D-Lib Magazine
January/February 2015
Volume 21, Number 1/2
Table of Contents
Challenges in Matching Dataset Citation Strings to Datasets in Social Science
Brigitte Mathiak and Katarina Boland
GESIS — Leibniz Institute for the Social Sciences, Germany
{brigitte.mathiak, katarina.boland}@gesis.org
DOI: 10.1045/january2015-mathiak
Printer-friendly Version
Abstract
Finding dataset citations in scientific publications to gain information on the usage of research data is an important step to increase visibility of data and to give datasets more weight in the scientific community. Unlike publication impact, which is readily measured by citation counts, dataset citation remains a great unknown. In recent work, we introduced an algorithm to find dataset citations in full text documents automatically, but, in fact, this is just half the road to travel. Once the citation string has been found, it has to be matched to the correct DOI. This is more complicated than it sounds. In social science, survey datasets are typically recorded in a much more fine-granular way than they are cited, differentiating between years, versions, samples, modes of the interview, countries, even questionnaire variants. At the same time, the actual citation strings typically ignore these details. This poses a number of challenges to the matching of citations strings to datasets. In this paper, we discuss these challenges in more detail and present our ideas on how to solve them using an ontology for research datasets.
1 Introduction
Many scientific disciplines, including the social sciences, rely on research data as basis for or validation of their findings. Research data can be results of measurements, survey data, archeological discoveries and many more [1]. Awareness of the significance of high-quality data has been increasing during recent years and the creation of research data is being more and more valued as a scientific achievement in itself. To ensure reproducibility of research, researchers must reveal their sources, including research data. By assigning Persistent Identifiers (PID) to datasets, they become identifiable and citable. Registration agencies handle the infrastructure of keeping metadata and data available under the permanent, citable link represented by the PID. Moreover, using PIDs enables persistent links between resources, e.g. between scientific datasets and literature. These links can be used for analyzing usage and impact of datasets and as added-value in information systems. Since these are important goals, we seek to identify data citations, even when the PID of a dataset is not given by the author in the citation.
In social science, the most prominent sort of research data is survey data. Surveys are typically conducted by asking questions to a carefully selected sample of people. Depending on the so-called mode of the survey, these questions are asked in personal interviews, by sending a questionnaire, by conducting a telephone interview, etc. Just as diverse are the sampling methods that identify the people these questions are asked to.
For methodological reasons, surveys are often repeated in regular intervals or waves (e.g. once a year). For each question asked, there is one or more variables that capture the answer in a code. The resulting dataset resembles a rectangular table, with the columns as the variables and the respondents in the rows.
Before publishing, some decisions concerning the composition or granularity of the datasets have to be made. Data from several waves may be aggregated and published as a single dataset. Yet, individual waves may just as well be published separately. A dataset may or may not contain all questions originally asked, may or may not be integrated with other results, e.g. statistical information or other surveys. In short, it contains a carefully chosen set of data points. The metadata gives those data points meaning.
PIDs are assigned at a high level of granularity because using different datasets can influence the observed findings. For example, it was shown that interview modes can influence the answers participants give [2]. Thus, it can be important that the data obtained by using different interview modes can be identified and individually cited. However, researchers tend to think of datasets on a coarser level of granularity: typically the level of a study being conducted at a specific point in time.
In the DDI-standard, a study is defined as a single coordinated set of data collection/capture activities. Strictly speaking, the survey data is a result of a survey that is part of a study, but in practice both terms are often used interchangeably. Conceptually, the study contains all the necessary information, the dataset is merely a view of this. Many studies publish more than one dataset for a variety of reasons. Whenever researchers omit information on the specific dataset used and instead only specify the study from which the data was taken, creating a link from a data citation string to a dataset becomes challenging.
We observed that large-scale studies tend to publish many datasets and also get cited very often. And so, while many small studies only publish one dataset, the problem of choosing the correct dataset from a given study affects a large number of the citations.
