|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Thomas Mestl, Olga Cerrato, Jon Ølnes, Per Myrseth, Inger-Mette Gustavsen Point of Contact for this article: Thomas Mestl, <Thomas.Mestl@dnv.com> |
![]()
|
It is hard to predict what the major challenge in search will be 100 years from now. The challenge may not even be related to information retrieval itself but could be the result of shortages of electricity, network disruptions due to insurgencies, information manipulation or access denial by an uncontrolled computer-based artificial intelligence (as imagined in the science fiction movie The Terminator). Of course, we could simply extrapolate the current ongoing trends, which we know do have an effect on information storage and retrieval, and might hope this gives an indication of some of the challenges that may affect finding and understanding information in a long-term perspective. In this article our focus will be on challenges that can be traced back to Time. Search is a two-sided issue: On one side, once data has been generated it has to be stored somewhere (on volatile or non-volatile media) and this stored data must somehow be accessible to a search or indexing engine; on the other side are the processes of search, retrieval and analysis of the data.
Finding the right information is not just about search; preparing the data for storage (and search) is at least as important. In this article we will point out some of the main challenges that may be encountered in search and retrieval across decades- or centuries-old digital objects. At present digital archives are full of textual documents, ones that are either 'born digital' in a text editor or that are scanned versions of paper-based documents. Scanning combined with optical character recognition (OCR) is still an important task of archives, but already today on a global basis more than 99.99% of all new information is generated and stored digitally.1 Scanning/OCR can thus be regarded as a transient phenomenon only. Additionally, one can predict that the majority of digital objects will not be textual documents but rather combinations of text, audio, video, images and other digitally born material. As time goes on, new types of digital information or knowledge carriers will certainly be invented. It is not hard to imagine that a future search agent could possess a considerable degree of artificial intelligence and that it may automatically evolve its search and analysis capabilities, e.g., by genetic programming. But no matter how intelligent this search agent may be, it will face time-related challenges when it navigates through cyberspace. Thus, interesting questions arise including: How will time affect the search and retrieval process and the understanding of data? How shall this time dependency be visualized or made explicitly available to the end user?
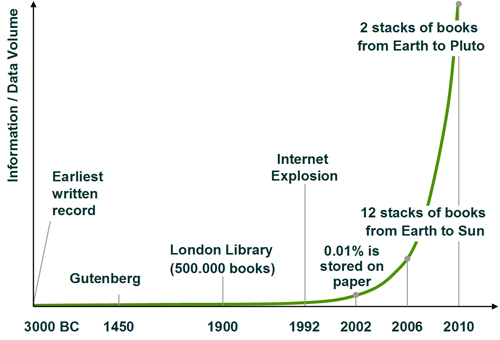
Figure 2 above provides a visualization of the historic development of information generation. Nearly 100% of all information is today generated and stored digitally. The Meaning of TimeThe indexing of information will be increasingly difficult, not only due to the characteristics of non-textual media types but also because search indices sooner or later will have to explicitly take time into account – but what does time mean anyway? From a long-term perspective, time becomes one of the most important characteristics of a data record. There are several variables (metadata) in a data record that explicitly relate to time such as:2
In addition it might be necessary to add:
A time stamp may provide the desired time references for the first two or three bullet points. Unfortunately, two data objects generated simultaneously but at different locations conceivably could receive different time stamps – up to 24 hours difference – as the locations may exist in different time zones. Specifying an exact moment in time in the metadata may actually be more difficult then expected and could complicate the understanding of causal references. However, there are several standards that could be used to code time more precisely.3 Furthermore, the exact age of a digital record will depend on the definition of its "time of birth". Is it the time a document was created, or is it the last time someone made some significant changes in the document (depending on what is meant by significant)? In many situations digital objects may be in use for many years, and an exact time of data creation cannot be assigned to them. Version control could shed more light on the detailed editing history of a document prior to publication, but it is doubtful whether such information will be stored over the long term or will be accessible to search engines. Time windows of varying sizes or fuzziness might then be more appropriate than trying to determine an exact time of data creation. When searching for objects that were created within a certain range of time, the time parameters in the metadata (e.g., time of file generation or alteration) could be insufficient, as they do not give any time information about the content in the file. For instance, searching for document records about World War II, a time window between 1939 and 1945, would only result in records that originated during the war. All documents about the war that were written after 1945 would not turn up in the search. Time references within a digital object could be time intervals or exact dates. From a search perspective these time references are unfortunately not always explicitly given but are very often provided indirectly – and are usually language and culturally dependent. For example, the terrorist attack on the World Trade Center has introduced a new "time frame" – i.e., the time before and the time after 11th of September 2001 (or "911" for short). A similar, although much less clearly defined time frame, would be the onset of the Internet, which took place somewhere between the 1980s and 1990s, or the reference to music or art styles, e.g., hip-hop (1970 →) or Art Nouveau (1880-1914). The effect of timeSearching for decades-old digital information will mean encountering a variety of ways that time was encoded, and searchers will especially experience the effect of time. Time does not only make people forgetful and equipment obsolete, but even more important, it affects the way people talk, describe and understand things. By definition, time is always related to changes; if nothing changes, time 'stands still'. Over decades or centuries these and other time-related changes will become a growing challenge for information search. Search will have to deal with changes in:
