|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Eva Müller, <eva.muller@ub.uu.se> |
![]()
IntroductionDiVA, a publishing system developed and maintained by the DiVA Project team within the Electronic Publishing Centre at Uppsala University Library, treats the electronic copy of a document as the "digital master" for both electronic and print versions and uses data originally entered by the document author as the basis for creation, reuse, and enhancement of all metadata. Each document is assigned a persistent identifier and then the document is stored, along with a checksum, in the local depository—known as the DiVA Archive. A depository copy of each document is preserved in the DiVA long-term archive and is sent to the national library—the Royal Library in Stockholm for long-term preservation as well. The system is built on open standards and recommendations. Metadata is stored in the DiVA Document Format, a rich, locally developed schema. Transformations of this schema provide metadata in a variety of other formats and support various metadata services, including harvesting via the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH). At present, the DiVA system is used by five universities in Sweden and one in Denmark. Publications from these institutions are available through a common interface, known as the DiVA portal. In this article we describe the current status of the DiVA system, the system's functionality and project plans for future development. We discuss strategies employed and decisions made that led to current solutions to development challenges. Some parts of the DiVA system—for example, publishing workflow, DiVA document format and solutions supporting long-term preservations—are highlighted. What Is DiVA?We use the name "DiVA", (the Digital Scientific Archive or Digitala Vetenskapliga Arkivet in Swedish) as an all-encompassing name for the electronic publishing system developed and maintained at Uppsala University Library. The word "archive" was added to the name, not because of the repository function of the DiVA system, but to point out that solutions supporting long-term preservation are a part of the system. Development of the system began in September 2000 within the framework of the DiVA project, which was initiated by both the faculty and the library at Uppsala University. The primary DiVA project goal was to improve the means for exposing, disseminating and preserving research results produced and published locally. The DiVA system has been in full operation since January 2003, and it is currently used by five universities in Sweden and one university in Denmark. A common interface—known as the DiVA portal—for federated search of documents published by local DiVA systems is also available. BackgroundThe DiVA ProjectSince 2000, a team at the Electronic Publishing Centre at Uppsala University Library [1] has been working on the development of technical solutions and a workflow for electronic publishing of scientific publications. The Centre itself is the result of an investigation carried out at Uppsala University in 1998/99 concerning the electronic publishing of scientific material. The DiVA project started in September 2000, and the project focused first on developing a workflow and finding technical solutions for publishing doctoral theses in electronic format. From the beginning, however, it was clear that the DiVA project should be extended to deal with other types of publications produced by university departments, such as research reports or undergraduate theses. Hence, project tasks were interpreted from a broader perspective when the requirements for system solutions started to emerge. The electronic publishing area is changing rapidly. Therefore it was important that flexibility and future perspectives would be mirrored in the suggested system solutions. It was desired that new, and hopefully even future, technologies and standards could be implemented in the system and that concepts introduced by DiVA could be reused. After a review of several existing solutions [2] developed by similar projects, the DiVA team concluded that those solutions had several limitations and did not correspond to established goals. One of the goals, for example, was to simplify the workflow for both authors and university staff (librarians and administrators) in order to gain time and efficiency; therefore, the team's vision for DiVA included the goal to reuse—in multiple