
D-Lib Magazine
June 1998
ISSN 1082-9873
A Distributed Architecture for Resource Discovery Using Metadata
Michael Roszkowski and Christopher Lukas
Internet Scout Project, Computer Sciences Department
University of Wisconsin-Madison
[email protected]
[email protected]

Abstract
This article describes an approach for linking geographically distributed collections of metadata so that they are searchable as a single collection. We describe the infrastructure, which uses standard Internet protocols such as the Lightweight Directory Access Protocol (LDAP) and the Common Indexing Protocol (CIP), to distribute queries, return results, and exchange index information. We discuss the advantages of using linked collections of authoritative metadata as an alternative to using a keyword indexing search-engine for resource discovery. We examine other architectures that use metadata for resource discovery, such as Dienst/NCSTRL, the AHDS HTTP/Z39.50 Gateway, and the ROADS initiative. Finally, we discuss research issues and future directions of the project.
Overview
The Internet Scout Project [SCOUT], which is funded by the National Science Foundation and is located in the Computer Sciences Department at the University of Wisconsin-Madison, is charged with assisting the higher education community in resource discovery on the Internet. To that end, the Scout Report and subsequent subject-specific Scout Reports were developed to guide the U.S. higher education community to research-quality resources. The Scout Report Signpost [SIGNPOST] utilizes the content from the Scout Reports as the basis of a metadata collection. Signpost consists of more than 2000 cataloged Internet sites using established standards such as Library of Congress subject headings and abbreviated call letters, and emerging standards such as the Dublin Core (DC) [DC]. This searchable and browseable collection is free and freely accessible, as are all of the Internet Scout Project's services.
As well developed as both the Scout Reports and Signpost are, they cannot capture the wealth of high-quality content that is available on the Internet. An obvious next step toward increasing the usefulness of our own collection and its value to our customer base is to partner with other high-quality content providers who have developed similar collections and to develop a single, virtual collection. Project Isaac (working title) is the Internet Scout Project's latest resource discovery effort. Project Isaac involves the development of a research testbed that allows experimentation with protocols and algorithms for creating, maintaining, indexing and searching distributed collections of metadata.
Project Isaac's infrastructure uses standard Internet protocols, such as the Lightweight Directory Access Protocol (LDAP) [LDAP] and the Common Indexing Protocol (CIP) [CIP] to distribute queries, return results, and exchange index or centroid information. The overall goal is to support a single-search interface to geographically distributed and independently maintained metadata collections.
Search Engines and Resource Discovery
Search engines that use robots to gather and index the contents of Web pages have been immensely useful tools for resource discovery. However, the problems with using them for this purpose generally fall into two categories:
- Difficulty in formulating queries that are discriminatory enough to return a "reasonable" number of hits. Queries that contain common terms often return tens or hundreds of thousands of results. In information retrieval terms, search engines that rely on indexes offer poor precision -- searches return a high percentage of non-relevant documents along with the relevant ones. Users must filter the relevant resources from the non-relevant, often resulting in relevant resources being missed. A related problem is that the user is given limited discriminatory information beyond the URL of a search result. The user must explore each result to determine the applicability of the result to the query.
- Lack of "quality control" of results. Many search engines try to "index the Web" without regard to the quality of the resources in the index. Therefore, even if a user enters a very specific query that returns relevant sites, some or all of the sites may be of little value because they lack authority, valid information on the subject, or currency.
To circumvent these problems, many people and organizations create handcrafted collections of Internet resources. People develop "value added summaries" of Web sites and data sets of interest. The value of these collections stems from their selectivity, documentation, and the authority of the resources included in them. Like our own Signpost, some of these collections of "third-party metadata records" classify the Internet resources using organizational methods such as Library of Congress classifications, UDC codes, or homegrown schemes. The collections often include rating systems and summaries of the content. They also usually include subject or keyword information, as well as title and authority information. This makes it possible to search the metadata with more precision than is possible when searching keyword indexes such as HotBot, Alta Vista, or InfoSeek.
Our approach -- linking relatively small, authoritative collections -- addresses both the issues of selective content and quality control. First, by searching human-applied metadata rather than machine-extracted keywords, a user should be able to formulate a more precise query that will retrieve a highly relevant result set. A user can specify that query terms appear in the title or subject fields, for example. This is analogous to searching a library's Online Public Access Catalog (OPAC). You can find all items for which a person is the author rather than all items that mention the person's name anywhere within the text. Much of the power of this approach depends on the fact that the items have been cataloged. It is easy to find resources that contain the phrase "Jimmy Carter" using a search engine that indexes keywords and/or strings such as Excite or InfoSeek. But it is not as easy to find only articles written by Jimmy Carter, i.e., Jimmy Carter as author. When searching metadata, you depend on the fact that catalogers or others skilled in description issues have used the phrase "Jimmy Carter" in an author field or subject heading.
