D-Lib Magazine
May/June 2017
Volume 23, Number 5/6
Table of Contents
ePADD: Computational Analysis Software Facilitating Screening, Browsing, and Access for Historically and Culturally Valuable Email Collections
Josh Schneider, Special Collections & University Archives, Stanford Libraries, Stanford University
orcid.org/0000-0002-7166-5080
josh.schneider [at] stanford.edu
Peter Chan, Special Collections & University Archives, Stanford Libraries, Stanford University
orcid.org/0000-0001-9389-6720
pchan3 [at] stanford.edu
Glynn Edwards, Special Collections & University Archives, Stanford Libraries, Stanford University
orcid.org/0000-0002-4360-0108
gedwards [at] stanford.edu
Sudheendra Hangal, Ashoka University
hangal [at] ashoka.edu.in
https://doi.org/10.1045/may2017-schneider
Abstract
ePADD is free and open-source software that supports the computational analysis of email with potential historical or cultural value. The software incorporates techniques from computer science and computational linguistics, including natural language processing, named entity recognition, and other statistical machine learning-associated processes. These functionalities enable ePADD to promote the appraisal, processing, discovery, and delivery of email held by archival repositories and other cultural memory institutions. In November 2015, Stanford Libraries, with partners University of Illinois Urbana-Champaign, Harvard University, University of California, Irvine, and Metropolitan New York Library Council, received three years of funding from the Institute of Museum and Library Services (IMLS) to advance the formation of a national digital platform by further developing ePADD. Now in year two of the grant, Stanford Libraries and its grant partners have continued to improve the program's scalability, usability, and feature set, while simultaneously taking steps to engage and grow the user community. This article provides background on the need for the ePADD software, identifies how ePADD contributes to the national digital platform, informs on the work completed, highlights the ways in which ePADD is being adopted by the community, and identifies next steps and areas for future project development.
Keywords: Archival Processing, Descriptive Metadata, ePADD, Email Archiving, Natural Language Processing, Machine Learning, Named Entity Recognition, Privacy, Redaction
1 Introduction
ePADD is free and open-source software that supports the computational analysis of email of potential historical or cultural value. The software incorporates techniques from computer science and computational linguistics, including natural language processing, named entity recognition, and other statistical machine learning-associated processes. These functionalities enable ePADD to promote the appraisal, processing, discovery, and delivery of email held by archival repositories and other cultural memory institutions.
2 Background and Need
ePADD was developed to confront challenges that donors, archivists, and researchers routinely face in donating, administering, or accessing email collections. These include concerns about privacy and copyright, the difficulty of processing large, multi-decade archives with potentially millions of messages, and ultimately the desire to make these archives accessible to scholars and other researchers.1 It is not atypical for projects of even modest scope, like the National Archives and Records Administration's collection of Justice Elena Kagan's email, to require over 6,000 work hours and upwards of 20 archivists and technicians to make available 75,000 individual pages.2 The challenges of processing 1.3 million email messages of the former administration of Virginia Governor Tim Kaine by the Library of Virginia reveals how these challenges compound when considered at the scale common to many government archives.3
The rising demand for an effective solution stems from the research value of email archives: Email offers singular insight into and evidence of a person's self-expression, as well as records of collaboration, networks, and transactions.4 Email communications of prominent individuals, including politicians, writers, scholars, and the like, reveal not only their professional and personal actions, decisions, and creative output, but also relationships within society and communities.5 Thus, the appeal of email collections extends beyond historians to all manner of researchers, journalists, and the general public seeking to obtain insight into individuals and their transactions. This is, in part, why email is the most frequent content type requested under the Freedom of Information Act (FOIA), and is increasingly in the news, as evidenced during the 2016 presidential election cycle.6
Because use of email is so ubiquitous, and because email records provide such insight into civic, artistic, and scholarly undertakings, archival institutions of all types increasingly seek to acquire email collections.7 Indeed, at least 84% of university archives now collect electronic records including email,8 and the last major surveys of archival associations and institutions identifies email and other e-documents as one of the top three most important collection issues, with the highest marks assigned across all repository types queried.9
When Stanford Libraries began systematically exploring the landscape of tools and services to support archival workflows for email, as a member of the AIMS project,10 we found that most projects focused primarily on ingest, normalization, and preservation, rather than appraisal, processing, or the provision of access for scholarship. We have designed ePADD specifically to confront these gaps in the archival management of large volumes of email.
