
D-Lib Magazine
July/August 1998
ISSN 1082-9873
Safeguarding Digital Library Contents and Users
Interim Retrospect and Prospects
Henry M. Gladney
IBM Almaden Research Center
San Jose, California 95120-6099
[email protected]

Abstract
The Safeguarding ... series in D-Lib Magazine is intended to suggest technology to help manage digital intellectual property. That technology can contribute only in a complex of administrative, legal, contractual, and social practices is broadly accepted; we now pause to examine how efforts to fit in the technological component are progressing and what next needs attention.
Among concerns for responsive and responsible management of intellectual property, technical aspects are surely secondary to prominent issues of public policy, law, and ethics. The latter are beginning to be addressed both in legislative processes and also by academic investigators. For the technical community, we assert that we can design offerings with sufficient flexibility that we need not wait for policy decisions which might affect software to administer rules chosen or to hinder unacceptable behavior. The current article projects technical directions without designing solutions. It emphasizes managing the data -- how it is stored, protected, and communicated.
For just over a year, the Safeguarding ... articles in D-Lib Magazine have discussed software assistance for protecting digital library (DL) contents. The current article presents a stock-taking, a pause to inspect what has been accomplished so far, to see how it falls short of needs which are rapidly becoming better understood, and to consider what should be done next. Our emphasis will be seen to be that of an industrial research team, extending from basics through software designs to questions of practical deployment, responsible usage, and pleasing customers. We are striving to devise software helpful within whatever policies the governing organizations choose, i.e., to avoid implicit policy-setting through errors in software design.
The technical tools which can help mitigate risks attending digital copies of intellectual property are based on digital computing security tools which have been developed for other purposes over a period of 30 years. This is a large field, with many topics and arcana. For practical reasons, digital library service must mostly ride on elements developed for other applications, limiting its own technical development to certain "middleware" components; this article is limited to the few components we believe we can and must enhance for digital library. Even these few are represented in a large literature to which we can indicate at most entry points. For brevity in this article, we assume that the reader has either looked at prior D-Lib articles to which we refer, or will do so as needed.
Several trends, some well known and some less so, present themselves:
- Many users each want more rapid access to each of many collections. Many collection managers want to satisfy this demand and to extend their offerings to more distant and more varied communities than they currently serve. The numbers of users, objects, and access events are so large that manual administration of contracts, laws, human relationships, and social agreements is becoming unaffordable or even impossible.
- The ease with which digital representations are copied is raising a realistic concern among rights-holders: that their statuatory rights and commercial interests are at risk. The retail value of pirated works -- particularly software, music, and motion picture performances -- is estimated as larger than $10B. In a recent presentation, former U.S. Member of Congress the Honorable Pat Schroeder reminded us that many livelihoods depended on managing intellectual property prudently and that we were putting this at risk by failing to teach our youth that, "Intellectual property is property".
- Parts of the software technology to address these concerns have been evolving for 20 years or longer, and other parts have started to evolve rapidly, stimulated by immense interest in e-business and its most visible component, e-commerce. Even well-understood parts of this technology are not yet effectively applied.
- Progress in at least one tool class, database for recording and managing contract obligations for copyright materials, is stalled because the next stage of development needs production pilots in enterprises willing to take the risks associated with being deployment leaders. We have come about as far as "toy" pilots can take us; for detailed design which realistically responds to enterprise needs, we need test beds of sufficient scale to be important to the executive management of businesses and universities. We will return to this issue below.
- Managing to rules for copyright works has been treated independently of access control, but these domains are now seen to be converging.
The technical means are the easy part of a large set of challenges. The hard part is a complex of policy issues and induced social behavior. An example occurs in the universities, which are beginning to face a revolution over intellectual property as technology blurs the lines between good business and good education; this includes the issue of who owns on-line course materials, the institutions or the faculty members who prepared them; see [Woody 1998]. Another helpful source is a report commissioned by The U.S. Copyright Office: Sketching the Future of Copyright in a Networked World is just now becoming available.
Long lists of detailed requirements are available in many sources; see, for example, what is said about the access control component [Gladney 1997]. Even more recently, we are presented with statements of requirements, from CNI on authentication and access management for cross-organizational use of information resources [Lynch 1998] and from the museum community on user confidence in the authenticity of digital resources [Bearman 1998]. From the many writings illustrated by these and from conversations with members of the IBM development and marketing communities, we select some particular requirements that we feel have not received the attention called for by their compelling nature.
- The means of access management must be scalable to massive numbers of low unit cost interactions, large numbers of users, immense collections, and constantly changing human relationships.
- Each user wants to connect to services only once in a network session, rather than as separate steps for each of many services drawn on.
- Interruptions to provide information needed by access management are a distraction for end users -- a distraction which can be and should be avoided; similarly, service administrators will not be able to deal with individual grants of authorization for each of many thousands of users, and our manifest ability to automate this must be delivered in software tools rooted in databases.
- Different resource custodians want different access rule schemes; we can and should permit all possible rules of access, without exposing the inherent complexity to end users or administrators who are not interested in the "plumbing".
- Libraries differ from piles of books and papers because librarians oversee collection development, selecting only holdings within their institutional missions and of known authenticity and provenance, and organize what they select with catalogs and other means; access management systems must help administer the achievement of such values, which cumulatively make for the quality of the collections.
- Authorization for library services must fit within other administrative processes, such as university student cards for all privileges and as data backup for networked personal computers.
- We demand continuity between delivery from research libraries, scientific databases, and collections of clerical paperwork.
Such requirements are additional to more detailed functional requirements typically emphasized in the literature, and include aspects essential to durable software.
Providing the protections sought has underpinnings which we need to mention, but not further discuss. These include physical security (e.g., network cables should not be exposed to terrorists), operating system security, and other broadly useful measures, as suggested in [IBM 1998]. They further include correct and responsible management control of how the serving computers are administered and independent audit of the same from time to time [Rosen 1970]. Highly respected guides for these topics were published in 1970 and renewed recently.
For stable library service, in addition to having the right functionality, the technology base must have "industrial strength", viz., handle all sorts of failures gracefully, be extensively tested in the environments in which it will be used, have good user and technical documentation, and be accompanied by long-term commitments for functional and platform upgrades and ready service for unanticipated interruptions. This is affordable only with a sufficient customer base and application breadth; for digital library services, the obvious base includes document imaging applications which are gradually broadening to include multimedia content. This application is sometimes called Enterprise Document Management (EDM); IBM's digital library strategy includes reusing as much as possible of EDM offerings for storing, protecting, and delivering digital documents, and as much electronic commerce technology as applies, recognizing that commerce in physical goods might extend into commerce for digital documents, although the latter prospect is developing more slowly than many people anticipated in 1995. (This fits well with the intention of some research libraries to cover part of their running costs by fee services.)
