|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Simon Tanner Trevor Muñoz Pich Hemy Ros |
![]()
1. IntroductionThis article will discuss how to measure the accuracy of Optical Character Recognition (OCR) output in a way that is relevant to the needs of the end users of digital resources. A case study measuring the OCR accuracy of the British Library's 19th Century Newspapers Database provides a clear example of the benefits to be gained from measuring not just character accuracy but also word and significant word accuracy. As OCR primarily facilitates searching, indexing and other means of structuring the user experience of online newspaper archives, measuring the word and significant word accuracy of the OCR output is very revealing of a resource's likely performance for these functions. Having such data is therefore extremely helpful for planning and quality assurance assessment. After briefly discussing the role of OCR in the text capture process and how OCR works, we give a detailed description of the methodology, statistical data gathering techniques and analysis used in this study. Our conclusions point the way forward with suggested actions to assist other mass digitization projects in applying these techniques. 2. Text CaptureText capture is a process rather than a single technology. It is the means by which textual content that resides within physical artifacts (such as books, manuscripts, journals, reports, correspondence, etc.) may be transferred from that medium into a machine-readable format. Whilst the focus of this article is mainly upon historical newspaper resources, much of this discussion is applicable as well to other types of printed historical materials. The text capture process should be conceived throughout as a way to add value in relation to the intellectual aims desired for text resources. In some cases, digital images of textual content are sufficient to satisfy the end user's information needs and provide access to the resource in a form that can be shared on the Web. However, to enable computer-based modes of use – such as for indexing, searching, copying and pasting – the text must be rendered machine-readable. This next stage, the creation of machine-readable text, may involve various capture processes (such as re-keying) but, for large-scale digitization projects, OCR technology is often used. As a digital collection of text becomes bigger, the only efficient way to navigate through it is with search tools supported by good indexing. OCR makes this practicable. Thus, the text capture process adds value to the resource and the user experience; likewise our methods of assessing OCR performance should be oriented to the intellectual and user aims desired from a resource. 3. How OCR worksThe history of OCR can be traced all the way back to 1809 when reading aids to the blind were patented [1]. In reality OCR did not come into its own as a realistic technology until the 1950s when the US Department of Defense created GISMO, a device that could read Morse Code as well as words on a printed page, one character at a time (it only recognized 23 characters). The 1960s saw OCR machines being used in the business world, but the technology was expensive and custom built. The IBM 1975 Optical Page Reader for reading typed earnings reports at the Social Security Administration cost over three million dollars. Once personal computers and high quality scanning equipment became cheap and accessible technologies in the late 1990s, OCR went through a series of changes and improvements to reach the high standards available today. However, OCR technology is still not delivering all the requirements desired for historical document recognition with text being the most disappointing element. IMPACT, an EU project [2], has been established to provide a significant improvement in text recognition and to enhance access to historical texts in mass digitization projects. Alternately, Rose Holley has developed collaborative text correction with the user base for Australian historic newspapers from the National Library of Australia partly in response to the lack of adequate accuracy achieved in their OCR processes [3]. Optical Character Recognition works through analysis of a document image where a scanned digital image that contains machine-printed text is input into an OCR software engine and translated into a machine-readable digital text format. OCR works by first pre-processing the digital page image into its smallest component parts with layout analysis to find text blocks, sentence/line blocks, word blocks and character blocks – a process known as zoning. Other features, such as lines, graphics, photographs, etc., are recognized and may be discarded for the purpose of text recognition. The assignment of zones becomes more challenging as the layout becomes more complex, and correct zoning remains a significant issue for newspaper OCR accuracy.