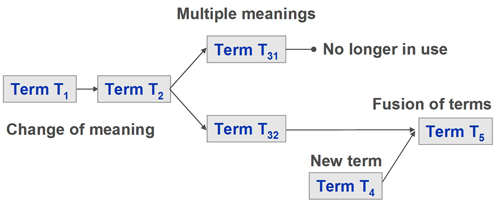
These change-processes are continuously occurring, though they may not be immediately noticeable because they usually have only subtle effects in the short term. However, occurring over decades, the result of these small effects may accumulate and completely alter the meaning of a term. Prime examples are words that have gradually obtained additional meanings with the introduction of information and communication technologies (ICT), such as application, compress or Windows. Sometimes the original term may not even be in use anymore or has been replaced by several more precise ones. Old and new terms will either have to be mapped between each other or backwards in time with as little loss of precision as possible. However, these backwards mappings will have to be done with as much background information as can be found.
The gradual change of semantics by alteration, fusion, split or birth of new meanings of terms or concepts will considerably complicate search in decades-old data (see Figure 3). Semantic backwards mapping may not be unique. Preparation of a search query to find data that were created decades ago will become more critical and time consuming. It is imaginable that in the future some automated interpreter might be developed to assist in the conversion of the semantics from one time period into another – either for preparation of the search or for analysis of the search results.4,5 Such a converter would have to take into account the fact that semantics vary between languages, and even within the same language as used in different societies (e.g., the language of the UK versus Australia), or groups within societies (e.g., the Indian cast system). The semantics may not even be unique in pure technological terms, e.g., power supply: 230V vs. 110V. Such changes in semantics will have to be reflected in the indexing of data as well. At present search indices do not explicitly take into account the gradual change of meaning over time. The indices are too static, and this will result in less precision when users formulate queries based on:
An example of these challenges can be seen when parents try to help their children with school work but their terminology has become somewhat misaligned. Reducing semantic ambiguity will increase the quality of search results. It may therefore be advantageous to have a longer time perspective in mind when preparing, indexing and especially storing data. One can only find what's been storedHigh semantic value translates to high data quality and indexing, which means structuring the data and supplying enough metadata. If the data generator does not supply an adequate amount of relevant metadata (especially for non-textual data), it may be difficult if not impossible to interpret and understand the stored data correctly. Then, the questions arise: what are the right metadata, and what other additional information should be stored to understand the context of the data? Some guidance may be found in data models and metadata sets such as Dublin core6 and MODS.7 In addition, if proprietary, encrypted, compressed or rare file formats were chosen by the content creator, then it will certainly be difficult to read and interpret that content correctly. Self-explanatory, human readable, well-specified and widely accepted formats such as XML might be preferred. If a data object cannot be interpreted without some specific hardware and/or software being available, someone someday in the future will have little use of the data unless the decoding application is somehow available too. Theory and practice is, however, not always aligned, and the fear of losing the battle of storing enough metadata may indeed be real. Falling prices in data-generating devices such as digital cameras, video, mobile phones and all sorts of sensors, together with cheaper storage media, has resulted in an exponential growth in the amount of data generated annually. According to Gantz,8 in 2006 a staggering 161 billion GB of new information was stored, with estimates suggesting that this amount will increase sixfold by 2010. If this trend continues, then 10 years later (by 2020) the amount of data generated annually will be 200 times higher than in 2008, or about 70 Zeta Bytes. Manually assigning metadata to all this information will be impossible, and the need for automated, context-aware metadata assignment will increase. Drowning in dataMuch of the data generated each year will stem from formerly analogue sources such as film, voice calls and TV signals, and it is assumed that individuals will be the source of the majority of the data, i.e., about 70% of it. In the not too distant future, this could lead to a change towards more system-based data generation as exemplified by surveillance systems, remote operations, automated control or automated analysis of biological systems (e.g., genomics, proteomics). Storing all these data may become a serious problem, as according to Gantz, in the year 2007 the amount of digitally created information surpassed the available storage capacity.