contexts—structured information originally entered by authors. Additionally, since a document might be published in both electronic and print formats, it was critical to guarantee that the electronic corresponded directly with the printed. The DiVA Publishing SystemThe first version of the DiVA Publishing System became operational in January 2003 and has since then generated a great deal of positive interest. The DiVA system incorporates standards, recommendations and new XML technologies, and from the point of system architecture, uses component-based design. DiVA system components are modular and reusable. The ability to seamlessly replace a given module with improved implementation provides needed flexibility. Structural mark-up is created by using templates for word processors (macros provide similar functionality in LaTex). Once the document is converted from the template into XML the data can be reused, displayed and disseminated in different formats (e.g, as XHTML or PDF web pages, MARC 21 catalogue records, or Dublin Core OAI records). Additionally, the archival copy of each document, with associated metadata, is stored in multiple archives at different geographical locations. The DiVA PortalAfter its development at Uppsala University, DiVA captured the interest of other Swedish universities. By establishing a consortium of these universities, the experiences and system solutions originally created for Uppsala University could be utilized by the other universities as well. This consortium was founded in 2002 and, in addition to Uppsala University, includes: Stockholm University Library, Umeå University Library, Örebro University Library, and Södertörn University College Library. In 2003, the first member from outside of Sweden—the State and University Library of Århus in Denmark—joined the consortium. DiVA cooperation is open to all universities and publicly financed research departments in Sweden and abroad and is based on the sharing of solutions, tools, expertise and costs. Within the framework of the consortium, a common interface to publications has been created. This portal—called the DiVA portal—can be both searched and browsed [3]. Since all participants support a common list of subject categories, a subject entry to the portal is also available. Another function of the portal is to disseminate metadata for documents published in full text. The metadata records can be harvested via the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) [4]. Each participating institution can decide whether to harvest metadata from the portal or from its own local DiVA system. However, an advantage of using the portal for metadata dissemination is that the number of publications combined from all participating universities is quite large, which makes the portal a more attractive target for harvesting by OAI service providers. The portal is a good example of interoperability because it builds on common agreements regarding organization and technology, as well as vocabularies, formats and metadata granularity. DiVA Project ContributionsBecause data with a very high granularity are captured directly from authors' documents, the publishing workflow offers possibilities for developing and introducing new features and services regarding the dissemination of metadata, services supporting long-term preservation, and production of cover and title pages directly from the metadata. The contributions of the DiVA project could be summarized as:
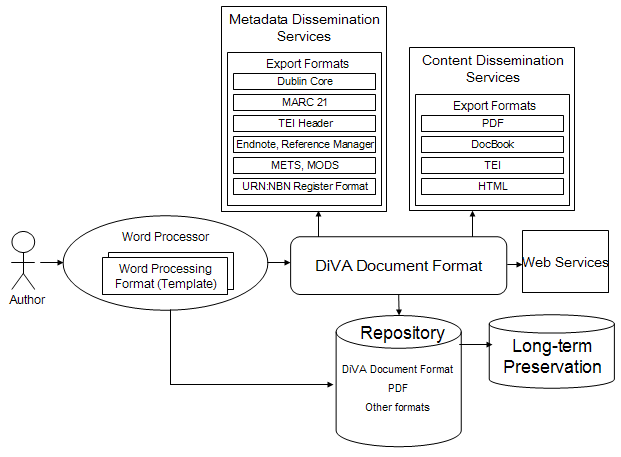
The DiVA Publishing WorkflowDiVA publishing workflow is based on the concept that data is entered in a structured form only once. The resulting structured document is then used throughout the entire chain for generating other products. For example, different metadata formats (a MARC record for the library catalogue or a record disseminated within the OAI framework); parts of the full text publication (the cover and the title page); or the presentation layer on the web are all created directly from the data delivered by the author. The author creates the original document using word processor templates (or LaTex macros). Both electronic and traditional print publications are created from a single source—the master file, which is produced from a file delivered by an author and created in a template for word processing. In this way, both the metadata and the structure of the document are marked up. The workflow for this is depicted in Figure 1.