The word and character blocks are then further broken down into components parts, pattern-recognized and compared to the OCR engine's large dictionary of characters from various fonts and languages. When a likely match is made, this is recorded, and a set of characters in the word block are recognized until all likely characters have been found for the word block. The word is then compared to the OCR engine's dictionary of complete words that exist for that language. These factors of characters and words recognized are the key to OCR performance – by combining them the engine can deliver much higher levels of accuracy. Modern OCR engines extend their performance through sophisticated pre-processing of source digital images and better algorithms for fuzzy matching, sounds-like matching and grammatical measurements to better establish word accuracy. The majority of OCR software suppliers define accuracy in terms of a percentage figure based on the number of correct characters per volume of characters converted. This is very likely to be a misleading figure, as it is normally based upon the OCR engine attempting to convert a perfect laser-printed text of the modernity and quality of, for instance, the printed version of this document. In our experience, gaining character accuracies of greater than 1 in 5,000 characters (99.98%) with fully automated OCR is usually only possible with post-1950's printed text, whilst gaining accuracies of greater than 95% (5 in 100 characters wrong) is more usual for post-1900 and pre-1950's text and anything pre-1900 will be fortunate to exceed 85% accuracy (15 in 100 characters wrong). 4. AccuracyHow helpful though is the above statement on character accuracy when we think about OCR as a tool for adding value to the text resource and the user experience? If our processes should orientate to the intellectual and user aims desired from that resource, then surely our means of measuring success should also be defined by whether those aims are actually achieved? This means we have to escape from the mantra of character accuracy and explore the potential benefits of measuring success in terms of words – and not just any words but those that have more significance for the user searching the resource. When we look at the number of words that are incorrect, rather than the number of characters, the suppliers' accuracy statistics seem a lot less impressive. 4.1 ExampleGiven a newspaper page of 1,000 words with 5,000 characters if the OCR engine yields a result of 90% character accuracy, this equals 500 incorrect characters. However, looked at in word terms this might convert to a maximum of 900 correct words (90% word accuracy) or a minimum of 500 correct words (50% word accuracy), assuming for this example an average word length of 5 characters. The reality is somewhere in between and probably more at the higher extent than the lower. The fact is: character accuracy of itself does not tell us word accuracy nor does it tell us the usefulness of the text output. Depending on the number of "significant words" rendered correctly, the search results could still be almost 100% or near zero with 90% character accuracy. The key consideration for newspaper digitization utilizing OCR is the usefulness of the text output for indexing and retrieval purposes. If it were possible to achieve 90% character accuracy and still get 90% word accuracy, then most search engines utilizing fuzzy logic would get in excess of 98% retrieval rate for straightforward prose text. In these cases the OCR accuracy may be of less interest than the potential retrieval rate for the resource (especially as the user will not usually see the OCRed text to notice it isn't perfect). The potential retrieval rate for a resource depends upon the OCR engine's accuracy with significant words, that is, those content words for which users might be interested in searching, not the very common function words such as "the", "he", "it", etc. In newspapers, significant words including proper names and place names are usually repeated if they are important to the news story. This further improves the chances of retrieval – as there are more opportunities for the OCR engine to correctly capture at least one instance of the repeated word or phrase. This can enable high retrieval rates even for OCR accuracies measuring lower than 90%. So, when we assess the accuracy of OCR output, it is vital we do not focus purely on a statistical measure but also consider the functionality enabled through the OCR's output such as:
5. British Library Case StudyThe 19th Century British Library Newspapers Database [4] is a digital archive of 48 national and regional newspapers from England, Wales, Scotland and Ireland comprising 2 million pages. Complete runs were included wherever possible and titles were selected to enable the comparative treatment of events in the national (London-based), specialist, and regional press. Both full-text and structured searching of the collection is available, and items are presented as both text and page images. The archive is accessible over the Internet via a subscription service, though access is free to UK Higher Education institutions through an agreement with JISC, which funded the digitization. The 19th Century British Library Newspapers Database is cross-searchable with the Burney 17th and 18th Century newspaper collection, which has also been digitized. Together the 19th Century British Library Newspaper Database and the Burney Collection provide chronological coverage from the 1620s through the end of the 19th century for newspapers from a wide geographic area of the UK and Ireland. The British Library (BL) and JISC commissioned Simon Tanner at King's Digital Consultancy Services, King's College London [5], to carry out a study to discover the actual OCR accuracy for the newspaper digitization program. The BL sought to better understand the OCR performance they had achieved in the program to date and use this information to assist their planning, both for search engine optimization across the current resource and to inform future digitization activities. To discover the actual OCR accuracy of the newspaper digitization program at the BL we sampled a significant proportion (roughly 1%) of the total 2 million plus pages looking for:
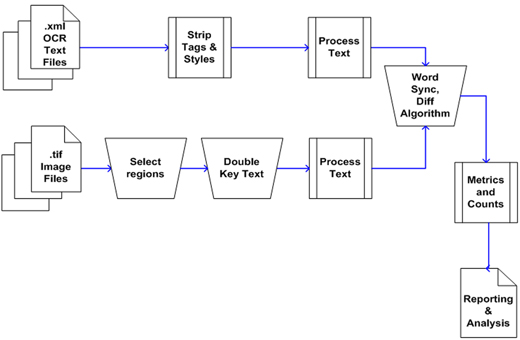
To achieve this, the OCR output for two different zones of each page image was compared using computational techniques against corresponding samples that had been double re-keyed. The work to re-key the data and compute the accuracy in comparison to the OCR output was done by Digital Divide Data [6] under the specification of King's Digital Consultancy Services. The goal was to find the highest OCR accuracy rate, not the lowest, on each page, as this represents the best possible accuracy for that material. This provides a 'high water mark' assessment that tells us that the OCR is unlikely to ever exceed this rate for that newspaper title, and thus the performance impact (e.g., search and retrieval rates) will be equally bounded at an upper limit related to this figure. This provides an assessment of the maximum likely performance, which is highly informative for assessing successful outcomes as defined earlier in this article. However, if we select to find the lowest possible OCR, all we then know is that performance impact will exceed that figure, but we do not know by what extent – a much less useful thing to know. The analysis was based upon the actual XML output supplied to the BL in relation to the original digital images of the newspapers. This means our analysis is not a direct check of the OCR process or engine used. The OCR process utilized may have varied over the period of the digitization, and the supplier of OCR processes may have changed their methodology and or technology over time. Therefore, whilst it will be possible to infer conclusions about the efficacy of the OCR process, it should be emphasized that this analysis is of the OCR outcome as evidenced by the XML file content.5.1 MethodologyTwo zones of the newspaper image were selected manually – one centered in the upper-left quadrant of the page and the other centered in the lower-right quadrant.
Segments were selected on the basis of being amongst the clearest on the page image, with above-average visual quality. Graphic, tabular or list type content was avoided wherever possible. The content of each segment was manually double re-keyed to deliver exactly 100 words from each selection. The accuracy specified for the re-keying was at least 99.98% accurate (1 error in 5,000 characters), although it is worth mentioning that no re-keying errors were found in this study (suggesting 100% accuracy). The consistency of the split re-keyed file with the image given was automatically checked. XML headers and tags were removed from the XML files, and entity tags such as "'" (for apostrophe) were replaced with their corresponding characters, resulting in a list of words, one word per line. All punctuation was removed, as this caused too many false negative results, especially in relation to dashed (-) content. The two regions of each XML text were automatically cut to correspond with the double entry text file. Finally, the two word lists were synchronized to a convenient format for the comparison tool. This created a matrix from each of the texts including both XML output text and double entry text files (approximately 80,000 files). The comparison tool then provided accuracy statistics upon: characters, words, significant words, significant words with a capital letter start and number groups. In comparing the word lists from the pairs of OCRed and double-entry texts, the double-entry text is considered to be the reference text and as such is assumed for the purpose of analysis to be absolute and correct. We assume that the deviation in results due to re-keying errors is unlikely to ever exceed 1-2% anywhere in the study, with deviations having the greatest impact at accuracy rates over 98% (something never seen in the newspaper archive). As we did not find any re-keying errors in the quality assurance process, we can safely assess that the statistics gathered from this process are highly accurate. 5.2 Definitions of terms
