![]()
D-Lib Magazine
January 2000
Volume 6 Number 1
ISSN 1082-9873
On DigiPaper and the Dissemination of Electronic Documents
Xerox PARC
[email protected]
Angela Moll
Cornell University
[email protected]
Abstract
Encoding electronic documents involves a tradeoff between maximizing the ease of dissemination and preserving the document appearance. For instance, a simple text file is the most easily and universally disseminated form of document, but it preserves none of the appearance. This paper proposes a new image-based document representation, called DigiPaper, which is designed to easily disseminate electronic documents with a guaranteed appearance, thus eliminating the tradeoff. DigiPaper provides fixed appearance by representing documents in image form, but uses new compression techniques to make the file size comparable to formats such as Word, PowerPoint or PDF. DigiPaper compression is based on two technologies, the Mixed Raster Content (MRC) color image model and token-compression. DigiPaper files are much smaller than current image formats used for scanning, achieving about a factor of 7 improvement in compression over TIFF Group 4 compressed images.
Electronic documents have forever changed the ways in which we share information, primarily due to the ease with which they can be disseminated compared to physical documents. Electronic documents can be more widely and cheaply disseminated because they can be transmitted across networks, replicated virtually for free, and accessed simultaneously by multiple users. Thus, as a medium for the dissemination of information, electronic documents are considerably more powerful than physical media such as paper.
Certain underlying assumptions that aid in the dissemination of electronic documents limit their usefulness, however. One such assumption is that the information in a document is carried primarily by its textual content, at the expense of the information carried by other elements such as layout and design. For instance, markup languages such as SGML and HTML focus on the textual content and make the specification of most layout, font, and other design content secondary. While this assumption is most evident in HTML, it is reflected to some degree in every electronic document representation, including "layout based" representations such as PostScript and PDF.
Because it is assumed that a document can be successfully transmitted by distributing its text, electronic documents have an intrinsic malleability in their rendering. This is manifested in common features which allow networked documents to be displayed on a multitude of platforms, such as the ability to make a font substitution when the specified font is not available or to adapt the aspect ratio of a document to that of the monitor or browser window. The most malleable (least fixed) form of a document is simple ASCII text, which specifies no information about appearance. A highly malleable document format is preferable when a document is to be presented in highly different ways, such as color versus monochrome, or on very different devices, such as a Palm Pilot and a photographic printer. In these situations, breadth of dissemination is privileged over appearance, and a malleable format that preserves text content over appearance is greatly advantageous.
While document malleability increases the potential for dissemination of the textual content, it limits the potential for dissemination of design and layout information, which are often very important in conveying information. The world of printed-paper documents has a centuries-long tradition of valuing document presentation for the information that it carries and for its communicative effect. Print publications have traditionally used the graphic elements of documents as an important aid in conveying meaning. Fonts, layout, and graphics appeal to our senses, reinforcing the connotations and emotional response the document tries to elicit. The physical characteristics of the medium allow the designer to determine to a large extent the visual experience of the reader. Graphic design has an increasing presence in todays business documents (e.g., annual reports, brochures, and product catalogs), making company literature more appealing and easier to understand for the reader.
Many authors and designers moving to the digital medium have been unwilling to abandon the practice of controlling document appearance. Despite the difficulties entailed in precisely encoding the layout of a page in HTML, the majority of well-designed web sites go to great lengths to control the page seen by the reader to the finest detail. They often use elements of HTML such as tables and images in ways not originally intended. In the minds of the designers of these web sites, the value of document appearance clearly outweighs the advantages of the malleable electronic document. Extensions to HTML such as Cascading Style Sheets (CSS) are intended to extend the ability of the designer to fix the appearance of the document. However, these extensions still do not provide the kind of control over appearance that is afforded by paper documents. Furthermore, for a malleable form of document, the document creator does not really know how the document will look, and cannot control the documents visual impact on the reader. By neglecting document presentation, the electronic document risks losing this valuable avenue of expression.