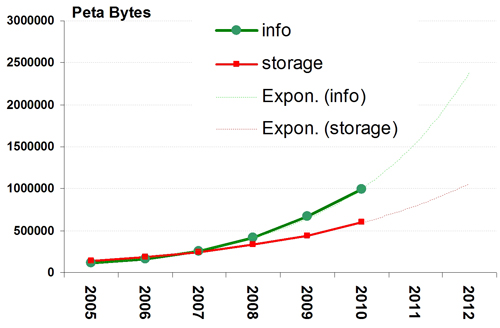
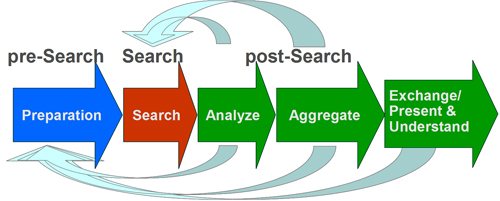
As illustrated in Figure 4, the annually expected growth in global data generation and storage capacity shows clearly that not all data generated can be stored8. If this trend continues then by 2012 there will be storage space only for half of the newly generated data. Whether the discrepancy between the amounts of data versus storage capacity will increase further in the disfavour of storage will depend on how successful the development of future storage technologies will be, e.g., holography or even protein-based storage technologies. With the current growth rate in storage capacity of about 37%, significantly below the estimated 57% increase in information growth, the issue of 'What shall be stored?' becomes evident. Decay-time of information valueThe time span an object should be kept depends on its value to the current user or some future user. Sometimes this time span is specified by law (e.g., in accounting), leading to a stepwise value function. After the mandatory time, the information value drops to zero or becomes very low. Deletion may even be mandated, e.g., for privacy reasons. In other situations the information value may gradually decay either slowly (e.g., books), or relatively quickly (e.g., weather news and stock market prices). Such a decay-time is tightly coupled with the life span of the processes (or persons) that use the information. If a person dies, a company is dissolved, a business process is reengineered or a law has been terminated, then the information may no more be needed. Processes or the legal environment, however, may lead to requirements for storing 'dead' information as long is it may be needed as evidence, in court or otherwise, of what was going on in the past. Then the question arises: what should be preserved for historical reasons, to document cultural heritage and for future research? Materials that may seem to have a very limited lifetime (e.g., commercials) may turn out to be of high value for describing the society and the time period in which the materials were created. Thus, deleting information that is no longer needed for any 'practical' purpose may not be wise. The explosion in the amount of data created will require specifying not only how to store information (format, metadata etc.) but increasingly what must, should, and could be stored, and especially what should definitely not be stored. One of the selection criteria could be time, or more exactly, the time frame in which an object has some certain information value. On-the-fly or context-based generation of information may be embedded in, or very tightly coupled with, quickly evolving technologies such as games, blogs or viewers (e.g., Flash). Such objects will represent a major challenge to preservation, as the objects are not necessarily stored and/or require specific software to access or to read them. When the majority of new data no longer can be stored, then the only way to utilize them is to immediately process, analyse and combine them with existing information. In this respect the data universe may gradually resemble the electricity grid, where the electricity produced must be consumed immediately. First, after a further refinement of the raw data into a smaller sub-set, the information may then be stored somewhere. In other words, the information value of raw data approaches zero, and these data will therefore not be kept – only their aggregation with a higher information value will be available in the future. Search and RetrievalWith an exponentially growing volume of data, it can be expected that all aspects of search will increasingly be more challenging in the future. If the majority of newly generated data no longer can be stored, but only their aggregation, then this has a tremendous effect on the way future search will have to be done. In these cases the search engine will have to be at the right place at the right time to index the raw data if these data are needed for search. This type of search will, however, fall outside a search perspective where data objects are decades or centuries old. Search and retrieval may roughly be divided into three parts: pre-search (preparation), search and post-search. Post-search in turn can be divided into analysis of search results, aggregation, exchange/presentation and understanding. Finding the right data is an iterative process where search results are analysed and new searches are initiated. The intended use determines the quality of the search results, and a main obstacle is to give an explicit description of what is actually desired. If all information about a subject shall be found, e.g., information about a person, then completeness would be a major quality parameter. As pointed out above, in a query preparation time will have to be explicitly taken into account as the terms that were in use, say 40 years ago, may vary considerably from today's terms, depending on the subject. A semantic time map specifically generated for a selected field of interest could therefore help to identify the correct search terms with respect to time.