2 Registration and Citation of Research Data
2.1 Registration Infrastructure
DataCite provides an organizational network for the registration agencies that are assigning persistent identifiers in the form of Digital Object Identifiers (DOI). Being one of these agencies, da|ra is running a DOI service for social and economic research data since 2010. da|ra has since assigned DOI names to over 400.000 objects. The core collection is made up by about 30.000 elaborately documented datasets from the fields of social science and economics that are archived and distributed by significant infrastructure institutions such as GESIS or the ICPSR. The documentation of each DOI-registered dataset is included in the da|ra database and thus retrievable through the da|ra metadata search.
In addition to solving technical issues for the data collecting institutions, registering datasets at registration agencies such as da|ra also renders the data much more visible and more easily accessible through standardized interfaces. Also, metadata creation is facilitated as existing metadata schemas can be used to describe the data.
2.2 Heterogeneity in Registered Datasets
Since a large number of datasets from different data publishers and data creators are registered and they are heterogeneous in many different aspects, differences in how data is registered are to be expected. When investigating registered studies in da|ra, we notice that the granularity indeed is quite heterogeneous.
For example, the German General Social Survey ALLBUS registers three DOI per conducted survey in each year to capture different modes of data collection: one DOI for data collected using paper assisted personal interviews ("PAPI"), one for data collected using computer-assisted personal interviews ("CAPI") and one for both sets integrated. Adding to that are a number of cumulative datasets spanning more years and integrating additional information, bringing the total count of DOI registered with ALLBUS to 143 (4.5 per year).1
In contrast, the SOEP, which is somewhat similar in size, make-up and importance, registers only cumulative datasets with overlapping time frames (each dataset containing all previously collected data plus the data of the current wave). Thus, data from the SOEP survey in the year 2000 is featured in to date no less than 8 different standard datasets. This completely different publication scheme results in only 27 registered datasets (1.1 per year). For citation matching, however, the differences in systematic pose more difficulties than any differences in quantity, as we will see later on.
This phenomenon is not limited to German studies. The ICPSR, which registers mainly American studies and study series, shows a similar pattern. CBS News polls are distinguished by month, year and collaborators, while the British Election Study datasets are registered per election event and differentiated by sampling method (cross-section vs. panel). Integrated sets are offered as well.
The selected examples are just the tip of the iceberg and make reality appear more orderly than it actually is. Simple browsing in any sizable data archive database reveals many, many more diverse publication strategies.
So, where do these differences come from? The choice of registration is not completely arbitrary and registration agencies do urge their customers to be sensible with what they register and don't register. Many of the differences can be accounted for by actual differences in the studies. Longitudinal studies, e.g. those that repeat themselves every year, usually publish about as often as they go into the field. Whether they decide to publish a dataset that covers the new time period only or one that is integrated with the last dataset, is completely up to them. Other reasons to publish new datasets include: different confidentiality levels prompting different requirements for dissemination, errors requiring new corrected versions and external factors demanding theme-oriented publishing or integration with other datasets.
2.3 Data citation in Social Science
Datasets are, to some degree, arbitrarily thrown together facts, which could, in theory, be combined in many other ways without losing their inherent value. So, other than citing registered datasets with PIDs, there is no simple and standardized way to describe data unambiguously. There are some initiatives in social science to remedy this problem. The IASSIST has a Data Citation Special Interest Group. Also, the international Initiative Research Data Alliance (RDA) recently established a working group on data citation (Data Citation WG) that seeks to develop prototypes and reference implementations for efficient data citation. So far, the observed citations mostly do not conform to the suggestions these groups have made.
As illustrated in [3], a typical data citation string includes a study name and a few further identifying details, typically the time frame of the survey. In contrast to literature citations, other metadata, such as publisher, author or publishing dates, are rarely mentioned. This behavior is somewhat intuitive as this description focuses on the conceptual data rather than on the actual dataset that was used. Similarly, the study name and time frame typically feature prominently as part of the title chosen by data publishers as a self-description. So, researchers and data publishers use the same general strategy when describing the data. Unfortunately, other metadata is relevant as well when trying to make exact matches, e.g. the version of a dataset is almost never mentioned in the citation even when different versions of the dataset indeed exist. While data publishers add this information in the metadata for the dataset, if not in the title, the information is typically missing in the data citation string. As a result, data citations are often underspecified allowing identification of the survey but not of the precise dataset.

