|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Joan A. Smith and Michael L. Nelson |
![]()
AbstractConventional wisdom holds that search engines "prefer" sites that are wide rather than deep, and that having a site index will result in more thorough crawling by the Big Three crawlers – Google, Yahoo, and MSN. We created a series of live websites, two dot-com sites and two dot-edu sites, that were very wide and very deep. We analyzed the logs of these sites for a full year to see if the conventional wisdom holds true. We noted some interesting site access patterns by Google, Yahoo and MSN crawlers, which we include in this article as GIF animations. We found that each spider exhibited different behavior and crawl persistence. In general, width does appear to be crawled more thoroughly than depth, and providing links on one or two "index" pages improves crawler penetration. Google was quick to reach and explore the new sites, whereas MSN and Yahoo were slow to arrive, and the percentage of site coverage varied by site structure and by top-level domain. Google is clearly king of the crawl: its lowest site coverage was 99%, whereas MSN's worst coverage was 2.5% and Yahoo's worst coverage of a site was 3%. Introduction: Why Crawlers Are Important to Digital LibrariesDigital Libraries have a vested interest in encouraging search engine robots to thoroughly crawl their sites, even if the content requires a subscription or access fee. Many repositories such as those of the IEEE and The New York Times allow selected crawlers full site access so that the information will be indexed and listed in search results, potentially bringing new subscribers or item-purchasers to the sites.1,2,3 The information is thus made visible even to non-subscribers, who typically get directed to an abstract or summary page, from which point they have an option to purchase the item or subscribe in full. Such users may not take advantage of facilities like local university libraries but instead rely completely upon Google, Yahoo, and MSN (the "Big Three") to find this information, whether it is free or fee-based.4 But how do these crawlers approach new and not-so-famous sites? Are they equally thorough in their crawls? Does the design of the site – deep or wide – affect robot behavior? Are there strategies that increase crawler penetration? Google, for example, makes specific recommendations with regard to site organization, number of links per page, and the use of a "sitemap,"5 but it will nonetheless crawl sites that do not follow their guidelines. Research into crawler behavior has usually focused on either building smarter crawlers or on improving site accessibility to crawlers. In this article, we are looking at the problem from the other side: Given certain website designs, how do crawlers perform? We set up four websites, two in the dot-com domain and two in the dot-edu domain, to see how the Big Three crawlers approached very wide-and-deep websites. This experiment builds upon an earlier experiment in which we created websites with content that gradually disappeared, to test the persistence of the missing content in search engine caches.6 Those test websites were relatively narrow and shallow, and were thoroughly crawled. We wondered if crawlers would be as aggressive at sites that are significantly wider and deeper.
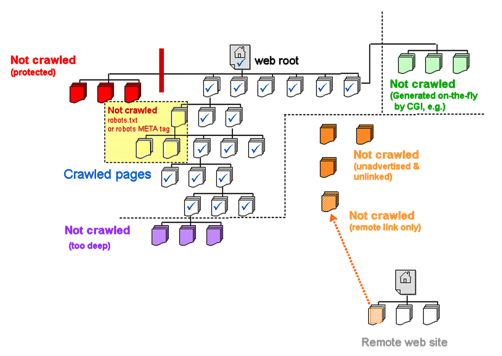
The Mechanics of Crawling: A Quick ReviewMost websites have a "root" or "home page," which is typically named index.html and which is the default page a user sees when visiting a site. Typing http://www.dlib.org into the browser address bar is in fact a request for the "root" document of the site, which in our example is http://www.dlib.org/index.html, labeled "web root" in Figure 1. From that point on, site discovery depends on following the links on that root page to other pages on the site. Note that in our Figure 1 example, the site has specifically excluded certain pages via the "robots.txt" protocol. Polite robots like the Big Three respect such requests, even though those pages are visible on the web to regular users. Other pages have access restrictions (shown in red) that prevent any unauthorized access. An example of this is the ".htaccess" file, which requires a UID-Password combination to view those resources. Some pages such as a credit card charge page might only be generated on-the-fly, that is, through user-interaction with the website. Typically, crawlers do not activate such links and therefore do not discover those pages. Web crawlers also generally start their crawls at the site's web root, in part because this is where a site's main links can usually be found. The accessible pages of a site are found by the crawler as it extracts the links from each page that it visits, adding these to the list of pages for the site and visiting each of those in turn. Once all unique links for a site have been collected and visited, the crawler is done. Of course, pages can exist without having a link to them on the site. In that case, a crawler will not be able to find out about that page unless the page is listed at some other site, or if it is included in a sitemap submitted to the search engine. Occasionally, links are "bad" – they point to a page that either no longer exists or that has been renamed. Users may "guess" at what the new location is, or they might use the website's search feature to find it. For a crawler, a bad link leads nowhere. The basic rule holds: crawlers can only visit pages that they know about and that actually exist. Many websites use the root page as an entry point to other sections of their own webs. D-Lib Magazine's root page contains links to Back Issues, to the D-Lib Forum, and to many other areas of the website in addition to links to the current month's articles. Search engine crawlers may initially visit just the root page to collect the list of main links and then pass each of these main links to a series of crawlers. The overall demand on the web server made by lots of simultaneous robot requests can impact its performance, but most search engine crawlers have worked out a reasonable compromise between efficient crawling and server responsiveness.