In this paper, we argue that there is an important role for electronic documents with a guaranteed fixed appearance that can be controlled by the document creator, much as with paper documents. Today, the need for networked documents with a fixed appearance is met by one of two methods. The first method is using a standardized page description language (PDL), such as Postscript or PDF. This approach has the advantages that Postscript and PDF are widely used, they are relatively compact (e.g., compared to image formats such as TIFF), and they encode much of the document structure. Nevertheless, the disadvantages of this method are substantial. To varying degrees, PDLs are not sufficiently standardized and require considerable processing power to display. Moreover, in practice they cannot guarantee the document appearance. Standard PDF and PostScript files are rendered differently on each device. This is sometimes imperceptible, but many users encounter documents they cannot view or print, or that appear in a distorted manner, especially when the correct fonts are not available.
A few niche markets, such as publishing, use digital images of a document as a means of addressing the need for a fixed electronic form of the document. Digital images provide guaranteed appearance: the placement of text and graphic art is fixed, fonts are not an issue, and text, art, and photographs can be mixed at will. In addition, the document can be viewed or printed without requiring the application that generated it (such as MS Word or PowerPoint), nor requiring a PDL renderer such as Adobe Acrobat or a Postscript viewer. This solution of transmitting electronic documents using an image representation has become standard in communities such as publishing and digital archiving. Publishers send books to press as TIFF images (often embedded in PostScript), thus avoiding problems caused by the lack of appropriate fonts in the printer. In digital archival repositories, the current practice is to use TIFF files with CCITT Group 4 compression as a preservation format. However, digital document images have one main drawback that prevents them from being used more widely: they tend to be very large. Consequently, they use a lot of storage and transmit too slowly for the majority of users. Their use is only cost effective in very specific cases where storage and bandwidth considerations are not an issue.
This paper proposes a new image-based document representation, DigiPaper,1 to encode efficiently document appearance and maintain the high dissemination potential characteristic of the electronic medium. DigiPaper provides guaranteed appearance, relies to a minimum on the environment in which it is rendered (e.g., does not require particular fonts or the application that created the document), and thus is readable by a varied audience. It eliminates the tradeoff between maximizing dissemination and preserving document appearance that today faces the creator of electronic documents. DigiPaper is designed to meet the need for a fixed electronic form of a document, while keeping file sizes small. It can be used successfully both with scanned and electronic source documents. Electronic source documents include those rendered to page images from page description languages such as Postscript (so called RIPped documents), and those generated with text processors or presentation software such as Microsoft Word or PowerPoint.
DigiPaper is a structured image representation for documents. One of the main reasons document images are so large is that current formats do not take sufficient advantage of the special nature of document images. For instance, most documents are composed of different types of content. Text, photographs, graphs, tables, and business graphics often appear together in a single page. A single treatment (i.e., resolution, color depth, compression) is never suited to all these kinds of material, but conventional document image formats do not provide good support for combining multiple encoding techniques. By using a structured image representation, with different layers for different kinds of material, it is possible to obtain much better compression. DigiPaper applies to each such layer an encoding method that is appropriate to that type of material, thereby providing a good trade-off between storage efficiency and image quality. To represent the different content types in the multiple layers, DigiPaper uses the Mixed Raster Content (MRC) imaging model. For compression, DigiPaper makes heavy use of token compression.
Mixed Raster Content Model
DigiPaper uses the Mixed Raster Content (MRC) multi-layer color image model that is part of XIFF 3.0, as well as proposed standards TIFF-FX and ITU-T.44 [3] [4]. DigiPaper also uses the binary JBIG2 format. Monochrome DigiPaper files are standard XIFF 3.0 files whereas color and gray-scale use extensions to XIFF 3.0. A key advantage of the MRC model is the ability to use different representations within a single page: different compression methods, color depths, and resolutions. For example, text and line art can be stored compactly at a high resolution using token-based compression, whereas certain color images might be stored at lower resolution using JPEG or wavelet compression. The result is both a compact file size and good image quality.