5.3 Computational Comparison Techniques
To facilitate the comparison of the XML output and the corresponding re-keyed files we selected DiffTool, an open source technology which uses a modification script to transform one text into another by a sequence of deletions and insertions. The tool then uses post-processing algorithms to chunk the text block in the XML file to correspond with the double entry file, preparing it for further analysis. DiffTool provides a rich set of functions including line-by-line comparison and case ignorance. Furthermore the tool's command-line mode was vital to meeting the requirement of processing many huge files at the same time. The accuracy tool developed for this analysis used The Levenshtein Edit Distance algorithm [7] to compare pairs of words, one from XML text and one from the double-entry text, to find the number of different characters between the two strings. The Levenshtein Edit Distance algorithm measures the distance between two sequences or strings in terms of the number of deletions, insertions, or substitutions required to transform one string into another. The greater the distance, the more different the strings are. A further post-processing algorithm was used after applying the Levenshtein Edit Distance algorithm in order to meet the accuracy requirements specified for the study in terms of punctuation accuracy, the ignoring of extra noise characters at the end of OCRed word, etc. The result of the comparison program is in plain text format where each record is represented line by line. This simple output structure allows flexibility to export into different formats, such as Excel, Access or a statistical package such as SPSS, depending on the particular needs of a project. Using these computational analysis techniques based on open source software and algorithms it is now possible to practically assess true OCR accuracy, even for mass digitization projects. 5.4 Outputs from the processFor the BL study the results from the comparison activity were expressed in Excel spreadsheets for each newspaper title with the following headings: Source newspaper information
Re-keyed content statistics and the XML content statistics
Accuracy statistics (correct and incorrect numbers)
For the BL newspaper program this provided more than 400,000 data points for comparison and analysis. The main mode of expression used was to find the average accuracy statistics as a percentage for each newspaper title broken down by year of publication. This information could then be built into other statistical models to express an overall average per collection or an expression of accuracy across time. 6. FindingsThe result of our analysis is a very deep and extensive dataset for comparison of OCR accuracy arranged by newspaper publication title and date. Having this data allows us to develop a fine-grained assessment of OCR performance that is relevant to the intellectual goals and user experience objectives of the BL newspaper program. The overall averages for the 19th Century Newspaper Project are:
The overall averages for the Burney Collection are:
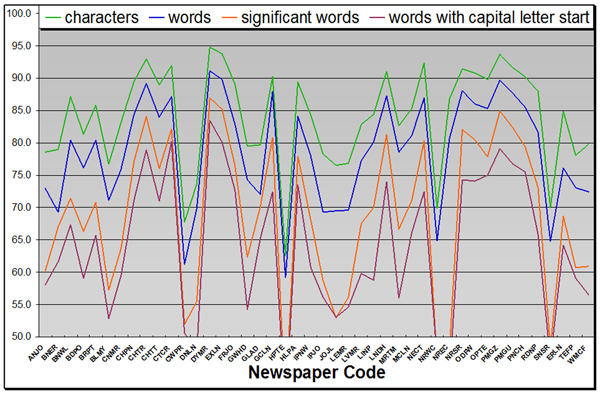
(Note: from this point on the statistics will refer purely to the 19th Century Newspaper Project content.) As Figure 4 shows, the character accuracy is naturally always higher than the word accuracy. What proves interesting is that the significant word accuracy is always less than the word accuracy (by an average of ~10%), and the capital letter start word accuracy is always less than the significant word accuracy (by an average of ~5%).
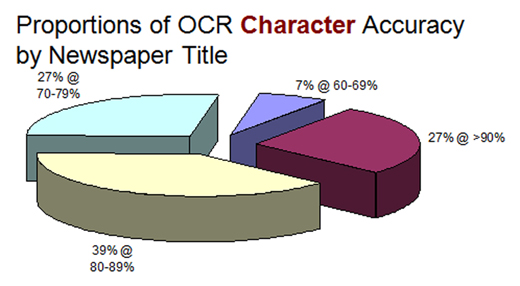
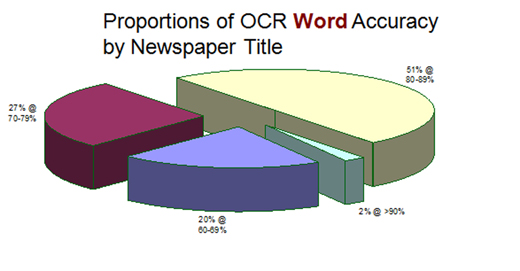
This demonstrates that significant words are generally harder to OCR accurately. This may be due to such words being generally longer or not in dictionaries, which thus provides more statistical opportunity for error. Where the content relates to names or place names as seen in significant words with capital letter start, then the rate of accuracy is always less than that for significant words. This again demonstrates that proper nouns, names and place names are harder for OCR engines to cope with. Where the publication content consists of large amounts of names and places - such as for lists of traders, births and deaths listings – then this can increase the apparent error rate for those newspaper titles. 6.1 Usefulness and functionality assessment of the OCR outputIn terms of the usefulness and functionality of OCR output it is clear that the higher the accuracy available the more useful and functional the content can be made. These results clearly show that 2/3 of the newspaper titles have an average character accuracy above 80% accuracy. However, 1/2 have the same for word accuracy and only a mere 1/4 have greater than 80% significant word accuracy.
