D-Lib Magazine
February 1999
Volume 5 Issue 2
ISSN 1082-9873
E-commerce Catalog Construction
An Experiment with Programmable XML for Dynamic Documents
Robert Thibadeau, Ph.D., Jorge Balderas, and Andrew Snyder
Universal Library Project
School of Computer Science
Carnegie Mellon University
Pittsburgh, PA
[email protected], [email protected], [email protected]John Nestor
XML For All, Inc.
Pittsburgh, PA
[email protected]
Because of an injury to one of the authors of this story, final editing of this story took place after the initial release. This definitive version was released on February 16, 1999 at 12:30 PM, The Editor, February 16, 1999 12:30 PM.
Abstract
This paper introduces the notion of a strongly dynamic document that may be useful in electronic commerce catalogs, advanced textbooks, and other applications. It augments the existing XML web standard to include tagging for conditional interpretation. With this inclusion, a document can perform computation as well as simply feeding classed data to an external computation.
In the web, the conventional way of implementing dynamic documents is to have external scripts that interact in prescribed manners with a marked-up page. This is particularly the case for a document that is composed from dynamic sources, such as databases. By extending markup to support conditional interpretation, dynamic documents can be composed and preserved without the need for writing special scripts for each document application. We show an operational E-commerce catalog that employs a version of this augmentation that we have called XML For All, or XFA.
Introduction
Web sites generally divide into three components:
- HTML to prescribe how pages will appear in a browser,
- the HTTP server that prescribes some simple interactions between the web site and actions on a page, and
- CGI scripts and plugins, or computer programs with specific input and output format requirements, that prescribe application-specific interactions possible between actions on a page and the web site.
This paper is about a strategy that greatly reduces the need for the third, application specific, coding component through the introduction of strong dynamic documents. We also provide one in-depth analysis of such a document that is a self-contained electronic catalog directly applicable to E-commerce.
The HTTP server implements a handful of interactions, such as following hyperlinks, but the computer programs affect much of the action, such as database posting and retrieval. Computer programs cannot be written in standard HTML, because the HyperText Markup Language is a collection of simple declarative predicates, such as "title" and "href" applied over specific text strings in a document. There is no defined notion of "a variable," or of "conditional interpretation" in HTML scripting. All conditional interpretation is carried out by the computer programs that are either intrinsic to the HTTP server or to the specific application.
Recently, the World Wide Web consortium has recommended an eXtended Markup Language, XML, to integrate the original parent of HTML, the Standard Graphics Markup Language, SGML, into the web. Where HTML prescribed a small repertoire of functions suitable to small documents that are web pages, SGML prescribes a very large and open-ended repertoire of functions suitable to marking up large documents for multiple simultaneous purposes. So, for example, in SGML a single set of tags may be employed to mark up a document both as a database of information and for display as a Postscript document. Another example is a document that has two languages for presentation, such as English and French, but shares common graphics and pictures. XML, a common ground for SGML and HTML, now provides the means of manipulating such multipurposed documents on the web.
XML, like SGML and unlike HTML, incorporates explicit notions of application specific variables in its DTDs (Document Type Declarations). But, also like SGML, XML does not incorporate conditional interpretation. XML, therefore, does not have the expressive power of a computer programming language. Without this expressive power the kinds of documents that can be represented in XML are highly limited -- typically to static, non-interactive, forms such as printing on paper. Advocates of XML and SGML suggest that the XML parsing engine and the interpreter, as might be provided in CGI scripts and plugins, would provide the conditional interpretation. But, experience in computer science suggests that multipurposing a document often requires conditional interpretation on the contents. This is particularly the case when one desires to compose a document from dynamic sources such as databases.
We have recently explored a dramatic example of a dynamic document composed of tens of thousands of other dynamic documents. This is an electronic collection of weekly bulletins from tens of thousands of Churches. The collection http://www.hows.net itself is the collection of all weekly bulletins created and modified as the editors of the bulletins see fit. Motivated by this specific application, we augmented XML to include conditional interpretation, and therefore the expressive power of a programming language. This augmented XML is called XFA (XML For All). The Church collection document on the web at the time of this writing does not use XFA, but a large XFA beta testing site is currently available to volunteers who edit bulletins for their churches. Dynamic pages are the rule, not the exception, in the beta site. One page of the Church bulletin document may need to fetch all churches within a mile of a selected location. This is clearly a dynamic page that requires conditional interpretation of some of its components.