MRC breaks an image into three kinds of layers: background (called layer 1), selector (called layer 2), and foreground (called layer 3). These layers are combined according to certain rules in order to produce the actual page images for a document. The layers are drawn from back to front, starting with the background. Each layer builds upon the previous layers, with each selector layer acting as a filter for the foreground layer just above it. This provides considerable flexibility in representing overlapping images, text, and graphics.
Layers are drawn in numerical order. The background layer generally contains low-resolution color image data, such as a background image, a wash or other pattern that would have text overlaid on it. There can be multiple selector and foreground layers, which come in pairs (e.g., layer 4 and 5, after layer 2 and 3). Each selector layer is an even-numbered layer that is paired with the next higher odd-numbered foreground layer. A selector layer contains binary image data that is high spatial resolution, such as text and line art. The data in a selector layer is used as a mask for drawing the corresponding foreground layer (the foreground image is drawn at each pixel where the selector is "on"). A foreground layer contains color data for the text and line art, and may also contain photographic or continuous tone color data. In this way, a compact high-resolution color font can be produced, since the color information is stored at a lower resolution, which requires significantly less space. The foreground layer can be used in the same way to represent high-resolution line art.
Adding to this basic 3-layer model, other images can be overlaid on the page, including color, grayscale, and binary pictures and line art. These images are placed in additional odd-numbered layers. All even-numbered layers act as a selector for the layer above in the same way that the selector layer, layer 2, selects pixels from the foreground layer, layer 3.
The following example shows the multi-layer representation of a color document. The page is composed by first laying down Layer 1 (background layer) and then having Layer 2 select pixels from Layer 3 (foreground layer), before being placed down. Layer 2 consists of a binary image. Black pixels in this layer indicate regions where the colors from the foreground image are to be rendered. Where pixels corresponding to the selector layer are missing in the background or foreground layer, the colors white and black are used, respectively. Once the images in the first three layers -- the background, selector, and foreground layers -- have been placed down, any images contained in additional layers are placed on top of the composed image. Transparency masks may be used to assure that these overlay images do not obscure portions of the underlying text image, or that one image does not overlap another.
Not all pages require a multiple-layer representation. If there is only one layer present, then that layer can be represented by only one image, which fully contains the page contents. The single image can be defined as background, foreground, or selector (binary) image.
Token compression
DigiPaper uses token-based (sometimes also called symbol-based) compression of both the selector and foreground layers of the MRC model. Token compression was proposed as early as 1974 by Ascher and Nagy [1], but was considered a laboratory curiosity until fairly recently, when new algorithms became accurate enough at matching tokens, and processing speeds significantly increased [5]. The representation of binary images using token compression is being formalized as part of the ISO JBIG2 standard [2], and DigiPaper will adopt that format after it is finalized.
Token-based compression identifies repeated elements that occur in a document image and stores just one image representing each such element, together with the positions where that element occurs. For instance, characters are units that are commonly repeated in documents. After compression, just one representation of each token is stored, together with position information that specifies all the locations where each token should be drawn. Token compression is particularly well suited to text documents because they primarily contain structures such as characters and other graphic elements that are repeated over and over, and can then be stored just once resulting in significantly reduced file sizes. In order to achieve the best compression, these repeated elements should be identified over the entire document, not just in a single page. Thus, DigiPaper is a document representation, not a single page representation. A DigiPaper file can have one or more token dictionaries that store the images of the unique tokens. Each page of the document then specifies which token dictionaries it refers to, and contains a list of positions at which to draw those tokens.
Token-based representation yields good compression for text documents and yet can be decoded quickly (the decoding is significantly faster than the encoding). It also provides a structured representation that can be used to support text-based editing and search, as well as allowing hints based on the image content for better rendering. For electronic source documents, the token compression process is lossless (the identical image can be recovered). For scanned source documents token compression is "visually lossless", which means that the decompressed image is not bit-by-bit identical to the original but the differences are not visually apparent.
