D-Lib Magazine
July/August 2016
Volume 22, Number 7/8
Table of Contents
Exporting Finnish Digitized Historical Newspaper Contents for Offline Use
Tuula Pääkkönen
National Library of Finland, Centre for Preservation and Digitization
tuula.paakkonen@helsinki.fi
Jukka Kervinen
National Library of Finland, Centre for Preservation and Digitization
jukka.kervinen@helsinki.fi
Asko Nivala
University of Turku, Department of Cultural History
asko.nivala@utu.fi
Kimmo Kettunen
National Library of Finland, Centre for Preservation and Digitization
kimmo.kettunen@helsinki.fi
Eetu Mäkelä
Aalto University
eetu.makela@aalto.fi
DOI: 10.1045/july2016-paakkonen
Printer-friendly Version
Abstract
Digital collections of the National Library of Finland (NLF) contain over 10 million pages of historical newspapers, journals and some technical ephemera. The material ranges from the early Finnish newspapers from 1771 until the present day. The material up to 1910 can be viewed in the public web service, where as anything later is available at the six legal deposit libraries in Finland. A recent user study noticed that a different type of researcher use is one of the key uses of the collection. National Library of Finland has gotten several requests to provide the content of the digital collections as one offline bundle, where all the needed content is included. For this purpose we introduced a new format, which contains three different information sets: the full metadata of a publication page, the actual page content as ALTO XML, and the raw text content. We consider these formats most useful to be provided as raw data for the researchers. In this paper we will describe how the export format was created, how other parties have packaged the same data and what the benefits are of the current approach. We shall also briefly discuss word level quality of the content and show a real research scenario for the data.
1 Introduction
The historical newspaper, journal and ephemera collection of NLF is available up to 1910. The online system offers page images of the content, which can be accessed either by browsing or using the search engine. Recently, the text content of the page as ALTO XML (Analyzed Layout and Text Object) was also released for the users. However, for doing any mass operations on the XML files, there needs be to a way to offer the whole content at once, instead of having to download it page by page.
Part of the Finnish newspaper corpus has been made available via the FIN-CLARIN consortium and Europeana Newspapers. FIN-CLARIN offers the data in two different formats. In the recent one the data is provided in the original ALTO XML format, but the directory structure follows the original file system order, where one newspaper title can span different archive files. FIN-CLARIN offers the original ALTO format via the Language bank service for years 1771-1874. Secondly, FIN-CLARIN also provides a processed version by offering the Finnish word n-grams 1820-2000 of the newspaper and periodicals corpus partitioned in decades with word frequency information. Thirdly, the data is available as one of the materials of the Korp corpus environment.
In addition, NLF has provided a data set to The Europeana Newspapers via the European Library (TEL), which was one of the partners of the Europeana Newspapers. At TEL, for example, eleven representative Finnish newspapers were selected that are in the public domain. TEL does not offer the texts themselves, but only the metadata associated with them (with links to page images). These are offered in RDF (in RDF/XML and Turtle serializations), as well as Dublin Core XML. The metadata records are also available in JSON format via the Europeana project, this time also including the raw text of the page. Presently, there are plans to move the TEL portal to a new newspaper channel of Europeana.
2 Creation of the Export
Before beginning export creation we needed to decide which metadata is added to the set, and which formats the data would be offered in. During outlining of the digital humanism policy of the NLF, there was lots of internal discussion about the various formats which the library should provide for researchers. For the newspaper corpus we decided to create the export with original ALTO XML and raw text plus the metadata. Initially we considered offering just ALTO XML as it is the main format from the post-processing of the production line. Raw text format was chosen to enable more convenient use for those who might not feel comfortable with ALTO XML, as it was relatively straightforward to extract the text from the NLF XML format. However, just when we were starting exporting, the need to also have the metadata arose. In order to avoid having several separated datasets, we also incorporated metadata to each XML file. We had earlier provided the raw text in the Digital Humanities Hackathon of 2015 (DHH15), where the raw texts were used alongside the precompiled word n-grams from the FIN-CLARIN (The Language Bank of Finland).