Initial development of ePADD was based on the MUSE software for exploring personal email archives, developed by Stanford University's Computer Science Department. From 2013-2015, with funding through the National Historical Publications and Records Commission (NHPRC), Stanford Libraries developed software based on MUSE that explores the application of natural language processing to help solve challenge routinely faced by archival institutions in administering email collections. The resulting product, ePADD Phase 1, was released in June 2015.
In November 2015, Stanford Libraries, with partners University of Illinois Urbana-Champaign, Harvard University, University of California, Irvine, and Metropolitan New York Library Council, received three years of funding from the Institute of Museum and Library Services (IMLS) to advance the formation of a national digital platform by further developing ePADD, including expanding the program's scalability, usability, and feature set, while simultaneously taking steps to engage and grow the community.11
3 Contribution to the National Digital Platform
ePADD enables a broad and diverse constituency of libraries, archives, and museums to appraise, process, and provide access to vital cultural heritage materials that would otherwise be unavailable for research. The software fills several gaps in our national digital capacity.
First, ePADD provides an integrated toolset to enable staff of memory institutions to efficiently carry out appraisal and processing of email in archival collections. These tools, which include customizable regular expression search and lexicon searches, a query generator to aid in comparative entity analysis between the archive and any other textual corpus, image attachment browsing, mailing list identification, graphical visualization, user annotation, and an interface for assigning authorized headings to correspondents and fine-grained named entities, are designed to meet the specific challenges of appraising and processing email outlined above. This includes screening large collections of email for confidential, restricted, or legally-protected information that would impede repositories from providing ready access to the materials.
Second, ePADD incorporates several automated — though user-overridable — functionalities which help optimize the provision of access to the email archive's intellectual content. These include name resolution, named entity recognition assigned to fine-grained types, and suggestion of links between both correspondents and entities and FAST, VIAF, and DBpedia persistent identifiers.
These functionalities also directly benefit scholarly researchers. For instance, ePADD offers an optional web-based discovery module12 intended to protect creator and third-person privacy, as well as copyright, while still furthering discovery of the email archive by researchers. This conceit relies heavily upon ePADD's automated resolution of correspondent names and extraction and classification of named entities.
All of these tools and functionalities are made available through a friendly graphical user interface, ensuring that non-programmers and relatively non-technical staff will be able to carry out the functions required to make email archives accessible for research. ePADD is being developed to support appraisal and processing of email archives of up to 750,000 messages using a personal computer, ensuring that the bar for participation is low enough that even institutions with relatively modest resources should still be able to take advantage of the software.
In order to help ensure ePADD integrates with the variety of other tools and services being developed in this space, and meet the diverse needs of our user community, the development team is also actively participating and exploring partnerships with many related initiatives, such as the Task Force on Technical Approaches for Email Archives, Social Networks and Archival Context (SNAC), and BitCurator NLP.
4 ePADD in Context
ePADD's development comes at a time of relative focus on email archives in the context of archival stewardship. Additional active work in this space includes Harvard's Electronic Archiving System (EAS), the Smithsonian Institution Archives' DArcMail, work performed by the State of Illinois and University of Illinois around Processing Capstone Email Using Predictive Coding, and the multi-state Transforming Online Mail with Embedded Semantics (TOMES) project.
There have also been several recent meetings and working groups convened at the national and international levels to explore how current tool developers, service providers, and the cultural memory community can more systematically define technical workflows for email and help ensure tool interoperability (in several ways mirroring the goals of the IMLS national digital platform funding priority). These include the Email Archiving Symposium (Washington, DC, June 2015) and subsequent Email Archiving Interest Group, co-sponsored by the Library of Congress and US National Archives; and the Harvard Email Archiving Stewardship Tools (EAST) Workshop (Cambridge, MA, March 2016) and related report, July 2016. The most recent of these is the Task Force on Technical Approaches for Email Archives, co-sponsored by the Mellon Foundation and the Digital Preservation Coalition (DPC), formed in November 2016.