Token-based compression works well with repeated structures such as characters and line art elements. It can also be used for halftones by identifying the halftone cells. With continuous tone images (non-halftoned), such as photographs, however, DigiPaper uses standard compression means such as JPEG, wavelet or Lempel-Ziv for better results than token compression would provide.
Color token compression
In color documents, DigiPaper records not only the position of each token, but also its color. The scheme is optimized for tokens that are of uniform color (as is usually the case in business documents). When using DigiPaper token-based compression for color documents, the position information is tagged to indicate what color to use for drawing each instance of a token. This representation is both highly compact and preserves structural information such as high-resolution edge location data for color characters. Consider the simple document consisting of the single word "rollo" (where the first three letters are black and the last two are red). The token dictionary would contain the three shapes, "r", "o" and "l", and the position information would specify the sequence of shapes to be drawn (1, 2, 3, 3, 2), as well as specifying their precise locations. The color information associated with these positions is represented by simply noting that the tokens in the first three positions should be drawn using the color black and the last two using the color red (actually, the precise RGB or CMYK values would be specified).
For tokens that are not of constant color, a slightly different version of the above tagging scheme is used. Rather than noting a color for each position, a color image is masked by a token shape. These images are stored in dictionaries similar to the normal token dictionaries, except that they hold color images to be masked, rather than token masks.
The tagged token color scheme used in DigiPaper can be applied separately to the foreground plane in the MRC model. However, a more compact representation can be obtained by sharing data (both binary token dictionaries and positions) between a selector and its corresponding foreground image. This sharing achieves very compact business graphics color document images, such as Word documents or PowerPoint slides, generally representing color versions of such documents in nearly the same space as monochrome.
It should be noted that DigiPaper makes a distinction between "sampled image" data and "edge image" data. Continuous tone sampled image data is either stored using some standard compression scheme, or is stored in a color image dictionary to be masked by normal token shapes as described above. In either case, this data is separate from the character and line-art positioning data stored in token-compressed form. This can provide certain printer rendering algorithms the ability to distinguish between edge data, where position information is very important, and continuous tone or sampled data where position is less important.
Embedding DigiPaper in file formats
DigiPaper is a document representation -- a set of data structures designed to represent an image -- and not a document format. The representation is then instantiated-or embedded- in a variety of actual document formats.
DigiPaper is currently embedded in standard file formats such as XIFF (extended TIFF) [6] or Level 2 PostScript. Standard file formats make it possible to readily access DigiPaper documents with existing programs on most computers and printers. This lowers the barrier to viewing documents compared with documents in source formats such as Word or PowerPoint (where the correct version of the application must be used to access the files). Postscript files generally specify how to render a document independent of the output device, using fonts tailored to the particular computer monitor or printer where the document is presented. However, it is also possible to embed images, without the use of fonts, in PostScript files. DigiPaper simply stores the entire document as such embedded images (Adobes Acrobat Capture for scanned documents also embeds images in PDF files; however, it uses device independent fonts where it is able to do so). The most promising current embedding for DigiPaper is XIFF 3.0, and it is the one that best showcases its most advanced features. In addition to the document images themselves, the embedding of DigiPaper in XIFF allows non-visible data to be encoded in the file, such as text labels to support searching and indexing, annotations, rendering hints, or other "metadata".
Some embeddings perform better than others. For instance, the embedding in image file formats, such as XIFF (extended TIFF), is considerably more compact than the embedding in PDL, such as Postscript. Since DigiPaper is an image representation, it has greater affinity for the structure of image formats than for those of PDLs. In any case, the higher compression achieved by DigiPaper allows the document creator to choose a specific embedding based on the desired method of dissemination unconstrained by performance concerns.
Digipaper compression performance
In order to evaluate DigiPapers performance, we have compressed several sample corpora with DigiPaper and other compression methods.