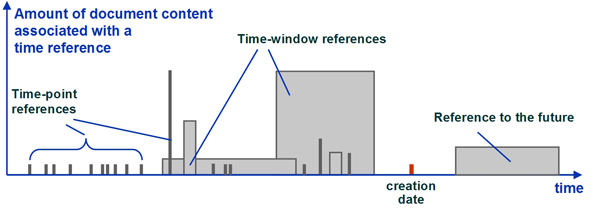
Organizational searchEven greater problems arise when searching inside an organization where not only the meaning of terms but most certainly also the organizational structure, roles and titles will have undergone considerable changes. Mergers, acquisitions or sell outs will complicate the situation further. A time series of detailed mappings between changing organizational charts and roles may be needed. Such maps usually do not exist, nor can they be generated in retrospect. If access rights to some old information objects were originally assigned to specific roles, the objects may become inaccessible following reorganizations. Organizational changes frequently lead also to replacement or introduction of new administrative or technical systems. Usually, only subsets of the digital objects in the old system are converted and transferred to the new system. Search functionality is increasingly offered through front-end (portal) applications, but when an old front-end application is replaced, many of the data objects may no longer be found or accessed. In addition, much of the information within an organization is confined to numerous silos only accessible through often incompatible search engines.9 In addition, documents could be encrypted, complicating search even more.10 Changes in company policies frequently occur in the wake of reorganizations. The management of important information objects may be negatively affected by a temporary, more relaxed IT security policy. Search may then be used not only to find a digital object but also to pinpoint the exact time when it lost some of its trustworthiness. Searching the often encrypted logs would then be important – but the content of logs can be considered as sensitive information.11 Aggregating into confidentialityIn order to improve the quality of the outcome of a search, in the future more focus may be on the analysis and aggregation of the search findings into more comprehensible and condensed results. Interestingly, the development of effective search, retrieval and aggregation tools could actually lead to infringement of security or privacy laws. In a world where data about almost all aspects of science, technology and society are freely accessible, their accumulation may still not be regarded as free or innocent. Such collections may, by law, become classified, as they could be used to perform criminal activities such as blackmailing or terrorist attacks. Information aggregation can intrude on the privacy of individuals or can be used for identification theft. The aggregation of allegedly related information can have tremendous negative consequences (e.g., information about John Smith the priest could get mixed up with information about a different John Smith – the murderer). Internet searchIn cyberspace, currently nearly 90% of all data are unstructured,12 i.e., either they do not have a data structure, or only have one that is not very usable or easily readable by computers. Examples of unstructured data include: digital images, voice, email, SMS, and most textual documents. About a third of all data are duplicates. The situation is not considerably better within organizations, where about 80% of the organizations' data is unstructured. Time introduces only a very weak form of structure, as it only orders objects chronologically. This lack of general structure represents a considerable challenge for search engines and result analysis. In the long term even structured data may risk losing some of their structure, as links, relationships, or references to the correct version of data models may be broken, unreadable or inaccessible. Another change that will definitely affect data storage, search and retrieval will be the growth of the Internet and the dispersal of information technology into new ethnic groups and areas throughout the world. Due to historical, technological and economical reasons, the dominant Internet language today is English – which is also reflected by the high Internet penetration rate of about 71% in North America. The high economic growth rates in emerging Asian countries, combined with their low Internet penetration of just 14%, will lead to a shift of the centre of Internet gravity towards the East. Accompanying this shift will be changes in meaning and use of many existing terms, and of the preferred language. Chinese may become the dominant Internet language that may frequently be encountered in future search queries. This is, of course, true for all languages that are used when creating digital objects. When searching for old information, these multi- or cross-lingual semantic aspects will have explicitly to be taken into account. Search and communication of temporal informationAssume a search query has resulted in a long list of highly relevant hits. The temporal information of the individual results, i.e., metadata such as date of creation, last