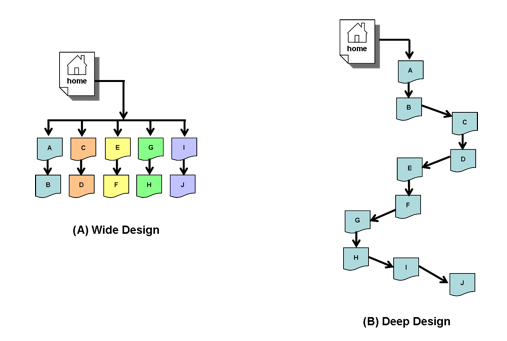
Designing the ExperimentOne of our goals was to test crawler willingness to explore the width and depth of a site. What do these terms mean? We can illustrate it using sample links for Figure 2. Assuming that "home" (web root) is "http://www.foo.edu/index.html" then the wide site (Figure 2-A) could have a series of links like this:
In just two "slashes" we reach the f.html web page. By comparison, a deep website like that in Figure 2-B will require several slashes (shown below in red) to reach f.html:
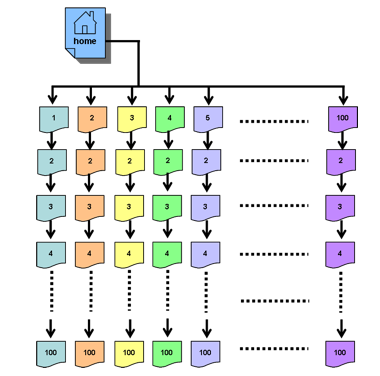
Essentially, slashes represent nested directories on the file system. Conventional wisdom holds that a crawler-friendly website is wide rather than deep. If our website has 10 documents, then a wide design like that in Figure 2-A is more crawler-friendly than the deep design of Figure 2-B. Web servers may also exhibit a prejudice toward wide rather than deep sites. For example, Apache's default configuration limits a request string to 256 characters. Deep pages, which have long request strings, may push this limit. Note that example (4) above would be a much longer request string if the single-letter path elements were more like those found at real sites, where each of the names would be several characters long. If wide is better than deep, can a site be too wide? And how deep is too deep? Do crawlers harvest a site that has a high-level resource list differently from a site that forces the crawler to explore each page in turn in order to find all resources? To answer these questions, we designed a series of 4 sites that were both very wide and very deep. Each site had 100 links on the site's main index page, each of which pointed to a separate subdirectory index page. In addition, each of those subdirectories had 100 levels of additional subdirectories below. The scheme is depicted in Figure 3. The total number of URIs on each site exceeded 20,000: 100 groups of 100 directories, each containing 2 pages (100 x 100 x 2 = 20,000), plus index pages for the various directories, and a collection of images. We hoped to challenge Google, Yahoo, and MSN with this site design, expecting the crawlers to "give up" after a certain width and depth. Part of the goal was to see if these crawlers exhibited a crawl limit at any or all four of the sites.
The four sites are still available for perusal, two in the dot-com domain and two in dot-edu:
Each site has unique content, consisting of non-copyrighted, English-language classic literature texts. We intentionally inserted unique content so that the sites would not be seen as "mirror" sites, i.e., sites that replicate each other. The HTML structure was similar across the sites but with the proliferation of pre-designed website templates, we felt that design duplication would not be a factor in crawler penetration. Search engines harvest the content rather than the design. Each site has about 15 MB of text content, and a few hundred KB of images. There is no hidden content, and since the text was extracted from classic literature, it "makes sense" grammatically. Breaks in the content were based on breaks in the original works – paragraphs, sentences, or poetic verses. In sum, the sites have the overall look and feel of "real" websites, attested to by the occasional visitor who arrived via a Google search. A final characteristic is the internal linking strategy, designed to evaluate a crawler's approach to ready-access of resources versus continually nested links. The two approaches can be thought of as the "Bread Crumb" style and the "Buffet" style. All sites have a list of each of the first-level groups on the main index page (as shown in Figure 4) that indicate the "width" of the site. Below this level, two different strategies were employed.
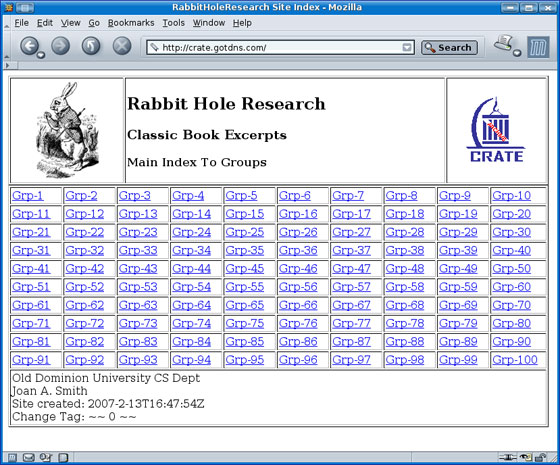
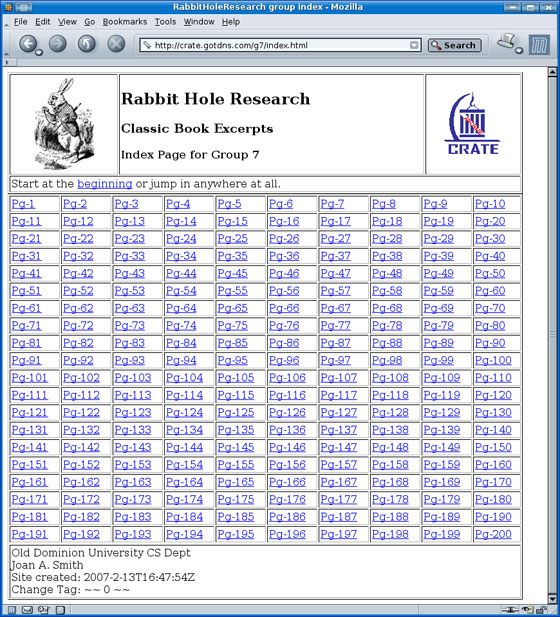
In the "Buffet" style, an index page was created for each of the 100 top-level directories. This index page contains a link to each of the 100 directories below it. In turn, each of the 100 subdirectories has a link to each of the pages below it. This gives crawlers a shortcut method to reach each page on the site, like a buffet restaurant where all desserts are on table 1, all salads on table 2, etc. An example from a Buffet-style site (crate.gotdns.com) can be seen in Figure 5.