The largest corpus is comprised of 1630 Cornell Computer Science technical reports. The reports are monochrome documents, composed mostly of text with inline tables and graphs, the layout is as is common in technical literature, and the median length of a report is 27 pages. Of all the documents, 80% are 600dpi bi-level TIFF Group 4 files that were scanned and the remaining 20% are electronic-source PostScript files that were rendered at 600dpi. The documents were compressed using DigiPaper XIF embedding. Table 1 shows a summary of the results.
A significant reduction in corpus size is the most noticeable result of applying DigiPaper compression to both the scanned and the electronic source corpus. Lossy compression was applied to the scanned corpus, achieving a compression factor of 7x overall (502MB vs. 3545MB). The lossy compression allows DigiPaper to combine pixel patterns that differ imperceptibly into a single token and, thereby, eliminates part of the noise introduced during the printing and subsequent scanning process in order to improve the compression.
The electronic source originals were processed with loss-less compression, given that the rendering is exact and thus lossy compression would not offer any advantages without visible artifacts. The resulting compression factor of 2.25x (172MB vs. 387MB) is impressive in that the DigiPaper image format is more compact than the original PostScript PDL, which is the reverse of what one would normally expect from comparing an image format with a PDL.
Regardless of compression factor, the more interesting comparison is the resulting average page size: the scanned documents average 8.7KB per page while the rendered ones average 13.7KB. The fact that the two are so close indicates that DigiPaper successfully extracts tokens representing glyphs from the scanned documents. However, the fact that the scanned documents use fewer bytes per page than the rendered ones is probably primarily an artifact of the document content: the scanned documents are older and printed predominantly using fixed-pitch typewriter fonts with fewer characters per page than the more recent PostScript documents.
Overall, the average size per page is remarkable in that for 90% of the scanned documents and 75% of the rendered documents, a page can be transmitted over a 28.8Kbaud modem link in less than 5 seconds. This makes DigiPaper a practical solution to disseminate guaranteed appearance electronic documents while allowing a satisfying interactive viewing experience.
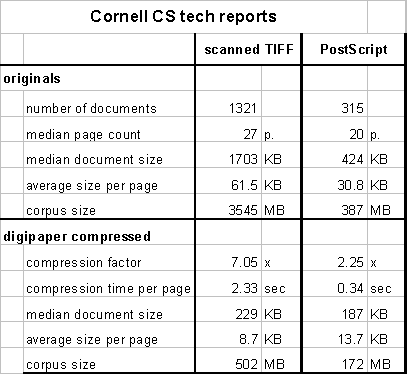
Table 1: Comparison of the original documents and the DigiPaper compressed versions for the Cornell Computer Science Tech Report corpus.
The compression times show that lossy compression takes, as expected, significantly more time than lossless compression. It takes on average 2.33 sec. for DigiPaper to compress a page from the scanned corpus on a Sun 170 Mhz UltraSparc with 4GB of memory, but only 0.34 sec. to compress one from the electronic source corpus. Since the current speed of fast scanners is 25 pages per minute at 600dpi, 2.33 sec. of compression time means that DigiPaper encodes at very close to the maximun scanner speed, allowing for efficient use of hardware resources.
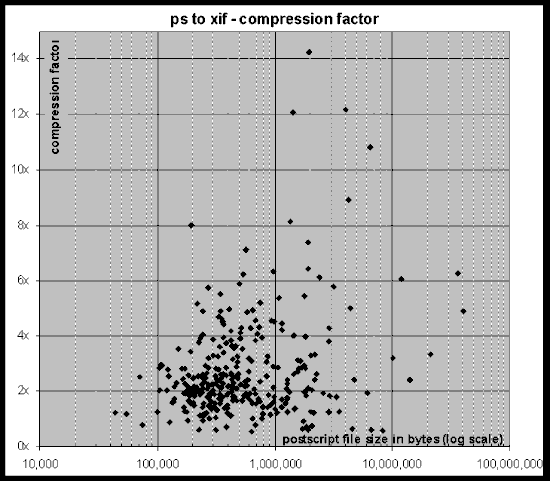
Figure 1: Compression factor achieved by DigiPaper for the PostScript documents in the Cornell CS-TR corpus.
