![]()
D-Lib Magazine
July/August 2000
Volume 6 Number 7/8
ISSN 1082-9873
Virginia Dons FEDORA
A Prototype for a Digital Object Repository
Thornton Staples
Digital Library Research and Development
University of Virginia
[email protected]
Ross Wayland
Digital Library Research and Development
University of Virginia
[email protected]
Introduction
The University of Virginia Library began developing a collection of digital resources in 1992 by setting up an electronic text center, soon followed by a digital image center. By 1998 there were four centers that had amassed a large collection that include a variety of SGML encoded etexts, digital still images, video and audio files, and social science and geographic data sets that were being served to the public from a collection of independent web sites that have very little cross-integration. After shopping for a digital library system unsuccessfully, in 1999 we created a digital library research and development group and set about creating the system that we need.
We have assumed from the beginning that we need a system that can serve large research library that will soon have millions of digital resources of all media and content types. We assume that we will continue to create and, increasingly, that we will buy access to digital resources. We also are hoping that the library community will increasingly find ways to collaborate on building digital collections, and we assume that we need a system that is prepared to interoperate with other digital library systems.
We also are being faced already with collecting digital scholarly projects that include digital facsimiles of objects in all media, as well as increasingly including born-digital resources in a variety of media. The Institute for Advanced Technology in the Humanities (IATH) here at Virginia has supported the creation of over forty such projects in all areas of the humanities, most of which have been supported by the Library's digital centers. In late 1999, IATH and the Library were awarded a grant by the Mellon Foundation to work out both the policy and technical issues involved in collecting these scholarly projects. Much of the activity of that project will center around building a digital library system that is capable of supporting scholarly research projects as they are created and then being able to collect and preserve them.
In general, we believe that the system described in the Making of America II white paper [1] provides the basic conceptual structure that is required for the kind of digital library that we need. It describes digital resources as data objects that include the resource plus metadata about the resource and software methods that give the resource behaviors, all in one conceptual package. We have been actively collaborating with the Digital Library Research Group at Cornell University to use their Flexible Extensible Digital Object Repository Architecture (FEDORA) [2] to implement the system that realizes those concepts.
2 The Architecture
We were attracted to FEDORA for several reasons. First, the definition that it gives for creating a digital object as a package of internally stored files and/or references to remote files ensures that we have many options for handling the variety of digital resources that we already have on hand, and to be ready for new types of resources that may come. Second, the elegant system of organizing computer scripts and programs, and attaching them to the objects in a very modular and flexible way, allows us to develop a set of intelligent, adaptable resources. Last, but certainly not least, is that FEDORA's designers made the interoperability of digital object repositories a basic design assumption that suffuses the entire protocol. [3] Though our efforts to this point have not included any work with interoperability, we believe that operating within these rules from the beginning will position us to adapt to whatever larger environment ultimately evolves around us.
2.1 The Data Object Model
The FEDORA protocol defines the digital object as a set of "datastreams", each of which can be either a file stored under the control of the repository system or a pointer to a file that is stored outside of it. From here on in this paper, the term "object" will refer to the complete package that includes the resource (hereafter known as the "basis"), the metadata needed to understand and use the object, and references to the software that creates actions or "disseminations" that are "methods" of the object. Note that each object in the repository will have a unique, persistent identifier that identifies it without respect to its physical location and that identifies the digital object as a whole. It is the repository system's job to resolve the id.
The basis is one or more datastreams that are (or are references to) the resource that is the main purpose of the object. A simple object is defined as one which has a basis which consists of a single datastream that contains no referential pointers to other objects within its content. An example of a simple object would be one for which the basis is a single JPEG image. The basis of a compound object contains more than one datastream, possibly having a GIF thumbnail image stored as a datastream within the object, and a JPEG and a TIFF image that are each stored as a datastream containing a pointer to a file that sits on a remote system. A complex object has a basis that contains references to other objects, such as an electronic text that is a transcription of a book that contains references to images of the pages of the original book.
Our objects have three metadata packages, each of which exists as a single datastream. The administrative metadata package contains information about the existence of the object, its access restrictions and the history of the basis as well as of each of the other datastreams. The technical metadata package contains media-specific information about the creation and internal structure of the basis. The descriptive metadata package contains information that describes the content of the basis of the object. A descriptive metadata datastream can include a very detailed description of the content or it can be a set of references to any number of other objects that are each capable of disseminating a descriptive metadata record for the basis. Note that our current implementation only handles descriptive metadata; the definitions of the other two types are still under development.