In the other strategy, "Bread Crumb" style linking, only a single link is given on the subdirectory index page, which points to the start of a text section (see Figure 6). That first text section has links to the next text section page down, and to the previous section page. This minimal linking continues throughout that "column" of the site, acting like a bread-crumb trail for the crawler to follow to the end. "Bread Crumb" style, in other words, is like Figure 2-B and "Buffet Style" is like Figure 2-A.
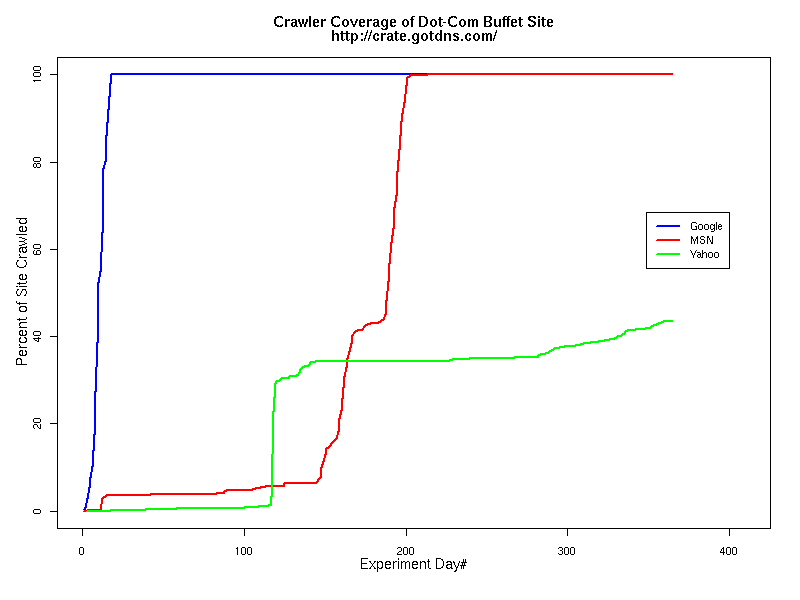
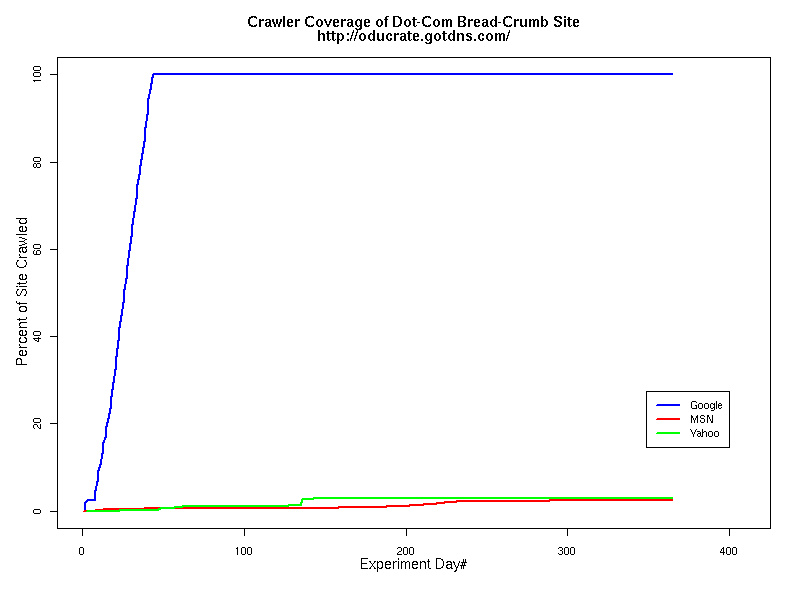
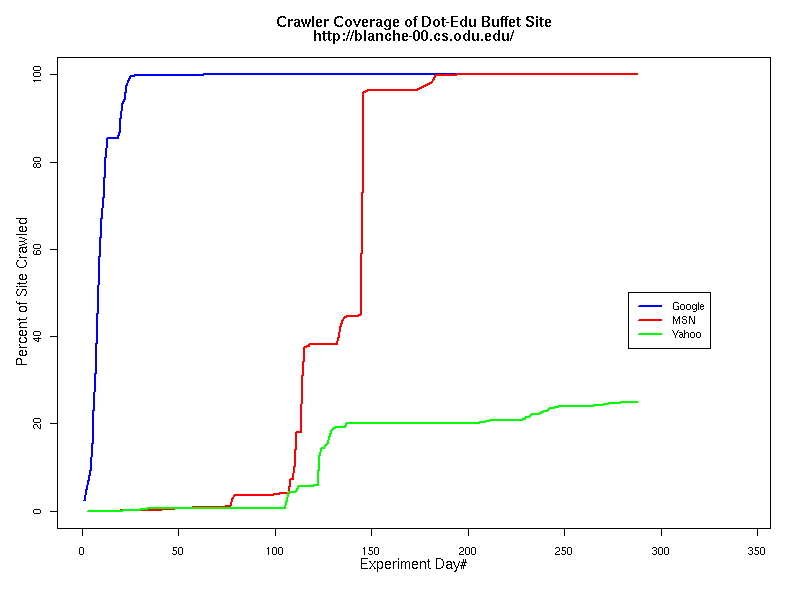
These two strategies represent the configuration extremes of common digital library (DL) designs. Some sites provide a "site index" page at a very high level of the site, where drilling down for information is minimized by direct links to deeper sections of the site. Other DL sites have sections with sub-index and sub-sub-index pages at progressively deeper levels. Although our deep site drew the crawlers down 100 levels, the sites had a finite bottom and were therefore not "spider traps," i.e., sites with infinitely deep linking. The sites were installed simultaneously in early February 2007. We advertised the existence of the new sites by posting links to them on several existing, well-crawled sites, including the authors' home pages (http://www.cs.odu.edu/~mln and http://www.joanasmith.com/). The content was completely static; no pages were