The approach, however, sacrifices breadth for quality of resources. For example, if you search for "Michael Roszkowski" in the Library of Congress OPAC you will get only a single hit. However, the same search in Alta Vista yields more than 50 hits. On the other hand, collections catalog resources, while search engines index pages [KIRRIEMUIR98], thus a single annotated resource in Signpost, SOSIG [SOSIG], or OMNI [OMNI] may describe a resource consisting of tens or hundreds of pages that might be returned as individual hits by a search engine that indexes each Web page as a distinct entity.
This combination of quality of resources and the ability to search with higher precision results in a highly useful service for our primary audience, the research and higher education community.
Project Isaac
Isaac uses the LDAP and CIP protocols to link geographically distributed metadata collections into a single, virtual metadata collection. We are primarily interested in human-mediated, highly authoritative collections of cataloged and classified Internet resources. To the user, Isaac will appear as a single metadata collection populated with Internet resources. A user's query can run against multiple collections and return a single "hit list" or result set. The user can then view the metadata records and/or can access to the actual resources.
As our primary goal is to serve the research and higher education community, we have made some assumptions that limit the scope of the project and simplify implementation. Some of these assumptions include:
- Isaac is a closed system. We are very interested in locating partners and working with them to make their collections available through Isaac. This is a collaborative project, but collections must be added to the system by agreement; a provider of a collection can not unilaterally add their collection to Isaac. This is an important factor in keeping the overall quality of the metadata high.
- As a result of the first assumption, Isaac does not aim to be a generalized search service that spans the Internet. Rather, it is a targeted service that will provide access to specialized collections of Internet resources of primary interest to the research and higher education community.
We hope to accomplish the following with Isaac:
- Provide a useful resource discovery service that utilizes metadata.
- Allow collaborators to develop, maintain, and manage their collections. Isaac provides a method to link the collections and will not subsume any of the individual collections.
- Experiment with metadata standards, such as the Dublin Core, to provide a common set of attributes with which to catalog and subsequently search collections of Internet resources.
- Develop a collaborative laboratory in which we can research topics of interest, such as indexing algorithms, automatic classification and categorization, alternative user interfaces, etc.
For our infrastructure, we chose to develop an architecture that was fairly simple, but it had to be open and flexible enough to allow us the ability to replace parts of the architecture for experimentation and research.
Isaac Architecture
Isaac consists of three services, a metadata repository service, an index service, and a search service. Isaac relies on standard Internet protocols for all of its operations. The search interface is Web-based and uses HTTP and HTML. The metadata servers use LDAP for query processing and the storage and retrieval of index information and CIP v3 to generate and transport indexes between servers.
There are two types of Isaac installations: a full node that supports all of the services (metadata repository, index and search) and a collection node that supports only the metadata repository service. A full node requires more resources, since it stores index information from all other Isaac nodes as well as its own collection data. In addition, a full node provides the search service for users and must be running a Web server to support that service.
Collection nodes provide a simple way for partner organizations to allow their data to be searched as part of Isaac without having to devote machine resources to storing indexes and servicing users' Web queries.
The metadata repository service uses a stand-alone LDAP server to store the metadata for a collection. The service supports LDAP queries against its metadata collection. The metadata repository service can also generate indexes of the metadata and transfer the index using the CIP protocol.
The index service gathers index information from other Isaac nodes and stores the index information in the LDAP database.
The search service handles the user interface. It allows users to submit queries and returns results to the user's Web browser.
Implementation Details
We are currently using University of Michigan's LDAP distribution [UMLDAP] as the basis for our LDAP implementation. However, the Michigan code implements LDAP version 2, so we have made local modifications to add support for LDAP v3 referrals. The Michigan code runs under many flavors of the UNIX operating system and is freely redistributable.
For indexing we have implemented the CIP v3 over a TCP/IP transport in the Perl language. We currently support the tagged index object [CIP-TAGGED] format for indexes.