If one accepts this, one must consider DL information protection tools as extensions of more broadly applicable tools. What follows implicitly draws on encryption, key management, and certificate technology for which there exist good textbooks and evaluations, e.g., [NRC 1996]; it explicitly discusses access control which assumes personal authentication, with the latter not being further mentioned.
Any information system has a boundary within which its custodians can enforce organization policies. Figure 1 suggests this boundary for the case of a digital collection which includes its own metadata and access control information. We can conveniently separate measures into those effective within this administrative boundary, those which extend the effective administrative boundary, and those far beyond the boundaries; the last encourage proper behavior and hinder unauthorized actions without being able to prevent them. Within the administrative boundary, it is often possible to constrain what software is used to process digital objects and/or to ensure that employees or other institutional members follow defined rules. In administrative boundary extensions of the type discussed below, it is possible to negotiate terms and conditions of document release. Beyond the administrative boundaries, technical means are less effective, so that we must rely on legal and social measures, and develop these beyond what exists today.
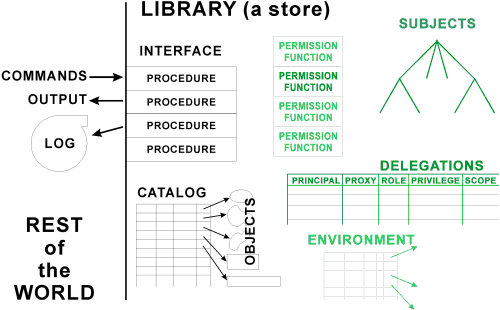
Figure 1. A protected resource and the rest of the world: The black portions describe any library or object store; the green portions are specific to access control.What the Safeguarding Series and Other Sources Already Teach
Each article in our Safeguarding ... series has presented a technology without connecting it carefully to other technologies needed to realize "complete" digital library services. These and other articles have sketched what is to be protected [Gladney 1997a], [Gladney 1997c]; what is available in digital watermarking for protection outside administrative control boundaries [Mintzer 1997]; how users might inspect and edit protection rules [Walker 1998]; how protection rules can durably record the terms and conditions for each property [Alrashid 1998]; transmitting rules from where they are generated to where they are needed; efficient payment mechanisms [Herzberg 1998]; trustworthy identification of who is generating a rule set (authentication), providing a document, or requesting one; unambiguous identification of the things being protected [Gladney 1998a]; how administrative data can be bundled with content for distribution [Lotspiech 1997]; and so on.
We do not agree that "trusted systems" [Stefik 1997] is a promising concept for document protection, at least not in the next few years and perhaps never because there seem to be fundamental flaws (see [Gladney 1998b]).
In the early 1990's, when attention was focused on "open distributed systems" and "object orientation", a popular model articulated what was wanted in building blocks from which loosely coupled services could be marshalled for tasks whose purposes were decided late in design progressions. Curiously, this compelling model no longer figures strongly in discussions, even though it effectively communicates design principles for resources that are sprinkled around the network and invoke each other dynamically. The model centers on the concepts of protected resources and related resource managers; suggested in Figure 2, a protected object is the combination of some data resource (which might be either persistent or ephemeral), and some server and client software which together constitute the resource manager.
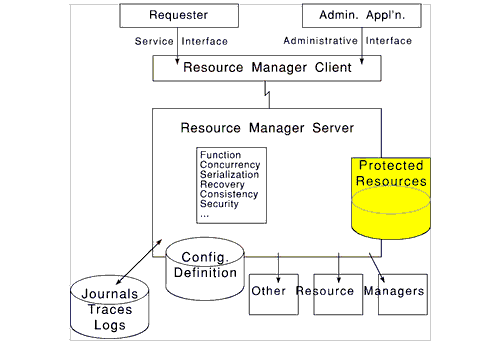
Figure 2. Client/server structure for a protected resource: being one way of providing isolation demanded by Figure 1.
- The only access paths to the data are the API's of the client portion of the resource manager.
- The server component confers all the functionality and quality (concurrency, serialization, recovery, integrity, security, ...) properties of the resource.
- To avoid redundant software, any resource manager can call other resource managers (more or less as subroutines).
- For performance when the client portion and the server portion are co-located, this can be detected automatically when (sub)systems are generated or loaded, followed by choice of optimal communications, e.g., when they are in the same minicomputer and suitable memory protection is provided by the hardware, copying in memory could be used.
- The meaning of "open" is that the client-server protocol is sufficiently defined and publicly communicated so that any software supplier can supply either a client instance or a server instance with confidence that it will interoperate with complying components supplied by others.
This protected resource model is implicit in some thinking about digital library, e.g., [Arms 1995] even though the authors do not explicitly acknowledge this.
Inside Administrative Control Boundaries: Document Access Control and Permissions
We know of an academic collection of photographic slides, in use for many years as a tool for undergraduates, for which the managers doubt they comply properly with rights-holders' constraints. As part of considering creating a digital version of this collection, they have decided to invest in careful compliance. Since the collection has several hundred thousand slides, representing the rules and commitments in an on-line database is being considered. This typifies a developing sense in many enterprises that the onset of digital documents demands better compliance with accepted intellectual property rules and that digital databases are part of what is needed to do this at acceptable cost. Recall that copyright privileges apply for 70 years or longer after the death of authors; institutional memory is at risk without more mechanized means than are commonly employed today.
We should refine prototype database schema and tools to record for decades or longer the terms and conditions of access to copyright-encumbered materials, making this information accessible to administrators and to end users in ways that allow negotiation of access to differentiated communities (members of the university, members of other universities, local citizenry, alumni, ...) with payment for access in some cases. University and IBM projects have such prototype technology in hand and are investigating lacunae, but we currently have too few early deployment opportunities. Many enterprises have urged, and continue to urge, that they need the kind of software that Case Western Reserve University (CWRU) has developed, but none apart from CWRU has yet been willing to risk being a deployment leader. The CWRU prototype is successful in its domain, but needs to be integrated with other digital library components, to have replaced certain components now understood to make untenable business assumptions, and to be tested in a publisher's environment and to scales beyond what CWRU can bring under control. We'll return to this issue of deployment later in the article.
In layered software, lower layers (those close to the hardware) tend to be more generic (useful to more applications) than higher layers (those close to what users see). To the extent that we can share functionality by pushing it into lower layers, we make this functionality less expensive and better tested. For digital library we certainly do this by using generic file systems, database management tools, and communication services and have to some extent achieved this for the storage subsystem [Gladney 1993], which embeds access control services [Gladney 1997]. We now see it possible and desirable to push into this layer the database core of authorization management by identifying the similarities and differences of permissions management and access control, and representing the similar things once only for applications which range from enterprise document management to digital library.