added or changed during the entire experiment. However, in late August we had to change the hosting company of the two dot-com sites. Despite coordinating the content transfer and changes to DNS, a glitch in the configuration file at the new site caused oducrate.gotdns.com to be inaccessible for two days. Crawlers did not seem to be affected by the outage; the temporary disappearance of the site did not change the rate of resource request from the search engines. Similar events happened at the dot-edu sites, where power outages caused occasional down time. For the dot-com sites we were able to analyze a full year's worth of logs (February 2007 – February 2008), and for the dot-edu sites we have over nine months' worth of log data (February 2007 – mid-December 2007). Crawler Behavior at the Dot-Com SitesWhen a crawler requests a page, it has the option of including a datestamp in the request. This is referred to as a "conditional get," and it means the server will only send the page to the crawler if the page is "newer" than the datestamp. Otherwise, the server responds with status code "304," indicating no changes. The reason is simple: downloading pages uses computational resources (time, disk space, bandwidth), affecting both crawler and website. If the page is the same as the one on file (i.e., "cached") at the search engine, there is no need to spend the extra resources re-acquiring the page. In addition, crawlers can record the 'change history' of a site, using the data to schedule the frequency and timing of return visits. Conditional request patterns for Google differed somewhat between the Buffet and Bread Crumb sites, as shown in Table 1. Even though both sites are identical in structure, the Buffet site received more than five times the number of Google visits tracked on the Bread Crumb site. In addition, the proportion of conditional requests for pages was more than three times as great, which means that less time was spent fulfilling the requests, because page content never changed on the site. Another significant figure is the time to complete a full site crawl. Google explored the Buffet site in just over two weeks, whereas the Bread Crumb site took six weeks to complete a full site crawl. In contrast, the MSN crawler took over 200 days to reach 100% coverage of the Buffet site and reached less than 3% of the Bread Crumb site. The worst performer, Yahoo, only explored 43% of the Buffet site and 3% of the Bread Crumb site. Even after a full year's availability, neither Yahoo nor MSN has crawled the Bread Crumb site completely. As Table 2 shows, these crawlers barely explored beyond the first few levels of the Bread Crumb site.
Table 1 Crawl Statistics for the Dot-Com Sites
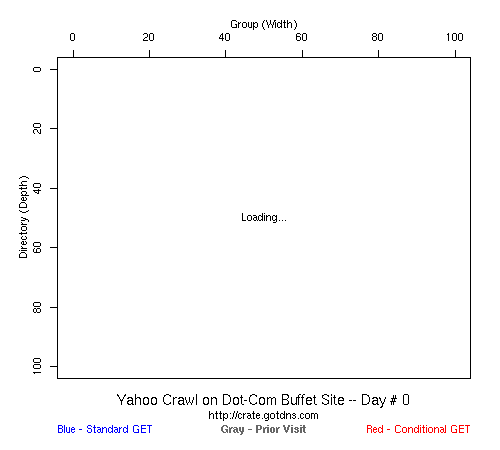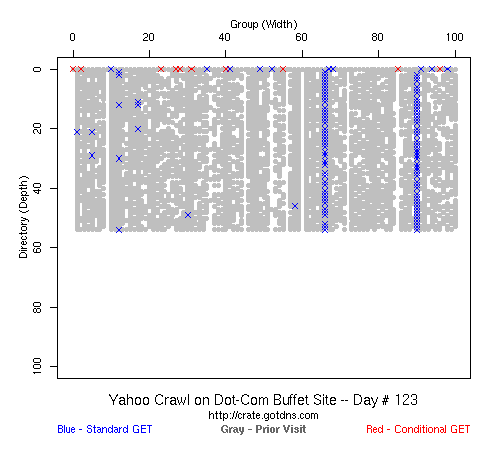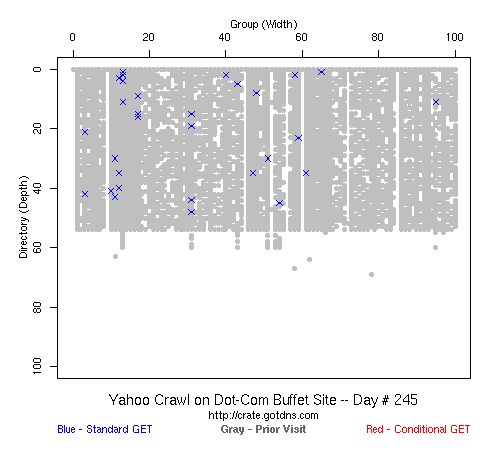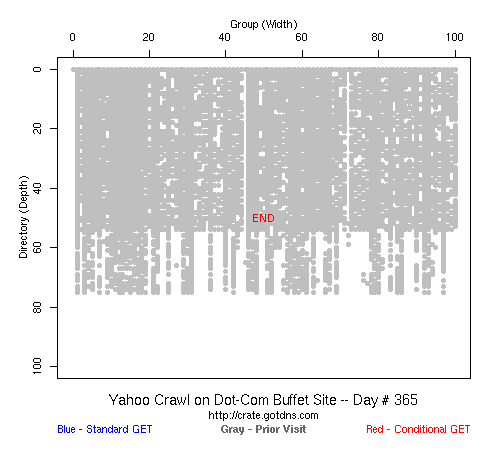
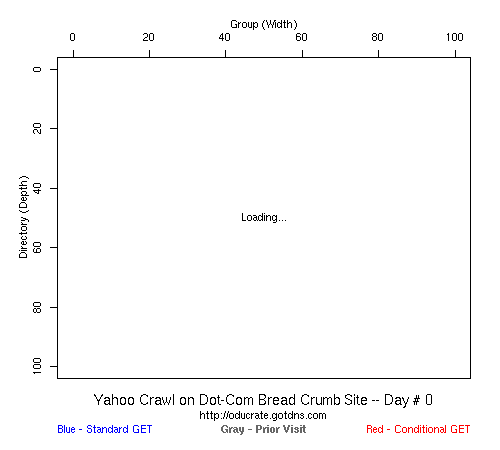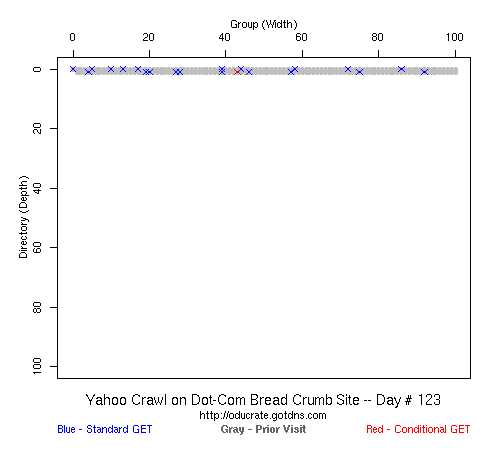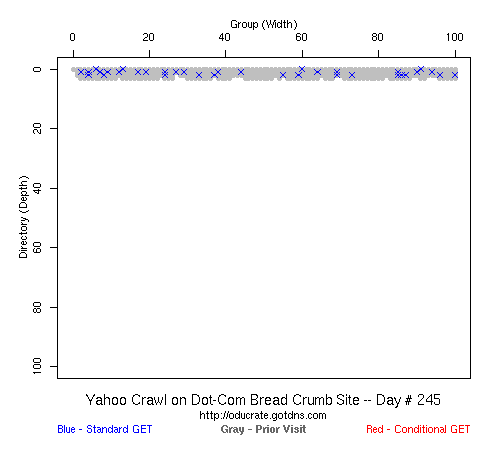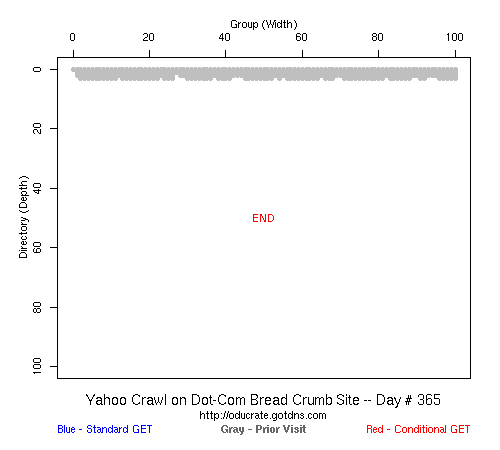
