 |
T A B L E O F C O N T E N T S
J A N U A R Y / F E B R U A R Y 2 0 1 4
Volume 20, Number 1/2
doi:10.1045/january2014-contents
ISSN: 1082-9873
E D I T O R I A L S
Special Issue on the Research Data Alliance
Editorial by Laurence Lannom, Corporation for National Research Initiatives
Building Global Infrastructure for Data Sharing and Exchange Through the Research Data Alliance
Guest Editorial by Fran Berman, Rensselaer Polytechnic Institute; Ross Wilkinson, Australian National Data Service; John Wood, The Association of Commonwealth Universities
A R T I C L E S
Synthesis of Working Group and Interest Group Activity One Year into the Research Data Alliance
Article by Beth Plale, Indiana University
Abstract: The Research Data Alliance (RDA) uses Working Groups and Interest Groups to carry out its work. Groups form when a concerned community develops around a topic for which there are well defined issues, common goals, and an opportunity to create a framework for timely action. One year in, RDA has 26 Working Groups and Interest Groups whose activities are focused on overcoming barriers to successful research data sharing, publishing, referencing and archiving, and on developing the infrastructure necessary to support those tasks.
Data Type Registries: A Research Data Alliance Working Group
Article by Daan Broeder, Max Planck Institute for Psycholinguistics; Laurence Lannom, Corporation for National Research Initiatives
Abstract: Automated processing of large amounts of scientific data, especially across domains, requires that the data can be selected and parsed without human intervention. Precise characterization of that data, as in typing, is needed once the processing goes beyond the realm of domain specific or local research group assumptions. The Research Data Alliance (RDA) Data Type Registries Working Group (DTR-WG) was assembled to address this issue through the creation of a Data Type Registry methodology, data model, and prototype. The WG was approved by the RDA Council during March of 2013 and will complete its work in mid-2014, in between the third and fourth RDA Plenaries.
Improving Access to Recorded Language Data
Article by Simon Musgrave, Monash University, Australian National Corpus
Abstract: This article discusses the work of the Research Data Alliance (RDA) Language Codes Working Group, which is addressing the problem of how scientists can discover data from various research areas that is managed by different disciplinary approaches and standards. The WG is addressing standardisation of metadata elements in two areas: codes for identification of languages and language varieties, and categories for describing the content of resources. The goal is to deliver metadata components that can be used by archives across disciplines which address these two areas, using descriptors linked to a registry of data categories to ensure transparency and consistency and lead to improved discovery and access for researchers across disciplines.
Opening and Linking Agricultural Research Data
Article by Esther Dzalé Yeumo Kaboré, French National Institute for Agricultural Research; Devika Madalli, Indian Statistical Institute; Johannes Keizer, Food and Agriculture Office of the United Nations
Abstract: A Research Data Alliance (RDA) Interest Group has formed around a community of scientists and researchers who wish to make agricultural data, information, and knowledge more accessible. The objective of the Agricultural Data Interest Group is to get together active representatives of the major international institutions that work on agricultural research and innovation worldwide, in order to address issues related to data that are important to the development of global agriculture. The Interest Group is moving toward this goal by advancing the formation of a Wheat Data Interoperability Working Group that will address diverse data problems of 'wheat data' and, within a time period of 18 months, provide a framework for wheat data interoperability. The framework will foster the adoption of common standards and vocabularies for wheat data management, and facilitate access, discovery, reuse, and integration of that data.
Organizational Status of RDA
Article by Mark A. Parsons, Rensselaer Polytechnic Institute
Abstract: The Research Data Alliance is an agile, adaptive, community-driven organization that is growing rapidly. More than one thousand members from around the world have come together to develop Interest and Working Groups dedicated to improving data exchange. Members meet twice each year at formal RDA Plenaries and in more informal regional workshops. A senior Council provides strategic direction and an elected Technical Advisory Board ensures technical viability, applicability, and balance. RDA is also building an organizational membership. The full RDA structure will be in place by March 2014, only one year after the launch.
C O N F E R E N C E R E P O R T S
Data Identification and Citation — The Key to Unlocking the Promise of Data Sharing and Reuse
Conference Report by Adam Farquhar, British Library and DataCite; Jan Brase, DataCite
Abstract: The Fourth DataCite Annual Meeting was held jointly with CODATA and co-located with the Research Data Alliance (RDA) Second Plenary, 19-20 September, 2013. DataCite is an international organisation whose mission is to make research better by enabling researchers to find, share, reuse, and cite data. It engages researchers, scholars, data centers, libraries, publishers, and funders through advocacy, guidance and services. The 2013 annual conference attracted nearly 200 attendees from around the world. This report describes the important discussion topics, and recent accomplishments and findings highlighted at the meeting, and also introduces some important remaining challenges.