Academic applications of document collections differ from clerical applications more in higher layer functions than in lower layer. In each case, library services need to blend into whatever front end applications the end user wants to use for most of his computing workload. For the internal revenue clerk, this is typically a work-flow management for rapidly executing similar checking for hundreds of tax returns; for the scholar, it is searching, reading, and extraction as an adjunct to analysis and writing. For some topics, such as environmental studies and public health investigations, researchers partly draw on the same documents as clerical users. Shared lower level tools thus become mandatory, rather than merely a cost-saving tactic.
The similarities between access control databases and permissions databases jump out at you if you inspect the schema sketched in [Gladney 1998b] with those in [Gladney 1997]. As authorization decisions begin to depend on users' organizational roles [Ferraiolo 1995] and other user attributes, such as commitment to pay, and document dependent values [Sloman 1994], we are further motivated in this direction. We seek further similarities, because the cost of incorporating more complex decision-making requires larger amortization bases, and because using organizations will neither tolerate nor accept different mechanisms for their administrative systems than for their document management systems. A final push comes from recent understanding that library services must bridge administrative domains (IBM Research and Stanford University are different administrative domains).
Access control software developed separately between 1970 and today for different operating systems and for different services within some systems (e.g., OS/MVS files and DB2 relational databases are protected by different software, even though access control functionality is similar for these two resource classes). The access control needs of different subsystems are converging as applications use them together. The complexity presented by marginally different access control solutions for the several services within any single computing complex is not acceptable to administrators; such differences extended to differences among service centers will not be acceptable to end users. We find scores of scholarly papers, touching on:
- Requirements in databases, in office applications, in LANs, in more general networks, within file systems, and recently also in information systems
- access control in object-oriented databases, and in distributed object services;
- distinctions between military and commercial systems;
- delegation and control based on organizational roles rather than on user identities and group memberships; and
- access control as a component of larger security services.
Notwithstanding all this work, the access control methods used by widely deployed software subsystems is only marginally changed from what was designed in the early 1970s. The new work has mostly had no effect.
Our Document Access Control Method (DACM) [Gladney 1997] is already well poised to implement what the prior paragraphs of this section call for. It is structured into a model-independent base within which each protected object selects an access control object which includes both access control data (this could be the kind of access control list that DCE file systems provide) and a pointer to some interpreter or permission function. Each of several interpreters would implement an access control model; this could be a role-based model, an object-oriented model, the model [Gladney 1997] recommends as particularly suited to office applications, or some entirely new model. As suggested by Figure 1, several such permission managers can be part of and invoked by a document storage subsystem (the data resource manager portion of a digital library).
We emphasize that thes software structure of the prior paragraph contributes to essential flexibility. Specifically, we already know that different applications favor different authorization models. We further anticipate that different jurisdictions will want different policies (e.g., the French government, in contrast to the University of California). Whenever a new policy is asked for by custodians of a class of collections, we need only create a new permission function (Figure 1). Typically the cost of this will be about two person months. Moreover, adding a permission function has no effect whatever on the existing content of a library; existing objects will continue to point to existing access control objects which will continue to point at prior permission functions. The new permission function will come into effect for those objects whose owners choose to use the new function. This treatment of the core of authorization management illustrates why we are confident of being able to implement whatever policy is chosen by the authorities for each collection, and do not need to wait until policies are chosen before we make available the authorization management. In fact, most of what is described in [Gladney 1997] is embedded in the IBM VisualInfo product, whose pertinent portions are reused in the IBM Digital Library offering, and has been in use for 4 years.
This dichotomy between supposed needs with suggested solutions and a change pace not suited the pace of introduction of other technologies suggests that we should consider stark alternatives and their consequences.
- We might accept that we must make do with current access control services for another 20 years; to software engineers and computer sciences, this notion is emotionally unacceptable.
- We might build a "federating" layer of application level software that intervenes between existing services and users to present interfaces which "paper over" the accidental differences; this approach is being followed by Tivoli Systems (an IBM subsidiary), and is commercially successful, but we cannot help wondering whether this is an interim solution or can be given a sufficient architectural basis to be durable.
- We might build modular access control services which can easily be incorporated into various middle software ("middleware") offerings and which have sufficient appeal to be adopted instead of custom solutions; we have such software within IBM VisualInfo, but have not yet seen a practical way to promulgate it in the marketplace. The hurdles are in marketing and investment, not technical.
- We might design to replace the current access control mechanisms, knowing the barriers to replacing what exists and works fairly well. For this approach to succeed, the proposed solution must be compellingly better than what is currently in use and must emulate every current method used in applications in which change seen by users is unacceptable. Finally, we must be poised with ready code and persuasive arguments when current methods "break", e.g., when centralized human administration breaks down because there are too many objects, too many users, and too many organizational changes for any central group to manage well.
The last suggests yet another observation: both user administration and access control services have been built starting from designs for monolithic systems ("big iron"), with extensions to accommodate the fact of distributed services. For example, LAN security service offerings are still in fact centralized, with a single data collection for each LAN-wide service. Perhaps it is time to design and build from a model with many uncoupled resource pools (Figure 2) to which coupling is added. We find this last prospect so compelling that we address it in a separate section below.
Enlarging Administrative Control Boundaries: Cryptographic Envelopes
Network technologies enable delivery directly from publishers, or even authors, to end users. Nevertheless we believe that the fundamental values of library organization along current lines carry into digital library services with little modification beyond their implementation mechanisms. We realize these values in a three-tier architecture in which the middle tier accumulates content (or pointers to content) from each of several publishers and directly from many authors (e.g., the faculty of the university), organizes these accumulations as deemed helpful for its most active user communities, and isolates those users from publishers for privacy, for performance, and for administrative convenience [Choy 1996].
The widely-known network security technologies, Secure Sockets Layer (SSL) and Secure HyperText Transport Protocol (SHTTP), are not as helpful with such a middle role as cryptographic envelopes, realized by IBM in a design called CryptolopeTM . From the end user's point of view, SSL/SHTTP do well, with good protection against eavesdroppers and guaranteed authenticity of information (if the server is trusted). Durability of access terms and conditions and continued access to information once delivered are, however, problematical. But they serve neither publishers nor librarians very well because they require continuous running of secure servers, which can be expensive, and little mechanism for administering licence restrictions [Lotspiech 1997].
Each cryptolope wraps a collection of related files, administrative information, and cryptographic keys into a package which includes cryptographic signatures to ensure authenticity, povenance, and completeness and encrypts secret portions under a secret key. We do require a network of clearing centers to administer compliance with owners' terms and conditions and provide keys for released portions to end users. The network protocols for encryption keys and other confidential information are fully worked out. Very pretty properties emerge:
- Cryptolopes may be transmitted by any means at all, without further care for their security.
