: Understanding Faculty to Improve Content Recruitment for Institutional Repositories. D-Lib Magazine, v. 11 n. 1, January 2005. <doi:10.1045/january2005-foster>. [10] Trustworthy Repositories Audit & Certification (TRAC): Criteria and Checklist. Update from 07/11/2008. <http://www.crl.edu/content.asp?l1=13&l2=58&l3=162&l4=91>. [11] The Boston Globe: Out in the open: Some scientists sharing results. News Item, 21 August 2008. <http://tinyurl.com/5p5qpx>. [12] Trusted digital repositories: Attributes and responsibilities. An RLG-OCLC report. May 2002. <http://www.oclc.org/programs/ourwork/past/trustedrep/repositories.pdf>. [13] Herbert Van de Sompel, et al.: Resource Harvesting within the OAI-PMH Framework. D-Lib Magazine, v.10 n.12, December 2004. <doi:10.1045/december2004-vandesompel>. [14] Theo van Veen, Bill Oldroyd: Search and Retrieval in The European Library – A New Approach. D-Lib Magazine, v. 10 n. 2, February 2004. <doi:10.1045/february2004-vanveen>. [15] Robert Tansley: Building a Distributed, Standards-based Repository Federation – The China Digital Museum Project. D-Lib Magazine, v.12 n. 7/8, July/August 2006. <doi:10.1045/july2006-tansley>. [16] Herbert Van de Sompel, et al: An Interoperable Fabric for Scholarly Value Chains. D-Lib Magazine, v. 12 n. 10, October 2006. <doi:10.1045/october2006-vandesompel>. [17] Paul Watry: Digital Preservation Theory and Application: Transcontinental Persistent Archives Testbed Activity. In: The International Journal of Digital Curation, v.2 i. 2, November 2007. <http://www.ijdc.net/ijdc/article/view/43/50>. [18] David Tarrant: From open storage to smart storage: enabling EPrints repository preservation. In: The Sun Preservation and Archiving Special Interest Group (PASIG) Spring Meeting (http://sun-pasig.org), May 27-29, 2008, San Francisco. <http://eprints.ecs.soton.ac.uk/15818/>. [19] Fedora Commons Technology Roadmap, V0.9. Viewed July 2008. <http://www.fedora-commons.org/pdfs/FedoraCommonsRoadmapDraft.pdf>. [20] DSpace/Fedora: Storage Delegation Layer. Fedora Commons Wiki, viewed November 2008. <https://fedora-commons.org/confluence/display/DSPACE/Storage+Delegation+Layer>. [21] T.Brody, L.Carr, J.Hey, A.Brown, and S.Hitchcock: PRONOM-ROAR: Adding Format Profiles to a Repository Registry to Inform Preservation Services. The International Journal of Digital Curation, 2 (2). 2007. <http://eprints.ecs.soton.ac.uk/>. Copyright © 2008 Andreas Aschenbrenner, Tobias Blanke, David Flanders, Mark Hedges, and Ben O'Steen |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/november2008-aschenbrenner
|