One of the most interesting and powerful facilities that FEDORA specifies is a special type of component called a "disseminator". A disseminator is the data structure that pairs a particular set of behaviors to a corresponding set of abstract methods, as will be described in more detail in the next section. An object can have multiple disseminators.
2.2 Object Behaviors
FEDORA provides two constructs that are used to confer behaviors on digital objects: signatures, which define sets of methods as abstract behaviors, and servlets, which provide corresponding actions for each of the methods in the signature. In a particular repository there can be many servlets for a particular signature. Each object that subscribes to a signature has a disseminator that identifies both that signature and a related servlet that is specific to that object. There is always a one-to-one correspondence between a method in a signature that defines a behavior and a method in a servlet which defines the action that the object will carry out to deliver that behavior when called upon.
A signature is essentially a template that provides a name for a method, a description of it and names and descriptions for any of the parameters required by that method. Ideally, a user could discover a signature from a list of the signatures included in a particular object's set of disseminators and be able to use it to get all of the information necessary to use the object in a particular way. A servlet is a computer program that can accept a method name as an input parameter and deliver a corresponding action for a specific object.
For example, we could define a signature called "web_book" that includes all of the methods that one would need to use it as a book on a web browser, such as get_table_of_contents, get_chapter, and get_page_image. An XML-encoded TEI-conformant etext would have a servlet that used the XML markup appropriately to deliver the methods. Another XML-encoded etext that was marked up using the rules of a different DTD would have another servlet that would interpret a different markup scheme to deliver the same methods.
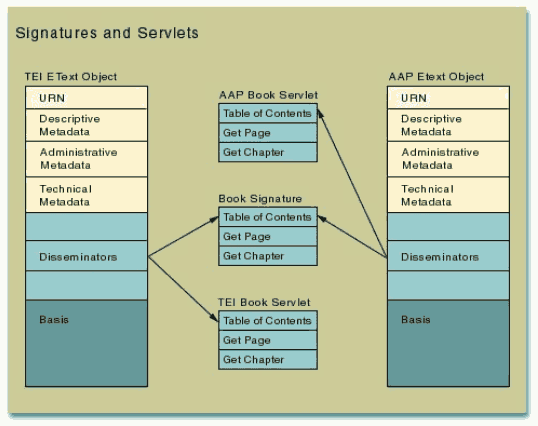
Figure 1. Signature/servlet relationship.
In our work so far we have only implemented one signature per object. Each of these has been designed to deliver a set of methods that provides each object with general user-oriented web site behaviors. The use of signatures becomes much more interesting when you start adding more of them. Multiple signatures allow for an object to have different sets of methods for different purposes or for the same set of purposes for a different audience. For example, an "open-E-book" signature could be added to etext transcriptions of novels, encoded archival finding aids and code books for numeric datasets to allow each of these texts to be downloaded to a hand-held reading device. Or different versions of the same methods could be provided for academic researchers and high-school students.All objects will subscribe to signatures that provide basic system functions for the object and to provide more generic uses of them. An "administration" signature that contains methods that provide the object with all of the necessary behaviors to manage and track it, will be applied to every object. These will include methods to disseminate each of the types of metadata, describe access restrictions for the object, update the object, etc.
An interesting signature that we have just started to think about is "web_default". This would be used to provide every object that is available to be used on the web with a minimum set of behaviors that could be assumed by a process that knew nothing about the object. One possibility is to have two methods, "get-resource", which would provide the action for the resource to completely take over the browser window, and "get_resource_in_context" which would be some minimal use method. For example, the first method could provide a large digital image with an applet that allowed it to be zoomed in on, the second could provide the image as a thumbnail that could be used in a predetermined context. Such a signature would be very useful when providing search results from a discovery search that returned hits of many different media. A mode where the user chooses one hit at time might use the first method, one where the user could choose multiple hits to be displayed simultaneously could use the second.
2.3 The Rest of the Story
We assume that a complete digital library system will require repository services that use the digital objects described above. Currently, we are providing user access to our testbed through a resource discovery service (i.e., our catalog of all digital resources) as a system that is completely external to the FEDORA objects. We index all of the descriptive metadata records as XML data and search them from a web page. Clicking on one of the hits returned by the search causes an appropriate FEDORA dissemination of the associated object. Most of the intelligence of this service is built into the system software, with a specific dissemination of each object encoded in the metadata. When we implement the web_default signature (described above), it will free the service from having to know anything about the media- or content-types of the resources it is providing access to. The metadata will only have to provide the persistent ID of the object, the user interface will request one of the two web_default methods for display, as appropriate to the context.