modification, etc., would allow a filtering or a chronological ordering of the hits. This is essential when searching for news, but usually is of little relevance when dealing with older information. When searching for digital objects that refer to some specific time period (past or future), the time period covered by the content is of importance. A future scenario description or some science fiction novel is not temporally fixed by its creation date but by its content time. If the content is tagged with adequate and useful time metadata, then this may be no problem; but very often, temporal content metadata tags are especially lacking in unstructured information. A prediction is that in the future more focus will be on automatic extraction of temporal information. Text or data mining and all sorts of automated feature recognition will be central in the task of extracting and analysing as much temporal information as possible from words, terminology, names, literature references, examples, style of writing, or images,13 etc. Figure 6 shows an example of an image with a series of temporal tags (or event landmarks), both time points as well as time windows, associated with the picture. [The image originally displayed in Figure 6 was removed at the request of the lead author on October 31, 2019.] The temporal metadata for the image above is (tp = time point, tw =time window):
The challenge will be to develop 'temporal analysers' that not only can make a time line representation of the content, but more importantly, also be able to estimate its weight, i.e., the amount of content, which relates to a certain time reference in a document or a picture.14 For example, a scientific paper has a publishing date, and all the literature references within the paper will also have publishing dates (time points). Some of the terminology used in the paper may refer to some time periods (or time windows), e.g., history, art, life span, etc. As some references or terminology are more important than others, they will be cited and used more frequently. For instance, a paper on New Romanesque art style could also refer to Impressionism or the Art Nouveau period, but to varying degrees. The relative weight of these references would constitute the temporal content of the paper. Figure 7 below shows how the weights of the temporal content could visualize the time-related information within a document. This or similar views may allow the end user to combine or toggle between various query result perspectives.
Figure 7 provides an example of how temporal references in a document could be visualized on a time line. Exact time references such as dates would appear as thin lines whereas fuzzy or time period references would be shown as time windows. The height of the lines or windows (i.e., weight) would provide a relative indication of the amount of information/text that is connected with a time reference. Temporal analysers will have to use a series of various techniques15 to extract as much temporal information as possible from a digital file. Relevant techniques are metadata extraction, e.g., JHOVE,16 web link analysers (URL, http protocol17) natural language processing (NLP) techniques or image recognition. The temporal visualisation approach as shown in Figure 7 would indicate the various time frames within a single object like a document, but it could not be applied to visualizing results from a search query. Here the challenge lies in the condensed overview timeline. What temporal information should be displayed: the creation date, the content date with the highest weight, or any other time? So far, only sparse attempts have been made to present multiple time tags of query results.18 Usually time tags are restricted to selection of only one (often the creation time), e.g., Time Walls,19 Google Timeline,20 SIMILE.21,22,23 etc. Aggregation of all the various temporal tags into a common time tag is still an open research area. The future lies in the pastSearch and retrieval of decades- or centuries-old digital objects will be difficult, since the effect of time on these objects will continue to grow. The importance of the Internet as an information source is growing rapidly, which requires higher search competency from the user with respect to such activities as query formulation and source criticality, but also from the search provider in the form of new or better results visualisation. We point out that time is quite neglected in search, and awareness must be raised towards the upcoming challenges as well as the opportunities. The main challenge is undoubtedly the identification of temporal elements, extraction of their time references and determination of their importance. This process will impose some – although weak – structure on unstructured data. It requires, however, a temporal taxonomy, i.e., a database of words, names, terms or definitions that is related to time points or periods. Research