The ALTO format of the package contains the information, which has been captured from the original page images. The quality assurance process of NLF is quite light and it aims mainly to check the metadata. For example, no layout or reading order issues are typically fixed from what the backend system (DocWorks) provides with the text content and logical layout of the page off-the-shelf.
The digitization of the NLF has spanned several years, averaging about 1 million pages a year. Nearly every year the backend system has also improved, and new versions, with new features or improvements have appeared, and the METS/ALTO files also contain this version information. The generic structure for the export is shown in Figure 1 (metadata, XML ALTO and the plain text).

Figure 1: General structure of the export files
2.1 Technical Implementation
In the generation of the export, our main database, which contains the information of the material (i.e. title metadata, page data, and file data containing the archive directory information) was utilized. At the beginning of the export, a title is selected and its metadata and location of ALTO XML files are extracted first from the database. Then the corresponding ALTO XML files are extracted, and combined with the raw text of the page, which is available in the database. All of these are combined as a NLF-specific XML file. We decided to produce one XML format, to ease our internal generation of the export and to keep the export as one complete set. In the long run, we hope that this will make management and versioning of the export set easier, in comparison with having three separate data sets. Our goal is to have one master set, which would be the same, which we offer to those researchers who do offline analysis. If we get feedback for the export set, it will be easier to trace back any suggestions and improve the originals or re-generate the export with enhancements with only one main export.
Implementation of the export script took a few days, but the most time consuming task was to run it against the material set. To speed the creation of the export packages, execution of the generation script was replicated so that it was possible to run different exports in parallel. Extracting one particular file from the database is quite fast, but adding the database operations and other processing takes time when it has to been done to millions of files. With several simultaneous batch runs the extraction was completed faster.
2.2 Metadata within the Exports
The format of the NLF-specific XML file is presented in Figure 2 in detail. The metadata fields of rows 5-9 and 18-22 are currently visible in the web presentation system on the page itself, but the details of the publisher rows 12-15 are only visible via the detailed information of the title. This information is not conveniently located in the event that some page-level calculations or analysis needs to be done. Page label is not visible in the presentation system, where the page numbers are as given in PageOrder. Language will be made available as one of the search criteria in an upcoming release, but currently it is not visible anywhere.
Figure 2: Example of an exported XML file: metadata, ALTO XML and CDATA
Thanks to a suitable infrastructure for the exporting, where we have one table with information about the storage location of the ALTO XML files and information about the publication date of the material, we were able to extract the material in a straightforward way. All pages before 1.1.1911 were exported and extracted in two different directories, one based on ISSN and other based on the publication year.
After the metadata comes the matching ALTO XML file for the given page id (starting from line 27 in Figure 2). For any processing that might be feedbacked from the researchers, for example, the tags pageIdentifier and bindingIdentifier are useful for the NLF, as they identify that particular item in a reliable manner as every page and binding have a unique identifier. This enables a feedback loop, in case there is opportunity to get improvements from the researcher community.
The ALTO XML is generated by the Content Conversion Specialists' DocWorks program in the post-processing phase of the digitization. ALTO XML contains the layout and the actual words of the page text, with the coordinates that indicate the location of each word on the page. Finally, at the end of each of the files, there is the raw text of the page from the database (CDATA, starting from line 2717 in Figure 2), which is what the search of the presentation system uses when giving search results to the users.
2.3 Top-level Structure
In the planning phase of the export we thought of potential user scenarios for the export. Based on earlier feedback we figured that the most probable needs are based on years or by ISSN, which were used as ways to divide the material before packaging. Language of the pages was also included as one folder level. Figure 3 shows the folder structure
.