With XFA, dynamic documents can be composed without the need for writing special programs that interpret specific markup. Often, perhaps all too often, those specific programs have little meaning or use outside of the particular document. Furthermore, in the spirit of the intentions behind SGML, the dynamic XFA document is completely self-contained in that all conditional interpretation reliant on web server resources or user input is made specific.
So, for example, with XFA, one can author an algebra textbook that contains exercises where a reader can actively test his knowledge of algebra. The document itself can interact with the user and tell whether the user is right or wrong. It would be hard to argue, as some XML advocates might, that these algebra exercises are not part of the document itself.
The programmable augmentation of XML that XFA provides is, itself, outside the scope of XML. While it is true that XFA subsumes XML, and any XFA document through a simple quoting filter can be parsed by an XML parser, the full specificity of the XFA document cannot be realized by a conventional XML system. This lack of interoperability should not be of concern because it would be the case in comparing any two XML systems that include more than just a syntactic parser (and perhaps style sheets). In effect, making a commitment to XFA requires a commitment to certain fixed ways of augmenting XML for programmability.
For this reason we have undertaken a series of studies of dynamic documents that may benefit from the augmentation provided in XFA. Certainly the dynamic church bulletin of bulletins and the algebra textbook are two such instances. We are in the process of investigating many others.
Principal among these are electronic commerce catalogs. The E-commerce catalog is particularly interesting because it is much more broadly applicable than church bulletins or textbooks. Furthermore, a useful electronic catalog is clearly a highly dynamic document even in its most simplified form. A reasonable dynamic catalog must be able to take orders for the products it lists and provide powerful ways to search for those products. We now turn to the experiment with an electronic commerce catalog.
The Experiment
The remainder of this paper reports in detail the experiment to clearly understand the work involved in a dynamic catalog document using XFA. We asked a 20 year old undergraduate from ITESM (the Monterrey Institute of Technology) in Mexico, the second author of the paper. His task was to take a simple design for a catalog, learn XFA, and write the dynamic document that implements the catalog. This paper reports on the time and effort involved, and also explains and shows the entire dynamic document markup for the electronic catalog.
The electronic catalog is at http://www.ecom.cmu.edu/xfa. It allows for an exploration of computer hardware catalog items by item name, product category, and manufacturer. A person coming to the catalog can register with the catalog. Another catalog page implements a shopping basket associated with the registered user. This page also dynamically totals the costs of all the items in a shopping basket and figures out shipping costs.
While this is a fairly simple electronic catalog, it was deemed sufficiently challenging to represent a good report on augmenting XML for dynamic document markup.
Methodology
The electronic catalog document incorporates procedures written in XFA to query and update data in a database. The XFA catalog pages are interpreted by the XFA interpreter.
We have implemented a general purpose XFA interpreter that can be used with any XFA page. This implementation is a CGI script on our HTTP server, but this particular implementation is arbitrary since XFA could also be realized as a plugin in a server or browser. So as to be compatible with any existing HTML browser, the interpreter generates an HTML page that incorporates responses to user input and the data retrieved from the database. HTML forms are read directly by form-specified XFA documents in order to allow the users to input the information for query or to enter information into the database. For compatibility with virtually all database systems, XFA provides a standard database interface using markup that queries and updates data through the widely-used ODBC protocol.
Detailed Catalog Description
The catalog allows the user to perform searches of a product in the catalog in three different ways: by the name of the product; by the name of the manufacturer; or by category of the product. If the user chooses to search a product by name, a form is displayed in which the user can input the product name. In the other two options, a list of categories or manufacturers is shown in the form of hyperlinks.
The user also has the option to browse the whole list of products in the catalog. In all cases the user will end up with a table that contains a list of products with price, manufacturer, quantity in stock and a link that allows the customer to add the product to his/her shopping cart. If the customer clicks on the link to add a product to cart, the customer's ID and password will be requested, and, if the password matches a valid customer ID, the product will be added to the customer's cart.
One more essential page lets the user register as a customer in the database. A form prompts the customer for name, address, telephone number, credit-card number, and password. This information is entered in the database and the customer is issued a customer ID number.
Every time the customer adds a product to his or her shopping cart, its contents are displayed. This page includes an option to place the order. The catalog page also provides the option to browse the contents of the customer's cart from the main page.