|
|
|
|
The DiVA team is frequently asked, "Is it necessary to use templates?" No, it isn't. DiVA also supports publishing of documents that are not produced with templates; however, in those cases the metadata needs to be entered separately into the system using one of the DiVA Manager tools. The choice of whether to use the template or not is determined by the level of functionality desired by the organization using the system. Nonetheless, templates are a useful component of the DiVA workflow. If everything is done properly, the whole process works smoothly. At Uppsala University, our strategy involved introducing the DiVA workflow gradually. It took about two years before doctoral students accepted the DiVA templates for posting and publishing their doctoral theses. The problem wasn't the actual use of the templates; researchers are accustomed to using templates when preparing publications for commercial publishers. The issues that slowed acceptance were the design of the templates and, in some cases, technical problems that arose while using them. Based on valuable feedback obtained from users early in DiVA development, the templates were improved, and as a result, discussions are now taking place for introducing the use of the DiVA templates by undergraduate and graduate students for publishing their essays, theses and dissertations. Some of the academic departments have also expressed a desire to use the DiVA templates for publishing their working papers and research reports. At other universities using DiVA, experiences have been similar to ours at Uppsala. The ability to introduce the DiVA workflow gradually provides a great advantage. As the DiVA system is introduced to an organization, it is sometimes more practical to add documents to the system using some of DiVA's administrative interfaces, where metadata are typed in and the files in various formats (mostly PDF) are uploaded, before moving on to using the template-based workflow. Documents created from DiVA templates are uploaded via an administrative tool called the DiVA Manager. During the upload process, files are automatically transformed to XML. As mentioned earlier, this tool also supports other ways of delivering metadata, abstracts and full text documents and can easily be integrated into different workflows. DiVA Manager consists of the following:
The technical solutions used by DiVA are based on XML as a format for both transmission and storage of both metadata and full text. However, there are still some unsolved problems when it comes to publishing the full text documents in XML in a production environment. For example, there are problems with mathematical formulas and tables. Because of this, most of the full text files are still published and stored in PDF. In addition to XML and PDF, other formats, like PostScript, can be used. The system can handle any file format. It is up to each participating organization to decide which formats they wish to support. DiVA Document FormatAs has previously been mentioned, one of the goals of the DiVA project was to create a workflow where information from the authors' original documents could be reused to extract metadata for various purposes and, ultimately, to extract the complete document in XML. We evaluated a number of existing schemas [metadata schemas and DocBook [6] and TEI [7] for the encoding of documents]. Unfortunately, none of the schemas we evaluated met all our requirements for DiVA. Many limitations were found, not only in the granularity of the description, but also in the ability to express relationships and hierarchies and in the extensibility of the schemas. Consequently, we decided to develop a new schema: the DiVA Document Format. The DiVA publishing workflow makes it possible to capture data at a deep level of granularity. We didn't want to lose the ability to capture this structured data; it is still relatively easy to produce structures with a lower granularity level from those with more structured data. It is more complicated—and in many cases it is impossible—to do it in the opposite way, i.e., to produce structured data from non-structured information. Another DiVA requirement involved making the structured DiVA Document Format compatible with a number of metadata schemas and standards. The idea was to be able to easily generate other formats from the basic, structured document format. In the context of producing other schemas from the basic schema, the granularity of the description is not enough. In many cases, it is necessary to be able to express relationships and hierarchies. Metadata recommendations (for example, in the area of the rights metadata and preservation metadata) are still under development, and new standards and recommendations will become available over time. Therefore, one of the requirements for the DiVA format was that it should be extensible. The format we developed at Uppsala, the DiVA Document Format, combines metadata elements with elements for structural mark-up. The current version of the format is defined by an XML schema. The methodology of component-based system development was also employed in this area: the DiVA Document Format is itself component-based and extensible. Currently, the DiVA Document Format consists of 99 metadata elements. Elements from the DocBok DTD are used to markup structure of the document [8]. As one of the next steps in the DiVA project, possibilities for semantic markup of document content will be explored. It is likely that the next version of the DiVA Document Format will be extended with new elements to support this [9]. By taking advantage of the DiVA Document Format capabilities, many features and services could be developed and integrated into the operational DiVA system. Additionally, the format is also an important part of the DiVA long-term preservation strategy. Accessibility and Preservation from a Long-term PerspectiveOne of the objectives of the DiVA project has been to explore ways to ensure the future use and understandability of the digital objects in the archive. The idea was to introduce basic solutions that can be improved over time. Early in the project, we explored and discussed different strategies with an emphasis finding a practical and convenient way to minimize risks for data loss, not only in the context of migration of the entire document and associated metadata to other formats and media in the future, but also in the context of accessibility. With that in mind, the following key decisions were made:
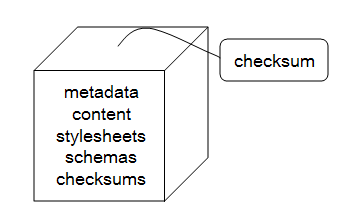
The first step in the process of planning for accessibility and preservation was deciding to use XML as the primary storage format for publications. The DiVA Document Format was then developed to support long-term preservation as an integral part of the DiVA archive. The question of ensuring accessibility in the future initiated cooperative projects with the Royal Library in Stockholm [10] to combine accessibility using persistent identifiers with a workflow for long term preservation. Using unique identifiers based on URN:NBN [11] and exchanging metadata and archive packages with the Swedish National Library Archive were the next important steps in the development of the DiVA workflow. Today, these processes, which are automated, make up integral parts of the operational DiVA system. DiVA both automatically assigns the persistent identifiers and saves all metadata and as much of the content as is possible in XML. The DiVA system creates the archiving packages (AIP in OAIS parlance [12]), stores them in the DiVA long-term preservation archive and sends copies of the packages to the Swedish National Library Archive [13]. Persistent LinksEach document published through the DiVA system is assigned a unique identifier based on the URN:NBN identifier scheme. In cooperation with the Royal Library, the DiVA project team has set up and put into operation a resolution service [14]. Once a persistent identifier has been assigned, the resolution service is able to locate a desired document and provide access to it. At this time, the document is accessed from one of the local DiVA sites, but when the DiVA local archive is unavailable for some reason, the document request is instead directed to the archived copy of the document held at the Royal Library. We hope that this service will be further developed and expanded to include similar international projects and activities (e. g., the one at Die Deutsche Bibliothek) [15]. The DiVA Long-term ArchiveMerely placing documents in a digital archive and refreshing them from time to time are fairly simple operations. It is when archived electronic documents are accessed and reused that difficulties arise. In our opinion, strategies for document storage should also include plans for document reuse. Planning for document reusability shaped our choice of archive formats and strategies. Thus, we decided early in DiVA project development to use XML as the primary format for storage [16]. The purposes of the DiVA Long-term Archive are both to preserve documents for future use and to provide an extra back-up for access to published documents. Technically, the archive is totally separate from the DiVA Publishing System and there is only one-way communication between the publishing system and the archive. A service where checksums between the life system and the DiVA archive can be compared will be developed. Each manifestation is stored as a package, which includes a file in the DiVA Document Format and a file that defines this format—today an XML schema—as well as checksums for all files in the package (see Figure 2). There are also specific files for each manifestation. For example, if the manifestation is published in PDF, a PDF file will be included in the package. If a manifestation is published in XML format, stylesheets for transformation and images will be included. Since the DiVA Document Format is a compulsory part of every package, all metadata can be reconstructed by extracting them from the DiVA Document Format.
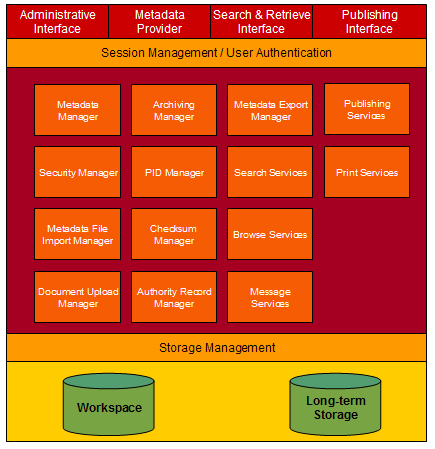
A cooperative workflow between the DiVA system and the National Library Archive has been developed. This operation is based on a package being sent in accordance with the process described above, depicted in Figure 2. The ability to store documents at different geographical locations not only minimizes the risk of data loss but also improves accessibility. Currently the DiVA project team is establishing a network within the Nordic countries, and the options for redundant storage of documents within this network are being discussed. Metadata DisseminationAs mentioned earlier, the DiVA system creates all other metadata formats directly from the DiVA Document Format. Because of the high granularity—99 metadata elements—and the ability to express relationships and hierarchical structures, it is possible to transform the DiVA Document Format into quite complex metadata formats like MARC-XML [17] or TEI-Header, for example. Some of the other formats that currently are provided include METS [18], MODS [19]and, of course, simple formats such as DC, qualified DC [20], Reference Manager