The electronic source corpus comprises a tremendous variation in document size, from 30KB to 30MB. Figure 1 shows the compression performance over this range of document size using a log-scale X axis. Most documents fall between 100KB and 1MB and achieve a compression factor between 1.5 and 3, thus confirming that the median is fairly representative. A fair number of documents attained a compression factor of more than 6x.
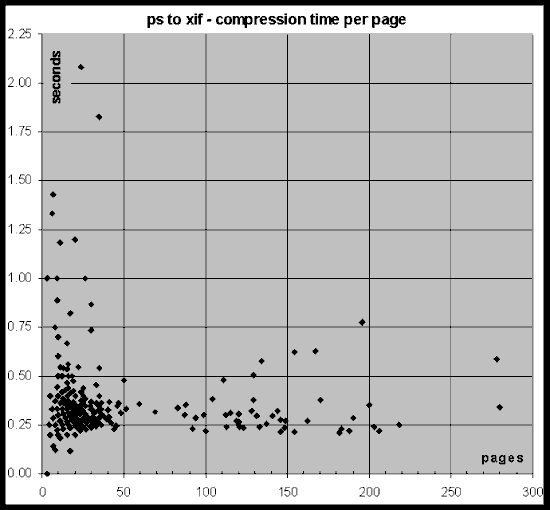
Figure 2: Compression time taken by DigiPaper for the PostScript documents in the Cornell CS-TR corpus.
Figure 2 shows the per-page compression performance which exhibits strong clustering, indicating that DigiPapers performance for electronic source documents is fairly unaffected by document size. The documents higher up along the Y axis contain some highly complex pages and thus require more processing time.
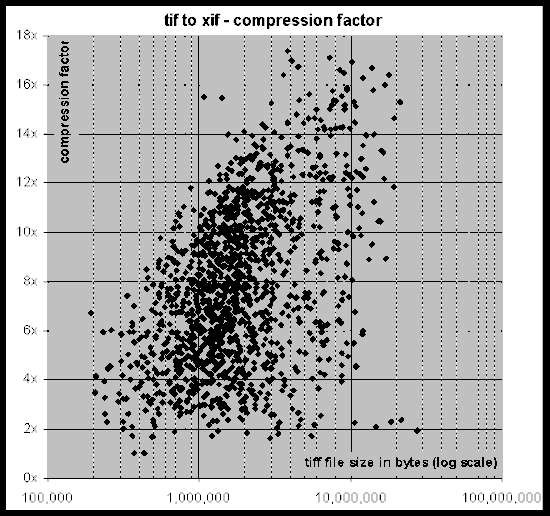
Figure 3: Compression factor achieved by DigiPaper for the scanned TIFF documents in the Cornell CS-Tr corpus.
Figure 3 shows the compression performance for the scanned documents. A noticeable trend towards higher compression with increasing document size can be observed. This trend is consistent with the use of token compression: in larger documents, token dictionaries occupy a smaller percentage of the total file size.
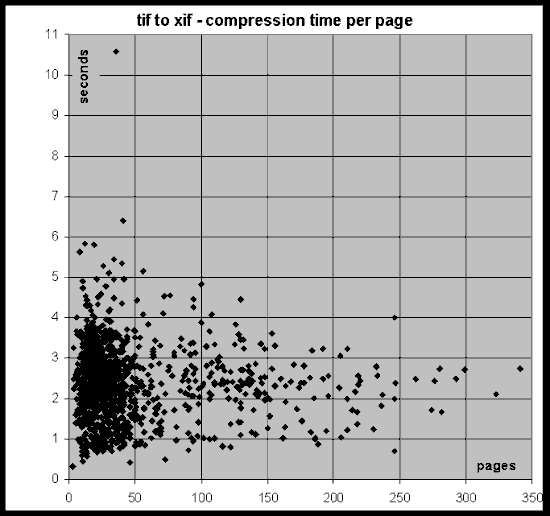
Figure 4: Compression time taken by DigiPaper for the scanned TIFF documents in the Cornell CS-TR corpus.