5 Software Overview
5.1 System Architecture
ePADD consists of four modules to support archival workflows. For the most part these incorporate similar functionality, but are designed to face different stakeholders:
Appraisal provides donors, curators, and archivists with a toolset to review and manage an email archive prior to accessioning it to a repository. ePADD can gather email from multiple sources. Upon ingest, ePADD deduplicates messages, resolves correspondent names from the address book, and extracts fine-grained entities using a custom NLP toolkit. These functionalities and others enable users to determine the relevance and importance of email messages, identify and flag confidential, restricted, or legally-protected information, and impose access restrictions prior to transfer.
Processing is designed for an archivist to further perform all functions included in the Appraisal module, including scanning for confidential, restricted, or legally-protected information, as well as other tasks that prepare the archive for discovery by and delivery to end users, such as reconciliation of correspondents and extracted entities with established authority records.
Discovery is designed to run under a standalone web server, and allows researchers to browse and search a redacted email collection prior to physically traveling to a repository's reading room to access the full corpus. Only metadata from the processed email archive is published online.
Delivery provides users with access to the full contents of the unrestricted portions of a processed email archive, including attachments, from a managed workstation in a repository's reading room.
5.2 Technical Specifications
ePADD builds on other open source and freely available technologies. The ePADD client software is browser-based, and designed for compatibility with Chrome and Firefox browsers. ePADD is written in Java and Javascript and powered by Apache Tomcat using Java EE Servlet API and Java Mail. Text and metadata extraction, indexing and retrieval is performed by Apache Lucene and Apache Tika. Charting and visualization is supported using the D3-based reusable chart library. Other Java libraries from Apache (Lang, commons, CLI, IO, logging, etc.) are also used. JSON formatting is performed with the libraries org.json and Gson. The project is developed with IDEs like IntelliJ Idea and Eclipse, built with Apache Maven, Ant, and custom shell scripts, and tracked using Git for source control and issue tracking. The software is currently optimized for OSX 10.10/10.11 and Windows 7/10 machines, using Java 8. Oracle's Java Application Bundler and Launch4J are used for packaging on Mac and Windows platforms respectively.
6 Work Performed to Date
Our principal goals during this grant period are to expand the program's scalability, usability, and feature set, while simultaneously taking steps to engage and grow the community.13 The following examples highlight ePADD's progress in achieving these goals since the start of IMLS funding in November 2015.
6.1 Expanding ePADD's scalability, usability, and feature set
ePADD has taken several steps to ensure that the software better meets the needs of our users. Development has focused on three key areas: improving the ability of users to screen large collections of email for confidential, restricted, or legally-protected information that would impede repositories from providing ready access to the materials; optimizing the provision of access to the email archive's intellectual content; and building greater support for user customization and workflow interoperability.
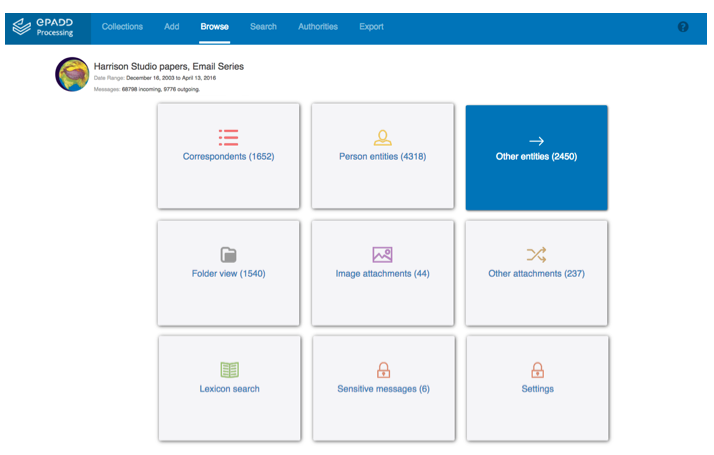
Figure 1: Browse options in the Harrison Studio papers — Email Series, Stanford University, ePADD Processing module, 2017 (Version 3.0).
6.1.1 Improvements relating to screening email archives for confidential, restricted, or legally-protected information
The ePADD Appraisal and Processing modules include a variety of functionality that supports screening email archives for confidential, restricted, or legally-protected information. These tools include customizable regular expression and lexicon searches (including ten default lexicons developed by the user community, several of which are specifically designed to identify these types of information), a query generator to aid in comparative entity analysis between the archive and any other textual corpus, and an image attachment browser.