We will also be providing specialized external index-and-search services for discrete collections within the repository, such as for collections of electronic transcriptions of literature, numeric dataset codebooks, architectural image collections, etc. In each of these cases a more specialized service is desired that provides the same kinds of functions as the resource discovery service, but indexes on the full XML texts.
The other major part of system that we have begun developing is the management service. It will provide us with a way to add and delete batches of objects, as well as to update each of the datastreams in an object. It is already apparent that these processes imply that there are collections of objects that need to be managed in the same ways. For example, when we install a batch of electronic finding aids, they all have the same set of disseminators and their descriptive metadata records are systematically derived from their content in the same way. And when we need to add five new finding aids to the existing collection, we would like to be able to tell the repository to add the new batch in the same way that earlier batches were done.
3. Implementation
Because of the object-oriented nature of the FEDORA architecture, a database management system that was object oriented and also XML-savvy would be the ideal choice for implementing the repository. However, we were unable to find an existing database management system with all the XML features we required and with licensing/pricing to fit within our constraints. We chose instead to implement the system using a relational database to store the object representations and a java servlet to provide a web-based communication interface to the repository. We chose the MySQL relational database management system because of its widespread acceptance in the user web community, its ease of use, its "academic friendly" licensing, and its robustness in handling very large tables.
3.1 The Environment
Our current prototype is running on a single processor SUN Ultra 10 workstation for research and testing. The implementation environment consists of the following components:
Hardware
- SUN Ultra 10 with a single 440MHz. processor and one gigabyte of memory (http://www.sun.com)
Software
- Operating System - SUN Solaris 2.7 (http://www.sun.com)
- Web server - Apache 1.3.9 (http://www.apache.org)
- Java Servlet engine - Apache Jserv 1.1 servlet engine (http://java.apache.org)
- Java Development Kit - build Solaris_JDK_1.2.2_05 (http://java.sun.com)
- Java Servlet Development Kit - JSDK 2.0 (http://java.sun.com)
- SQL Database - MySQL 3.22.32 (http://www.mysql.com)
- XSL engine - SAXON 5.3.2 (http://users.iclway.co.uk/mhkay/saxon/index.html)
- XML parser - Apaches Xerces-J 1.1.0 (http://xml.apache.org)
The XSL engine and XML parser are required for our work with XML documents and XSL stylesheets but are not required for our implementation of the FEDORA architecture.
3.2 Repository Communication Protocol
We wanted a communication protocol that was familiar to our web designers that did not require any knowledge of the underlying relational database table structure. Making requests from the repository should only require a knowledge of an objects primitive FEDORA components such as the object identifier (URN), signature name, and method name. We chose to use a java servlet using JDBC to process the SQL queries with the underlying relational database. We chose to use a java servlet instead of a java applet because we wanted the bulk of the processing to be handled on the server-side, rather than at the client, and for performance reasons.
Repository requests are encoded as URLs which invoke the java servlet with a number of parameters specifying the type of request to be made. The syntax of the encoded URLs consist of the path to the java servlet executable followed by a question mark (?) and one or more argument keyword/value pairs (e.g., keyword=value) separated by an ampersand (&). The argument keyword named "action" defines the type of communication request and is required on every request. The value of the action keyword then determines the number of additional arguments (if any) that are required to complete the request.
Currently, only three action types are available. We plan to expand the types of requests to include a full range of functions that enable an end user to easily ascertain information about any FEDORA primitive component including object, signature, disseminator, method, and datastream.
For example:
http://dl.lib.virginia.edu/servlets/ObjectServlet? <action-type> [ & <argument> ]
<action-type> (required)
action =
list - list all objects in the repository; requires no additional arguments
select - list all behaviors of a given object; requires the following additional argument: doid = <URN of object>
dissem - execute a specific behavior of a given object; requires the following additional arguments: doid , sigName , methName , parmName , and parmValue
<argument> (optional/required depending on action type)
doid = <URN of object>
sigName = <signature name>
methName = <method name>
parmName = <method parameter name> [ + <method parameter name> ]
parmValue = <method parameter value> [ + <method parameter value> ]
Consider for example an object with a URN of 1007.lib.dl.test/text_ead/viu00003 which subscribes to a signature named "web_ead". The method named "get_web_default" which requires no additional parameters is the method used to disseminate this objects default web behavior. To invoke a dissemination that produces the default web behavior for this object, the encoded URL would appear as:
To execute the dissemination, the java servlet parses the incoming URL to extract the various arguments and then issues the appropriate SQL query to the repository database using JDBC to extract the desired information. In the case of a dissemination request, the SQL query returns the value of the "Action" column in the Servlet table and the names of the objects associated datastreams. The java servlet then assembles the outgoing URL based on the action and associated datastreams and redirects the servlets output stream to the newly assembled URL. Currently, an action is limited to being in the form of an HTTP request (i.e., the action could be an HTTP GET, HTTP POST, call another java servlet , call a perl cgi script, etc.).