Figure 4 shows that most scanned documents require just a few seconds per page to encode, regardless of file size. Outlier documents are slow due to complex pages, not to document length. Note that DigiPaper achieves better compression for longer documents without any time penalty.
In summary, DigiPaper generally achieves the following compression performance using the XIF file embedding:
Monochrome scanned documents: on average a factor of 7.05 compression versus TIFF Group 4. Monochrome electronic-source documents: on average 2.25 times smaller files than PostScript. The processing time for scanned pages can keep up with 25 page-per-minute 600dpi scanners.
For the PostScript embedding of DigiPaper, the files are generally two to three times larger than for the XIF embedding (that is, the compression ratios are one half to one third of those above).
Summary
The intrinsic rendering malleability of electronic documents has significantly contributed to their fantastic ease of dissemination. On the flip side, it has resulted in an unprecedented neglect of document appearance.
This paper has examined the existing need for electronic documents with a guaranteed fixed appearance, and has proposed a new image-based document representation, DigiPaper, to fill this need. DigiPaper eliminates todays common tradeoff between maximizing dissemination and preserving document appearance. DigiPaper is designed to keep file sizes small while providing a fixed electronic form of a document.
DigiPaper relies on two technologies, MRC and token-compression. MRC is a multi-layer color image model that distinguishes between different content types within an image and then applies the best treatment to each of them. Token compression is then used as an ideal compression technology for the appropriate content types. DigiPaper is not a file format; rather, it is a document representation that can be embedded in several different kinds of file formats.
DigiPaper files are generally similar in size to an electronic source document file, such as Word or PowerPoint, or to a viewable file such as PDF. For monochrome scanned documents DigiPaper are on average 7 times smaller than CCITT G4 Fax TIFF. Because it produces very small image files, DigiPaper enables fast interactive viewing and high-speed printing. It also offers guaranteed document appearance, and is native application independent. In summary, DigiPaper is a powerful technology for networked document dissemination.
Note and References
[Note 1] DigiPaper is being standardized through the ISO JBIG2 standard for binary image compression and the MRC (Mixed Raster Content) model in ITU T.44 and in TIFF-FX profile M.
[1] R. N. Ascher, G. Nagy. "A means for achieving a high degree of compaction on scan-digitized printed text", IEEE Transactions on Computers, C-23 (11), p. 1174-1179, Nov. 1974.
[ 2] P.G. Howard, F. Kossentini, B. Martins, S. Forchhammer, W Rucklidge. "The Emerging JBIG2 Standard", IEEE Transactions on Circuits and Systems for Video Technology, 8 (7), p. 838-848, Nov, 1998.
[3] L. McIntyre, S. Zilles, R. Buckley, D. Venable, G. Parsons, J. Rafferty. File Format for Internet Fax. March 1998. (Format: TXT=200525 bytes) (Status: proposes standard).
[4] "Mixed Raster Content (MRC)", ITU-T Recommendation T.44, International Telecommunications Union.
[5] I. H. Witten, A. Moffat, T. C. Bell. Managing Gigabytes: Compressing and Indexing Documents and Images. New York: Van Nostrand Reinhold, 1994. p. 254-294.
[6] XIFF. EXtended Image File Format, version 3.0. Draft. ScanSoft, Inc., 1997.
Copyright © 2000 Dan Huttenlocher and Angela Moll
Search | Author Index | Title Index | Monthly Issues
Previous story | Next story
Home | E-mail the Editor
D-Lib Magazine Access Terms and Conditions
DOI: 10.1045/january2000-moll