Figure 1: Example for a non-simple matching. Without further information, it is impossible to determine the correct match.
3 Consequences for Data Citation String Matching
So far, we have looked into the characteristics of both data citation strings and datasets. We have observed that data citation strings are often underspecified because vital information is missing, but also that granularity and systematics of data publishing greatly vary between different data publishers.
This leads to the problem that even when matching manually, a correct 1:1 matching is not always possible. For example, the reference "ALLBUS 2000" cannot be matched to a single dataset since there is information missing on the interview mode (cf. fig. 1) and the version. The reference "SOEP 2000" cannot be matched to a single dataset either, because the SOEP data is published as aggregated datasets consisting of surveys of many different years.
In total, we identified five different matching scenarios as illustrated in table 1:
| Relation / Scenario |
Example: Cited Dataset |
Example: Registered Dataset |
Description |
| 1) partOf (superset) |
<study> 2000 |
<study> 1984-2009 |
The data citation only refers to a part of a larger dataset. The registered datasets feature additional data. |
| 2) partOf (subset) |
<study> 2000-2001 |
<study> 2000; <study> 2001 |
The data citation refers to data that is only covered by combining one or more datasets. |
| 3) underspecified |
<study> 2000 |
<study> 2000 version 1.0;
<study> 2000 version 2.0 |
The data citation is underspecified, one (or more) of the registered datasets was used but it is unclear which one(s). |
| 4) mixed |
<study> 2000-2001 CAPI |
<study> 2000 CAPI version 1.0;
<study> 2000 CAPI version 2.0;
<study> 2001 CAPI |
Combinations of relations. |
| 5) sameAs |
<study> 2000 |
<study> 2000 |
Cited dataset corresponds to registered dataset. |
Table 1: Examples of different matching scenarios.
The ideal of simply linking to the correct entity one-on-one can only be achieved in scenario five. Real-life examples from large-scale studies, however, tend towards scenario four. A strategy for handling these cases is needed. In the next subsection, we investigate what the requirements on the links are in different use cases and which strategies may be employed to satisfy them.
3.1 Requirements on Data Citation Links
We identified three basic use cases for data citation links. First, literature information systems that link to cited datasets. Second, dataset information systems that link to citing literature. Third, the analysis of citation structure, e.g. bibliometric analysis or other citation statistics.
In the first use case, we would like to have a list of linked dataset titles that are referenced in the paper currently in detail view. This list should not be too long and not too redundant. This forbids a "greedy" strategy of simply showing all similar datasets including supersets, subsets and underspecified candidates. In the example of "ALLBUS" being cited without further specifications, this would give us 143 links, one link for each dataset registered. Showing only a "best" match would be preferable, but what is "best" is not easy to decide for all cases. In scenario 1, we might choose the smallest dataset containing the data, interpreting "best" as most similar. We could choose the newest version, and when no heuristics of that kind exist, choose randomly. However, this may lead users to conclude that the displayed dataset is more relevant than all the others, which might not be true.
In the second use case, the data information system, we would like to have a reference list of publications citing this dataset. Looking at the list for a specific PAPI dataset, users would probably conclude that the references include only publications referring to PAPI specifically. Unfortunately, with both strategies established so far ("greedy" and "best"), this is not guaranteed. In fact, it is not even likely in our example, given that the general likelihood that a paper is dealing with these methodological questions is quite low. A new strategy to solve that problem would be "exact-only", allowing only exact matches (scenario 5). However, given that many data citations are underspecified that leaves us with little information to display.