We chose to use the 15 Dublin Core (DC) [DC] metadata elements as the base metadata description format for Isaac for a number of reasons. Signpost, our metadata collection, is based on the DC elements, with minor local additions and modifications. Also, DC is a simple format that is seeing increased use in multiple communities, and the limited number of fields makes it suitable for fielded searches.
The LDAP attributes [HAMILTON96] that we are using for Isaac are based on object definitions published as an Internet draft in November 1996 for expressing Dublin Core fields in LDAP and X.500.
To participate in Isaac, metadata collections need not use DC, but must have "like" fields that can be reasonably mapped to the Dublin Core elements. Isaac does allow extensions to the base DC element set to provide for richer metadata descriptions of resources.
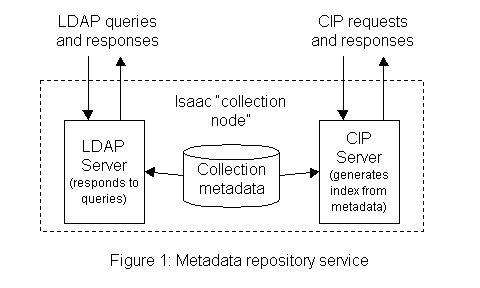
The Metadata Repository Service
The metadata repository service allows a collection to become part of the Isaac testbed. This service consists of a stand-alone LDAP server (SLAPD) that stores the metadata and processes queries from the search service.
The metadata repository service also can extract index information from the collection and transfer the index using the CIP protocol.
The Index Service
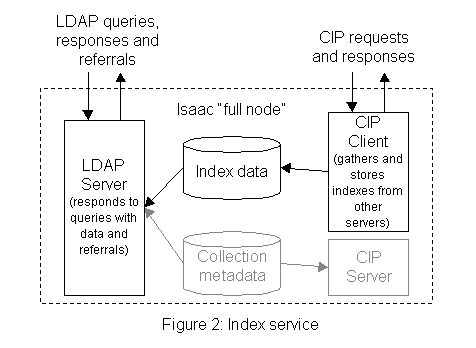
We felt that query routing, that is, using index information to "route" a query only to servers that are likely to have relevant information, provided many advantages over a "broadcast search" scheme. A recent D-Lib Magazine article[KIRRIEMUIR98] contained a good discussion of the benefits and methods of query routing. While LDAP does not incorporate the use of indexes as knowledge references directly into the protocol, neither does it preclude their use.
Isaac's index service allows "full nodes" to request index information from other Isaac nodes. The index service is built on CIP v3 clients and servers and implements the tagged index object for indexes. The tagged index object consists of a "centroid" for each indexed LDAP attribute. Index information is stored in the LDAP directory and used for generating referrals in response to LDAP queries.
Isaac's "full nodes" maintain index information from all other Isaac nodes.
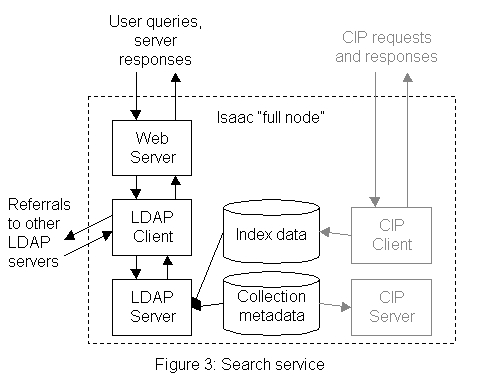
The Search Service
The search service is Web-based. Using a browser, the user fills out a form with query information and a CGI script handles the form. The CGI script uses an LDAP client to submit the query to the local LDAP server on a "full node," and the LDAP client processes any referrals (based on the index information) before results are returned to the user.
It is possible to query Isaac using any LDAP compatible client. While this allows greater flexibility, in the future we may decide to support enhancements such as result ranking and search services not available in the current architecture, including proximity searching and phrase searching. These enhancements could require the use of LDAP protocol extensions or post-processing of the result set in a customized client.
Gateways to Other Protocols
We have implemented a simple LDAP to WHOIS++ [WHOIS++] gateway as an LDAP "backend" so that we can include collections in the Isaac testbed that are made available using the ROADS software. This gateway converts LDAP queries into WHOIS++ queries and repackages results received from WHOIS++ servers into LDAP format. Currently, this gateway is not generic in that it requires specific knowledge of the WHOIS++ templates (schema) for each target.
Other Resource Discovery Projects: Dienst, AHDS, and ROADS
The application of metadata for resource discovery is not a new idea. In this section, we discuss some notable projects that have goals and/or methods similar to Isaac and have influenced the design of the Isaac system.