- Document authenticity and provenance can be checked by end users, without assistance from librarians. Well-known certificate mechanisms and hierarchies of trust can be used for insurance.
- Authorizations can be checked without either publishers or librarians managing user identification.
- Descriptions of protected content and protected administrative data can be included in the clear, so that patrons can have information to decide whether to buy access.
- Portions of related content can be released separately, so that publishers can package to enable customers to avoid paying for portions of no interest.
- Administration can be extended to information transmitted by different channels, e.g., encryption keys for cable video delivery.
At this point, the reader might wonder, "Since this technology is advertised so glowingly, why is it not available commercially?" Part of the answer is that, although in 1995 it was conventional wisdom that information would be "sold on the click", no such market has emerged. IBM's first Cryptolope product was optimized for this market, and misses features needed for digital library applications. We have portions needed for digital library in hand, but have not yet integrated them into a market offering partly for reasons which will become clear below.
Along the way, we learned that we need to represent terms and conditions in at least three domains: on screens in a style that administrators and end users can edit, understand, and analyze with a minimum of prior training or "help" text; in databases made reliably durable for survival over decades and longer; and for transmission among heterogeneous computing systems, i.e., supporting "open" systems so that software consumers have the benefit of multiple technology sources. The best storage representation is one that allows the administrative data to be reliably preserved for many years; this can best be done with relational database technology [Alrashid 1998]. The transmission format must be linear; XML is fast evolving as the favored choice. The external language should be whatever is best for human comprehension and convenience; the author feels the best choice to be Walker's IKM.
Protection Beyond Feasible Administrative Control Boundaries: Marking Documents
When a valuable digital object is in the clear (not encrypted) and outside the sphere of control of administrators committed to protecting it, the only technical means of hindering misappropriation or other misuse is to distort it to discourage and/or detect wrong-doing. This can be either by releasing only versions of insufficient quality for the suspected sins or by adding a signal that includes provenance information.
The basic idea -- marking a document so that secret information is needed to detect and decipher the marks -- is ancient. The ancient trick, called "steganography (secret writing)", is mentioned as early as 700 B.C.:
For Zeus had brought all Argos under the scepter
Of Proetus, whose wrath began this way. Anteia,
His beautiful wife, lusted madly to lie with Bellerophon
In secret love, but she could in no way seduce
That princely, prudent young man. Hence, she made up
A lie and told it thus to her husband the King:
"If you don't want to die, O Proetus, kill Bellerophon.
Though I wouldn't let him, he did his best to seduce me."
At this the King was seized with rage, but since
His soul recoiled from murdering a guest, he sent him
To Lycia instead, where Anteia's father was King.
And grievous credential he gave the young man to take with him,
A folded tablet whereing lord Proetus had written
Many pernicious and fatal signs, which he bade
Bellerophon show to the Lycian King -- who would then
Contrive his death.
So he, with the gods' unfailing
Protection, journeyed to Lycia, and when he reached
That wide land and the flowing Xanthus, the King made him welcome
And heartily entertained him for all of nine days
With as many sacrificed oxen. But when, on the tenth
Dim morning, rose-fingered Dawn appeared, the King
At last got around to asking about the credential
His guest may have brought from Proetus his son-in-law.
Then, having seen the murderous signs, he began
By bidding Bellerophon kill the ferocious Chimaera,
... Homer, The Illiad, Book VI (Ennis Rees translation, Random House, 1963).More recently, visible but difficult-to-remove marks were introduced to identify the origin of printed documents and to discourage their duplication. Watermarks embed in transmitted or stored documents information about their owners and/or sources; fingerprints embed information about their target recipients. Watermarks have eclipsed fingerprints because the latter are much more expensive and inconvenient to administer. Watermarks may be classified in various more or less independent ways:
- As to what they attest to: ownership and provenance or authenticity and completeness;
- As to whether they are perceptible or impercetible to human beings unaided by machinery;
- As to robustness and fragility (fragile watermarks do have useful purposes);
- As to whether the information they carry is encrypted or in the clear; and
- As to the protected information's representation: text, image, video, audio, etc.
Generally comprehensible reviews of watermarking have just appeared, so the analysis that we might otherwise include here is not needed. [Zhao 1998] summarizes the business values of marking. [Memon 1998] summarizes image watermarking in terms that non-technical people will be able to understand. [Craver 1998] shows that recent proposals include methods readily "cracked" or bypassed if used as litigation evidence. [Mintzer 1998] identifies data standardizations to support end users extracting and interpreting watermarks carrying auxiliary information within pictures, to authenticate that information received has not been tampered with, or to show specifically which parts of a picture have been altered. These papers focus on still image marking, treating other media less thoroughly. The technically-inclined reader who wants more depth and pointers into literature which is rapidly developing, may find [Swanson 1998] useful; it touches on algorithms and pays attention to marking of audio signals and motion pictures.
It might be supposed that a robust imperceptible watermark could be the basis of persuasive evidence in litigation. The approach would be that the owner Oliver would produce the original image Io, the watermark pattern Wo, the watermarking software, and show that he could duplicate the watermarked copy Iw that he alleges was misappropriated by Mary. This he would do by adding the watermark to the original image: Io + Wo = Iw . Supposing Oliver could persuade the court that his demonstration was not a sophisticated hoax (a considerable hurdle in itself, probably requiring the watermarking program to conform to a widely accepted standard and the court to use an independently certified implementation of the standard), he would claim as proof of ownership that his sole possession of Io and Wo and that these sufficed to reconstruct Iw. However, anticipating this, Mary might have constructed an Im by subtracting her watermark Wm from the publicly accessible Iw, and could provide identical "evidence" as Oliver, because Im + Wm = Iw !
This example, taken from [Craver 1998] illustrates what is currently being found in analytical attacks on proposed watermarking schemes -- that many are not merely flawed but susceptible to attacks not requiring sophistication from the attacker. The particular attack described above can be overcome by the originator including as part of a watermark a digital signature which verifies the full transmission (the image and watermark combined) if this watermark can be extracted and the signature separately extracted with publicly-distributed (standard) software which is certifiably honest. Our point here is not to argue whether or not imperceptible watermarking can be made trustworthy for proof of ownership, but rather that the question is still open and needful of careful analysis by technical experts, in a contest of methods and code-breaking similar to that used to design quality cryptography. In contrast to proofs of ownership, we believe sound certain methods of proving that a digital object has not been tampered with since authenticating mark was applied. (They do not guard against a fraudulent authentication to a fraudulent document whose provenance is not proven.)
What's Needed When Everything is Distributed?