What this means to the end user experience is clear – the lower the significant word accuracy the lower the likely search result accuracy or volume of search result returns. Our experience suggests that should the word accuracy be greater than 80%, then most fuzzy search engines will be able to sufficiently fill in the gaps or find related words such that a high search accuracy (>95-98%) would still be possible from newspaper content because of repeated significant words. At below 80% word accuracy, the search capacity will drop off steeply as the word accuracy drops. Thus, the BL's Burney Collection loses a lot of search capacity because the long 's' character reduces word accuracy to such a low point that searching can become very difficult. For the BL's 19th Century Newspaper Project these results help to focus attention on which titles and date ranges require the highest amount of attention to potentially improve search performance. Considering that the average word accuracy across the whole 19th Century Newspaper Project is 78% with the significant word accuracy at 68.4% then it is clear that searching the resource will not be as satisfactory for the end user as might be desired. It is also inescapable that this is due to a combination of two major factors: the OCR process itself and the content+physical quality of the newspapers. 7. ConclusionsAutomated recognition technologies have been a key driver of large-scale text digitization by lowering costs, increasing search capabilities and delivering higher volumes of content than could be conceived with manual transcription. Optical Character Recognition (OCR) is often treated as a panacea for cheap, effective searching of large text resources. However, both creators and users understand the limitations of OCR and the difficulties in gaining a true sense of the performance or accuracy of a search system when dealing with the inherently inaccurate text provided by automated technologies. Without solid statistical data on OCR accuracy, project leaders cannot appropriately decide how to optimize their OCR process, what other tools to use and what level of effort and cost to expend on text correction. Measuring OCR accuracy in terms of word and significant word accuracy focuses attention upon the performance indicators most relevant to the usefulness of the OCR output for functions like searching and indexing. The methodology, statistical data and analysis developed here are the means for making better OCR decisions because they directly relate OCR performance to the goal of adding value to the text resource and the user experience. Having this data allows us not simply to assess how well text capture processes are performing but to improve them. The method developed here for historical newspaper materials could be applied to other kinds of documents and has many applications. We think the benefits that could accrue from using the model described in this article would be to provide actionable information for mass digitization projects that would deliver:
Due to the amount of work required to re-key and analyze a significant sample for OCR assessment, we feel that a service model is the most effective way to provide projects with actionable OCR accuracy data. King's Digital Consultancy Services in partnership with Digital Divide Data is able to offer a service to assess the true statistical accuracy of OCR for digitization projects in any Latin font or European language. Our consultative service will use these accuracy results to give our partners actionable information to use to select content, optimize OCR processes, improve search performance, design delivery systems and reduce the costs for the project. 8. References[1] Schantz, Herbert F. The History of OCR, Optical Character Recognition. Manchester Center, Vt.: Recognition Technologies Users Association, 1982. [2] IMPACT project. <http://www.impact-project.eu/>. [3] Holley, Rose. "How Good Can It Get?: Analysing and Improving OCR Accuracy in Large Scale Historic Newspaper Digitisation Programs." D-Lib Magazine. March/April 2009, vol. 15 no 3/4. <doi:10.1045/march2009-holley>. [4] 19th Century British Library Newspapers Database. <http://www.bl.uk/reshelp/findhelprestype/news/newspdigproj/database/index.html>. [5] King's Digital Consultancy Services (KDCS) provides research and consulting services. Specializing in the information and digital domains our services are used by cultural, heritage and information professionals along with corporate clients. This venture is led by its Director, Simon Tanner, and is based within the Centre for Computing in the Humanities (CCH) at King's College London. <http://www.digitalconsultancy.net>. [6] Digital Divide Data (DDD) bridges the divide that separates young people from opportunity by providing disadvantaged youth in Cambodia and Laos with the education and training they need to deliver world-class, competitively priced IT services to global clients and acquire essential business management skills. <http://www.digitaldividedata.org>. [7] A demonstration of the Levenshtein Edit Distance algorithm can be found at: <http://www.merriampark.com/ld.htm>. Copyright © 2009 Simon Tanner, Trevor Muñoz and Pich Hemy Ros |
|||||||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/july2009-munoz
|