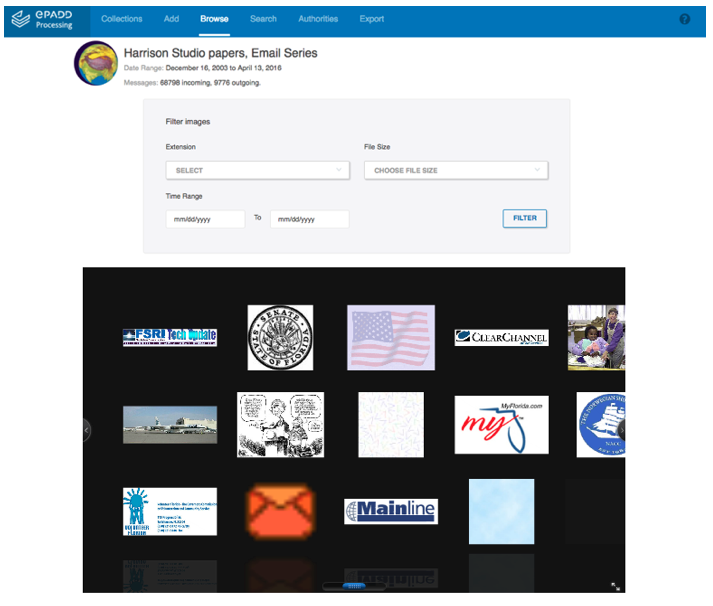
Figure 2: Browse image attachments in the Harrison Studio papers — Email Series, Stanford University, ePADD Processing module, 2017 (Version 3.0).
Beginning with the 2.0 release in July 2016, ePADD introduced mailing list identification, as well as an advanced search interface, which has grown increasingly sophisticated over successive releases. Starting with the 3.0 release in March 2017, for example, users can perform a search for messages containing entities from the disease entity category, or hits from the sensitive lexicon, and further limit this search by mandating that the search should exclude results from a mailing list. In this way a record creator could search for potentially sensitive information to embargo for a specific period of time or to not transfer to a repository, while avoiding much of the likely harmless noise that might otherwise be present in the results. (The user may also direct their actions expressly at mailing lists that ePADD has identified, by manually editing or overriding the email addresses ePADD has added to that list.)
We have also continued to develop functionality to support the bulk processing of sets of email messages according to user-defined criteria; for instance, the user can assign annotations or actions to the set messages that result from an advanced search or to all correspondents included in a provided CSV file. In the case of the Processing module, for example, this enables the user to more efficiently mark sets of messages for deaccession, restriction, or as approved for public access.
6.1.2 Improvements that optimize the provision of access to the email archive's intellectual content
ePADD includes a variety of powerful features and analysis tools that help prepare the data for visualization and analysis by various stakeholders, including record creators, curators, archivists, researchers, and others. These include name resolution, whereby ePADD resolves the variety of names and email addresses that can be associated with a given correspondent into a single identity; and named entity recognition, whereby ePADD recognizes and classifies certain categories of named entities contained within email messages and message headers.
Perhaps the most dramatic improvement has been with regard to named entity recognition (NER). ePADD relies upon NER to both help drive appraisal and processing and to support research, by enabling users to: browse across categories of classified entities, incorporate entity categories and tokens as search criteria, and generate comparative entity analysis queries between the email archive and any other textual corpus. ePADD also relies heavily upon NER for the optional web-based Discovery module, which provides researchers with online access to a redacted version of the email archive. We see great value in this interface for enabling researchers to make better informed decisions around accessing the complete email archive, and improvements to named entity recognition therefore provide direct benefit for discovery and delivery of these materials as well.
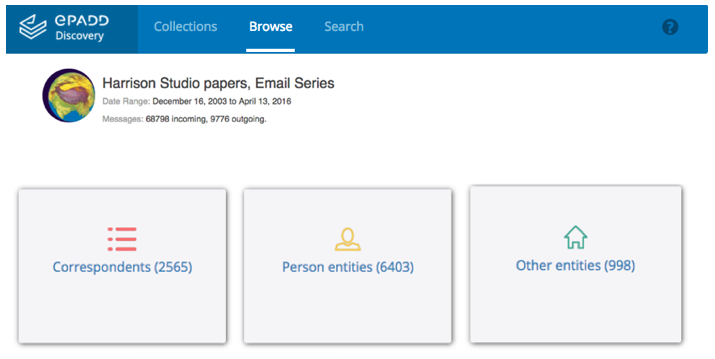
Figure 4: Browse options in the Harrison Studio papers — Email Series, Stanford University, ePADD Discovery module, 2017 (Version 3.0). (Retrieved from epadd.stanford.edu.)