In the example above the "Action" returned from the database looks like:
http://dl.lib.virginia.edu/cgi-dl/eaddoc.pl?file=<datastream
The java servlet replaces <datastream> with the appropriate datastream of the object based on the results of the SQL query and then executes the fully formed URL. If the action executable had additional parameters other than the location of the datastream, these would be passed as method parameters and appended to the outgoing URL. In this example, there are no additional parameters required by the perl script name eaddoc.pl.
3.3 Relational Database FEDORA Model
The goal of the relational database implementation of FEDORA was to preserve the FEDORA object model without sacrificing performance in the relational model. The current implementation consists of 10 relational tables that comprise the repository. The first five tables (URN_ID, SIG_ID, DISS_ID, DS_ID, and METHOD_ID) are simple lookup tables that enforce referential integrity by providing a unique numeric identifier for each primitive FEDORA component including object name, signature name, disseminator name, datastream name, and method name. Given a name for any of these primary components, you can determine its associated numeric identifier that is used as an index into the other tables.
|
URN_ID table |
||||
|
Column Name |
Type |
Indexed |
Unique |
Description |
|
URN_ID |
INT |
Primary |
Yes |
URN numeric ID |
|
URN_name |
VARCHAR(200) |
Yes |
Yes |
URN name |
|
SIG_ID table |
||||
|
Column Name |
Type |
Indexed |
Unique |
Description |
|
SIG_ID |
INT |
Primary |
Yes |
Signature numeric ID |
|
SIG_name |
VARCHAR(50) |
Yes |
Yes |
Signature name |
|
DISS_ID table |
||||
|
Column Name |
Type |
Indexed |
Unique |
Description |
|
DISS_ID |
INT |
Primary |
Yes |
Disseminator numeric ID |
|
SIG_ID |
INT |
Yes |
No |
Signature numeric ID |
|
DISS_name |
VARCHAR(50) |
Yes |
Yes |
Disseminator name |
|
METHOD_ID table |
||||
|
Column Name |
Type |
Indexed |
Unique |
Description |
|
METHOD_ID |
INT |
Primary |
Yes |
Method numeric ID |
|
METHOD_name |
VARCHAR(50) |
Yes |
Yes |
Method name |
|
DS_ID table |
||||
|
Column Name |
Type |
Indexed |
Unique |
Description |
|
DS_ID |
INT |
Primary |
Yes |
Datastream numeric ID |
|
DS_name |
VARCHAR(50) |
Yes |
Yes |
Datastream name |
The SIG table defines each signature, its associated methods, and a high-level description of each method. Given a signature name , you can find all of the methods available to that signature. This table is relatively small with a maximum size defined by the number of signatures times the maximum number of methods per signature.
|
SIG table |
||||
|
Column Name |
Type |
Indexed |
Unique |
Description |
|
SIG_ID |
INT |
Yes |
No |
Signature numeric ID |
|
METHOD_ID |
INT |
Yes |
No |
Method numeric ID |
|
METHOD_DESC |
VARCHAR(200) |
No |
No |
High level description of method |
The DISS table uniquely defines each disseminator given the urn name, signature name, and disseminator name. This is one of the three larger tables in the database whose size is determined by the number of objects (O) times the maximum number of signatures (S) for each object. The maximum number of signatures per object is anticipated to be relatively small (currently less than 5). If the maximum number of signatures is allowed to grow large it could have adverse effects on performance.
|
DISS table |
||||
|
Column Name |
Type |
Indexed |
Unique |
Description |
|
URN_ID |
INT |
Yes |
No |
URN numeric ID |
|
SIG_ID |
INT |
Yes |
No |
Signature numeric ID |
|
DISS_ID |
INT |
Yes |
No |
Disseminator numeric ID |
The SERVLET table provides the pairing between a disseminator and its signature/servlet pair. In our implementation, the column called "Action" in the SERVLET table represents this executable chunk of code in the form of an HTTP request. Given a signature name, disseminator name and a method name one can determine the action (the program that implements the method) to be performed, the return type of the method, and a description of the methods implementation. The method description in the SERVLET table describes how this particular method is implemented. The size of this table is bound by the number of signatures times the maximum number of disseminators for each signature times the maximum number of methods for each signature, all of which should be relatively small numbers (e.g., less than 20).