Besides, we cannot know whether a user really is interested in PAPI-related work. In a similar situation, a user looking at an older version of a dataset may be surprised to not find any links at all, which is very likely with the "best" strategy. In fact, this may or may not be helpful. Since there is no research on user expectations in such a situation, it is unclear what users expect at this point exactly. One of the projected goals of having publications displayed with the data is to indicate the quality of the dataset. So, how many links are displayed is a sensitive, possibly even political issue and requires careful thought.
This brings us to the third use case: citation analysis. Links resulting from scenarios 2 and 5 do not pose any problems, but all other links are difficult to interpret. "Greedy" strategy dramatically increases citation counts for large-scale studies with overlapping datasets such as SOEP. "Best" strategy gives only one link per citation, but depending on the definition of "best" skews the citation distribution within datasets from the same study series. "Exact-only" strategy over-represents small studies with just one dataset.
One way to overcome these problems in theory is to link to complete studies instead of individual datasets. Every time a dataset is cited, the citation count of the corresponding survey would increase regardless of the specific variant used.
While this disallows data centers to estimate the popularity of different variants of their datasets, this strategy would allow researchers to perform sensible citation analysis for comparing different studies. Practically, however, this strategy requires knowledge on the memberships of datasets to specific surveys and this knowledge is currently not encoded in the metadata.
Another issue not addressed so far is that researchers sometimes cite organizations providing data instead of mentioning the name of the dataset in which the data is published. This is often the case for ministerial data such as data from a federal statistics agency or for large and well-known organizations such as the OECD. Especially in the latter case, such references are not very helpful for finding the correct dataset as the amount of published data and different datasets is enormous even when a year is given. In principle, it would be possible to generate links to all datasets that were registered by the cited organizations. But as the amount is large and it is not guaranteed that the cited data is even registered as one of the candidate datasets, the usefulness of such links can be doubted. Thus, it might be sensible to not link these citations to any datasets. This poses a new problem for an automatic matching: the algorithm must be able to distinguish dataset names from organization names to be able to treat both citation types differently. In any case, by ignoring information about organizations, valuable information is lost.
From this analysis, we can conclude that none of the proposed simple strategies fit all of the use cases. While they may be optimized to work in specific applications, a more general solution, like the one presented next, is preferable.
4 Solving the Heterogeneity Challenge
The heterogeneity challenge presented in the last section is a general problem not only applying to data citation string matching. Similar problems arise when trying to rank results from general queries on datasets, when trying to index datasets with keywords or even when computing download statistics. The solutions presented next are designed to improve performance in all these cases.
4.1 General Concept
Prior to the actual citation string matching, more information on how the registered datasets are related to each other is needed to construct a suitable ontology. Using this information, a representation can be derived which enables a precise description of how a citation string relates to a dataset.
Many registered datasets, e.g. from the ALLBUS survey, exhibit partOf-relationships. A small fraction of the resulting hierarchy is illustrated in Figure 2.
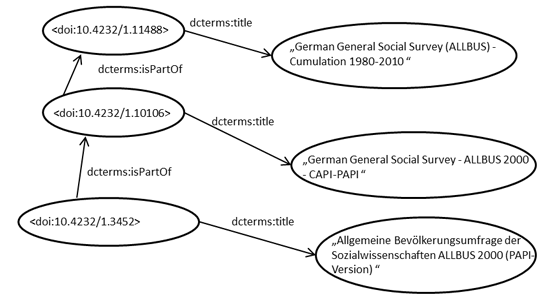
Figure 2: Hierarchy within some of the 137 ALLBUS datasets. Many relations, such as rdf:type are omitted in the illustration.
The PAPI dataset of 2010 is partOf the integrated dataset of 2010, which is itself partOf the integrated dataset from 1980 to 2012. There is also a compact version with a reduced variable set (again partOf). In fact, the da|ra metadata scheme [4] already contains the element relation, which allows to specify relations to other datasets. The controlled list of relation types is based on the DataCite standard. Currently, the relation element is not much in use. For one, it is not a mandatory field in da|ra, thus publication agents are not required to specify relations if there are any. Secondly, the functionality is not being used for retrieval and navigation functionalities yet.