ePADD's initial release (1.0) in June 2015 included a custom Apache OpenNLP named entity classifier that identified and extracted persons, organizations, and locations from the archive. Beginning with the 2.0 release, we implemented a new custom named entity classifier that includes fine-grained named entity types of organizations and locations bootstrapped from DBpedia, such as universities, companies, and governmental agencies, as well as other entity types (such as events and diseases, the latter of which can assist with searching the archive for confidential information). ePADD learns the affinity of different tokens from these categories, to help recognize and classify likely entities that do not themselves appear in DBpedia. The classifier also incorporates variants, such as Robert and Bob, automatically from DBpedia variants.
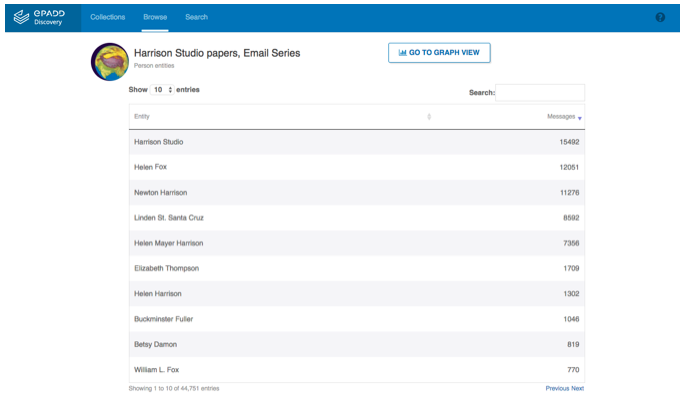
Figure 5: Browsing person entities in the Harrison Studio papers — Email Series, Stanford University, ePADD Discovery module, 2017 (Version 3.0). (Retrieved from epadd.stanford.edu.)
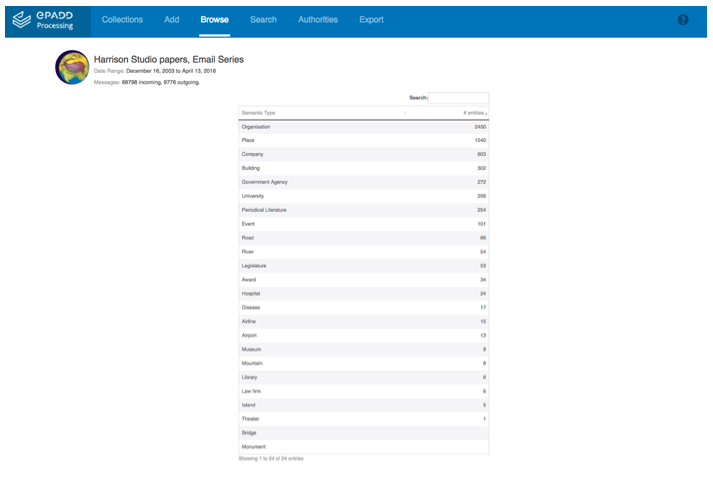
Figure 6: Browsing fine-grained entity categories in the Harrison Studio papers — Email Series, Stanford University, ePADD Processing module, 2017 (Version 3.0).
Beginning with the 3.0 release, ePADD provides an entity merge interface, which enables users to override match algorithms, by merging named entities (including selecting the preferred entity name), classifying named entities under a different category, or completely suppressing text-strings from appearing as entities within ePADD.
In all, these improvements (which also carry over to the researcher-facing Discovery and Delivery environments) allow users with limited technical knowledge to make effective use of ePADD in support of appraisal, processing, and research. They also democratize use of natural language processing techniques by the cultural heritage community, by offering an alternative to command line tools. In this way, ePADD further advances the national digital capacity to more efficiently carry out this work at scale for born-digital collection materials.