Some large institutions are considering digital library strategies without central services, but rather networks in which anyone who meets basic quality criteria and conforms to published interface standards could offer access to a collection. The illusion of an institutional library would be created by federating search and navigation services. Although intellectual property issues have not yet, as far as we know, been carefully discussed for such networks, we presume that the fact of service distribution will not relax the functional requirements on access administration. For collections to which read access may be freely given to anyone, or for which simple rules which can be simply administered (as with IP-address filtering), this could be made to work well without much further ado. For collections whose access rules depend on the institutional membership and other attributes of individual users, which might require run-time checks (has he paid the access fee?), mechanisms such as those already discussed in Safeguarding ... and other writings will be needed. Further, each individual user will want to be shielded from most administrative differences of various collections. Users mostly won't care whether such differences are incidental to distributed sources within a delivering enterprise, or fundamental because different source enterprises have different objectives and practices; they simply don't want to be reminded of administrative details during every request.
However, administering complex access limitations is already seen as needing institutional sophistication at applying software which is mostly yet to be written and deployed. Will each of many distributed librarians be required and able to install and administer such tools for his collection?
Consider your own and my usage patterns, as examples of what scholars, students, or other knowledge workers would want. A part of what we do is finding and exploring relationships which have not been considered by any prior worker, doing this by a wandering whose specifics are difficult to predict much in advance. Faced with some specific question, the experts among us will know which collections are likely to be helpful and will want federated search over a small selection of collections, followed by rapid delivery of the most promising documents, to select manually the most pertinent for the interest of the moment. The less expert will want to explore possible sources rapidly. What is in common is that expert and non-expert collection users will often want rapid access to collections to which they have not been admitted before. They won't want to be interrupted to negotiate access; nor can collection administrators afford to check each individual's credentials -- the pace wanted in the wired world will be too high.
Part of what will be needed is addressed in a Cambridge University prototype, whose authors noticed that, although users will rarely have in advance arranged access to external collections (external to their own institutions), prior inter-institutional agreements are already common (inter-library loan) and could be extended to include complex rules about the kind of affiliation users have with their home institutions and possibly on other user attributes (such as having a bank account from which small access fees may be extracted without further human negotitation). [Ching 1996] provides a formalization of the needed communication of credentials, without including the notion of prior agreement negotiated by the end user's organization with the information-delivering organization.
Before projecting the administrative data structures needed to handle the implied scenarios, we need to recall some additional factors: rapid change of institutional membership and even more rapid change of members' privileges within their institutions, and the fact that each end user will belong to several institutions: her university, her city, state, and country, her professional societies, her clubs, and so on. Universities with tens of thousands of students, faculty, and staff, with a turnover of about 20% annually, cannot afford to register each member separately for each service; most already have a single "student card" which extends to libraries, and some are building related digital authentication services to be used by all digital services. Similar less dramatically challenging circumstances exist in commercial and other institutions. When, for example, I seek access to University of California documents for which IBM has already negotiated privileges for Research Staff Members, we all (the University, IBM, and I) want that access to be granted without further human administration. If, however, I also happened to be a University Extension student and if that studentship confered access to a document not available to IBM Reseach Staff Members, we all would be annoyed if I were denied that document.Given all this, the required data structures and processing are manifest:
- Each individual collection user should be described in a single place, together with those attributes wanted for library collection access. This description should identify each institution to which the user belongs. (A single world-wide user descriptor may create serious privacy risks, but we will not address these in this article.)
- Each institution should manage an affiliations database which describes each member's privileges. This may include an organizational structure as simple as groupings common in widely-deployed access control services, but is more likely to support more complex relationships as called for by [Ferraiolo 1995] and delegation rules such as those described by [Gladney 1997b].
- Each collection would have a meta-database. Its root record for each holding would refer to an access control object which itself could be a document, could also include conventional access control lists, or refer to rules and rule interpreters as suggested by [Hayton 1998] and [Walker 1998]. This access control meta-data could be in the same catalog as the collection meta-data, as is described by [Gladney 1997b] and implemented in an IBM content management product which is reused in IBM Digital Library. However, it could also be held in another database as we do in DataLinks [IBM 1997].
- As called for by the applicable standards [ISO 1995], when a user U requested permission P to an object O held by a resource manager RM, RM would pass the meta-data pointers to U, P, and O to a base access control decision function. From O, this would find the applicable access control object A which in turn would indicate which rule set interpreter R was to be used. U would indicate the organizations to which U claimed membership; the base access control service could from these assemble the possibly pertinent descriptors of U. The base access control decision function would pass this marshalled information to the rule set interpreter, which could be of the type described in [Alrashid 1998], [Hayton 1998], or [Walker 1998], which would inform RM whether to grant access and if, not, possibly indicate why not.
- If the rules indicated a payment was to be made or decryption keys were required, the foregoing process could use our Cryptolopetm mechanism [Lotspiech 1997]. The specifics of how, when, and where this would be done have not yet been worked out.
- All this implies many interprocess communications and undesirable delays. Prudently laid-out databases will, in fact, combine logically independent data so that the objects most frequently used together in individual events are in the same databases. Well-known optimization techniques will ensure that only requests that must traverse networks or even process boundaries in the same processor in fact do so; if this is done well, local accesses will not incur processing overhead or delays simply because the access control subsystem is prepared to handle remotely stored information.
Handling wide-spread distribution incurs one new challenge -- more important and more fundamental than the performance issue just alluded to. Implicit in what has just been sketched is a set of inter-dependencies of administrative processes which must trust each other for well-defined purposes. This includes name services and other network services which mediate inter-process connections, so that any process A which is part of the access decision mechanism and is dependent on another process B can decide whether it trusts B's answers for information requested, and also be reasonably confident that the answer truly comes from B rather than a counterfeit.
Hierarchies of trust are needed, following basics of delegated trust articulated in [Abadi 1993] and [Lampson 1992], who consider the calculus of "speaks for" relationships. The implementation of such basics will be an infrastructure of authentication, certificate management, and underlying encryption and key management tools. Fortunately for the library community, this is being developed rapidly for electronic commerce applications whose risks of malfeasance are more evident and more serious than those of purloined digital information. We can confidently wait on and exploit this e-commerce infrastructure.
In addition to basic standards already alluded to, practical services will have to comply with implementation standards, e.g., for CORBA as in [OMG 1996]. Such compliance is part of what is meant by "industrial strength" built into product software but often not into prototypes. Which particular implementation standards should be followed is itself a tricky question, as developing and adopting standards is a slower process than Web software development. Beyond emphasizing the importance of choosing and complying with such standards for stable, long-term service commitments, we don't need to discuss the topic further in this article.