|
SERVLET table |
||||
|
Column Name |
Type |
Index |
Unique |
Description |
|
SIG_ID |
INT |
Yes |
No |
Signature numeric ID |
|
DISS_ID |
INT |
Yes |
No |
Disseminator numeric ID |
|
METHOD_ID |
INT |
Yes |
No |
Method numeric ID |
|
DS_ID |
INT |
Yes |
No |
Datastream numeric ID |
|
ACTION |
TINYTEXT |
No |
No |
Pointer to program implementing this method |
|
TYPE |
VARCHAR(20) |
No |
No |
Return type of action |
|
METHOD_DESC |
VARCHAR(200) |
No |
No |
Method description |
The PARM table defines any parameters that are required by a given method and provides a description of the parameter and how it is used. The primary purpose of the description fields in this and other tables is to provide descriptive information that can be used by an end user to assist in selecting an appropriate behavior. The size of this table is bounded by the number of methods times the maximum number of parameters per method.
|
PARM table |
||||
|
Column Name |
Type |
Indexed |
Unique |
Description |
|
METHOD_ID |
INT |
Yes |
No |
Method numeric ID |
|
PARM_NAME |
VARCHAR(50) |
No |
No |
Parameter name |
|
PARM_VALUE |
VARCHAR(50) |
No |
No |
Parameter value |
|
PARM_DESC |
VARCHAR(200) |
No |
No |
Parameter description; possible values, etc. |
The DS table defines the mapping between an object and its associated datastreams. This table is one of the three larger tables. Its size is bound by the number of objects (O) times the maximum number of datastreams (D) per object. The number of datastreams per object is anticipated to be small (less than 5). If the number of datastreams per object is allowed to grow large, it could impact performance. Typically, most objects will have only a single datastream. An example of an object with multiple datastreams is an image object where one might have multiple datastreams representing different sizes and/or resolutions of the same image. All of these datastreams are part of the single image object but would exist as separate datastreams associated with that object.
|
DS table |
||||
|
Column Name |
Type |
Indexed |
Unique |
Description |
|
URN_ID |
INT |
Yes |
No |
URN numeric ID |
|
DS_ID |
INT |
Yes |
No |
Datastream numeric ID |
|
URL |
VARCHAR(200) |
Yes |
No |
URL of datastream |
The relationship between the various tables is shown in figure 2.
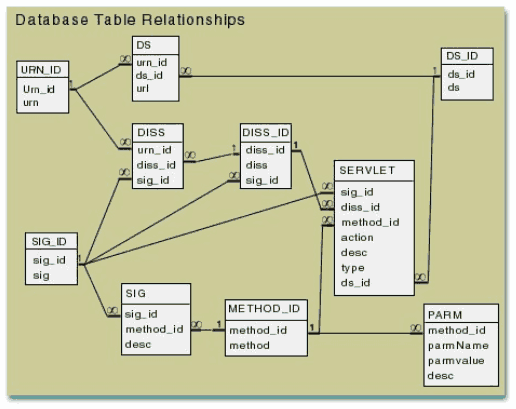
Figure 2. Database Table Relationships.
The size of a digital repository is governed primarily by the number of objects included. With the exception of the URN_ID, DISS, and DS tables, the other table sizes are independent of the total number of objects in the repository so those table sizes are relatively small. The URN_ID table has a maximum size determined by the number of objects (O) and the Disseminator and Datastream tables are bound by a small multiple (currently 5) of the total number of objects. One obvious concern was performance in doing table joins on large tables as the number of objects grew large. We conducted a crude benchmark by loading a million dummy objects into the tables and found that performance with table sizes of a million rows in the three larger tables did not show any significant degradation in performance. The benchmark did not test concurrent user load nor did it test the effect of what happens when the number of signatures per object or number of datastreams per object becomes large (i.e., much greater than 5). Further testing will be needed to determine the upper limit at which performance may begin to seriously degrade, but we are confident that this implementation will allow us to include all of the digital objects that we now have on hand. This should give us a sufficient testbed to determine the feasibility of investing the resources needed to implement this architecture for a collection of millions of digital objects
Next Steps
The power of the FEDORA approach centers around packing as much intelligence into the data objects as possible, freeing up the repository services to be generic and configurable. Certainly, with the collection of intelligent data objects that we have already developed, we are at a point where we can begin to think about building robust services that will enable us to use them as they are. However, the power of representing more complex resources as data objects, making more intelligence available to the services as data objects rather than building it in ahead of time, appears to present tantalizing possibilities.