Big Humanities Data Workshop at IEEE Big Data 2013
Conference Report by Tobias Blanke, Göttingen Centre for Digital Humanities, Department of Digital Humanities, Kings College London; Mark Hedges, King's College London; Richard Marciano, University of North Carolina at Chapel Hill
Abstract: The "Big Humanities Data" workshop took place on October 8, 2013 at the 2013 IEEE International Conference on Big Data (IEEE BigData 2013), in Santa Clara, California. This was a day-long workshop featuring 17 papers and a closing panel on the future of big data in the humanities. A diverse community of humanists and technologists, spanning academia, research centers, supercomputer centers, corporations, citizen groups, and cultural institutes gathered around the theme of "big data" in the humanities, arts and culture, and the challenges and possibilities that such increased scale brings for scholarship in these areas. The use of computational methods in the humanities is growing rapidly, driven both by the increasing quantities of born-digital primary sources (such as emails, social media) and by the large-scale digitisation of libraries and archival material, and this has resulted in a range of interesting applications and case studies.
N E W S & E V E N T S
In Brief: Short Items of Current Awareness
In the News: Recent Press Releases and Announcements
Clips & Pointers: Documents, Deadlines, Calls for Participation
Meetings, Conferences, Workshops: Calendar of Activities Associated with Digital Libraries Research and Technologies
|
|
F E A T U R E D D I G I T A L
C O L L E C T I O N
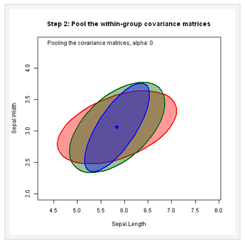
This animated series of plots illustrate the essential ideas behind the computation of hypothesis tests in a one-way MANOVA design and how these are represented by Hypothesis - Error (HE) plots.
[Copyright Michael Friendly. Used with permission.]
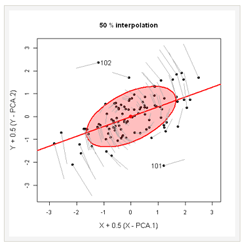
This demonstration illustrates why multivariate outliers might not be apparent in univariate views, but become readily apparent on the smallest principal component.
[Copyright Michael Friendly. Used with permission.]
The DataVis.ca web site is the creation of Michael Friendly, Professor of Psychology, Chair of the graduate program in Quantitative Methods at York University, and Associate Coordinator with the Statistical Consulting Service. The Gallery of Data Visualization site displays some examples of the Best and Worst of Statistical Graphics, with the view that the contrast may be useful, inform current practice, and provide some pointers to both historical and current work.
The Gallery webpages are organized as a collection of images, along with a few of the 1000 words each may be worth and some links to original sources. There are over 160 images, categorized under the following headings:
- Laurels (Best): Historical Milestones; Bright Ideas; Graphical Excellence; Visual Explanation; Visual Delights
- Darts (Worst): The Lie Factor; Goosed-Up Graphics; Missed Opportunities; Context: Compared to What?; Have Something to Say; Evil Pies
- Other topics: Related links, Timelines; Re-Visions of Charles Joseph Minard; Statistical Animations
In addition to the Gallery, also available at Dr. Friendly's datavis website are:
- Milestone Project: a comprehensive, visual compendium of significant events in the histories of data visualization, statistical graphics and thematic cartography. This part of the site features an interactive timeline, with links to the details, images and references for events and a zoomable map showing the birth places of milestones authors. At present, the Milestones Project documents nearly 300 contributions, with 350 references, and 770 media items including 370 online images and 400 hyperlinks to documents and images hosted externally.
- Books: A list of links to Dr. Friendly's books on data visualization and statistical graphics, as well as other related books of interest.
- Courses & Short Courses: links to short courses taught by Dr. Friendly that contain online materials.
- Online Papers: Links to online papers and presentations. These include published papers, technical reports, slides from presentations and links to other related materials.
- R Software: This page provides brief descriptions of R packages related to Dr. Friendly's work on data visualization and the history of statistical graphics.
- SAS Software: These pages provide access to a large collection of SAS macros, SAS/IML programs, data sets and other materials developed in relation to Dr. Friendly's books, papers and courses, and made available through this site.
D - L I B E D I T O R I A L S T A F F
Laurence Lannom, Editor-in-Chief
Allison Powell, Associate Editor
Catherine Rey, Managing Editor
Bonita Wilson, Contributing Editor
|