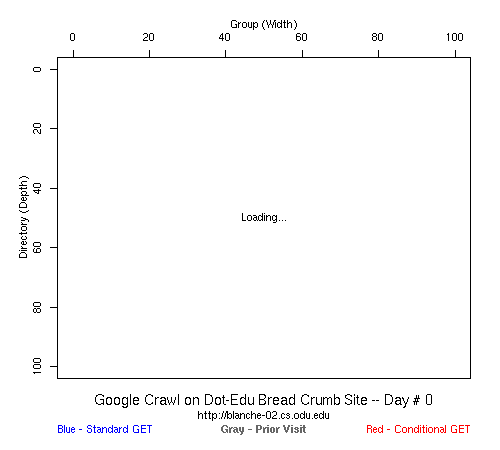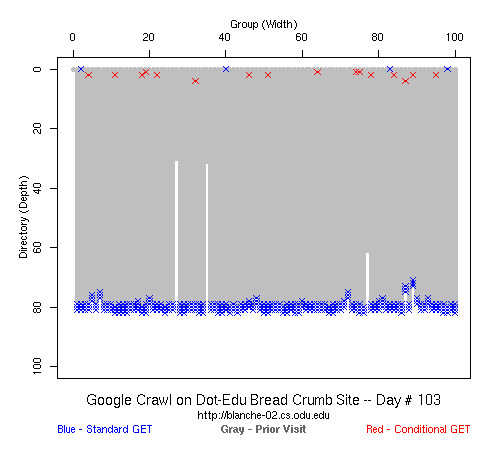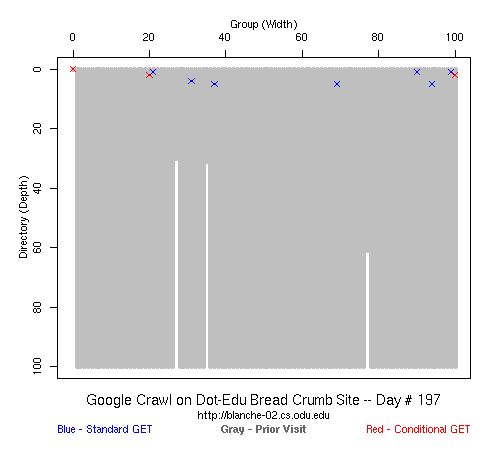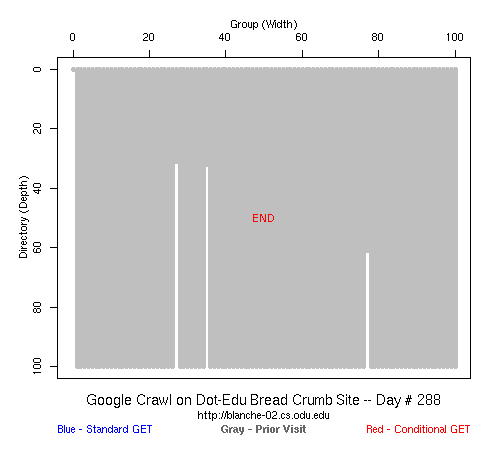
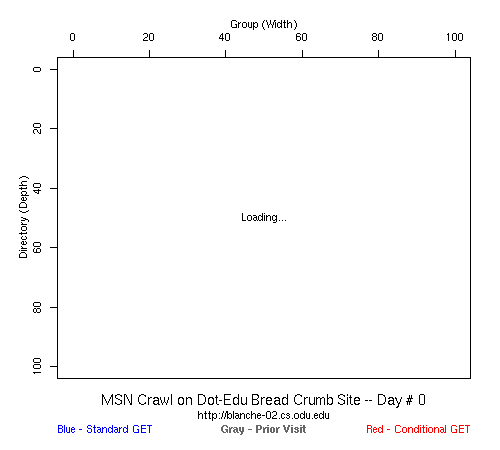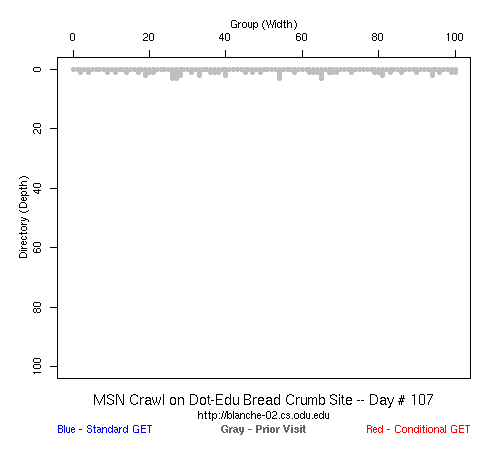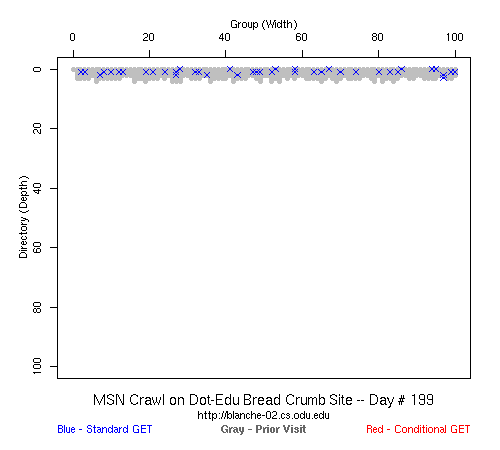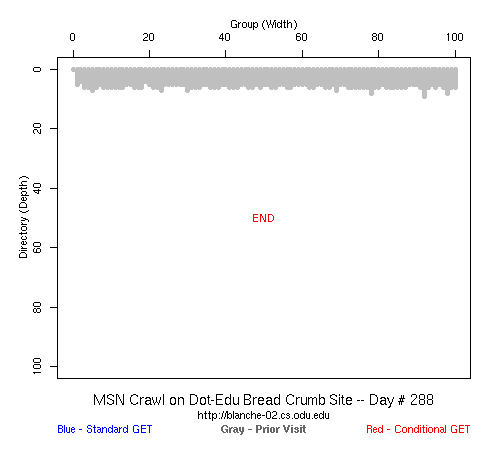
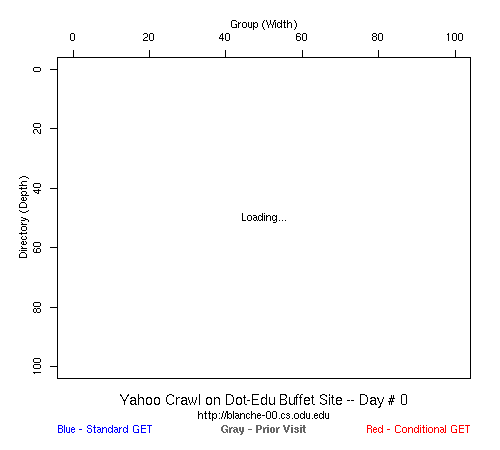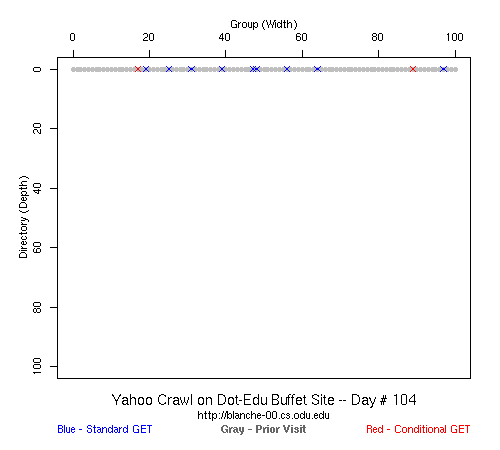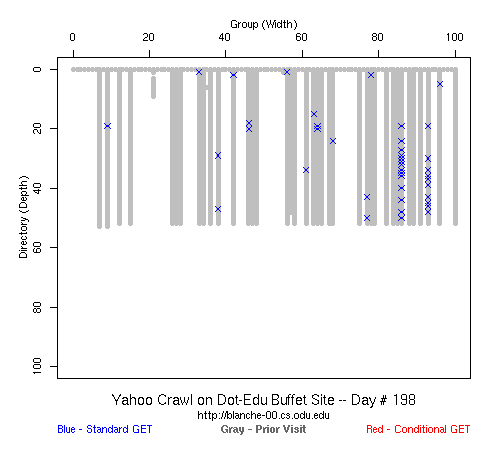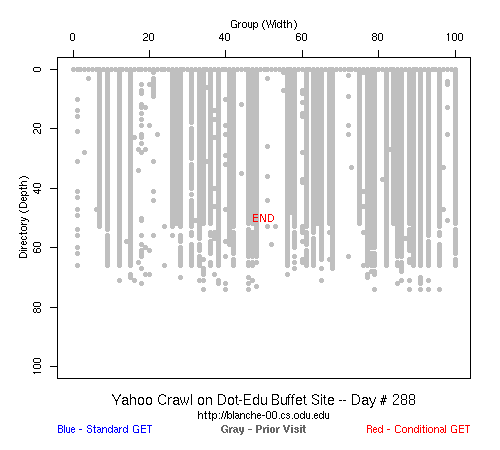
Table 2 Crawler Coverage of the Dot-Com Domain Sites The crawling patterns are visually interesting, particularly the "Bread Crumb" site crawls where the GoogleBots proceed almost like a cadre of soldiers down through the site. Animations of the crawls can be seen by clicking on the images in Table 3. We've colored the conditional page requests red and the standard requests blue. Once a page is crawled, the page coordinate point becomes gray. Eventually, most or all of the background is gray. The crawlers continue to keep an eye on the sites, which can be seen as new requests plotted in color (red, blue) over the gray, fully crawled resources. Yahoo exhibited some unexpected behaviors, such as skipping whole directories. These are visible as "stripes" of white columns in the image. The Yahoo crawlers also made some scattered requests deeper in the site without fully exploring that particular level in width. MSN followed certain