Practical Considerations
What precedes suggests that the techology problems are either solved or well on their way to being solved to the extent that software technology can theoretically mitigate intellectual property risks. This is true, but not enough. For digital library service to be socially and economically significant, it must operate on very large scales and be integrated gracefully into the regular operations of its deploying institutions. Implied are significant engineering challenges which might expose further unsolved fundamental challenges. We cannot simply implement existing designs into offerings acceptable to customers, much less offerings which profoundly please them. Software engineering is still a practical art which requires "production prototypes" -- prototypes built to full scale and tested in environments whose users are fully committed to using them, warts and all, as a step towards re-engineered versions which stand a chance of being satisfactory. We (the technology entrepreneurs) are having trouble finding enterprises willing to encounter and overcome the inherent risks in return for the advantages of leading their competitors.
[Moore 1995] has modelled this problem and characterized the players. His model, one of customer classes and technology entrepreneur adjustments to the marketplaces, focuses on describing customers as in Figure 3. His innovators are those people or organizations who are so enthusiastic about technology that they buy in early, even when tools and enterprise integration cannot be purchased; the Lawrence Livermore AEC Laboratory has approximated this in its attitude towards high-end computers. Moore's early adopters are people who see sufficient promise in a technology to adopt it and build whatever is needed to create a new business they envision; the creation of the Federal Express package delivery business is an example; what Frederick Smith recognized was an opportunity created by the airlines shifting to hub airfields and the availability of automatic package-sorting machinery. Moore's early majority are customers who will not take such risks, who require end-to-end packaged products "integrated" into their businesses (often they are companies that do not wish to employ programmers), and that will not buy unless we can point them at "reference customers" -- companies like their own that are using the new technology. Moore's chasm is the gap between early adopters and early majority.
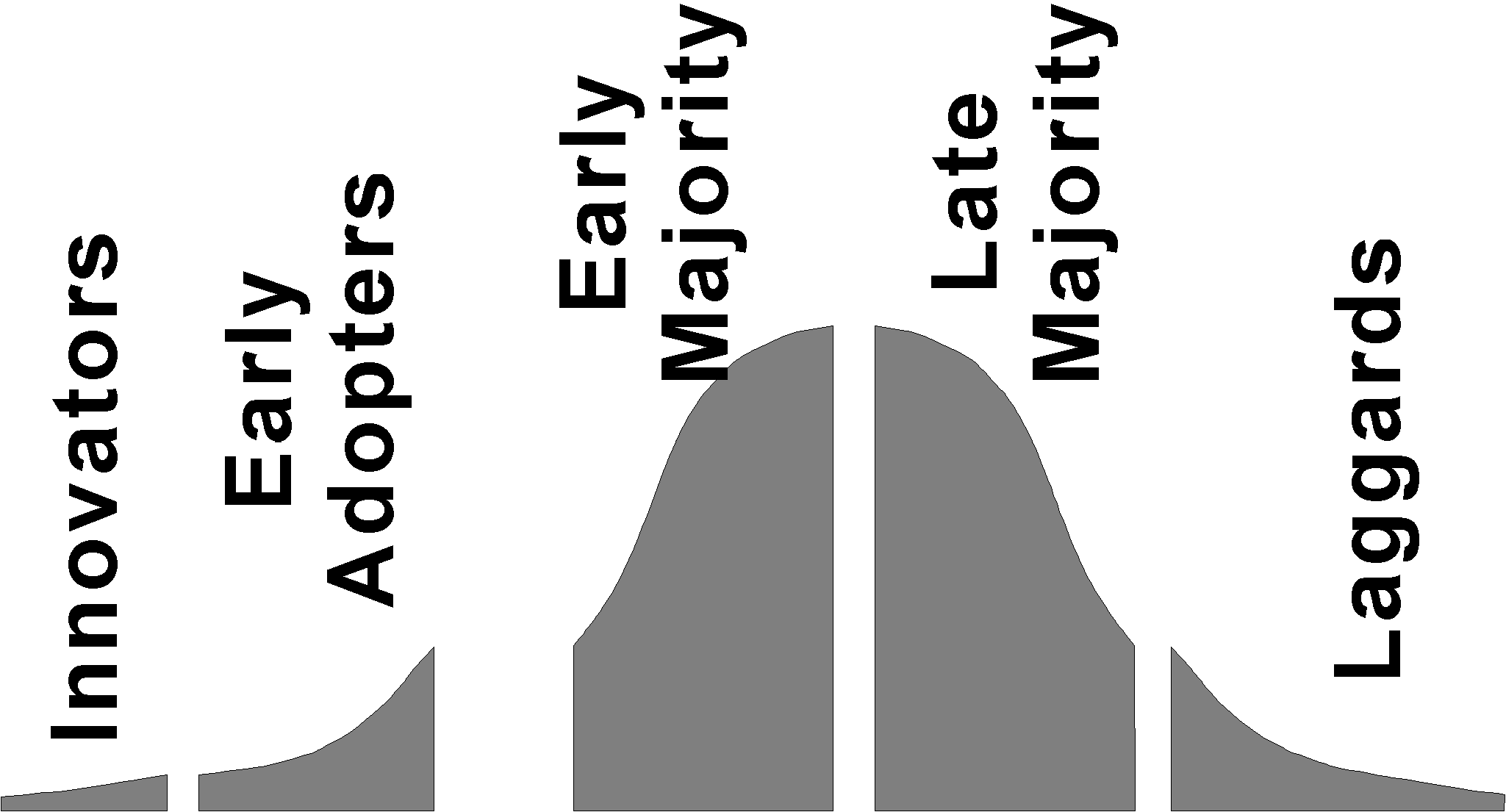
Figure 3.We see Moore's model as a useful guide to our current challenge. The current deployment problem for technology to help manage intellectual property is to move from niche encounters based on piece parts, with many different groups faced with integration responsibilities and costs that distract from their missions, to mainstream deployment based on "complete" solutions. This includes technical challenges of a broad system design nature, but the business challenges currently dominate, and we are forced to limit our technical work to those aspects which address barriers to "crossing the chasm". The software producers are unwilling to build to scale without committed user communities. No user community is willing to commit to something it cannot see in operation in a like user community.
More generally, digital library is currently positioned on the brink of the "early adopter" side of Geoffery Moore's chasm (Figure 3). While design for information protection presents many fascinating technical challenges, progress towards social benefit and business value will in the next few years depend more on practical, deployable solutions to institutional barriers, such as managing information about intellectual property rights and finding ways in which each university can share its digital collection with other universities, and in turn get access to their collections. Particularly the latter challenge is one of more tractable sharing agreements among institutions -- more tractable than currently exist -- with new views required about the balance between collaboration between institutions and competition in which control of intellectual resources is used to distinguish one institution from another.
In a nutshell, we are just now technology rich. There is opportunity for invention, but progress does not seem to be impeded by missing technology. Instead, the principal impediment is the readiness of document collection managers to work with software developers to bring into committed service tools whose importance prospective customers have emphasized for several years. Their reluctance is understandable because these are database applications from which there is no turning back once adopted, only migration forward with corrections for oversights, and because sometimes no organization wants to be the first to adopt. But we believe there will little substantive progress until someone takes the risks.