Catalog Architecture
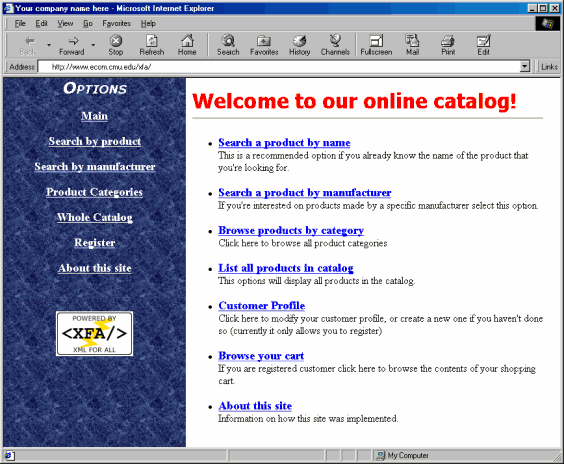
The architecture of the main page of the document consists of a pair of frames: the main and the menu frame. Both frames have the same option links, but the menu frame remains always present while the main frame is used to display the page requested.
The frames that compose the welcome page and the "About" page are the only static HTML files of the catalog. Everything else that is presented to the user is a rendering of dynamic XFA pages. These are expressed in HTML for transmission to the user's browser.
Figure 1
Look and feel of the catalogDatabase
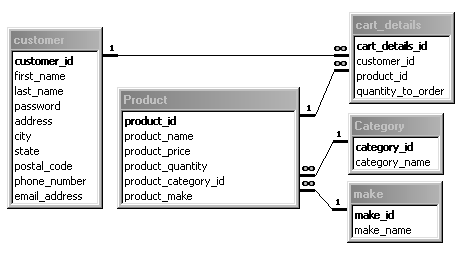
All of the product and customer information is stored in a relational database implemented using Microsoft Access. Five tables are used: customer, product, cart details, category and make. The customer table contains all the information (i.e., name, address, etc.) about the customer. The primary key, the Customer ID, is assigned at the time of registration.
Figure 2
ERD of the databaseThe product table contains the attributes: ID (its primary key), name, price, quantity, category and manufacturer name. Both category and make tables contain two attributes: the ID and the name of the category or manufacturer accordingly. There is a fifth table, which contains the details for all shopping carts. This entity contains as attributes: the customer and product ID, which are references to their corresponding tables, and the quantity to order.
Effort
The estimated time involved in building the electronic catalog, including the time spent in learning the markup language, with no prior knowledge of XML but working knowledge of HTML, was about 60 hours.
The distribution of time spent in building the E-commerce application including time learning XFA programming, coding and debugging time, and database and catalog construction is shown in the chart in Figure 3.
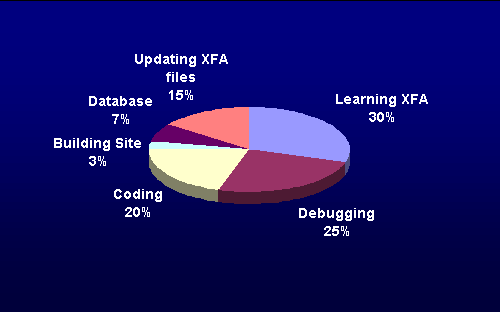
Figure 3
Distribution of time spent building the catalog.Thirty percent of the total time (i.e., about 18 hours) was spent becoming familiar with the language itself. That involved learning the syntax, data types, and providing methods and conditional interpretation statements (e.g., for, if, etc.) in XFA.
Coding and debugging the XFA document involved about half of the time invested in completing the demo. All coding was done using a simple text editor. The second author is of the strong opinion that coding time can be reduced with the use of a text editor that simply highlights the reserved keywords of the language.
A significant 15% of the time was devoted to replacing changes in the syntax of XFA. Since XFA is undergoing active development at this time, we might expect this additional time would be eliminated when the language is fully developed. On the other hand, this 15% is also a sign that markup does require periodic updating, if only to keep up with new features in standards.
Building the catalog and the database in Microsoft Access required around 10% of the overall time. The author was already familiar with Access.
XFA
The XFA markup language is processed by an interpreter which is written in C. The interpreter incorporates a nearly complete XML parser augmented for computer programmability and for certain standard I/O interfaces. These interfaces include an ODBC interface to databases such as Microsoft Access, Sybase, ADABAS, and Oracle, and an interface for handling HTML form input.
All of the XFA code that implements the E-commerce catalog is available on the catalog at http://www.ecom.cmu.edu/xfa in the "About" area, and, in fact, uses additional XFA markup pages to fetch and pretty-print the actual code for viewing. This is not a copy of the code; it is the real code as the interpreter sees it. Again, this makes a case for strongly dynamic documents because you are not left wondering if the code you are seeing is, in fact, capable of producing what you see.
As a programming language, XFA supports the following data types: strings, trees, objects and object sets. Strings are further explicitly specialized if necessary as integers, booleans, currencies, dates.