6.1.3 Improvements relating to user customization and workflow interoperability
ePADD is intended to be flexible and freely incorporated by a variety of institution types in a multitude of contexts. To this end, beginning with the 2.1 release, ePADD has included a customization file that allows users to customize their installation of ePADD, including selecting a default module and default lexicon, as well as selecting the location of installation and settings directories, which can, for example, enable multiple users to process a single collection via a shared workstation.
We have also improved and streamlined the export interface, in order to support a greater variety of institutional workflows and interoperability with other software. ePADD supports exporting confirmed authority records for correspondents and fine-grained named entities. Beginning with the 3.0 release, ePADD optionally enables users to export email directly to MBOX from the Appraisal module, without first needing to import the archive into the Processing module. Additionally, ePADD now optionally allows users to export only attachments from both the Appraisal and Processing modules, according to a variety of user-specified criteria.
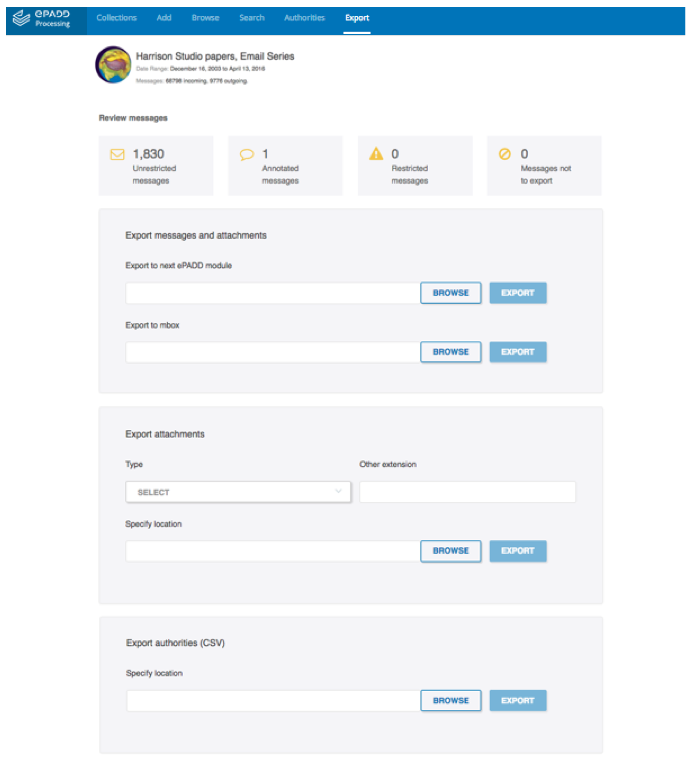
Figure 7: Export Options in the Harrison Studio papers — Email Series, Stanford University, ePADD Processing module, 2017 (Version 3.0).
ePADD 3.0 also introduces persistent message identifiers to help support a variety of institutional workflows, including remote delivery of email messages specified by researchers, as well as ingest of messages to institutional preservation repositories.
6.2 Engaging and growing the user community
Improving our national digital platform means more than just designing software that fulfills a niche in our national digital capacity; it also means providing a broad array of individuals and institutions with the expertise and support to successfully deploy that software in a variety of contexts. For this reason, we have taken several steps to build our community, including ensuring that our users have the documentation, training resources, and other support they need. In addition, we hold regular training workshops throughout the year.
We have also helped ensure that the software is responsive to the needs of an ever-growing user community, by collecting user stories and use cases, convening focus groups and user forums, and forming working groups examining select areas of the software, such as the ePADD Lexicon Working Group, which has had a strong impact on ensuring that ePADD's default lexicons reflect a broad range of collections and community interests. We also ensure regular and timely updates to our user community, through webinars, conference presentations, articles, and social media.14
7 Preliminary Results
ePADD is being used by Stanford Libraries to ensure that contemporary intellectual content — including the email of American Black Mountain poet Robert Creeley, and environmental artists Helen and Newton Harrison — are discoverable by scholars. Several other email archives at Stanford are currently in the process of being made discoverable, including the email of Computer Science professors Terry Winograd and Richard Fikes.
Beyond Stanford, ePADD has also been adopted by dozens of other academic libraries and cultural heritage institutions, in order to appraise and process a diverse set of email archives across these institutions.15
Much of the functionality that has been developed within ePADD has been a result of specific needs requested by the user community. For instance, the ability for users to take bulk actions across the email archive (such as restricting messages) based on a provided CSV of correspondents, the ability for users to decide on whether the default appraisal action should be to transfer or not transfer all messages to a repository, and the ability to export directly to MBOX from the Appraisal module, without first needing to import the archive into the Processing module, were all functionalities developed as a result of requests by the broader ePADD user community.