Figure 3: The folder structure
Below the lowest-level folder are the actual ALTO XML files, which are named descriptively, for example: fk25048_1906-10-03_9_002.xml (= ISSN_YEAR_DATE_ISSUE_PAGE). We hope that the folder level structure and the file naming policy will provide enough flexibility for us to be able to generate subsequent exports based on user needs. If the request is for all of the material, then everything under by_year structure is given. The selected year divisions are estimations based on the amount of pages and estimated sizes, to get each year span's export package to be roughly of the same size.
2.4 Export File Sizes
The sizes of the export files are considerable: 187 gigabytes as zip files. For this reason, downloadable packages were put in the first phase to an external service, which provides enough storage space. The pilot version was offered to the key contact points via Funet FileSender, and the upload speed was at some point 6MB / second, meaning that just uploading the whole data set took nearly nine hours. In the future, the export dumps will be offered via the http://digi.kansalliskirjasto.fi website, which enables us to generate new versions more fluently. Table 1 shows sizes of the zip package parts.
| Export file name |
Size |
| nlf_ocrdump_v0-2_journals_1816-1910.zip |
18G |
| nlf_ocrdump_v0-2_newspapers_1771-1870.zip |
12G |
| nlf_ocrdump_v0-2_newspapers_1871-1880.zip |
13G |
| nlf_ocrdump-v0-2_newspapers_1881-1885.zip |
12G |
| nlf_ocrdump-v0-2_newspapers_1886-1890.zip |
16G |
| nlf_ocrdump-v0-2_newspapers_1891-1893.zip |
13G |
| nlf_ocrdump-v0-2_newspapers_1894-1896.zip |
15G |
| nlf_ocrdump-v0-2_newspapers_1897-1899.zip |
16G |
| nlf_ocrdump-v0-2_newspapers_1900-1902.zip |
16G |
| nlf_ocrdump-v0-2_newspapers_1903-1905.zip |
18G |
| nlf_ocrdump-v0-2_newspapers_1906-1907.zip |
18G |
| nlf_ocrdump_v0-2_newspapers_1908-1909.zip |
20G |
| nlf_ocrdump_v0-2_newspapers_1910.zip |
9.9G |
Table 1: Packages and their sizes
The number of ALTO XML files in the newspaper part of the export is presented in Figure 4 with languages. The total number of pages is ca. 1.961 M. The language is the primary language of the title as listed in our newspaper database. For clarity, information about the number of Russian and German pages has been omitted (in total 8,997 and 2,551 pages, respectively) and we show only the number of Finnish and Swedish pages. The total number of Finnish pages is 1,063,648, and the total number of Swedish pages 892,101. Journal data is more varied: out of its 1,147,791 pages, 605,762 are in Finnish and 479,462 are in Swedish (total 1,085,224 pages). The rest are either multilingual or in other languages.
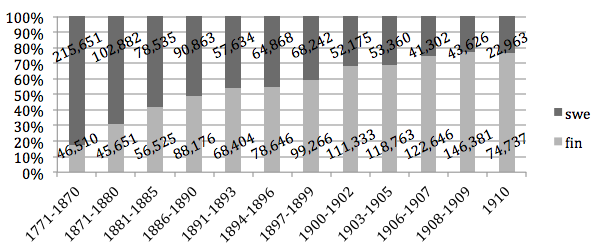
Figure 4: Number of pages in Finnish and Swedish in different packages
3 Nordic Situation Briefly
Opening of data is in its early phases in Scandinavia. In Finland, the National Library of Finland has started by opening the main portal Finna (Finna API, 2016) and ontology and thesaurus service of Finto. The Fenno-Ugrica service has opened material from the digital collection of Uralic languages. In comparison to these, the Finnish newspaper and journal collection data would be quite large, consisting of around three million pages.
In Sweden, the National Library of Sweden has opened their data via the http://data.kb.se service. The opened data is an interesting cross-cut of different material types, with a couple of newspapers, namely Post- och inrikes tidningar (1645-1705) (aka POIT) and Aftonbladet (1831-1862). Interestingly, these have made different data available: POIT offers original page images (.tif), text of the pages and the corrections of the page texts as .doc files. The data set of Aftonbladet, on the other hand, offers the combination of post processing outputs, i.e. METS, ALTO and page images (.jp2). In Denmark the practice is currently that access to the digitized newspapers is provided via the State and University Library, the Royal Library and the Danish Film Institute. In Norway, for example, the newspaper corpus is offered via the Språkbanken, for the years 1998-2014.