indicates that extraordinary events can act as anchors within a time reference.24 Most probably these time relations will not be unique as a term may not only change meaning over time, but also have ambiguous meaning dependent on time relations, e.g., the Great War, President Bush. Most of these time relations will be relative to when they were used. In 1920 the Great War was World War I, whereas in 1946 it became World War II. Other terms like 'Future' or 'Past' are entirely relative to the time the digital object was created. We believe that by incorporating and better handling the concept of time, both in storage as well as search, we will also be able to utilize more of the data we are currently storing. If we do not succeed in this task, then we will certainly drown in all the 0s and 1s. AcknowledgementThis article was prepared in connection with the LongRec25 research project, which addresses issues related to Read, Understand, Trust and Find of decades old digital objects. This project is partly funded by the Norwegian Research Council. Notes and References1. See <http://www2.sims.berkeley.edu/research/projects/how-much-info-2003/>. 2. Dekkers, M. Craglia, M. (2008) Temporal Metadata for Discovery. Spatial Data Infrastructures. Unit of the European Commission Joint Research Centre to AMI SARL. 3. ISO 8601:2004, ISO 19108:2002, W3CDTF, TimeML and ISO/CD 24617-1, RFC3161. 4. Klein, M. C. A; Kiryakov, A; Ognyanov, D; Fensel, D. (2002). Finding and Characterizing Changes in Ontologies. Proc. of 21st Intl' Conf. on Conceptual Modeling, Tampere, Finland, LNCS Vol. 2503, Springer-Verlag, pp. 79-89, 2002. <doi:10.1007/3-540-45816-6_16>. 5. Santos, J; Staab, S. (2003) Engineering a Complex Ontology with Time. Proc. of Intl' Workshop on Ontologies and Distributed Systems (in conj. with IJCAI 2003), Mexico. 6. See <http://dublincore.org/documents/dcmi-period/>. 7. See <http://www.loc.gov/standards/mods>. 8. Gantz, J., et. al. (2007). The expanding digital universe: A forecast of worldwide information growth through 2010. IDC http://www.nec-computers.com/LocalFiles/Site2007/specs/storage/WhitePaper_DSeries-uk.pdf>. 9. Lederman, A. Deep Web Technologies, New Mexico. 10. Park et al. (2005) Searchable Keyword-Based Encryption. <http://eprint.iacr.org/2005/367.pdf>. 11. Waters, B. et al. (2004) Building an Encrypted and Searchable Audit Log. NDSS Symposium 2004. 12. Blumberg, R; Atre S. (2003) The Problem with Unstructured Data. DM Review Magazine. 13. Graham, A; Garcia-Molina, H; Paepcke, A; Winograd, T. (2002) Time as Essence for Photo Browsing through Personal Digital Libraries", Proc. of 2nd ACM/IEEE Joint Conf. on Digital Libraries (JCDL '02), p. 326-335. <doi10.1145/544220.544301:>. 14. Swan, R. C; James, A (1999) Extracting Significant Time Varying Features from Text, Proc. of 8th ACM Intl' Conf. on Information and Knowledge Management (CIKM '99), pp. 38-45, 1999. <doi:10.1145/319950.319956>. 15. Wong, K., Xia, Y., Li, W. and Yuan, C. (2005) An overview of temporal information extraction. International Journal of Computer Processing of Oriental Languages, 18(2), 137-152. <doi:10.1142/S0219427905001225>. 16. See <http://hul.harvard.edu/jhove/jhove.html>. 17. Amitay, E., Carmel, D., Herscovici, M., Lempel, R. and Soffer, A. (2004) Trend detection through temporal link analysis. J. Am. Soc. Inf. Sci. Technol., 55(14), 1270-1281. <doi:10.1002/asi.20082>. 18. Knolmayer, G.F; Myrach, T, (2000) The Representation of Different Time Dimensions of Web Documents through Meta-Data. (in German), Proc. of Workshop on Application of Concepts of Temporal Data Management in Database Systems and World Wide Web (ZobIS), Siegen, Germany, p. 283-290. 19. Alonso, O; Gertz, M; Baeza-Yates, R. Search Results using Timeline Visualizations. <http://www.inxight.com/products/sdks/tw/>, <http://dbis.ucdavis.edu/publications/sigir07demo.pdf>. 20. Google Timeline, <http://www.google.com/experimental>. 21. SIMILE: Semantic Interoperability of Metadata and Information in unLike Environments. <http://simile.mit.edu/>. 22. Ringel, M; Cutrell, E; Dumais, S; Horvitz, E. (2003) Milestones in Time: The Value of Landmarks in Retrieving Information from Personal Stores. <http://research.microsoft.com/~sdumais/sislandmarks-interact2003-final.pdf>. 23. Kumar, V., Furuta, R., and Allen, R. (1998) Metadata Visualization for Digital Libraries: Interactive Timeline Editing and Review. Proceedings of DL, 126-133. <doi:10.1145/276675.276689>. 24. Smith, S., Glenberg, A., and Bjork, R. (1978) Environmental Context and Human Memory. Memory and Cognition, 6(4), 342-353. 25. See <http://www.longrec.com/>. Copyright © 2009 Thomas Mestl, Olga Cerrato, Jon Ølnes, Per Myrseth, and Inger-Mette Gustavsen |
|
| |
|
|
Top | Contents | |
| | |
|
(Editorial note: the image originally displayed in Figure 6 was removed at the request of the lead author on October 31, 2019.) D-Lib Magazine Access Terms and Conditions doi:10.1045/may2009-mestl
|