directories from top to bottom, while approaching others across the width. All three of the crawlers utilized multiple robots, typically 3-4 per day, but occasionally more than a dozen different robots (detected by distinct IP addresses) would crawl simultaneously or within minutes of each other.
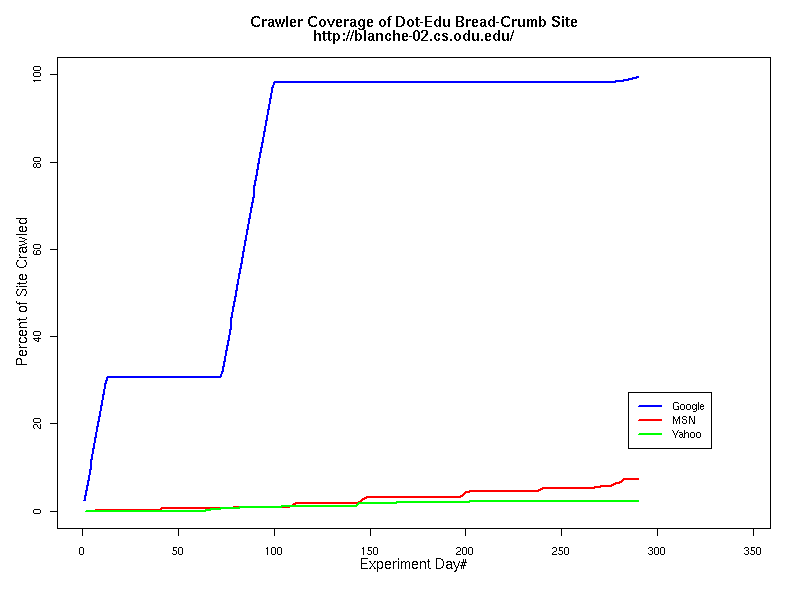
Table 3 Links to Animations of Crawler Activity at the Dot-Com Sites Crawler Behavior at the Dot-Edu SitesIn general, the crawlers approached the dot-edu sites in the same way as they did the dot-com sites. However, as both Table 4 and Table 5 illustrate, the overall coverage rate was lower for the dot-edu domain, and the timetable was longer. Even though Google did fully crawl the dot-edu Buffet site, it took 105 days to complete that crawl compared with only 16 days to complete the dot-com Buffet site crawl. We were surprised to note that Google had still not completed a full crawl of the dot-edu Bread Crumb site by the end of the experiment. However, during the last few days of the experiment Google's crawlers had started to crawl the previously ignored pages. Is there an internal book-keeping script that notes which parts of a site have not been explored? Did a Googlebot server break down, missing its scheduled crawl through those pages? While we cannot answer those questions, we can state that Google is more likely to finish a complete crawl of the site than MSN or Yahoo. Links to animations of the crawls are found in Table 6.