In the Nordic context the NLF export is thus quite extensive, with a time range of 1771-1910, and coverage of all the titles published during that time. The year 1910 is in Finland currently the year before which we feel that the risk of copyright problems is minimized. However, in the feedback from some researchers, there is a desire to get data from later than 1910, especially as the centenary of Finland's independence in 2017 is nearing.
4 Quality of the OCRed Word Data in the Package
Newspapers of the 19th and early 20th century were mostly printed in the Gothic (Fraktur, blackletter) typeface in Europe. Most of the contents of Digi have been printed using Fraktur, Antiqua is in the minority. It is well known that the typeface is difficult to recognize for OCR software (cf. e.g. Holley, 2008; Furrer and Volk, 2011; Volk et al., 2011). Other aspects that affect the quality of the OCR recognition are, among others: quality of the original source and microfilm; scanning resolution and file format; layout of the page; OCR engine training; noisy typesetting process; and unknown fonts (cf. Holley, 2008).
As a result of these difficulties, scanned and OCRed document collections have a varying amount of errors in their content. The amount of errors depends on the period and printing form of the original data. Older newspapers and magazines are usually more difficult for OCR; newspapers from the early 20th century are usually easier. Tanner et al. (2009), for example, report for the British Library's 19th Century Newspaper Project an estimated word correctness of 78%.
There is no single available method or software to assess the quality of large digitized collections, but different methods can be used to approximate quality. In Kettunen and Pääkkönen (2016) we discussed and used different corpus analysis style methods to approximate overall lexical quality of the Finnish part of the Digi collection. For the Swedish part, assessment is missing so far. Methods include usage of parallel samples and word error rates, usage of morphological analyzers, frequency analysis of words and comparisons to comparable edited lexical data.
Our results show that about 69% of all the 2.385 B word tokens of the Finnish Digi can be recognized with a modern Finnish morphological analyzer, Omorfi. If orthographical variation of v/w in the 19th century Finnish is taken into account and the number of out-of-vocabulary words (OOVs) is estimated, the recognition rate increases to 74-75%. The rest, about 625 M words, is estimated to consist mostly of OCR errors, at least half of them hard ones. Out of the 1 M most frequent word types in the data that make 2.043 billion tokens, 79.1% can be recognized.
The main result of our analysis is that the collection has a relatively good quality rating, about 69-75%. Nevertheless, about a 25-30% share of the collection needs further processing so that the overall quality of the data can improve. However, there is no direct way to higher quality data: re-OCRing of the data may be difficult or too expensive/laborious due to licensing models of the proprietary OCR software or the lack of font support in open-source OCR engines. Post-processing of the data with correction software may help to some extent, but it will not cure everything. Erroneous OCRed word data is a reality with which we have to live.
5 Use Case of the Material: Text Reuse Detection and Virality of Newspapers
Computational History and the Transformation of Public Discourse in Finland 1640-1910 (COMHIS), a joint project funded by the Academy of Finland, is one of the first large projects that will utilize the newspaper and journal data of Digi. The objective of the consortium is to reassess the scope, nature, and transnational connections of public discourse in Finland 1640-1910. As part of this consortium, the Work Package "Viral Texts and Social Networks of Finnish Public Discourse in Newspapers and Journals 1771-1910" (led by Prof. Hannu Salmi), will be based on the text mining of all the digitized Finnish newspapers and journals published before 1910. The export package will be the main data source for this. The project tracks down the viral texts that spread in Finnish newspapers and journals by clustering the 1771-1910 collection with a text reuse detection algorithm. This approach enables one to draw new conclusions about the dissemination of news and the development of a newspaper network as a part of Finnish public discourse. We study, for example, what kinds of texts were widely shared. How fast did they spread and what were the most important nodes in the Finnish media network?