Format, EndNote and a number of service-specific, XML-based formats [21]. Services Based on MetadataTo support the dissemination of information about published documents, the DiVA system offers metadata to other services. Examples of such services include not only support for harvesting via the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH), but also a flow where catalogue records in MARC 21 are created and transmitted to the national and local library systems as a part of an automated process. Metadata can also be transmitted to other local systems on demand. Another metadata service based on XML and very frequently used by departments at Uppsala University is the facility to put department-relevant publications directly into the websites of specific departments—for example, as a list of recent publications—and, in the near future, also into the personal web pages of university staff. Recently added publications are also made available through an RSS channel [22]. Search and Browse - User InterfaceAn important part of the DiVA system is its public, user interface on the web. The interface is built on XML technologies and can easily be tailored for different layouts. A simple plain text version designed according to the Web Content Accessibility Guidelines (WAI) [23] is also available. Currently, all pages are available in Swedish and English, although other language versions can be added. Search options include both a structured search form and free text searching (including abstracts and keywords). Bibliographical information about all records can be downloaded in different formats, created directly from the DiVA Document Format. Because an increasing number of full text documents are stored in a structured form in XML, the browse and search capabilities will be extended in the next release of the DiVA system to make it possible to browse and search table of contents as well as different levels of headings. Based on feedback from researchers, bibliographic records from bibliography and reference lists stored in a structured form will also be available for downloading to personal libraries. Additionally, an interface that allows presentation of relationships between documents published within the DiVA system based on the references might be added. The DiVA Architecture and the Technical PlatformThe DiVA development team prefers using open source software wherever possible. As a practical matter, however, a combination of open source and commercial software is being used at this time. Nevertheless, the team plans to replace the commercial pieces of software being used in DiVA (currently, only Oracle database software) as soon as viable, non-commercial solutions emerges. In addition, the DiVA system does not depend on a particular operating system. Since the technical solutions underpinning the system are built using a component-based design methodology, modules and components can be seamlessly replaced with improved components as they become available. Modularity and component reusability offer a tremendous advantage over other methods and provide a solid basis for further local and cooperative development. The system has been created using a three-layer architecture. These layers include the storage layer, business layer (server applications) and interface layer (client applications). The DiVA system architecture is shown in Figure 3.
The storage layer uses XML files in UTF-8 in combination with an Oracle database for searching and indexing. The next release of DiVA—expected to be available in January 2004—will use the XML-DB feature in Oracle 9i. This is a result of our strategic decision to make it possible to exchange the DBMS for a XML-based solution in the future and, at the same time, to archive XML data only, independent of a commercial database. This capability is important for preservation of the data coming from the operational publishing system and offers the potential to easily reconstruct the data if necessary. One of the reasons we decided to use Oracle was that Oracle made it possible to easily create search indexes for multiple languages. A feature in Oracle makes it possible to build search interfaces in which even words with diacritics can be searched without typing the diacritic in the search interface. This is an important feature for searching in a number of European languages. Other reasons we decided on Oracle included the quality of its support for Unicode and the ability to exchange data in XML. For the server applications, DiVA uses an Apache web server and the Apache Tomcat servlet container running on a Linux server. Java (i.e., java servlets and java beans) is used for various DiVA applications and tools (updating and data management tools, and metadata dissemination). Several different XML technologies are used for transformation of the web interface and to exchange data between the storage and application layers (XML, XSL, XSLT). Apache FOP (XSL-FO) is used for dynamic creation of some pages in PDF format. Future DevelopmentA component-based system development methodology has been used in the construction of the DiVA system. This offers a great advantage: the components can initially be developed with minimal, but sufficient, functionality. As more resources become available and new demands for the system arise, a simple component can be replaced by one that is more advanced. Further development of DiVA is planned at the following three levels:
ConclusionsThe DiVA project has created exciting possibilities for further development. The project team at the Uppsala University Library has initiated cooperative projects with other universities in Sweden and Denmark. Although the original focus of DiVA was not on research, but rather focused on developing a practical electronic publishing implementation, several spin off projects—including both research and operational projects—have been started as a result of DiVA system development. The valuable cooperation taking place within the consortium of universities using the DiVA system provides a platform in which both technical and organizational matters are being discussed and plans for future development are being made. We hope cooperation within Sweden in the field of electronic publishing will be established between users of a variety of systems and, in this way, that it will be possible to share experiences and expertise. Although the current operational DiVA system satisfies the original project goals and requirements set up in 2000, we see a lot of potential for enhancing DiVA system functionality, as well as building new services. Although many problems and challenges will need to be tackled for future development, a solid base has been put in place from which to move forward. AcknowledgmentsIn January 2003, when the DiVA system was put into operation, the Electronic Publishing Centre was divided into two groups: production and development. The first group is now responsible for the production of printed and electronic publications. The production group makes the work of the development team visible. We would like to thank the entire production group for their contributions, especially Erik Siira, the head of production, and our colleague Ann-Sofie Köpmans, both of whom previously were members of the development team. Discussions with other developers, librarians, researchers and users also influenced the DiVA project. We especially thank members of our reference group [24] for their feedback and support. We also thank the Information Technology faculty at Uppsala University and Prof. Eva Brittebo, Chair of the Steering Group for Electronic Publishing at Uppsala University, for their invaluable support. Notes and References[1] Electronic Publishing Centre at Uppsala University Library, <http://publications.uu.se/epcentre/>. [2] See, for example, EPrints, <http://www.eprints.org/> and Greenstone, <http://www.greenstone.org>. [3] DiVA Portal, <http://www.diva-portal.se>. [4] The Open Archives Initiative, <http://www.openarchives.org>. [5] MathML, <http://www.w3.org/Math>. [6] There is no XML schema today for DocBook. See <http://www.docbook.org/>. [7] Text Encoding Initiative, <http://www.tei-c.org/>. [8] For details, see specification: DiVA Project (2003), DiVA Document Format, <http://publications.uu.se/schema/1.0/diva.xsd>. [9] A project dealing with semantic marking of learning resources was started in cooperation with researchers, publishers, educational bodies and libraries. More information (in Swedish) may be found at <http://www.skeptron.ilu.uu.se/broady/dl/mu.htm>. [10] The Royal Library, The National Library of Sweden, <http://www.kb.se>. [11]RFC 3188. Using National Bibliography Numbers as URNs. October 2001 <http://www.ietf.org/rfc/rfc3188.txt>. [12] Consultative Committee for Space Data Systems, Reference Model for an Open Archival Information System (OAIS), CCSDS 650.0-B-1, Blue Book, January 2002. <http://wwwclassic.ccsds.org/documents/pdf/CCSDS-650.0-B-1.pdf>. [13] Müller, Eva; Klosa, Uwe; Hansson, Peter; Andersson, Stefan: "Archiving Workflow between a Local Repository and the National Archive Experiences from the DiVA Project". Proceedings of the Third ECDL Workshop on Web Archives, in conjunction with the 7th European Conference on Research and Advanced Technologies for Digital Libraries in Trondheim, Norway. August 21st, 2003. <http://bibnum.bnf.fr/ecdl/2003/>. [14] URN - Uniform Resource Name, <http://www.kb.se/URN/default.htm> (Swedish). [15] Die Deutsche Bibliothek. Demonstration of the URN (NBN) resolver, <http://nbn-resolving.de/ResolverDemo-eng.php>. [16] Müller, Eva; Klosa, Uwe; Hansson, Peter; Andersson, Stefan; Siira, Erik "Using XML for Long-term Preservation.Experiences from the DiVA Project". Proceedings of the ETD 2003: Next Steps - Electronic Theses and Dissertations Worldwide. The Sixth International Symposium On Electronic Theses and Dissertations, the Humboldt-University in Berlin, Germany, 21 - 24 May 2003. <http://edoc.hu-berlin.de/etd2003/hansson-peter/HTML>. [17] MARC 21 XML scheme, <http://www.loc.gov/standards/marcxml/>. [18] Metadata Encoding and Transmission Standard (METS), <http://www.loc.gov/standards/mets/>. [19] Metadata Object Description Schema (MODS), <http://www.loc.gov/standards/mods/>. [20] Dublin Core Metadata Initiative, <http://dublincore.org/>. [21] Müller, Eva; Andersson, Stefan; Klosa, Uwe; Hansson, Peter: "Metadata Workflow Based on Reuse of Original Data". Proceedings of the ETD 2003: Next Steps - Electronic Theses and Dissertations Worldwide. The Sixth International Symposium On Electronic Theses and Dissertations, the Humboldt-University in Berlin, Germany from 21 - 24 May 2003. <http://edoc.hu-berlin.de/etd2003/andersson-stefan/HTML/index.html>. [22] Really Simple Syndication (RSS). RSS 2.0 Specification, <http://blogs.law.harvard.edu/tech/rss>. [23] Web Accessibility Initiative (WAI), <http://www.w3.org/WAI>. [24] Reference group for electronic publishing at Uppsala University, <http://publications.uu.se/epcentre/diverse/refgrupp.html>. Copyright © Eva Müller, Uwe Klosa, Stefan Andersson, and Peter Hansson |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/november2003-muller
|