All of XFA is expressed in the form of tags. In keeping with XML name space proposals, all XFA tags start with xfa (e.g., <xfa:val row^attribute>). XFA procedures are known as functions and they must begin with the tag: <xfa:function name>, and, at the time of this writing, must be saved in the .xfa file that matches the function name. More generally, a function is always defined as a path in a hierarchy of objects.
An XFA document can include any valid HTML and XML. A typical XFA document will include XFA tags mixed with HTML tags. A sample XFA file is shown in Figure 4. This example shows the syntax of a loop in XFA, delimited by the tags <xfa: for ..> and </xfa: for>. Within this loop there are several XFA tags, such as <xfa: val s1^product_name> which provides the value of a field in the database.
XFA provides support for HTML form entry. XFA forms work as HTML forms. For instance, the XFA interpreter supports the HTTP method post, which will call an XFA function when the submission button is pressed and will pass the text input in the form fields to an XFA function.
<xfa:function list_all>
<xfa:note This macro allows to list all the products in the database/>
<HTML>
<HEAD>
<TITLE>
List of all existing products.
</TITLE>
</HEAD>
<BODY BACKGROUND="../fondo.gif">
<FONT FACE="Tahoma" COLOR="Navy">
<H3>
List of products.
</H3>
</FONT>
<HR>
<P>
<CENTER>
<TABLE BORDER=1>
<TR>
<TD><STRONG>
<TD><STRONG>Manufacturer
<TD><STRONG>Name
<TD><STRONG>Price
<TD><STRONG>Quantity<BR> in stock
<xfa: for s1=Sort(objects^product,"product_category_id")>
<TR>
<TD><xfa:ref input_cust_id (s1.product_id)>
<I>Add to cart!
</xfa:ref>
<TD><xfa:val s1^product_make.make_name/>
<TD><xfa:val s1^product_name/>
<TD ALIGN=RIGHT>
<xfa:val s1^product_price/>
<TD ALIGN=RIGHT>
<xfa:val s1^product_quantity/>
</xfa: for>
</TABLE>
</BODY>
</HTML>
</xfa:function>Figure 4
Sample of a XFA file: list_all.xfaA relational database in XFA is referenced as objects; a table from a database has type object set; and a table row has type object. A database table in XFA should be referenced as objects^table_name and an attribute from a table is referenced as obj^table_name^attribute_name.
XFA provides the following database access methods: filter, sort, new and delete, which allow performing equivalent operations to the "SELECT FROM WHERE" and "UPDATE" statements in SQL.
A database configuration file is needed to map the tables and fields that are to be accessed through XFA functions. This file is shown in Figure 5.
<xdata:database dsn="catalog"
user="Admin" password="">
<xdata:db_table
XFA_name="product" SQL_name="product"
SQL_key="product_id">
<xdata:table_attr
XFA_name="product_name"
SQL_name="product_name"
type="string" size="50"
default="*name*"/>
<xdata:table_attr
XFA_name="product_price"
SQL_name="product_price"
type="currency" default="$0.0"/>
<xdata:table_attr
XFA_name="product_quantity"
SQL_name="product_quantity"
type="integer" default="0"/>
<xdata:table_attr
XFA_name="product_category_id"
SQL_name="product_category_id"
type="ref" ref="category" default="1"/>
<xdata:table_attr
XFA_name="product_make"
SQL_name="product_make"
type="ref" ref="make" default="1"/>
</xdata:db_table>
</xdata:database>Figure 5
data.xml - database configuration fileConclusions
The original intent of SGML was to provide a means for creating multipurposed digital documents. With HTML this intent was partially lost because HTML was itself only a single instantiation of purpose. The purpose was solely the viewing of mini-documents on the web that were tied together through hyperlinks and simple actions such as form requests. However, most of the intelligence behind the documents has had to be specially programmed using languages like PERL, C, Visual Basic, and JAVA, as CGI scripts and plugins. With the introduction of XML as a recommended method for reinstating the multipurposing power of SGML, we can also entertain broadening the purposes to which documents can be authored. This paper has considered broadening the purpose to the largest known possible set by the inclusion of conditional interpretation and general programmability.
To be as clear and definite as is possible, we have explored a complete E-commerce catalog using an augmented version of XML termed XFA and we have provided all the source for the XFA catalog document for viewing. This experiment cannot be judged a success or failure since we knew a priori that general programmability could guarantee that the XFA language could be employed to express whatever document actions were desired. Rather, this experiment constitutes a set of observations, and this paper constitutes a clear elucidation of these observations. It is for the practitioners of the art of authoring dynamic documents to judge whether conditional interpretation is to be preferred over the use of specialized CGI scripts and plugins.