Dienst
Dienst is an architecture and protocol for digital library services. It grew from the Computer Science Technical Reports (CS-TR) project, a DARPA-funded project by the Corporation for National Research Initiatives, which was begun in 1992. The most visible collection currently using the Dienst protocol is NCSTRL [NCSTRL], the Networked Computer Science Technical Reference Library.
The Dienst architecture consists of four classes of services, all communicating via the Dienst protocol: a Repository Service stores digital documents, each of which has a unique name and may exist in several different formats; an Index Service searches a collection and returns a list of documents that match the query; a single, centralized Meta Service or Contact Service provides a directory of locations of all other services; and a User Interface service mediates human access to the collection.
The Dienst Index Service is the metadata search service. Dienst metadata uses the tagged, text-based markup format specified in RFC 1807, A Format for Bibliographic Records [BIBFMT], for bibliographic information. Like the Dienst protocol, this metadata format was developed as part of the CS-TR project.
The Dienst Index Service runs on each Dienst server. Queries are sent to all servers (or all servers that the user has selected) and responses are presented to the user. Users can search a Dienst collection by specifying a query with keywords in the title, author and/or abstract fields. Boolean operators can be used to combine terms. Dienst also allows a user to browse a distributed collection by author or date range.
AHDS HTTP/Z39.50 Gateway
The Arts and Humanities Data Service (AHDS) [AHDS], a UK-based service funded by the Joint Information Systems Committee, is developing an HTTP/Z39.50 Gateway [AHDS-GW] to allow users to query multiple collections of human-mediated metadata. The Gateway uses NISO Z39.50, a client/server protocol for information retrieval. It enables a client to search a database provided by a server, retrieve database records identified by a search, scan a term list, and sort a result set. The AHDS Gateway architecture consists of four layers: User services, service description, distributed access, and an administration database.
The user services access layer is responsible for the interface. It provides a Web-based interface to the Gateway. It also provides a contextual map of the information and services available from the Gateway. This layer also handles authentication of users.
The service description layer stores profiles of known databases, including information such as record structure, supported query types and the format in which results are returned. This layer is also responsible for converting the syntax of result-set records to a canonical format.
The distributed access layer provides support for querying multiple remote databases in parallel. It consists of a parallel query manager and multiple instances of a Z39.50 client.
Finally, the administration database manages administrative and configuration data for the Gateway. The database contains profiles that describe the addresses and capabilities of remote databases which can be searched by the Gateway (used by the service description layer) and syntax schema, which describe the record structures that may be returned by remote targets. The syntax schema are also used by the service description layer for its syntax conversion tasks.
ROADS
The ROADS (Resource Organisation And Discovery in Subject-based Services) [ROADS] initiative is a UK-based project that is part of the eLib (Electronic Libraries) Programme. The project, begun in 1995, has developed a software package of Perl modules for developing and maintaining a subject gateway, that is, a Web-accessible database of metadata records relevant to one particular subject area such as medicine or chemistry. The ROADS software (currently Version 2 is in beta test) includes a Web-based cataloging interface to add new resources to a collection, a Web-based search interface, and a number of utilities for indexing the data, verifying URLs, etc.
For distributed resource discovery, ROADS supports cross-searching subject gateways. The cross-searching capability uses the WHOIS++ protocol for queries and referrals to other servers. ROADS supports distributed indexing using the Common Indexing Protocol (CIP). The authors of the ROADS package have developed a test implementation of CIP v3.
ROADS uses Internet Anonymous FTP Archives (IAFA) templates [IAFA] as its metadata format. The templates are extensible, though sites need to be using similar templates for cross searching to be effective. There are currently more than a dozen subject gateways using ROADS. However, while the software supports the cross-searching capability, most of the sites that have implemented the ROADS software are using it to make their collections available in a stand-alone manner.
Design Choices
We chose to develop a new architecture instead of adopting or adapting existing implementations such as ROADS or NCSTRL. We felt that none of the existing systems met all of our research goals, which include:
- The use of query routing using knowledge references and distributed indexing.
- The use of existing protocols to speed development and increase interoperability.
- An extensible data model that is adaptable to evolving metadata standards.
We had decided early on that we wanted to pursue the use of query routing using knowledge references and distributed indexing. Both Dienst and Z39.50 use a broadcast search strategy, whereby a user's query is sent to a pre-selected set of servers (or all servers). Since we wanted the option of experimenting with indexing algorithms in the future, this was a significant drawback to using either of those systems.