The historical newspaper and journal collection of NLF from the 1770s to the 1900s enables various digital humanities approaches, like topic modeling, named-entity recognition, or vector-space modeling. However, the low OCR quality of some volumes sets practical restrictions for the unbiased temporal distribution of the data. Fortunately, text reuse detection is relatively resistant to OCR mistakes and other noise, which makes virality of newspapers a feasible research question. The COMHIS project is currently testing a program called Passim for detecting similar passages with matching word n-grams, building on the methods developed for the similar study of 19th century US newspapers by Ryan Cordell, David A. Smith, and their research group (Cordell, 2015; Smith et al., 2015). Text reuse detection is an especially suitable method for a newspaper corpus. In contrast to novels, poetry, and other forms of fiction, authorship of a newspaper article was usually irrelevant in the 19th century publication culture. The more the news was copied the more important it was, whereas fictional texts were considered as an individual expression of their author. Circulation of the texts was reinforced by the lack of effective copyright laws prior to the Berne Convention in 1886. By analyzing the viral networks of Finnish newspapers, our aim is not to track down the origin of a specific text, but rather to study the development of media machines and the growing social and political influence of the public sphere from a new perspective.
In the Finnish case, the rapid increase in newspaper publishing happened relatively late. As shown in Figure 4, the growth of the press was almost exponential at the beginning of the 20th century. It thus makes sense to analyze the 1900-1910 data as its own group. Because the project has just started, a complete analysis of the clustering results is not finished yet, but it is possible to give a few examples of widely shared text. During the time period of 1770-1899, one interesting cluster encountered so far is the succession of the Russian throne to Tsar Alexander III. These dramatic events started with the assassination of Tsar Alexander II, who died in the bomb attack by Polish terrorists on 13 March 1881. The death of the beloved emperor became viral news. The official statement of the new ruler Alexander III to Finnish people was first printed in Suomalainen Wirallinen Lehti on 17 March 1881. Between 17-26 March the text was printed in 15 major newspapers around Finland. The same text was also reprinted in the following years, e.g. on 26 July 1890 in Waasan Lehti and on 30 December 1890 in Lappeenrannan Uutiset (Table 2). Finally, the death of Alexander III was reported in 2 November 1894 in Suomalainen Wirallinen Lehti and it also became a similar viral text.
| Newspaper title, number of reprints |
Date |
| Suomalainen Wirallinen Lehti, Uusi Suometar (2) |
1881-03-17 |
| Aura (1) |
1881-03-18 |
| Sanomia Turusta, Tampereen Sanomat, Satakunta (3) |
1881-03-19 |
| Waasan Lehti, Vaasan Sanomat (2) |
1881-03-21 |
| Savo (1) |
1881-03-22 |
| Tapio, Karjalatar (2) |
1881-03-23 |
| Hämeen Sanomat (1) |
1881-03-25 |
| Ahti, Kaiku, Savonlinna, Waasan Lehti (4) |
1881-03-26 |
| Lappeenrannan Uutiset (1) |
1890-12-30 |
| Turun Lehti (1) |
1892-02-02 |
Table 2: Reprints of the inauguration statement of the emperor Alexander III
Virality was a more typical feature of newspapers, but it is of course possible to process all Finnish journals with Passim. When it comes to journals, the most shared texts are Bible quotations. Among the biggest clusters mined so far is the one consisting of 87 references to the Finnish translation of the Book of Revelations (3:20). In Swedish material, John 3:16 is reprinted 58 times over the time period, and there are lots of other widely-shared Bible passages, which could provide an interesting perspective to the tempo of secularization in Finland. The biggest group of clusters after the religious texts appears to be advertisements by publishing houses, banks, and insurance companies. Only after that there are stories and magazine articles, which can be reprinted many years after their original time of publication.