Conclusions
Much technology for protecting information owners', librarians', and end users' legitimate interests is understood, except that interesting and amusing lacunae exist among theoretically feasible measures. We can be confident that the latter will be mostly be filled before or when the risks they respond to become economically important. Most of this technology will be motivated by other application domains than digital library -- most visibly in the next few years from satisfying the needs of electronic commerce. For portions we need to develop specially for digital library, promising directions have recently become clear.
Processes and databases to record the rules for managing intellectual property and access control databases can be made to be similar. We believe these similarities will offer simplifications for both users and software providers. Twenty-five years of scholarly publication provides a sufficient basis to design a comprehensive access control system to satisfy most published statements of need and to replace aging software which has been tinkered with for too long and developed too many accidental differences in systems which must be used together. We think we know how to do this and will look into it in the immediate future. Database for access and permissions is THE key building block which is needed for responsible collection management, but missing in wide deployment.
Cryptolope technology is "right"; its elegant design is close to ready for practical service.
Watermarking has some way to go before we will understand how dependable it is for ownership certification. Document owners can confidently deploy it in the near future to assure their users that information received is trustworthy.
We believe it is unreasonable to expect to use personal computers to enforce content providers' interests as so-called "trusted systems" [Stefik 1997]. Further, we believe it would mislead the public to refer even to clearance centers as "trusted systems"; to convey what useful function such machines and their human managers can provide, it would be better to call them "trustworthy services". Running server machines within prudently managed "glass houses" [Rosen 1998], with prudent audit [Rosen 1970], continues to be essential for any service called "secure".
To teach protection technology, it helps to partition it into elements useful within protection boundaries (a.k.a. administrative domains), elements which extend the effective reach of protection boundaries, and elements which help beyond protection boundaries. The prominent tools are respectively: user authentication, authorization (access control) and permissions management; cryptographic packages, digital signatures and certificates, and hierarchies of trust; and marking technology.
Prototypes, ours and others, have been sufficiently developed to be bases for confidence in broadly-applicable designs and building production pilots. Why have we not already built them? Although many enterprises urge the need for tools like those described and alluded to above, and although our prototypes have not suffered any compelling criticisms, none of the organizations which profess the need has yet been ready to deploy a pilot to scale. We are leery of building something without a committed user community, because software built on speculation so often misses the mark. Deployment is a bigger challenge than technology enhancement.
One value of technological aids is to provide mitigations for mistrust, augmenting legal, contractual, and social pressures by making cheating difficult and forcing cheaters to take overt steps which remind them of property rights and create evidence of violations. There is another practical value: although the terms and conditions for each work might be simple, the aggregated terms and conditions of millions of works held for decades -- often beyond the job tenures of the individuals who negotiated for each work -- constitute an administrative nightmare that digital storage, communication, and analysis go a long way towards relieving. What we describe are essential elements of larger complete solutions. Deployment depends on tests at very large scale.
The technical topics that are the focus of this article lead directly to open questions of legal interpretation and of social policy -- questions that are being carefully considered in public discussions, in other articles, by legal, political, and economics scholars, and in some cases by legislative committees. Such questions are important enough, urgent enough, and difficult enough that the U.S. National Science Foundation has commissioned a U.S. National Research Council-managed Study Committee for Intellectual Property Rights and the Emerging Information Infrastructure. Individual members of this committee would like to hear carefully considered opinion on any topic within the project scope.
Although during the day we are confident in the emerging understanding of protection technologies, in the darkness of the night we also harbor nagging doubts that our understanding will be complete and that we have truly avoided egregious error. Part of the purpose of this article is to expose our views openly and widely. The author and his colleagues sincerely solicit constructive criticism of what has been presented in the Safeguarding ... series, and will endeavor to respond directly, and in future articles, to criticisms received.
Acknowledgements
This article draws on the work of too many colleagues for specific acknowledgements. Scores of people have helped with hundreds of conversations. They know who they are. I hope they accept my thanks and take satisfaction when they see their insights and views reflected in what is written in the D-Lib Safeguarding ... series.
Bibliography
[Abadi 1993] M. Abadi, M. Burrows, B. Lampson, and G. Plotkin, A Calculus for Access Control in Distributed Systems, ACM Trans. Prog. Lang. and Sys. 15(4), 706-734, (1993).[Arms 1995] R. Kahn and R. Wilensky, A Framework for Distributed Digital Object Services, (May 1995).
[Bearman 1998] D. Bearman and J. Trant, Authenticity of Digital Resources: Towards a Statement of Requirements in the Research Process, D-LIB on-line magazine, (June 1998).[Ching 1996] N. Ching, V. Jones, and M. Winslett, Authorization in the Digital Library: Secure Access to Services across Enterprise Boundaries, IEEE Proc. ADL '96, 110-119, (1996).[Choy 1996] D.M. Choy, J.B. Lotspiech, L.C. Anderson, S.K. Boyer, R. Dievendorff, C. Dwork, T.D. Griffin, B.A. Hoenig, M.K. Jackson, W. Kaka, J.M. McCrossin, A.M. Miller, R.J.T. Morris, and N.J. Pass, A Digital Library System for Periodicals Distribution, Proc. ADL'96, held at the Library of Congress, (May 1996). Reprinted IEEE Computer Society Press, Los Alamitos, Calif., pp. 95-103.[Craver 1998] S. Craver, B.-L. Yeo, and M. Yeung, Technical Trials and Legal Tribulations, Comm. ACM 41(7), 44-55, (1998).[Ferraiolo 1995] D.F. Ferraiolo, J.A. Cugini, and D.R. Kuhn, Role-Based Access Control (RBAC): Features and Motivations, Computer Security Applications Conference, (1995).[Gladney 1993] H.M. Gladney, A Storage Subsystem for Image and Records Management, IBM Systems Journal 32(3), 512-540, (1993).[Gladney 1997] H.M. Gladney, Access Control for Large Collections, ACM Trans. Info. Sys. 15(2), 154-194, (1997).[Hardy 1998] I.Trotter Hardy, Project Looking Forward: Sketching the Future of Copyright in a Networked World, final report to the U.S. Copyright Office, (1998).[Hayton 1998] R.J. Hayton, J.M. Bacon, and K. Moody, Access Control in an Open, Distributed Environment, Proc. IEEE Symposium on Security and Privacy, 3-14, (May 1998).[IBM 1994] IBM Corporation, ImagePlus VisualInfo® General Information and Planning Guide, IBM Systems Ref. Lib.GK2T-1709, (1994).[IBM 1997] IBM Corporation, DataLinks: Managing External Data with a DB2 Universal Database, (1997).