Table 4 Crawler Coverage of the Dot-Edu Domain Sites
Table 5 Crawl Statistics for the Dot-Edu Sites
Table 6 Links to Animations of Crawler Activity at the Dot-Edu Sites Implications for Digital LibrariesThe patterns seen in the crawls by Google, Yahoo, and MSN imply certain strategies for digital libraries that seek to have maximum exposure of their content on the major search engines. Three factors emerged from our experiment that may help the DL manager achieve a strategic advantage: time, site design, and the link disclosure mechanism. (1) Time In previous web crawler experiments6 we found little penetration by MSN and Yahoo. It is possible that those experiments actually ended too early (three months or less), and that we would have had more site penetration if they had run longer. While Google is quick to respond and as thorough as its reputation implies, other crawlers took more time to explore the sites. By leaving resources at stable locations on a site, other search engines have a greater opportunity to harvest the information and make it available to their users. Eventually, Google, Yahoo and MSN explored the top two levels of all of the sites. However, full exploration appears to depend more on other factors than just time. All of the sites have been fully accessible for a full year, and the links have been persistent for the entire time, but large portions of the Bread Crumb sites still remain unexplored by some of the crawlers. Of course, other factors that we did not measure may play a role – PageRank, page content, number of requests for such content by search engine users, etc. – but these would reasonably apply to both the Bread Crumb and the Buffet sites. Time may help by 'convincing' crawlers that the site is going to stick around, but it is not sufficient by itself. (2) Site Design Robot behavior cannot be controlled by site design, but we have seen here that it appears to influence the speed, width, and depth of crawls. The path distance did not seem to affect a crawler's "willingness" to request a page, except for Yahoo, which limited the depth of its crawls to level 45 for the first 7 months, and subsequently to level 75. The "widest" link at all of the sites is buried 101 directories below site root, and is over 400 characters in length (see Table 7), but even links at level 45 are over 200 characters long. The depth limitation may have more to do with Yahoo's general crawling strategy rather than path distance. This hypothesis is supported by its later, sudden dive to level 75. Still, the implication for the DL manager is that the site will be more thoroughly crawled if it is wide rather than deep. Table 7 The Longest Link (3) Link Disclosure Mechanism The number of hops required to access deeper pages appears to play an important role. The Buffet style site had a very high index-page request rate. It was also crawled more quickly and more thoroughly than the Bread Crumb site. If a single page such as a "Site Index" is linked at a top level of the site, the crawling process is much easier for the search engine. In part this is because post-crawl processing to extract links is reduced to 200 links on one page rather than one link on each of 200 pages. Sites that support the sitemap protocol facilitate crawling by providing an XML document outlining the site's resources. The document also supplies crawler-critical information like the expected change frequency of resource content, and it may expose sections of the site that are otherwise deeply buried. Google, Yahoo and MSN do not promise full crawls of sitemap-enabled sites, but they support it and recommend its use. Another alternative to a Site Index is using an OAI-PMH-compliant web server (modoai7, for example) and submitting the baseURL to the search engines. In that case, a simple "ListIdentifiers" query at the site provides the crawler with a complete inventory of accessible resources. ConclusionsDigital library sites that want to maximize their exposure to search engine users should look to improve the crawler-friendliness of their site. Even those who have their own established customer base may want to examine ways to increase crawler penetration, since search engines cache much of their content (providing a type of "lazy preservation" for the site8), and new users may arrive from exploring search engine results. Finding all of a site's resources requires considerable processing effort, and strategies that simplify resource location can help users and administrators as well as crawlers. Finally, DL researchers may wish to consider the duration of experiments involving crawlers, and plan to allow such experimental sites to persist several months or longer. Further InvestigationsWe are intrigued by MSN and Yahoo's lengthy delay in exploring our sites. Yahoo waited over three months before exploring more than the root index level. MSN took nearly as long (82 days). Is this a deliberate strategy on the part of these search engines, perhaps some kind of quarantine period? Websites come and go quickly, so ignoring very new sites could save a search engine the cost of exploring what amounts to an evanescent site. While Google did thoroughly probe the two dot-com sites quickly, its crawlers took significantly longer to explore the dot-edu sites. Again, perhaps this is a deliberate strategy where Google is focused on the potential to maximize ad revenues from dot-coms, something that is not usually an option in the dot-edu domain. Would the sitemaps protocol support have made a difference? Such experiments are, by their very nature, not repeatable in the way that clinical drug trials are repeatable. Search engines are continually competing to improve their scope, and crawling strategies are likely to continue to evolve. Since our first experiment6, MSN has stopped outsourcing its crawls to Inktomi, and now uses its own robots. Still, we are preparing another site to see if the MSN and Yahoo delayed-crawl behavior is repeated. Another factor that may play a role in robot preferences is the sitemaps protocol adopted by Google, Yahoo, and MSN. Sites that implement this approach essentially create a "Buffet" style index designed specifically for crawlers. In summary, site design does matter to the crawler and webmasters should consider implementing a crawler-friendly site design that includes index pages and/or a sitemap. Notes1. Onn Brandman, Junghoo Cho, Hector Garcia-Molina, and Narayanan Shivakumar. Crawler-friendly web servers. SIGMETRICS Perform. Eval. Rev., 28(2):9-14, 2000. <doi:10.1145/362883.362894>. 2. Chris Sherman. Getting The New York Times More Search Engine Friendly. Search Engine Watch. 15 June 2006. <http://searchenginewatch.com/showPage.html?page=3613561>. 3. Frank McCown, Xiaoming Liu, Michael L. Nelson, and Mohammed Zubair. Search engine coverage of the OAI-PMH corpus. IEEE Internet Computing, 10(2), March/April 2006, pages 66-73. <http://doi.ieeecomputersociety.org/10.1109/MIC.2006.41>. 4. Edward T. O'Neill, Brian F. Lavoie, and Rick Bennett. Trends in the evolution of the public web: 1998-2002. D-Lib Magazine, 9(4), April 2003. <doi:10.1045/april2003-lavoie>. 5. Google. Webmaster Guidelines. (Visited on 15 Feb 2008) <http://www.google.com/support/webmasters/bin/answer.py?answer=35769>. 6. Joan A. Smith, Frank McCown, and Michael L. Nelson. Observed Web Robot Behavior on Decaying Web Subsites. D-Lib Magazine, 12(2), February 2006. <doi:10.1045/february2006-smith>. 7. Michael L. Nelson, Joan A. Smith, and Ignacio Garcia del Campo. Efficient, Automatic Web Resource Harvesting. In Proceedings of the 8th Annual ACM International Workshop on Web Information and Data Management (WIDM'06), November 2006, pages 43-50. <http://doi.acm.org/10.1145/1183550.1183560>. 8. Frank McCown, Joan A. Smith and Michael L. Nelson. Reconstructing Websites for the Lazy Webmaster. In Proceedings of the Eighth ACM International Workshop on Web Information and Data Management (WIDM'06), November 2006, pages 67-74. <http://doi.acm.org/10.1145/1183550.1183564>. Copyright © 2008 Joan A. Smith and Michael L. Nelson |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/march2008-smith
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||