Historical newspapers have been an important genre of sources for historical research. Before becoming available as a digitized collection, the Finnish newspapers and journals were read as originals or on microfilm. Traditionally historical scholarship has been based on the ideal of close reading, which implies careful interpretation of each document before one is able to draw any conclusions based on the sources. However, in the case of the digitized newspapers, the mere quantity of available textual data makes this approach virtually impossible. Franco Moretti (2007) has asserted that in order to readjust the methodology of humanities to the scale of big data, we need to develop methods of distant reading to process substantial amounts of textual documents without losing analytical rigor. Moreover, the humanist scholars may have to abandon any strict dichotomy between narrative and database (Hayles, 2012). The research questions of the digital humanities often entail converting a textual corpus to a database for various forms of computational analysis and heuristics. After this, the new textual locations discovered by the computational algorithm are then closely read. For example, the text reuse detection algorithm can cluster widely shared text passages together for further analysis, but it cannot typically distinguish whether the text is an advertisement, a common Bible quotation, or an interesting news article. In future it could be possible to use ALTO XML metadata or machine learning methods (like Naive Bayes classifier) to group the detected clusters according to their textual genre.
6 Conclusion
As Tanner (2016) says, the digital library can face a "growing unfunded mandate", as additional requirements of digital material, such as availability and accessibility, create a new kind of demand for the material, while data production resources decrease or remain the same. Therefore it is crucial that research use is considered to be one impact factor, and for it to become more observable to a content or raw research data provider, such as National Library of Finland. Collaboration with research units should be increased so that researchers can express their needs regarding what should be digitized, and they could tell if there is need for curation or special formats. However, this is a balancing act — how should a library organization best serve researchers with its limited resources? Is it possible to find joint funding opportunities and actually complete tasks together, in close relationship? The National Library of Finland is aiming to improve this via forthcoming Digital Humanism and Open Data policies which are due to be published during 2016. The key tenet in the policies is to work together and consider researchers as one customer segment. Research usage should also be considered as a result metric for NLF, either via collaborative projects or keeping track of where the digitized materials are used.
The work on the export continues. During early summer we plan to set up our own website to share the export data sets with anyone who is interested. For the statistics, we will have a short survey about the research use which we hope will also give us insight into what kind of exports would be useful in the future, and if there is something that should be taken into consideration with the long-term digitization roadmaps. The big question is the structure of the export. Should it contain all of the content within one file, or should it be structurally divided so that each data item (metadata, ALTO, page text) is available separately. There are advantages and disadvantages in both approaches, so it needs to be determined which would be the best long-term solution with the available resources. In addition, we need to consider the content itself, to see if there is a need for the METS and the page images, too.
With input from those who have the first released versions we have the opportunity to develop the export further, by adding data or adjusting the fields and their content accordingly. We anticipate a clear increase in researchers' needs which could lead to closer collaboration between NLF and researchers.
Acknowledgements
Part of this work is funded by the EU Commission through its European Regional Development Fund and the program Leverage from the EU 2014-2020. COMHIS is funded by the Academy of Finland, decision numbers 293239 and 293341.