While the relations that are currently included in the vocabulary are certainly useful, for our purposes it would be better to have more sub-classes of partOf to allow us to be even more specific. It is easy to see that reducing variables, reducing the time frame or choosing a mode are different operations. So far, only versions, continuation and compilation have their own dedicated relationships. Similar work was done in the Europeana context [5] and for other vocabularies.
The key to being able to link citations of individual surveys to cumulatively published datasets, such as for SOEP in scenario 1, is creating anonymous study objects that do not exist outside of a theoretical description. In this case, the SOEP 84-07 would have a partOf relationship to an abstract SOEP 2006 dataset as depicted in Figure 3.
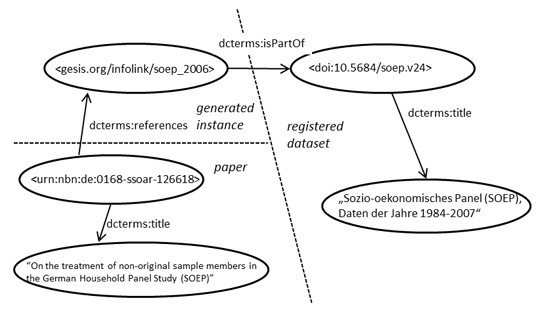
Figure 3: The instance in the left upper corner is the generated abstract SOEP 2006, which directly relates to the citation string in the publication (here just represented by URN and title). Connection to the actually registered dataset on the right side is made by isPartOf.
In a similar manner, we can derive an abstract ALLBUS study to which all ALLBUS datasets have a direct or indirect relationship. This entity can be linked when there is no information on year, mode or used variables, i.e. in scenario 3 when links are underspecified. All abstract entities, be they manually established dataset series or algorithmically deducted, may have a generated landing page displaying their relationships to existing registered entities. Representing all entities as actual instances instead of using blank nodes also enables reasoning on the data. Thus, for every link to an entity indirect links can be inferred to all entities in a direct or indirect relation. Using partOf relations, links of scenario 1 and 2 can be obtained. Likewise, tentative links to all possible variants of abstract entities can be inferred using the suitable relations to obtain links of scenario 3.
Different applications can choose how to use the different links. Bibliometric research can redefine any kind of abstract studies to reflect citation realities. There is a great number of options when displaying the citation links with the registered studies by carefully adjusting the reasoning behind them. Even the organizations can be appropriately handled.
4.2 Strategies for Finding the Links
Using the aforementioned ontology, the task for matching now has two parts: First, the relationships between the datasets have to be established, and second, the citations have to be matched to the new set of dataset entities.
Relationships between datasets can be established manually. Since doing so for legacy data is time-consuming, however, several heuristics can be applied to facilitate the task by incorporating automated methods. The registered studies have detailed and high-quality metadata on time and should therefore be matchable quite easily. The same holds for modes and geography. Inclusion and exclusion of variables are more difficult, but potential candidates can be identified by comparing variable counts if information on variable-level is available. Study series can be identified by term clustering and by the agent that delivered the study. Study names already identified in data citations, e.g. by application of the reference extraction algorithm in [3], can be used as a feature as well.
The second part, matching citation strings to datasets, is a standard entity linking problem and can be tackled using standard fuzzy string matching. However, it becomes somewhat easier as there are now new virtual entities available to link. These require less information which especially facilitates the matching of underspecified citations. Also, through deriving information on studies from datasets, we gain an authoritative list of study names that can be assumed to be better suited for string-based matching of titles. This is because they will contain only information that is common for all corresponding datasets filtering all information specific to different variants. As researchers tend to omit specific information of variants in their citations as well, this should lead to a reduction of noise for string matching. Furthermore, establishing the relationships between datasets gives clues on the properties a citation should be searched for.