We have received requests from several institutions for a community-driven online discovery environment for email (relying upon ePADD's Discovery module), that would lower the bar for institutions to take advantage of this module, while supporting federated search and browsing across all email archives processed through ePADD. Although exploring the potential for cross-institution discovery was already on our development roadmap for this grant period, this feedback has further convinced us of the merit of developing a cross-institution discovery service.
8 Next Steps and Future Directions
We are now approaching the halfway mark of this three-year grant period, and while we are excited about the work we have accomplished, much more remains to be done. Remaining goals include advancing ePADD's support for restriction and derestriction of materials; continuing to optimize ePADD performance at scale; and development of cross-collection search and browsing.
We also plan to develop support for exporting message headers as GraphML for network visualization, and correspondents and fine-grained named entities as linked open data. In some cases this process can be fully automated — for instance, certain fine-grained entities matched to DBpedia entries can likely be automatically exported with persistent identifiers with a fairly high level of confidence. In other cases, such as with correspondents, users may wish to manually review links to suggested authorized headings provided by ePADD prior to export.
We will also continue promotion of ePADD's integration within an ecosystem of projects, software, services, schema, and processes supporting archival technical workflows for email, including preservation. This includes continuing to explore additional customization options within ePADD, to further support diverse community workflows and institutional requirements.
Community engagement efforts will continue through workshops (including "train the trainer" exercises), focus groups, user forums, and social media outreach. We were impressed with the success of the Lexicon Working Group — we hope to similarly advance policy and workflow discussion and support within ePADD through the formation of additional working groups. We are also sponsoring a hackathon for personal digital archiving in Spring 2017, as well as an online conference geared towards better understanding the requirements of government archives, scheduled for later in the year.
Additionally, there are several analysis functions that we are exploring incorporating into the software, such as entity co-occurrence analysis to aid with entity disambiguation across fine-grained named entity categories; and topic extraction from messages and threads based on the co-occurrence of entities and lexicon results.
The roadmap for ePADD's future development beyond this grant period (which depends largely on the continued availability of external funding) includes the development of cross-institution discovery capabilities and the creation of a web service to federate search and browsing across all content that has been processed through ePADD worldwide, in order to streamline the discovery of this content by scholars.
We aim to explore future collaborations with ongoing efforts by the cultural heritage community, including around linked open data.
We would also like to assist cultural heritage institutions (in particular non-developers) in extracting structured data from other types of archival collection materials in a more automated fashion, by extending these same computational techniques and bulk processing functionalities towards other genre types and file formats collected by these institutions, including social media. Eventually, we hope to enable integrated discovery and delivery environments for born-digital and digitized files to take full advantage of the scale of automatically-derived metadata generated through these types of computational analysis.
ePADD's continued development fills a gap in our national digital platform around archival processes, expertise, and support for email. We look forward to continuing to improve the software and grow the user community, while working with other projects and initiatives to help ensure that cultural memory institutions adopt a holistic approach to developing solutions for the appraisal, processing, discovery, and delivery of born-digital cultural heritage materials.