Another factor was that we did not want to implement the system from scratch. We hoped to find freely available software that we could use as a starting point for development. There are a limited number of freely available Z39.50 implementations, and most do not support simultaneous connections to multiple servers, which is a requirement for our project.
A general issue with Dienst is that it is a complete digital library system. That is, it is geared toward collections of documents as well as metadata objects relating to those documents. We are concerned with surrogate objects as first class objects. As such, Dienst includes many facilities that we would not need, such as the ability to uniquely name a document and store it in multiple formats (such as Postscript, SGML, TIFF and ASCII).
Our decision to use a directory protocol was made for the following reasons:
- Directories are simply databases that are tuned to respond quickly to queries, possibly at the expense of update performance. In this sense, they are a good fit with our requirements as a metadata collection that is queried frequently relative to the frequency of updates.
- They are vendor-neutral, open protocols (compared to using a distributed database system which requires that all sites use software from the database vendor).
- They offer inherent support for distributed operation.
- They offer separation of the query protocol from the database backend.
ROADS uses the WHOIS++ directory protocol for search and indexing operations. WHOIS++ shares some of LDAP's capabilities and attributes. Both are fairly simple protocols that support fielded searches with Boolean operators and substring matching. Both let the client specify which attributes should be returned in response to a query.
We chose to use LDAP because its data model is flexible and extensible. It is based on named attribute-value pairs and allows multi-valued attributes (for example, multiple authors in an "author" field). The University of Michigan LDAP distribution also provides a defined "backend" API that makes it possible to use different database systems to hold LDAP data for a server. For example, if we find partners whose collections are stored in a relational database system, we could write or help write an LDAP backend that accepts LDAP queries and converts them to database queries, and converts the results back into LDAP format. In addition, some database vendors may supply such LDAP gateways directly.
Lastly, we chose to use LDAP because of its strong support by commercial vendors. While our code runs only under UNIX, Isaac should be able to make use of any LDAP v3 server. Such servers are now available from several vendors and can run on a variety of operating systems. So, while LDAP is more complex than WHOIS++, we felt that the benefits that it offered were sufficient to warrant its use.
Research Issues
There are a number of open issues that will require further work as we gain experience building a virtual collection.
Metadata Issues
The mapping of complex DC fields will comprise one research issue. For example, our Signpost collection has Library of Congress Subject Headings and Library of Congress Classification codes assigned to resources in the collection. In Isaac, this subject information is made available through the Dublin Core Subject field using the "scheme" qualifier [DC-SCHEME] to indicate the controlled vocabulary or classification scheme. For example, consider a Signpost record with the following subject information:
Library of Congress Subject Headings:
Medicine -- Formulae, receipts, prescriptionsLibrary of Congress Classification codes:
Drugs -- Handbooks, manuals, etc.
Pharmacology -- Handbooks, manuals, etc.RSThe subject information is encoded into the DC Subject field as follows:
RM(scheme=LCC) RSIf other collections use other subject classification schemes, searching may become a problem for the user. What kind of query must a user enter to retrieve resources from the combined, virtual collection? The same resource that Signpost cataloged with the preceding subject information is also listed in OMNI, the UK-based medical information service, as follows:
(scheme=LCC) RM
(scheme=LCSH) Medicine -- Formulae, receipts, prescriptions
(scheme=LCSH) Drugs -- Handbooks, manuals, etc.
(scheme=LCSH) Pharmacology -- Handbooks, manuals, etc.NLM sections:
QV4: PharmacologyMESH-98 headings:United StatesBoth records and services use well known, authoritative files, yet these descriptors are not equal. Cross mapping related descriptors might be one way to resolve this issue.
Pharmaceutical Preparations
Databases, Factual
Browsing
Currently, browsing by subject category is not implemented. Since collections in Isaac may use different subject classification schemes, providing a browsing facility is problematic. To browse resources, users must enter a very general query and browse the results.
The Future
Creating the Isaac infrastructure is only a first step toward developing a useful search service with "third party" metadata collections. In the near term, we plan to develop tools to help collaborators make their metadata available using Isaac. These tools will fall into two categories. One category is data extraction -- tools that take metadata from one source (such as a database) and load the data into an Isaac LDAP repository. The second category will be LDAP front ends to database systems, which avoid the problems of data duplication by providing a "live link" between Isaac's LDAP server and a collaborator's existing metadata store. Development priority will depend on the needs of our collaborators.