5 Related Work
Most works on citation matching [6, 7] concentrate on literature citations and metadata which are highly structured compared to data citations. Thus, the proposed methods cannot be directly applied to data citation matching.
[3] introduce an approach for automated extraction of dataset references in Social Science. While this is a necessary first step for linking publications and datasets, the linking of references to dataset records needs to be accomplished in a further step.
Recent attempts to map named entities to large knowledge bases, such as Wikipedia [8] or IMDB [9], address a similar problem but lack the specific challenges outlined in this paper.
Disregarding the natural language and rather defining the problem as matching strings to digital objects leads to the field record linking or duplicate record detection [10]. These methods concentrate on either string mutation heuristics, such as compensating for spelling mistakes or matching by comparing auxiliary information on the object, e.g. attribute values. Both methods are valuable for the problem per se, but are not covered in this paper, which concentrates on structural heterogeneity.
6 Discussion
Structural heterogeneity of research datasets and citations is not uniform across scientific disciplines. In particular, Biology stands out allowing very structured references to digital data objects, supported by an emphasis on data publication in databases rather than datasets, which enforces much higher standardization. Thus, data citations can be extracted from full texts with very high precision [11]. It would seem that this is the exception, rather than the rule. Reports from Geophysics [12] and Psychology [13] indicate that the problem is wide-spread. In [14], it is observed that data citation standards themselves are both widely heterogeneous and not conformed to in the majority of publications studied. Although the sample used is small, it covers many disciplines including Humanities and other fields of science.
Connecting datasets and publications by data citations is an important step for making research more reproducible and transparent [15]. Although there are some attempts with manual and self-reported collections, we lack a large-scale infrastructure to make empirically sound judgments on data use, value for retrieval and re-use. In this paper, we propose a way to close the final gaps towards such an infrastructure by making the relations between datasets explicit using a standardized vocabulary in order to allow linking to correct entities.
This would not only facilitate a sensible presentation of links to users inside of various information systems and would increase the usefulness of links for bibliometric citation analysis, but would also be beneficial for a wide variety of tasks not making direct use of links between publications and research data. For example, the retrieval of datasets can be improved when knowledge about the relations of datasets can be incorporated into the retrieval process.
For the next development phase of the da|ra service it is planned to systematically establish links between related studies, based on the relation element that is already provided in the da|ra metadata scheme. That way, all studies or waves of one collection or different versions of one study can be retrieved, navigated and displayed according to their respective relationship. This has to be done retrospectively for the already existing corpus of studies, but also as a standard routine for newly added records.
In conjunction with the InFoLiS II project (InFoLiS II is funded by the DFG (MA 5334/1-2)), automatic methods for deriving relations between da|ra datasets retrospectively will be implemented and evaluated. Additionally, we will extend our previous efforts in linking research data and publications automatically using the enriched hierarchical dataset metadata. All results shall be made publicly available during the course of InFoLiS II to be used by researchers in the social sciences and other scientific fields.
Acknowledgements
This work is funded by the DFG (SU 647/2-1). We would like to thank our InFoLiS partners as well as Johann Schaible, Tanja Friedrich and the da|ra team for providing valuable insights of their work and for adding useful feedback and information to this paper.
Notes
1 All numbers as of July 2014.
References
[1] DFG (2013). "Sicherung guter wissenschaftlicher Praxis — Safeguarding Good Scientific Practice." Memorandum. Wiley-VCH, Weinheim. ISBN 978-3-527-33703-3.
[2] Leeuw, E.D., J. Hox, and G. Snijkers. (1998). "The effect of computer-assisted interviewing on data quality. A review." In Blyth, B. Market Research and Information Technology. ESOMAR Monogaph. pp. 173—198. ISBN 92-831-1281-4.