In the next stage of work on our repository services, we plan to investigate developing them around collection objects. As described above, a complex object is one in which the basis contains references to other objects. Complex objects are inherently collection objects, providing structural metadata that makes sense of a set of digital objects from a particular point of view. For example, an etext transcription of a book that has embedded references to 200 page images of the original printed book, provides structural metadata about a collection of 200 digital images; likewise for an electronic archival finding aid that contains references to images. We have also begun experimenting with an XML DTD that is designed to provide structural metadata for collections of art, architecture and archeology images by creating what are, in effect, textual models of artworks, buildings and sites. We are also hoping that such structural metadata objects can be used to create a formal structure for the scholarly projects created by IATH; almost all of them are currently organized at the highest level by HTML pages on a web site.
Collection objects are parent objects capable of disseminating behaviors for, and descriptive metadata about, the child objects. Because we assume that child objects will, in many cases, have multiple parent objects, we believe that it is very useful to think about making the disseminators on the children as generic as possible and relying on the parents to use them appropriately. We are also experimenting with relying on the parent objects to supply the descriptive metadata for a child; the child only needs to carry a reference to the parent. We believe that this scheme will allow images, for example, to be discovered from many different points of view and will allow a user who has discovered an image from one point of view to discover the other views (and other methods of use) by investigating the image object. In particular, the many page images of texts that we have would not need to carry metadata about the books they came from and any of them would be open to be easily used in other contexts. For example, if our special collections department had one of Thomas Jefferson's diaries that happened to have the first sketch of Monticello on one of the pages, that page image would be a child object for an electronic finding aid, an etext transcription and a descriptive model of Monticello. Each of these contexts would be free to use the image in a different way and to precisely describe it in that context. A user who found the page by searching a collection of colonial American texts and reading the diary, could then discover a complex representation of Jefferson's home.
This explicit approach to collection objects seems to be best used for relatively small collections and collections where the resources are associated in a specific, intentional way, as in the scholarly projects created at IATH. For objects that represent large collections and collections where new members are continuing to be added systematically, as in the case of the index-and-search and management services, an implicit approach seems to be required. In this approach, the basis of the collection object would not carry explicit references to each of its child objects; the children of each collection would explicitly carry the references. The basis of the collection object itself would only have to describe the content and general structure of the collection as a whole. The signatures to which these objects subscribe would enable the collections to create indices, disseminate appropriate query pages, carry out batch management processes, etc. We have already begun to work with the explicit collection objects, but the implicit approach is just now in the brainstorming stage, both at Virginia and with our collaborators at Cornell. We expect to spend much of the next year evaluating both approaches to see just how generic and modular our repository services can be.
Acknowledgements
We would like to thank Carl Lagoze, Sandy Payette and Naomi Dushay at Cornell University and Christophe Blanchi at CNRI for working with us to get this far. They have given us lots of their time, both explaining FEDORA and in conversations about implementation design. We would especially like to thank them for being willing to risk their relative peace as researchers to work closely with people trying to implement their ideas in a library setting.
References
[1] Bernard J. Hurley, John Price-Wilkin, Merrilee Proffitt, Howard Besser , The Making of America II Testbed Project: A Digital Library Service Model. Council on Library and Information Resources Reports; ISBN 1-887334-72-6. <http://www.clir.org/pubs/abstract/pub87abst.html>
[2] S. Payette and C. Lagoze, "Flexible and Extensible Digital Object and Repository Architecture (FEDORA)," presented at Second European Conference on Research and Advanced Technology for Digital Libraries, Heraklion, Crete, 1998. <http://www2.cs.cornell.edu/payette/papers/ECDL98/FEDORA.html>
[3] S. Payette, C. Blanchi, C. Lagoze, and E. Overly, "Interoperability for Digital Objects and Repositories: The Cornell/CNRI Experiments," D-Lib Magazine, May1999. <http://www.dlib.org/dlib/may99/payette/05payette.html>
Copyright © 2000 Thornton Staples and Ross Wayland
Search | Author Index | Title Index | Monthly Issues
Previous story | Next Story
Home | E-mail the Editor
D-Lib Magazine Access Terms and Conditions
DOI: 10.1045/july2000-staples