Notes
| 1 |
Hangal, S., et al. (2014). Historical research using email archives in special collections. Proceedings of ACM CHI Conference on Human Factors in Computing Systems. Toronto, Canada; Fung, B. (2015, February 10) Uh-oh: Jeb Bush's 'transparency' effort also exposed Florida residents' personal data. Washington Post. |
| 2 |
National Archives and Records Administration. (2010). Processing the presidential records of Elena Kagan. |
| 3 |
See Virginia Memory Collection, Look Under the Hood. |
| 4 |
Zhang, J. (2015). Correspondence as a documentary form, its persistent representation, and email management, preservation, and access. Records Management Journal, 25(1), 78-95.; Sinn, D., et al. (2011). Personal records on the web: Who's in charge of archiving, Hotmail or archivists? Library & Information Science Research, 33(2011), 320–330; Pennock, M. (2006, July), Curating e-mails: A life-cycle approach to the management and preservation of e-mail messages. In DCC Digital Curation Manual, S. Ross & M. Day (Eds.). |
| 5 |
E-mail and potential loss to future archives and scholarship, or, the dog that didn't bark. First Monday, 4(9). |
| 6 |
See for example Guillén, A. (2017, February 22). Pruitt emails show close ties to oil, gas interests. Politico; Lipton, E. (2016, December 16). The Perfect Weapon: How Russian Cyberpower Invaded the U.S. New York Times; Chozick, A. (2016, October 11). John Podesta Says Russian Spies Hacked His Emails to Sway Election. New York Times; Harding, L. (2016, April 5). What are the Panama Papers? A guide to history's biggest data leak. The Guardian; What e-mails have shown us about Flint water crisis (2016, February 19). Detroit Free Press. |
| 7 |
See for example: Brown, M. (2014). Ian McEwan's literary archive bought by Harry Ransom Center for $2m. The Guardian; Harry Ransom Center (2013). McSweeney's Archive Acquired by Harry Ransom Center; Howard, J. (May 6, 2011). On a New Frontier for Archives, British Library Buys Poet's 40,000 E-Mails. 57(35) Chronicle of Higher Education, p. A25; Wright, M. (May 10, 2011). Why the British Library archived 40,000 emails from poet Wendy Cope. Wired UK. |
| 8 |
Noonan, D., & Chute, T. (Spring/Summer 2014). Data Curation and the University Archives. The American Archivist, 77(1). |
| 9 |
Dooley, J.M., & Luce, K. (2010; updated 2011). Taking our pulse: The OCLC Research survey of special collections and archives. Dublin, Ohio: OCLC Research. |
| 10 |
AIMS Work Group. (2012). AIMS born-digital collections: An inter-institutional model for stewardship. Retrieved from http://www2.lib.virginia.edu/aims/whitepaper/AIMS_final.pdf |
| 11 |
Email: Process, Appraise, Discover, Deliver — ePADD Phase 2. Project Proposal, National Leadership Grant for Libraries, Insitute of Museum and Library Services. |
| 12 |
For example, see the Discovery module for Stanford University's Special Collections & University Archives. |
| 13 |
See Stanford University Libraries — Email: Process, Appraise, Discover, Deliver — ePADD Phase 2. |
| 14 |
See Stanford Libraries, ePADD, Presentations & Publications. |
| 15 |
See Stanford Libraries, ePADD Users. |
About the Authors
Josh Schneider is Assistant University Archivist at Stanford University, where he acquires and supports researcher use of Stanford University records, faculty papers, and materials documenting campus and student life. Josh serves as ePADD Community Manager. His case study on appraisal of electronic records appeared in the latest volume of the Society of American Archivists' Trends in Archival Practice series. Josh serves on the editorial boards of The American Archivist, Journal of Western Archives, and the blog of SAA's Electronic Records Section (BloggERS!). He received an MLIS from Simmons College and a BA in Philosophy from Brown University.
Peter Chan is Digital Archivist at Stanford University. Peter serves as Project Manager for ePADD. He pioneered the use of AccessData FTK to appraise and process born-digital collections, and has built workstations which can read FAT-formatted 5.25 inch floppy disks in native mode. Peter proposed the use of SKOS controlled vocabularies for platforms and storage media as part of the IMLS-funded GAMECIP project. He was Vice President for Operations and Planning for Bank of America, Asia. He also served as a Lecturer in the Chinese University of Hong Kong, teaching computer applications in accounting.
Glynn Edwards is Head of Technical Services for Special Collections at Stanford University, where she oversees the acquisition, cataloging, and processing of incoming archival collections (in any format) and rare and antiquarian books. Glynn serves as ePADD Project Director. She helped design and manages the department's Born-Digital Program in collaboration with Stanford Libraries' Digital Libraries Systems and Services. Glynn is also part of an IMLS funded collaborative project to develop best practices for cataloging and citing computer games (GAMECIP). She received an MLIS and an MA in History from Simmons College and an AB in Classics from Brown University.
Sudheendra Hangal is Professor of Practice in Computer Science at Ashoka University, where he also co-directs the Trivedi Center for Political Data. Formerly, he was the Associate Director for the Mobisocial Lab at Stanford University. Sudheendra developed the MUSE software for exploring personal email archives, and serves as Technical Advisor for ePADD Phase 2. His research explores the areas of social computing and human-computer interaction.