[3] Boland, Katarina, Dominique Ritze, Kai Eckert, and Brigitte Mathiak. "Identifying references to datasets in publications." In Theory and Practice of Digital Libraries, pp. 150-161. Springer Berlin Heidelberg, 2012. http://doi.org/10.1007/978-3-642-33290-6_17
[4] Brigitte Hausstein, Natalija Schleinstein, Ute Koch, Jana Meichsner, Kerstin Becker, and Lena-Luise Stahn. "da|ra Metadata Schema" GESIS-Technical Reports 2014|07 (2014) p. 30-31. http://doi.org/10.4232/10.mdsxsd.3.0 http://doi.org/10.4232/10.mdsxsd.3.0
[5] Wickett, Karen M., Antoine Isaac, M. Doerr, Katrina Fenlon, Carlo Meghini, and Carole L. Palmer. "Representing Cultural Collections in Digital Aggregation and Exchange Environments." D-Lib Magazine 20, no. 5 (2014): 2. http://doi.org/10.1045/may2014-wickett
[6] Pasula, Hanna, Bhaskara Marthi, Brian Milch, Stuart Russell, and Ilya Shpitser. "Identity uncertainty and citation matching." In Advances in neural information processing systems, pp. 1401—1408. 2002.
[7] Lawrence, Steve, C. Lee Giles, and Kurt Bollacker. "Digital libraries and autonomous citation indexing." Computer 32.6 (1999): 67—71. http://dx.doi.org/10.1109/2.769447
[8] Milne, David, and Ian H. Witten. "Learning to link with wikipedia." Proceedings of the 17th ACM conference on Information and knowledge management. ACM, 2008. http://doi.org/10.1145/1458082.1458150
[9] Drenner, Sara, Max Harper, Dan Frankowski, John Riedl, and Loren Terveen. "Insert movie reference here: a system to bridge conversation and item-oriented web sites." In Proceedings of the SIGCHI conference on Human Factors in computing systems, pp. 951—954. ACM, 2006. http://dx.doi.org/10.1145/1124772.1124914
[10] Elmagarmid, Ahmed K., Panagiotis G. Ipeirotis, and Vassilios S. Verykios. "Duplicate record detection: A survey." Knowledge and Data Engineering, IEEE Transactions, 19.1 (2007): 1—16. http://doi.org/10.1109/TKDE.2007.9 http://dx.doi.org/10.1109/TKDE.2007.250581
[11] Kafkas Ş, Kim J. H., and J.R. McEntyre. Database citation in full text biomedical articles. PLoS One. 2013;8(5) e63184. http://doi.org/10.1371/journal.pone.0063184. PubMed PMID: 23734176; PubMed Central PMCID: PMC3667078.
[12] Parsons, Mark A., Ruth Duerr, and Jean-Bernard Minster. "Data citation and peer review." Eos, Transactions American Geophysical Union 91.34 (2010): 297-298. http://doi.org/10.1029/2010EO340001
[13] Sieber, Joan E., and Bruce E. Trumbo. "(Not) giving credit where credit is due: Citation of data sets." Science and Engineering Ethics 1.1 (1995): 11—20. http://doi.org/10.1007/BF02628694
[14] Mooney, H., and M.P. Newton. "The Anatomy of a Data Citation: Discovery, Reuse, and Credit". Journal of Librarianship and Scholarly Communication 1(1) (2012). http://dx.doi.org/10.7710/2162-3309.1035
[15] Piwowar, Heather A., and Todd J. Vision. "Data reuse and the open data citation advantage." PeerJ 1 (2013): e175. http://doi.org/10.7717/peerj.175
About the Authors
 |
Brigitte Mathiak holds a PhD in Computer Science on the topic of Layout Analysis in Biomedical Literature. Dr. Mathiak works currently at GESIS — Leibniz Institute for the Social Sciences as a team leader where she is supervising, among many other projects, the InFoLiS project.
|
 |
Katarina Boland earned her Magister degree in Computational Linguistics, Psychology and Computer Science at Heidelberg University in Germany. Since then, she has been working on the InFoLiS Project at GESIS — Leibniz Institute for the Social Sciences as PhD Student. Her research is focused on finding and interpreting data citations in scientific literature using natural language processing techniques.
|
|