In the longer term, we plan to develop tools to aid in the creation of metadata. These tools may include capabilities such as automatically harvesting metadata embedded within Web pages for augmentation by human catalogers. We hope that the automatic harvesting of this metadata might speed the process of developing selective and descriptive catalogs of Internet resources.
Some of the embedded metadata schemes that we would hope to support for automatic harvesting include DC metadata embedded in HTML using META tags, and various metadata formats embedded within the Resource Description Framework (RDF) [RDF], including Dublin Core and Instructional Management System (IMS) [IMS] metadata schemes.
Organizations who are interested in collaborating with us in the project can contact the authors or Susan Calcari, the Internet Scout Project's director, at [email protected]. We welcome the opportunity to explore the possibilities of building a useful service with collaborators. We are willing to share software and ideas and help collaborators incorporate their metadata collections into the testbed.
Acknowledgements
The Internet Scout Project provides information about the Internet to the U.S. research and education community under a grant from the National Science Foundation, number NCR-9712163. The Government has certain rights in this material. Any opinions, findings, and conclusions or recommendations expressed are those of the author(s) and do not necessarily reflect the views of the University of Wisconsin-Madison or the National Science Foundation.
Bibliography
[AHDS] Arts and Humanities Data Service (AHDS), http://www.ahds.ac.uk/
[AHDS-GW] AHDS HTTP/Z39.50 Gateway, http://ahds.ac.uk/public/metadata/disc_06.html
[BIBFMT] RFC1807: A Format for Bibliographic Records, ftp://ftp.isi.edu/in-notes/rfc1807.txt
[CIP] The Architecture of the Common Indexing Protocol (CIP), http://www.ietf.cnri.reston.va.us/internet-drafts/draft-ietf-find-cip-arch-01.txt; CIP Transport Protocols: http://www.ietf.cnri.reston.va.us/internet-drafts/draft-ietf-find-cip-trans-00.txt; MIME Object Definitions for the Common Indexing Protocol (CIP), http://www.ietf.cnri.reston.va.us/internet-drafts/draft-ietf-find-cip-mime-02.txt
[CIP-TAGGED] A Tagged Index Object for use in the Common Indexing Protocol, http://www.ietf.org/internet-drafts/draft-ietf-find-cip-tagged-06.txt
[DC] The Dublin Core Home Page, http://purl.oclc.org/metadata/dublin_core
[DC-SCHEME] Dublin Core Qualifiers/Substructure, http://www.loc.gov/marc/dcqualif.html
[HAMILTON96] Martin Hamilton, et al. Representing the Dublin Core within X.500, LDAP and CLDAP (draft-hamilton-dcxl-00.txt) (expired Internet draft).
[IAFA] Peter Deutsch, et al. Publishing Information on the Internet with Anonymous FTP (expired Internet draft).
[IMS] Educom's IMS Instructional Metadata System Home Page, http://www.imsproject.org
[KIRRIEMUIR98] John Kirriemuir, et al. Cross-Searching Subject Gateways: The Query Routing and Forward Knowledge Approach, http://www.dlib.org/dlib/january98/01kirriemuir.html
[LDAP] RFC 2251: Lightweight Directory Access Protocol (v3), ftp://ftp.isi.edu/in-notes/rfc2251.txt
[NCSTRL] Networked Computer Science Technical Reference Library (NCSTRL) home page, http://www.ncstrl.org/
[OMNI] OMNI: Organising Medical Networked Information, http://www.omni.ac.uk/
[RDF] The Resource Description Framework, http://www.w3.org/RDF/
[ROADS] ROADS: Resource Organisation And Discovery in Subject-based Services, http://www.ilrt.bris.ac.uk/roads/
[SCOUT] Internet Scout Project, http://scout.cs.wisc.edu/scout/
[SIGNPOST] Internet Scout Project Signpost, http://www.signpost.org/
[SOSIG] Social Science Information Gateway (SOSIG), http://www.sosig.ac.uk/
[UMLDAP] University of Michigan Distributed Directory Services Project LDAP Home Page, http://www.umich.edu/~dirsvcs/ldap/
[WHOIS++] Architecture of the Whois++ service, http://www.ietf.org/internet-drafts/draft-ietf-asid-whoispp-02.txt
Copyright © 1998 Michael Roszkowski, Christopher Lukas
Top | Magazine
Search | Author Index | Title Index | Monthly Issues
Previous Story | Next Story
Comments | E-mail the Editorhdl:cnri.dlib/june98-roszkowski