[IBM 1998] IBM Corporation, IBM SecureWay Library, (1998).[ISO 1995] International Organization for Standardization (ISO), Standard for Information Retrieval, Transfer and Management for OSI: Access Control Framework, ISO/IEC JTC 1/SC 21/WG 1 N6947 Second CD 10181-3, (May 1992); Information Technology -- Open Systems Interconnection -- Systems Management: Objects and Attributes for Access Control, ISO/IEC 10164-9, (Dec. 1995).[Lampson 1992] B. Lampson, M. Abadi, and M. Burrows, Authentication in Distributed Systems: Theory and Practice, ACM Trans. Computer Systems 10(4), 265-310, (1992).C. Lynch et al., A White Paper on Authentication and Access Management Issues in Cross-organizational Use of Networked Information Resources, (1998).[Malkhi 1998] D. Malkhi, M.K. Reiter, and A.D. Rubin, Secure Execution of Java Applets using a Remote Playground, Proc. IEEE Symposium on Security and Privacy, 40-51, (May 1998).[Memon 1998] N. Memon and P.W. Wong, Protecting Digital Media Content, Comm. ACM 41(7), 34-43, (1998).[Mintzer 1998] F. Mintzer, G.W. Braudaway, and A.E. Bell, Opportunities for Watermarking Standards, Comm. ACM 41(7), 56-65, (1998).[Moore 1995] G.A. Moore, Crossing the Chasm: Marketing and Selling High-Tech Products to Mainstream Customers, Harper Collins Publishers, Inc., New York, (1995).[NRC 1996] National Research Council, Cryptography's Role in Securing the Information Society, (1996).[OMG 1996] Object Management Group, CORBAservices:Common Object Services Specification, particularly chapter 15, Security Service Specification, (November 1996).[Rabitti 1991] F. Rabitti, E. Bertino, W. Kim, and D. Woelk, A Model of Authorization for Next-Generation Database Systems, ACM Trans. Database Systems 16(1), 88-131, (1991).[Rosen 1970] R.J. Rosen, R.J. Anderson, L.H. Chant, J.B. Dunlop, J.C. Gambles, and D.W. Rogers, Computer Audit Guidelines, Canadian Inst. of Chartered Accountants, (1970).[Rosen 1998] R.J. Rosen, R.J. Anderson, L.H. Chant, J.B. Dunlop, J.C. Gambles, D.W. Rogers, and J.H. Yates, Computer Control Guidelines, Canadian Inst. of Chartered Accountants, (1970). Superceded by Information Technology Control Guidelines, 3rd Edition, (1998). Available via <http://www.cica.ca>.[Sloman 1994] M. Sloman, Policy Driven Management for Distributed Systems, J. Network & Sys. Mgmt. 2(4), 333-360, (1994).[Stefik 1997] M. Stefik, Trusted Systems, Scientific American 276(3), 78-81, (1997).
[Swanson 1998] M. Swanson, M. Kobayashi, A. Tewfik, Multimedia data-embedding and watermarking technologies, Proceedings of the IEEE, 86(6), 1064-1087, (June 1998).[Woody 1998] T. Woody, "Higher Learning: The Fight to Control the Academy's Intellectual Capital, (1998).[Zhao 1998] J. Zhao, E. Koch, and C. Luo, In Business Today and Tomorrow, Comm. ACM 41(7), 66-73, (1998).The Safeguarding series:-[Gladney 1997a] H.M. Gladney and J.B. Lotspiech, Safeguarding Digital Library Contents and Users: Assuring Convenient Security and Data Quality, D-Lib Magazine, (May 1997).[Gladney 1997b] H.M. Gladney, Safeguarding Digital Library Contents and Users: Document Access Control, D-Lib Magazine, (June 1997).[Gladney 1997c] H.M. Gladney, F.C. Mintzer, and Fabio Schiattarella, Safeguarding Digital Library Contents and Users: Digital Images of Treasured Antiquities, D-LIB on-line magazine, (July 1997).[Lotspiech 1997] J.B. Lotspiech, U. Kohl, and M.A. Kaplan, Safeguarding Digital Library Contents and Users: Protecting Documents Rather Than Channels, D-Lib Magazine, (September 1997).[Mintzer 1997] F. Mintzer, J. Lotspiech, and N. Morimoto, Safeguarding Digital Library Contents and Users: Digital Watermarking, D-LIB on-line magazine, (December 1997).[Herzberg 1998] A. Herzberg, Charging for Online Content, D-Lib Magazine, (January 1998).[Walker 1998] A. Walker, The Internet Knowledge Manager: Dynamic Digital Libraries, and Agents You Can Understand, D-Lib Magazine, (March 1998). A live demonstration version is accessible to anyone.[Alrashid 1998] Tareq M. Alrashid, James A. Barker, Brian S. Christian, Steven C. Cox, Michael W. Rabne, Elizabeth A. Slotta, and Luella R. Upthegrove, Safeguarding Copyrighted Contents: Digital Libraries and Intellectual Property Management, D-Lib Magazine, (April 1998).[Gladney 1998a] H.M. Gladney, Safeguarding Digital Library Contents and Users: a Note on Universal Unique Identifiers, D-Lib Magazine, (April 1998).[Gladney 1998b] H.M. Gladney and J.B. Lotspiech, Safeguarding Digital Library Contents and Users: Storing, Sending, Showing, and Honoring Usage Terms and Conditions, D-Lib Magazine, (May 1998).Copyright and Disclaimer Notice
Copyright IBM Corp. 1998. All Rights Reserved. Copies may be printed and distributed, provided that no changes are made to the content, that the entire document including the attribution header and this copyright notice is printed or distributed, and that this is done free of charge. We have written for the usual reasons of scholarly communication. Wherever this report alludes to technologies in early phases of definition and development, the information it provides is strictly on an as-is basis, without express or implied warranty of any kind, and without express or implied commitment to implement anything described or alluded to or provide any product or service. Use of the information in this report is at the reader's own risk. Intellectual property management is fraught with policy, legal, and economic issues. Nothing in this report should be construed as an adoption by IBM of any policy position or recommendation.
The opinions expressed are those of the author and should not be construed to represent or predict any IBM position or commitment.
An updated version of Figure 1 was substituted on July 16, 1998 at the request of the Author. Minor corrections to the punctuation and to the mark-up were also made at that time. The Editor, July 16, 1998 3:43 pm.
The URL for [Walker 1998] was corrected at the request of the Author. The Editor, July 22, 1998 9:01 AM.
(HTML coding errors regarding a heading tag and a link tag corrected 8/31/05.)
Top | Magazine
Search | Author Index | Title Index | Monthly Issues
Previous Story | Next Story
Comments | E-mail the Editorhdl:cnri.dlib/july98-gladney