References
| [1] |
Cordell, R. (2015). Reprinting, Circulation, and the Network Author in Antebellum Newspapers. American Literary History, 27 (3), pp. 417-445. http://doi.org/10.1093/alh/ajv028 |
| [2] |
Finna API (in English) — Finna — Kansalliskirjaston Kiwi. (2016). |
| [3] |
Furrer, L. and Volk, M. (2011). Reducing OCR Errors in Gothic-Script Documents. In Proceedings of Language Technologies for Digital Humanities and Cultural Heritage Workshop, pp. 97-103, Hissar, Bulgaria, 16 September 2011. |
| [4] |
Hayles, N. K. (2012). How We Think. Digital Media and Contemporary Technogenesis. Chicago; London: The University of Chicago Press. |
| [5] |
Holley, R. (2009). How good can it get? Analysing and Improving OCR Accuracy in Large Scale Historic Newspaper Digitisation Programs. D-Lib Magazine March/April 2009. http://doi.org/10.1045/march2009-holley |
| [6] |
Hölttä, T. (2016). Digitoitujen kulttuuriperintöaineistojen tutkimuskäyttö ja tutkijat. M. Sc. thesis (in Finnish), University of Tampere, School of Information Sciences, Degree Programme in Information Studies and Interactive Media. |
| [7] |
Kettunen, K. and Pääkkönen, T. (2016). Measuring lexical quality of a historical Finnish newspaper collection — analysis of garbled OCR data with basic language technology tools and means. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016). |
| [8] |
Kingsley, S. (2015). Eteenpäin sopimalla, ei lakia muuttamalla. Kansalliskirjasto, 57(1), pp. 18-19. |
| [9] |
Moretti, F. (2007). Graphs, Maps, Trees: Abstract Models for a Literary History. London; New York: Verso. |
| [10] |
Smith, D. A., Cordell, R. and Mullen, A. (2015). Computational methods for uncovering reprinted texts in antebellum newspapers. American Literary History 27 (3), pp. E1-E15. http://doi.org/10.1093/alh/ajv029 |
| [11] |
Tanner, S. (2016). Using Impact as a Strategic Tool for Developing the Digital Library via the Balanced Value Impact Model. Library Leadership and Management, 30(3). |
| [12] |
Tanner, S., Muñoz, T. and Ros, P. H., (2009). Measuring Mass Text Digitization Quality and Usefulness. Lessons Learned from Assessing the OCR Accuracy of the British Library's 19th Century Online Newspaper Archive. D-Lib Magazine July/August. http://doi.org/10.1045/july2009-munoz |
| [13] |
Volk, M., Furrer, L. and Sennrich, R. (2011). Strategies for reducing and correcting OCR errors. In C. Sporleder, A. Bosch, and K. Zervanou, editors, Language Technology for Cultural Heritage, 3-22. Springer-Verlag, Berlin/Heidelberg. |
About the Authors
M. Sc. Tuula Pääkkönen works in National Library of Finland as Information Systems Specialist. Her work includes the development of some of the tools to support digitization efforts, technical specification and projects for the DIGI.KANSALLISKIRJASTO.FI service. She has been working in the library in a project dealing with copyrights and data privacy topics as well as other development projects, which have dealt with digital contents, crowdsourcing and metrics.
Mr. Jukka Kervinen has worked as a Systems Analyst in the National Library of Finland since 1999. His main responsibilities have been designing and setting up Library's in house digitization workflows and post processing. His experience encompasses metadata development (METS, ALTO, PREMIS, MODS, MARCXML), system architecture planning and database design. He is a member of ALTO XML editorial board since 2009 and member of METS editorial board since 2011.
Dr. Asko Nivala is a Postdoctoral Researcher in Cultural History at the University of Turku, Finland. His research focuses on early nineteenth-century cultural history and especially on the Romantic era. His other research interests include the recent discussions on the digital humanities and posthumanism. Nivala has co-edited the collection "Travelling Notions of Culture in Early Nineteenth-Century Europe" (Routledge 2016) and written the monograph "The Romantic Idea of the Golden Age in Friedrich Schlegel's Philosophy of History" (Routledge, to be published in 2017).
Dr. Kimmo Kettunen works at the Centre for Preservation and Digitisation of National Library of Finland as a research coordinator in the Digitalia project. His work includes research related to the DIGI.KANSALLISKIRJASTO.FI service. He has been involved especially in the quality estimation and improvement of the content of the service. He has also conducted research on Named Entity Recognition (NER) of the OCRed newspaper material. Kimmo is part of the digital humanities research team at the Centre.
D.Sc. Eetu Mäkelä is a computer scientist from Aalto University, Finland. His current main interest is to further computer science through tackling the complex issues faced by scholars in the humanities when using their tools and data. Thus, he currently spends most of his time in collaboration with multiple international digital humanities research projects. Through these collaborations, and through having attained his doctorate in research on data integration and Linked Data, he has ample experience in best practices for publishing data in as usable a form as possible.