The example of a textbook that contains its own interactive exercises and, perhaps, tests would be an interesting further experiment for XFA. But there are many other, perhaps less obvious, uses. Another book that would be much better as a dynamic book would be an atlas. Plausably a complete atlas is several billion bytes, but an intelligent atlas might overcome this problem by providing its own methods for interacting with the desires of the person trying to use it. In past experiments, we developed an extreme science fiction novel called "Metafire," that contains such active experiential elements as an ultrafast web spider and a live geiger counter. Use of a language like XFA would permit a closer tie to reading the novel and physically experiencing its plot components.
We also developed a metadata language for document storage and display where the code for the interpretation of many of the metatags could be better incorporated into the document itself. For example, many figures and graphics have no general solutions for alternative display. There could be a "conditional skip chain" that queries environmental resources for storage and presentation according to the author's own judgement.
Finally, we believe our work with color presentation of antique books would be enhanced with built-in internal search, or page hopping, associated with the book content itself. The same words meant something quite different two hundred years ago, and important topics and events were important in their day, not ours. When you are "in" one of these books, you are in a different world, and that world demands its own unique interactive solutions to electronic presentation.
More generally, self-contained dynamic documents allow authors, publishers, and people who index documents, much greater flexibility as the individual characteristics of the individual documents become more important to accessing document content in a preservable fashion.
The introduction of the XML recommendations from the World Wide Web consortium promised the "contextualization" of document information. In effect, by employing the DTDs to type or classify tags, it is hoped that new tags could be introduced and their proper parsing known. While it is readily possible to produce a DTD for XFA, the DTD does not contextualize a document as strongly as, for example, ANSI C function declarations contextualize ANSI C functions. This is a problem for meeting the full spirit of XML, if, indeed, people find it advantageous to employ strongly dynamic documents for textbooks, collections of dynamic documents like bulletins, extreme books, old books, and for E commerce catalogs. We have to be concerned about dynamic documents of the future as well as the static documents of the past.
But, there is a deeper problem of contextualization that SGML, XML, and XFA do not address. This is contextualization to the semantic levels needed to disambiguate the intent of content across the Internet. For example, how can I know that the XFA catalog site is a demo site that illustrates the use of augmented XML in strong dynamic documents, and not, for example, a real ecommerce site that is selling goods from Hewlett-Packard? While a person can readily detect that this is a demo site, a machine may have difficulty. A newer recommendation from the World Wide Web consortium, termed RDF, or the Resource Description Framework. RDF permits the predication of document parts by other documents and document parts. Standardizing predications would be a logical next step past RDF. RDF, like XFA, is written in XML but includes certain assumptions about conditional interpretation that XFA may make explicit. An interesting experiment would be to write RDF predications in XFA and make these sources available as dynamic predicating of new documents and document parts. For example, a document that can answer questions about itself, even though it, itself, may be dynamic. So a view of all this is a view of digital libraries of dynamic documents utilized as we use reference documents or textbooks today.
References
For additional reference, the following links are provided:
http://www.ecom.cmu.edu/xfa
URL for the E-commerce catalog mentioned in this paper.http://www.xmlforall.com
Site for the extended markup language (XFA).http://www.w3c.org/xml
XML Site from the World Wide Web Consortium.http://www.w3c.org/rdf
RDF Site from the World Wide Web Consortium.Glossary of terms
ANSI C (American National Standards Institute "C" Programming Language Conventions)
CGI (Common Gateway Interface)
DTD (Document Type Declarations)
ERD (Entity Relationship Diagram)
HTML (HyperText Markup Language)
HTTP (HyperText Transfer Protocol)
ODBC (Open Data Base Connectivity)
RDF (Resource Description Framework)
SGML (Standard Generalized Markup Language)
SQL (Structured Query Language)
XFA (XML For All): XML augmented with Programmability.
XML (eXtended Markup Language)
Copyright © 1999 Robert Thibadeau, Jorge Balderas, Andrew Snyder and John Nestor
Because of an injury to one of the authors of this story, final editing of this story took place after the initial release. This definitive version was released on February 16, 1999 at 12:30 PM, The Editor, February 16, 1999 12:30 PM.
Top | Contents
Search | Author Index | Title Index | Monthly Issues
Previous Story | Clips and Pointers
Home| E-mail the EditorD-Lib Magazine Access Terms and Conditions
DOI: 10.1045/february99-thibadeau